
Der Kthreadd ist der Vater aller Kernelthreads. Die von ihm abgeleiteten Codesequenzen erben einen eindeutigen Kontext. Für Entwickler von Vorteil: weniger Arbeit und weniger Fehler im Code.
Kernelthreads haben einen festen Platz im Betriebssystemkern. Ein Ubuntu 10.04 beispielsweise aktiviert – je nach Rechnerhardware – zwischen 50 und 80 derartiger Verarbeitungssequenzen. Sie sind unabhängig vom Userland, Linux weckt sie nur bei Bedarf auf und sie belasten das System kaum. Sie sind effizient und dank der Realzeit-Eigenschaften des Linux-Kernels nur mit geringen Latenzzeiten behaftet. Daher setzen die Kernelhacker sie ein, um Jobs zwischen Rechnerkernen zu verschieben, regelmäßig Daten des Pagecache auf die Festplatte zu sichern oder um Daten zu ver- beziehungsweise zu entschlüsseln.
Fußgängern droht Stolpergefahr
Da die rudimentäre Variante, einen Thread durch Aufruf der Funktion »kernel_thread()« zu erzeugen, fehlerträchtig ist, wie der Kasten “Kernelthreads” beschreibt, stellt Linux mit dem im Kernel laufenden Kthreadd ein risikolos verwendbares Framework bereit. Es sorgt nämlich anders als ein schlichter neuer Thread für eine eindeutige Erbmasse: Die vom Kthreadd erzeugten Threads belegen keine Ressourcen im Userspace, öffnen keine Dateien, blockieren alle Signale, dürfen auf jeder CPU eines Multicore rechnen und besitzen anfangs eine eindeutige Priorität.
|
Kernelthreads |
|---|
|
Kernelthreads sind unabhängige Codesequenzen, die der Scheduler wie normale Applikations-Threads aktiviert und die CPU abarbeitet. Folglich besitzen sie einen eigenen Prozess-Kontrollblock (siehe Kasten “Prozess-Kontrollblock”) und eine eigene PID. Sie unterscheiden sich von normalen Applikations-Threads dadurch, dass Code und Daten im Kernelspace – und eben nicht im Userspace wie bei den Benutzerprogrammen – liegen. Außerdem wird ihre Abarbeitung im Kernel nur dann unterbrochen, wenn höher priore Aufgaben anliegen. Kernelthreads erzeugt der Programmierer durch Aufruf der Funktion »int kernel_thread(int (*fn)(void*), void *arg, unsigned long flags)«. Das Argument »fn« bezeichnet die Adresse der im Rahmen des Thread zu startenden Funktion und »arg« ein Argument, das ihr der Kernel beim Starten übergibt. Der Parameter »flags« steuert die Thread-Erzeugung über verschiedene, in der Include-Datei »linux/sched.h« definierte Konstanten. Bei Kernelthreads verwenden Entwickler dazu typischerweise die Kombination aus »CLONE_FS«, »CLONE_FILES« und »CLONE_SIGHAND«, um sich der nicht mehr benötigten Filesystem-Information zu entledigen und zunächst die gleichen Filedeskriptoren und Signalhandler des “Erzeugers” (Elternprozess) zu übernehmen. Innerhalb der Threadfunktion geben Programmierer durch Aufruf der Funktion »daemonize()« zum einen die geerbten Ressourcen im Userland frei (Code- und Datensegmente), zum anderen geben sie dem Kernelthread einen Namen. Verantwortungsbewusste Entwickler legen ihre Threads regelmäßig schlafen, damit der Scheduler auch gleich oder niedriger priorisierte Prozesse auswählen darf. Schließlich verhindern ein Completion-Objekt und der Aufruf der Funktion »complete_and_exit()«, dass Linux den Threadcode entlädt, bevor der Thread sich beendet. Unterlässt der Programmierer das oder sorgt darüber hinaus nicht dafür, dass der neue Kernelthread eine eindeutige Priorität besitzt und auf allen Rechnerkernen einer Mehrprozessormaschine arbeiten darf, sind Fehlersituationen programmiert! |
Daher delegieren clevere Entwickler die Aufgabe, einen neuen Thread zu starten, an die Komponente, die etwas davon versteht: den Kthreadd. Der Kernel aktiviert ihn als Vater aller Kernelthreads direkt nach dem Start des Init-Prozesses. Folglich besitzt der Threadverteiler auch die PID 2 (Abbildung 1). Er wartet auf Aufträge, neue Prozesse zu erzeugen und mit einem Namen zu versehen, um sie dann umgehend ausführen zu lassen.
