
© Orlando Florin Rosu, fotolia.com
Kaum ein Thema trennt Entwickler so nachhaltig wie die Frage nach der besten Programmiersprache. Typisierung, Datenstrukturen, Freiheit in der Syntax oder Kürze des Code halten als Argumente her. Das Linux-Magazin hat prominenten Protagonisten von fünf populären Sprachen die gleiche Aufgabe gestellt.
Kleine Scharmützel am Entwicklerstammtisch zwischen den Anhängern unterschiedlicher Progammiersprachen sind zwar meist unterhaltsam, verlaufen aber in der Regel ergebnislos. Wirklich vereint ernsthafte Entwickler nur die allerletzte Erkenntniss, dass die Frage nach der einen, der einzigen, der universellen Programmiersprache eher akademischer Natur ist. Allgemeine Zustimmung findet da meist auch die These, dass sich unterschiedliche Sprachen für manche Anwendungsszenarien besser oder schlechter eignen als andere.
Um in diesen Sprachverwirrungen einen Überblick zu gewinnen, hat das Linux-Magazin prominente Entwickler gebeten, eine überschaubare Programmieraufgabe in ihrer Lieblingssprache zu lösen. Gefordert war, eine Textdatei neu zu sortieren, deren Fußnoten durcheinandergeraten sind (siehe Kasten “Die Spezifikation der Aufgabe”). Der Algorithmus zur Lösung sollte keinen Sprachpapst vor unlösbare Herausforderungen stellen, und die Teilnehmer sollten sich weniger in einem Programmierwettbewerb wähnen, sondern sich eher als Botschafter der Konzepte der unterschiedlichen Sprachen verstehen. Aus diesem Grund durften sie die Aufgabenstellungen in einem gewissen Grad variieren, wenn sie das glaubhaft rechtfertigen konnten.
Primär war also nicht, wer die Aufgabe mit den wenigsten Zeilen löst oder welcher Code am schnellsten läuft, sondern wie die in den Sprachen angelegten Denkmodelle sich in den Lösungen niederschlagen.
|
Die Spezifikation der |
|---|
|
Ein Text möge ungeordnete Fußnoten enthalten. Am Ende des Textes folgt ein getrennter Abschnitt, der auf die Verweise im Text Bezug nimmt. Jede Fußnote zeigt genau zu einem Verweiseintrag, es darf jedoch mehrere Fußnoten geben, die auf den gleichen Eintrag verweisen. In der Eingabedatei sind sowohl Fußnoten als auch die Verweiseinträge am Textende ungeordnet, beide beginnen nicht notwendigerweise mit 1, die Reihenfolge darf Lücken aufweisen. Die Lösung ist ein Programm, das die Fußnoten aufsteigend nummeriert. FormatDie Eingabedatei besteht aus Text, kodiert im Format ISO-8859-15, und enthält Fußnoten der Form »[13]«. Die Fußnoten dürfen überall im Text stehen, allerdings steht der Verweis immer ungetrennt auf einer Zeile. Die eigentlichen Einträge folgen am Ende des Textes nach der Markierung »@footnote:«. Alle Nummern in eckigen Klammern nach dem Marker sind folglich Verweisziele, keine Verweise. Beispiel:A great brown fox [13] jumped of a pile of lorem ipsum [4], [7]. He met with a silver penguin, browsing the Linux Kernel Mailinglist [3]. They debated other the question whether to start a C-program with "main (int argc, char **argv)" or with "main (int argc, char *argv[])". Square brackets annoyed them [9999]. @footnote: [13] Al Fabetus: "On characters and animals", 1888, self published. [4] Lorem Ipsum, <a href="http://en.wikipedia.org/wiki/Lorem_ipsum">UWeb Link</a> [9999] Annoying Link. [7] B. Fox: "More on Blind Text". [3] Linux Kernel Maintainers: LKML Die Aufgabenstellung bearbeitet eine einzelne Textdatei, deren Namen ihr der Anwender als Aufrufparameter nennt. Das Ergebnis dazu erhält er direkt auf der Standardausgabe. Die Texte können von sehr unterschiedlicher Länge sein, angefangen von einigen wenigen KBytes bis hin zu mehreren Hundert MBytes. Die Nummerierung der Implementierung soll einer der beiden folgenden Varianten folgen oder beide ermöglichen:
|
Fünf Kandidaten auf dem Prüfstand
Ins Feld zogen schließlich PHP, Perl, Java, Python und Java FX. Gern hätte die Redaktion auch Ruby und andere antreten lassen, allein es erklärten sich keine VIPs dafür bereit. Alle Lösungen, die dieser Artikel in der Reihenfolge ihres Eingangs in der Redaktion präsentiert, konnten die geforderte Aufgabe lösen, auch wenn einzelne Entwickler kleine Modifikationen vorgenommen haben. Der Test bewertet dabei aber nicht nur die programmiertechnische Korrektheit, sondern auch den Ressourcenverbrauch des Programms.
Ein Thinkpad X60s im 32-Bit-Modus unter einem Intel Core Duo L2400 mit 1,6 GHz diente als Testsystem. Den vorhandenen üppigen Speicherausbau von 3 GByte schöpfte allerdings keines der Programme aus. Für die Messung zogen die Tester eine 55 MByte große Datei heran, in die sie eine Million zufällige Fußnoten eingetragen hatten.
PHP
PHP ist eine für Webanwendungen optimierte Skriptsprache mit einer C-ähnlichen Syntax, die als vergleichsweise leicht zu erlernen gilt [1]. Die Sprache ist schwach typisiert, seit Version 4 (ab Mitte 2000) enthält PHP erste Sprachkonstrukte für objektorientierte Programmierung, die Version 5 (ab Mitte 2004) vervollständigt.
Viele verbreitete Webanwendungen wie Typo3 [2], WordPress [3] oder Joomla [4] sind in PHP geschrieben. Der Repository-Crawler Ohloh.net [5] bescheinigt der Sprache mit 107 Kernentwicklern eines der größten Teams in der Open-Source-Welt. Als Mängel gelten Inkonsistenzen der Syntax wie unterschiedliche Parameterreihenfolgen bei Funktionen mit ähnlicher Aufgabe, das fehlen eines Bytecode-Cache, fehlende Thread-Sicherheit, was den Einsatz des Apache-MPM Worker ausschließt, sowie die erst für Ende 2008 in Version 6 erwartete durchgängige Unicode-Untersützung [6].
Der Einsender der PHP-Lösung, Zeev Suraski (siehe Abbildung 1), entwickelte 1998 zusammen mit Andi Gutmans PHP 3, das auf der Konzeption von Rasmus Lerdorf basierte.

Abbildung 1: Zeev Suraski gründete zuammen mit Andi Gutmanns die Firma Zend, die nach wie vor treibende Kraft hinter PHP ist.
Zeev Suraski: In einem Zug zur Lösung
1999 gründete er mit Gutmans Zend Technologies [7]. Die Firma ist seit PHP 4 die treibende Kraft bei der Entwicklung und bietet kommerzielle Produkte für PHP an, etwa das Zend-Klassenframework oder die beschleunigende Laufzeitumgebung Zend Optimizer.
