
Der Kernel bietet auf Multicore-Maschinen eine ganze Reihe von Methoden an, um Prozesse auf CPUs zu verteilen. Für alle braucht er die Mithilfe des Admin. So gewappnet erfüllt Linux auch harte Echtzeitanforderungen – wenn die betroffenen Prozesse ausreichend CPU-Zeit bekommen.
Multitasking im Linux-Kernel verhält sich ähnlich wie das Fotografieren: Im Automatik-Modus bringt jeder brauchbare Bilder zustande – ausreichende Lichtverhältnisse vorausgesetzt. Professionelle Fotografen dagegen, die mehr als Schnappschüsse erwarten, stellen selbst Blende, Verschlusszeit, Entfernung und Lichtempfindlichkeit ein und schaffen damit unter schwierigen Bedingungen stilvolle Bilder.
Mit der Hand gefertigt
Auch der Linux-Kernel kommt mit den meisten Lastsituationen prima zurecht, bietet aber zusätzlich Einstellschrauben, um auch schwierige Anforderungen zu erfüllen. Wer beeinflussen will, wie Linux Aufgaben auf die Rechnerkerne einer Multicore-Maschine verteilt, darf zwischen konkurrierenden Methoden wählen: CPU-Affinity, CPU-Hotplugging, CPU-Isolation und CPU-Sets. Das ist verwirrend und mancher Admin fragt sich zu Recht, welche Methoden seine Anforderungen am besten erfüllen.
Der Hintergrund: Mehrkern-Maschinen steigern einerseits die Verarbeitungsleistung und reduzieren andererseits die Latenzzeiten. Das erreicht der Linux-Scheduler allerdings nur, wenn er die anstehenden Aufgaben auch geeignet auf die mehrfach vorhandenen Verarbeitungseinheiten verteilt. Manchmal ist es hilfreich, ihm dabei unter die Arme zu greifen.
Das ist oft gar nicht so einfach, weil nicht nur Prozesse, sondern genau genommen Kernelthreads, Workqueues, Applikationsthreads ebenso wie Interrupts und Soft-IRQs inklusive Tasklets und Timer darauf warten, dass Linux ihnen eine CPU zuweist.
Zuneigung zeigen
Der Kernel verteilt die Threads auf Grundlage des Attributs »cpus_allowed«. Es ist Teil des Prozess-Control-Blocks (PCB) und für jeden Rechenprozess einmal vorhanden. Das Attribut »cpus_allowed« ist ein Bitfeld vom Typ »cpumask_t«, in dem je ein Bit eine CPU repräsentiert (siehe Abbildung 1). Ein gesetztes Bit teilt dem Scheduler mit, dass er die entsprechende CPU damit beauftragen darf, den Prozess zu bearbeiten. Eine Null unterbindet jegliche Verarbeitung.
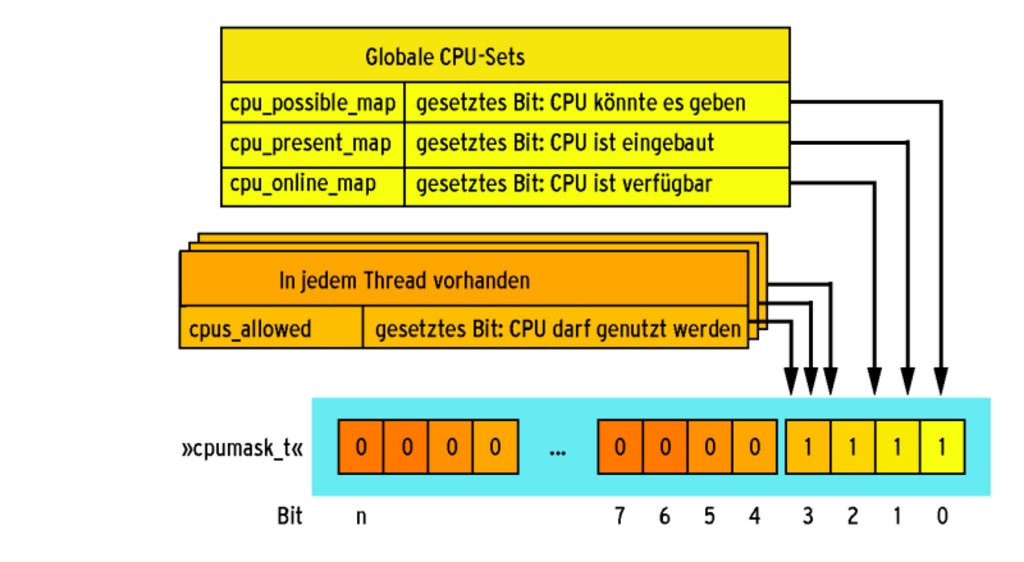
Abbildung 1: Der universelle Datentyp »cpumask_t« verwaltet die Rechnerkerne mit einer Bitmaske. Sie legt als Attribut »cpus_allowed« des PCB für jeden Thread fest, welche Kerne online sind und dem Thread zur Verfügung stehen.
