
Ein kleiner, aber wichtiger Teil des Linux-Kernels ist in Assembler geschrieben. Der Inline-Assembler integriert die Maschinenbefehle dabei harmonisch in C-Funktionen. Bleibt, den Code zu verstehen .
Kein Zweifel, die Programmiersprache C dominiert die IT-Landschaft und erst recht den Linux-Kernel. Effizienter Code, Hardwarenähe und Freiheit für den Programmierer zählen unter C-Fans zu den Gründen für den Einsatz.
Doch der Hardwarenähe und Effizienz zum Trotz geht es prinzipbedingt auch im Jahre 2008 noch immer nicht ohne den guten alten Assembler: Die Programmiersprache C kennt – klugerweise – weder direkten Zugriff auf die Ein- und Ausgabegeräte der Hardware noch in der Sprache verankerte Elemente zur Synchronisation des Prozessors. Darüber hinaus ist ein vom Profi handoptimierter Assembler-Code – sparsam und strategisch eingesetzt – in seiner Performance durch automatisch generierten Code eines Compilers selten zu schlagen.
Die Frage ist also weniger, ob Entwickler Assembler-Code benötigen, sondern vielmehr, wie sie ihn effizient mit C-Code kombinieren, um die jeweiligen Vorteile zu nutzen. Eigenständige Assembler-Funktionen zu schreiben und sie mittels Linker mit dem C-Code zu kombinieren ist wenig spektakulär. Die Entwickler wünschen sich stattdessen Teile einer C-Funktion in Assembler auszuführen, den Assembler-Code also in den C-Code einzubetten. Genau diese Funktion bietet der GNU-Compiler GCC mit seinem von den Linux-Entwicklern reichlich genutzten Inline-Assembler.
Wie der Code-Ausschnitt aus dem Linux-Kernel in Listing 1 zeigt, hat dieser Inline-Assembler allerdings etwas von einer Geheimsprache, die nur eingeweihte Entwickler kennen. Zeit, um etwas Licht ins Dunkel zu bringen und zu erläutern, wie man Assembler im Kernel liest und schreibt.
|
Listing 1: Inline-Assembler aus |
|---|
01 static int check_stack_overflow(void) {
02 long sp;
03
04 __asm__ __volatile__("andl %%esp, %0"
05 : "=r" (sp)
06 : "0" (THREAD_SIZE - 1));
07
08 return sp <
09 (sizeof(struct thread_info) + STACK_WARN);
10 }
|
Abstimmung erforderlich
Um Assembler-Code einzubetten, stellt der GCC das Makro »asm« bereit. Denkbare Konflikte mit einem Bezeichner dieses Namens vermeiden Kernelentwickler, indem sie stattdessen auf die gleichwertige Variante »__asm__« zurückgreifen. Das Makro nimmt nicht nur die einzelnen Assembler-Zeilen entgegen, sondern regelt zugleich dessen Interaktion mit dem C-Code. Denn will der Low-Level-Programmierer auf die dort definierten Variablen zugreifen, muss er sich mit dem Compiler abstimmen, wie sie untereinander Daten austauschen.
Das geht entweder über die Register der CPU oder über Speicherzellen. Dies gilt für beide Richtungen, vom C-Programm zum Assembler-Code und umgekehrt. Das Asm-Makro koordiniert den Austausch und hat vier Felder, die jeweils ein Doppelpunkt (»:«) voneinander trennt (siehe Abbildung 1).

Abbildung 1: Das Asm-Makro baut eine Brücke zwischen Quelltext in C und eingebettetem Assembler-Code. Es hat vier Felder, Doppelpunkte trennen sie ab. Neben dem eigentlichen Code (gelbes Feld) gibt der Programmierer für ihn Ein- (hellorgange) und Ausgabevariablen (dunkelorange). Ändert der Code weitere Register, benennt der Entwickler diese im vierten, optionalen Feld (rot) als „clobbered Register“.
