
www.photocase.com
Journaling-Dateisysteme versprechen, ihre Integrität auch bei Systemausfällen zu bewahren – tatsächlich klappt das aber nur unter bestimmten Bedingungen. Zuerst muss der Admin dafür sorgen, dass die Voraussetzungen stimmen.
Das Dateisystem hat keinen spektakulären Job: Unzählige Male im Computerleben besorgt es seinem Rechner Daten oder legt sie für ihn ab. Dabei malocht es beharrlich, aber kaum beachtet im Hintergrund – zumindest, solange nichts passiert. Im Fehlerfall nämlich offenbart sich sofort: Alles hängt von ihm ab, oh-ne seine Dienste ist der PC ein hilfloser Haufen Blech. Spätestens jetzt ist der Admin gut beraten, der weiß, wie die Datenablage hinter den Kulissen genau zu Werke geht.
Dieses Wissen kann man leicht schnel-ler benötigen, als einem lieb ist. So hatte der Autor auf seinem IBM ThinkPad T23 mit Kernel 2.6.16, XFS und aktiviertem Schreibpuffer der Festplatte mit drei Da-teisystem-Crashes innerhalb einer Woche zu kämpfen [1]. Bei deaktiviertem Schreibcache gab es mit dem gleichen Kernel keinerlei Probleme – frühere Kernelversionen waren allerdings auch mit Schreibpuffer stabil gelaufen. Schließlich brachte ein neuer Kernel 2.6.17 und dessen Write-Barrier-Funktionalität die Stabilität zurück. Dieser Beitrag erklärt, was es mit den hilfreichen Schreibbarrieren auf sich hat.
So funktioniert Journaling
Journaling-Dateisysteme, zu denen auch das XFS im Beispiel gehört, bieten ihren Daten eine besondere Lebensversicherung, indem sie über jedwede Änderung penibel Buch führen.
Dabei kann man grundsätzlich zwei Vorgehensweisen unterschieden: Metadaten-Journaling garantiert die Konsistenz der Dateisystem-Struktur, während das langsamere Daten-Journaling (oder Full Journaling) auch die Konsistenz der Dateiinhalte gewährleistet (siehe Kasten “Daten-Journaling”). Unter Metadaten versteht man in diesem Zusammenhang alle Informationen über gespeicherte Dateien und Verzeichnisse wie Datei- und Verzeichnisnamen, Dateigrößen, Rechte und den Speicherort. Solche Informationen speichert das Dateisystem in speziellen Blöcken für Verwaltungsinformationen, den Inodes (siehe Artikel ab Seite 80).
|
Daten-Journaling |
|---|
|
Ein Journaling-Dateisystem, das nur Metadaten ins Journal aufnimmt, hat einen Nachteil: Nach einem abrupten Abbruch der Schreib-Aktivitäten enthalten Dateien nach unvollständigen Schreibvorgängen mitunter Müll [14]: So hatte das Dateisystem vielleicht weitere Datenblöcke für die Datei reserviert, bevor Schreibvorgänge in diese Blöcke abgeschlossen waren. Oder ein Schreibvorgang, der Daten in einer Datei überschreiben sollte, war noch aktiv. Ein Dateisystem mit Daten-Journaling schafft hier Abhilfe, indem es auch die eigentlichen Daten zuerst in das Journal schreibt. Bei einem unvorhergesehenen Abbruch stellt das Dateisystem anhand der Informationen aus dem Journal wieder einen konsistenten Zustand her, bei dem Metadaten und Daten in den Dateien zusammenpassen und einzelne Schreibvorgänge abgeschlossen sind oder nicht stattgefunden haben. Die Dateisystem Ext3, ReiserFS 3 und Reiser 4 unterstützten Daten-Journaling. XFS und JFS