
© psdesign1, Fotolia
Über das Proc-Filesystem lassen sich leicht aktuelle Daten zwischen System und Anwender austauschen. Dazu liest und schreibt man einfach in ein File. Dieser Mechanismus eignet sich auch, um erste Schritte der Kernelprogrammierung zu demonstrieren.
Gemäß der zentralen Unix-Philosophie “Everything is a File” publiziert Linux seit Jahren Systeminformationen über die virtuellen Filesysteme »/proc« und »/sys« (siehe Kasten “Das Proc-Filesystem”). Das ist eine geniale Sache, ermöglicht es doch den lesenden und schreibenden Zugriff auf Systeminterna mit Hilfe der immer gleichen Zugriffsfunktionen »read()« und »write()« .
Das Proc-Filesystem
Beim Proc-Filesystem handelt es sich um ein virtuelles Dateisystem, dessen Ordner und Dateien nicht auf einer Festplatte gespeichert sind, der Kernel erzeugt sie erst beim jeweiligen Zugriff dynamisch. Der Namensvorsatz “Proc” leitet sich von “Processes”, also Rechenprozesse, ab und verdeutlicht, dass das Proc-Filesystem vor allem Informationen zu Rechenprozessen liefert (Abbildung 4).
Abbildung 4: Verzeichnisse und Dateien des Ordners »/proc/«.
Für jeden Rechenprozess legt der Kernel ein eigenes Verzeichnis mit der Prozess-Identifikationsnummer als Namen an. Unterhalb des Verzeichnisses befinden sich umfangreiche Informationen zum Job, angefangen bei den Aufrufparametern (»cmdline« ) über die genutzten Filedeskriptoren (»fd« ) sowie die Environment-Variablen (»environ« ) bis hin zu Prozessstatistiken.
Neben Informationen zu Rechenprozessen nutzt auch der Kernel selbst das virtuelle Dateisystem, um darüber mit dem Anwender Systeminformationen auszutauschen und Konfigurationen entgegenzunehmen. Alle Daten zur aktuellen CPU finden sich unter »/proc/cpuinfo« , Interrupt-Quellen und die Häufigkeit ihres Auftretens unter »/proc/interrupts« , die aktivierten Gerätetreiber gehören mit ihren Gerätenummern unter »/proc/devices« . Durch das Schreiben einer »1« auf die Datei »/proc/sys/net/ipv4/ip_forward« wird das Routing im Linux-Kernel aktiviert und »/proc/sys/kernel/watchdog« konfiguriert schließlich die Watchdog-Funktionalität [2].
Es ist durchaus sinnvoll und lehrreich, einmal durch das Proc-Filesystem zu navigieren. Die Bedeutung der Proc-Dateien ist typischerweise über die Namen erkennbar. Hardware-relevante Informationen befinden sich übrigens – mit Ausnahme der Infos über die CPU – im Sys-Filesystem. Dieses bietet sich für Treiberprogrammierer als Plattform für den Informationsaustausch an.
Die Shell wiederum bildet diese Zugriffsfunktionen auf die Kommandos »cat« (Lesen) und »echo« (Schreiben) ab. Um die Anzahl der seit dem Hochfahren ausgelösten Interrupts auszulesen, reicht es dank dieser Methode, im Terminal das Kommando »cat /proc/interrupts« einzugeben. Oder: Um das Durchleiten von Netzwerktraffic zu ermöglichen, braucht der Superuser lediglich eine »1« in die Datei »/proc/sys/net/ipv4/ip_forward« zu schreiben: »sudo echo 1 > /proc/sys/net/ipv4/ip_forward« . Solche Funktionen sind auch in Skripten sehr leicht zu verwenden.
Das Proc-Filesystem eignet sich auch dazu, erste eigene Schritte in der Kernelprogrammierung zu gehen: Mit weniger als 50 Zeilen Code generiert der Compiler ein Modul, das beim Zugriff auf eine Proc-Datei den berühmten String “Hello World” ausgibt (Listing 1).