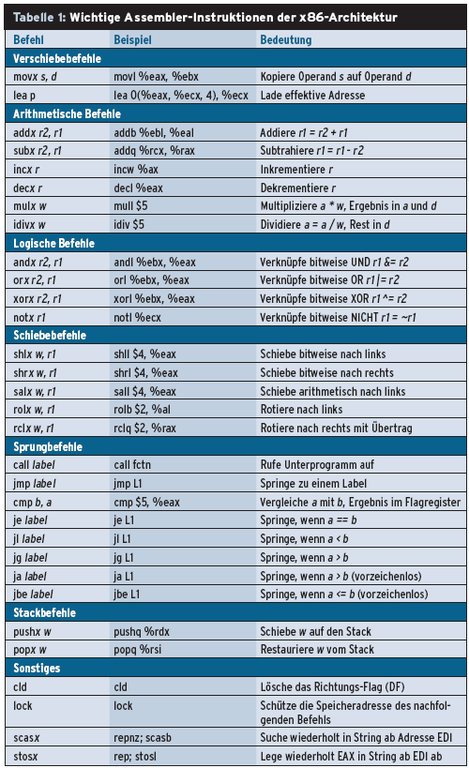
Im ersten Feld findet sich der eigentliche Assembler-Code (siehe Kasten “Registermodell und Befehlssatz einer x86-CPU” und Tabelle 1). Ihm folgen – im zweiten und dritten Feld – erst eine Zuordnungsliste von Ausgaberegistern zu C-Variablen und dann eine Abbildung von C-Variablen zu Eingaberegistern, jeweils aus Sicht des übergebenen Assembler-Code. Im letzten Feld schließlich findet sich optional eine Liste von Registern, die der Assembler-Code modifiziert.
|
Registermodell und Befehlssatz |
|---|
|
Bei der häufig eingesetzten x86-Architektur ist am Registermodell der Ballast einer ursprünglich auf 16 Bit ausgelegten Architektur sichtbar. Den 8086 stellte Intel immerhin bereits 1978 vor. Dessen Code läuft im Prinzip heute noch auf den modernsten Multicore-CPUs. Die Abbildung 3 illustriert, dass aus den ehemals sechs 16-Bit-Registern zwischenzeitlich 32 64-Bit-Register wurden. Jede Erweiterung der Registerbreite bringt ihr eigenes Präfix vor dem Registernamen mit, nutzt aber praktisch das gleiche Register. So lässt sich ablesen, ob ein Operand mit 8 Bit (AL), mit 16 Bit (AX), mit 32 Bit (EAX) oder schließlich mit 64 Bit (RAX) gemeint ist. Die meisten Assembler-Befehle im GCC verwenden die so genannte AT&T-Syntax und haben den Aufbau »Befehl mit Ergänzung Quelle, Ziel;«. Ein Beispiel, das einen 32-Bit-Wert (long, »l«) von Register EAX nach EBX kopiert, lautet: movl %eax, %ebx; Die Befehlsergänzung – möglich sind hier die Buchstaben »b«, »s«, »l« und »q« – legt die Größe der Operanden fest. Die Buchstaben am Ende der Opcodes geben an, dass die Argumente jeweils eine Breite von 8, 16, 32 oder 64 Bit haben, und korrespondieren mit den jeweiligen Registernamen gleicher Länge. Tabelle 1 listet die wichtigsten Befehle auf, sortiert nach Befehlsgruppen. Eine Einführung in den x86-Prozessor, sein Registermodell, die Adressierungsarten und seine Programmierung findet sich unter [5] und [6]. CPU-Hersteller Intel selbst beschreibt in [7] ausführlich die einzelnen Befehle. |
Den eigentlichen Programmtext definiert der Entwickler in einem einzelnen String. Jede einzelne Codezeile schließt dabei entweder ein Semikolon oder noch besser »nt« ab. Das ist darum vorteilhaft, weil der resultierende Assembler-Code so übersichtlicher wird.
Die nächsten zwei Felder der Anweisung sind komplizierter. Sie legen die Beziehung zwischen den C-Variablen und den CPU-Registern oder Speicherzellen fest. Dazu fasst der Programmierer die verwendeten C-Variablen in normale Klammern ein und trennt sie durch Kommas. Zusätzlich spezifiziert er für jede Variable, wie der C-Compiler sie handhaben soll: Entweder überlässt er es dem Compiler, ein aus dessen Sicht geeignetes Prozessorregister für den Variableninhalt auszuwählen, oder er gibt selbst eines vor.
|
Tabelle 1: Wichtige |
|---|
|
|
Geben und nehmen
Diese Entscheidung legt er über die so genannten Constraints fest (siehe Tabelle 2). So überlassen die Constraints »r« für normale 32-Bit-Register und »q« für die Register der 64-Bit-Erweiterung dem Compiler die freie Registerwahl für Variablen (die generische Variante ohne x86-Bezug für »q« ist »g«). Ein Constraint »a« bis »d« zwingt dagegen den Compiler im Fall einer 32-Bit-Variablen dazu, eine Variable über die Register EAX bis EDX zugänglich zu machen (siehe Listing 2). Benötigt die zugehörige Variable weniger Platz, verwendet der Inline-Assembler automatisch die passenden Register, etwa AX oder AL und so weiter.
|
Listing 2: |
|---|
01 #include <stdio.h>
02
03 int main(int argc, char **argv) {
04 char *from = "Hello Worldn";
05 int count;
06
07 asm(
08 "movl $-1, %%ecx nt"// Charzähler
09 "movb $0, %%al nt" // Suchzeichen '
|
|
Tabelle 2: x86-Constraints |
|---|
|
|

Es gibt noch viele weitere Constraints. Sie erlauben es dem Entwickler, dediziert auf alle Register inklusive der 64-Bit-Erweiterungen zuzugreifen. Eine ausführliche Liste der Constraints für verschiedene Prozessorfamilien steht in der Dokumentation zum GNU-C-Compiler [1].