hingegen bislang nicht. Schreibvorgänge sind bei aktiviertem DatenJournaling deutlich langsamer, da alle Schreibvorgänge doppelt stattfinden. Daten landen zuerst im Journal und erst dann am eigentlichen Punkt auf der Festplatte. Einzig Reiser 4 bietet die Möglichkeit, die Daten sofort an ihren Bestimmungsort zu schreiben und dabei ein wanderndes Journal über diese Daten zu legen [15]. Die Dateisysteme Ext3 und ReiserFS 3 bietet eine Zwischenlösung, welche ohne Daten-Journaling auskommt: Das Dateisystem schreibt die zur einer bestimmten Metadaten-Transaktion gehörenden Datenblöcke, bevor es die Transaktion in das Journal schreibt. Die neu reservierten Datenblöcke einer Datei enthal-ten damit immer gültige Daten. Ein nur halb vollendeter Vorgang, der Daten in einer Datei überschreibt, hinterlässt allerdings immer noch einen inkonsistenten Zustand. Selbst beim Daten-Journaling sind Anwendungsdaten nicht automatisch sicher, falls der Schreibprozess ein abruptes Ende findet. Deshalb verfügen viele Datenbanken und Server-Programme wie Mailserver über eigene Me-chanismen, um auch bei einem Systemab-sturz oder Stromausfall die Integrität der Daten zu gewährleisten. Dieses anwendungsbezogene Daten-Journa-ling basiert in der Regel ebenfalls darauf, Daten in einer bestimmten Reihenfolge zu schreiben und auf unteilbare Schreibvorgän-ge zurückzugreifen. Einen anderen Weg schlagen Programme wie die KDEPIM-Anwendungen KAddressBook, KOrganizer und Akkregator ein. Sie legen von wichtigen Dateien selbständig Backups an. |
Wird das Dateisystem beim Ändern der Metadaten unterbrochen, gerät es leicht in einen inkonsistenten Zustand, weil die meisten Änderungen aus mehreren Schritten bestehen, die nun womöglich erst zur Hälfte absolviert wurden. So muss das Dateisystem beim Anlegen eines neuen Files einen Verzeichniseintrag erstellen, Speicherplatz reservieren, die Daten schreiben und sich ihren Ablageort merken. Bei einem abrupten Abbruch ist nun vielleicht der Speicherplatz der Datei reserviert, allerdings kein Verzeichniseintrag erstellt, oder umgekehrt, je nachdem, welche Informationen es noch auf die Festplatte geschafft haben.
Ein Dateisystem ohne Journal-Funktion weiß nach dem Neustart nur, dass es nicht ordentlich abgemeldet wurde. Ob die Metadaten durcheinander geraten sind, muss in diesem Fall ein spezialisiertes Programm wie »fsck« überprüfen. Bei großen Dateisystemen mit vielen Verzeichnissen sowie Dateien kann das sehr lange dauern.
Atomisch schreiben
Ein Journaling-Dateisystem hingegen schreibt die Änderungen für einen kompletten Vorgang wie das Anlegen einer Datei zunächst als eine Transaktion in sein Journal (Abbildung 1). Eine Transaktion ist ein atomischer, also unteilbarer Vorgang, der zwei Zustände kennt: komplett abgeschlossen oder nicht stattgefunden. Ist eine Transaktion vollständig, markiert das Dateisystem sie in einem unteilbaren Schreibvorgang.
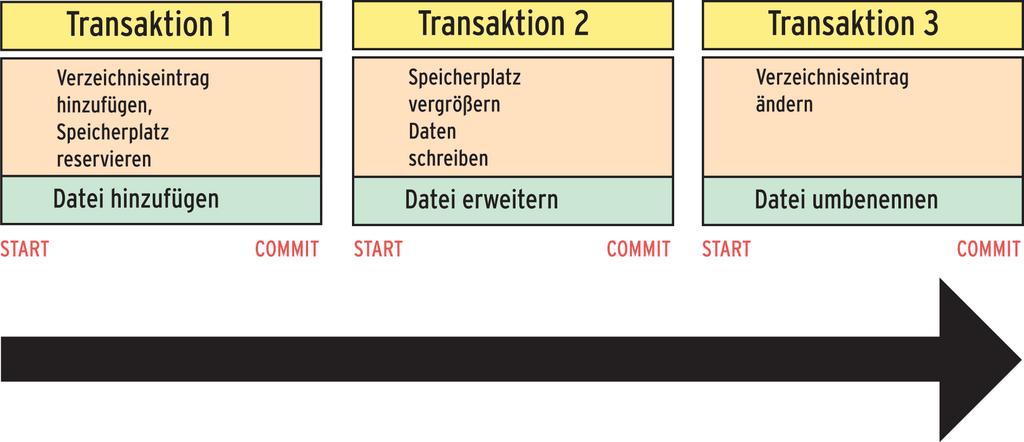
Abbildung 1: Das Dateisystem schreibt einzelne Transaktionen hintereinander in das Journal. Vollständige geschriebene Transaktionen markiert es in einem unteilbaren Schreibvorgang.