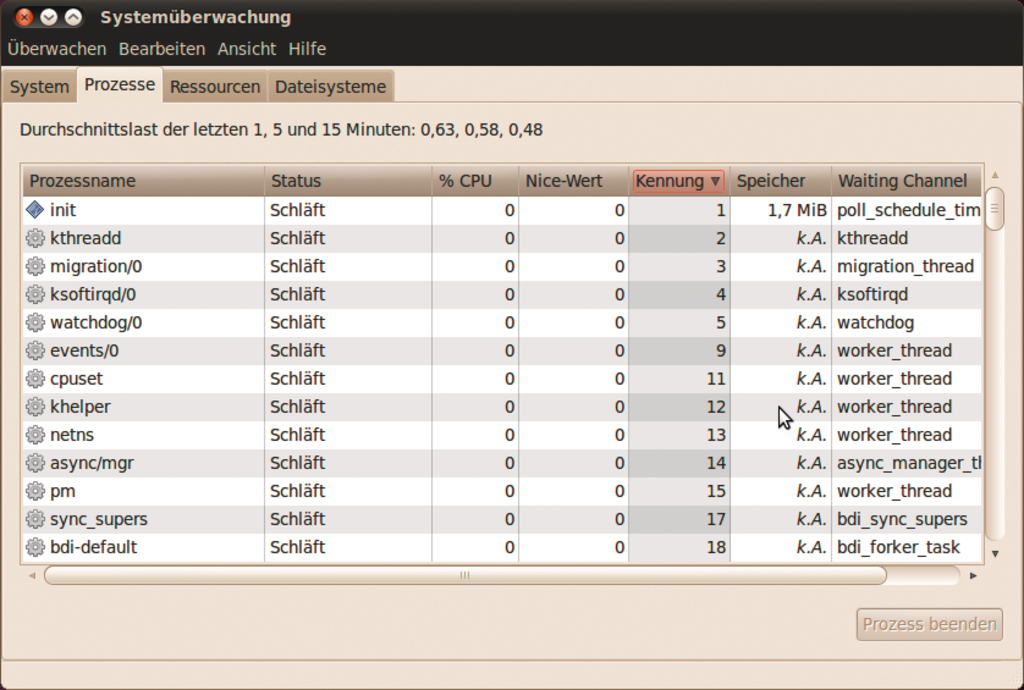
Abbildung 1: Linux startet den Kthreadd als zweiten Prozess. Von ihm leitet das Betriebssystem die meisten übrigen Kernelthreads ab (im Bild alle nachfolgenden).
Der Programmierer meldet dem Kthreadd drei Werte: erstens die Adresse der im Kontext des Thread abzuarbeitenden Funktion, zweitens ein Argument, das der Daemon der Funktion beim Aufruf übergibt, und drittens den neuen Threadnamen. Das zweite Argument ermöglicht es dem Programmierer, Threadfunktionen mehrfach zu verwenden: Er identifiziert damit die jeweilige Instanz.
Innerhalb der gewählten Funktion sind die für Kernelthreads üblichen Einschränkungen zu beachten: Der Programmierer gibt daher nur die Signale frei, die zu einer Unterbrechung führen dürfen. Sind Threads einmal aktiv, werden nur noch Geschwister sie unterbrechen, die eine höhere Priorität genießen. Daher verhält sich der Entwickler auch bei den über den Kthreadd erzeugten Threads kooperativ und legt seine Codesequenzen regelmäßig schlafen (siehe Abbildung 2). So hat jeder Thread eine Chance auf die CPU. Nach dem Aufwachen prüft er, ob ein Signal den Job geweckt hat. War dies der Fall, behandelt er das Signal und beendet normalerweise den Thread.

Abbildung 2: Der Funktionscode wertet »kthread_should_stop()« aus, um sich bei Signalen zu beenden.
