
© photocase.com
Heutige Prozessoren sammeln eine Menge Informationen darüber, wie sie Maschinenbefehle ausführen. Damit können Entwickler ihre Programme besser auf die vorhandene Hardware abstimmen und so entscheidend beschleunigen. Geht es um Intel-Prozessoren, hilft dabei Vtune.
Moderne CPUs verfügen über eine Vielzahl an Möglichkeiten, ein Programm zu beschleunigen. Das bedeutet aber gleichzeitig, dass die Zahl von Fußangeln, die eine optimale Performance verhindern, wächst. Oft zeigt sich erst zur Laufzeit, wie ein Programm auf die gestellte Last reagiert. Damit kommt der Software-Optimierung ein immer größerer Stellenwert zu. Der Entwickler muss sich jedoch auf die verfügbare Hardware und ihre Möglichkeiten einstellen. Der Intel Vtune Performance Analyzer [1] erleichtert das Auffinden solcher Probleme. Dieser Artikel demonstriert dies anhand eines einfachen Beispiels.
Prozessor-Interna
Bevor ein Programm zu Ausführung gelangt, wird es in mehreren Schritten vom Sourcecode in Maschinensprache übersetzt. Es ist dabei unerheblich, ob das bei der Programmentwicklung durch Compiler oder erst zur Laufzeit durch Interpreter geschieht – die CPU sieht am Ende nur noch den binär kodierten Assembler-Code.
Jede Instruktion besteht aus einem oder mehreren Bytes Code, der für die CPU eine elementare Operation darstellt, zum Beispiel: Lade aus der Adresse 0x1234 das Datum in das Register RAX. Intern verarbeiten moderne CPUs eine solche Anweisung nicht direkt, sondern in kleinere Mikro-Operationen – so genannte µops – aufgeteilt. Diese Vorgangsweise führt aber auch dazu, dass Befehle nicht mehr in einem Takt abgearbeitet werden, sondern mindestens in diesen Stufen:
- Lade einen Befehl.
- Zerlege den Befehl in µops.
- Führe den/die µops aus, berechne notwendige
Adressen. - Optional: Lade die Daten.
- Schreibe das Ergebnis in den Speicher.
Im realen Prozessor-Design geht die Unterteilung noch weiter, sodass sich am Ende oft zehn oder mehr Schritte ergeben – bei machen Systemen sind es über 30. Statt einen Assembler-Befehl nach dem anderen abzuarbeiten, wandert, sobald ein Befehl die erste Stufe passiert hat, der Folgebefehl in die Pipeline.
Unter optimalen Bedingungen könnte rein serieller Code nach diesem Verfahren mit maximaler Performance ablaufen. In der Praxis ist das aber selten möglich: Es treten wegen der Verzweigungen und Schleifen im Quellprogramm immer wieder Sprünge auf. Statt dann einfach zu warten, bis das Ziel eines bedingten Sprungs bekannt ist, versucht die Voraussage-Logik der CPU den wahrscheinlichsten Pfad zu erkennen.
Erkennt das System am Ende der Pipeline, dass die Vorhersage falsch war, muss es alle anderen in der Pipeline gerade aktiven Tätigkeiten abbrechen und die Pipeline neu füllen. Diese so genannte Branch-Misprediction kostet verständlicherweise sehr viel Zeit.
Caches
Ein anderer häufig auftretender Bremsklotz ist der Zugriff der CPU auf den Hauptspeicher. Aktuelle CPUs werden mit Taktfrequenzen von 2 bis 4 GHz betrieben, ein Takt dauert also 0,5 Nanosekunden. Muss die CPU auf den Hauptspeicher zugreifen, entstehen Wartezeiten von 70 bis 100 ns, also bis zu 600 Takte. Während dieser Zeit kann der Prozessor im Allgemeinen keine sinnvolle Arbeit verrichten. Dieser Problematik sollen Caches entgegenwirken, die Zugriffszeiten durch schnelleren Speicher minimieren. Sie sind heute aber wesentlich kleiner als die realen Programme oder Datensätze. Das Programm muss also auch so gestaltet sein, dass die Caches optimal verwendet werden.
Neben diesen beiden Beispielen gibt es noch viele weitere Möglichkeiten für eine Optimierung. Glücklicherweise hilft moderne Hardware dem Programmierer dabei weiter. Die auf Intel Pentium oder Core 2 Duo basierenden Prozessoren können das Auftreten so genannter Events registrieren. In jedem Prozessor gibt es einige Zählregister, deren Wert bei jedem Auftreten des gemessenen Events inkrementiert wird. Überschreitet ein Zähler eine zuvor festgelegte Schranke – in der Intel Terminologie als SAV (Sampling after Value) bezeichnet -, löst die CPU einen Interrupt aus. Geeignete Software, also ein Treiber im Betriebssystem, kann auf den Interrupt reagieren und den Event auswerten.
Mess-Sonden in der CPU
Es fielen bereits mehrfach die Begriffe Event und Counter, ohne auf ihre praktische Bedeutung einzugehen. Beispiele für zwei häufig verwendete Events auf Pentium-Systemen sind Clockticks und Instructions Retired. Erstere messen die Zeit und erhöhen sich mit jedem Signal des Taktgebers (also zum Beispiel jede Nanosekunde). Letzteres steht für die Zahl der abgearbeiteten Instruktionen. Allerdings ohne jene Befehle, die sich zwar in der Pipeline befanden, aber aufgrund falscher Spekulationen nicht zum Tragen kamen.