Neue per »fork()« respektive »clone()« erzeugte Jobs erben das Attribut von ihren Eltern. Vom Userland aus erhalten Anwender durch Aufruf von »sched_getaffinity()« Auskunft über das Attribut, über die Makros »CPU_ZERO()«, »CPU_CLR()« und »CPU_SET()« modifizieren sie es oder setzten den Wert direkt mit dem Systemaufruf »sched_setaffinity()« [1].
Gruppenbildung
Etwas eleganter lassen sich Threads zu einer CPU durch CPU-Sets zuordnen: Sie sind zwar seit Version 2.6.12 im Standardkernel enthalten, basieren aber seit Kernel 2.6.24 auf dem allgemein einsetzbaren Framework Control Groups, das ehemals Container hieß. Control Groups (Cgroups) bilden einen Rahmen, in dem Anwender Rechenprozesse und ihre Nachkommen, die spezifische Eigenschaften besitzen, hierarchisch organisieren. Mit diesem Mittel gruppiert der Admin über ein virtuelles Filesystem vom Typ »cpuset« sowohl Prozessoren als auch Speicherressourcen (Memory Nodes) und verteilt die Rechenprozesse auf die eingerichteten Gruppen.
Abbildung 2 zeigt, dass diese Verteilung hierarchisch aufgebaut ist. Die oberste Gruppe enthält sämtliche Prozessoren und Memory Nodes. In einer Ebene darunter lassen sich die Ressourcen auf mehrere Untergruppen verteilen. Per Flag »cpu-exclusive« und »memory-exclusive« lässt sich festlegen, ob mehrere Gruppen eine Ressource (überlappend) verwenden dürfen oder ob diese exklusiv einer Gruppe zur Verfügung steht.
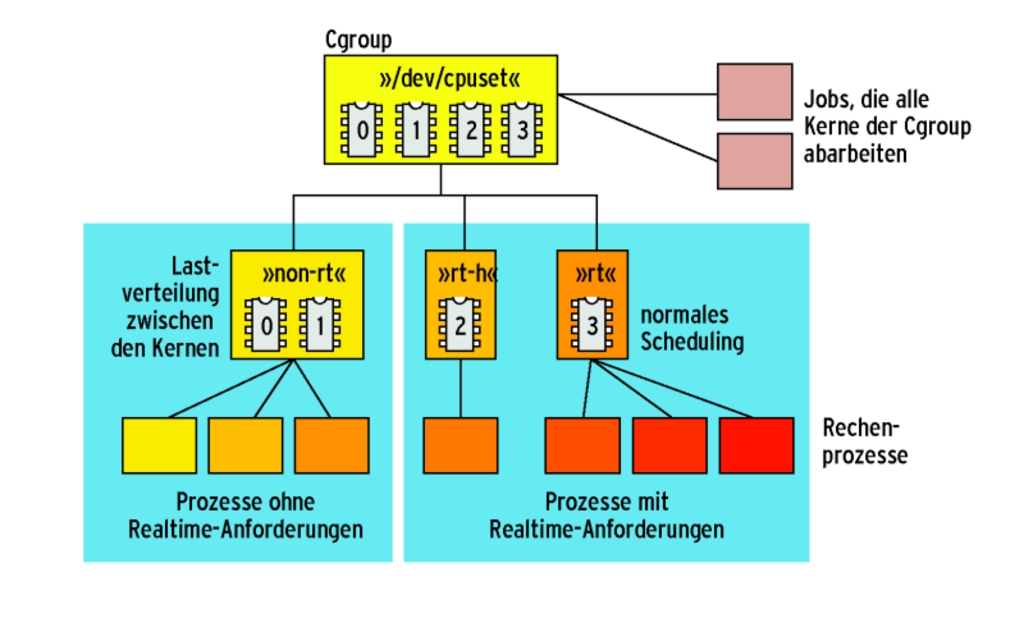
Abbildung 2: CPU- und Memory-Ressourcen lassen sich über Cgroups hierarchisch verwalten. Solange es kein gesetztes »exclusive«-Flag besitzt, sind Jobs einer übergeordneten Cgroup allen Ressourcen der Gruppe zugeordnet.