Reine Kernelthreads
Falls ein Kernelmodul den Thread startet, fängt der Programmierer noch eine Race Condition ab: Auf keinen Fall darf die Bearbeitungssequenz aktiv sein, wenn ein Anwender das Modul entlädt. Vorher beendet es seinen Thread beispielsweise mit Hilfe eines Signals und wartet auf eine Vollzugsmeldung. Dabei hilft der im Kasten “Completion-Objekt” beschriebene Mechanismus.
|
Completion-Objekt |
|---|
|
Das Completion-Objekt »struct completion« synchronisiert einen Ablauf mit dem Ende einer Codesequenz und realisiert die beiden Methoden »void complete(struct completion *)« und »void wait_for_completion(struct completion *)«. Die erste setzt der Entwickler an das Ende des zu überwachenden Abschnitts, die zweite Methode ruft der wartende Kernelthread oder die wartende Treiberfunktion auf. Die Variante »complete_and_exit()« der Methode »complete()« setzen Entwickler bei Kernelthreads ein. Das Ende mehrerer Codesequenzen zeigt »void complete_all(struct completion *)« an. Zu »wait_for_completion()« gibt es drei Varianten: »unsigned long wait_for_completion_timeout(struct completion *, unsigned long timeout)«, »int wait_for_completion_interruptible(struct com-pletion *)« und »unsigned long wait_for_completion_interruptible_timeout(struct completion *, unsigned long timeout)«. Dazu kommen noch Makros und Funktionen, die das Objekt initialisieren. Das Makro »DECLARE_COMPLETION(struct completion *name)« legt für das Objekt statischen Speicher unter »name« an. Initialisiert der Programmierer ein Completion-Objekt zur Laufzeit, reserviert er erst den Speicher und übergibt dann die Adresse von »void init_completion(struct completion *)«. Technisch steckt hinter dem Completion-Objekt eine Integer-Variable (Abbildung 6), die die Funktion »complete()« beim Aufruf inkrementiert. Die Funktion »wait_for_completion()« legt den Thread schlafen, wenn die Variable bereits 0 ist. Andernfalls dekrementiert sie die überwachende Variable. 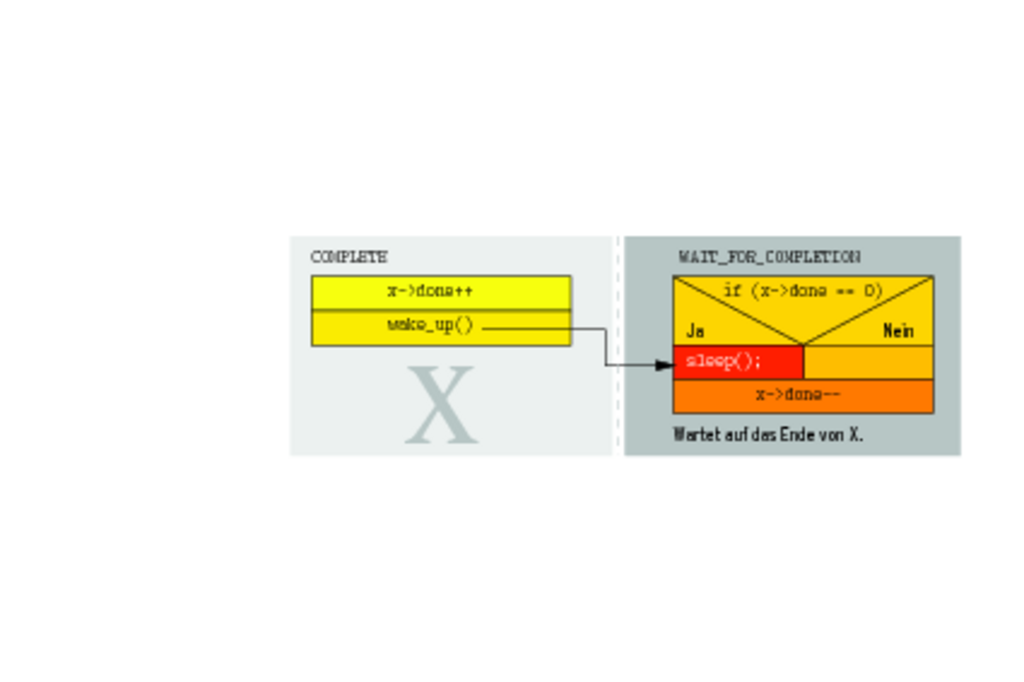 Abbildung 6: Vereinfacht dargestellt schläft der Thread, der auf das Ende einer Codesequenz wartet, bis die Variable »done« positiv ist. Aktiviert der Kernel zum Beispiel erst einen Thread, der wegen »wait_for_completion()« auf das Ende einer anderen Codesequenz wartet, ist die Variable »done« noch 0. Folglich legt der Kernel den Thread schlafen. Er wird durch Aufruf von »complete()« wieder aufgeweckt. Ist die Reihenfolge jedoch andersrum – erst wird die Codesequenz mit »complete()« aufgerufen -, dann ist der Wert der Variablen »done« 1. Der später kommende Thread legt sich nicht schlafen, sondern dekrementiert nur »done«, sodass die Variable wieder den Wert 0 hat. Der Trick mit der Variablen ermöglicht es, mit einem Objekt auch auf das Ende mehrerer Codesequenzen auf einmal zu warten. Die Funktionen, auf die das Objekt warten soll, führen jeweils am Ende »complete()« aus, während die abwartende Instanz mehrfach die Funktion »wait_for_completion()« aufruft. |
Ein Programmierinterface macht die Auftragsvergabe leicht. Es besteht aus den in Tabelle 1 gelisteten Funktionen. Um einen neuen Kernelthread zu erzeugen und gleichzeitig auch zu aktivieren, wählt der Programmierer das Makro »kthread_run()«. Es bekommt mindestens drei Parameter übergeben.
