Ausgabe April 2005

Artikel

Linux hat sich als Betriebssystem für Embedded-Geräte längst etabliert - nicht zuletzt, weil die Hersteller von der Vorarbeit der Community profitieren und Entwicklungszeit sparen. Doch manche Firmen nehmen die GPL nicht allzu genau und erschweren den Zugang zu den Quellen.
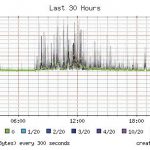
Das Ausbleiben oder übermäßige Verzögerungen von Ping-Antworten können ein Hinweis auf drohende Serverprobleme sein. Damit sie den Admin nicht mit Fehlalarmen aufschreckt, muss rein auf Ping gestützte Überwachungssoftware feinkörnig konfigurierbar sein - so wie Smokeping.

Selbst die besten Programmierer machen Fehler - immer wieder. Je nach Erfahrung des Entwicklers, Komplexität des Projekts und Wichtigkeit des Endprodukts bedarf es unterschiedlicher Debugging- und Testmethoden sowie geeigneter Tools.

Ende Januar fand in Köln die Security-Konferenz IT-Defense 2005 statt. Prominente Vortragende wie Marcus J. Ranum, der als Vater der Firewall gilt, und Nessus-Projektleiter Renaud Deraison sprachen über aktuelle Entwicklungen in der IT-Sicherheit. Die Vorträge waren zwar interessant und...

Trotz SCO ist und bleibt Microsoft der Lieblingsfeind der Linux-Menschheit. Dabei gibt es doch genug Firmen, die sehr durchschnittliche Software unter rückständigen Lizenzen produzieren und vermarkten. Doch gelegentlich gibt es auch Positives zu berichten. So bekam der deutsche Ableger des...

HA und VPN behindern sich: Die Verschlüsselung und Signatur von IPsec unterbindet viele der Tricks, die High-Availability-Produkte üblicherweise anwenden. Unter bestimmten Voraussetzungen gelingt der Spagat dennoch, ohne die Sicherheit des VPN auszuhebeln.

Wer Programme schreibt, baut ahnungslos oft auch gut versteckte Bugs ein. Die richtigen Tools und etwas Geduld vereinfachen das Debugging. Dieser Workshop erklärt die Grundlagen der Fehlersuche und vermittelt den Umgang mit dem prominentesten Vertreter der Gattung, dem GNU-Debugger GDB.

Jeder sorgfältige Admin erstellt Backups aller wichtigen Daten. Die Auswahl des richtigen Mediums ist nicht der einzige Knackpunkt. Benutzer wollen schließlich nach einem Crash so schnell wie möglich weiterarbeiten. Einige leicht verständliche Konzepte helfen bei der Strategiewahl.

Sicherheit in Computernetzen ist eine diffizile Angelegenheit, darüber schreiben nicht minder. Das Linux- Magazin stellt drei Bücher vor, die sich daran versuchen.

Fast jedes Skript oder Programm öffnet und bearbeitet Dateien. Dieser Workshop zeigt, wo die Gefahren lauern, und erklärt Admins und Entwicklern, wie sie Fehler schon an der Wurzel neutralisieren.

Statische Gerätedateien sind angesichts aktueller Hardware nicht mehr zeitgemäß. So erfordert Hotplugging an USB- und anderen Bussen dynamisches Gerätehandling. DevFS erfüllt zwar viele Ansprüche an eine solche Lösung, wird aber nun von Udev abgelöst.

Wie dienstbare Geister verwalten Router den Zugang zu Internet und WLAN. Die Firmware der stillen Diener ist immer öfter ein Linux-System, das diese Geräte für eigene Anpassungen öffnet.

Gründe, Windows- durch Linux-Server zu ersetzen, sind schnell gefunden. Dank Samba fühlt sich Linux auch in vorhandenen Domänen wohl. Nur für den Admin wird das Leben schwerer, denn viele Komponenten führen ein Eigenleben - ein Umstand, den UCS zu beseitigen trachtet.

Häufig müssen Programme strukturierte Eingabedateien verarbeiten und verstehen. Komplizierte Dateiformate erfordern dabei hohen Programmieraufwand - oder den Einsatz eines Parsergenerators. JavaCC deckt die wichtigsten Aspekte der Parsergenerierung für Java-Programme ab.

Es gibt nicht besonders viele Linux-Groupwareserver, die bei Bedarf hunderttausende Mailboxen verwalten. Zwei bedeutende Vertreter ähneln sich zudem stark - kein Wunder, stammen doch beide direkt von HP Openmail ab. Doch jetzt driften sie auseinander.
| LINUX-MAGAZIN KAUFEN | ||
|---|---|---|
| EINZELNE AUSGABE | Print-Ausgaben | Digitale Ausgaben |
| ABONNEMENTS | Print-Abos | Digitales Abo |
| TABLET & SMARTPHONE APPS |  Bald erhältlich |  Deutschland |
