
© psdesign1, Fotolia
Kritische Code-Abschnitte, bei deren paralleler Abarbeitung Inkonsistenzen entstehen können, müssen geschützt werden. Die Informatik kennt dafür mehrere geeignete Verfahren, die meisten produzieren aber Overhead oder gar Deadlocks. Beim vergleichweise neuen RCU ist das anders.
Wenn mehrere Threads verzahnt auf dieselben Daten schreibend zugreifen, geht das mit einiger Wahrscheinlichkeit schief. Denn im ungünstigsten Fall verändert der eine Thread Daten, die ein parallel anderer just im gleichen Moment liest. Code-Abschnitte, die anfällig für solche Inkonsistenzen sind, heißen kritisch.
Das Problem ist ein alter Hut, auch deshalb, weil die Informatiker-Elite sehr früh eine Lösung fand: Wenn der gleichzeitige Zugriff zu Inkonsistenzen führt, lassen sie eben nacheinander zugreifen. Für den Betrachter des Ganzen passieren die Zugriffe sequenzialisiert. Aus der Sicht eines Thread mit konkurrierendem Zugriffswunsch findet ein gegenseitiger Ausschluss (Mutual Exclusion) statt [1].
Passende Schutzobjekte haben die Informatiker gleich mitgeliefert: Mutexe als eine Form der Semaphore beispielsweise oder Spinlocks. Codesequenzen, die auf gemeinsame Betriebsmittel – hier die Daten – zugreifen, heißen kritischen Abschnitte. Zu ihrem Schutz umschließt sie der Programmierer mit einer Lock- und einer Unlock-Operation (Abbildung 1).
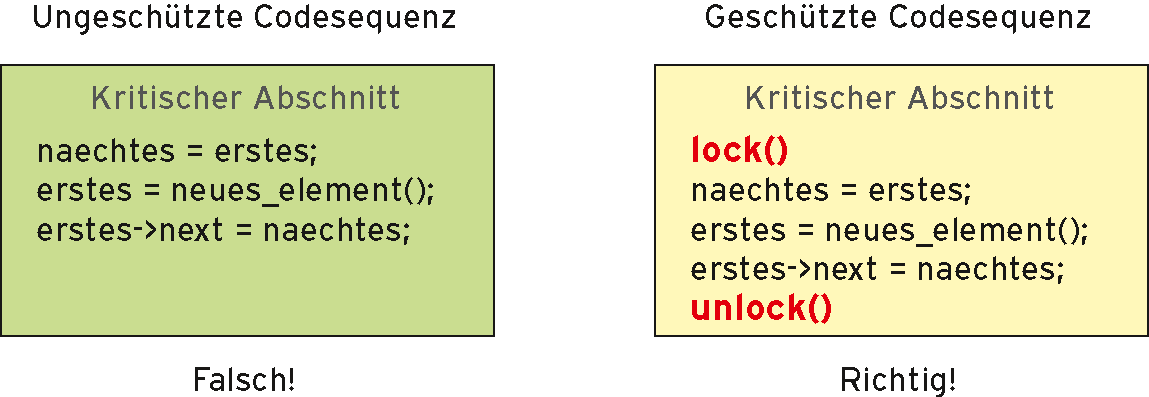
Abbildung 1: Zugriffe auf globale Daten sind programmtechnisch zu schützen.
Der Reihe nach
Der sequenzielle Zugriff hat aber Nachteile. Erstens kosten die Lock- und Unlock-Operationen extra Rechenzeit, zweitens sind Spinlocks, Mutexe und Semaphore eine Quelle von Deadlocks. Tritt durch unglückliche Programmierung ein Deadlock auf, friert gerne das gesamte System ein – erst ein Reboot bringt es wieder zum Laufen. Am problematischsten sind aber die deutlichen Latenzzeiten, die entstehen, wenn Codesequenzen auf das Unlock einer parallel zugreifenden Instanz (schlafend) warten.
Bereits so genannte Schreib-Lese-Locks ermöglichen gleichzeitige Lesezugriffe. Sobald jedoch eine Schreiboperation notwendig wird, bremst sie die Leser aus. Sie müssen auf das Ende der Operation warten. Schreib-Lese-Locks bringen im Mittel betrachtet eine Verbesserung, im Worst Case aber nicht.