|
Tabelle 1: |
|
|---|---|
|
Funktion |
Beschreibung |
|
struct task_struct *kthread_create(int (*threadfn)(void *data), |
Erzeugt einen Kernelthread, zum Starten ist “wake_up_process()” |
|
struct task_struct *kthread_run(int (*threadfn)(void *data), |
Makro. Erzeugt und startet einen Kernelthread. |
|
int kthread_should_stop(struct task_struct *k); |
Das Makro überprüft das per “kthread_stop()” gesetzte |
|
int kthread_stop(struct task_struct *k); |
Ein gestarteter, aber noch nicht aktiverter Kernelthread wird |
|
int kthread_bind(struct task_struct *k, unsigned int cpu); |
Der Kernelthread “k” wird nur auf den in der Maske “cpu” |
|
int wake_up_process(struct task_struct *process); |
Aktiviert den Thread “process”. |
Mit dem ersten Parameter nennt er die Adresse der Funktion, die Linux im Rahmen des Thread ausführen soll. Zweitens übergibt er einen Parameter, den das Makro seinerseits der Threadfunktion überantwortet. Drittens schließlich spezifiziert er den Namen des Thread. Ihn gibt er – wie bei »printf()« – in Form eines Formatstrings mit nachfolgenden Parametern an: Die Funktion hat also tatsächlich eine variable Anzahl von Argumenten (Listing 1, Zeile 31).
|
Listing 1: |
|---|
01 #include <linux/module.h>
02 #include <linux/kthread.h>
03
04 static struct task_struct *thread_id;
05 static wait_queue_head_t wq;
06 static DECLARE_COMPLETION(on_exit);
07
08 static int thread_code(void *data)
09 {
10 unsigned long timeout;
11 int i;
12
13 allow_signal(SIGTERM);
14 for (i = 0; i < 5; i++) {
15 timeout = HZ; // wait 1 second
16 timeout = wait_event_interruptible_timeout(wq,
17 (timeout == 0), timeout);
18 printk("thread_function: woke up ... %ldn",
19 timeout);
20 if (timeout==-ERESTARTSYS) {
21 printk("got signal, breakn");
22 break;
23 }
24 }
25 complete_and_exit(&on_exit, 0);
26 }
27
28 static int __init kthread_init(void)
29 {
30 init_waitqueue_head(&wq);
31 thread_id = kthread_create(thread_code, NULL,
32 "mykthread%d", 0);
33 if (thread_id == 0)
34 return -EIO;
35 wake_up_process(thread_id);
36 return 0;
37 }
38
39 static void __exit kthread_exit(void)
40 {
41 kill_pid(task_pid(thread_id), SIGTERM, 1);
42 wait_for_completion(&on_exit);
43 }
44
45 module_init(kthread_init);
46 module_exit(kthread_exit);
47
48 MODULE_LICENSE("GPL");
|
Die eigentliche Funktion für das Anlegen des Kernelthread als Kindprozess des Kthreadd ist allerdings »kthread_create()«. Die Parameter sind identisch zum Makro »kthread_run()«, unterschiedlich ist allein, dass der Thread nur angelegt und die eigentliche Threadfunktion (produktiver Code) nicht direkt gestartet (ausgeführt) wird.