Das Verhältnis von Clockticks zu Instructions Retired (auch als CPI, Clocks per Instruction bezeichnet), gibt an, wie lange eine Instruktion im Mittel gebraucht hat, um abgearbeitet zu werden. Da moderne CPUs mehr als eine Instruktion parallel verarbeiten, kann dieser Wert kleiner als 1 werden. In der Praxis ist dies aber nur selten erreichbar, etwa bei Video-Kompression/Dekompression mit SSE-Befehlen. Werte zwischen 1 und 1,5 gelten als gut, alles größer als 4 ist verbesserungsbedürftig.
Die Messung der in einem Programm, einer Funktion oder sogar in einzelnen Codezeilen anfallenden Clockticks zeigt dem Entwickler also, wie lange ein Programmteil zur Ausführung benötigt. Der Wert CPI lässt dabei erkennen, ob die Ausführung aus Sicht der CPU-Architektur effizient war.
Ein Hilfsmittel, diese Events zu registrieren und auszuwerten, ist das für Intel-Prozessoren entworfene Programm Vtune. Es lässt sich nicht auf anderen x86-kompatiblen Produkten verwenden, da die notwendigen Hardware-Counter nicht Bestandteil der x86-Architektur-Definition und bei anderen Herstellern wie AMD anders implementiert sind. Jeder Hersteller von x86-kompatibler Hardware ist schließlich gezwungen, seine eigene Mikroarchitektur zu entwickeln. Da die Event-Zähler tief in der Architektur verankert sind, ist eine Kompatibilität zwischen den Herstellern nicht möglich. Trotz der Architektur-Unterschiede zeigt sich aber in der Regel, dass mit Vtune gefundene Performance-Engpässe Hersteller-übergreifend auftreten.
Events zählen
Es wäre sinnlos, bei jedem Auftreten eines Events sofort zu zählen und festzustellen, wo im Code das Ereignis aufgetreten ist. Würde man das zum Beispiel mit dem Instruction-retired-Event tun, stiege die Ausführungszeit eines Programms um ein Vielfaches.
Stattdessen kommt eine statistische Methode zum Einsatz. Der Zähler wird mit dem SAV-Wert (Sample After Value) geladen, der so gewählt wird, dass die CPU nach etwa 1 Millisekunde das Programm durch einen Interrupt unterbricht. Im Interrupt-Handler speichert das Laufzeitsystem von Vtune die Information über den aktuell ausgeführten Befehl (Program Counter Register) und die Nummer des ausführenden Thread und Prozesses. Diese Daten zieht Vtune bei der späteren Auswertung der Messung heran.
Im Falle eines 2-GHz-Systems bedeutet dies, dass alle 2 Millionen Taktzyklen festgestellt wird, an welcher Stelle sich das Programm gerade befindet. Läuft jede Zeile des Programms genau einmal ab, sollte die Verteilung gleichmäßig sein. Sprünge, Schleifen und Verzweigungen erzeugen aber so genannte Hotspots, also Programmteile, die einen merkbaren Anteil der Ausführungszeit in Anspruch nehmen. Außerdem können zusätzliche Latenzzeiten durch Zugriffe auf Speicher, Disk oder Netzwerk ein Programm bremsen.
Es ist zu bedenken und bei der Durchführung der Messung auch zu berücksichtigen, dass Vtune mit den Hotspots eine statistische Methode zur Evaluierung eines Programms verwendet. Folgende Punkte sind dabei wichtig:
- Das Programm muss mit realistischen Daten arbeiten (das gilt
natürlich auch für jede andere Art der
Performance-Analyse). - Die Ausführungszeit muss lange genug sein, sodass sich
statistisch gesehen genug Events in jedem Hotspot ereignen. Vtune
kann dazu auch die tatsächlich gemessene Anzahl an Events
darstellen. Beruht die Messung eines Hotspot auf nur wenigen
Events, etwa weniger als 20, ist die Aussage wenig
vertrauenswürdig. - Es kann theoretisch vorkommen, dass Hotspots nicht erkannt
werden. - Es passiert häufig, dass die Messung eine Ungenauigkeit
– genannt Skid – aufweist. Der tatsächliche Event
und die angezeigte Programmzeile passen nicht genau zueinander.
Hier ist ein wenig Erfahrung notwendig, aber es sollte jedem
Programmierer klar sein, dass zum Beispiel nur bei einer
Verzweigung ein Branch Mispredict vorkommen kann.
Diesen Einschränkungen stehen auch einige Vorteile gegenüber:
- Es ist nicht nötig, den eigenen Quellcode zu
instrumentieren. - Vtune erlaubt einen Blick auf das gesamte System. Der Autor
konnte beispielsweise mit Hilfe von Vtune schon mehrfach
Performance-Probleme auf einen störenden Prozess
zurückführen, der mit der Applikation selbst nichts zu
tun hatte.