Listing 1
Einfache Proc-Datei
01 #include <linux/module.h>
02 #include <linux/proc_fs.h>
03 #include <linux/seq_file.h>
04
05 #define PROC_FILE_NAME "Hello_World"
06 static struct proc_dir_entry *proc_file;
07 static char *output_string;
08
09 static int prochello_show( struct seq_file *m, void *v )
10 {
11 int error = 0;
12
13 error = seq_printf( m, "%s\n", output_string);
14 return error;
15 }
16
17 static int prochello_open(struct inode *inode, struct file *file)
18 {
19 return single_open(file, prochello_show, NULL);
20 }
21
22 static const struct file_operations prochello_fops = {
23 .owner = THIS_MODULE,
24 .open = prochello_open,
25 .release= single_release,
26 .read = seq_read,
27 };
28
29 static int __init prochello_init(void)
30 {
31 output_string = "Hello World";
32 proc_file= proc_create_data( PROC_FILE_NAME, S_IRUGO , NULL,
33 &prochello_fops, NULL);
34 if (!proc_file)
35 return -ENOMEM;
36 return 0;
37 }
38
39 static void __exit prochello_exit(void)
40 {
41 if( proc_file )
42 remove_proc_entry( PROC_FILE_NAME, NULL );
43 }
44
45 module_init( prochello_init );
46 module_exit( prochello_exit );
47 MODULE_LICENSE("GPL");
Module sind bekanntlich Erweiterungen des Linux-Kernels. Sie sind immer ähnlich aufgebaut (Abbildung 1). Zwei Dinge benötigt die Verwaltung des Moduls: Routinen, die die eigentliche Modulfunktionalität implementieren, und eine Datenstruktur, die die Adressen der zentralen Routinen aufnimmt. Die beiden Verwaltungsfunktionen sind »xxx_init()« und »xxx_exit()« , wobei »xxx« stellvertretend für den Modul- oder einen beliebig wählbaren Namen steht. Die »xxx_init()« läuft, wenn das Kommando »insmod« das Modul in den Kernel lädt, »xxx_exit()« ist dran, wenn das Modul per »rmmod« wieder entladen werden soll.

Abbildung 1: Kernelmodule lassen sich in drei Bereiche gliedern.
Die wesentliche Aufgabe der Funktion »xxx_init()« besteht darin, die Datenstruktur mit den Adressen der relevanten Modulroutinen einem Kernel-Subsystem zu übergeben. Das Modul meldet sich bei dem oder den gewünschten Subsystemen an, es registriert sich. Damit kennt der Kernel die relevanten Modulroutinen und kann sie aktivieren. Analog ist »xxx_exit()« fürs Abmelden zuständig.
In Listing 1 sind die drei Bereiche eines typischen Linux-Moduls gut erkennbar: die Verwaltungsfunktionen »prochello_init()« und »prochello_exit()« (Zeilen 29 und 39), die Modulroutinen »prochello_show()« und »prochello_open()« (Zeilen 9 und 17) und drittens die zum Anmelden beim Kernel verwendete Datenstruktur »prochello_fops« (Zeile 22).
Zugriffsrechte übergeben
Innerhalb der Init-Funktion »prochello_init()« meldet sich das Modul mit Hilfe der Funktion »proc_create_data()« beim Proc-Subsystem des Linux-Kernels an. Es übergibt den Namen der Proc-Datei und die Zugriffsrechte auf diese Datei. Da die Zugriffsrechte als Bitmuster kodiert sind, verwendet man Defines (»S_IRUGO« ). Im Beispiel erhalten sowohl der Besitzer (User) als auch die Gruppe und alle übrigen Leserechte.
Der dritte Parameter legt fest, wo im Verzeichnisbaum des Proc-Filesystems die Datei zu erzeugen ist. »NULL« legt die Datei unterhalb von »/proc/« an. Der vierte Parameter schließlich übergibt die Datenstruktur, die die eigentlichen Zugriffsfunktionen auf die neue Proc-Datei enthält. Insgesamt sind für den lesenden Zugriff drei Funktionen nötig: »open()« , »read()« und »release()« .
Selbst implementiert ist allerdings nur die Open-Routine (»prochello_open()« ). Wer will, kann die übrigen Routinen (»read()« und »release()« ) ebenfalls selbst implementieren. Das ist aber kompliziert und nur in Ausnahmefällen sinnvoll. Die Kernelentwickler haben dafür eine fehlerresistente Zwischenschicht eingebaut, die den Datenaustausch auf Funktionen analog zu »printf« reduziert. Die Grundidee der Zwischenschicht besteht darin, dass der Modulprogrammierer alle Daten in einen ausreichend großen Speicherbereich schreibt (Abbildung 2).