Shahar Evron hat ihn beim Erstellen seiner Lösung unterstützt. Das Skript (Listing 1) durchläuft den Text zunächst zeilenweise und nummeriert die Fußnoten mit Hilfe eines regulären Ausdrucks neu, der bei jedem Treffer eine Callback-Funktion aufruft (»handleTextBlock()«, Zeile 41 bis 58). Eine Konversionstabelle (das Array »$_table()« aus der Klasse »Footnotes«, Zeilen 89 bis 130) sorgt dafür, dass mehrfache Verweise auf dieselbe Fußnote die gleiche Nummer erhalten.
|
Listing 1: |
|---|
001 <?php
002 /**
003 * Read text with footnotes, reorder the footnote numbers
004 * starting from 1. Written-for and tested on PHP 5.2.6.
005 **/
006
007 // PHP is typically configured for short-lived Web page rendering
008 // applications. Since this app may potentially be working on very
009 // large data sets, remove execution time limits, and increase
010 // maximum memory consumption.
011 ini_set('max_execution_time', 0); ini_set('memory_limit', '512m');
012
013 // Handle command line
014 if (isset($_SERVER['argv'][1])) {
015 $filename = $_SERVER['argv'][1];
016 } else {
017 $filename = 'php://stdin';
018 }
019
020 // Open input file
021 $infp = fopen($filename, "r");
022 if (!$infp) {
023 exit("Unable to open '$filename' for input.n");
024 }
025
026 // Handle conversion
027 handleTextBlock($infp);
028 handleFootnotesBlockInMemory($infp);
029
030 // Close input stream and terminate (not strictly necessary)
031 fclose($infp);
032 exit();
033
034 /// Utility functions (can be in a separate file) ///
035 /**
036 * Read text block and reorder the footnotes as we go (automatically
037 * maintains a translation table from old footnote numbers to new ones)
038 *
039 * @param fileStream $infp
040 */
041 function handleTextBlock($infp)
042 {
043 define('FOOTNOTE_HEADER', '@footnote:');
044 define('FOOTNOTE_HEADER_LENGTH', strlen(FOOTNOTE_HEADER));
045
046 while ($line = fgets($infp)) {
047 // Convert footnotes
048 $line = preg_replace_callback('/[(d+)]/',
049 'Footnotes::replaceCallback',$line);
050 // Print output
051 echo $line;
052 // Stop if we reached the footnote target section
053 if ($line[0]=='@' && strncmp($line, FOOTNOTE_HEADER,
054 FOOTNOTE_HEADER_LENGTH)==0) {
055 break;
056 }
057 }
058 }
059
060 /**
061 * Handle reordering of the footnotes in-memory
062 * @param fileStream $infp
063 */
064 function handleFootnotesBlockInMemory($infp)
065 {
066 // Reorder footnotes if needed, and print them out
067 $footnoteTargets = array();
068 // Iterate over footnote lines
069 while ($line = fgets($infp)) {
070 // If line doesn't seem to be a footnote, print as-is
071 if ($line[0] != '[') {
072 echo $line;
073 continue;
074 }
075
076 // Get the footnote key (number) and value (text)
077 list($key, $val) = explode(' ', $line, 2);
078 $key = Footnotes::translate(trim($key, '[]'));
079
080 $footnoteTargets[$key] = $val;
081 }
082
083 $numFootnotes = count($footnoteTargets);
084 for ($i=1; $i<=$numFootnotes; $i++) {
085 echo "[$i] ", $footnoteTargets[$i];
086 }
087 }
088
089 class Footnotes
090 {
091 /**
092 * Table of footnote number conversion
093 *
094 * @var array
095 */
096 static protected $_table = array();
097
098 /**
099 * Footnote counter
100 * @var integer
101 */
102 static protected $_count = 0;
103
104 /**
105 * Translate a given footnote number according to the translation
106 * table. If the footnote numer is encountered for the first time,
107 * a new entry will be added to the conversion table
108 *
109 * @param integer $number
110 * @return integer
111 */
112 static public function translate($number)
113 {
114 if (! isset(self::$_table[$number])) {
115 self::$_table[$number] = ++self::$_count;
116 }
117 return self::$_table[$number];
118 }
119
120 /**
121 * A callback function wrapping self::translate() for use with
122 * preg_replace_callback
123 * @param array $match
124 * @return string
125 */
126 static public function replaceCallback($match)
127 {
128 return '[' . self::translate($match[1]) . ']';
129 }
130 }
|
Blockweises Lesen
Die Klassenfunktion »translate« prüft, ob die im Text stehende Fußnotennummer bereits in »$_table[]« enthalten ist. Ist das der Fall, gibt sie die vorige Nummer zurück, wenn nicht, erhöht sie den Zähler für die Fußnotennummer (»$_count«, Zeile 115) und schreibt ihn als neuen Eintrag in das Array »$_table[]«.
Das Skript liest den Text über die Funktion »fopen()« ein (Zeile 21) und iteriert mit einer While-Schleife über die Eingabezeilen (Zeile 46). Suraski weist darauf hin, dass das gleichzeitige Einlesen von 1000 Zeilen die Performanz des Skripts um etwa 25 Prozent verbessern würde, er jedoch zugunsten der Übersichtlichkeit auf diese Optimierung verzichtet habe.
Die Hauptarbeit bei der Sortierung bildet der Aufruf der PHP-Funktion »preg_replace_callback()« in Zeile 48. Die Funktion arbeitet mit Perl-kompatiblen regulären Ausrücken und sucht nach von eckigen Klammern eingeschlossenen Ziffern.
Eine Callback-Funktion ist nötig, da es zwei Fälle zu unterscheiden gilt: Entweder die im Text gefundene Fußnote trägt eine Nummer, die bereits vorgekommen ist, dann gibt die Funktion »translate()« (Zeilen 112 bis 118) diese unverändert zurück. Oder die Fußnotennummer ist noch nicht vorgekommen, dann gibt »translate()« die um eins erhöhte Nummer der letzten Fußnote zurück und schreibt sie für die zukünftige Prüfung in das Array »table[]«. Die eigentliche Callback-Funktion »replaceCallback()« kapselt dabei »translate()«. Zeile 51 gibt die Zeile mit angepassten Fußnotennummern aus.
Zwischenziel
Ist beim Durchlauf durch den Text das Token »@footnote:« erreicht, bricht Zeile 55 die »while()«-Schleife ab. Nun ist die Funktion »handleFootnotesBlockInMemory()« (Zeilen 64 bis 87) dafür zuständig, die Fußnotentexte am Textende in die richtige Reihenfolge zu bringen. Sie filtert zunächst Zeilen aus, die nicht mit »[« beginnen, bei denen es sich also nicht um Fußnoten handelt.
Zeile 77 teilt die Zeile mit der String-Funktion »explode()« am ersten Leerzeichen in Fußnotennummer und Fußnotentext. Das Array aus den zwei Teilstrings, das »explode()« liefert, teilt »list()« den Variablen »$key« und »$value« zu. Die Methode »translate()« der Klasse »Footnotes« gibt, nachdem »trim()« die Fußnotennummer in »$key« von den umgebenden Klammern befreit hat, die neue Nummer der Fußnote zurück.
