
© clafouti, Photocase.com© Vision Lab, Universität Antwerpen
Wer gerade die Millionen für ‘nen Super-Boliden nicht zur Hand hat, nimmt eben eine oder mehrere Standardkisten und Linux. Das mag übertrieben sein, doch aktuelle Systeme bedienen sich vieler Techniken des High Performance Computing.
Ein Flop, das ist die kleinste Münze der Leitwährung für Rechenleistung, eine Floatingpoint-Operation pro Sekunde. Für die Ermittlung der Werte hat sich ein normalerweise in Fortran geschriebener Benchmark namens Linpack [1] seit vielen Jahren etabliert, der einen Satz linearer Gleichungen numerisch löst. Ein halbwegs aktuelles 64-Bit-Dualcore-System mit 2,66 MHz Taktfrequenz bringt es auf rund 25 Gigaflops, also 25 mal 109 Gleitkomma-Operationen pro Sekunde. Ein PC-Bolide mit Intels Core-i7-CPU kommt auf rund 33 Gigaflops.
Auch die Königsklasse des Supercomputings, deren Adelsregister die zwei Mal im Jahr erscheinende Top-500-Liste ist, unterwirft sich dem Flop-Ranking. Aktuell benötigen die schnellsten Rechner der Welt den Einheitenvorsatz Peta für eine Billiarde (1015) Operationen.
Aus eins mach viele
Diese Marke erreichte im Jahr 2008 erstmals das von IBM und dem Los Alamaos Lab gemeinsam entwickelte Hybridsystem Roadrunner, das mit 6120 AMD-Opteron-Dualcore-Prozessoren sowie einer Power-Xcell-CPU pro Core rechnet [2]. Das Blade-System, auf dem RHEL läuft, kam damit auf 1026 Teraflops, also gut ein Petaflop. Die nächste Stufe auf der Leiter der Maßeinheiten wäre der Exaflop mit 1018 Fließkomma-Operationen, die kein Rechner nach heutiger Prognose vor dem Jahr 2020 erreichen wird.
Wer gerade die Millionen Euro oder Dollar für solche Boliden nicht zur Hand hat, braucht sich nicht zu grämen – es sei denn, er will die Detonation einer Atombombe simulieren oder ähnliche Extremrechnungen anstellen. Denn auch ganz normale Server und Workstations der jüngsten Generation weisen Rechenleistungen auf, die sich bei komplexen Aufgaben durchaus sehen lassen dürfen.
Der technische Fortschritt bei den Prozessorherstellern bringt nämlich Techniken in den Mainstream, die eine Art Abfallprodukt des High Performance Computing sind, Multicore und schnelle CPU-interne Bussysteme beispielsweise. Vierkern-Prozessoren wie der Athlon X4 sind für rund 100 Euro zu haben. Intels “Gulftown”-Core i7 980 und der Phenom II X6 von AMD eröffnen derzeit die Sechskern-Ära im Desktopsektor. Weitere Informationen über aktuelle Multicore-Prozessoren enthält der Beitrag von Daniel Kottmair in diesem “Mehr rausholen”-Spezial.
Shoppingtour bei IBM & Co.
Wer Anwendungen mit hohem Rechenleistungsbedarf benutzt und keinen modernen Rechner im Rack oder unterm Schreibtisch stehen hat, muss shoppen gehen. Das Linux-Magazin hat beispielhaft bei vier namhaften Herstellen angefragt, was sie aus ihrem Portfolio zum Numbercrunching empfehlen, wenn der Kunde weniger als 10 000 Euro ausgeben will (siehe Tabelle 1). IBM findet diese Zielgruppe interessant. “Supercomputing ist nicht mehr der Spitzenforschung vorbehalten. Zahlreiche Fachabteilungen und Mittelständler setzen heute HPC-Lösungen ein, von den größten Wissenschaftszentren der Welt bis hin zu Ingenieurbüros”, weiß Stephanie Kühdorf, Leiterin des Supercomputing-Bereichs.