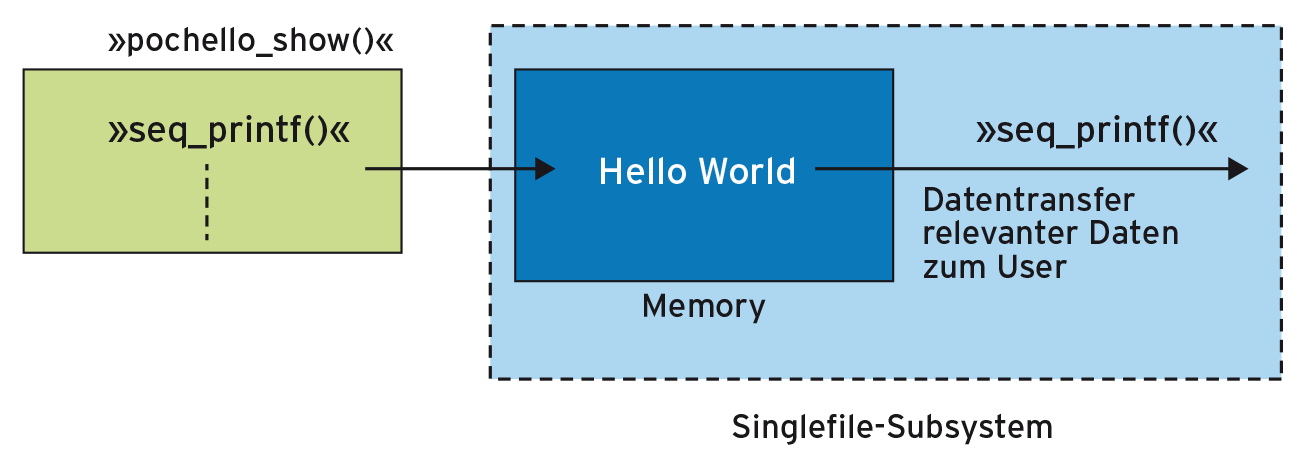
Abbildung 2: Die Show-Funktion schreibt die Daten per »seq_printf()« in den Hauptspeicher, das Singlefile-Subsystem kopiert relevante Daten zum User.
Um die weitere Verarbeitung der Daten, also insbesondere den Transfer an die Nutzer der Proc-Datei, kümmert sich die Zwischenschicht. Dieser Transfer ist nämlich komplizierter als es auf den ersten Blick erscheint. Denn der Nutzer liest unter Umständen nicht einfach alle Daten, sondern nur Teilbereiche davon. Eventuell holt er sich die Daten auch über mehrere Lese-Aufrufe.
Die besagte Zwischenschicht firmiert unter dem Namen “Singlefile”, einer Sonderform von Sequencefiles [1]. Ein Singlefile implementiert vor allem die Lese- und die Release-Funktion (entspricht dem Systemcall »close()« ), sodass sie sich ohne Änderungen für den Zugriff auf die Proc-Datei verwenden lässt. Zum Anlegen der Singlefile-Instanz muss der Modulprogrammierer die Funktion »single_open()« aufrufen, der dann die Adresse einer zumeist »show()« genannten Routine übergibt.
Diese Show-Routine bekommt die Adresse einer Speicherseite übergeben, in die die auszugebenden Daten beispielsweise per »seq_printf()« geschrieben werden. »seq_printf()« lässt sich mehr oder minder beliebig oft innerhalb der Show-Funktion aufrufen.
Limitierte Singlefiles
Singlefiles sind nicht dazu gedacht, viele Daten zu schreiben. Vielmehr ist der zur Verfügung gestellte Speicherbereich auf 64 KByte limitiert. Das reicht für die meisten Aufgaben. Außerdem überwacht »seq_printf()« bei jedem Aufruf, ob über das Limit hinaus geschrieben würde. Wäre das der Fall, vergrößert das Subsystem automatisch den Speicher (etwa durch Neu-Anlegen und Umkopieren) und schreibt danach die Daten. Ist das Vergrößern unmöglich, gibt »seq_printf()« einen negativen Fehlercode zurück. Professionelle Programmierer werten den Rückgabewert selbstverständlich aus. Die Funktion »single_open()« , die die Adresse der Show-Funktion erhält, wird in der Open-Funktion zur Proc-Datei aufgerufen (Listing 1, Zeile 19).