Das Array »$footnoteTargets[]« speichert den Fußnotentext schließlich unter dem Key der bereinigten Nummer, sodass eine Schleife über dieses Array die Fußnoten sortiert ausgeben kann (Zeilen 84 bis 86). Auf eine Ausnahmebehandlung verzichtet das Skript. PHP 5 verfügt allerdings über die aus anderen Sprachen bekannten Konstrukte »try{}« und »catch()«.
Wenig Speicherbedarf
In der vorliegenden Form benötigt das PHP-Skript auf dem eingangs beschriebenen Testsystem etwa 36 Sekunden, um einen 55 MByte großen Text zu verarbeiten. Zeev Suraski nennt allerdings noch mehrere Optimierungsmöglichkeiten. Unter anderem wäre es bei langen Fußnotentexten effizienter, nicht den Text selber zwischenzuspeichern, sondern lediglich den Offset der Fußnoten im Ausgangstext. Der Speicherverbrauch lag bei etwa 170 MByte realem und 180 MByte virtuellem RAM.
Java
Das objektorientierte Java geht auf die kalifornische Firma Sun Microsystems zurück [8]. Sie wollte Anfang der 1990er Jahre eine Programmiersprache für das Internet entwickeln. Unter der Führung von James Gosling sammelten die Ingenieure viele Eigenschaften eines halben Dutzends populärer Programmiersprachen zusammen. Das Projekt trug zuerst den Namen Oak, später Java. Sprachhistoriker entdecken heute reichhaltige Klassenstrukturen wie bei ADA, eine syntaktische Anmutung, die an Objective-C erinnert und sogar Anleihen an das Lambda-Kalkül aus Scheme und Lisp.
Ein Compiler übersetzt den Java-Quelltext in einen Bytecode, den eine virtuelle Maschine in einer Laufzeitumgebung interpretiert. Der anfängliche Hype um den Einsatz im Netz hat sich ein wenig gelegt, die wenigsten Java-Anwendungen sind für den Einsatz direkt im Browser konzipiert.
Dagegen hat sich die Sprache im geschäftlichen Umfeld einen Namen gemacht. Starke Typisierung, leistungsfähige Klassenbibliotheken und nicht zuletzt gute Entwicklungsumgebungen wie Eclipse [9] oder Netbeans [10] haben zu ihrer weiten Verbreitung beigetragen. Java läuft durch den Ansatz der virtuellen Maschine auf einer Vielzahl von Plattformen und gilt daher vielen als Inbegriff der Portabilität. Versionen für Linux gibt es schon lange, seit gut einem Jahr auch unter einer freien Lizenz [11].
James Gosling: Gut sortiert
James Gosling (siehe Abbildung 2) ist ein Pionier auf mehreren Gebieten der Computergeschichte. Der bei Sun Microsystems als CTO der Produktentwicklergruppe beschäftigte Kanadier hat sich schon auf mehreren Gebieten profiliert. Er hat grafische Fenstersysteme und Editoren entwickelt, aber auch eine Menge zu dem beigetragen, was Java heute auszeichnet. Für das Linux-Magazin hat er eine Lösung der Programmieraufgabe in reinem Java beigesteuert.

Abbildung 2: Für James Gosling stand bei seiner eingereichten Lösung des Fußnoten-Problems die Klarheit des Quelltextes im Mittelpunkt.
Erwartungsgemäß besteht seine Variante (siehe Listing 2) – wie immer in der objektorientierten Programmiersprache – aus einer eigene Klasse. Los geht’s in der öffentlichen Methode »main()«. In einem Try-Block erzeugt die Methode zunächst eine einzelne Instanz »doc« ihrer eigenen Klasse, liest die Daten durch Aufruf von »doc.load()« ein, sortiert sie durch »doc.reorder()« und gibt sie schließlich mittels »doc.dumpDocument()« wieder aus. Dieses Einlesen der Textdatei kann als Sinnbild für Wohl und Wehe von Java gelten: Nur um die Standardeingabe in einen großen String im Speicher einzulesen, musste Gosling vier Klassen instanzieren.
Bei einem »BufferedInputStream«, einem »InputStreamReader«, einem »BufferedReader« und dem »StringBuilder« finden sich Neulinge nur mit Mühe zurecht. Zum Vergleich: Perl realisiert die gleiche Aufgabe durch die zwei simplen Zeichen »<>«. Aber der Vergleich hinkt natürlich etwas, da sich jede Java-Klasse in vielen Einzelaspekten sehr fein anpassen lässt. Schön präsentiert sich dagegen in der Methode das Konzept der Ausnahme, »Exception« in der Java-Sprache.
Da sie die komplette Methode umfasst, muss sich der Entwickler in ihr nicht mehr um lästige Checks kümmern, zum Beispiel darum, ob die Dateien lesbar sind oder ob der Eingabetext korrekt geformt ist.
|
Listing 2: |
|---|
01 /**
02 *
03 * @author James Gosling
04 */
05 import java.io.*;
06 import java.util.*;
07 import java.util.ArrayList;
08 import java.util.regex.*;
09
10 public class BibReorder {
11 String[] parts;
12 DocumentFragment[] documentBody, bibliography;
13 static Pattern bibRefPattern = Pattern.compile("\[([0-9]+)\]");
14 public static void main(String[] args) {
15 try {
16 BibReorder doc = new BibReorder();
17 boolean byFirstOccurrance = false;
18 boolean processed = false;
19 for(String s:args)
20 if("-f".equals(s)) byFirstOccurrance = true;
21 else {
22 processed = true;
23 doc.load(new FileInputStream(s));
24 doc.reorder(byFirstOccurrance);
25 doc.dumpDocument();
26 }
27 if(!processed) {
28 doc.load(BibReorder.class.getResource("sample. Data").openStream());
29 doc.reorder(byFirstOccurrance);
30 doc.dumpDocument();
31 }
32 } catch (IOException ex) {
33 System.err.println("Error reading file: "+ex);
34 }
35 }
36 void load(InputStream in) throws IOException {
37 Reader inc = new BufferedReader(new InputStreamReader(new BufferedInputStream(in)));
38 StringBuilder sb = new StringBuilder();
39 int c;
40 while((c=inc.read())>=0) sb.append((char)c);
41 parts = sb.toString().split("@footnote:");
42 if(parts.length!=2) throw new IOException("Must have exactly 2 parts");
43 documentBody = parseDocumentPart(parts[0]);
44 bibliography = parseDocumentPart(parts[1]);
45 in.close();
46 }
47 void reorder(boolean byFirstOccurrance) {
48 int slot = 0;
49 if(byFirstOccurrance) {