Natürlich haben die Stuttgarter gleich die passenden Systeme im Angebot: Neben den Power-Unix-Servern gibts x86-Systeme und das Highend-Cluster-Produkt I-Data-Plex. Wer nach einer HPC-Lösung unter 10 000 Euro fragt, den empfielt IBM die EX5-Familie (zwei 19-Zoll-Modelle, [3]) oder HX5-Blades. Für letztere braucht man freilich noch ein Bladecenter (alle in Abbildung 1). Die Blades führt IBM als 2- oder 4-Sockel-Einschübe. Mit den so möglichen 16 Xeon-Cores erreicht der Käufer eine ansehnliche Rechendichte, bis zu 640 GByte RAM und maximal 100 GByte internem Plattenplatz. Hot-swappable Harddisks sind bei dem Preis leider nicht drin. Immerhin kann der Kunde aber auf den optionalen Embedded Hypervisor zurückgreifen.

Abbildung 1: Das kleine IBM-Familienbild zeigt (von oben nach unten) zwei HX5-Blades, einen 2-Socket-Server und den 4-Socket-Server der EX5-Serie.
Eine Flunder von Dell
Nur eine Höheneinheit hoch ist Dells Empfehlung fürs günstige HPC, der Power Edge R 410 [4]. Ein sinnvolles HPC-Setup gibt es laut Hersteller bei einem Listenpreis von etwa 3 500 Euro (Abbildung 2). Für so wenig Geld stecken in der Flunder auch nur zwei Xeons der 5600-Serie mit 2,4 GHz und nur magere vier der technisch bis zu 64 möglichen GByte RAM. Vier 250-GByte-SATA-Festplatten und ein DVD-Brenner lassen sich einbauen, HD-Hotplug kostet 100 Euro mehr. Ausstattung und Preis lassen sich leicht hochtreiben, am einfachsten per Konfigurator auf der Webseite.

Abbildung 2: Viel flacher geht kaum – in die Dell-Server mit dem Namen Power Edge R410 passen auch zwei der teueren Intel-Xeon-CPUs mit jeweils sechs Kernen.
Thomas Krenn: Wahl zwischen Intel und AMD
Auch Intel-Server-Spezialist Thomas Krenn empfiehlt auf Anfrage eine Pizzaschachtel ([5], Abbildung 4). Der Server heißt SC813, kostet 6500 Euro und beherbergt zwei Intel 6-Core-Xeons (Westmere), 24 GByte RAM und bietet 450 GByte Plattenplatz. Bei den Bayern gibt es aber auch die neuen AMD-Hexacores, die bei gleicher Ausstattung meist deutlich günstiger zu haben sind. Ein mit zwei 6-Core-Istanbul-CPUs, 64 GByte RAM und mit 2 TByte Speicherplatz auf vier SAS-Platten ausgestatteter Server kommt auf den gleichen Preis. Für ein fast identisches System mit Intel-CPUs muss man bei Krenn 1 000 bis 1 500 Euro mehr veranschlagen.

Abbildung 4: Thomas-Krenn-Server mit Intel-CPUs setzen auf Westmere-Xeons. Für weniger Geld gehen die vergleichbaren 6-Core-CPUs aus AMDs Istanbul-Reihe über den Ladentisch.
Neueinsteiger Fujitsu
Es trifft sich gut, dass Fujitsu, der Hersteller der Server mit den kleinen grünen Hebelchen, nach eigener Aussage “gerade dabei ist, in den HPC-Markt für KMUs einzusteigen”: Als 19-Zoll-Rack bietet er den 1-HE-Server Primergy RX 200 ([6], Abbildung 5) sowie als Blade-Server mit höcherer Rechendichte den BX 900 an. Wer mehr will und keine 10 000-Euro-Grenze kennt, der greift zum Wandschrank der CX 1000. Auch in die RX 200 passen Intels 6-Core-CPUs der 5600er-Serie mit bis zu 192 GByte RAM. Sechs oder acht 2,5-Zoll-Festplattenschächte warten auf SATA- oder SAS-Platten.

Abbildung 5: Vom 19-Zoll-Server bis zum Wandschrank reicht das Angebot von Fujitsu, hier der unspektakuläre, eine Höheneinheit dicke Server RX 200.
Selbst entworfener Superrechner für 6000 Euro
Weit mehr als nur eine Handvoll Cores finden sich auf aktuellen Grafikkarten – in der Regel über hundert. Diese Rechenpower lässt sich für allerhand parallelisierbare Berechnungen auch abseits der Grafikausgabe verwenden. Der Hersteller Nvidia hat zu diesem Zweck die Compute Unified Device Architecture (Cuda) geschaffen und stellt passende Programmiertools zur Verfügung. Wie Entwickler die nutzen, erläutert der GPU-Computing-Artikel in diesem Magazin-Schwerpunkt. Mit Open CL [7] gibt es auch einen herstellerübergreifenden Standard für das Rechnen auf der Grafikkarte, an dem zum Beispiel AMD und Apple mitwirken.