Für das Journal gibt es zwei grundlegende Speicherformate: Ein physisches Journal, wie es Ext3 verwendet, nimmt komplette Blöcke mit Metadaten auf. Das Dateisystem Ext3 greift dabei auf das Journal Block Device (JBD) zurück [2]. Ein Dateisystem mit einem logischen Journal, wie XFS, ReiserFS 3 oder JFS, speichert Metadaten hingegen in einem eigenen, kompakteren Format.
Wird ein Journaling-Dateisystem nach einem abrupten Abbruch der Schreib-operationen erneut gemountet, versucht es, anhand der Informationen im Journal einen konsistenten Zustand herzustellen: Ist eine Transaktion wie das Anlegen einer Datei im Journal unvollständig, dann verwirft das Dateisystem sie. Ei-ne abgeschlossene Transaktion geht es Schritt für Schritt durch. Dabei prüft es, welche Änderungen schon auf dem Datenträger gelandet sind. Bislang ungeschriebene Änderungen holt es nun nach. Erst wenn alle Änderungen wirklich sicher auf dem Datenträger angekommen sind, markiert es die Transaktion als erledigt und gibt deren Speicherplatz im Journal wieder frei.
Beschleunigtes Recovery
Da das Dateisystem nur die gespeicherten Journal-Einträge durchgehen muss, anstatt die gesamte Metadaten-Struktur zu überprüfen, benötigt es für diesen Recovery-Prozess in der Regel nicht länger als einige Sekunden. Wird das Da-teisystem beim Recovery-Prozess erneut unterbrochen, macht es beim nächsten Mal einfach bei der letzten unerledigten Transaktion weiter.
Reihenfolge von Schreibvorgängen
Dieses Vorgehen garantiert nicht, dass nach einem Abbruch tatsächlich sämt-liche Änderungen abgespeichert sind. Die Konsistenz der Dateisystem-Struktur ist allerdings jederzeit gewährleistet, wenn die Schreibvorgänge in der richtigen Reihenfolge stattfinden: Als Erstes schreibt das Dateisystem die Transaktion in das Journal, dann führt es die dazugehörigen Metadaten-Änderungen aus, und erst danach markiert es die Transakti-on als erledigt.
Landen Metadaten-Änderungen hingegen vor dem Journal-Eintrag auf dem Datenträger und bricht der Vorgang anschließend abrupt ab, dann findet das Dateisystem beim Recovery-Prozess kei-ne Informationen darüber im Journal. Das Dateisystem ist in einem inkonsisten Zustand und bedarf einer Reparatur. Im Fall von Transaktionen, welche als erledigt markiert sind, obwohl die Metadaten-Änderungen nicht komplett auf den Datenträger gelangten, ergeben sich ähnliche Probleme.
Das Dateisystem muss daher sicherstellen, dass alle Änderungen immer in einer bestimmten Reihenfolge ablaufen. Aber das ist bei Laufwerken mit Schreibpuffer nicht gewährleistet. Denn eine Festplatte mit aktiviertem Puffer nimmt zu schreibende Daten zunächst einmal in diesen Zwischenspeicher auf, der zwischen dem schnellen RAM und der langsamen Mechanik der Festplatte vermittelt. Dann entscheidet die Firmware der Platte, in welcher Reihenfolge die Inhalte des Schreibpuffers auf den Datenträger kommen (Abbildung 2).