In einigen Fällen bieten so genannte Sequenzlocks ein höheres Maß an Parallelität. Sie versetzen den lesenden Job niemals in eine Warte- oder Schlafposition. Er darf jederzeit zugreifen und sich eine Kopie der Daten ziehen. Allerdings muss er prüfen, ob jemand während seines Zugriffs die Daten verändert hat. Wenn ja, muss er seinen Zugriff wiederholen.
RCU-Hexenküche
Seit 2002 praktiziert Linux eine 1995 patentierte Methode, die den gleichzeitigen Zugriff von mehreren lesenden und einem schreibenden Job erlaubt ([2], [3], [4], [5], [6]). Das Pfiffige daran: Der lesende Zugriff produziert keinerlei Overhead! Das Read-copy Update (RCU) getaufte Verfahren besitzt viele Vorteile:
- Es lässt einen nur lesen wollenden Job unter keinen Umständen warten, legt ihn also nicht schlafen.
- Der lesen wollende Job braucht nicht die Zustände auszuwerten und im Konfliktfall mehrfach zuzugreifen.
- Normalerweise führt der Algorithmus keine extra (Maschinen-)Befehle aus.
- Wenn kein Job warten muss, entsteht keine Deadlock-Situation.
- Der Lock-Mechanismus lässt sich zudem rekursiv einsetzen.
Ein Wundermittel also? Nicht ganz, es gibt Einschränkungen, und daher eignet sich das Verfahren nicht, um jede Sorte kritischer Abschnitte zu sichern. So passiert es beim RCU gelegentlich, dass ein Datensatz kurzzeitig in mehreren Varianten vorliegt. Das klingt im ersten Moment nach einem nicht beherrschbaren Effekt, er erweist sich in der Praxis für die meisten Anwendungen jedoch als unproblematisch. Im Netzwerkhandling beispielsweise ist es üblich, dass Routingtabellen ausgetauscht werden; dass anschließend noch einige Pakete auf der alten Route unterwegs sind, stört nicht.
Die Kopie als Original
Während lesen wollende RCU-Jobs (die Leser) wie gehabt auf die Daten zugreifen, arbeiten die Jobs, die Daten verändern wollen (in der Sprache der Erfinder die Updater), zunächst mit einer Kopie. Dabei macht sich RCU den Umstand zu Nutze, dass die Datensätze typisch über Zeiger adressiert werden.
Der Updater reserviert Speicher für den neuen Datensatz zum Beispiel per »kmalloc()« , kopiert die Daten aus dem ursprünglichen Datensatz, verändert sie in der Kopie und legt dann nur den Basiszeiger auf den Datensatz mit der Adresse des neuen Datensatzes. Damit wird aus der Kopie das neue Orginal.
Leser, die vor dieser Umbelegung einen Zugriff begonnen haben, arbeiten naturgemäß vorläufig mit den alten Daten weiter. Neuzugriffe bekommen aber die aktuellen Daten zugeteilt. Für den Programmierer ergeben sich daraus zwei Schlussfolgerungen:
- Er sollte die Leser nicht ewig mit den (möglicherweise alten) Daten hantieren lassen, sondern es ihnen ermöglichen, ihre Aktionen zügig durchführen. Mit dem nächsten Zugriff holen sie sich eine neue Kopie des Basiszeigers und arbeiten ab dann auf den aktuellen Daten.
- Wenn die Leser ihren Zugriff beendet haben, hängen die nicht mehr benötigten Kopien im System herum. Der Programmierer muss sie aufräumen. Der Vorgang heißt Reclamation.
Das wiederum ist eines der Hauptprobleme beim RCU-Verfahren, da man den lesenden Job nicht mit derartigen Belanglosigkeiten belasten mag.