50 for(DocumentFragment p:documentBody)
51 if(p.tag!=null && p.tag.sequenceNumber==0) p.tag.sequenceNumber = ++slot;
52 Arrays.sort(bibliography, new Comparator<DocumentFragment>(){
53 public int compare(DocumentFragment o1, DocumentFragment o2) {
54 return (o1.tag==null ? 0 : o1.tag.sequenceNumber)-(o2.tag==null ? 0 : o2.tag.sequenceNumber);
55 }
56 });
57 } else
58 for(DocumentFragment p:bibliography)
59 if(p.tag!=null) p.tag.sequenceNumber = ++slot;
60 }
61 void dumpDocument() {
62 dumpDocumentPart(documentBody, parts[0]);
63 System.out.append("@footnote:");
64 dumpDocumentPart(bibliography, parts[1]);
65 }
66 DocumentFragment[] parseDocumentPart(String s) {
67 Matcher m = bibRefPattern.matcher(s);
68 DocumentFragment prev = new DocumentFragment(0,null);
69 ArrayList<DocumentFragment> pieces = new ArrayList<DocumentFragment>();
70 pieces.add(prev);
71 while(m.find()) {
72 prev.end = m.start(0);
73 String tlabel = s.substring(m.start(1),m.end(1));
74 BibliographyTag t = tags.get(tlabel);
75 if(t==null) { t = new BibliographyTag();
76 tags.put(tlabel, t); }
77 prev = new DocumentFragment(m.end(0),t);
78 pieces.add(prev);
79 }
80 prev.end = s.length();
81 return pieces.toArray(new DocumentFragment[pieces.size()]);
82 }
83 void dumpDocumentPart(DocumentFragment[] pieces, String part) {
84 for(DocumentFragment p:pieces) {
85 if(p.tag!=null) System.out.print("["+p.tag.sequenceNumber+"]");
86 System.out.append(part,p.start,p.end);
87 }
88 }
89 class DocumentFragment {
90 int start, end;
91 BibliographyTag tag;
92 DocumentFragment(int st, BibliographyTag t) { start = st; tag = t; }
93 }
94 class BibliographyTag { int sequenceNumber; }
95 HashMap<String,BibliographyTag> tags = new HashMap<String, BibliographyTag>();
96 }
|
Großzügig mit dem Speicher
Gosling zerlegt den String im Speicher mittels einer Regular Expression, die er in einer Instanz von »Pattern« erst einmal übersetzen und vorbereiten muss. Er iteriert durch den String, sucht sich das Auftreten der einzelnen Matches heraus und speichert sie in einem Template von »ArrayList«. Es fällt auf, wie viele Klassen im Java-JDK bereits vorhanden sind – Gosling macht reichlich Gebrauch von ihnen. “Ich habe einen ganz direkten Ansatz gewählt”, schreibt er zu seiner Lösung. Er gibt aber auch zu: “Der Code hätte auch kürzer sein können, ich habe mehr Methoden verwendet als notwendig. Sie sind dort, um Klarheit zu schaffen.”
Der Lösungsansatz illustriert das Denkschema der Java-Entwickler. Gosling schreibt: “Die Problemstellung besagte, dass die Eingabedaten mehrere Hundert Megabytes umfassen könnten. Auf heutigen Systemen ist das gar nichts. Daher habe ich auch alles in den Hauptspeicher geladen.”
Entsprechend groß war der Memory-Footprint des Skripts beim Testlauf mit einer Million Fußnoten: 900 MByte virtueller Speicher reservierte sich die virtuelle Maschine zu Beginn, auch die dann tatsächlich genutzten 300 MByte sprechen eine deutliche Sprache.
Perl
Die Skriptsprache Perl [12] hatte ihr Erfinder Larry Wall bereits Ende der 1980er Jahre konzipiert. Sie ist wegen ihrer Fähigkeit, Texte mit wenig Aufwand zu verarbeiten, bei Administratoren nach wie vor sehr beliebt. Perl zeichnet sich dadurch aus, dass es schnell Ergebnisse liefert: Die Syntax ist sehr kompakt und kennt unzählige Operatoren und Funktionen, nicht zuletzt dank des Comprehensive Perl Archive Network (CPAN, [13]), das viele Erweiterungen enthält.
Jedoch haben die Entwickler der Sprache häufig das Ziel verfolgt, typische Anwendungsfälle von Administratoren zu antizipieren. Das führt zu kompakterem Code, der allerdings oft schwer lesbar ist. Perl interpretiert den Code und übersetzt ihn zur Laufzeit in einen Zwischencode. Dabei erreicht es oft eine für interpretierte Sprachen überraschende Leistung.
Typenvielfalt
Die Datenstrukturen von Perl sind einfach, die Sprache ist schwach typisiert, sodass der Programmierer jeder Variablen fast alle Objekte zuweisen darf.
Perl kennt Skalare, die sowohl Zahlen als auch Strings umfassen, und Listen. In ihrer Inkarnation als Arrays lassen sie sich dynamisch erweitern, in ihrer Form als Hashes oder assoziative Arrays erlauben sie sogar beliebige Objekte als Schlüssel, um auf Elemente zuzugreifen.
Die Datenstruktur der Referenz und das objektorientierte Modell von Perl kritisieren Skeptiker als ein wenig konstruiert und warten seit mehreren Jahren auf Version 6, die die bekannten Probleme endlich lösen soll. Wesentlich zum Erfolg von Perl trägt die Implementierung von Regular Expressions bei, die sie eng in die Sprache integriert.
Wer Perl kennt, kennt zumeist auch das so genannte Camel-Book, das Randal L. Schwartz (siehe Abbildung 3) maßgeblich mitverfasst hat. Es gilt als unerlässliches Einsteigerwerk in die Skriptsprache. Neben zahlreichen anderen Perl-Büchern kümmert sich Schwartz vor allem in Kolumnen, auf Konferenzen und in Form der Perl-Mongers, einer weltweiten Benutzerorganisation von Perl-Anwendern, um die Community.

Abbildung 3: In der Perl-Welt ein Begriff: Randal L. Schwartz hat mit seinem so genannten Camel-Book die ultimative Einsteigerlektüre geschrieben.
Randal L. Schwartz: Alternative Tabellen
Schwartz lieferte die kürzeste aller eingesandten Lösungen ab. In den 50 Codezeilen von Listing 3 liest er ab Zeile 13 zunächst den Textteil ein und speichert ihn zeilenweise in der Liste »@parsed«. Enthält eine Zeile eine Fußnote, trennt er sie vom umschließenden Text (Zeile 18) und speichert eine Referenz auf ein assoziatives Array (Zeile 20). Erreicht das Programm die Markierung »@footnote«, befüllt es die bereits angelegten Datenstrukturen mit dem Text der Referenzen (Zeilen 28 bis 35).
