
© Juan Jose Tugores, 123RF
Mithilfe von Cgroups behalten Admins die Kontrolle über ihren Rechner. Nach mehreren Jahren der Entwicklung ist Version 2 reif für Produktivsysteme.
Ohne ordnende Hand herrschen Chaos und Anarchie: Im Computer streiten sich Tasks um Prozessorkerne, um Rechenzeit, um Hauptspeicher oder um Netzwerkbandbreite. Eine kleine Fork-Bombe hier, ein aktiver Memory-Leaker dort, und das System ist nicht mehr zu gebrauchen – wäre da nicht das eingebaute Ressourcen-Management als Kernaufgabe des Betriebssystems.
Ein pfiffiges Ressourcen-Management verhindert nicht nur den versehentlichen oder absichtlichen Missbrauch, sondern ermöglicht die optimale Nutzung sämtlicher Betriebsmittel. Neben den seit Jahrzehnten vorhandenen Unix-Mechanismen (wie zum Beispiel Ulimit) hat Linux zur dedizierten, fein abgestuften Verteilung die Cgroups (Control Groups) implementiert. Zunächst 2008 in Version 1 erschienen, stellt der Linux-Kern seit 2016 eine überarbeitete Version 2 zur Verfügung (Kasten “Eins gegen Zwei”).
Eins gegen Zwei
Controller Groups der Version 2 sollen Version 1 beerben. Eine neue Version mit geändertem Interface war notwendig, weil sich Cgroups in der ersten Version in der Praxis als schwer zu verwalten zeigten. Das Konzept, für jeden Controller-Typ einen eigenen Management-Baum aufzubauen, ist zwar flexibel [5], aber auf der anderen Seite höchst unübersichtlich [6]. Zudem ist jeder Controller unabhängig implementiert, was zu inkonsistenten Interfaces führte, mit zusätzlich unterschiedlichem Verhalten.
In der alten Version erbt die neu angelegte Gruppe mal die Attribute der Elterngruppe, mal wird sie mit Default-Werten ausgestattet. Der eine Controller-Typ legt spezifische Konfigurationsdateien in der Wurzel des Baums ab, der andere nicht. Version 2 dagegen wirbt mit seiner “unified hierarchy”, einem einheitlichen hierarchischen Modell, bei dem jeder Prozess zu genau einer Gruppe gehören kann. Namen und Werte der Interface-Dateien inklusive Vererbungsstrategien sind einheitlich definiert und dokumentiert.
Ein weiterer Vorteil der Version 2: Die Kernel-Entwickler haben eine Schnittstelle zu den programmierbaren eBPFs (Berkeley Packet Filters) gebaut, die in modernen Systemen die Firewall realisieren. Mit Cgroup v2 wird darüber das Erzeugen und Verwenden von Gerätedateien kontrolliert.
Bei den Cgroups werden Rechenprozesse in Gruppen eingeteilt, und den einzelnen Gruppen werden Ressourcen zugeordnet (Abbildung 1). Während sich in der Version Cgroup-v1 ein Rechenprozess unterschiedlichen Gruppen zuordnen ließ, ist Cgroup v2 in diesem Punkt stringenter: Ein Job gehört genau einer Gruppe an. Die Gruppen selbst sind hierarchisch organisiert, also baumartig. Der Admin teilt eine Gruppe in Untergruppen und eine Untergruppe in Unter-Untergruppen – wenn er es denn für sinnvoll hält.