Verlagert der Kernel einen Rechenprozess in eine Gruppe, überschreibt er das Attribut »cpus_allowed« des verschobenen Prozesses. Er erbt auf diesem Wege die Einstellungen der Gruppe, da der Prozess die Affinity-Maske der Gruppe erhält. Das ist praktisch: Auf diese Weise lassen sich einfach und dauerhaft die zeitkritischen Prozesse von den weniger anspruchsvollen Prozessen trennen.
Ein Beispiel zeigt Listing 1: Im einfachsten Fall legt der Admin etwa die zwei Gruppen »rt« und »non-rt« (Zeilen 3 und 4) an, weist ihnen die Speicherressourcen und die Prozessorkerne zu (Zeilen 5 bis 10) und verschiebt sämtliche Prozesse in die »non-rt«-Gruppe (»for«-Schleife ab Zeile 11). Anschließend pickt er sich die zeitkritischen Rechenprozesse heraus und migriert diese in die »rt«-Gruppe (Zeilen 14 bis 16).
|
Listing 1: |
|---|
01 mkdir /dev/cpuset 02 mount -t cpuset -ocpuset cpuset /dev/cpuset 03 mkdir /dev/cpuset/rt 04 mkdir /dev/cpuset/non-rt 05 echo 0 > /dev/cpuset/rt/mems 06 echo 0 > /dev/cpuset/non-rt/mems 07 echo 2 >/dev/cpuset/rt/cpus 08 echo 1 >/dev/cpuset/rt/cpu_exclusive 09 echo 0-1 >/dev/cpuset/non-rt/cpus 10 echo 1 >/dev/cpuset/rt/cpu_exclusive 11 for pid in $(cat /dev/cpuset/tasks) 12 do 13 echo $pid > /dev/cpuset/non-rt/tasks 14 done 15 cd /dev/cpuset/rt 16 echo $$ > tasks 17 starte_rt_task |
Wer die Prozesse einmal verteilt hat, sollte davon absehen, nachträglich die Affinity-Maske einer Gruppe zu ändern. Das wirkt sich nämlich auf den innerhalb der Gruppe befindlichen Prozess nicht mehr aus. Um die Parametrierung wirksam zu verändern, müsste der Admin den Rechenprozess der entsprechenden Gruppe neu zuordnen. Ein Prozess kann aber über die Funktion »sched_setaffinity()« aus dem Container-Gefängnis Cgroup weder ausbrechen noch darin eindringen. Nur wenn ein Prozessorkern zu der Gruppe gehört, darf der Prozess dorthin migrieren.
Schiebung
Verschiebt ein Anwender Prozesse in die Gruppe »non-rt«, schaufelt er den nicht benutzen Kern für Realzeitaufgaben frei. Das lässt sich einfacher per CPU-Hotplugging bewerkstelligen. Eigentlich heißt Hotplugging, dass Anwender während des Betriebs Hardware hinzufügen oder entfernen; in diesem Fall ist einer von mehreren Prozessoren gemeint. Das sollten allerdings glückliche Besitzer von Mehrprozessormaschinen nicht wörtlich nehmen und während des Betriebs den Rechner aufschrauben. Echtes Hardware-CPU-Hotplugging unterstützen nämlich nur wenige Servertypen.
