
© psdesign1, Fotolia
Scheduling ist eine zentrale Aufgabe des Linux-Kernels, der sich dabei um größte Fairness bemüht. Wer aber glaubt, dass damit alle das Gleiche bekommen, der irrt.
Das Task-Scheduling beeinflusst, wie sich ein Computer unter Last verhält. Nicht zufällig war diese CPU-Zuteilung häufig nicht nur Diskussions-, sondern sogar Streitthema unter den Linux-Entwicklern. Mit Kernel 2.6.23 vom Oktober 2007 hat der ungarische Entwickler Ingo Molnar den bis dahin in Linux verwendeten Scheduler O(1) durch den Completely Fair Scheduler (CFS) ersetzt, der seitdem – mit einigen Veränderungen versehen – seine Arbeit tut.
Fair Play
Anstelle der im O(1)-Scheduler implementierten Heuristik setzt CFS zur Erreichung von Interaktivität auf Fairness. Da er damit harte zeitliche Anforderungen nicht erfüllen kann, gibt es vorgeschaltet noch einen Echtzeit-Scheduler. Das Grundprinzip des CFS besteht darin, die zur Verfügung stehende Rechenzeit fair auf die lauffähigen Tasks aufzuteilen [1].
Dazu bekommt jede Task innerhalb einer definierten Scheduler-Periode je einmal Rechenzeit zugeteilt. Die Länge dieser Rechenzeit berechnet sich im ersten Ansatz durch Division der Scheduling-Periode durch die Anzahl der lauffähigen Tasks. Ist beispielsweise eine Scheduler-Periode 20 Millisekunden lang und es gibt vier lauffähige Tasks, darf jede Task 5 Millisekunden lang rechnen, bevor die nächste Task die CPU übernimmt.
Diese gleichförmige Aufteilung der Rechenzeit ist aber noch nicht fair. Daher berücksichtigt der Scheduler außerdem den Nice-Wert, die “Nettigkeit” von Tasks: Ist eine Task besonders nett, gibt sie sich mit weniger Rechenzeit zufrieden und besitzt einen positiven Nice-Wert. Bei einem negativen Nice-Wert dagegen erwartet sie mehr Rechenzeit.
Der alte O(1)-Scheduler realisierte den Nice-Wert über Prioritäten, die der Scheduler – um Interaktivität zu gewährleisten – während der Laufzeit modifizierte. So setzte er die Priorität eines Jobs, der ständig rechnete, herunter und die Priorität eines I/O-intensiven Jobs hoch.
CFS dagegen zieht die Nice-Werte heran, um die Laufzeit der Tasks anzupassen. Nette Tasks laufen kürzer, die übrigen entsprechend länger. Dazu rechnet der Scheduler den Nice-Wert in eine Weight genannte Gewichtung um. Das Gewicht für eine Task mit einem Nice-Wert von 0 beträgt per definitionem 1024 [2]. Die Gewichte für andere Nice-Werte berechnen sich nach der Formel:
w(nice)=1024/1.24^nice
Ein Nice-Wert von 1 resultiert somit in einem Gewicht von 820, ein Nice-Wert von -1 ergibt den Wert 1277. Durch die Art der Berechnung ergibt sich eine gewollte exponentielle Gewichtung der Nice-Werte in Abgrenzung zur früher üblichen linearen Zuteilung. Wird der Nice-Wert um 1 erhöht, reduziert sich die zugehörige Rechenzeit um etwa 10 Prozent: Die eigene Rechenzeit wird um 5 Prozent reduziert, die der übrigen Tasks um 5 Prozent erhöht.
Nette Tasks
Die Laufzeit einer Task innerhalb der Scheduler-Periode berechnet der Kernel anteilig zu ihrem Gewicht. Sie ergibt sich durch Multiplikation der Scheduling-Periode mit dem Quotienten aus dem Gewicht der Task und der Summe aller lauffähigen Gewichte (Tabelle 1). Ist beispielsweise eine Task mit einem Nice-Wert von 2 versehen, hat sie ein Gewicht von 655. Bei insgesamt vier Tasks, von denen eine einen Nice-Wert von -2, eine von 2 und die übrigen beiden 0 haben und die Scheduling-Periode 20 Millisekunden beträgt, ergibt sich für die erste Task eine Zeitscheibe von etwa 3 Millisekunden, für die beiden Tasks mit einem Nice-Wert von 0 je 5 Millisekunden und für die Task mit -2 eine Zeitscheibe von etwa 7 Millisekunden.