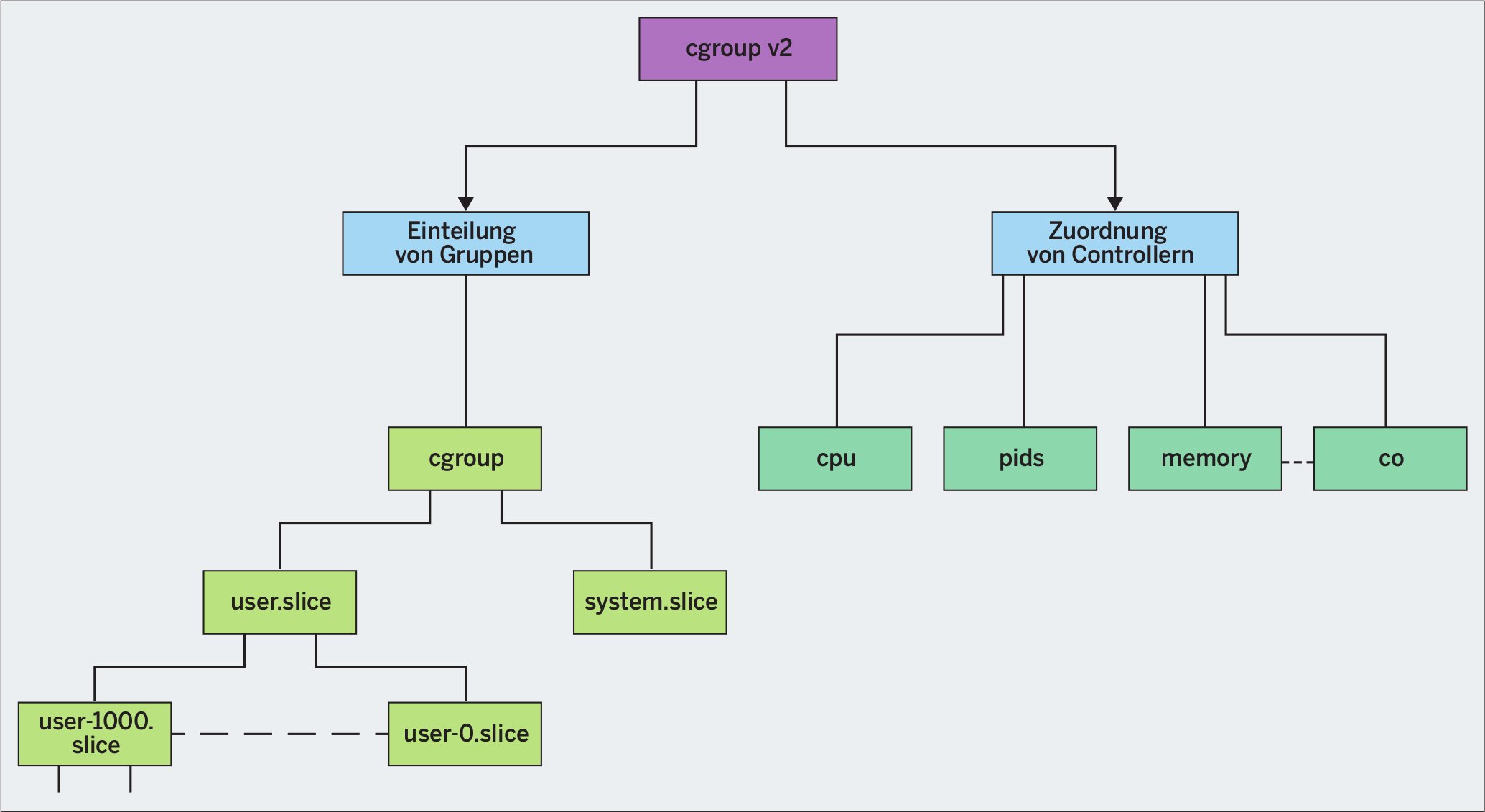
Abbildung 1: Die Einteilung von Gruppen und Verteilung von Ressourcen.
Beim Aktivieren von Cgroup v2 erstellt Ubuntu, oder besser der Dienst Systemd, standardmäßig zwei Gruppen. Die eine enthält alle Systemdienste, die andere die User-Programme [1]. In Analogie zur Pizza nennt sich das dann »system.slice« und »user.slice«. Unterhalb des »user.slice« legt Systemd für jeden eingeloggten User eine weitere Gruppe an, die die User-ID (UID) im Namen trägt. Der User mit der UID 1000 findet seine Jobs in der Gruppe »user-1000.slice«, der Superuser (root) in der Gruppe »user-0.slice«. Diese Unterteilung hat den charmanten Vorteil, dass der User unterhalb seines Verzeichnisses ohne Root-Rechte zugreifen und seine Tasks selbst verwalten kann.
Gemäß dem Motto “alles ist eine Datei” repräsentieren Linux-üblich Verzeichnisse und Dateien diese Hierarchie (Abbildung 2), was einen einfachen Zugriff ermöglicht. Das Basisverzeichnis auf einem Ubuntu-System liegt im virtuellen Sys-Filesystem und heißt »/sys/fs/cgroup/«. Der komplette Pfad zur Gruppe des Users mit der ID 1000 lautet »/sys/fs/cgroup/user.slice/user-1000.slice/«.

Abbildung 2: Cgroups konfiguriert der Admin über das Sys-Filesystem.
In den Verzeichnissen wiederum finden sich reihenweise (virtuelle) Dateien, die zum einen einen Überblick über die aktuelle Ressourcenlage bieten und zum anderen das Konfigurieren der Ressourcenverteilung ermöglichen. Die Datei »cpu.stat« beispielsweise listet die von der Gruppe verbrauchte Rechenzeit in Mikrosekunden auf. Die Datei »memory.stat« informiert über den zurzeit von der Gruppe belegten Hauptspeicher. Um zu sehen, welche Jobs der aktuellen Gruppe zugeordnet sind, liest der Admin die Datei »cgroup.procs« aus.
