
Vorgefertigte Codestücke helfen dabei, die Komplexität von Treibercode zu beherrschen. Makros und Muster unterstützen Treiberentwickler bei kritischen Abschnitten und dem Powermanagement.
Open-Source-Programmierer wissen es längst: Vorhandene Software nutzen, um damit neue Software zu gestalten, lohnt sich. Das als Software-Reuse bezeichnete Vorgehen vermeidet Doppelarbeit, Fehler und Unvollständigkeiten. Die Effizienz-Programmierer setzen dabei auf Bibliotheken, Frameworks und Templates. Hinzu kommen die Entwurfsmuster, die eine grundsätzliche, Programmiersprachen- und Umgebungs-unabhängige Beschreibung eines Problems geben.
Das Linux-Magazin und insbesondere die Kern-Technik-Serie versucht Programmierern das Leben zu erleichtern und stellt allgemein gehaltene und vielfältig nutzbare Codeschnipsel vor, die sich in eigene Entwicklungen einbauen lassen. So hat die vorige Folge beispielsweise ein Template behandelt, das den Kernel um eigenen Code erweitert [1].
Diese Kern-Technik ergänzt die Sammlung um weitere Funktionstemplates und Entwurfsmuster. Denn für einen neuen Treiber sind immer wieder bestimmte Funktionen zu implementieren, die einen ähnlichen Aufbau haben (siehe Abbildung 1). Bei den zu implementierenden Routinen handelt es sich um die wesentlichen Zugriffsfunktionen »driver_open()«, »driver_close()«, »driver_read()«, »driver_write()« und »driver_poll()«. Dazu gehören aber auch die Funktionen »template_suspend()« und »template_resume()« für das Powermanagement.
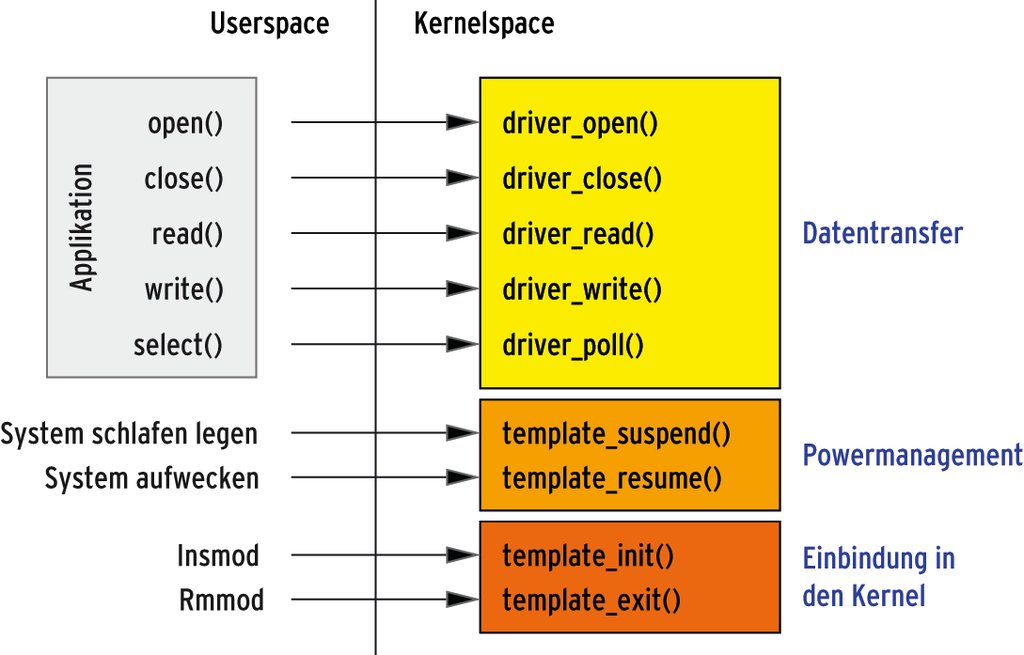
Abbildung 1: Die Grundfunktionen zum Einbinden eines Moduls in den Kern, zum Datenzugriff und zum Powermanagement muss jeder Treiber implementieren.
Wenn ein Treiberentwickler die Funktionen schreibt, sollte er sowohl blockierende als auch nicht-blockierende Zugriffe ins Auge fassen. Das führt letztlich zur hohen Komplexität der ansonsten recht einfach strukturierten Lese- und Schreibfunktionen (siehe Abbildung 2).