Abbildung 3 zeigt, wie Interessierte den Quellcode aus Listing 1 mit Hilfe des Makefile (Listing 2) kompilieren, danach per »insmod« das generierte Modul in den Kernel laden und schließlich mit »cat« testen. Wer die Proc-Datei nicht direkt unter »/proc« , sondern in einem Unterordner anlegen will, erzeugt mit Hilfe von »proc_mkdir« ein Verzeichnis. Die Funktion gibt einen Zeiger auf eine Datenstruktur vom Typ »proc_dir_entry« zurück, die das neu angelegte Verzeichnis repräsentiert.
Listing 2
Makefile
01 ifneq ($(KERNELRELEASE),) 02 obj-m := prochello.o 03 04 else 05 KDIR := /lib/modules/$(shell uname -r)/build 06 PWD := $(shell pwd) 07 08 default: 09 $(MAKE) -C $(KDIR) M=$(PWD) modules 10 endif
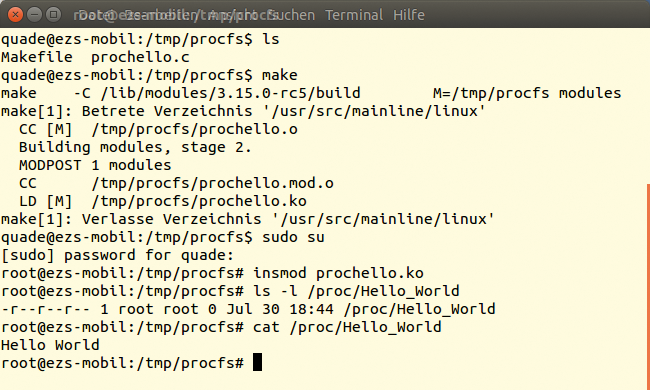
Abbildung 3: Generierung und Verwendung des Kernelmoduls.
Die Funktion »proc_mkdir()« bekommt zwei Parameter übergeben. Der erste enthält den Verzeichnisnamen als String, mit dem zweiten übergibt der Programmierer eine Kennung, in der das neue Verzeichnis angelegt werden soll. Ist der zweite Parameter gleich »NULL« , entsteht der neue Ordner unterhalb des Verzeichnisses »/proc« .
Es ist ein Kardinalfehler, zu vergessen, angelegte Proc-Verzeichnisse und -Dateien wieder zu löschen, wenn man sie nicht mehr braucht oder das ganze Modul entfernt. Dazu dient die Funktion »remove_proc_entry()« , die neben dem Namen der zu entfernenden Datei auch die Kennung für das Unterverzeichnis angibt, das die Proc-Datei enthält.
Hand anlegen
Die Übernahme von Konfigurationsdaten in den Kernel per Schreiben auf eine Proc-Datei wird nicht vom Subsystem unterstützt. Hier legt der Modulprogrammierer selbst Hand an. Zunächst benötigt er Speicher, um die zu schreibenden Daten im Kernel für die Auswertung zwischenzuspeichern. Ist davon ausreichend vorhanden, kopiert er die zu schreibenden Daten vom Userspace in diesen Speicher. Danach kann er die Daten auswerten und die vom User gewünschte Aktion ausführen. Dabei ist darauf zu achten, nicht mehr Daten zwischen User- und Kernelspace zu transferieren, als Speicher bereitsteht. Das stellt die Minimum-Funktion sicher.
Außerdem muss der Modulprogrammierer ständig darauf gefasst sein, einen Anwender vor sich zu haben, der durch falsche Adressenangaben versucht Speicherbereiche des Kernels zu überschreiben. Die Transferfunktion »copy_from_user()« achtet allerdings auch darauf und kopiert nur von unbedenklichen Speicheradressen.
Listing 3 zeigt eine Erweiterung des Proc-Datei-Beispiels um eine Schreibfunktion. Sie erlaubt es, durch Schreiben des Schlüsselworts »deutsch« in die Proc-Datei den beim Lesezugriff zurückgegebenen String auf die deutsche Variante »Hallo Welt« umzuschalten. Wird »english« auf die Proc-Datei geschrieben, erscheint beim nächsten Lesen wieder das Original »Hello World« .