Doch Achtung: Um Redundanzen zu vermeiden, enthält nur die jeweils unterste Ebene (die Blätter des Baums) die Prozess-IDs. Über das Kommando aus Listing 1 kann der neugierige User herausfinden, in welcher Gruppe sich die Shell befindet, von der aus er den Befehl abgesetzt hat.
Listing 1
Gruppe der Shell ermitteln
$ find /sys/fs/cgroup/ -name cgroup.procs -execdir grep $$ {} \; -print
Die Datei »/sys/fs/cgroup/user.slice/cgroup.procs« enthält keine Einträge, da sie nicht in einem Blatt des Baums verortet ist. Die Datei »/sys/fs/cgroup/user.slice/user-1000.slice/user@1000.service/dbus.service/cgroup.procs« hingegen listet beispielsweise auf einem Testsystem neun Jobs, die zur Gruppe »dbus.service« gehören.
Verschafft sich der Admin durch Lesezugriffe auf Verzeichnisse und Dateien einen Überblick über die aktuelle Verteilung, kann er die Betriebsmittel durch Schreibzugriffe konfigurieren. Um beispielsweise einen Job einer Gruppe zuzuteilen, schreibt er die zum Job gehörende PID in die Datei »cgroup.procs« im zur Gruppe gehörenden Verzeichnis (unterste Ebene).
Controller
Die Ressourcen selbst werden bei Cgroup v2 über sogenannte Controller verwaltet. Der Kernel bietet mit »cpuset«, »cpu«, »io«, »memory«, »pids«, »rdma«, »hugetbl« und »device« einen Reigen unterschiedlicher Verwaltertypen an. Jeder Controller informiert den Admin über den aktuellen Stand und erlaubt gleichzeitig, die Regler anzupassen.
Der Controller »cpu« hilft dem Admin, die zur Verfügung stehende Rechenzeit zu verteilen, die er dazu in Mikrosekunden angibt. Er kann für die in einer Gruppe zugeordneten Tasks weiche Grenzen setzen und – so er denn Root-Rechte besitzt – auch harte. Der Admin spezifiziert die nutzbare Rechenzeit durch Angabe einer Zeit X, die in einem Zeitintervall Y zur Verfügung steht.
Der Controller »pids« hat die simple Aufgabe, die Anzahl der Jobs innerhalb einer Gruppe zu limitieren und dadurch unter anderem eine klassische Fork-Bombe zu verhindern. Gemäß Modell landen neu erzeugte Jobs, sowohl in der Ausprägung als Threads als auch als Prozesse, in der Gruppe des Eltern-Tasks. Als bessere Alternative zum alten Kommando »ulimit -u« schreibt der Admin die Obergrenze in die Datei »pids.max«. Die Datei »pids.current« gibt die Anzahl der momentan in einer Cgroup befindlichen Prozesse an.
Der Controller »cpuset« ermöglicht das Zuordnen von Rechenkernen und Speicherknoten auf die Cgroup, sodass die zur Gruppe gehörenden Tasks nur auf die erlaubten Kerne und Knoten zugreifen können. Über die Datei »cpuset.cpus« ordnet der Admin die erlaubten Cores zu, über »cpusets.mems« die Speicherknoten.
Grenzstation
Der Controller »memory« ist wohl der komplexeste Controller. Unter seinen Fittichen lassen sich der Applikationsspeicher (Page Cache und Anonymous Memory), die Datenstrukturen im Kernel, beispielsweise für Zugriffe auf den Hintergrundspeicher (Dentries und Inodes), sowie die TCP-Socket-Buffer im Netzwerk-Stack verwalten.
Der Controller setzt das Modell der weichen und harten Grenzen um (Abbildung 3). So gibt es einen minimalen, einen niedrigen, einen hohen und einen maximalen Stand. Minimal und niedrig stehen initial auf 0, hoch und maximal auf »max«. Der Admin gibt die Grenzen in der Einheit Bytes an.