Tabelle 1
Berechnung der Zeitscheiben
|
Datenbank |
»nice« -Wert |
Gewicht »w« 1 |
Timeslice2 |
|---|---|---|---|
|
T1 |
2 |
655 |
3 ms |
|
T2 |
1024 |
5 ms |
|
|
T3 |
1024 |
5 ms |
|
|
T4 |
-2 |
1586 |
7 ms |
Die Länge der Scheduler-Periode lässt sich über die virtuelle Datei »/proc/sys/kernel/sched_latency_ns« konfigurieren. Im selben Verzeichnis kann man in »sched_min_granularity_ns« die minimale Zeitscheibenlänge für eine Task festlegen. Die zugehörige Variable verhindert, dass die Zeitscheiben zu kurz werden, wenn beispielsweise viele Tasks im System lauffähig sind.
In diesem Fall erhöht der CFS selbstständig die Scheduling-Periode: Ist »sched_min_granularity_ns« zum Beispiel auf 2 Millisekunden eingestellt – wobei die ursprüngliche Scheduling-Periode wieder 20 Millisekunden beträgt – und sind 20 Tasks lauffähig, ergibt sich eine reale Scheduling-Periode von 20 mal 2, also von 40 Millisekunden.
Virtuelle Laufzeit
Neben den unterschiedlichen Längen der Zeitscheiben entscheidet CFS auch über die Reihenfolge, in der er die Tasks nacheinander abarbeitet. Dazu hat Molnar die virtuelle Laufzeit »vruntime« eingeführt. Vruntime reflektiert die von einem Rechenprozess bisher genutzte Laufzeit. Sie ist jedoch wiederum gewichtet – daher auch virtuell –, sodass jede Task den Beitrag liefert, den sie bei einem Nice-Wert von 0, also einem Gewicht von 1024, gehabt hätte (Abbildung 1). Die vier Tasks haben zwar real unterschiedliche Laufzeiten (3, 5 und 7 Millisekunden), ihre Vruntime ist aber identisch.
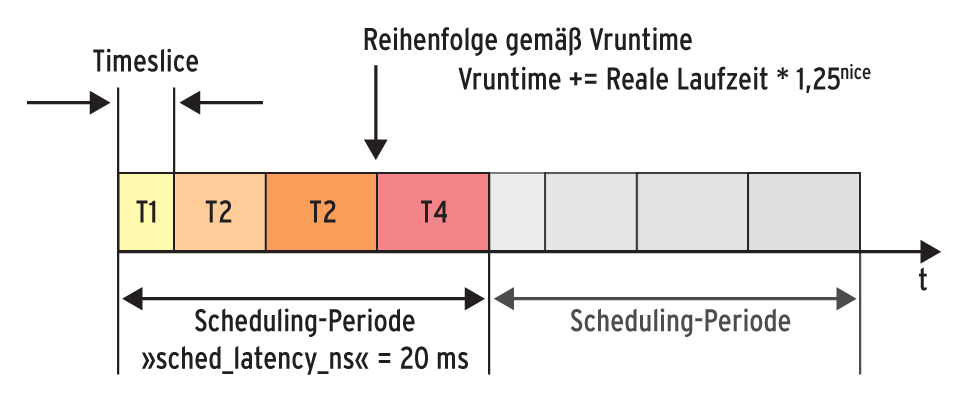
Abbildung 1: Die Länge der zugeteilten Zeitscheibe berechnet der Kernel anhand des Gewichts einer Task.
Um mit möglichst wenig Rechenaufwand die Auswahl treffen zu können, sind alle lauffähigen Tasks in einem Red-Black-Tree (RB-Tree) einsortiert. Der ist Informatikern als eine Form der Datenstruktur “Binärer Baum” bekannt (Abbildung 2). Jede Task ist durch einen Knoten in dieser Datenstruktur repräsentiert. Ein RB-Tree sortiert Daten ausbalanciert nach einem vorgegebenen Kriterium, in diesem Fall nach der Vruntime. Der Job, der die geringste virtuelle Laufzeit aufweist, ist ganz links im Baum abgelegt und wird von dem Scheduler ausgewählt.