![Abbildung 2: Die Reihenfolge der Schreibvorgänge ist bei aktiviertem Schreibpuffer ohne weitere Maß-nahmen nicht steuerbar [3].](https://www.linux-magazin.de/wp-content/uploads/2007/06/abb2_jpg-16.jpg)
Abbildung 2: Die Reihenfolge der Schreibvorgänge ist bei aktiviertem Schreibpuffer ohne weitere Maß-nahmen nicht steuerbar [3].
Um dennoch die richtige Reihenfolge zu gewährleisten, existieren zwei Verfahren: Im ersten Fall weist das Dateisystem den Treiber an, vor sowie nach dem Schreiben einer Transaktion durch einen Cache Flush den Puffer zu leeren.
|
Alternative |
|---|
|
Neben dem Journaling gibt es alternative Ansätze, um die Integrität des Dateisystems zu bewahren. Soft-Updates: Anstatt die Metadaten im Journal zu duplizieren, ordnet das Dateisystem die Schreibvorgänge mit Blick auf die Metadaten so an, dass die Integrität des Dateisystems im-mer gewährleistet ist. Diese erstmals für Free- BSD eingeführte Technologie ist mittlerweile auch für andere BSD-Varianten verfügbar [16]. Persistente Schreib-Caches und unterbrechungsfreie Stromversorgung: Der Controller oder Treiber speichern zu schreibende Daten zunächst in einem nicht-flüchtigen Speicherbereich, zum Beispiel in einem NVRAM. Bei einem abrupten Abbruch ist dann durch eine Stromreserve genügend Zeit vorhanden, um die Daten noch auf den Datenträger zu schreiben. Verschiedene RAID-Controller und die Storage-Appliance Fabric Attached Storage (FAS), auch Filer, von Netapp arbeiten mit dieser Technologie [17]. Log-strukturierte Dateisysteme: Das ganze Dateisystem ist ein Journal – daher ist es nicht nötig, Metadaten und Daten doppelt zu schreiben [18]. Das DVD-Dateisystem UDF fällt in diese Kategorie. Reiser 4 oder WAFL (Write Anywhere Layout), das die Storage-Appliance NetApp FAS nutzt, verwenden einige Ansätze aus diesem Bereich [15]. |
Schreibbarrieren
Im zweiten Fall verwendet das Dateisystem die Write-Barrier-Funktionalität des Kernels, um Schreibzugriffe in eine geeignete Reihenfolge zu bringen [4]. Ein Barrier Write Request weist den Blocklayer von Linux an, beim Schreiben die folgende Reihenfolge einzuhalten: Alle Write Requests vor dem Barrier Request landen zuerst in beliebiger Reihenfolge auf der Platte, daraufhin folgt der Bar-rier Request, und erst dann gelangen alle Write Requests nach dem Barrier Request wiederum in beliebiger Reihenfolge auf den Datenträger.
Dieser Ansatz hat zwei entscheidende Vorteile: Zum einen ist kein sofortiger Cache Flush nötig, sondern erst direkt vor dem Barrier Request. Zum anderen kann es der Treiber intelligenten Speicher-geräten ganz oder teilweise selbst überlassen, die Reihenfolge der Requests zu bestimmen. Der Blocklayer des Kernels unterscheidet Laufwerke dabei nach den zwei Kriterien, nämlich der Reihenfolge der Requests und der Art des Schreib-puffers (siehe Kasten “Unterschiedliche Geräteklassen”). So benötigen Laufwer-ke mit Forced Unit Access nach dem Barrier Request keinen Cache Flush.