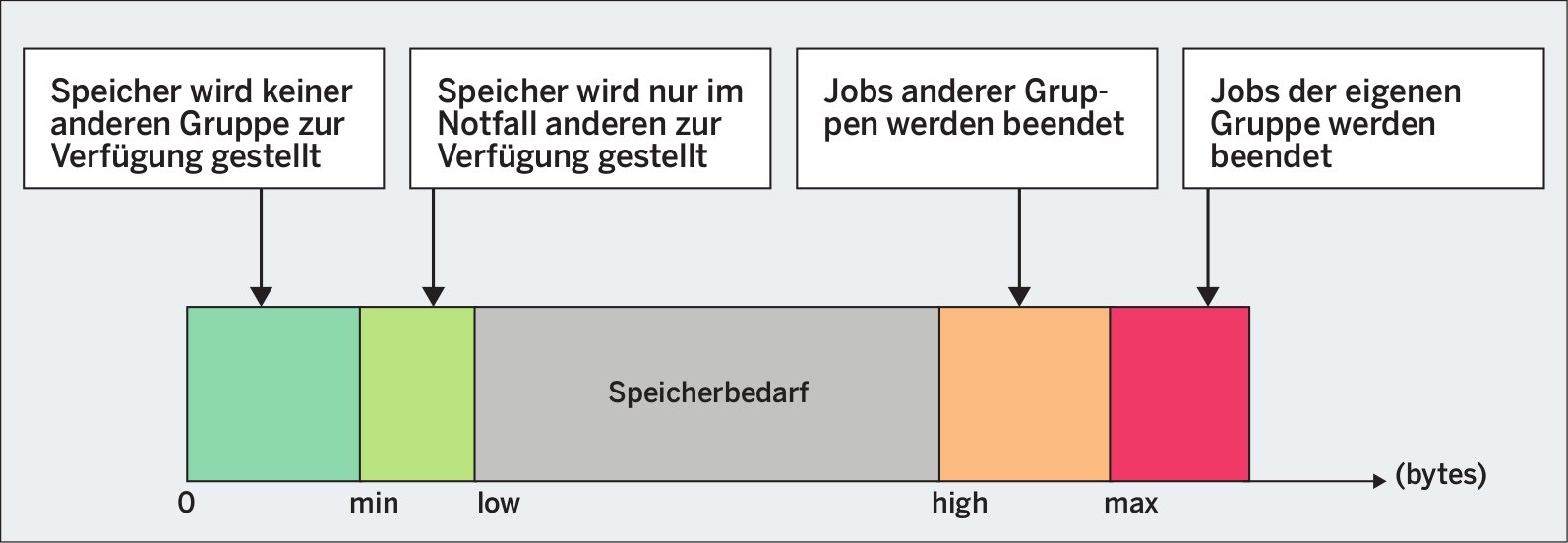
Abbildung 3: Weiche und harte Grenzen beim Memory-Controller.
Allerdings wird nicht jeder Wert akzeptiert, schließlich basiert die Speicherverwaltung auf Seiten (Pages). Insofern sind nur Angaben als Vielfaches von Pages (typischerweise 4096 Byte) valide. Erfreulicherweise nimmt der Kernel die Anpassung an die nächste Page selbstständig vor, falls der Admin einen Wert eingibt, der nicht dem Vielfachen einer Seite entspricht.
Ruhe sanft
Bei den Grenzen »min« und »max« handelt es sich um harte Grenzen. Braucht die Cgroup weniger Speicher, als durch »min« definiert, bleibt der Speicher dennoch der Applikation zugeordnet und wird keiner anderen Applikation zur Verfügung gestellt. Benötigt umgekehrt eine Cgroup mehr Speicher, als in »max« hinterlegt, aktiviert der Kernel den OOM-Killer, also die Einheit, die eine der Tasks in der Cgroup gnadenlos löscht.
Wird innerhalb der Cgroup die weiche Grenze »low« erreicht beziehungsweise unterschritten, erhält keine anderen Gruppe respektive Applikation Speicherseiten, solange eine andere Cgroup Speicher beansprucht, der nicht anderweitig reserviert werden kann. Ebenso wird bei Erreichen der Grenze »high« verfahren. In diesem Fall drosselt der Kernel die Rechenprozesse der Gruppe und fordert massiv Speicher zurück, allerdings ohne die Keule OOM-Killer hervorzuholen und die Jobs gleich abzuschießen.
Da der Kernel die Memory-Ressourcen für jede Gruppe getrennt verwaltet, kann es insbesondere bedingt durch die unteren Grenzen auch zu einem sogenannten Overcommitment kommen. Dabei werden mehr Ressourcen angefordert, als der übergeordneten Gruppe zustehen. Der Kernel verteilt in diesem Fall die durch die übergeordnete Gruppe erlaubten Ressourcen anteilig auf die anfordernden Prozesse.
Grenzen überwinden
Das Ressourcen-Management von Ein- und Ausgabeoperationen gestaltet sich ebenfalls komplex. Entsprechend umfangreich fallen auch die Konfigurationsmöglichkeiten des IO-Controllers aus – sie würden einen eigenen Artikel verdienen.