Erste Schritte
Die Installation ist auf neueren Linux-Systemen meist problemlos. Üblicherweise finden aktuelle Suse-, Red-Hat- oder Fedora-Distributionen gute Unterstützung und sind auch zertifiziert. Die aktuelle Vtune-Version lässt sich aber auch problemlos zum Beispiel auf Open Suse 10.1 (32 Bit) verwenden, obwohl sie diese Release offiziell noch nicht unterstützt. Auch auf Debian-Systemen wurde die Software vom Autor bereits erfolgreich verwendet.
Die Installation setzt neben dem Tar-Archiv ein gültiges Lizenzfile voraus. Über [3] ist auch eine kostenfreie 30-Tage-Testlizenz verfügbar. Die ermäßigte Version für Studenten kostet knapp 50 Euro, eine normale Einzelplatzlizenz gibt es ab 630 Euro. Den Installations-Vorgang startet das Skript »install.sh«. Es empfiehlt sich dabei, zunächst die Default-Einstellungen beizubehalten.
Kernelmodul obligatorisch
Vtune benötigt ein globales Datendirectory, das es per Default in »/opt/intel/vtune/global_data« anlegt. Es setzt ein eigenes Kernelmodul voraus, dessen Sourcecode sich in »/opt/intel/vtune/vdk/src« befindet. Bei neuen Kernel- oder Distributions-Versionen kann dies zu Problemen führen. Mit etwas Geschick lassen sie sich aber in der Regel beseitigen.
Vtune verfügt sowohl über ein grafisches Benutzerinterface (»vtlec«) als auch über ein Tool für die Kommandozeile (»vtl«). Unter Linux basiert das GUI auf dem Eclipse-Framework und stellt damit bestimmte Anforderungen an CPU und Speicher. Diese Anforderungen können allerdings im Einzelfall dazu führen, dass die Leistungsmessungen verfälscht werden. Der Autor empfiehlt daher, Messung und Analyse zu trennen.
Grafisches Interface
Als praktisches Beispiel steht unter [2] ein kleines C-Programm bereit, mit dem die folgenden Tests ausgeführt wurden. Es basiert auf OpenMP und läuft damit parallel in mehreren Threads. Die Übersetzung erfolgte mit dem Intel-C-Compiler mit »icc -g -o vt_test -openmp omp_mm4.c«. Wichtig ist die Option »-g«: Die Auswertung der Messung setzt die Symbol-Informationen voraus, andernfalls kann Vtune nur eine Zuordnung zu der Assembler-Zeile anzeigen (genau wie ein Debugger).
Der GUI-Teil der Applikation startet über »/opt/intel/vtune/bin/vtlec«. Der Menüpunkt »File | New | New Project | Tuning Activity« startet eine neue Analyse. Die erste Untersuchung gilt häufig dem so genannten Callgraph. Dabei untersucht Vtune den Kontrollfluss auf der Ebene der Funktionsaufrufe und ordnet ihnen gemessene Events zu. Durch Instrumentieren des auszuführenden Code erhält man absolut korrekte Daten, zum Beispiel, wie oft das Programm eine gegebene Funktion aufgerufen und welchen Teil der Ausführungszeit es dort verbracht hat. Dadurch sieht der Programmierer sofort, welche Funktionen einen erheblichen Teil zur gesamten Ausführungszeit beitragen.
Ein Wizard führt durch alle notwendigen Einstellungen. Normalerweise reicht es, den Pfad zur Applikation mit den erforderlichen Startparametern einzutragen. Vtune instrumentiert das Binary (um Entry/Exit-Punkte von Funktionen zu überwachen) und führt das Programm aus. Nach Programmende analysiert es die Daten und gibt sie als Tabelle und Callgraph aus (Abbildung 1).
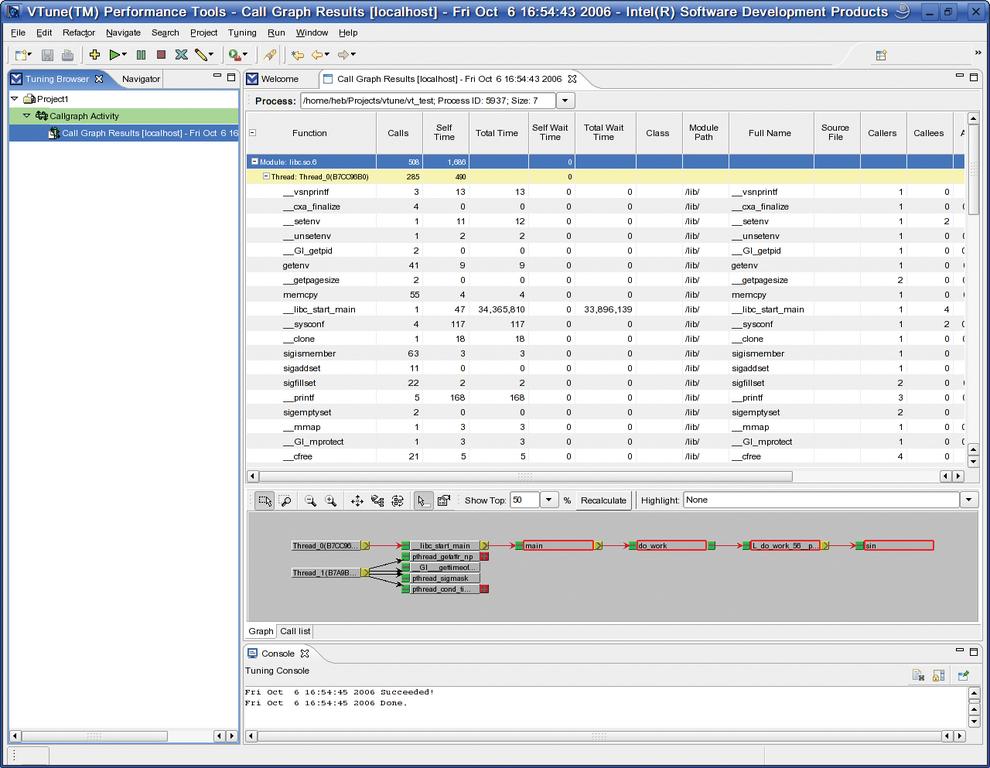
Abbildung 1: Das erste Ergebnis der Callgraph-Analyse (oben tabellarisch, unten grafisch aufbereitet). Das Diagramm zeigt die logischen Zusammenhänge, verzichtet aber auf Zahlen.