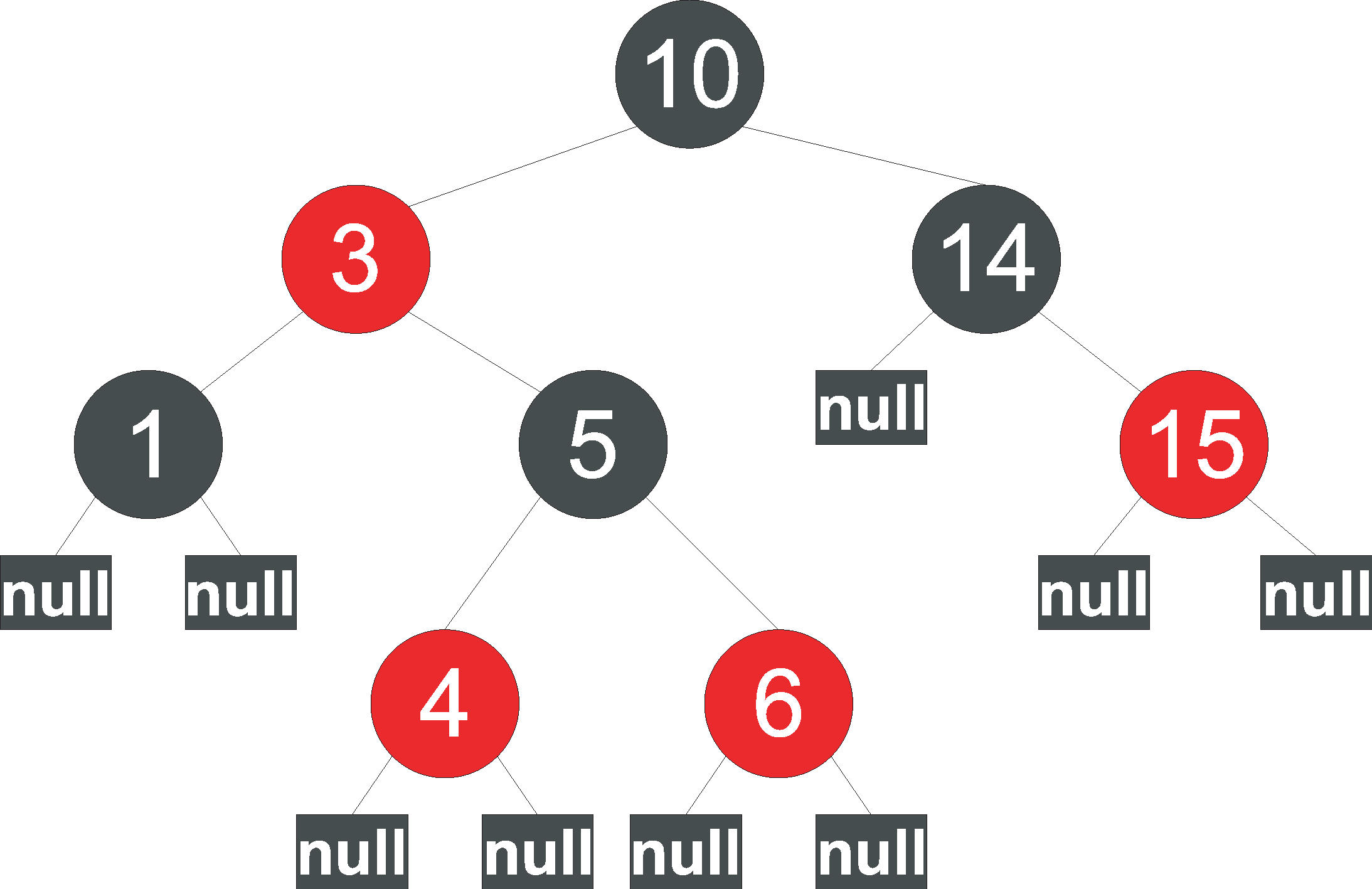
Abbildung 2: Red-Black-Tree: Nach dieser Datenstruktur sortiert der Scheduler die Tasks anhand ihrer virtuellen Laufzeit.
Während der alte O(1)-Scheduler für den Vorgang, den nächsten Rechenprozess auszuwählen, eine konstante Rechenzeit benötigte, die zudem noch unabhängig von der Anzahl lauffähiger Tasks war, schneidet CFS in diesem Punkt nicht ganz so gut ab. Er benötigt zum Einsortieren einer Task in den Baum eine Rechenzeit von O(log(n)).