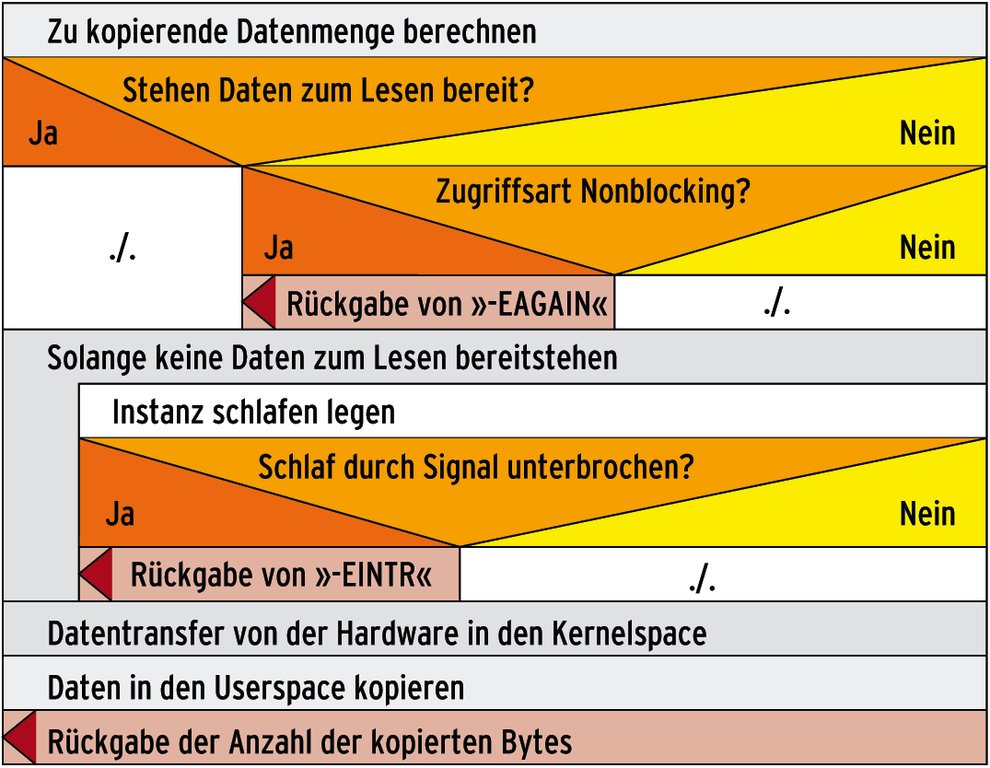
Abbildung 2: Falls Treiber mehrere Zugriffsarten unterstützen, ist die Implemention nicht mehr trivial, da es diverse Fälle zu berücksichtigen gilt.
Geben und nehmen
Die Lese- oder Schreibfunktion eines Treibers aktiviert der Kernel dann, wenn eine Applikation die Systemcalls »read()« oder »write()« für die zugehörige Gerätedatei aufruft. Falls ständig Daten zum Lesen bereitliegen oder der Kernel sie direkt schreiben darf, sind die zu implementierenden Aktionen gradlinig: Beim »read()« transferiert der Treiber die Daten von der Hardware in den Kernelspace und von dort schließlich in den Speicherbereich der Applikation. Der Syscall »write()« macht es umgekehrt: Er transferiert die Daten aus dem Speicher der Applikation in den Kernel und von hier in die Hardware (siehe Abbildung 3).