Auf der linken Seite zeigt das Programm eine Baumstruktur der Messungen. Ein Doppelklick auf einen Run-Ordner (oder eine der darunter angeordneten Einzelmessungen) öffnet die Datenansicht. Diese zeigt Vtune über das Kontextmenü (rechte Maustaste) als Tabelle und als Balkengrafik.
Genaue Analysen setzen einen so genannten Sampling Run voraus, den der »Sampling Wizard« in »Tuning Activity« startet. Möchte der Benutzer über die Standardeinstellung hinaus zusätzliche Events messen, muss er auf der letzten Dialogbox des Wizard das Häkchen für »Change Sampling Events« setzen. In der »Activity Configuration« kann er über »Events« zusätzliche Messungen hinzufügen (Abbildung 2).
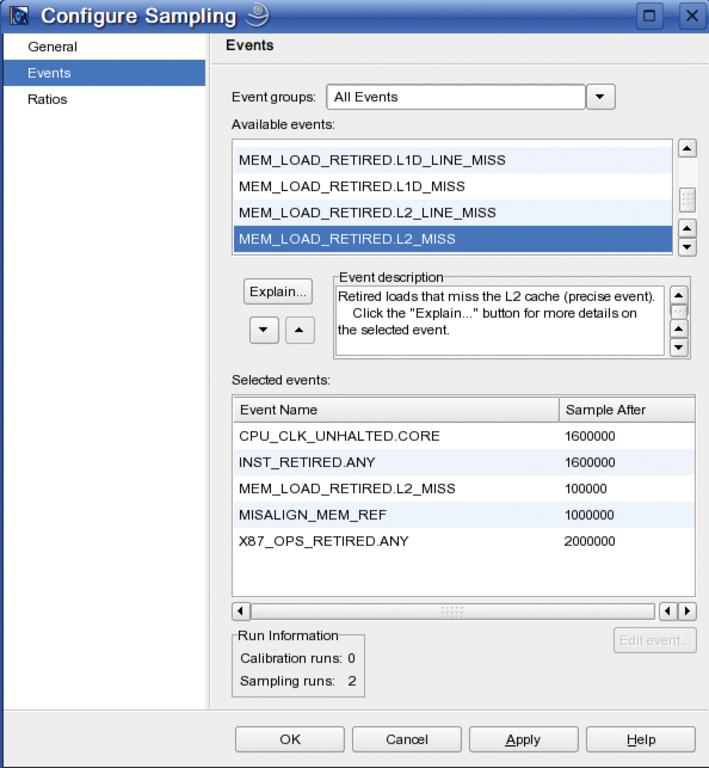
Abbildung 2: Vtune erlaubt, neben den voreingestellten Events eigene auszuwählen.
Die Zahl der in einem Lauf gleichzeitig gemessenen Events hängt von der CPU und der Kombination der Events ab. Vtune generiert automatisch entsprechend der Definition der Messung eine passende Zahl von Läufen und führt sie aus. Das bedeutet natürlich auch, dass jeder Run das Programm zweimal abarbeitet: einmal für die Kalibrierung, einmal für die Messung. Vtune unterstellt dabei, dass das Programm jedes Mal exakt gleich arbeitet.
Events und Zähler
Auf Core-2-CPUs stehen prinzipiell fünf Counter zur Verfügung. Davon sind drei auf Standard-Events beschränkt, es bleiben also nur zwei Counter für allgemeine Messungen übrig. Es ist jedoch meist sinnvoll, die Standard-Events in jedem Fall zu bestimmen. Dadurch können Verhältnisse wie INST_RETIRED.ANY/CPU_CLK_UNHALTED.CORE (also Instruktionen pro Clock) immer mit ausgewertet werden. Die Liste der verfügbaren Events ist abhängig von der CPU, in den modernsten Systemen zusätzlich auch vom Chipsatz. Events wie “2nd Level Cache Read Misses” sind auf allen aktuellen CPUs zu finden, aber SSE3-Counter zum Beispiel nur auf Systemen mit Prozessoren, die diese Einheit auch implementieren.
Es sei darauf hingewiesen, dass Intel die Counter nicht in einer Prozessor-übergreifenden Systematik implementiert hat. Pentium, Xeon und Centrino sind einander relativ ähnlich, unterscheiden sich jedoch aufgrund der komplett andersartigen Architektur vom Itanium. Der neue Core 2 Duo orientiert sich wiederum an beiden Vorgängern und ist mit über 700 Events ausgerüstet, die auch systematisch gegliedert sind.