Grundsätzlich wird durch Lesen der Datei »io.stat« die Statistik in Form der gelesenen, geschriebenen sowie verworfenen Bytes und IO-Operationen für jede Gerätedatei ausgegeben. Über die Datei »io.max« lassen sich die Grenzen für die (relativen) Lese- und Schreibraten beziehungsweise Ein- und Ausgabeoperationen jeweils pro Sekunde festlegen. Darüber hinaus definiert der Controller ein Kostenmodell, das über Gewichtungen funktioniert und das Festlegen von Anforderungen bezüglich der Latenzzeit ermöglicht.
Auch zum Verwalten von RDMA-Betriebsmitteln gibt es einen Controller. RDMA steht für Remote Direct Memory Access und ermöglicht es, Daten von einem Rechner zum anderen zu kopieren, ohne dabei die CPU respektive den Kernel zu bemühen. Vielmehr werden die Daten (zumeist im Umfeld von High Performance Computing) via Netzwerk direkt von einer Applikation zu einem anderen Rechner übertragen. Die Ressourcen für eine Gruppe lassen sich über die Datei »rmda.max« limitieren und die aktuell genutzten über »rdma.current« auslesen.
Ein weiterer Controller-Typ, der Device-Controller, reglementiert das Erzeugen von und den Zugriff auf Gerätedateien. Der Controller fällt dadurch auf, dass er keinerlei Interface-Dateien im Sys-Filesystem bereitstellt. Vielmehr nutzt er ähnlich einer aktuellen Firewall den Berkeley Packet Filter (BPF), um die Zugriffe zu kontrollieren.
Bericht erstatten
Eine ähnliche Sonderrolle nimmt die Event-Verarbeitung ein. Das Cgroup-Subsystem stellt in jedem Verzeichnis die Datei »cgroup.events« zur Verfügung, die in aktuellen Kernel-Versionen (ab 5.2) zwei Einträge hat. Die erste Zeile informiert unter dem Stichwort »populated« darüber, ob es in der Gruppe überhaupt Tasks gibt. Der zweite Eintrag gibt über das Stichwort »frozen« an, ob die Jobs einer Cgroup gerade eingefroren (suspended) sind. Änderungen an dieser Datei lassen sich aus dem Userland effizient mithilfe von »poll«, »inotify« oder »dnotify« überwachen.
Bedienungsanleitung
Standardmäßig sind mit Ausnahme des PID-Controllers die Ressourcen-Controller des Linux-Kernels nicht aktiviert. Die Datei »cgroup.controllers« listet alle Controller auf, die generell in einer Gruppe zur Verfügung stehen.
Zum Aktivieren schreibt der Admin per Echo-Kommando den Namen mit einem vorangestellten Pluszeichen in die Datei »cgroup.subtree_control«. Zum Deaktivieren verwendet er anstelle des Pluszeichens ein Minuszeichen. So aktiviert der Aufruf »echo +memory >/sys/fs/cgroup/user.slice/cgroup.subtree_control« den Memory-Controller für die Applikationen, das Kommando »echo -memory >/sys/fs/cgroup/user.slice/cgroup.subtree_control« entfernt ihn wieder.
Untergeordneten Gruppen stehen nur die Controller zur Verfügung, die in der Elterngruppe aktiviert wurden. Der Admin konfiguriert also von den Zweigen zu den Blättern.
Nutzlose Konfiguration
Wer mit Docker oder dergleichen arbeitet, kommt an Cgroups nicht mehr vorbei. Da verwundert es nicht, dass diese auf beinahe sämtlichen Linux-Systemen durch das Mounten des Dateisystemtyps »cgroup« respektive »cgroup2« aktiviert sind.
Allerdings aktivieren die Betriebssystemkonfektionierer Cgroups im sogenannten Hybrid-Betrieb. Dabei stehen im Prinzip beide Varianten zur Verfügung, also Version 1 zusammen mit Version 2. Im Prinzip deshalb, weil man praktisch einen Controller-Typ nur mit einer Version verwenden kann und weil mit dem Booten alle Controller-Typen der alten Version zugeteilt werden. Daher kann man diese ohne erheblichen Aufwand in der Version 2 nicht nutzen.
Glücklicherweise haben die Kernel-Programmierer aber den Boot-Parameter »systemd.unified_cgroup_hierarchy« implementiert, der Cgroups der Version 1 deaktiviert und beim Booten das Einhängen der Ressourcenverwaltung in Version 2 veranlasst. Den Parameter kann man beispielsweise unter Ubuntu durch Editieren der Datei »/etc/default/grub« einbauen.