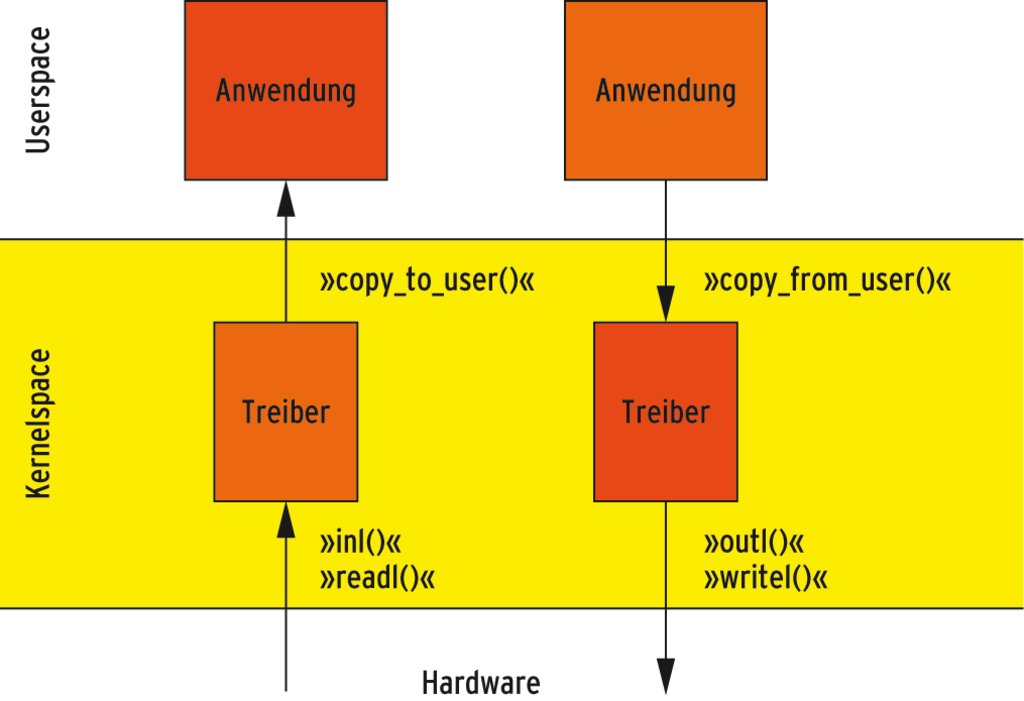
Abbildung 3: Das Grundprinzip jedes Treibers ist ein Datentransport in zwei Zügen: Erst koordiniert er den Datentransfer von der Hardware in den Kernelspace, danach kopiert er sie aus dem Kernel in den Userspace.
Ist der Hardwarezugriff jedoch nicht sofort möglich, weil beispielsweise die Hardware noch mit anderen Aufgaben beschäftigt ist, wird es komplizierter. Dann muss der Treiber nämlich die in den Aufrufparametern übergebene Zugriffsart auswerten.
Warten auf die Hardware
Als Default implementiert ein Treiber einen blockierenden Zugriff. Dabei legt er die Applikation und damit die im gleichen Kontext laufende Treiberfunktion so lange (und immer wieder) in den Zustand Schlafen, bis er endlich Daten transferieren kann. Beim nicht-blockierenden Zugriff legt die Treiberfunktion die aufrufende Applikation nicht schlafen, sondern signalisiert ihr mit dem Rückgabewert »-EAGAIN«, dass sie zurzeit nicht lesen oder schreiben darf und sie es später erneut probieren soll.
Der Code, der prüft, ob sich Daten unmittelbar lesen oder geschreiben lassen, stellt einen kritischen Abschnitt dar, den es beispielsweise über Spinlocks zu schützen gilt. Das ist alles andere als trivial und in der Vergangenheit sehr häufig falsch implementiert worden. Daher hat Linus Torvalds das für eine korrekte Implementierung zugrunde liegende Entwurfsmuster in Form eines Makros realisiert.
Das Makro implementiert die in Abbildung 2 sichtbare Schleife. Für den Entwickler heißt das, im Wesentlichen nur noch eine Wait-Queue und den C-Code für eine Bedingung zu implementieren. Anhand der Bedingung muss erkenntlich sein, ob – im Fall des Lesezugriffs – Daten für die Applikation bereitliegen oder nicht. Beim »write()« gibt die Bedingung darüber Auskunft, ob der Treiber Daten schreiben kann. Die Wait-Queue ist ein Objekt, das für das eigentliche Schlafenlegen und Aufwecken notwendig ist. Linux initialisiert es beispielsweise beim Laden des Moduls in der Funktion »template_init()« [2].