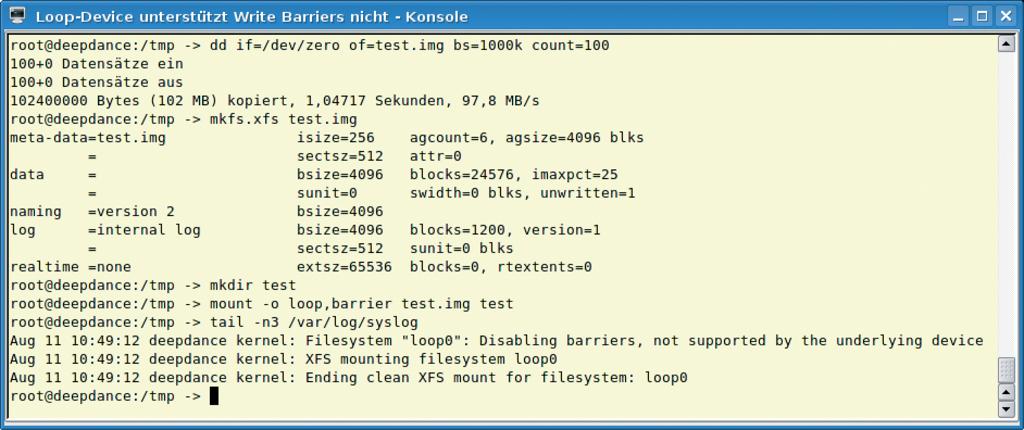
Abbildung 3: Zumindest bis Kernel 2.6.17.7 unterstützt das Loop-Device keine Write Barriers und eignet sich daher, sich die Fehlermeldungen der Dateisysteme anzuschauen.
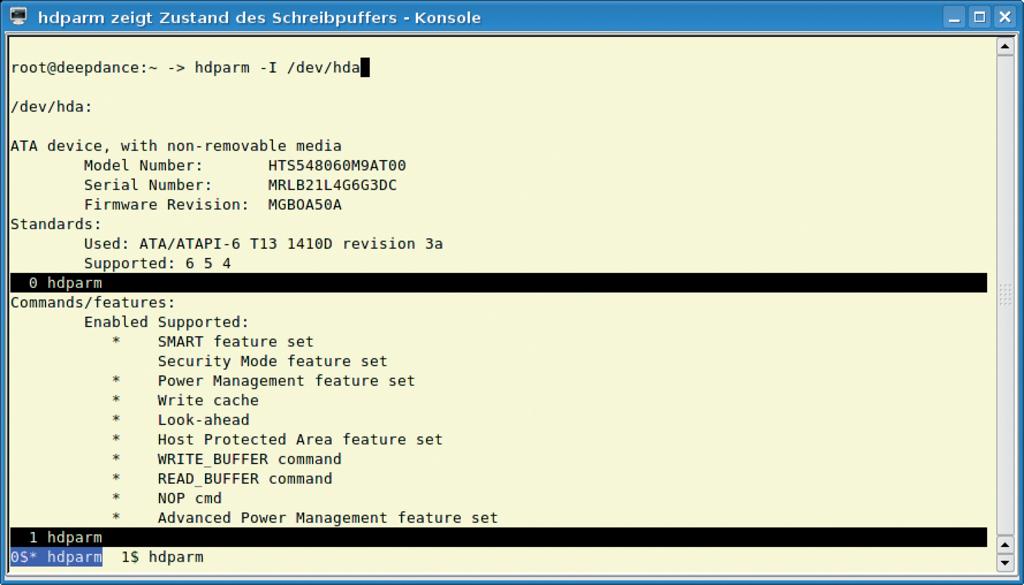
Abbildung 4: Der Befehl »hdparm« zeigt, ob der Schreibpuffer der Festplatte eingeschaltet ist.