Listing 2 enthält ein Sed-Kommando dazu, das der Admin mit Root-Rechten aufruft. Abbildung 4 zeigt die Ergänzung in der Zeile »GRUB_CMDLINE_LINUX_DEFAULT« nach Aufruf des Kommandos. Aktiv wird diese Konfiguration allerdings erst durch Aufruf von »sudo update-grub« in einer Konsole und einen nachfolgenden Neustart des Systems. Der Admin nimmt solche Eingriffe freilich nicht auf einem systemkritischen Produktivsystem vor, sondern nur auf einem Testsystem.
Listing 2
Sed-Kommando
# mv /etc/default/grub /etc/default/grub.orig # cat /etc/default/grub.orig | sed "s/GRUB_CMDLINE_LINUX_DEFAULT=\"\(.*\)\"/GRUB_CMDLINE_LINUX_DEFAULT=\"\1 systemd.unified_cgroup_hierarchy=1\"/" > /etc/default/grub # update-grub
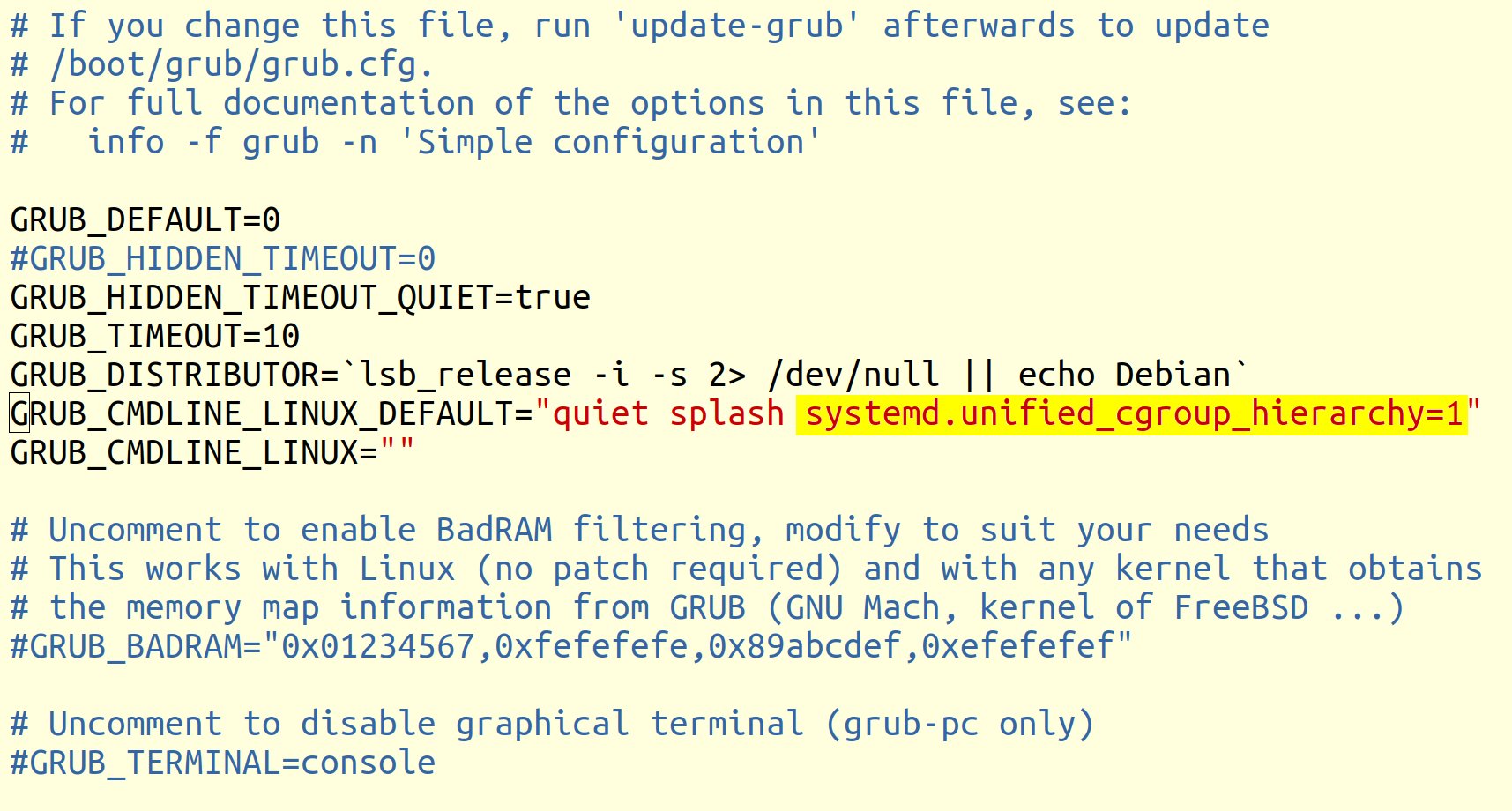
Abbildung 4: Über den Bootloader aktiviert der Admin Cgroups v2.