Seltsame Rückgabewerte
Beim eigentlichen Datentransfer zwischen Kernel- und Userspace gibt es drei Aspekte zu beachten. Erstens: Die Anzahl der real zu transferierenden Bytes muss der Treiber auf Basis des Minimums von angeforderten und zur Verfügung stehenden Daten berechnen. Zweitens: Das Transferieren der Daten kann teilweise oder komplett fehlschlagen; die Funktionen »copy_to_user()« und »copy_from_user()« geben die Anzahl der nicht übertragenen Bytes zurück. Und drittens: Die Funktionen »driver_read()« beziehungsweise »driver_write()« sollten die Anzahl der wirklich übermittelten Bytes zurückgeben.
Das Kopieren kann im Übrigen dann fehlschlagen, wenn die Applikation den Kernel mit falschen Adressen versorgt, beispielsweise mit einem Nullpointer. Die Funktionen »copy_to_user()« und »copy_from_user()« prüfen die Adressen vor dem eigentlichen Transfer und kopieren nur so viele Daten, wie aus ihrer Sicht in Ordnung ist.
Schablonen führen dem Entwickler die Hand
Listing 1 zeigt das Codegerüst für das Entwurfsmuster einer Funktion »driver_read()«. Damit es zum Teil eines funktionierenden Treibers wird, ergänzt der Programmierer noch den Datentransfer zwischen Hardware und Kernel – falls es überhaupt eine Hardware gibt. Beispielsweise eine Interrupt-Service-Routine initiiert so einen Datentransfer. Kopiert sie die Daten dabei in einen globalen Kernelspeicherbereich, ist dieser durch ein Spinlock zu schützen. Im einfachsten Fall aber liest der Code innerhalb der Funktion »driver_read()« ein Hardwareregister aus.
| Listing 1: Codegerüst für Lesefunktion im Treiber |
|---|
01 static atomic_t bytes_available = ATOMIC_INIT(0);
02
03 #define READ_POSSIBLE (atomic_read(&bytes_available) != 0)
04
05 ssize_t driver_read(struct file *instance, char __user *buffer,
06 size_t max_bytes_to_read, loff_t *offset)
07 {
08 size_t to_copy, not_copied;
09 char kernelmem[128]; // lokale Variable: Schutz über Spinlocks kann entfallen
10
11 if (!READ_POSSIBLE && (instance->f_flags & O_NONBLOCK)) {
12 // keine Daten vorhanden und Nonblocking-Mode
13 return -EAGAIN;
14 }
15 if (wait_event_interruptible( wq_read, READ_POSSIBLE)) {
16 // während des Schlafens durch ein Signal unterbrochen
17 return -ERESTARTSYS;
18 }
19 to_copy = min((size_t)atomic_read(&bytes_available), max_bytes_to_read);
20 not_copied = copy_to_user(buffer, kernelmem, to_copy);
21 atomic_sub(to_copy - not_copied, &bytes_available);
22 return to_copy - not_copied;
23 }
|
In beiden Fällen – der Treiber kopiert die Daten außerhalb von »driver_read()« in den globalen Kernelspace oder holt sie innerhalb der Funktion direkt von der Hardware ab – passt der Entwickler die globale Variable »bytes_available« an. Sie reflektiert im vorliegenden Template die Anzahl der Bytes, die eine Applikation zurzeit lesen darf. Stehen neue Bytes zur Verfügung, erhöht der Code die Variable entsprechend. Hat er Daten gelesen, erniedrigt er sie um die zugehörige Anzahl Bytes. Da die Variable global ist, könnten mehrere Instanzen sie gleichzeitig modifizieren. Also schützt sie der umsichtige Programmierer durch die Wahl des Datentyps »atomic_t« und die darauf definierten Zugriffsfunktionen [3].
Listing 2 zeigt das Codegerüst für das Entwurfsmuster der Funktion »driver_write()«. Ähnlich wie bei »driver_read()« ist auch hier der Datentransfer zwischen der Hardware und dem Kernelspace zu ergänzen. Die globale Variable »bytes_that_can_be_written« ist vor parallelen Zugriffen zu schützen. Dazu bietet sich wieder der atomare Datentyp an.