Falls ein Programmierer eine Zuordnung zwischen C-Variable und CPU-Register über ein Constraint wie »a« fixiert hat, verwendet er im Assembler-Code auch die bekannten Registernamen (»eax«). Will er dem Compiler die Möglichkeit zur Optimierung einräumen, überlässt er diesem die Wahl des Registers. Dann verwendet er im Code statt der ausgeschriebenen Registernamen eine numerische Referenz aus den Zuordnungslisten. Dabei zählt der Assembler die Variablen in den Listen bei Null beginnend durch und referenziert sie dann im Code über die Substitutionszeichen »%n«. Den Platzhalter »n« ersetzt der Entwickler mit dem entsprechenden Zählwert.
Diffiziler Austausch
Gibt es beispielsweise drei Ausgabevariablen im C-Code, in die der Assembler-Code Daten schreibt, listet der Programmierer sie in der ersten Zuordnungsliste auf. Er greift auf die erste Variable über »%0«, auf die zweite über »%1« und auf die dritte schließlich über »%2« zu.
Die Positionsnummer darf er übrigens auch im Constraint selbst verwenden. Das dient beispielsweise zur Vorinitialisierung eines Registers, wie Zeile 6 in Listing 1 zeigt. Der Compiler legt den Wert von »(THREADSIZE – 1)« in der Variablen mit der Nummer »0« ab. Das ist in Zeile 5 die Variable »sp«.
Abbildung 2 enthält ein weiteres Codebeispiel, das demonstriert, wie der Assembler auf Variablen aus einem C-Programm zugegreift. Dort sind die drei Variablen »i«, »j« und »k« definiert. Gemäß der Reihenfolge ihres Auftretens in den beiden Zuordnungslisten für Ein- und Ausgaberegister referenziert sie der Inline-Assembler: Die Variable »j« taucht dort als Erste auf. Sie erhält damit innerhalb des Assembler-Code den Namen »%0«. Es folgen »k« als zweites Argument mit dem Namen »%1« und schließlich schreibt der Assembler-Programmierer »%2«, wenn er »i« ansprechen möchte. Um die Operanden (im Beispiel »%0«, »%1« und »%2«) von den Registern besser zu unterscheiden, bekommen die Register übrigens neben dem ohnehin obligatorischen »%«-Zeichen ein identisches zweites Zeichen zugestellt. Das Register EAX schreibt sich also im Inline-Assembler-Code »%%eax«.

Abbildung 2: Die Zuordnung von Variablen zu Registern bereitet oft Schwierigkeiten: Der C-Code übergibt »i« an den Assembler und heißt dort »%2« (rot). Die in der Zuordnungsliste als erste und zweite genannten Variablen »j« und »k« heißen »%0« (gelb) und »%1« (orange).
Wer die Nummerierung der automatisch zugeordneten Register nicht mag, darf für die Variablen einen symbolischen Namen wählen. Dieser steht dann in eckigen Klammern vor dem zur Variablen gehörenden Constraint. Das sieht folgendermaßen aus:
asm("movl %[variable_i], %%eax;nt"
"movl %%eax, %[variable_j];n"
:[variable_j] "=r"(j) /* output */
:[variable_i] "r"(i) /* input */
:"%eax" /* clobbered register */
);
Jeder Constraint lässt sich um einen Modifier ergänzen, also um die Beschreibung seiner Eigenschaften (siehe Tabelle 3). Das im Beispiel vorangestellte »=« bedeutet etwa, dass sich das Register nur vom Assembler-Code beschreiben lässt. Häufig ist auch der Early-Clobber-Modifier »&« notwendig: So gekennzeichnete Register werden bereits vor dem Zugriff im Assembler-Code verändert. Dafür könnte beispielsweise der Compiler verantwortlich sein, sollte er es mit einem Initialwert belegen. Weitere Ergänzungen für die x86-Architektur enthalten die Tabelle 3 und zusätzlich für andere CPU-Architekturen die GCC-Dokumentation.