Die Erfinder von RCU haben für das Aufräumen, das an eine Garbage Collection erinnert, eine Lösung parat: Wenn garantiert ist, dass sich die lesenden (Kernel-)Threads während des Zugriffs nicht schlafen legen und zudem Linux die Codesequenzen nicht unterbricht, stellt das für den nächsten Kontextwechsel (Threadwechsel) sicher, dass der Zugriff abgeschlossen ist – ein guter Zeitpunkt, die alten Daten freizugeben.
Folglich überwacht das RCU-Subsystem das Scheduling. Dazu ist im Linux-Kernel seit Version 3.6 der Kernelthread »rcu_sched« zuständig. Der ist so programmiert, dass er sich von jedem Prozessorkern eines Multicore-Systems einmal bearbeiten lässt. Sobald eine solche Runde abgelaufen ist, gibt er die alten Datenkopien frei.
Ein Schutz für den Schutz
Abbildung 2 veranschaulicht das Prinzip anhand eines Beispiels. Im oberen Teil hat sich ein Leser die Adresse des Datensatzes kopiert. Er greift damit auf die Daten (»a« , »b« , »c« ) zu. Gleichzeitig ist ein Updater aktiv. Er hat bereits eine Kopie der Originaldaten angelegt und den Wert für »b« von 34 auf 78 geändert. Nach der Änderung (mittleres Teilbild) rettet der Updater zunächst die Adresse des alten Datensatzes für die spätere Freigabe, bevor der Basiszeiger mit der Adresse des neuen Datensatzes aktualisiert wird.
Abbildung 2: Schreibende Prozesse (Updater) arbeiten mit und auf Kopien.
Der Zugriff auf den Basiszeiger erfolgt über die Funktionen »rcu_dereference()« und »rcu_assign_pointer()« . Das ist notwendig, um einen implizit kritischen Abschnitt zu schützen; denn nicht alle Prozessoren gewährleisten, dass sie einen Zeiger (mit 4 oder 8 Bytes Länge) auch in einem Rutsch lesen und schreiben. Außerdem stellen die Funktionen sicher, dass kein Reordering der Befehle durch die CPU zur Laufzeit oder den Compiler vorab stattfindet (siehe Kasten “Umsortieren unterbinden”).
Umsortieren unterbinden
Moderne CPUs und moderne Compiler versuchen unabhängig voneinander die Laufzeit von Binärcode zu verringern, indem sie die Reihenfolge der Maschinenbefehle abändern, wenn dies auf die Gesamtfunktion der Routine keine Auswirkungen hat. Insbesondere in kritischen Abschnitten kann genau das zu Inkonsistenzen führen.
Das Optimieren der CPU zur Laufzeit abzuschalten gelingt über so genannte Memory Barriers, die dafür sorgen, dass die CPU in ihrer Pipeline alle Lese- oder Schreibebefehle abarbeitet, bevor sie sich den nächsten Befehl holt. Die zugehörigen Assembler-Befehle mappt Linux auf die Funktionen »rmb()« (Read Memory Barrier), »wmb()« (Write Memory Barrier) und »mb()« (Lesen und Schreiben). Die Linux-Funktion »barrier()« unterbindet dagegen das Compiler-Reordering.
Hat der Updater den Basiszeiger aktualisiert, muss noch jemand den alten Datensatz freigeben. Dazu wartet der Schreiber durch Aufruf von »synchronize_rcu()« , bis alle Leser die Zugriffe auf den alten Datensatz beendet haben, also bis der Scheduler auf jedem CPU-Core einmal aktiv war (unteres Teilbild). Diese Zeit heißt Grace-Period.
Anstelle des Wartens kann der Updater durch Aufruf von »rcu_callback()« auch einen Callback bemühen. Die arbeiten neuere Linux-Versionen in Kernelthreads ab – für jeden CPU-Core zwei. Das steigert laut Kernelentwickler, RCU-Maintainer und Patentinhaber Paul McKenney die Effizienz, vor allem aber verkürzt es die Latenzzeiten. Außerdem bieten mehrere Kernelthreads die Möglichkeit der Priorisierung und damit der Anpassung an den vorherrschenden Workload.