| Listing 2: Codegerüst für Schreibfunktion |
|---|
01 static atomic_t bytes_that_can_be_written = ATOMIC_INIT(0);
02
03 #define WRITE_POSSIBLE (atomic_read(&bytes_that_can_be_written) != 0)
04
05 ssize_t driver_write(struct file *instance, const char __user *buffer,
06 size_t max_bytes_to_write, loff_t *offset)
07 {
08 size_t to_copy, not_copied;
09 char kernelmem[128]; // Größe anpassen
10
11 if (!WRITE_POSSIBLE && (instance->f_flags & O_NONBLOCK)) {
12 // Hardware oder Treiber sind nicht bereit die Daten zu
13 // schreiben und der Zugriff erfolgt im NON_BLOCKING-Mode
14 return -EAGAIN;
15 }
16 if (wait_event_interruptible(wq_write, WRITE_POSSIBLE)) {
17 // Während des Schlafens durch ein Signal unterbrochen
18 return -ERESTARTSYS;
19 }
20
21 // Rückgabewerte berechnen
22 to_copy = min((size_t)atomic_read(&bytes_that_can_be_written),
23 max_bytes_to_write);
24 not_copied = copy_from_user(kernelmem, buffer, to_copy);
25
26 // Kernel darf jetzt Daten in die Hardware schreiben
27 atomic_sub(to_copy - not_copied, &bytes_that_can_be_written);
28
29 return to_copy - not_copied;
30 }
|
Zum Abholen bereit
Jeder Treiber sollte zusätzlich zu den Transferfunktionen auch »poll()« und das funktional weitgehend gleichwertige »select()« anbieten, damit Anwendungen herausfinden können, ob der Treiber für einen Datenaustausch bereit ist.Dazu implementiert der Programmierer eine Funktion »driver_poll()«, mit der er überprüft, ob er Daten lesen oder schreiben darf. Das Ergebnis hiervon hält er in Form einer Bitmaske fest (siehe Listing 3). Typischerweise lässt sich diese Funktion ohne Änderungen in einen neuen Treiber übernehmen.
| Listing 3: Test, ob Daten warten |
|---|
01 unsigned int driver_poll(struct file *instance,
02 struct poll_table_struct *event_list)
03 {
04 unsigned int mask = 0;
05
06 poll_wait(instance, &wq_read, event_list);
07 poll_wait(instance, &wq_write, event_list);
08 // Flags zeigen Status an
09 if (READ_POSSIBLE)
10 mask |= POLLIN | POLLRDNORM;
11 if (WRITE_POSSIBLE)
12 mask |= POLLOUT | POLLWRNORM;
13 return mask;
14 }
|
Für »driver_open()« sowie »driver_close()« hält der Kernel Default-Routinen bereit, die der Programmierer einsetzt, falls er keine Hardware-Initialisierungen vorzunehmen braucht oder keine zusätzlichen, erweiterten Zugriffsrechte prüfen will. Implementiert ein Treiber diese beiden Funktionen nicht selbst, dann greift der Kernel automatisch auf die Defaults zurück.
Neben der Initialisierung von eventuell vorhandener Hardware testen Kernelhacker des Öfteren in der »open()«-Funktion zusätzliche Zugriffsberechtigungen. Eine Anwendung macht das Betriebssystem durch Aufruf von »open()« darauf aufmerksam, dass sie und wie sie auf Daten zugreifen möchte: Zur Auswahl stehen blockierende und nicht blockierende sowie lesende und schreibende Zugriffe.
Bitte einzeln eintreten!
Das Betriebssystem prüft zunächst, ob die zugreifende Instanz entsprechend dem geäußerten Zugriffswunsch dazu die Berechtigung hat. Ist das der Fall, ruft es im zugehörigen Treiber die Funktion »driver_open()« auf. Innerhalb von »driver_open()« hat der Entwickler die Option, die Anzahl der parallel zugreifenden Instanzen zu kontrollieren und etwa zu verhindern, dass Anwender den Treiber zweimal gleichzeitig öffnen, wenn das nicht sinnvoll ist.
Um dieses Verhalten zu realisieren, verwaltet der Treiber eine globale Variable, die die Anzahl der zugreifenden Instanzen zählt. Beim Aufruf von »driver_open()« zählt er die Variable hoch. Hat sie einen Wert von 1, darf die Instanz zugreifen. In jedem anderen Fall verweigert der Treiber den Zugriff. Der Aufruf von »driver_close()« dekrementiert die Variable wieder.