Die Zeile 29 verdeutlicht den Gebrauch von Regular Expressions in Perl: Die Ergebnisse seines Ausdrucks speichert Schwartz ohne weitere Umwege in den Variablen »$number« und »$text«. Bemerkenswert ist dabei, dass er ihre Eingabe gar nicht spezifiziert: Implizit verwendet die Sprache dann »$_«, jene Variable, die automatisch die aktuelle Zeile der Eingabe enthält, über die die While-Schleife in Zeile 28 iteriert.
|
Listing 3: |
|---|
01 #!/usr/bin/env perl
02 use strict;
03 $|++;
04
06 my $ORDER_BY = "defined"; # my $ORDER_BY = "used";
08 my @parsed;
09 my %mapping; # mapping of digits
10
11 {
12 my $counter = 1;
13 while (<DATA>) {
14 if (/^@footnote?:/) {
15 push @parsed, $_;
16 last;
17 }
18 while (s/^ (.*?) [ (d+) ]//x) {
19 push @parsed, $1;
20 push @parsed, $mapping{$2} ||= { used => $counter++ };
21 }
22 push @parsed, $_;
23 }
24 }
25 die "missing footer" if eof DATA;
26 {
27 my $counter = 1;
28 while (<DATA>) {
29 my ($number, $text) = /^ [ (d+) ] (.*)/x
30 or (push @parsed, $_), next;
31 my $item = $mapping{$number} or
32 warn("ignoring unused note: $_"), next;
33 $item->{defined} = $counter++;
34 $item->{definition} = $text;
35 }
36 }
37
38 for my $item (@parsed) {
39 if (ref $item) {
40 printf '[%s]', $item->{$ORDER_BY};
41 } else {
42 print $item;
43 }
44 }
45 for my $itemkey (sort {
46 $mapping{$a}{$ORDER_BY} <=> $mapping{$b}{$ORDER_BY}
47 } keys %mapping) {
48 my $value = $mapping{$itemkey};
49 printf "[%s]%sn", $value->{$ORDER_BY}, $value->{definition};
50 }
51
52 __DATA__
53 A great brown fox [13] jumped of a pile of lorem ipsum [4], [7]. He met
54 with a silver penguin, browsing the Linux Kernel Mailinglist [3]. They
55 debated whether to start C-programs with "main (int argc, char **argv)"
56 or with "main (int argc, char *argv[])". Brackets annoyed them [9999].
59 @footnote:
61 [13] Al Fabetus: "On characters and animals", 1888, self published.
62 [4] Lorem Ipsum, <a href="http://link.org/Lorem_Ipsum">Web Link</a>
63 [9999] Annoying Link.
64 [7] B. Fox: "More on Blind Text".
65 [3] Linux Kernel Maintainers: LKML
|
Sortieren nach Wunsch
Der Rest ist einfach: Texte gibt Schwartz ohne weiteren Zwischenschritt aus (Zeile 42), bei Fußnoten hat er zwei Optionen: Je nach Schlüssel (Zeile 6) schreibt er entweder die Fußnoten in der Reihenfolge ihres Auftretens (»used«) oder ihrer Definition im zweiten Textteil (»defined«).
Die Zeilen 45 bis 50 erzeugen abschließend die Einträge unter den Text, sortiert nach der gewählten Reihenfolge. Die Testdatei mit einer Million Fußnoten bearbeitet Perl in rund 51 Sekunden und beansprucht dazu etwa 420 MByte tatsächlichen Hauptspeicher. Damit zählt die Lösung nicht gerade zu den sparsameren Varianten. Dafür ist sie übersichtlicher, allerdings auf Kosten der etwas längeren Laufzeit.
Python
Python [14] entwarf Anfang der 1990er Jahre ihr Schöpfer Guido van Rossum am Zentrum für Mathematik und Informatik in Amsterdam als Nachfolger für die Lehrsprache ABC. Er legte besonderen Wert auf Einfachheit und Übersichtlichkeit. Weil Python zur Definition von Codeblöcken statt Klammern Einrückungen benutzt, erzwingt die Sprache eine lesbare Formatierung.
Der akademische Ursprung leuchtet an vielen Stellen durch, etwa im Datentyp einer komplexen Zahl. Python ist strenger typisiert als Perl oder PHP, für numerische Typen sind jedoch implizierte Casts definiert. Anders als Java ist Python auf kein bestimmtes Programmier-Paradigma zugeschnitten. Die Sprache eignet sich gleich gut für funktionales wie für objektorientiertes Programmieren.
Python bietet ein leistungsstarkes Exception-Handling, das sogar Syntax-Fehler abfängt. Zu der Sprache gehört darüber hinaus auch eine große, plattformunabhängige Standardbibliothek. Das im Lieferumfang enthaltene Tkinter nutzt TK für grafische Oberflächen, es gibt Bindings zu anderen verbreiteten Toolkits wie GTK, QT und Wx-Widgets. Eines der wichtigsten Python-Programme ist der Application-Server Zope [15].
David Mertz: In Ordnung gebracht
David Mertz (siehe Abbildung 4), der Einsender der Python-Lösung, ist Buchautor, Kolumnist für IBMs Developerworks-Webseite [16] und Maintainer der Gnosis-Utilities [17], einer verbreiteten Public-Domain-Sammlung von Python-Bibliotheken. Er studierte Philosophie und Mathematik und hat in Philosophie promoviert. Der Python-Entwickler Ka-Ping Yee hat ihm bei der Lösung der Linux-Magazin-Aufgabe geholfen.

Abbildung 4: David Mertz hat sich als Maintainter der Gnosis-Utilities, als Buchautor und Kolumnist im Python-Umfeld eine Namen gemacht.
Die Zeilen 58 bis 62 in Listing 4 prüfen zunächst, ob der Anwender das Skript mit dem Parameter »–test« aufgerufen hat. Ist dies der Fall, dann verarbeitet es den bis Zeile 18 definierten String, ansonsten übernimmt es den Text mit den zu sortierenden Fußnoten von der Kommandozeile.
Die Funktion »footnote()« (Zeilen 39 bis 56) enthält fast die gesamte Funktionalität. Als Erstes trennt sie den Text am Token »@footnote« in Lauftext und Fußnotenblock (Zeile 41). Über den regulären Ausdruck »'[d+]’« sucht das Skript in beiden Teilen nach Fußnoten (Zeilen 42 und 43). Die Funktion »nodups()« filtert dabei mehrfache Vorkommen der gleichen Fußnotennummer aus. »MkMap()« (Zeilen 28 und 29) erstellt beim Aufruf in Zeile 44 ein Dictionary, das die ursprünglichen Fußnotennummern mit der Folge [1, 2, …, n] kombiniert.
|
Listing 4: |
|---|
01 #!/usr/bin/env python
02 """USAGE: footnotes.py [-a] [--test] [< input.txt]
03 --test Self-test using text SAMPLE in script source
04 -a Number footnotes in order of appearance in text
05 """
06
07 SAMPLE = '''A great brown fox [13] jumped of a pile of lorem ipsum [4],
08 [7]. He met with a silver penguin, browsing the Linux Kernel
09 Mailinglist [3]. They debated whether to start a C-program with
10 "main (int argc, char **argv)" or with "main (int argc, char *argv[])".
11 Square brackets annoyed them [9999]. Multiple references exist [4].
12 @footnote:
13 [13] Al Fabetus: "On characters and animals", 1888, self published.
14 [4] Lorem Ipsum, <a href="http://link.org/Lorem_Ipsum">Web Link</a>
15 [9999] Annoying Link.
16 [7] B. Fox: "More on Blind Text".