Als Ergebnis eines Sampling Run erscheint zunächst eine Ansicht (Abbildung 3), die alle Prozesse anzeigt, die während der Messzeit im System abliefen. Bleibt der Mauszeiger für einige Sekunden über einem Modulnamen stehen, gibt Vtune für dieses Modul eine Zusammenfassung aus.
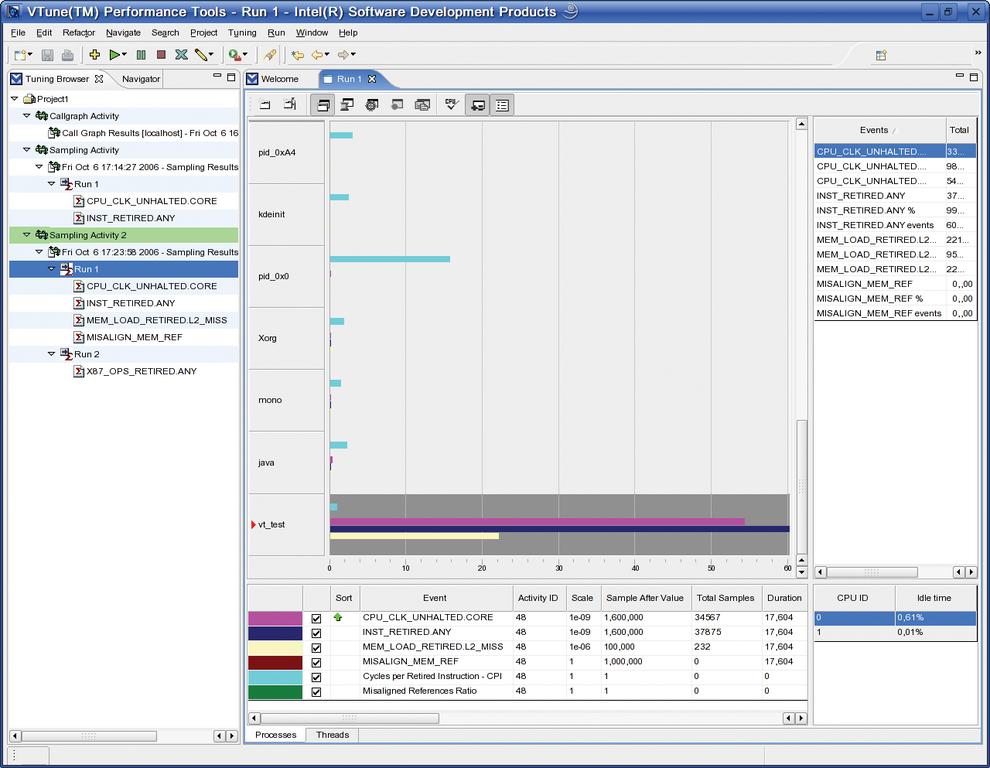
Abbildung 3: Das Ergebnis eines Sampling Run zeigt die statistisch erfassten Events aller auf dem System laufenden Prozesse. Das Objekt der Untersuchung ist in der grau unterlegten Zeile abgebildet.
Im Beispiel hat das Programm »vt_test« die höchsten Werte, sowohl bei der Zahl der abgearbeiteten Instruktionen (INST_RETIRED.ANY) als auch bei der Laufzeit (CPU_CLK_UNHALTED.CORE). Letzteres ist für einen ersten Überblick das wichtigste Kriterium. Optimierungen zahlen sich dort aus, wo sehr viel Laufzeit beansprucht wird. An diesen Stellen, den Hotspots, gibt das Verhältnis zur Anzahl der Instruktionen einen Anhaltspunkt dafür, ob sich eine Optimierung aus Sicht der Mikroarchitektur lohnt.
Erste Auswertung
Bei solchen Entscheidungen ist immer zu beachten, wie viel Zeit real für ein Stück Code benötigt wurde. In einem Programm, das 10 Sekunden läuft, ist es wenig sinnvoll, einen Codeteil mit CPI=20 zu optimieren, wenn dieser nur 0,1 s für die Ausführung benötigt. Weiter wichtig: Wird im Mittel bereits mehr als eine Instruktion pro Tick retired, ist durch reine Code-Optimierungen kaum mehr ein Geschwindigkeitsgewinn zu erzielen. Dann wird es Zeit, sich zu überlegen, ob nicht eher der Algorithmus einer Verbesserung bedarf oder ob Parallelisierung ein gangbarer Weg wäre und so weiter. E
Im Beispiel ist dies definitiv nicht der Fall. Ein Doppelklick auf den Eintrag zu »vt_test« öffnet die Thread-Ansicht (Abbildung 4). Es zeigt sich sofort, dass die beiden OpenMP-Threads nicht gleich viel Arbeit leisten. Beide arbeiten eine stark unterschiedliche Zahl an Instruktionen ab und brauchen dafür logischerweise auch unterschiedlich lange. Auch das Verhalten jedes einzelnen Thread ist weit vom Optimum entfernt.