Eine leistungsfähige Grafikkarte wie die Nvidia Geforce GTX275 besitzt 240 parallel arbeitende Prozessoren und bringt es beinahe auf 1 Teraflop Rechenleistung. Einige Forscher am Vision Lab der Universität Antwerpen haben 13 solcher GPUs in ein Gehäuse gesteckt, um die Rechenpower von 12 Teraflops zu erhalten, die sie für die hochauflösende Darstellung der feinen Knochenstrukturen in computertomografischen Aufnahmen benötigen. Das Budget für einen echten Supercomputer hatten sie nämlich beileibe nicht zur Verfügung.
Deshalb nicht verlegen, verbauten sie sechs Mal die Doppel-GPU-Karte GTX295 und ein Mal die GTX275 von Nvidia. Um die sieben Komponenten in einem Towergehäuse unterzubringen, ließen sich die Uni-Mitarbeiter vom Hersteller Asus und dem belgischen Händler Tones helfen. Die PCI-2.0-Express-Anbindung der Karten realisierten sie mit Flachbandkabeln. Zur Stromversorgung dienen vier Netzteile, und die Kühlung des Fastra II benannten Rechners ist ebenfalls eine Herausforderung (Abbildung 6).

Abbildung 6: Beim belgischen Forschungsrechner Fastra II stecken sieben Hochleistungs-Grafikkarten in einem PC-Gehäuse, das sie mit einem speziellen Käfig stabilisieren mussten.
Ein extra Patch für den Linux-Kernel
Um das Gerät zum Laufen zu bringen, war zudem ein von Asus maßgeschneidertes 64-Bit-Bios und ein Patch gegen den Linux-Kernel 2.6.29.1 erforderlich. Beides gibt es auf den Fastra-II-Seiten zum Download [11].
Das Vision Lab rühmt sich, damit den schnellsten Rechner weltweit im PC-Format zu besitzen, der mit 1200 Watt weniger Energie als ein 512-Kern-Cluster aus regulären CPUs verbraucht, der 90 000 Watt schluckt. Mitte 2008 wäre das System noch auf der Top-500-Liste der Supercomputer gelandet.
Im Gegensatz zu deren Gleitkomma-Genauigkeit von 64 Bit bietet der Antwerpener Bolide jedoch nur 32 Bit. Dafür haben ihn die Universitätsmitabeiter zum Selbstbau-Preis von rund 6000 Euro zusammengeschraubt – ein Schnäppchen im Vergleich zu vielen Konkurrenten.
Tesla mit 64-Bit-Arithmetik
Statt 32 Bit wie beim Fastra gibt es 64-Bit-Präzision mit Nvidias Ultra-Highend-Karte Quadro FX 5800 [12] und in der Tesla-20-Reihe, die der Hersteller von Grund auf für Hochleistungsberechnungen entwickelt hat (Abbildung 7). Zum Preis des Fastra II darf der Kunde bei den Tesla-Komplettsystemen allerdings nur eine Maschine mit lediglich zwei Tesla-10-Karten und insgesamt rund 2 TFlop Rechenleistung erwarten [13]. Die weiteren Ausbaustufen erstrecken sich vom stärkeren Personal Supercomputer mit vier Karten bis zum Clustersystem, das in Racks unterkommt.

Abbildung 7: Nicht für Grafikausgabe, sondern fürs Hochleistungsrechnen entwickelt: Nvidias Tesla-20-Karte schafft rund 1 Teraflop Rechenpower.
Um in den Genuss der Cuda-Technologie zu kommen, muss der Anwender nicht unbedingt selbst zum Compiler greifen. GPU-Beschleunigung gibt es unter anderem für Matlab, Mathematica und die freie Statistiksoftware R [14]. Daneben listet Nvidia auf einer eigenen Seite [15] weitere kommerzielle Anwendungen aus Bereichen wie GIS, Chemoinformatik, Bioinformatik, Finanzwesen und medizinischer Bildgebung auf.
