
Ein Programm nachträglich für mehrere Landessprachen umzubauen erfordert hohen Aufwand. Besser ist es, von Anfang an im Sourcecode die nötigen Vorkehrungen für mehrsprachige Strings zu schaffen. Das Gettext-System bietet dafür die passende Infrastruktur.
Choose a language – oder doch lieber “Wählen Sie eine Sprache”? Eine Software in viele Landessprachen übersetzen wird angesichts der weltweiten Verbreitung von Linux immer wichtiger. Häufig kocht dabei aber jeder Programmierer sein eigenes Süppchen. Während Hardliner alle Sprachen direkt im Quellcode unterbringen, trennen umsichtige Entwickler mit selbst entwickelten Systemen Programmcode und Textausgabe. Um Wildwuchs zu vermeiden, schuf das GNU-Projekt 1995 das Gettext-Paket.
Dolmetscher
Gettext besteht aus einigen Programmen und einer Bibliothek, die im Zusammenspiel die Übersetzungsarbeiten nicht nur radikal vereinfachen, sondern gleichzeitig auch standardisieren. Welche Programmiersprachen Gettext gegenwärtig beherrscht, verrät der Kasten “Unterstützte Programmiersprachen”.
Als Beispiel für die Übersetzung von Software dient das bekannte Hello World in C. Dieses Programm gibt über die Funktion »printf()« stur den englischen Text “Hello World” aus, egal wo die Anwendung sie auch immer ausführt. Um der Software Deutsch beizubringen, bindet man in einem ersten Stritt das Gettext-System ein. Das erledigen diese beiden Headerdateien:
#include <libintl.h> #include <locale.h>
»libintl.h« enthält die im Folgenden verwendeten Funktionen, »locale.h« einige wichtige Konstanten. Nun wäre es schön, wenn das Programm die Zeichenkette »hello world« selbstständig gegen das deutsche Pendant austauschen würde – abhängig vom Inhalt der Sprach-Umgebungsvariablen wie »LANG« (siehe Kasten “Umgebungsvariablen”). Dabei hilft die Funktion »gettext()«, die dem Paket seinen Namen verlieh. Aus »printf(“hello worldn”)« wird somit »printf(gettext(“hello worldn”))«.
Während der Ausführung schlägt Gettext in einer Datei die Übersetzung für »hello worldn« nach und liefert die passende deutsche Zeichenkette zurück. Ist keine entsprechende Übersetzungsdatei vorhanden oder tritt ein anderer Fehler auf, erscheint der im Quellcode festgelegte String. Auf diese Weise lassen sich alle Zeichenketten, die der Benutzer später zu Gesicht bekommt, in Gettext-Funktionsaufrufen kapseln.
Kleiner Langenscheidt
Die in der Gettext-Terminologie als Kataloge bezeichneten Übersetzungsdateien muss der Programmierer selbst erzeugen. Dabei hilft das Programm Xgettext:
xgettext -d hello -n hello.c
Dieser Aufruf findet in der Datei »hello.c« alle »gettext«-Aufrufe und speichert die entsprechenden Zeichenketten in einer ».po«-Datei (für Portable Object). Im Hello-World-Beispiel sieht das Ergebnis aus wie in Listing 1. Am Anfang der Datei stehen die allgemeinen Informationen wie etwa Übersetzer oder Erstellungsdatum. Kommentare beginnen mit einer Raute »#«.
Am wichtigsten sind die letzten vier Zeilen. Zunächst ist nach dem »#:« der Ort der Zeichenkette angegeben, im Beispiel Zeile 8 von »hello.c«. Dem »#,« folgen die so genannten Flags. Hier legt »c-format« fest, dass die Nachricht ein String im C-Format ist. Hilfsprogramme können mit dieser Information prüfen, ob die C-typischen Steuerzeichen wie »n« oder »%d« auch in der Übersetzung auftauchen. Hinter »msgid« steht der Ursprungstext, darunter bei »msgstr« die Übersetzung, die im Beispiel noch fehlt.