Anders ausgedrückt: Eine Verzehnfachung der Taskanzahl führt zu einer Verdoppelung der Laufzeit beim Einsortieren in den Baum. Damit kann man aber sogar in einem Echtzeitumfeld gut leben. Zum einen ist die Zeit durch die maximale Anzahl von Tasks, mit der Linux umgehen kann, gedeckelt und zum anderen kommt CFS ohnehin für Realzeitaufgaben nicht direkt zum Einsatz.
Batch oder nicht?
CFS unterstützt zwei Scheduling-Policies, unter die ein Programmierer seine Jobs stellen kann: »SCHED_NORMAL« und »SCHED_BATCH« . Tasks, die der Scheduler nach der Policy »SCHED_BATCH« behandelt, unterbrechen keine anderen Tasks, die unter der Policy »SCHED_NORMAL« laufen. Daraus folgt eine geringere Interaktivität der als Batchjobs gekennzeichneten Tasks.
Der Completely Fair Scheduler bietet darüber hinaus noch mehr: Mit dem Gruppen-Scheduling hebt er die Fairness auf die nächste Ebene. Damit fasst der Admin Tasks zu in »/sys/fs/cgroup/« definierten Gruppen zusammen, die eine eigene virtuelle Laufzeit erhalten (siehe [1], Abschnitt 7).
Diese Gruppen und die nicht gruppierten Tasks konkurrieren um die Rechenzeit, die CFS nach dem beschriebenen Verfahren fair verteilt. Innerhalb der Gruppe findet dann ebenfalls die faire Verteilung entsprechend der virtuellen Laufzeit der einzelnen Tasks statt.
Auf diese Art ist es beispielsweise möglich, die Tasks einzelner User zu jeweils einer Gruppe zusammenzufassen und so zu verhindern, dass ein User überproportional mehr Rechenzeit bekommt, nur weil er viele Rechenprozesse startet. Allerdings bietet CFS keine rekursive Gruppierung; eine Gruppe kann also nicht wiederum selbst aus (Unter-)Gruppen bestehen.
Wunderpatch
Das Gruppen-Scheduling bildet auch die Basis für das 200-Zeilen-Wunderpatch, das Linus Torvalds mit Kernel 2.6.38 unter der Feature-Kennung »autogroup« übernommen hat. Dabei bildet der Kernel automatisch Gruppen gemäß den aktiven Sessions, was in den meisten Anwendungsfällen die Interaktivität spürbar steigert. Ist das Feature einkompiliert, lässt es sich mit
echo [01] > /proc/sys/kernel/sched_autogroup_enabled
aus- beziehungsweise einschalten. Mit Kernel 3.2 kam schließlich auch noch die Bandbreitenkontrolle dazu, die ebenfalls das Gruppen-Scheduling voraussetzt (siehe Kasten “Bandbreitenkontrolle für Admins”).
Bandbreitenkontrolle für Admins
Seit Kernel 3.2 kann CFS die Rechenzeit nicht nur zwischen Tasks aufteilen, sondern per Bandbreitenkontrolle (Bandwith Control) auch begrenzen. Das nutzt der Admin, um für eine gleichmäßigere Auslastung zu sorgen. Dies stellt Tasks oder Taskgruppen unabhängig von der sonstigen Systemlast immer die gleiche Rechenzeit zur Verfügung.
Bandbreitenkontrolle konfiguriert der Admin über das Cgroup-Interface. Grundsätzlich muss dazu »CPU bandwith provisioning« im Kernel einkompiliert sein, was bei den meisten Distributionen, etwa Ubuntu, der Fall ist.
Cgroups konfigurieren
Um Zugang zu den Konfigurationsvariablen zu erhalten, aktiviert der Superuser zunächst das Cgroup-Interface im Sys-Dateisystem, wie in Listing 1 zu sehen ist.
Danach erstellt er eine neue Taskgruppe, indem er ein Verzeichnis im Sys-Filesystem anlegt:
root@host# cd /sys/fs/cgroup/cpu/ root@host# mkdir bw_tasks
Mit dem Bilden der Taskgruppe stellt der Kernel im neuen Verzeichnis »bw_tasks« automatisch eine Reihe von Konfigurationsvariablen bereit. Für die Bandbreitenkontrolle sind »cpu.cfs_period_us« , »cpu.cfs_quota_us« und »tasks« relevant. Über die Variable »tasks« lassen sich die zu kontrollierenden Jobs angeben, »cpu.cfs_period.us« legt die Periode fest, »cpu.cfs_quota_us« den Anteil, den die Tasks maximal innerhalb der Periode bekommen sollen.