|
Buildfarmen bei |
|---|
|
Von Anwendern unbeachtet stellt das Übersetzen und Zusammenstellen ihrer Software die Mitglieder großer Open-Source-Projekte oft vor erhebliche Aufgaben. Der Zweitaufwand für jeden Komplett-Build steht und fällt nicht wie in den Anfangsjahren von Linux mit der Schnelligkeit der benutzten Festplatten, sondern mit der CPU-Leistung. Darum schlägt ein Hauch HPC auch bei freien Großprojekten positiv zu Buche. Das Linux-Magazin hat sich bei prominenten Projekten umgehört, wie und womit sie diesen Job organisieren. Überraschend schlank: KDEVergleichsweise moderat gehts bei KDE zu, denn das Projekt veröffentlicht nur Source-, keine Binärpakete. Die bauen nämlich die Distributionen selbst. Trotzdem plant das Projekt regelmäßige Builds und Tests von der gesamten KDE Software Collection, einzelne Mitglieder wie C. Dirk Müller betreiben eigenständige Builds [8]. Ein Nightly Build aller KDE Module auf allen unterstützten Plattformen plant KDE auf [http://my.cdash.org] einzurichten. Die knapp 5 Millionen Zeilen Code baut das Projekt für Linux, Solaris, einmal mit dem Sun-Studio-Compiler und meistens auch noch für Free BSD, alles über Cmake angesteuert. Das Release für Linux benötigt dabei auf einem Quadcore Intel Core2 etwa 4 Stunden. Sprachtalent: Open OfficeEiniges mehr an Aufwand als KDE muss sich OpenOffice.org machen. Das Projekt baut jeden Meilenstein einmal komplett durch. Das passiert je nach Zahl der Änderungen rund einmal pro Woche. Die Entwickler pflegen je eine Codebase für das aktuelle Release und die aktiven Änderungen, in die die Entwickler ihre privaten Branches einpflegen, wenn sie die Qualitätskontrolle überwunden habe. Eine Besonderheit ist der Umfang der sprachabhängigen Teile. So kennt Open Office rund 70 Sprachen und ungefähr zehn Zielplattformen für Linux, Solaris, Mac OS X und Windows sowie exotischerer Umgebungen wie OLPC/Sugar, Haiku-OS oder für den ARM-Prozessor. Aus den rund 7 Millionen Zeilen C++-, Java-, Python- und Perl-Code baut die Buildfarm rund 45 Pakete für die beiden Unix-Plattformen. Oracle als Gastgeber der Entwicklung nutzt ein selbst geschriebenes, plattformübergreifendes Buildsystem. Die meisten Programmierer selbst greifen zu Icecream, um ihre Builds korrekt zu verteilen [9]. Das Open-Office-Projekt pflegt darüber hinaus noch einen kleinen Zoo aus so genannten Buildbots, die die Community dazu nutzt, um kleinere Releases zu bauen. Jeder Buildbot läuft auf einer eigenen Maschine und benötigt auf einem Quadcore mit zwei fixen Raid-0-Festplatten weniger als eine Stunde für eine Sprache, für Windows bemerkenswerterweise doppelt so lange. An einem kompletten Release mit allen Sprachen knabbert ein gut ausgestatteter Heim-PC schon einen ganzen Tag. Die Entwickler nennen eine schnelle Festplatte und möglichst viele Prozessoren als wichtige Kenngröße. Mit dem Hauptspeicher hatten die Open-Officeler bislang kaum Scherereien. Wenn sich das anbietet, nutzt das Projekt sogar virtualiserte Hardware. Mächtig groß: Open SuseUm die