Für jede zu unterstützende Sprache ist eine solche Datei anzulegen und vom entsprechenden Dolmetscher auszufüllen. Das kann entweder per Texteditor oder mit einem der zahlreichen Übersetzungsprogramme geschehen. Beispiele für diese Werkzeuge sind PO-Edit (Abbildung 1), KBabel oder Gtranslator. Praktisch dafür ist auch das Ubuntu-Projekt Rosetta (Abbildung 2).
| Unterstützte Programmiersprachen |
|---|
| C, C++, Objective C, Shellskripte, Python, Librep (Lisp), GNU Smalltalk, Java, GNU Awk, Pascal (Free Pascal Compiler), YCP (Yast-Skriptsprache), Tcl/Tk, Perl, PHP, Pike.
Das Hilfsprogramm »xgettext« ist standardmäßig auf C und C++ eingestellt. Bei Bedarf deaktiviert der Parameter »-L Sprache« die Erkennungsautomatik. |
Um nicht für jede Sprache Xgettext starten zu müssen, gibt der Programmierer der einmal produzierten Datei am besten die Endung ».pot« für Portable Object Template und verwendet sie als Vorlage für alle weiteren Kataloge. Wie man mit Änderungen am Quellcode umgeht, verrät der Kasten “Revisionen”.
Gruppenbildung
Müsste die »gettext«-Funktion auf der Suche nach einer Übersetzung den entsprechenden Katalog durchgehen, wäre das bei großen Projekten nicht besonders effizient. Stattdessen durchsucht Gettext mit einer Hashfunktion binäre ».mo«-Dateien (Machine Object), die das kleine Hilfsprogramm »msgfmt« aus ».po«-Dateien erzeugt:
msgfmt -c -o hello.mo hello.po
Wenn mehr als ein Katalog vorliegt, stellt sich das Problem sinnvoller Dateinamen. Die Lösung liegt in einer speziellen Verzeichnisstruktur (siehe Kasten “Unterverzeichnisse verarbeiten”). Zunächst erhält jede ».mo«-Datei den Namen des Programms oder des Projekts. Anschließend wandert sie in ein Verzeichnis, dessen Name dem folgenden Schema entspricht:
/Pfad_zu_Sprachdateien/Sprachkürzel/Kategorie/Katalog.mo
Das Sprachkürzel besteht aus zwei Buchstaben für die Sprache, einem Unterstrich und der Länderkennung. Für Deutschland ist dies »de_DE«, für Österreich »de_AT«. Weitere Kennungen legen die ISO-Standards 639 für die Sprache und 3166 für die Länderkennungen fest.
| Umgebungsvariablen |
|---|
| Die Spracheinstellungen werden durch einige Umgebungsvariablen gesteuert. Die wichtigste von ihnen ist »LANG« beziehungsweise, je nach System, auch »LANGUAGE«. Das darin enthaltene Sprachkürzel wie »de_DE« gilt für alle von der Sprache abhängigen Bereiche wie Programmtexte oder das Datumsformat.
Für eine feinere Unterscheidung sind alle Variablen mit einem vorangestellten »LC_« die erste Wahl. Beispielsweise kümmert sich »LC_MESSAGES« um die Sprache in allen (Programm-)Meldungen, während »LC_TIME« sich auf das Zeitformat bezieht. Der Kommandozeilenbefehl »locale« listet die aktuellen Einstellungen auf. |
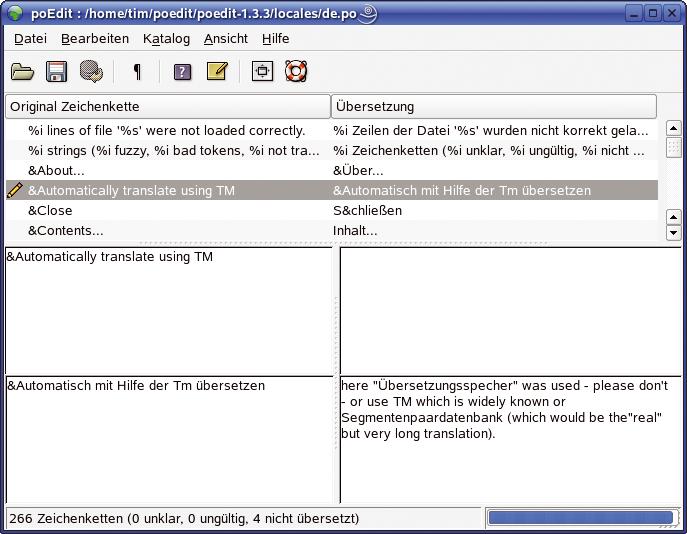
Abbildung 1: PO-Edit ist ein komfortables Werkzeug zum Editieren von PO-Dateien. Es zeigt im Hauptfenster den Ursprungstext, den übersetzten Text sowie den Kommentar und weitere Informationen an.