Abbildung 3: Gab es beim 8086 nur sechs 16-Bit-Register, stehen dem Programmierer in der neusten x86-Generation 16 Datenspeicher mit je 64 Bit zur Verfügung. Das Register A etwa hat 64 Bit, RAX bezeichnet alle von ihnen. EAX Hat nur 32 Bit. 16 Bit umfasst AX und mit AH und AL erhält der Entwickler die beiden niederwertigsten Bytes.
|
Tabelle 3: |
|---|
|
|

Unvermutete Änderung
Nach den beiden Zuordnungslisten folgt noch das letzte Feld für die Clobbered Register. Es listet die CPU-Register auf, die der Assembler-Code verändern wird. Die muss der Compiler kennen, um zu planen, welche Register er vor dem Starten des Inline-Code sichern muss.
Doch aufpassen! Der Inline-Assembler ist empfindlich und erlaubt nur solche Register anzugeben, die nicht bereits in der Liste für die Ausgabe- oder Eingabevariablen stehen. Ansonsten reklamiert der Assembler einen Fehler. Programmierer müssen hier auch das Condition Code Register mit dem Namen »cc« angeben, wenn es der Assembler-Code verändert, was bei mehr als einzeiligem Code praktisch immer der Fall ist. Eine Liste der enthaltenen Flags zeigt Tabelle 4.
|
Tabelle 4: Wichtige |
|---|
|
|

Gerade für Neulinge ist die Zuordnung zwischen CPU-Register und C-Variable unübersichtlich. Wer aber den Compiler mit der Option »-S« startet, kann den erzeugten Assembler-Code kontrollieren. Den selbst geschriebenen Assembler-Code schließt der Aufruf
GCC -S -o ij.s ij.c
dabei in die Kommentare »#APP« und »#NO_APP« ein (siehe Zeilen 16 bis 20 in Listing 3).
|
Listing 3: Assembler markiert |
|---|
01 .file "ij.c" 02 .text 03 .globl main 04 .type main, @function 05 main: 06 .LFB2: 07 pushq %rbp 08 .LCFI0: 09 movq %rsp, %rbp 10 .LCFI1: 11 movl %edi, -20(%rbp) 12 movq %rsi, -32(%rbp) 13 movl $10, -8(%rbp) 14 movl $0, -4(%rbp) 15 movl -8(%rbp), %edx 16 #APP 17 movl %edx, %eax; 18 movl %eax, %edx; 19 20 #NO_APP 21 movl %edx, -4(%rbp) 22 movl $0, %eax 23 leave 24 ret |
Zugang zum Herzen
Zum Abschluss ein Hinweis zu der in Listing 1 verwendeten Kombination von »asm« und »volatile«: Falls der Compiler per Option optimiert, passiert es schon mal, dass er den Assembler-Code aus einer Schleife hinausschiebt oder gar ganz wegoptimiert. Das Schlüsselwort »volatile« verhindert das.
Mit diesen Informationen sind angehende Kernelentwickler in der Lage, Inline-Assembler im Kernel zu lesen und auch selbst zu schreiben. Sie sollten sich dabei nicht durch den mitunter ruppigen Compiler entmutigen lassen, denn er achtet penibel darauf, dass die Entwickler die Notation genau einhalten. Eine Reihe weiterführender und hilfreicher Hinweise enthalten [2], [3] und [4]. Dem direkten Weg zum Herzen des Prozessors steht damit nichts mehr im Wege. (mg)
|
Infos |
|---|
|
[1] Constraints und Modifier:[http://GCC.GNU.org/onlinedocs/GCC-4.3.2/GCC/Constraints.html#Constraints] [2] Brennen Underwood, “Brennan\’s Guide to Inline Assembly”:[http://www.delorie.com/djgpp/doc/brennan/brennan_att_inline_djgpp.html] [3] S. Sandeep, “GCC-Inline-Assembly-Howto”: [http://www.ibiblio.org/gferg/ldp/GCC-Inline-Assembly-HOWTO.html] [4] Bharata Rao: “Inline assembly for x86 in Linux”: [http://www.ibm.com/developerworks/linux/library/l-ia.html] [5] Fabian Schmied, “AMD64-Assembler-Handbuch”: [http://www.complang.tuwien.ac.at/ubvl/amd64/amd64.ps] [6] Basic of x86-Architecture:[http://www.tenouk.com/Bufferoverflowc/Bufferoverflow1a.html] [7] Intel, “Architecture Software Developer\’s Manual”: [http://developer.intel.com/design/pentium/manuals/24319101.pdf] |
|
Die Autoren |
|---|
|
Eva-Katharina Kunst, Journalistin, und Jürgen Quade, Professor an der Hochschule Niederrhein, sind seit den Anfängen von Linux Fans von Open Source. Unter dem Titel “Linux Treiber entwickeln” haben sie zusammen ein Buch zum Kernel 2.6 veröffentlicht. |