Bombenleger
So vorbereitet, kann man beispielsweise einen Fork-Bomben-Schutz mithilfe des PID-Controllers realisieren. Den bösartigen Programmcode »forkbomber.c« finden Sie in Listing 3. Er lässt sich durch Aufruf von »make forkbomber« in ein ausführbares Schadprogramm transformieren. Doch vor dem Start des Systemgefährders erfolgt noch die Schutzkonfiguration als praktisches Beispiel für den generellen Umgang mit dem Subsystem.
Listing 3
Einfache Fork-Bombe
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <time.h>
int main(int argc,char **argv,char **envp)
{
int pid;
struct timespec sleeptime;
while (1) {
pid = fork();
if (pid==-1) {
printf("fork failed - forkbomber stopped\n");
exit(-1);
}
if (pid==0)
break;
}
printf("new child %d\n", getpid());
sleeptime.tv_sec = 15;
sleeptime.tv_nsec= 0;
clock_nanosleep( CLOCK_MONOTONIC, 0, &sleeptime, NULL );
return 0;
}
Fehlzündung
Listing 4 zeigt die Kommandos, mit denen der Admin durch Anlegen des Verzeichnisses »myshell/« eine eigene Cgroup erstellt (Zeile 1 und 2). Anschließend aktiviert er den Controller-Typ »pids« für die neue Gruppe. Normalerweise müsste er dazu vom Cgroup-Root-Verzeichnis ab bis zur aktuellen Ebene den Typnamen mit vorangestelltem Pluszeichen in die Datei »cgroup.subtree_control« schreiben. Für den Pids-Controller hat das aber für die vorhandenen Ebenen Systemd bereits erledigt. Daher ist dieser Schritt nur noch im neu angelegten Verzeichnis notwendig (Zeile 3 und 4).
Listing 4
pids-Controller aktivieren und konfigurieren
$ cd /sys/fs/cgroup/user.slice/user-1000.slice/user@10000.service/ $ mkdir myshell $ cd myshell $ echo +pids >cgroup.subtree_control $ echo 10 >pids.max $ echo $$ >cgroup.procs $ cd /tmp/ $ make forkbomber $ ./forkbomber
Im dritten Schritt schließlich konfiguriert der Admin den freigegebenen Controller durch Schreiben einer »10« in die Datei »pids.max« auf das entsprechende Limit (Zeile 5). Noch ist der Cgroup keine einzige Task zugewiesen. Der Admin verschiebt also die aktuelle Shell in die Gruppe. Dazu schreibt er die PID der Shell, die sich in der Shell-Variablen »$$« findet, in die Datei »cgroup.procs« (Zeile 6).