Ort für Übersetzungen
Da es sich bei den Kataloginhalten um Programmmeldungen handelt, ist die Kategorie immer zwingend »LC_MESSAGES«. Im Beispiel kommt die Datei »hello.mo« mit der deutschen Übersetzung ins Verzeichnis »/usr/share/locale/de_DE/LC_MESSAGES/«. Dieses Sortierschema sammelt alle Kataloge einer bestimmten Sprache in einem eindeutig benannten Verzeichnis. Selbstverständlich kann der Programmierer hiervon auch abweichen und beispielsweise die Übersetzungen direkt im Programmverzeichnis ablegen. Unter Suse Linux wandern zum Beispiel alle systemweiten KDE-Kataloge in das Verzeichnis »/opt/kde/share/locale«.
| Listing 1: PO-Datei |
|---|
01 # SOME DESCRIPTIVE TITLE. 02 # Copyright (C) YEAR THE PACKAGE'S COPYRIGHT HOLDER 03 # This file is distributed under the same license as the PACKAGE package. 04 # FIRST AUTHOR <EMAIL@ADDRESS>, YEAR. 05 # 06 #, fuzzy 07 msgid "" 08 msgstr "" 09 "Project-Id-Version: PACKAGE VERSIONn" 10 "Report-Msgid-Bugs-To: n" 11 "POT-Creation-Date: 2005-09-26 16:15+0200n" 12 "PO-Revision-Date: YEAR-MO-DA HO:MI+ZONEn" 13 "Last-Translator: FULL NAME <EMAIL@ADDRESS>n" 14 "Language-Team: LANGUAGE <LL@li.org>n" 15 "MIME-Version: 1.0n" 16 "Content-Type: text/plain; charset=CHARSETn" 17 "Content-Transfer-Encoding: 8bitn" 18 19 #: hello.c:8 20 #, c-format 21 msgid "hello worldn" 22 msgstr "" |
| Revisionen |
|---|
In der Entwicklung erfährt ein Programm oft grundlegende Überarbeitungen. Dabei kommen neue Textausgaben hinzu, andere fallen weg. Um anschließend nicht die Übersetzung neu beginnen zu müssen, gibt es das nützliche Programm »msgmerge«. Voraussetzung für seine Anwendung sind eine neu erzeugte ».pot«-Datei sowie ein ».po«-Katalog mit einer bestehenden Übersetzung. Im Hello-World-Beispiel könnten dies »hello_new.pot« und »de.po« sein. Die Befehlszeile
msgmerge hello_new.pot de.po bringt die Datei »de.po« auf den neuesten Stand. Dabei löscht »msgmerge« nicht mehr benötigte Zeichenketten, fügt die neuen hinzu und versucht dabei sogar selbstständig aus den vorhandenen Übersetzungen noch fehlende abzuleiten. Anschließend muss der Übersetzer nur noch den so aufgefrischten Katalog korrigieren und die verbliebenen unübersetzten Meldungen ergänzen. |
Drei mal eins
Abschließend muss der Entwickler dem Gettext-System nur noch mitteilen, welche Sprachdatei es anwenden soll. Das übernehmen drei Funktionen, die jedes Programm möglichst direkt nach seinem Start aufrufen sollte. In einem C-Programm ist der beste Platz normalerweise am Anfang von »main«:
setlocale (LC_ALL, "");
bindtextdomain ("hello","/usr/share/locale");
textdomain ("hello");
| Listing 2: Hello World übersetzt |
|---|
01 #include <stdio.h>
02 #include <libintl.h>
03 #include <locale.h>
04
05 main()
06 {
07 setlocale (LC_ALL, "");
08 bindtextdomain ("hello","/usr/share/locale");
09 textdomain ("hello");
10
11 printf(gettext("hello worldn"));
12 }
|
In der ersten Zeile setzt »setlocale« die Sprache auf jene, die in der Umgebungsvariablen »LC_ALL« steht. Die nächste Zeile gibt an, in welchem Unterverzeichnis sich die Wörterbücher befinden (in der oben genannten Unterverzeichnisstruktur ist dies »Pfad_zu_Sprachdateien«). In diesem Fall forscht »bindtextdomain« im entsprechenden Unterverzeichnis von »/usr/share/locale« nach dem Katalog mit dem Namen »hello.mo«. Die Funktion »textdomain()« wählt das ab sofort zu benutzende Wörterbuch. Grundsätzlich sind mehrere Bindtextdomain-Aufrufe erlaubt, der Anwender kann also während der Ausführung zwischen verschiedenen Katalogen hin und her springen.