Unabhängig davon können Admins aber Software-technisch (logisch) einzelne Prozessoren (und damit auch Prozessorkerne) deaktivieren und wieder aktivieren. Schalten sie eine CPU ab, migriert Linux dessen Prozesse auf andere Kerne. Dieses Feature setzten Admins dann sinnvoll ein, wenn sie den Verdacht haben, dass ein einzelner CPU-Kern defekt ist. Die CPU 0 spielt als Bootprozessor eine Sonderrolle und lässt sich auf vielen Systemen nicht deaktivieren. Das hängt damit zusammen, dass bei diesen Architekturen einige Interrupts fest an den ersten Prozessorkern gekoppelt sind.
Kerne klarmachen
Abbildung 3 zeigt, wie sich durch Zugriffe auf das Sys-Filesystem eine CPU aktivieren und deaktivieren lässt. Sichtbar am Inhalt der Datei »/proc/interrupts« sind zunächst vier Kerne online. An der mit »ps axwu« erzeugten Prozesstabelle lassen sich die auf dieser CPU lokalisierten Kernelthreads entdecken. Sie tragen die CPU-Nummer im Namen, abgetrennt durch einen Schrägstrich. Deaktiviert der Anwender die CPU jetzt durch
echo "0" > online
dann taucht die CPU in »/proc/interrupts« nicht mehr auf. Auch die prozessorspezifischen Kernelthreads sind verschwunden. Fehlt bei einer CPU der Dateieintrag »online« im virtuellen Filesystem, lässt sie sich auch nicht deaktivieren.
Listing 2 zeigt anhand einer Callback-Funktion, wie sich Kernelcode darüber informiert, ob eine CPU wegfällt oder eine neue den Dienst aufgenommen hat. Über die Kernelfunktion »register_hotcpu_notifier()« meldet das ladbare Kernelmodul in Zeile 29 die ab Zeile 5 implementierte Funktion »my_cpu_callback()« an. Sobald sich etwas am CPU-Status ändert, informiert die Funktion darüber. Die Ausgabe lässt sich mit »dmesg | tail« beobachten.
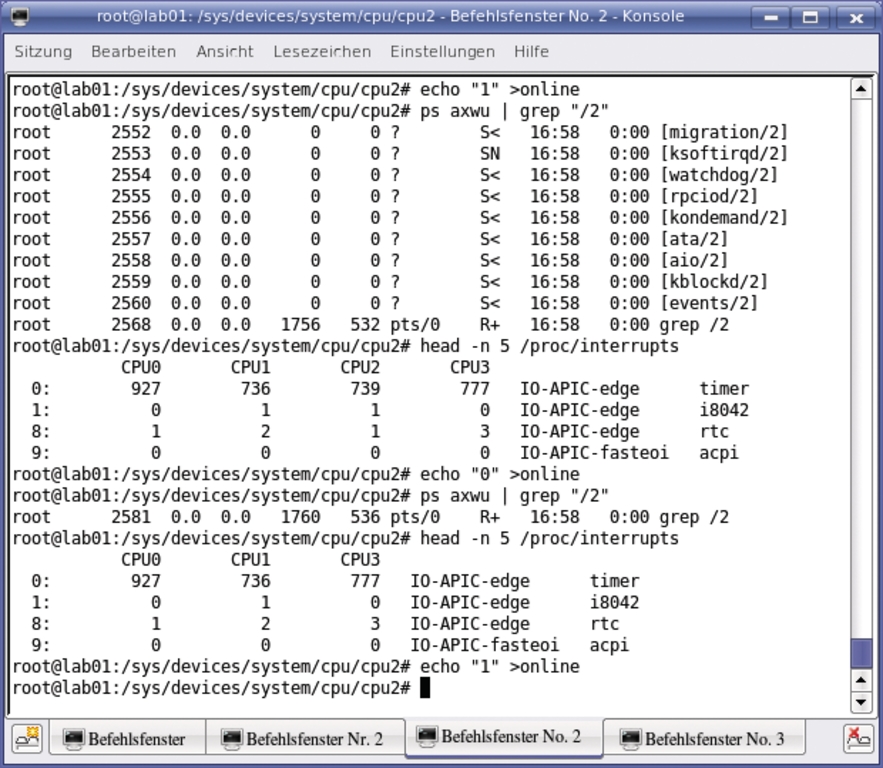
Abbildung 3: Durch einfache Schreibzugriffe auf das Sys-Filesystem lassen sich per Kommandozeile einzelne Rechnerkerne aktivieren und deaktivieren. Die virtuelle Datei »online« steuert dies. Hier schickt der Admin eine Null an die CPU 2, die daraufhin ihre Kernelprozesse beendet und zusätzlich Interrupts auf die noch aktiven Kerne umleitet.