Diese Sequenz ist zunächst unspektakulär ist, aber es gilt, einen kritischen Abschnitt zu schützen. Schließlich können beliebig viele Instanzen gleichzeitig die Funktion »driver_open()« triggern. Zum Schutz eignen sich atomare Variablen wie in »driver_read()«. Aufgrund der Eigenart atomarer Variablen und der zugehörigen Zugriffsfunktionen ist eine Überwachung auf den Wert 0 einfacher: Daher initialisiert der Code die Variable mit -1. Listing 4 implementiert so eine Kontrolle der Anzahl zugreifender Instanzen.
| Listing 4: Nur eine Applikationsinstanz erhält Zugriff |
|---|
01 // Lock sperrt nach Increment bei Null:
02 static atomic_t access_count = ATOMIC_INIT(-1);
03
04 static int driver_open(struct inode *devicefile,
05 struct file *instance)
06 {
07 if (atomic_inc_and_test(&access_count) != 0)
08 // true, falls == 0
09 return 0; // Zugriff erlaubt
10 atomic_dec(&access_count);
11 return -EBUSY;
12 }
13
14 static int
15 driver_release(struct inode *devicefile,
16 struct file *instance)
17 {
18 atomic_dec(&access_count);
19 return 0;
20 }
|
Grundsätzlich sollte ein moderner Gerätetreiber Powermanagement unterstützen und eventuell vorhandene Hardware in den Schlafzustand versetzen beziehungsweise wieder aus diesem Zustand wecken können. Hierfür sind zwei Funktionen zu schreiben: Die Funktion »template_suspend()« ruft der Kern auf, wenn er sich komplett schlafen legt. Sie bekommt im Aufrufparameter vom Typ »pm_message_t« mitgeteilt, ob es sich um Suspend oder um Hibernate handelt. Innerhalb der Funktion kodiert der Entwickler die notwendigen Kommandos, um den Stromverbrauch der durch den Treiber bedienten Hardware auf ein Minimum zu senken.
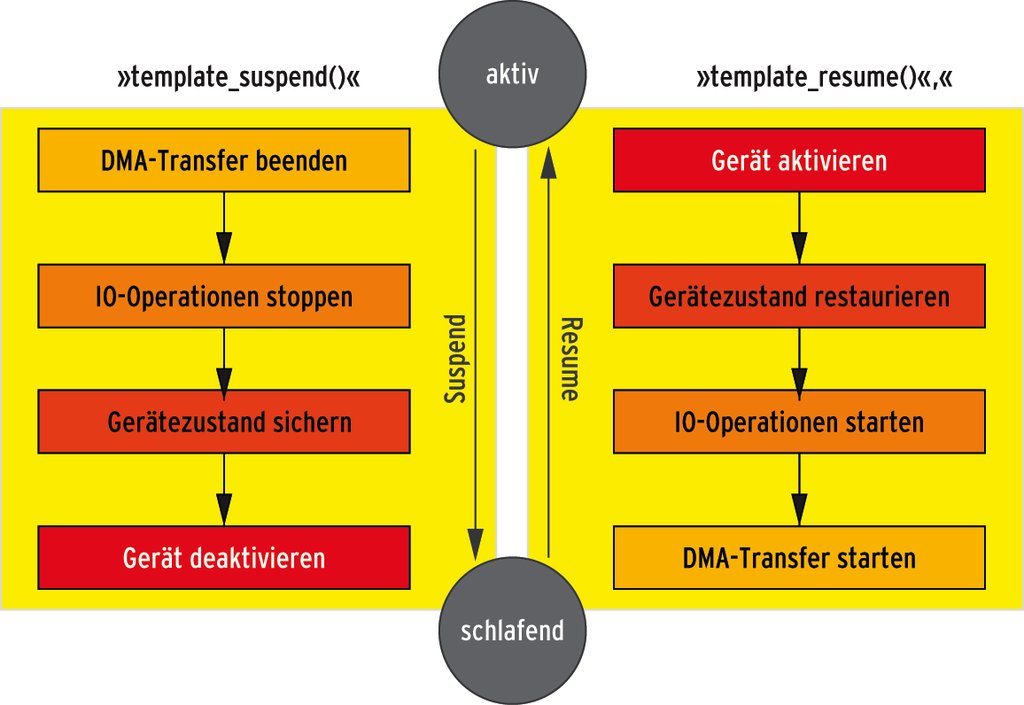
Abbildung 4: Zum Schlafenlegen einer Hardwarekomponente führt der Treiber mehrere Operationen durch. Wacht das Gerät wieder auf, durchläuft sie der Kernel in umgekehrter Reihenfolge.