Pro CPU-Core gibt es zwei RCU-Threads, weil der Kernel Codesequenzen in unterschiedlichen Kontexten abarbeiten kann (Abbildung 3). Die Threads mit dem Namen »rcuos/N« bedienen RCU-geschützte kritische Abschnitte im Prozess- oder Kernelkontext. »N« steht für die Nummer des CPU-Core. Threads mit dem Namen »rcuob/N« bedienen dagegen die mit RCU geschützten kritischen Abschnitte auf Soft-IRQ-Ebene.
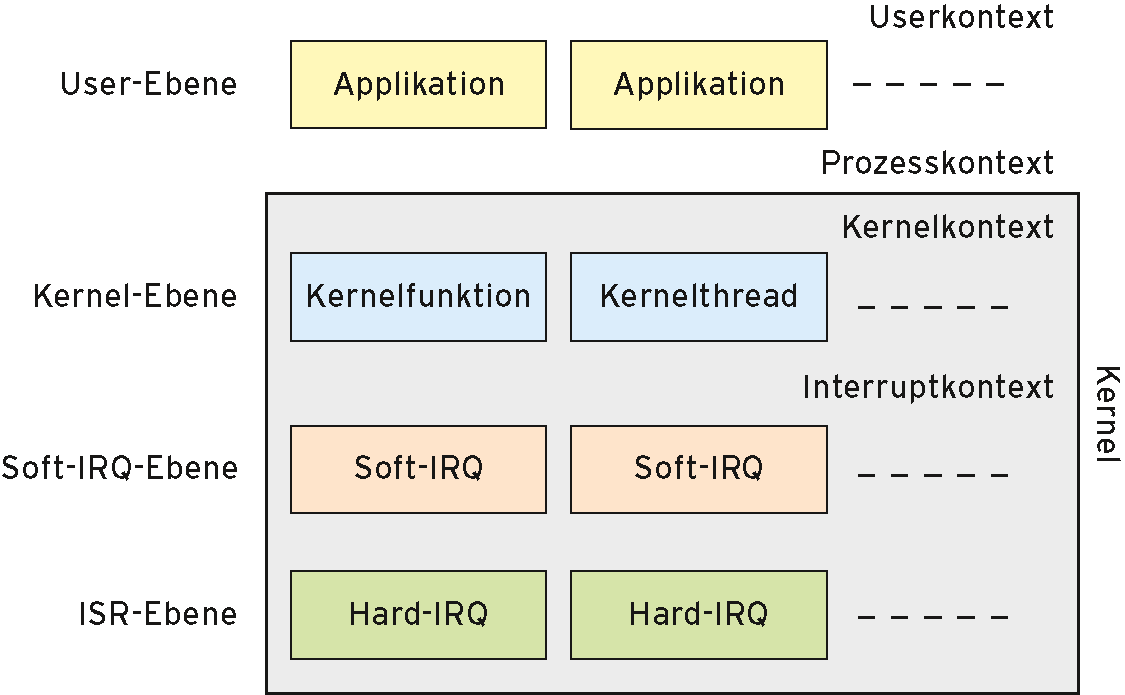
Abbildung 3: Ein Ebenen- und Kontextmodell des Linux-Kernel.
Codestücke einrahmen
Tatsächlich ist RCU auch auf Soft-IRQ-Ebene einsetzbar, also in Tasklets und Timern. Das macht allerdings einen anderen Mechanismus notwendig, um das unterbrechungsfreie Abarbeiten des kritischen Abschnitts zu gewährleisten und das Ende des lesenden Zugriffs zu identifizieren: Der Programmierer rahmt den kritischen Abschnitt eines lesenden Zugriffs durch eine Lock- (»rcu_read_lock()« ) und eine Unlock-Funktion (»rcu_read_unlock()« ) ein.
Der Lesezugriff gelingt damit leider nicht mehr hundertprozentig kostenlos. Vielmehr gewährleisten andere Mechanismen – beispielsweise eine temporäre Preemption-Sperre – die unterbrechungsfreie Abarbeitung des kritischen Abschnittes. Das Gleiche gilt, wenn die Kernelkonfiguration das Unterbrechen von Codesequenzen generell erlaubt (»CONFIG_PREEMPT« ).