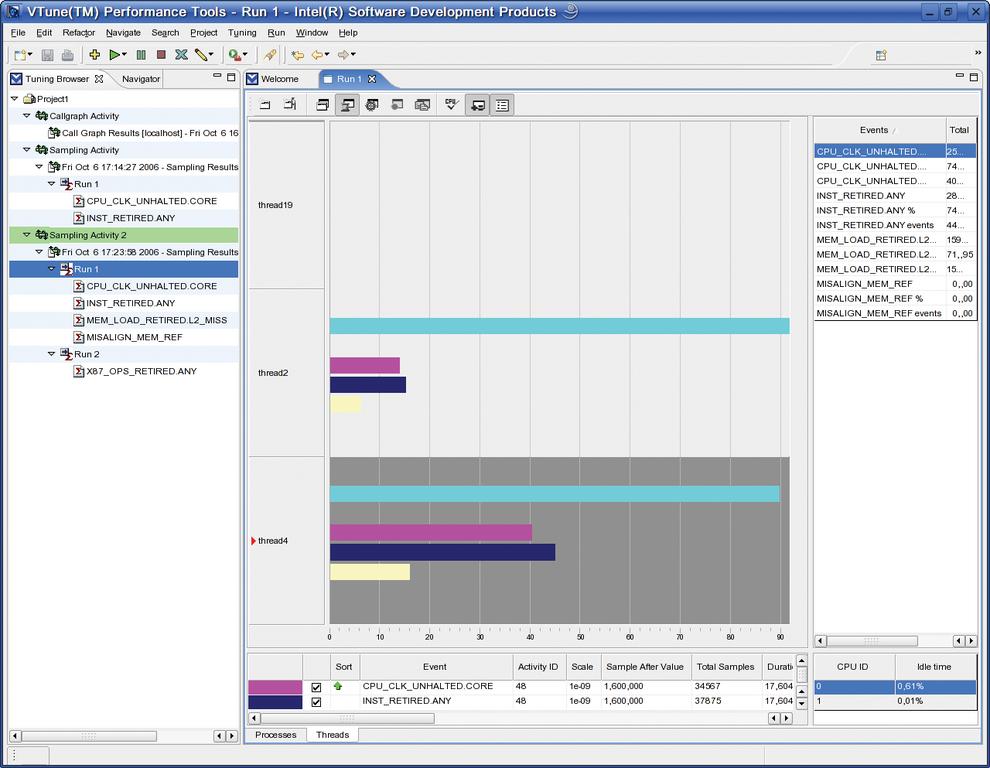
Abbildung 4: Die Thread-Ansicht verrät: Ein Thread hat mehr Arbeit zu verrichten als der andere und läuft deshalb auch länger. Außer der Laufzeit sind die jeweiligen Anteile an den protokollierten Events zu sehen.
Optimierungsansätze
Ein weiterer Doppelklick auf einen der Threads öffnet die Modul-Ansicht. Der Benutzer kann sich per Mausklick über die Hotspots weiter bis hin zum Sourcecode vorarbeiten (Abbildung 5), dessen innere Schleife in Listing 1 zu sehen ist. Hier zeigen sich nun die großen Unterschiede zwischen den drei Schleifen, aus denen das Programm besteht. Jede Schleife erledigt im Prinzip die gleiche Arbeit – die Unterschiede bestehen in der Art der Datenspeicherung.
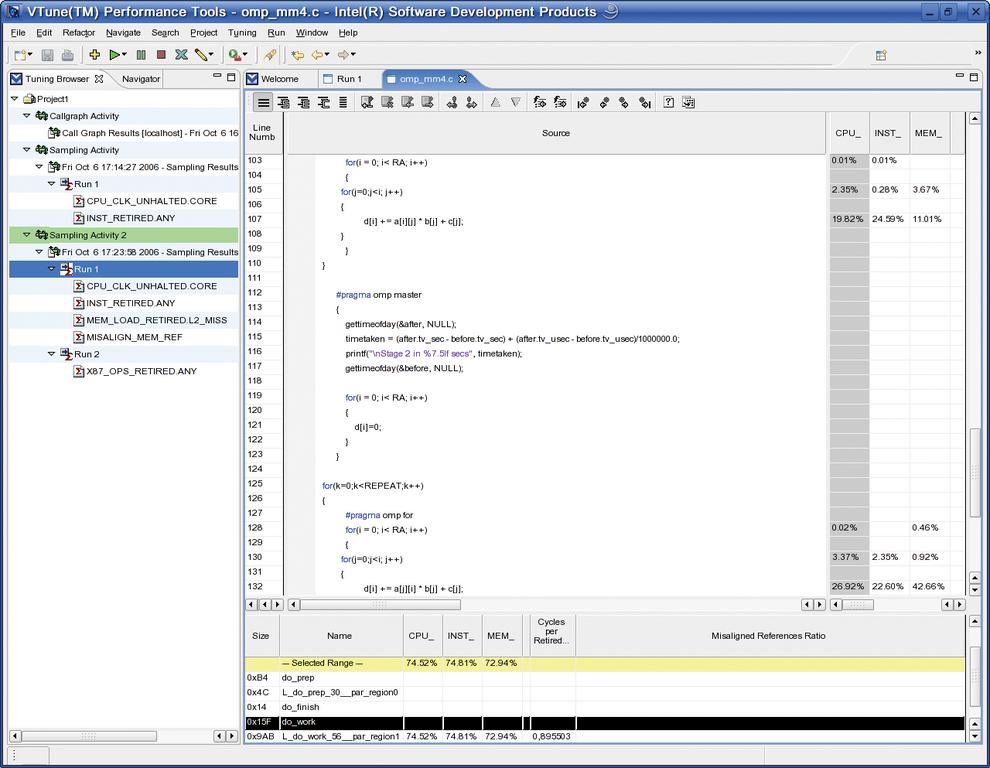
Abbildung 5: Die Source-Ansicht bricht die erfassten Daten bis auf die einzelne Codezeile herunter. In der grau unterlegten Spalte auf der rechten Seite ist der CPU-Anteil jeder Anweisung zu sehen.