|
Listing 2: |
|---|
01 #include <linux/module.h>
02 #include <linux/fs.h>
03 #include <linux/cpu.h>
04
05 static int __cpuinit my_cpu_callback(struct notifier_block *nfb,
06 unsigned long action, void *hcpu)
07 {
08 unsigned int cpu = (unsigned long)hcpu;
09
10 switch (action) {
11 case CPU_ONLINE:
12 case CPU_ONLINE_FROZEN:
13 printk("cpu 0x%x aktiviertn", cpu);
14 break;
15 case CPU_DEAD:
16 case CPU_DEAD_FROZEN:
17 printk("cpu 0x%x deaktiviertn", cpu);
18 break;
19 }
20 return NOTIFY_OK;
21 }
22
23 static struct notifier_block my_cpu_notifier = {
24 .notifier_call = my_cpu_callback;
25 };
26
27 static int __init mod_initialize(void)
28 {
29 register_hotcpu_notifier(&my_cpu_notifier);
30 printk("cpu_notifier angemeldetn");
31 return 0;
32 }
33
34 static void __exit mod_release(void)
35 {
36 unregister_hotcpu_notifier(&my_cpu_notifier);
37 printk("cpu_notifier abgemeldetn");
38 }
39
40 module_init( mod_initialize );
41 module_exit( mod_release );
42 MODULE_LICENSE("GPL");
|
Weggegangen, Platz vergangen
Wer übrigens eine CPU logisch entfernt, die zu einem CPU-Set gehört, streicht diese auch aus dem CPU-Set. Daher kehrt sie nicht automatisch wieder in das CPU-Set zurück, wenn der Anwender sie wieder aktiviert; er muss sie aktiv mit Hilfe des Sys-Filsystems wieder aufnehmen. Ebenfalls spannend ist die Frage, wie der Kernel mit einem Rechenprozess verfährt, der fest an eine offline zu nehmende CPU gebunden ist: Der Kernel geht bei Wegfall der den Prozess bearbeitenden CPU recht pragmatisch vor und ändert die CPU-Maske so, dass der Prozess fortan auf den übrigen Prozessoren arbeitet.
Isolationshaft
Von den CPU-Sets grenzt sich die CPU-Isolation dadurch ab, dass sie bereits beim Booten einsetzt. Per Bootparameter »isolcpus« lassen sich einzelne Rechnerkerne mit Ausnahme der CPU 0 direkt deaktivieren und vom Load-Balancing, dem Verteilen der Last zwischen den vorhandenen Prozessoren, ausnehmen. Die Methode ist sehr rudimentär, bringt aber kürzere Bootzeiten mit sich. Ansonsten spricht wohl noch die einfache Handhabung für den Bootparameter.
Sollen auf einer Mehrkernmaschine mehrere Prozessoren zeitkritische Rechenprozesse abarbeiten, verteilt der Kernel – anders als bei den Cgroups – bei vorhandenem Bootparameter »isolcpus« keine Lasten innerhalb der isolierten Kerne. Trotzdem arbeitet Linux auch auf den auf diese Weise isolierten Rechnerkernen ISRs, Tasklets und Timer ab. Das lässt sich allenfalls durch den Bootparameter »max_cpus« verhindern. Insofern ist verständlich, dass bei den wenigen Vorteilen die Entwickler diskutieren, dieses Feature aus dem Kernel zu entfernen.