Listing 1 setzt RCU ein und zeigt das Codefragment für einen lesenden Job. Der Job kennzeichnet den Beginn des kritischen Abschnitts (Zeile 1), kopiert sich den Zeiger in Zeile 2 auf die Daten und darf in Zeile 4 unbeschadet zugreifen. Nach dem Zugriff markiert Zeile 6 das Ende des kritischen Abschnitts.
Listing 1
Kritischen Abschnitt einrahmen
01 rcu_read_lock();
02 ptr = rcu_dereference(basiszeiger);
03 if (ptr != NULL) {
04 do_something_with(ptr->a, ptr->b, ptr->c);
05 }
06 rcu_read_unlock();
Listing 2 zeigt den Updater. Die Forderung, dass nur ein Job schreibt, erfüllt hier ein Spinlock per gegenseitigem Ausschluss. Nach Freigabe des Spinlocks schläft das Codefragment in Zeile 8 in der Funktion »synchronize_rcu()« , bis sich der Datensatz (per »kfree()« ) freigeben lässt – das so genannte Schlafen auf das Ende der Grace-Period hin.
Listing 2
Aktualisierungen erfolgen auf Kopien
01 spin_lock(&mylock); 02 backup_ptr = basiszeiger; 03 update_ptr = kmalloc(sizeof(*basiszeiger), GFP_KERNEL); 04 *update_ptr = *basiszeiger; 05 update_ptr->b = 78; 06 rcu_assign_pointer(basiszeiger, update_ptr); 07 spin_unlock(&mylock); 08 synchronize_rcu(); 09 kfree(backup_ptr);
Es gibt noch mehr als die soeben vorgestellten RCU-Funktionen. Insbesondere besitzt Linux Routinen, die den Umgang mit Listen vereinfachen. Der Kern unterstützt bei dieser Gelegenheit per RCU geschützte geschlossene, doppelt verkettete Listen (Ringlisten) sowie offene, verkettete Listen. Die Namen der Zugriffsunktionen sind im Kasten “Listenfunktionen des RCU-Subsystems” zu finden. Sie sind weitgehend selbsterklärend.
Listenfunktionen des RCU-Subsystems
Ringliste:
- »list_add_rcu()«
- »list_add_tail_rcu()«
- »list_replace_rcu()«
- »list_del_rcu()«
- »list_for_each_entry_rcu()«
Offene Liste:
- »hlist_add_after_rcu()«
- »hlist_add_before_rcu()«
- »hlist_add_head_rcu()«
- »hlist_replace_rcu()«
- »hlist_del_rcu()«
- »hlist_for_each_entry_rcu()«
Erfolgsstory geht weiter
Read-copy Update (RCU), ein vergleichsweise neues Verfahren, um kritische Abschnitte bei konkurrierenden Zugriffen zu schützen, hat sich innerhalb des Linux-Kernels bereits fest etabliert: Wer einen aktuellen Kernel danach durchforsten würde, käme auf mehr als 2000 Fundstellen. Ein Teil davon weist eine erhebliche Komplexität auf.
Der im Vergleich zu Spinlocks um Größenordnungen geringere Overhead (siehe Benchmark in Abbildung 4), die perfekte Skalierbarkeit angesichts der weitverbreiteten Multi- und Manycore-Systeme und die Immunität gegenüber Deadlocks machen den Mechanismus für Kernelhacker sehr interessant.