|
Unterschiedliche |
|---|
|
Die Write-Barrier-Funktionalität im Block-Lay-er stellt eine bestimmte Reihenfolge beim Abarbeiten von IO-Requests sicher. Barrier Requests benötigen aus diesem Grund zwei Eigenschaften [3]: Reihenfolge der RequestsHierbei kann man folgende Varianten unterscheiden: 1) Geräte mit Support für mehrere Requests in einer Queue sowie für geordnete Requests (TCQ-Geräte) – zum Beispiel moderne SCSI-Controller und Laufwerke: Der Block-Layer gibt den Barrier Request als geordneten Request weiter. Low-Level-Treiber, Controller und Laufwerk sind dafür verantwortlich, die korrekte Reihenfolge einzuhalten. TCQ steht dabei für Tagged Command Queueing, die Fähigkeit, von Laufwerken, mehrere Requests in eine Warteschlange (Queue) einzureihen. Diese Möglichkeit ist derzeit unter Linux nicht aktiv, da das SCSI-Subsystem bin hin zu Kernel 2.6.17 ei-nen Request in der Dispatch-Funktion nicht atomisch an den SCSI-Controller weitergibt. Die Reihenfolge der Requests kann sich dadurch ändern. 2) Geräte mit Support für mehrere Requests in einer Queue, jedoch nicht für geordnete Requests – das betrifft ältere SCSI-Controller und Laufwerke sowie SATA-Laufwerke: Der BlockLayer stellt die richtige Reihenfolge sicher. 3) Geräte, die einen Request nach dem anderen entgegennehmen – sehr alte SCSI-Geräte und IDE-Laufwerke: Auch hier stellt der BlockLayer die geeignete Reihenfolge sicher. Schreibpuffer (Write Cache)Mit Blick auf den Write Cache kann man folgende Fälle unterscheiden: 1) Kein Schreibpuffer: Es reicht, die Anforderungen in die geeignete Reihenfolge zu bringen. 2) Schreibpuffer (Writeback Cache), jedoch keine Cache Flushes: Hier gibt es keine Garantie der richtigen Schreib-Reihenfolge, daher ist kein Support für Write Barriers möglich. Solche Laufwerke funktionieren mit Journaling-Da-teisystemen bei abrupten Unterbrechungen nur dann stabil, wenn der Schreibpuffer ausgeschaltet ist. 3) Schreibpuffer und Cache Flushes, aller-dings keine Force Unit Accesses (FUA): Das Block-Subsystem löst vor und nach dem Barrier Request einen Cache Flush aus (Abbil-dung 5). 4) Schreibpuffer, Cache Flushes und Forced Unit Accesses (FUA): Der Block-Layer löst vor dem Barrier Request einen Cache Flush aus. Den Barrier Request gibt es als FUA Request weiter. FUA steht für Forced Unit Access und weist das Laufwerk an, den Request sofort auf den Datenträger zu schreiben und dabei den Schreibpuffer zu umgehen (Abbildung 6). 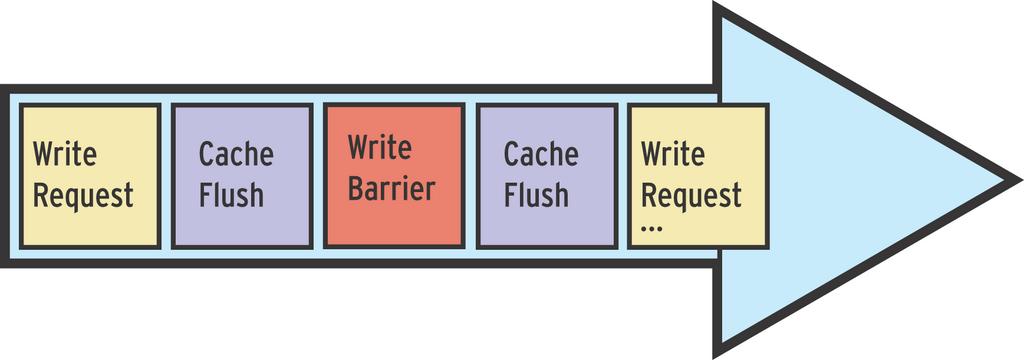 Abbildung 5: Ohne Forced Unit Accesses sind zwei Cache Flushes nötig, um die richtige Reihenfolge zu gewährleisten: vor und nach dem Barrier Request. 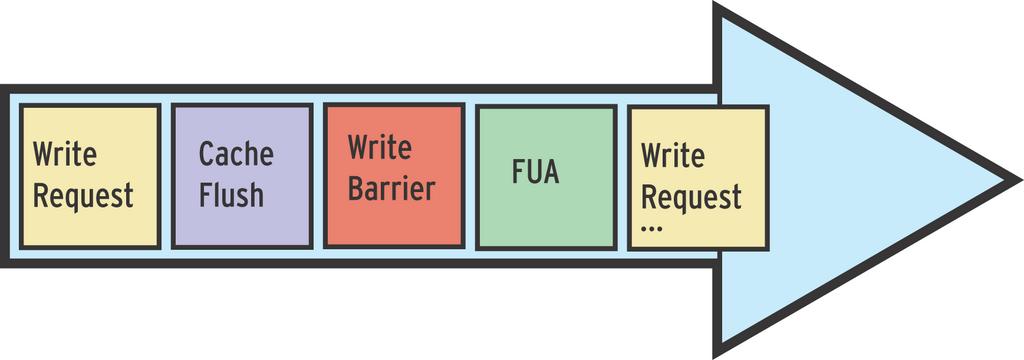 Abbildung 6: Forced Unit Access (FUA) ermöglicht es, den Cache Flush nach dem Barrier Request einzusparen. |
Praxis
Wer die Write-Barrier-Funktionalität nutzen möchte, der sollte eine relativ neue Kernelversion ab Version 2.6.16, für XFS besser ab 2.6.17.7, einsetzen. Ein erster Patch für Ext3 und ReiserFS 3 existiert zwar schon für Kernelversion 2.6.5, und offiziell ist Write-Barrier-Support – anfangs für Ext3 und ReiserFS 3 – ab Ker-nelversion 2.6.9 enthalten. Doch enthält Kernel 2.6.16 zahlreiche Änderungen und Korrekturen für die Write Barriers, und das Dateisystem XFS unterstützt sie erst ab Version 2.6.15 (siehe Tabelle “Write-Barrier-Historie”).