|
Listing 1: Main Loop |
|---|
01 for (k = 0; k < REPEAT; k++)
02 {
03 #pragma omp for
04 for(i = 0; i < RA; i++)
05 {
06 for(j = 0; j < i; j++)
07 {
08 d[i] += a[i][j] * b[i] + c[i];
09 }
10 }
11 }
|
Der Unterschied zwischen zweiter und dritter Schleife liegt im Zugriff auf die Matrix »a[][]«. Der letzte – und schlechteste – Fall läuft über den ersten Index und arbeitet damit konträr zur Caching- und Pre-Fetching-Struktur der Hardware. Jeder Fehlzugriff auf den Cache (Cache Miss) lädt nicht nur das notwendige Datum, sondern auch die daran anschließenden Elemente in den Cache. Die Schleifen 1 und 2 verwenden diese Daten auch sofort wieder. Die dritte verlangt aber in jedem Schritt einen komplett anderer Speicherbereich, was zu einem eklatanten Anstieg der Cache Misses führt. Der ist nicht nur in Vtune zu beobachten, er zeigt sich auch in den Laufzeiten (Listing 2).
|
Listing 2: Threads |
|---|
01 $ export OMP_NUM_THREADS=2 02 $ ./vt_test 03 example with 2 threads 04 05 Stage 1 in 5.06335 secs 06 Stage 2 in 5.05060 secs 07 Stage 3 in 6.87645 secs 08 Finished 09 10 $ export OMP_NUM_THREADS=1 11 $ ./vt_test 12 example with 1 threads 13 14 Stage 1 in 6.82961 secs 15 Stage 2 in 6.70549 secs 16 Stage 3 in 9.10998 secs 17 Finished |
Das Ungleichgewicht zwischen beiden Threads ist durch einen beim Einsatz von OpenMP häufigen Fehler erklärbar. Thread 1 arbeitet die Schleife von 0 bis N/2 ab, Thread 2 von N/2 bis N. Die Länge der inneren Schleife steigt aber proportional zu N an. Das ist mit ein Grund dafür, dass sich Laufzeiten beim Einsatz zweier CPUs nicht halbieren. Der interessierte Leser sei dazu auf die OpenMP-Spezifikation [3] verwiesen, Stichwort Schedule.
Dient »vtlec« zur Messung, kann es passieren, dass dieser Prozess zusammen mit X11 und dem Window-Manager bereits einen großen Teil der vorhandenen CPU-Kapazität verbraucht. Zudem ist auf Batch-Systemen ein interaktiver Betrieb häufig nur schwer möglich. Deshalb ist es gut, dass ein großer Teil der Vtune-Funktionalität sich auch über die Kommandozeile erreichen lässt (Abbildung 6). Dabei gibt »vtl -help« einen Überblick über die möglichen Kommandos und Optionen. Detaillierter gibt die Hilfe Auskunft, wenn man den gewünschten Befehl als zusätzliche Option angibt. Dabei kommt dem Standardbefehl für die Messung eine Sonderstellung zu: »vtl -help -c sampling«.
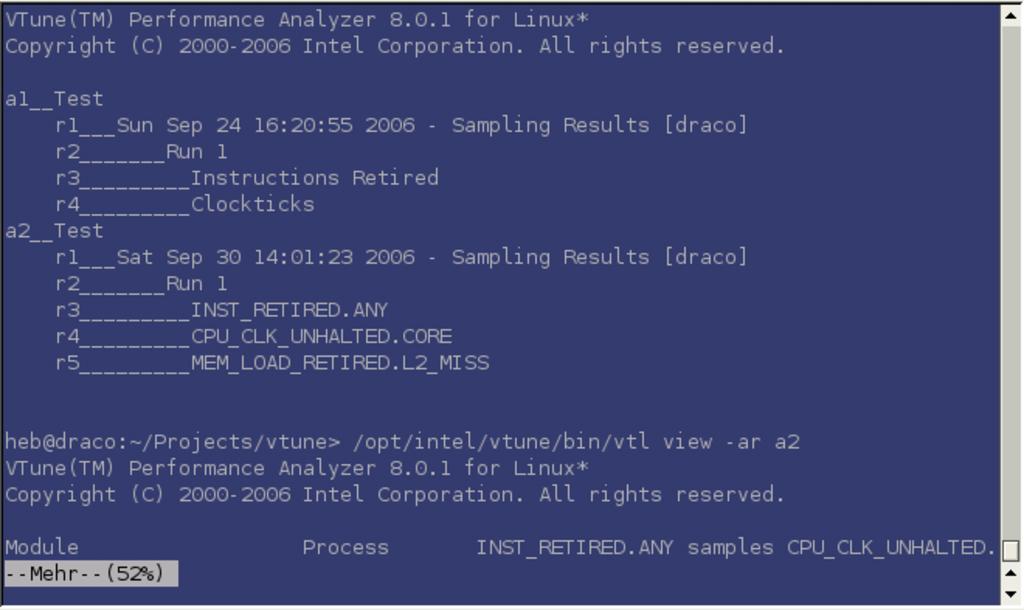
Abbildung 6: Wichtige Informationen für eine Optimierung liefert auch das textbasierte Tool »vtl«. Zum Beispiel gibt es einen Überblick über protokollierte Events.