17 [3] Linux Kernel Maintainers: LKML
18 '''
19 import sys, re
20
21 def nodups(lst):
22 new = []
23 for x in lst:
24 if x not in new:
25 new.append(x)
26 return new
27
28 def mkMap(lst):
29 return dict([(ref, "[%d]" % (n+1)) for n, ref in enumerate(lst)])
30
31 def asNum(line):
32 try:
33 key, _ = line[1:].split(']', 1)
34 key = int(key)
35 except:
36 key = line or None # If line looks wrong, just return the raw line
37 return key
38
39 def footnote(s, usebody=False):
40 FOOTSPLIT = 'n@footnote:n'
41 body, foots = s.split(FOOTSPLIT)
42 links = nodups(re.findall(r'[d+]', body))
43 targets = nodups(re.findall(r'[d+]', foots))
44 mapping = mkMap(links if usebody else targets) # Order body or foots
45
46 # Replace source->target footnote numbers
47 def numsub(m):
48 return mapping[m.group(1)]
49 body = re.sub(r'([d+])', numsub , body)
50 foots = re.sub(r'([d+])', numsub, foots)
51
52 # May need to reorder target lines in foots
53 if usebody:
54 foots = 'n'.join(sorted(foots.splitlines(), key=asNum))
55
56 return body + FOOTSPLIT + "n" + foots.strip()
57
58 if __name__ == '__main__':
59 if '--test' in sys.argv[1:]:
60 print footnote(SAMPLE, usebody='-a' in sys.argv[1:])
61 else:
62 print footnote(sys.stdin.read(), usebody='-a' in sys.argv[1:])
|
Wer A sagt …
Hat der Benutzer den Parameter »-a« angegeben, entsteht das Dictionary aus den Verweisen im Fließtext, andernfalls aus den Nummern des Fußnotenblocks. Dieses Wörterbuch dient als Basis für die Sortierung, das Skript sortiert die Fußnoten also abhängig vom Aufruf nach der Reihenfolge der Verweise im Text oder der Reihenfolge im Fußnotenblock.
Ausgehend von diesem Dictionary tauscht der Code in den Zeilen 49 und 50 die Fußnotennummern im Fließtext und im Fußnotenblock gegen numerisch aufsteigende Werte aus. »numsub« dient dabei als Callback-Funktion, die für jede Fundstelle den Match des regulären Ausdrucks »([d+])« als Parameter erhält. »group(1)« gibt den Inhalt des ersten und einzigen Klammerpaars im regulären Ausdruck zurück.
Werden die Fußnoten nach dem Vorkommen im Text sortiert, so bringt Zeile 54 noch den Fußnotenblock in die richtige Reihenfolge. Zeile 56 gibt schließlich den Text in der endgültigen Form zurück. Als einziger Testteilnehmer scheiterte das Python-Skript am Benchmark mit der 55 MByte-Datei, was allerdings eindeutig daran liegt, dass der Python-Skript die Datei nicht zeilenweise, sondern in einem Block einliest.
Java FX
Quasi außer Konkurrenz erreichte die Redaktion noch eine Lösung in der neuen Sprach-Umgebung Java FX [18]. Wie der große Bruder stammt das System von Sun Microsystems, es soll den Boden wiedergewinnen, auf dem Java vor gut einer Dekade gestartet ist: im Browser und auf mobilen Geräten. Genau genommen ist Java FX nämlich gar keine neue Sprache, sondern eine Entwicklungsumgebung (Software Development Kit). Das SDK lässt sich mit einem klassischen Java-Compiler übersetzten und läuft in einer virtuellen Maschine. Die mitgelieferten Klassen sprechen besonders Webentwickler an.
John Rose: Lohnender Formalismus
Als Senior Staff Engineer arbeitet John Rose (Abbildung 5) am Open-JDK-Projekt. Seit über zehn Jahren verbessert er Suns JDK [19], etwa durch innere Klassen, JIT-Optimierungen und einen Groovy-Parser. Bei Programmiersprachen kennt Rose sich aus, denn er hat vor seinem Job bei Sun schon an Common Lisp, Scheme und C++ gearbeitet.

Abbildung 5: John Rose arbeitet schon lange am JDK mit und zählt sich selbst zu den Fans von inneren Klassen und klaren APIs.
Die Lösung in Java FX gibt somit einen weiteren, interessanten Blick darauf, wie viele alternative Ansätze für ein Problem möglich sind. Rose kommentiert sein Programm: “Ich habe den nicht ganz überraschenden Eindruck gewonnen, dass Java im Gegensatz zu Skriptsprachen mehr Formalismus erfordert.”
Den Eindruck bestätigt auch ein Blick auf die Einsendung (siehe Listing 5), die die doppelte Länge der anderen Lösungen hat. Rose hat den Quelltext dafür ausführlich Javadoc-konform kommentiert. Er habe den Code so geschrieben, dass er ihn leicht in eine Bibliotheksklasse mit einem API umwandeln könne: “So lässt sich das besser in ein größeres System integrieren.” Dazu definiert der Sun-Ingenieur zu Beginn der Klasse »EndNotes« eine Reihe von Regular Expressions (Zeilen 28 bis 37), die den Aufbau der Ein- und Ausgabe konfigurierbar machen.
Das Programm startet ab Zeile 243 mit den Methoden »main()« und »run()«, parst die Kommandozeile und ruft »doFile()« mit der Eingabedatei auf. Die Methode erlaubt es dem Entwickler, Sortier-Varianten zu implementieren, etwa in alphabetischer Reihenfolge der Einträge im zweiten Abschnitt (Zeilen 207 bis 241) oder nach Auftreten. Dazu definiert Rose innere Klassen: “Die Worker-Klassen sind privat und verkörpern die Abläufe durch den Text. In einem Schwung voller Enthusiasmus habe ich einige Bonusfeatures eingebaut, um den Mechanismus zu verdeutlichen”.
Die regulären Ausdrücke, die Verarbeitung von Ein- und Ausgabe und die Art und Weise, den Text zu zerlegen, ähneln der anderen Java-Lösung aus Listing 3. Der Reichtum an vorhandenen und eigenen Klassen legt nahe, dass zwei Implementationen von erfahrenen Java-Entwicklern durchaus zu äußerst unterschiedlichen Quelltexten führen können.
Der Code, auch wenn er deutlich komplexer als die erste Java-Lösung ist, hat ein ähnliches Laufzeitverhalten: Auch seine virtuelle Maschine fordert gleich zu Beginn 900 MByte an Speicher, belegt letztlich aber nur rund 200 MByte. Den Testtext bearbeitete das Programm in rund 30 Sekunden, also noch eine Spur schneller als sein großer Bruder.
|
Listing 5: |
|---|
001 import java.util.*;
002 import java.io.*;
003 import java.util.regex.*;
004
005 /**
006 * Renumber endnotes in an almost-flat text file.
007 * <p>
008 * This example is structured as a driver class plus one or more
009 * inner classes which function as workers. The driver class presents
010 * the API to the rest of the world, including a main routine
011 * and (potentially) a set of option switches and entry points.
012 * The worker class is private to the driver, and embodies the
013 * pass structure of the problem.
014 * <p>
015 * Most program elements are declared as having default access,
016 * which means they are private to this class and its siblings
017 * in the same package. Upgrading this example to a reusable
018 * API would require moving it to a named package, deciding
019 * which elements ought to be made private, and adding public
020 * API elements to manage option control and invocation.
021 * <p>
022 * This code was developed on a MacBook Pro using NetBeans 6.1.