Erst auf Kommando starten
Zum Starten muss der Programmierer erst ein »wake_up_process()« mit der Adresse des Prozess-Kontrollblocks aufrufen (siehe Kasten “Prozess-Kontrollblock”). So versetzt er den Thread schon mal in eine Warteposition und kann ihn dann mit kurzer Latenz aktivieren.
|
Prozess-Kontrollblock |
|---|
|
Jeder Rechenprozess, also auch die Kernelthreads, ist im Betriebssystemkern über eine Datenstruktur, den so genannten Prozess-Kontrollblock (PCB), eindeutig identifiziert. Im PCB sind beispielsweise der Prozesszustand, der Name, die PID, die Priorität, die zur Abarbeitung freigegebenen Rechnerkerne ebenso hinterlegt wie die Adressen der Segmente, in denen sich Code und Daten des Jobs befinden. Bei der Prozessorganisation untersucht der Scheduler die Liste der PCBs, um daraus den nächsten Job auszuwählen, den er dann abarbeitet. Im Linux-Kernel lautet der Name des PCB »struct task_struct«. Die Struktur ist in der Headerdatei »linux/sched.h« definiert. |
Falls er es sich nach dem Starten und vor dem Aktivieren jedoch anders überlegt hat und den Thread beenden will, bevor der produktive Code überhaupt abgearbeitet ist, ruft er vor dem Aufwecken die Funktion »kthread_stop()« auf. Diese setzt in einer zum Thread gehörenden Datenstruktur das Flag »should_stop«. Der Zustand des gesetzten Flag lässt sich mit der Funktion »kthread_should_stop()« prüfen (Abbildung 3).
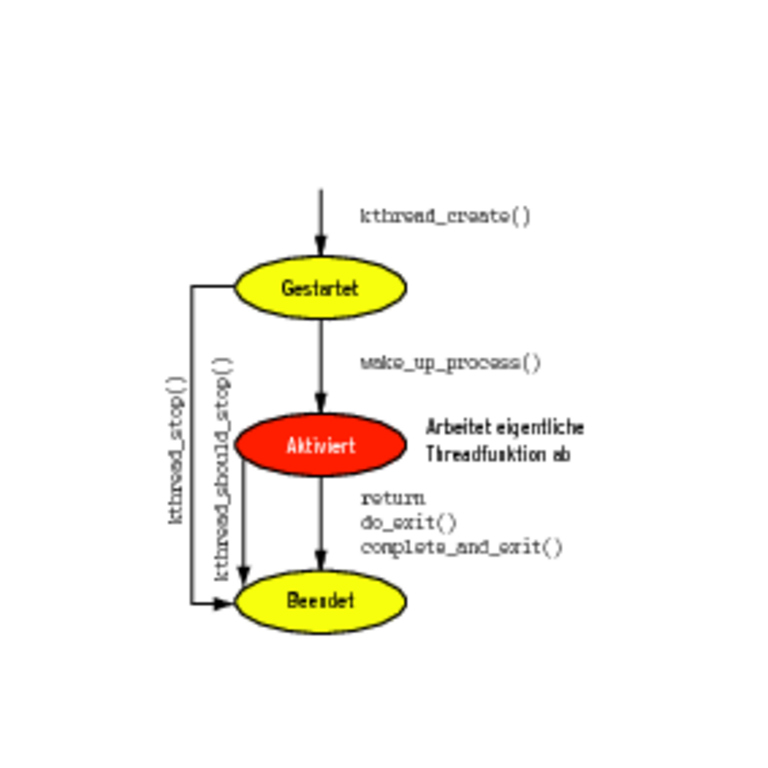
Abbildung 3: Per Kthreadd erzeugte Kernelthreads durchlaufen bis zu drei Zustände.
Eine weitere Funktion ist »kthread_bind()«. Mit ihr fesselt der Entwickler auf einem Mehrkernsystem den Kernelthread an einen oder an mehrere Prozessoren und zwingt den Kernel damit, ihn dort exklusiv abzuarbeiten.
Threadfunktionen, die der Kthreadd startet, müssen nicht zwangsläufig, dürfen aber »do_exit()« am Ende ihres Code aufrufen. Ein einfaches »return« reicht, weil der Kthreadd der eigentlichen Threadfunktion noch Code vor- beziehungsweise nachlagert (Abbildung 4).