Listing 3
Erweiterte Proc-Datei
01 static ssize_t prochello_write( struct file *instanz,
02 const char __user *buffer, size_t max_bytes_to_write,
03 loff_t *offset )
04 {
05 ssize_t to_copy, not_copied;
06
07 to_copy = min( max_bytes_to_write, sizeof(kernel_buffer) );
08
09 not_copied = copy_from_user(kernel_buffer,buffer,to_copy);
10 if (not_copied==0) {
11 printk("kernel_buffer: \"%s\"\n", kernel_buffer);
12 if (strncmp( "deutsch", kernel_buffer, 7)==0) {
13 output_string = TEXT_GERMAN;
14 }
15 if (strncmp( "english", kernel_buffer, 7)==0) {
16 output_string = TEXT_ENGLISH;
17 }
18 }
19 return to_copy - not_copied;
20 }
Allerdings bedarf es neben der Eingabe des Codes von Listing 3 am Originalcode noch weiterer Änderungen. Erstens muss der Programmierer die Schreibfunktion in die Datenstruktur aufnehmen. Dafür ergänzt er die Struktur »file_operations prochello_fops« um die Zeile:
write = prochello_write,
Außerdem ist noch der schreibende Zugriff zu erlauben. Dazu sind die Zugriffsrechte beim Aufruf von »proc_create_data« anzupassen: statt »S_IRUGO« gilt »S_IRUGO | S_IWUGO« .
Zuletzt müssen noch im Programmkopf vier Zeilen ergänzt werden:
#include <asm/uaccess.h> static char kernel_buffer[256]; #define TEXT_GERMAN "Hallo Welt" #define TEXT_ENGLISH "Hello World"
Mit diesen Änderungen sollte nach dem Kompilieren, dem Entladen der alten Modulversion und dem Neuladen des Treibers auch der schreibende Zugriff möglich sein.
Der Code für die Implementierung von Proc-Dateien eignet sich gut als Template für eigene Entwicklungen. Im Wesentlichen sind dabei der Name der Proc-Datei und die Show-Funktion anzupassen. Wer umfangreiche und sich häufig ändernde Ausgaben hat, sollte sich eher mit den Sequencefiles beschäftigen. Frühe Kern-Technik-Folgen zu diesem Thema sind als Leitfaden leider nur noch bedingt geeignet (siehe Kasten “Änderungen mit Kernel 3.10”). (jcb)
76
Änderungen zu Kernel 3.10
Kernel ab 3.10 unterstützen die Funktion »create_proc_entry()« nicht mehr:
proc_file = create_proc_entry("example_file", S_IRUGO, proc_dir );
if (proc_file) {
proc_file->read_proc = proc_read;
proc_file->data = NULL;
}
Stattdessen verwenden Programmierer die hier vorgestellte Funktion »proc_create_data()« “, die allerdings anders parametrisiert wird. Während in früheren Kernelversionen einzelne Elemente der Datenstruktur »proc_dir_entry« initialisiert werden mussten, reserviert der Entwickler in einer aktuellen Kernelversion die bereits aus der Treiberprogrammierung bekannte Struktur »struct file_operations« und weist dieser die Zugriffsmethoden (»open()« , »read()« , »release()« ) zu:
static struct file_operations example_proc_fops = {
.owner = THIS_MODUL,
.open = example_proc_open,
.read = example_proc_read,
.release = example_proc_release,
}[...]
static int __init example_proc_init(void)
{
proc_file = proc_create_data( "example_file, S_IRUGO, proc_dir,
&example-proc_fops, NULL );[...]
Damit unterscheiden sich nun allerdings auch die Zugriffsmethoden »read()« und »write()« im Vergleich zu früheren Versionen. Der einstige Parameter »peof« , der früher signalisierte, dass das System zu diesem Zeitpunkt alle Daten gelesen hat, existiert nun nicht mehr. Die aktuelle Variante schreibt dagegen die Daten an die als Parameter übergebene Speicheradresse und gibt anschließend die Anzahl der geschriebenen Zeichen zurück (falls nicht ohnehin – wie im Artikel beschrieben – das Singlefile verwendet wird).
Infos
- Quade, Kunst, “Kern-Technik, Proc-Filesystem und Sequence-Files”: Linux-Magazin 02/2004
- Quade, Kunst, “Kern-Technik, Watchdog”: Linux-Magazin 05/2009