Einschlafen und aufwachen
Linux ruft beim Wecken die Funktion »template_resume()« auf und reaktiviert schlafende Komponenten. Da das Powermanagement programmtechnisch über das Gerätemodell realisiert ist, binden Linux-Entwickler die beiden Callback-Funktionen in der Initialisierungsfunktion »template_init()« entweder an das Klassen- oder ans Geräteobjekt. Welches der beiden Objekte sie wählen, entscheidet im Wesentlichen über den Zeitpunkt, an dem Linux die Callbacks aufruft: Rückrufe vom Klassenobjekt kommen früher an die Reihe [2]. Listing 5 demonstriert diese Variante.
| Listing 5: Zwei Funktionen für das Powermanagement |
|---|
01 #ifdef CONFIG_PM // Powermanagement
02
03 static int template_suspend(struct device *dev, pm_message_t state)
04 {
05 switch (state.event) {
06 case PM_EVENT_ON:
07 printk("on ...n"); break;
08 case PM_EVENT_FREEZE:
09 printk("freeze ...n"); break;
10 case PM_EVENT_SUSPEND:
11 // Stromsparmodus einschalten
12 printk("suspend ...n"); break;
13 case PM_EVENT_HIBERNATE:
14 // Tiefschlaf einschalten
15 printk("hibernate ...n"); break;
16 default:
17 printk("pm_event: 0x%xn", state.event);
18 break;
19 }
20 printk("template_suspend(%p)n", dev);
21 return 0;
22 }
23
24 static int t emplate_resume(struct device *dev)
25 {
26 // Sparmodus ausschalten, Gerät reaktivieren
27 printk("template_resume(%p)n", dev);
28 return 0;
29 }
30 #endif
31
32 [...]
33
34 static int __init template_init(void)
35 {
36 init_waitqueue_head(&wq_read);
37 init_waitqueue_head(&wq_write);
38 [...]
39 template_class = class_create(THIS_MODULE, TEMPLATE);
40 if (IS_ERR(template_class)) {
41 printk("template: no udev supportn");
42 goto free_cdev;
43 }
44 #ifdef CONFIG_PM
45 template_class->suspend = template_suspend;
46 template_class->resume = template_resume;
47 #endif
48 [...]
|
Da sich der Linux-Quellcode an verschiedene Anforderungen anpassen lässt, benötigt er nicht immer alle Subsysteme. Umsichtige Entwickler rahmen deshalb ihren Powermanagement-Code in ein »#ifdef CONFIG_PM« ein. Solch ein Kernel kommt dann wahlweise auch ohne Powermanagement aus.
Umfangreiches Rahmenwerk
Der Kernel im Allgemeinen und Treiber im Besonderen sind selbst in rudimentären Funktionen ziemlich komplex: Die Codegerüste der vorigen beiden Kern-Techniken umfassen immerhin gut drei Seiten Quellcode. Der Umfang spiegelt auch wider, dass Linux dem Kernelhacker viel Know-how und gute Planung abverlangt, soll produktiver Code entstehen. Aber dank Software-Reuse und mit Hilfe der vorgestellten Codefragmente ist der Einstieg “quick and clean” möglich. Das Treibergerüst gibt\’s wie immer zum Download [4]. (mg)
| Infos |
|---|
| [1] Kunst, Quade: “Kern-Technik: Treibergerüste”, Folge 48, Linux-Magazin 11/09, S. 98
[2] Kunst, Quade: “Kern-Technik: Powermanagement”, Folge 42, Linux-Magazin 11/08, S. 102 [3] Quade, Kunst: “Linux-Treiber entwickeln”: Dpunkt-Verlag, 2. Auflage, Juni 2006 [4] Listing und Makefiles zur Kerntechnik: [https://www.linux-magazin.de/Service/Listings/2010/01/Kern-Technik] |
| Die Autoren |
|---|
| Eva-Katharina Kunst, Journalistin, und Jürgen Quade, Professor an der Hochschule Niederrhein, sind seit den Anfängen von Linux Fans von Open Source. Unter dem Titel “Linux Treiber entwickeln” haben sie zusammen ein Buch zum Kernel 2.6 veröffentlicht. |