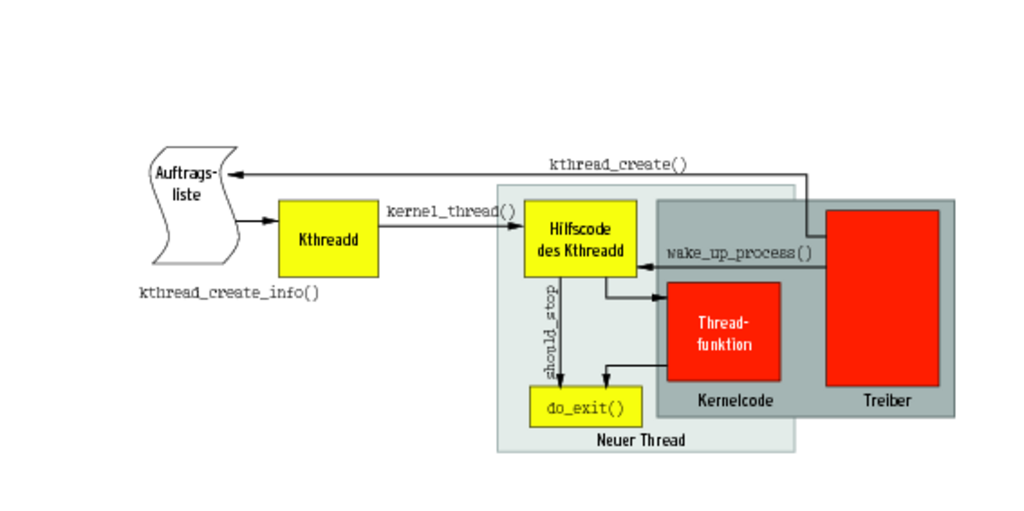
Abbildung 4: Treiber erzeugen Kernelthreads nicht mehr selbst, sondern delegieren diese Aufgabe an den Kthreadd. Der kümmert sich insbesondere um die Einbettung in den Schedulerbetrieb.
Intern erzeugt der Kthreadd die neuen Kernelthreads. Der Einstieg in den Daemon aus Kernelcode, etwa einen Treiber, ist die Funktion »kthread_create()«. Sie hängt in eine Auftragsliste Namen, Parameter und Funktionsadresse des Thread ein und weckt den Kthreadd auf. Der holt sich den Auftrag und ruft seinerseits die Funktion »kernel_thread()« auf und erzeugt somit einen neuen Thread, startet allerdings noch nicht die eigentliche Threadfunktion. Stattdessen legt vorgeschalteter Code den neuen Thread erst einmal schlafen. Er wartet auf den Aufruf von »wake_up_process()«.
Erfolgt der, überprüft der Daemon, ob er den Thread nicht direkt wieder beenden soll, indem er »should_stop« auf 1 hin prüft – und zwar noch bevor er die Threadfunktion tatsächlich aufruft. Steht das Ende unmittelbar bevor, folgt »do_exit()«, ansonsten führt der Kthreadd den produktiven Code aus, nämlich die vom Kernelcode beziehungsweise Treiber registrierte Threadfunktion.
Konsistenz erhalten
Besonders diffizil ist das Sichern der diversen kritischen Abschnitte. So müssen die Programmierer verhindern, dass die Liste, in der Linux die Aufträge einträgt, inkonsistent wird. Dazu verwenden sie ein Spinlock. Zudem unterbindet das Betriebssystem, dass anderer Code »wake_up_process()« aufruft, bevor sein Erzeuger den neuen Thread überhaupt gestartet hat. Hierzu setzen die Kernelentwickler auf ein Completion-Objekt, das Element »done« in der zur Verwaltung des Thread verwendeten Datenstruktur. Ein weiteres Objekt kommt zum Einsatz, um das Ende des neuen Thread abzuwarten, wenn sein Erzeuger den Thread vor dem eigentlichen Aktivieren gleich wieder beenden will.