|
Tabelle 1: |
|||||
|---|---|---|---|---|---|
|
Funktionalität |
Ext3 |
ReiserFS 3 |
Reiser 4 |
XFS |
JFS |
|
Write Barriers |
barrier=1 |
barrier=flush |
Standard |
barrier (Standard ab 2.6.17) |
– |
|
Kein Write Barriers |
barrier=0 |
barrier=none |
– |
nobarrier |
– |
|
Daten-Journaling |
ordered=journal |
ordered=journal |
Standard (Wanderne Logs) |
– |
– |
|
Daten vor Metadaten |
ordered=data |
ordered=data |
– |
– |
– |
|
Writeback-Modus |
ordered=writeback |
ordered=writeback |
– |
Standard |
Standard |
|
Tabelle 2: |
||
|---|---|---|
|
Kernelversion |
Zeitpunkt |
Änderung |
|
2.6.5 |
März 2004 |
Erstes Write-Barrier-Patchset. Unterstützte Dateisysteme: |
|
2.6.9 |
Oktober 2004 |
Write-Barrier-Support für IDE, SCSI, MD, device mapper. |
|
2.6.10 |
Dezember 2004 |
Fix für Mount-Fehler mit Write Barriers bei SATA-Platten. |
|
2.6.12 |
Juni 2005 |
Write-Barrier-Unterstützung für DASD-Controller |
|
2.6.13 |
August 2005 |
Fix für Hänger des IO-Schedulers CFQ (Completely Fair |
|
2.6.14 |
Oktober 2005 |
MD/RAID unterstützt noch keine Write Barriers |
|
2.6.15 |
Januar 2006 |
Write-Barrier-Support für XFS Support für |
|
2.6.15.4 |
Februar 2006 |
Geordnete Schreibvorgänge mit Cache Flush für SCSI |
|
2.6.16 |
März 2006 |
Neuimplementation der Behandlung von Barrier Requests IDE/SCSI: |
|
2.6.17 |
Juni 2006 |
Write Barriers für XFS standardmäßvig |
Auch wer einen aktuellen Kernel verwendet, sollte recherchieren, ob seine Kombination aus Kernelversion, Treiber, Dateisystem, Controller sowie Laufwerk Write Barriers unterstützt.
Einige grobe Hinweise helfen hier bei der Orientierung: IDE-Laufwerke ohne Schreibpuffer, IDE-Laufwerke mit Cache Flushes, SCSI-Laufwerke ohne Schreibpuffer, SCSI-Laufwerke mit Cache Flu-shes sowie SCSI-Laufwerke mit Cache Flushes und FUA (Forced Unit Access) sollten mit Write Barriers funktionieren (siehe Kasten “Unterschiedliche Geräteklassen”). Mit dem Software-Raid MD/ RAID1 sollte es ebenfalls klappen, sofern sowohl der Controller als auch sämtliche Laufwerke Cache Flushes unterstützen. Andere RAID-Varianten werden bislang nicht unterstützt.