Unterbrechungen verhindern
Ähnlich wie Rechenprozesse besitzen auch Interrupts im Kernel ein Attribut namens »mask«. Es legt pro Prozess mit Hilfe einer Bitmaske fest, welcher Prozessor eine Interrupt-Serviceroutine ausführen darf. Bei den Hardware-Interrupts legt der Kernelprogrammierer beim Einhängen der Interrupt-Serviceroutine fest, ob die ISR “balanced” sein soll oder nicht. Wählt er diese Eigenschaft ab, führt der Kernel die Routinen nur auf einer CPU aus.
Aus dem Userland manipuliert der Anwender das Attribut »mask« wieder einmal über das Proc-Filesystem:
cat /proc/irq/1/smp_affinity 0f echo "0x0e" > /proc/irq/1/smp_affinity cat /proc/irq/1/smp_affinity 0e
Dazu ist etwas Hex-Artithmetik nötig: In dem Beispiel nimmt der Anwender auf einer Vier-Kerne-Maschine – »smp_affinity« hat den Wert 0x0f, also sind vier Bits gesetzt – die CPU 0 von der Verarbeitung des Interrupts 1 aus, indem er das niederwertigste Bit löscht und »smp_affinity« nun den Wert 0x0e zuweist.
Weiche Interrupts
Wie die vorhandenen Prozessoren die Threads und Interrupts abarbeiten, lässt sich mit den beschriebenen Methoden gut kontrollieren. Das sind aber nicht die einzigen Arbeiter im Linux-Kernel: Soft-IRQs, Tasklets und Timer, aber auch Workqueues sind anders gelagert. Typischerweise arbeitet jene CPU Soft-IRQs und Tasklets ab, auf der auch die Interrupt-Serviceroutine lief.
Daher muss der Systemarchitekt dafür sorgen, dass er die IRQ-Affinität für Prozesse mit harten Echtzeitanforderungen auf dafür reservierte Kerne lenkt. Da heutzutage mehrere Hardwarekomponenten oft einen Interrupt gemeinsam nutzen, darf nur ein Kern die zugehörige Interruptleitung nutzen. Das ist bei vielen Architekturen nur durch einen Eingriff in das PCI-Handling möglich und erschwert die Portabilität.
Tuning schafft Performance
Das ist auch die Quintessenz, die aus einer guten und einer schlechten Nachricht besteht. Die gute: Dank der manuellen Kontrolle über das Load-Balancing lässt sich ein Standard-Linux-Kernel mit handelsüblichen Mehrkernprozessoren für Anwendungen mit harten Echtzeitanforderungen einsetzen. Entwickler berichten auf der Linux-Kernel-Mailingliste von Worst-Case-Latenzzeiten im einstelligen Mikrosekundenbereich [2].
Die schlechte Nachricht: Die guten Latenzzeiten erreicht Linux nicht von selbst, vielmehr muss der Systemarchitekt seine Maschine gut kennen und geeignet konfigurieren. Dazu bietet der Kernel gleich mehrere, konkurrierende Methoden. Trotz etwas manuellem Mehraufwand in der Konfiguration kristallisiert sich dabei ein Favorit heraus: Je mehr Kerne eine Maschine besitzt, desto weniger kommt der verantwortliche Admin an den CPU-Sets vorbei. (mg)
|
Infos |
|---|
|
[1] Eva-Katharina Kunst, Jürgen Quade, “Kern-Technik: Multiprocessing und -threading”, Folge 33: Linux-Magazin 05/07, S. 52 [2] Realtime-Linux-Wiki: CPU shielding using »/proc« and »/dev/cpuset«:[http://rt.wiki.kernel.org/index.php/CPU_shielding_using_/proc_and_/dev/cpuset] |
|
Die Autoren |
|---|
|
Eva-Katharina Kunst, Journalistin, und Jürgen Quade, Professor an der Hochschule Niederrhein, sind seit den Anfängen von Linux Fans von Open Source. Unter dem Titel “Linux Treiber entwickeln” haben sie zusammen ein Buch zum Kernel 2.6 veröffentlicht. |