Um Tasks der neuen Gruppe zuzuordnen, muss der Administrator nur die zugehörige Task-PID per Echo-Kommando in die Datei »tasks« schreiben. Die Periode ist standardmäßig auf 100 Millisekunden (100000 Mikrosekunden) eingestellt, Quota auf -1, was mit “ausgeschaltet” gleichzusetzen ist. Will der Admin den Tasks etwa die Hälfte der Rechenzeit zugestehen, setzt er die Quota per Echo auf 50000.
Die Periode bezieht sich übrigens immer auf einen Prozessorkern, daher darf Quota auf Mehrkernmaschinen auch durchaus größer als die Periode werden. Setzt Root die Quota beispielsweise auf 200000, nutzen die Tasks zwei Prozessorkerne zu 100 Prozent aus.
Testprogramm
Die Wirkungsweise der Bandbreitenkontrolle lässt sich sehr gut anhand des Testprogramms aus Listing 2 demonstrieren [7], das per »make loops« kompiliert wird. Nach dem Start zeigt es die eigene PID und – als Referenz für die in Anspruch genommene Rechenzeit – die Anzahl der Schleifendurchläufe pro Sekunde:
user@host:/tmp/bandwith$ ./loops [4474] 216226792 [4474] 216229899 [4474] 216212148[...]
Hier hat der gestartete Job die PID 4474 und die Schleife wird pro Sekunde etwa 216 Millionen Mal durchlaufen. Zum Ausprobieren stoppt Root das Programm nicht, sondern fügt den Prozess 4474 – am geschicktesten auf einem anderen Terminal – der zu kontrollierenden Taskgruppe hinzu. Danach limitiert er die Bandbreite beispielsweise auf die Hälfte, indem er »cpu.cfs_quote_us« auf 50000 setzt:
root@host:/sys/fs/cgroup/cpu# echo 4474 > bw_tasks/tasks root@host:/sys/fs/cgroup/cpu# echo 50000 > bw_tasks/cpu.cfs_quota_us
Anhand der Ausgabe von Job 4474 im anderen Terminal ist dann erkennbar, wie die Durchläufe von 216 Millionen auf etwa 96 Millionen sinken:
[...] [4474] 214471135 [4474] 216215018 [4474] 215916496 [4474] 96123349 [4474] 96041753 [4474] 93157035[...]
Listing 1
Cgroup-Interface aktivieren
01 root@ezs-mobil:/# mount none /sys/fs/cgroup/ -t tmpfs 02 root@ezs-mobil:/# mkdir /sys/fs/cgroup/cpu 03 root@ezs-mobil:/# mount none /sys/fs/cgroup/cpu/ -t cgroup -o cpu 04 root@ezs-mobil:/# ls /sys/fs/cgroup/cpu/ 05 cgroup.clone_children cpu.cfs_quota_us cpu.stat 06 cgroup.event_control cpu.rt_period_us notify_on_release 07 cgroup.procs cpu.rt_runtime_us release_agent 08 cpu.cfs_period_us cpu.shares tasks 09 root@ezs-mobil:/#
Listing 2
Laufzeit-Messprogramm loops.c
01 #include <stdio.h>
02 #include <time.h>
03 #include <unistd.h>
04
05 int main(int argc,char **argv,char **envp)
06 {
07 long long int compteur;
08 time_t debut = time(NULL);
09
10 // Wait for the next second
11 while (time(NULL) == debut)
12 ;
13 while (1) {
14 compteur = 0;
15 time (& debut);
16 while (time(NULL) == debut)
17 compteur ++;
18 printf("[%u] %lld\n", getpid(),
19 compteur);
20 }
21 return 0;
22 }
Ingo Molnar hat mit dem Completely Fair Scheduler nicht nur ein neues Scheduling-Verfahren eingeführt, sondern dabei die komplette Scheduler-Implementierung ausgetauscht. Die früher hart kodierte, auf Prioritätsebenen beruhende Implementierung ersetzte er durch ein auf Prioritätsklassen basierendes Framework (siehe Abbildung 3). Die Scheduling-Klassen – wovon ein Standard-Linux zurzeit vier realisiert – arbeitet der Kernel nacheinander ab.