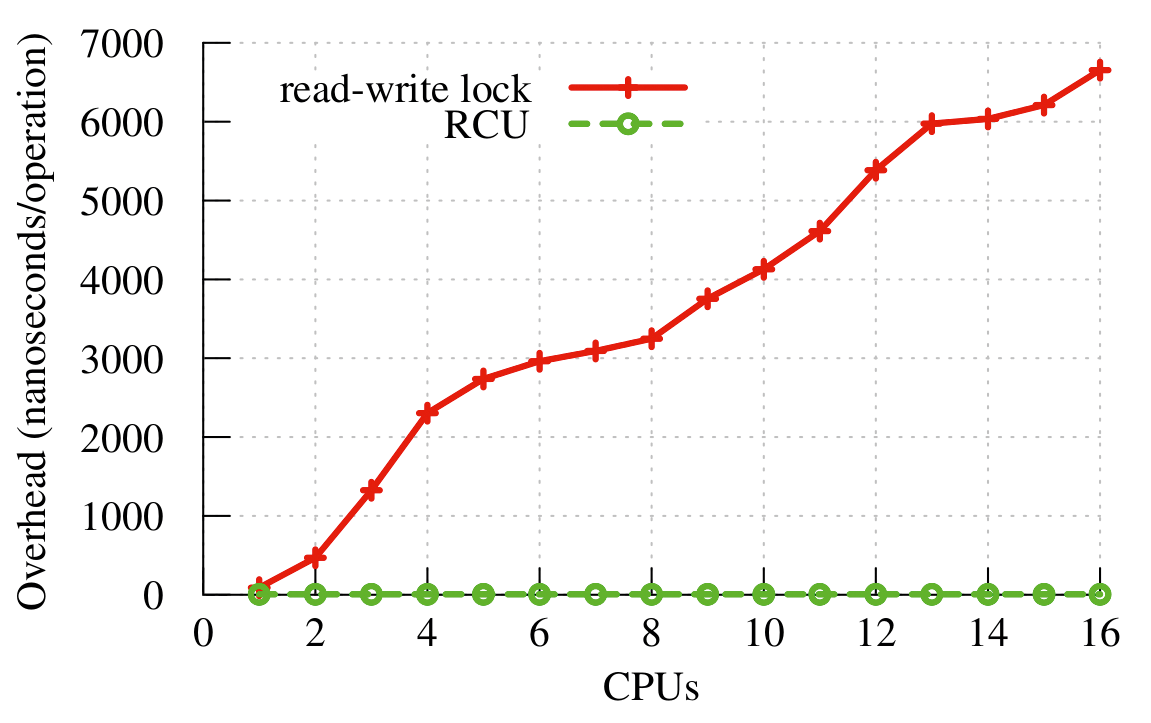
Abbildung 4: RCU benötigt beim Lesen keinen Overhead und ist unabhängig von der Anzahl der Rechnerkerne.
Die Kehrseite: Kurzzeitig existieren alte Datensätze und Datenreste verbleiben bis zum nächsten Scheduling im System,.Der Entwickler muss jene Daten sinnvollerweise als Datensätze organisieren, auf die über einen Basiszeiger zugegriffen wird. Zu einem Zeitpunkt x bleibt – wie anderswo auch – stets nur ein schreibender Zugriff erlaubt.
Immerhin berücksichtigt RCU in der Linux-Praxis unterschiedliche Abarbeitungskontexte ebenso wie Realzeit-Anforderungen – inklusive Prioritätsinversion und Threaded Interrupts. Mit SRCU (Sleeping RCU) hat Linux sogar eine Variante in petto, bei der Threads im kritischen Abschnitt schlafen dürfen. Für das Userland gibt es die Liburcu [8]. Die Entwicklung geht also munter weiter.
Infos
- Quade, Kunst, “Kern-Technik” – Folge 51: Linux-Magazin 05/10, S. 92, https://www.linux-magazin.de/Ausgaben/2010/05/Kern-Technik
- McKenney, Walpole, “What is RCU, Fundamentally?”: https://lwn.net/Articles/262464/
- McKenney, “Requirements for RCU part 1: the fundamentals”: http://lwn.net/Articles/652156/
- Ebenda Kenney, “RCU requirements part 2 – parallelism and software engineering”: http://lwn.net/Articles/652677/
- McKenney, “RCU requirements part 3”: http://lwn.net/Articles/653326/
- McKenney, “Is Parallel Programming Hard, And, If So, What Can You Do About It?”: https://www.kernel.org/pub/linux/kernel/people/paulmck/perfbook/perfbook.2015.01.31a.pdf
- McKenney, Boy-Wikizer, Walpole, “RCU Usage In the Linux Kernel: One Decade Later”: http://www2.rdrop.com/users/paulmck/techreports/RCUUsage.2013.02.24a.pdf
- Userspace-RCU http://liburcu.org