Listing 1 zeigt Code, der einen Thread mittels Kthreadd startet. Dessen Funktion kodieren die Zeilen 8 bis 26. Das passende Completion-Objekt und der Aufruf der Funktion »complete_and_exit()« am Ende (Zeilen 6 und 25) sind nötig, wenn der Kernelthread aus einem Modul heraus starten soll. Das Completion-Objekt verhindert, dass Linux den Modulcode entlädt, bevor es den Kernelthread vollständig beendet hat. Es schießt den Thread durch Aufruf der Funktion »kill_pid()« ab und schickt so dem im ersten Parameter angegebenen Thread ein Signal. Um bei gegebenem Prozess-Kontrollblock an die zugehörige PID zu gelangen, verwenden Entwickler am einfachsten das Makro »task_pid()« wie in Zeile 41.
Zukunftsaussichten
Experimentierfreudige übersetzen den Code mit dem Makefile in Listing 2. Mit »insmod« laden sie das kompilierte Kernelobjekt und lesen im Syslog mit
sudo tail -f /var/log/messages
die per »printk()« erzeugten Ausgaben des gestarteten Kernelthread. Abbildung 5 dokumentiert das Übersetzen und einen erfolgreichen Testlauf.
|
Listing 2: Makefile |
|---|
01 ifneq ($(KERNELRELEASE),) 02 obj-m := kthread.o 03 else 04 KDIR := /lib/modules/$(shell uname -r)/build 05 PWD := $(shell pwd) 06 07 default: 08 $(MAKE) -C $(KDIR) M=$(PWD) modules 09 endif 10 11 clean: 12 rm *.o *.ko |
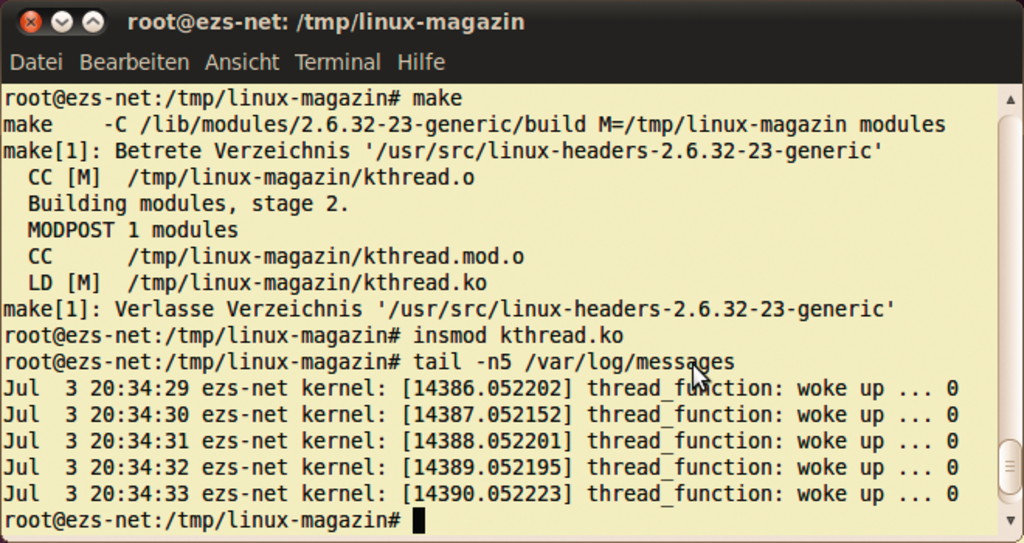
Abbildung 5: Wer mit Threads experimentieren möchte, übersetzt das Modul mit »make« und lädt es mit »insmod« in den Kernel. Die Ausgaben erscheinen im Syslog.
Kernelthreads spielen in modernen, echtzeitfähigen Kerneln eine besondere Rolle [1]. So ist es folgerichtig, dass Linus Torvalds und sein Team mit dem Kthreadd eine einfach handhabbare Umgebung schaffen, um ohne Risiko Codesequenzen zu erzeugen. Sie halten sich damit an den amerikanischen Geschäftsmann Rockefeller, der meinte: “Ich arbeite nach dem Prinzip, dass man niemals etwas selbst tun soll, was jemand anderes für einen erledigen kann.” (mg)
|
Infos |
|---|
|
[1] Eva-Katharina Kunst, Jürgen Quade, “Kern-Technik”, Folge 34: Linux-Magazin 07/07 |
|
Die Autoren |
|---|
|
Eva-Katharina Kunst, Journalistin, und Jürgen Quade, Professor an der Hochschule Niederrhein, sind seit den Anfängen von Linux Fans von Open Source. Zur Zeit arbeiten Sie an der dritten Auflage ihres Buches “Linux-Treiber entwickeln”. |