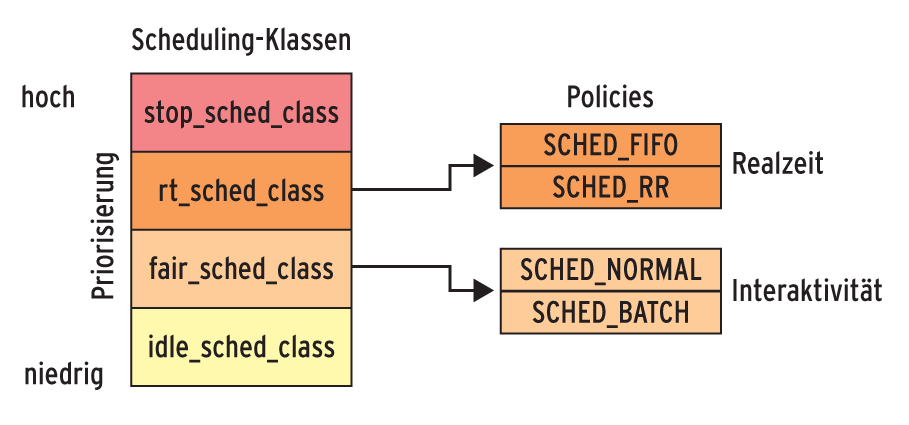
Abbildung 3: Vier Prioritätsklassen sorgen in einem normalen Linux-Kernel für Ordnung beim Scheduling.
Klassengesellschaft
Zuerst überprüft das Scheduling-Framework, ob es Tasks in der Klasse »stop_sched_class« gibt. Ist dies der Fall, dürfen diese rechnen. In diese Klasse lässt sich eine Super-Task einordnen, die alle anderen unterbricht, selbst aber nicht unterbrochen werden darf. Anschließend wird die Klasse »rt_sched_class« aktiviert. Diese implementiert das auf Prioritätsebenen basierende Posix-Scheduling mit den Policies »SCHED_RR« und »SCHED_FIFO« .
Echtzeit
In diesem Bereich hat sich nichts geändert: Linux bietet weiterhin 99 Realzeit-Prioritätsebenen an, die für ein Realzeitsystem notwendig sind. Erst wenn alle Realzeit-Tasks abgearbeitet sind, kommt die dritte Klasse »fair_sched_class« zum Zuge, die das CFS repräsentiert und die beiden Policies »SCHED_NORMAL« und »SCHED_BATCH« implementiert. Befindet sich in dieser Klasse kein lauffähiger Job, aktiviert der Kernel als Letztes schließlich die »idle_sched_class« mit der so genannten Idle-Task.
Scheduling-Klassen haben den Vorteil, die Integration anderer Verfahren zu vereinfachen. Realzeitsysteme etwa nutzen gerne das als optimal geltende Scheduling-Verfahren Earliest Deadline First (EDF), bei dem als nächste jene Task rechnen darf, die als erste eine Reaktion erbringen muss. Hierfür gibt es Implementierungen, die eine eigene Scheduling-Klasse realisieren, die sich etwa zwischen der RT- und der CFS-Klasse einbauen lässt ([3], [4]).
Implementierungstechnisch betrachtet ist eine Scheduling-Klasse ein Objekt (deklariert in »include/linux/sched.h« ), das unter anderem die in Tabelle 2 aufgeführten Methoden implementiert. Aus dem Task-Kontrollblock »struct task_struct« , der im Kernel einen Rechenprozess eindeutig identifiziert, zeigt der Code auf das jeweils zugehörige Scheduling-Klassenobjekt (siehe Abbildung 4).