023 *
024 * @author john.rose@sun.com
025 */
026 public class EndNotes {
027 // --- options (note: we could put these under an API)
028 /** Regexp for endnote uses. */
029 Pattern usePattern = Pattern.compile("\[([0-9]+)\]");
030 /** Regexp for endnote definitions. */
031 Pattern defPattern = Pattern.compile("(?<=^\s*)\[([0-9]+)\]");
032 /** Replacement expression for the notation we are transforming. */
033 String noteRewrite = "[%s]";
034 /** Regexp for the marker separating body from endnotes. */
035 String boundaryPattern = "^\s*@footnotes?:\s*$";
036 /** How lines are separated on output. */
037 String lineSeparator = System.getProperty("line.separator", "n");
038
039 /** If true, definitions are resorted. */
040 boolean resortDefs;
041 /** If true, definitions are renumbered in compact ascending order.
042 * Otherwise, initial uses are renumbered in compact ascending
043 * order. (+++ Bonus feature.)
044 */
045 boolean renumberByDef;
046 /** If true, generate placeholder lines for missing definitions.
047 * (+++ Bonus feature.)
048 */
049 boolean generateMissing;
050
051 /** Map endnote references to their new numberings. */
052 TreeMap<String, Integer> oldNotes = new TreeMap<String, Integer>();
053 /** Next note number to generate into oldNotes.values. */
054 int nextNewNote = 1;
055 /** Output channel. */
056 Writer out;
057
058 /**
059 * Given an old endnote numeral, find or create
060 * a new endnote number. The new numbers are produced in a compact
061 * sequence beginning with {@link #nextNewNote}.
062 * The ordering of calls to this method is significant,
063 * because the first call to a previously unseen numeral
064 * will always return the value of {@link #nextNewNote}.
065 * @param oldnum the old numeral (without brackets)
066 * @return new number
067 */
068 int getNewNumber(String oldnum) {
069 Integer newnum = oldNotes.get(oldnum);
070 if (newnum == null) {
071 oldNotes.put(oldnum, newnum = nextNewNote++);
072 }
073 return (int) newnum;
074 }
075
076 /**
077 * Find all endnote occurrences in the given string, and renumber them.
078 * @param line a line of text; may contain embedded line separators
079 * @param pattern the endnote pattern; group(1) is replaced
080 * @return the original line with endnotes renumbered
081 */
082 String replaceNotes(String line, Pattern pattern) {
083 Matcher m = pattern.matcher(line);
084 StringBuffer sb = null;
085 while (m.find()) {
086 int newnum = getNewNumber(m.group(1));
087 if (newnum < 0) {
088 continue;
089 }
090 if (sb == null) {
091 sb = new StringBuffer(line.length() + 20);
092 }
093 String newnote = String.format(noteRewrite, newnum);
094 m.appendReplacement(sb, newnote);
095 }
096 return (sb == null) ? line : m.appendTail(sb).toString();
097 }
098
099 /** The processing loop, with pluggable behaviors.
100 * It is an inner class (non-static) so that the main
101 * class can supply environmental settings as if they were
102 * global variables.
103 */
104 class Scanner {
105 BufferedReader in;
106 void doFile(File file) throws IOException {
107 in = new BufferedReader(new FileReader(file));
108 try {
109 String lastLine = doBody();
110 if (lastLine != null)
111 doEndNotes(lastLine);
112 } finally {
113 in.close();
114 in = null;
115 }
116 }
117 String doBody() throws IOException {
118 for (String line; (line = in.readLine()) != null;) {
119 if (line.matches(boundaryPattern))
120 return line;
121 putLine(doBodyLine(line));
122 }
123 return null;
124 }
125 String doBodyLine(String line) {
126 return replaceNotes(line, usePattern);
127 }
128 void doEndNotes(String line) throws IOException {
129 for (; line != null; line = in.readLine())
130 putLine(doEndNoteLine(line));
131 }
132 String doEndNoteLine(String line) {
133 return replaceNotes(line, defPattern);
134 }
135 void putLine(String line) throws IOException {
136 if (line == null) return;
137 out.write(line);
138 out.write(lineSeparator);
139 }
140 }
141
142 /** Use this for sorting endnotes. */
143 class NoteComparator implements Comparator<String> {
144 public int compare(String n1, String n2) {
145 Matcher m1 = defPattern.matcher(n1);
146 Matcher m2 = defPattern.matcher(n2);
147 int c = 0;
148 if (!m1.find()) c = m2.find() ? -1 : 0;
149 else if (!m2.find()) c = 1;
150 else c = comparePrimary(m1, m2);
151 // secondary key is the whole line:
152 if (c == 0) c = n1.compareTo(n2);
153 return c;
154 }
155 /** Use the note prefix from the strings as a primary key. */
156 int comparePrimary(Matcher m1, Matcher m2) {
157 Integer i1 = getNewNumber(m1.group(1));
158 Integer i2 = getNewNumber(m2.group(1));
159 return i1.compareTo(i2);
160 }
161 };
162
163 /** Variant of Scanner which collects endnotes, rather than
164 * immediately renumbering them.
165 */
166 class CollectingScanner extends Scanner {
167 int endNote;
168 ArrayList<String> endText = new ArrayList<String>();
169 @Override
170 String doEndNoteLine(String line) {
171 if (defPattern.matcher(line).find()) {
172 ++endNote;
173 }
174 if (endText.size() <= endNote) {
175 endText.add(line);
176 assert(endText.size() == endNote+1);
177 } else { // collect multi-line note
178 endText.set(endNote, endText.get(endNote)
179 + lineSeparator + line);
180 }
181 return null; // tell putLine to do nothing
182 }
183 List<String> endNotes() {
184 return endText.subList(1, endText.size());
185 }
186 void finishEndNotes() throws IOException {
187 for (String line : endText)
188 putLine(super.doEndNoteLine(line));
189 }
190 // +++ BONUS FEATURE
191 void generateMissingEndNotes() throws IOException {
192 TreeSet<Integer> missing = new TreeSet<Integer>();
193 for (int i = 1; i < nextNewNote; i++)
194 missing.add(i);
195 for (String line : endNotes()) {
196 Matcher m = defPattern.matcher(line);
197 if (m.find())
198 missing.remove(getNewNumber(m.group(1)));
199 }
200 for (int i : missing) {
201 String gen = String.format(noteRewrite, i)+" (missing)";
202 putLine(gen);
203 }
204 }
205 }
206
207 public void doFile(File file) throws IOException {
208 if (renumberByDef) {
209 // +++ BONUS FEATURE: scan endnotes before body +++
210 // We will use anonymous inner classes to add the extra methods.