Vtune-Kommandozeile
Er gibt nicht nur die gewünschten Details zum Befehl aus, sondern auch eine Liste aller verfügbaren Events. Ohne weitere Instrumentierung lässt sich das Testprogramm wie aus »vtlec« heraus unter Vtune ausführen:
vtl activity Test -d 40 -c sampling -o "-ec en='Instructions Retired' en='Clockticks' -cal yes" -app ./vt_test run
Die Elemente »activity Test« definieren eine neue Messung, die mit »-d 40« maximal 40 Sekunden dauern darf (das verhindert Probleme bei hängenden Programmen). Es wird eine Messung vom Typ »sampling« durchgeführt, die zwei Events beobachtet. Um die Counter zu kalibrieren, führt Vtune mit dem Schalter »-cal yes« automatisch zwei Läufe durch: Der erste zählt einfach alle auftretenden Events, im zweiten führt es die eigentliche Messung durch.
Das angehängte Kommando »run« startet die definierte Messung sogleich. Andernfalls würde der obige Befehl nur eine Messung definieren, die der Entwickler zu einem späteren Zeitpunkt über »run« startet. Die Daten hinterlegt Vtune im Homedirectory unter »~/VTune«. Auf der Kommandozeile zeigt »show« die aktuell gespeicherten Daten, mit der Option »-all« inklusive der in einem Lauf gespeicherten Events: »vtl show -all«.
Testdaten transportabel
Ein erster Überblick über die Messung ist über die Konsole mit dem Befehl »vtl view test -modules« möglich. Damit gibt Vtune alle Softwareprozesse aus, die während der Messung aktiv waren, inklusive der gemessenen Werte. Weitere Auswertungen gestalten sich in der Konsole leider etwas mühsam. Die gesammelten Daten lassen sich aber verpacken und zur Auswertung auf einen anderen Rechner übertragen. Im ersten Schritt packt »vtl pack test.vxp -ar test« die Ergebnisse ins Archiv-File »test.vxp«. Es enthält neben der eigentlichen Daten-Datei (»*.tb5«) auch Informationen darüber, welche Informationen wann gemessen wurden. Die vorhin gespeicherten Daten lassen sich im GUI »vtlec« mittels »File | Import | Tuning File | Export File (*.vxp)« einlesen.
Neben den vorgestellten Analysen bietet Vtune auch die Möglichkeit, Auswertungen über einen eingeschränkten Zeitbereich vorzunehmen beziehungsweise Informationen über die zeitliche Entwicklung eines Events zu liefern.
Um die Entwicklung parallelisierter Programme zu erleichtern, stehen mit dem Intel Thread Checker und dem Intel Thread Profiler zwei spezielle Vtune-Erweiterungen zur Verfügung. Der Thread Checker überprüft OpenMP-, Posix-Threads- oder Windows-Threads-basierte Programme auf Korrektheit, und zwar vor allem, ob die Speicherzugriffe richtig programmiert sind und keine Race Conditions auftreten können.
Der Thread Profiler erleichtert es, das zeitliche Verhalten eines Thread-basierten Programms zu untersuchen und festzustellen, wann während der Programmausführung welche der gestarteten Threads aktiv sind. Auf diese Weise lassen sich vor allem Deadlocks wesentlich einfacher finden.
Fazit
Intel Vtune hilft Programmierern Probleme zu lokalisieren, die aufgrund einer schlechten Anpassung des Programms an Intel-Hardware auftreten. Der Autor konnte in der Praxis feststellen, dass diese Probleme meist alle x86-Kompatiblen mehr oder weniger stark treffen und eine mögliche Optimierung allen derartigen Systemen zugute kommt.
Vtune kann aber auch dem Einsteiger eine Fülle von Informationen verständlich aufbereiten. Es ist nicht notwendig, Code speziell zu instrumentieren. Manches Problem lässt sich auch ohne Zugriff auf Sourcecode eingrenzen, da der Anwender mit einer Messung ein Abbild des kompletten Systems erhält.
Damit ist Vtune ein Tool mit vielen Möglichkeiten, das zudem einfach einzusetzen ist, allerdings eine gewisse Kenntnis der verwendeten Hardware verlangt. Denn die Fähigkeit, zu erkennen, welche der vielen messbaren Events im Anwendungsfall relevant sind, kann auch dieses Programm keinem Entwickler abnehmen. (ofr)
|
Infos |
|---|
|
[1] Intel Vtune: [http://www.intel.com/vtune] [2] Listings online: [https://www.linux-magazin.de/Service/Listings/2006/12/Vtune] [3] OpenMP: [http://www.openmp.org] |