Tabelle 2
Ausgewählte Methoden, die eine Scheduling-Klasse implementiert
|
Methode |
Bedeutung |
|---|---|
|
enqueue_task |
Fügt eine Task in die Runqueue ein; wird aufgerufen, wenn die Task lauffähig wird |
|
dequeue_task |
Entfernt eine Task aus der Runqueue; wird aufgerufen, wenn die Task nicht mehr lauffähig ist |
|
yield_task |
Gibt die CPU frei |
|
check_preempt_curr |
Überprüft, ob eine Task die gerade laufende Task unterbricht |
|
pick_next_task |
Wählt die nächste zu bearbeitende Task aus |
|
task_tick |
Summiert die Rechenzeit der Task |
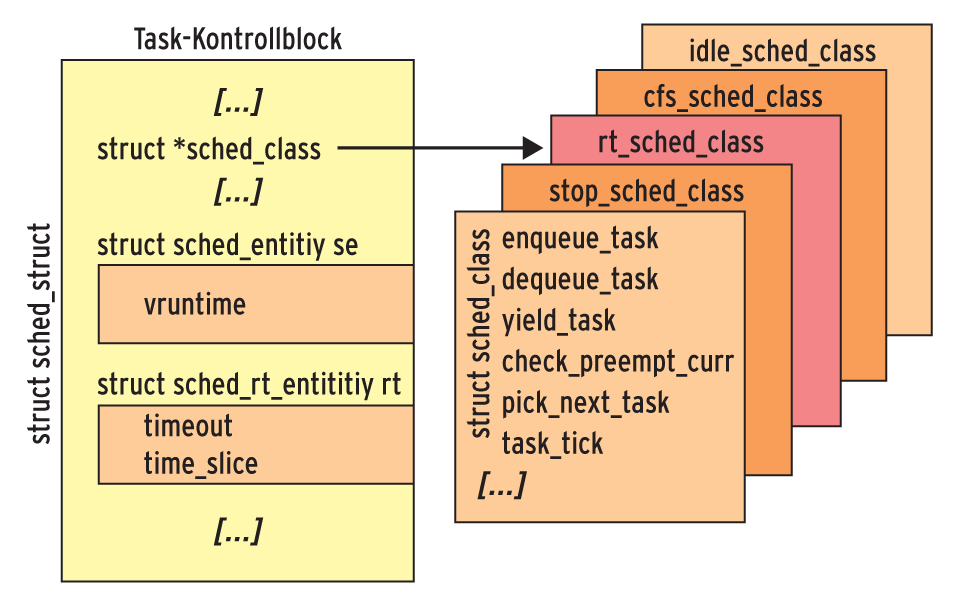
Abbildung 4: Der Task-Kontrollblock referenziert die Scheduling-Klasse.
Auch wenn das Austauschen eines Algorithmus während der Laufzeit noch nicht vorgesehen ist, lassen sich eigene Algorithmen auf diese Weise leicht implementieren [5].
Ausblick
Potenzial für Verbesserungen gibt es mehr als genug, besonders weil das Thema Multicore- beziehungsweise Manycore-Scheduling noch recht neu ist. Schließlich muss CFS im Linux-Kernel mit dem Multicore-Scheduler kooperieren, der fürs Load Balancing zuständig ist, also für die Lastverteilung zwischen den verfügbaren CPU-Kernen [6].
Der geringste Aufwand fällt bei einer Hyperthreading-Architektur (Symmetric Hyperthreading, SMT) an, doch auch der Leistungsgewinn ist dabei klein. Schwieriger wird es beim klassischen symmetrischen Multiprocessing (SMP). Am kompliziertesten ist es auf Numa-Systemen, bei denen Prozessoren auf die ihnen zugewiesenen Speicherbereiche schneller zugreifen können als auf das von anderen CPUs verwaltete Memory. In der Realität kommen die verschiedenen Basisarchitekturen zudem oft in Kombination vor. (mhu)
Infos
- Kernel-Dokumentation zum CFS-Scheduler: http://www.kernel.org/doc/Documentation/scheduler/sched-design-CFS.txt
- Oakbytes, Linux-Scheduler (CFS): http://oakbytes.wordpress.com/linux-scheduler/
- Faggioli et al., “An EDF scheduling class for the Linux kernel”: http://lwn.net/images/conf/rtlws11/papers/proc/p16.pdf
- Faggioli, Lelli, “SCHED_DEADLINE”:http://www.evicence.eu.com/sched_deadline.html
- Sousa, Ferreira, “Implementing a new real-time scheduling policy for Linux”: http://www.embedded.com/design/operating-systems/4204929/Real-Time-Linux-Scheduling-Part-1
- Quade, Kunst, “Kern-Technik”, Folge 33: Linux-Magazin 05/07, S. 52
- Christophe Blaess, “Linux 3.2 – CFS CPU bandwidth”: http://www.blaess.fr/christophe/2012/01/07/linux-3-2-cfs-cpu-bandwidth-english-version/