Notfalls ohne Cache
Von den Dateisystemen unterstützen Ext3, ReiserFS 3, Reiser 4 und XFS Write Barriers. Bei XFS ist diese Funktionalität ab Kernel 2.6.17 standardmäßig eingeschaltet. Reiser 4 verwendet Write Barriers – falls unterstützt – und ansonsten synchrone Schreiboperationen, also direkte Cache Flushes. JFS verwendet ausschließlich synchrone Schreiboperationen. Die anderen Dateisysteme und XFS vor 2.6.17 benötigen die explizite Angabe einer Mount-Option (siehe Tabelle “Mount-Optionen”).
Ein Blick auf das Systemprotokoll gibt beim Mounten eines Dateisystems mit aktivierter Write-Barrier-Funktionalitat Auskunft darüber, ob es geklappt hat. So gibt XFS je nach der Situation ei-ne von drei Fehlermeldungen aus, wenn es nicht klappt (Abbildung 3 und [5]). Das Journal Block Device, welches Ext3 verwendet, meldet: »JBD: barrier-based sync failed on %s – disabling barriers«. Die anderen Dateisysteme geben ähnliche Meldungen aus.
Ohne Write-Barrier-Funktionalität bewahren Journaling-Dateisysteme bei einem abrupten Abbruch der Schreibak-tivität oftmals lediglich dann tatsäch-lich ihre Integrität, wenn der Schreibpuffer des Datenträgers ausgeschaltet ist oder das Dateisystem Transaktionen synchron schreibt.
Der Befehl »hdparm -I /dev/hda« zeigt unter »Command/features« bei »Write cache« an, ob der Schreibpuffer gera-de aktiv ist (Abbildung 4). Der Befehl »hdparm -W0 /dev/hda« schaltet den Schreibpuffer aus, »hdparm -W1 /dev/hda« schaltet ihn ein, und »hdparm -i /dev/hda« gibt unter »WriteCache« ei-nen Hinweis auf die Standardeinstellung des Herstellers.
Laufwerken mit Schreibpuffer, welche keine Cache Flushes unterstützen, sind prinzipbedingt nicht in der Lage, eine bestimmte Reihenfolge beim Schreiben der Requests zu garantieren. Hier erhält der Anwender auch bei einem Journaling-Dateisystem nur dann eine höhe-re Sicherheit, wenn er den Schreibpuf-fer deaktiviert.
Controller und Laufwerke mit persistentem Schreibpuffer (NVRAM) benötigen in der Regel jedoch keinen Write-Barrier-Support, weil sie in der Lage sind, auch nach Absturz oder Stromausfall noch alle Daten auf das Medium zu schreiben. Der XFS-FAQ empfiehlt gar, Write Barriers für solche Geräte auszuschalten [6].
Turbo für XFS
Wer mit XFS ohne großen Aufwand eine höhere Geschwindigkeit bei Metadaten-Operationen, vor allem dem Löschen von vielen Verzeichnissen und Dateien, erreichen möchte, der mountet das Dateisystem zum Beispiel mit »logbufs=8« mit einer höheren Anzahl an Puffern für das Journal (standardmäßig 2, höchstens 8) [7].
Wer Kernel 2.6.17 mit XFS einsetzen möchte, der sollte mindestens Version 2.6.17.7 verwenden, da diese einen Fix für XFS enthält [10], [11], [12], oder diesen Patch manuell einspielen. Ohne diesen Patch können Dateisystem-Defekte entstehen, die sich mitunter mit der aktuellen Version von »xfs_repair« nicht reparieren lassen. Es gibt einen Patch, der das Problem beheben soll [13]. (jcb)
|
Der Autor |
|---|
|
Martin Steigerwald arbeitet als Systemadministrator bei der team(ix) GmbH in Nürnberg. Ein Schwerpunkt seiner Tätigkeit liegt dabei im Second-Level-Support für Linux als Business-Desktop bei Kunden von team(ix). Er hat Linux schon vor Jahren auf seinem Amiga 4000 installiert und nutzt es auch privat. Er schreibt auch für das “Amiga-Magazin”. |