Distribution jederzeit konsistent zu halten, übersetzt Open Suses Build Service ein Paket neu, sobald sich abhängige Pakete ändern. Die Dependencies löst die Umgebung eigenständig auf. Es sind nur etwa 40 Pakete, die in der Praxis einen kompletten Rebuild auszulösen vermögen, zum Beispiel die Glibc oder die Bash. Das passiert ungefähr zweimal pro Woche. Open Suse baut aus 3500 Quelltextpaketen rund 15 000 Binärpakete auf der i586- und x86_64-Plattform. Daraus stellen weitere Schritte eine Gnome- und eine KDE-Live-CD, eine Installations-DVD und eine Net-Install-CD pro Architektur zusammen. Zusätzlich baut die Open-Suse-Instanz des Build Services auch noch Pakete anderer Projekte (siehe Abbildung 3), die diesen Dienst in Anspruch nehmen [10]. Die Betreiber beziffern das auf mehr als 12 000 Projekte mit rund 93 000 Source-Paketen und 23 000 Entwicklern. 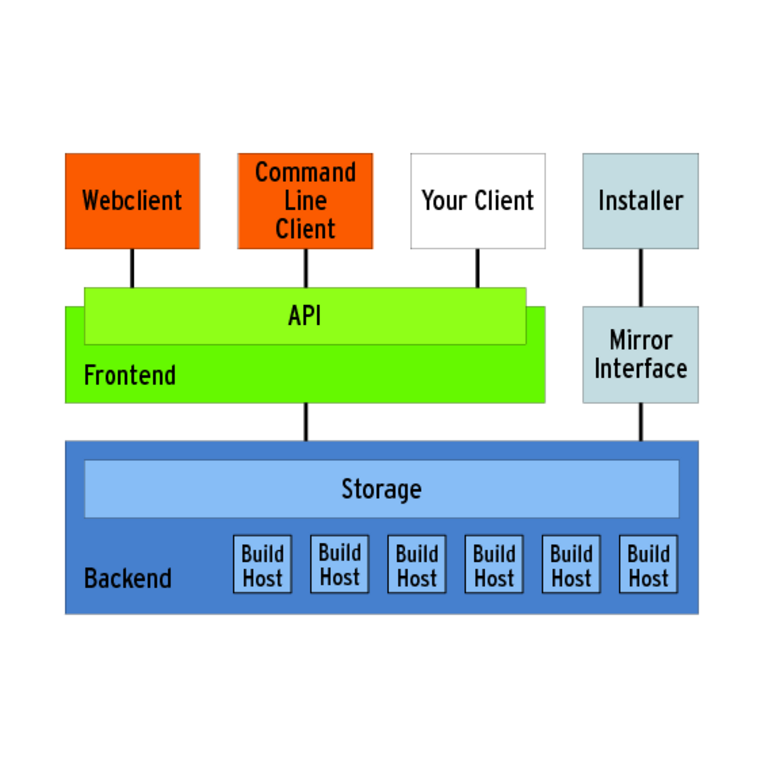 Abbildung 3: Den Buildservice von Open Suse nutzt nicht nur das eigene Projekt. Über Schnittstellen und gehostete Dienste dürfen auch andere Projekte ihre Software für eine Reihe von Architekturen und Distributionen bauen. Die Architektur des Build Services teilt sich strikt in klassische Clients, die über das API das Backend steuern. Die Komponenten kommunizieren über HTTP und lassen sich auch verteilt aufsetzen. Den eigentlichen Build erledigen rund 200 Clients verschiedenster Hardware. Das Bauen passiert in virtuellen Maschinen, so genannten Workern. Ein durchschnittlicher Arbeiter entspricht einem 2-GHz-AMD-Opteron mit 1 GByte RAM und einer 250-GByte-Festplatte. Mit dieser Armada dauert ein kompletter Rebuild im Schnitt 40 Stunden. Spätestens hier wird klar: Die Open-Suse-Instanz des Build Service im Suse-Rechenzentrum in Nürnberg ist eine verteilte und sehr rechenintensive Anwendung. Nils Magnus |
Möglichst parallel
Egal ob GPU oder CPU: Damit der Anwender von der leistungsfähigeren Hardware profitiert, muss die Software mitspielen, sprich aus parallelisierbaren Teilen bestehen. Auf Systemen mit gemeinsamem Speicher erreicht man das durch standardisierte Programmierschnittstellen wie Open MP, die für die Sprachen C, C++ und Fortran zur Verfügung steht [16], [17]. (Solche APIs, parallele Dateisysteme, Cluster-geeignete Linux-Distributionen und ähnliches Handwerkszeug beschreibt der folgende Artikel.) Daneben können junge Sprache wie Clojure oder Neuauflagen wie C++0x ebenfalls die Vorteile der Mehrkerntechnik nutzen.
Allerdings eignen sich nicht alle Abschnitte eines Programms zur Parallelisierung, es bleiben seriell abzuarbeitende Teile übrig. Sind von einem Programm beispielsweise 80 Prozent parallelisiert, läuft es auf einer Vierkern-CPU nicht wie erwartet viermal so schnell wie auf einem einzelnen Kern, sondern nur um den Faktor 2,5 schneller. Dieses Phänomen ist als Amdahlsches Gesetz in die Informatik eingegangen [18]. Kleiner Trost: Für echte Supercomputer gilt das Gesetz natürlich auch – nur dass der Effekt dort weit mehr ins Geld geht als bei Hardware von der Stange.