Um das Ergebnis der Übersetzung zu testen, kompiliert man zunächst »hello.c«. Das Binary mit der Libintl-Bibliothek zu linken ist auf Systemen mit der Glibc nicht notwendig, da diese alle Gettext-Funktionen enthält. Bleibt nur noch die entsprechende Umgebungsvariable mit »export LANG=”de_DE”« auf Deutsch einzustellen. Bei der Ausführung gibt »hello« nun die beliebte Meldung auf Deutsch aus. Den kompletten Quellcode zeigt Listing 2.
| Unterverzeichnisse verarbeiten |
|---|
Besteht ein Programm aus mehr als einer Datei, so müssen diese dem Aufruf von »xgettext« hinzugefügt werden. Am einfachsten geschieht dies, indem man gleich die kompletten Unterverzeichnisse einbindet:
xgettext -D Eingabeverzeichnis -d hello.po Hiermit stehen alle Zeichenketten nur in der Datei »hello.po«, was die Arbeit für den Übersetzer erheblich erleichtert. |
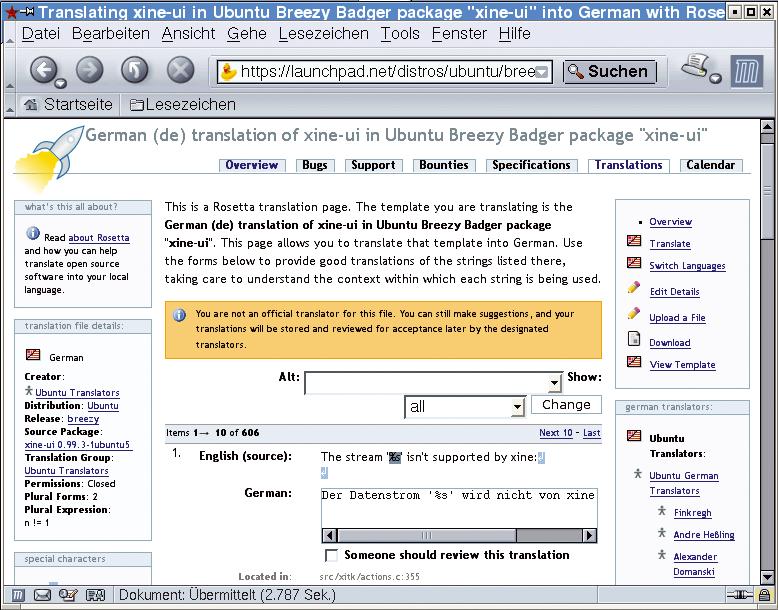
Abbildung 2: Die Ubuntu-Foundation betreut das Rosetta-Projekt, das die Übersetzung von PO-Dateien im Browser ermöglicht. Damit können auch Nicht-Programmierer zur Übersetzung beitragen.
Fazit
Gettext unterstützt die mehrsprachige Übersetzung von Programmen, indem es Textausgabe und Programmcode trennt. Auf diese Weise lassen sich nachträglich weitere Sprachen hinzufügen, ohne eine einzige Zeile Quellcode zu ändern. Auch einem bereits existierenden Programm bringt Gettext schnell fremde Sprachen bei: Drei Zeilen zum Programmbeginn und einige Gettext-Kapselungen genügen. Es lohnt sich also, bei der mehrsprachigen Programmentwicklung auf Gettext zu setzen. (ofr)
| Infos |
|---|
| [1] Gettext: [http://www.gnu.org/software/gettext]
[2] PO-Edit: [http://www.poedit.org] [3] Rosetta: [https://launchpad.net/rosetta] |