211 // must visit the defs section first
212 CollectingScanner firstPass = new CollectingScanner() {
213 // totally ignore body lines
214 @Override String doBodyLine(String line) { return null; }
215 // produce no output at all
216 @Override void putLine(String line) { }
217 };
218 firstPass.doFile(file);
219 if (resortDefs) {
220 Collections.sort(firstPass.endNotes(), new NoteComparator() {
221 /** First strip the note prefix from the strings, then compare. */
222 @Override int comparePrimary(Matcher m1, Matcher m2) {
223 return m1.replaceFirst("").compareToIgnoreCase(m2.replaceFirst(""));
224 }
225 });
226 }
227 firstPass.finishEndNotes();
228 }
229 // streaming pass over the data, buffering one body line at a time
230 if (!resortDefs && !generateMissing) {
231 new Scanner().doFile(file);
232 } else {
233 CollectingScanner scanner = new CollectingScanner();
234 scanner.doFile(file);
235 if (resortDefs)
236 Collections.sort(scanner.endNotes(), new NoteComparator());
237 scanner.finishEndNotes();
238 if (generateMissing)
239 scanner.generateMissingEndNotes();
240 }
241 }
242
243 // command-line entry point
244 public static void main(String... av) throws IOException {
245 // with no args, assume sample data file, and use all possible options
246 if (av.length == 0) av = new String[] { "-s", "-d", "-g", "sample-data.txt" };
247 new EndNotes().run(av);
248 }
249 public void run(String... av) throws IOException {
250 File file = null;
251 for (String arg : av) {
252 if (arg.startsWith("-")) {
253 if (arg.equals("-s") || arg.equals("--sort")) {
254 resortDefs = true;
255 } else if (arg.equals("-u") || arg.equals("--uses")) {
256 renumberByDef = false;
257 } else if (arg.equals("-d") || arg.equals("--defs")) {
258 renumberByDef = true;
259 } else if (arg.equals("-g") || arg.equals("--generate-missing")) {
260 generateMissing = true;
261 } else {
262 usage();
263 }
264 } else {
265 if (file != null) {
266 usage();
267 }
268 file = new File(arg);
269 }
270 }
271 if (file == null) {
272 usage();
273 }
274 out = new BufferedWriter(new OutputStreamWriter(System.out));
275 doFile(file);
276 out.flush();
277 }
278
279 private static void usage() {
280 throw new IllegalArgumentException(
281 "Usage: EndNotes [--sort | --uses | --defs | --] input.txt > output.txt");
282 }
283 };
|
Harmonie in Babylon
Fünf Sprachen und fünf “Päpste” sind angetreten und haben sich sehr unterschiedlich präsentiert. Die Messwerte von Laufzeit und Speicherverbrauch in Abbildung 6 geben einen ersten Eindruck: Die PHP-Lösung zeigt, dass schlaue Optimierungen gute Leistungswerte er-zielen. Die beiden Java-Varianten ber-gen kleine Über-raschungen: trotz hohem programmtechnischem Aufwand schneiden sie gut ab – setzen jedoch fundierte Kenntnisse des JDKund viel RAM voraus. Perl zeigt sich knapp, aber etwas formschwach. Python hatte leichtes Pech im Testfeld: Die konkrete Lösung kommt nicht gut mit den großen Eingabedateien klar, ihr Code ist dafür aber recht lesbar. Zwei Eindrücke bleiben: Die Sprachen agieren auf Augenhöhe, jede hat ihre Stärken. Vielleicht trägt die Erkenntnis zu etwas Harmonie im Programmier-Babylon bei. (mfe)
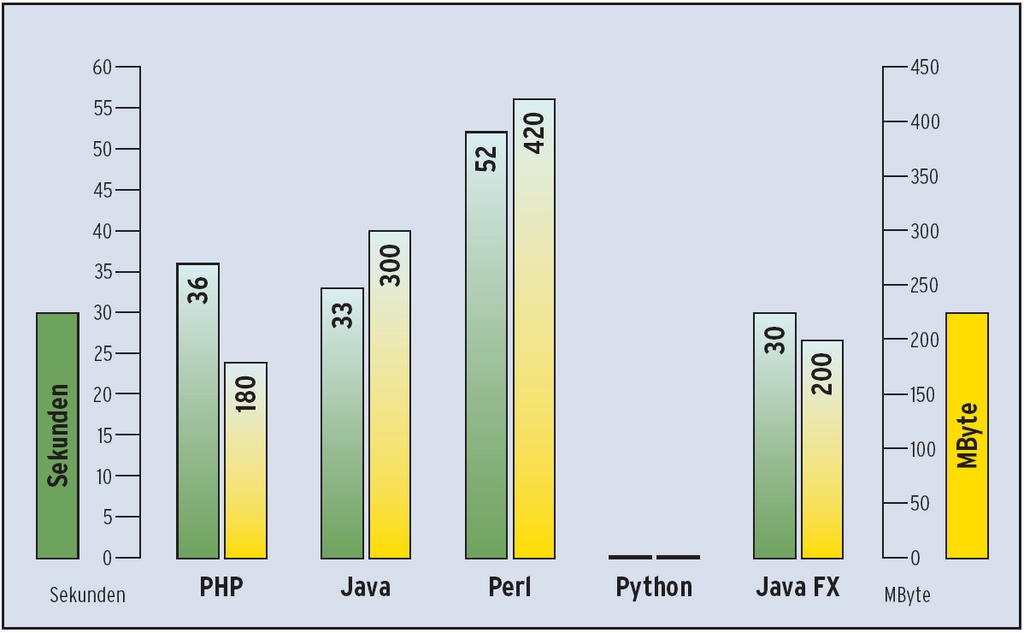
Abbildung 6: Das Diagramm zeigt Laufzeit und Speicherverbrauch der eingegan-genen Lösungen. Python scheiterte an der 55 MByte großen Testdatei.
|
Linux-Magazin-Leser sind |
|---|
|
Das Linux-Magazin hatte die Aufgabenstellung bewusst offen formuliert, damit die Sprach-Experten frei für kreative Lösungen waren. Nun sind Sie, die Leser des Linux-Magazins an der Reihe: Wer kennt noch weitere Python-Kniffe? Wer kann die Java-Lösung kürzen oder die Perl-Variante effizienter gestalten? Welche anderen Programmiersprachen lösen das Problem vielleicht noch eleganter? Schreiben Sie uns! Die Redaktion begutachtet alle bis zum 30. September unter [mailto:redaktion@linux-magazin.de] eingehenden Skripte oder Programme und prämiert die drei kreativsten Lösungen mit je einem Fachbuch. Die Einsendungen verlinken wir auf Linux-Magazin Online. |
|
Infos |
|---|
|
[1] PHP: [http://www.php.net] [2] Typo3: [http://typo3.org] [3] WordPress: [http://wordpress.org] [4] Joomla: [http://www.joomla.de] [5] Ohloh: [http://www.ohloh.net] [6] PHP und Unicode:[http://www.php.net/~scoates/unicode/render_func_data.php] [7] Zend: [http://www.zend.com] [8] Java: [http://www.java.com] [9] Eclipse: [http://www.eclipse.org] [10] Netbeans: [http://www.netbeans.org] [11] Java unter der GPL:[https://www.linux-magazin.de/Online-Artikel/Lizenz-zum-Geldverdienen] [12] Perl: [http://www.perl.org] [13] CPAN: [http://www.cpan.org] [14] Python: [http://www.python.org] [15] Zope: [http://www.zope.de] [16] IBM Developers Works: [http://ibm.com/developerworks] [17] Gnosis: [http://gnosis.cx/download] [18] Java FX: [http://javafx.com] [19] Suns JDK: [http://java.sun.com/javase/downloads/index.jsp] [20]Listings aus diesem Artikel: [ftp://linux-magazin.de/pub/listings/magazin/2008/10/sprachen] |