Ab jetzt unterliegt die Shell der festgelegten Limitierung. Wird der Forkbomber-Quellcode im Verzeichnis »/tmp/« abgelegt, dort per »make forkbomber« generiert und danach gestartet, meldet er bereits nach kurzer Zeit, dass er keine neuen Rechenprozesse mehr erzeugen kann (Abbildung 5).
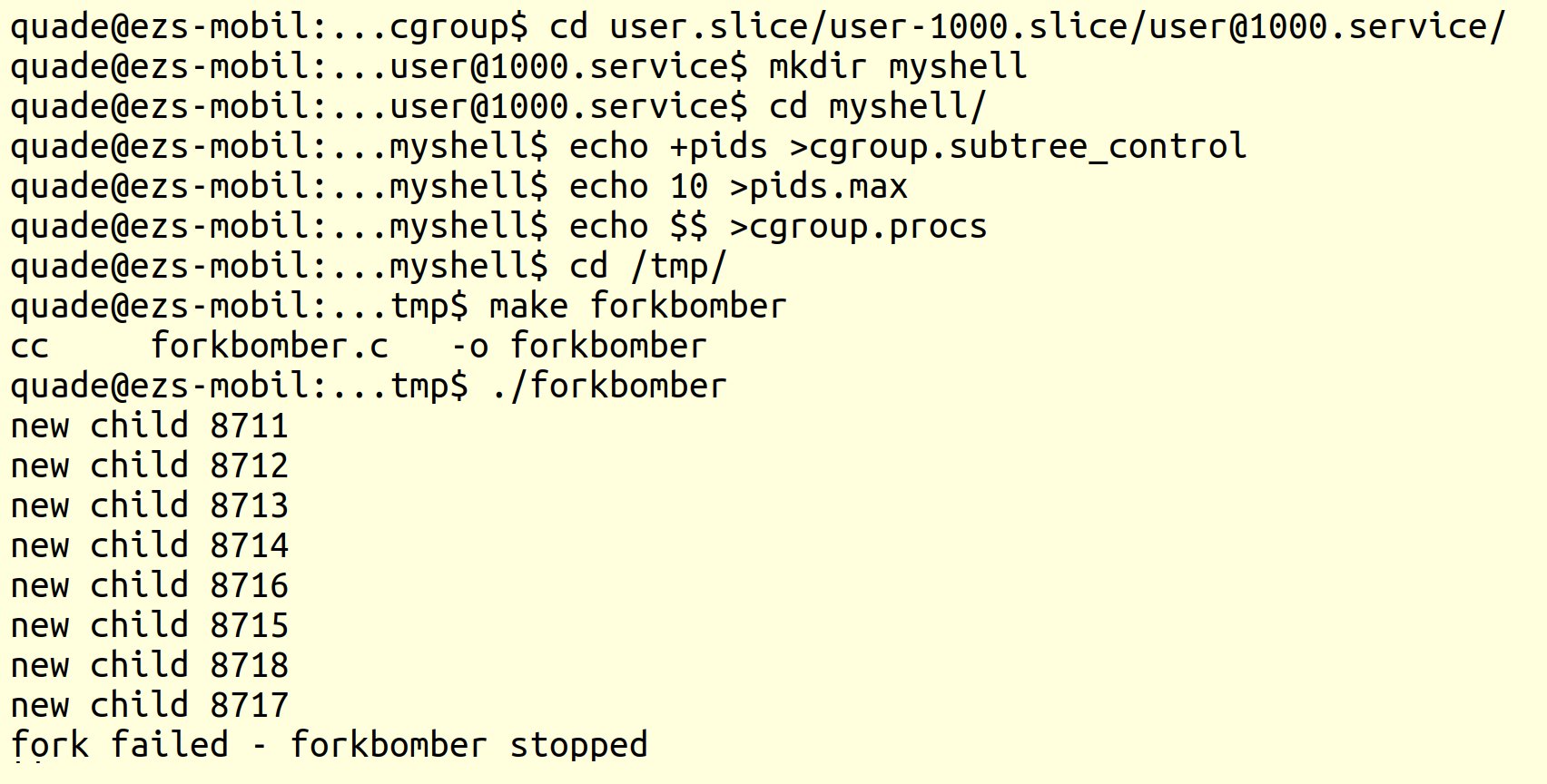
Abbildung 5: Die Cgroup bremst den Fork-Bomber wirksam aus.
Dokumentation
Die Dokumentation zum Kernel-Quellcode beschreibt die Controller samt ihrer Interface-Dateien ausführlich [2]. Daneben gibt es auch eine leidlich aktuell gehaltene Manpage zu Cgroups [3]. Darüber hinaus ist die Informationslage insbesondere zur eigentlichen Konfiguration zurzeit allerdings eher dürftig.
Von Facebook als eifrigem Nutzer findet man Berichte zum Einsatz [4]. Dabei isoliert der Technologiegigant auf seinen Servern erfolgreich die produktiven Jobs von Hintergrundprozessen, also Webserver von Systemprozessen und zeitkritische Arbeit von Hintergrundjobs.
Ausblick
In Anbetracht der vielfältigen Möglichkeiten stellt sich die Frage, warum Cgroup v2 noch nicht standardmäßig aktiviert ist, obwohl es doch bereits seit 2013 entwickelt wird. Die simple Antwort: Die Entwicklung von Cgroup v2 erfolgt evolutionär, in den letzten Versionen war nur ein kleiner Teil der Controller realisiert. Funktional hat das Subsystem allerdings in jüngster Zeit zu Version 1 aufgeschlossen, sodass der Übergang nicht mehr lange auf sich warten lassen dürfte. (jlu)
Die Autoren
Eva-Katharina Kunst ist seit den Anfängen von Linux Fan von Open Source. Jürgen Quade, Professor an der Hochschule Niederrhein, führt auch für Unternehmen Schulungen zu den Themen Treiberprogrammierung und Embedded Linux durch.
Infos
- Systemd resource control: https://wikitech.wikimedia.org/wiki/Systemd_resource_control
- Control Group v2: https://www.kernel.org/doc/Documentation/cgroup-v2.txt
- Manpage Cgroups: http://man7.org/linux/man-pages/man7/cgroups.7.html
- “Maximizing Resource Utilization with cgroup2”: https://facebookmicrosites.github.io/cgroup2/docs/overview.html
- “What’s new in control groups (cgroups) v2”: http://www.man7.org/conf/lca2019/cgroups_v2-LCA2019-Kerrisk.pdf
- “The current adoption status of cgroup v2 in containers”: https://medium.com/nttlabs/cgroup-v2-596d035be4d7





