
Linux selbst beherrscht viele Techniken, die den ein- und ausgehenden Netzwerkverkehr kontrollieren, begrenzen, priorisieren und aufteilen. Alle Queueing-Varianten unterstehen der abstrakten QDisc-Schicht, die wiederum dem TC-Kommando gehorcht.
Vernetzte Anwendungen wollen ihre Daten meist möglichst schnell transportiert wissen. Diesem Wunsch kommt Linux nach Kräften nach. Aber nicht immer ist das für alle Beteiligten ideal: Besonders bei asynchronen DSL-Anschlüssen sowie VoIP (Voice over IP) ist es viel wichtiger, die Verzögerung und Priorität einzelner Pakete gezielt zu beeinflussen. VoIP beispielsweise braucht kaum Bandbreite, dafür aber einen gleichmäßigen Versand der Pakete mit möglichst kleiner Latenz. Ein FTP-Transfer dagegen ist für jedes Quäntchen Bandbreite dankbar, einzelne verzögerte Pakete fallen aber nicht ins Gewicht.
Teilen sich mehrere Parteien einen Internetzugang, dann sollte der (Linux-)Zugangsrouter die tendenziell knappen Netzressourcen gerecht zuweisen. Die Basis für diese Traffic Engineering genannte Aufgabe legt der Kernel per Queueing Disciplines, kurz QDiscs. Sie dienen jeder Netzwerkschnittstelle als Puffer. Bei einer kurzfristigen Überlastung nimmt die Schnittstelle weiterhin Pakete entgegen und speichert sie per QDisc, statt sie sofort weiterzusenden.
Schön der Reihe nach
Die Puffer sind im Normalfall als einfache Warteschlangen organisiert, die Pakete in unveränderter Reihenfolge weiterreichen (Fifo; First in, first out). QDiscs können den Verkehr aber auch begrenzen, verzögern, aufteilen und anderweitig regeln. Die passenden Module liegen in der Kernelkonfiguration (»make xconfig«) unter »Device Drivers | Networking support | Networking options | QoS and/or fair queueing«.
Aus Sicht der Software dient die Queueing Discipline als allgemeine und abstrakte Schnittstelle zu verschiedenen Implementierungen (im Kernelverzeichnis »net/sched«). Sie definiert Operationen, die jede Implementierung unterstützen muss. Im Mittelpunkt stehen die Funktionen »enqueue()« und »dequeue()«, die Pakete aufnehmen und wieder freigeben.
Für das Zustellen der Pakete an eine Netzwerkschnittstelle ist im Kernel die Funktion »dev_queue_xmit()« (in »net/core/dev.c«) zuständig. Sie hängt das Paket mit »enqueue()« in die konfigurierte QDisc und startet dann den Sendevorgang mit der »qdisc_run()«-Funktion. Letztere sendet so lange die zwischengespeicherten Pakete, bis die QDisc leer ist oder eine Abbruchbedingung eintritt. Das könnte ein Fehler der Netzwerkschnittstelle sein, die sich noch mit einem anderen Paket beschäftigt, oder die QDisc gibt keine weiteren Pakete mehr frei, weil sie ein definiertes Limit überschritten hat.
Schlange marsch
Die Funktion »qdisc_run()« ruft für jeden Sendeversuch einmal »qdisc_restart()« auf. Diese entnimmt mit »dequeue()« ein Paket aus der QDisc und übergibt es an die »hard_start_xmit()«-Funktion des Gerätetreibers. Meldet der Treiber einen Fehler, dann stellt »qdisc _restart()« das Paket durch einen »requeue()«-Aufruf wieder an seine ursprüngliche Position in die QDisc und teilt dem Kernel per »NET_TX_SOFTIRQ« mit, dass noch Pakete in der QDisc warten. Dieser Aufruf steckt in der Inline-Funktion »netif_sched()«. Bei nächster Gelegenheit ruft der Kernel dann »qdisc_run()« auf. Abbildung 1 zeigt die Zusammenhänge.

Abbildung 1: Eine QDisc besteht im Wesentlichen aus den »enqueue()«- und »dequeue()«-Funktionen. Trifft ein Layer-3-Paket ein, hängt »dev_queue_xmit()« es in eine Warteschlange und startet mit »qdisc_run()« die Übertragung.
Jeder Netzwerkschnittstelle darf immer nur eine QDisc zugeordnet sein. Für komplexe Strukturen sind Klassen nötig. Eine klassenbasierte Queueing Discipline muss zusätzliche Funktionen bereitstellen. Deren Prototypen sind in der »Qdisc_class_ops«-Struktur in »include/net/pkt_sched.h« definiert. Einer Klasse lassen sich wiederum QDiscs zuordnen. Die QDisc- und Klasseninstanzen werden im QDisc-Konzept anhand eines zweiteiligen 32-Bit-Werts x:y identifiziert. Die ersten 16 Bit (x) dieser ID bezeichnen die QDisc, die übrigen (y) die Klasse (Abbildung 2).
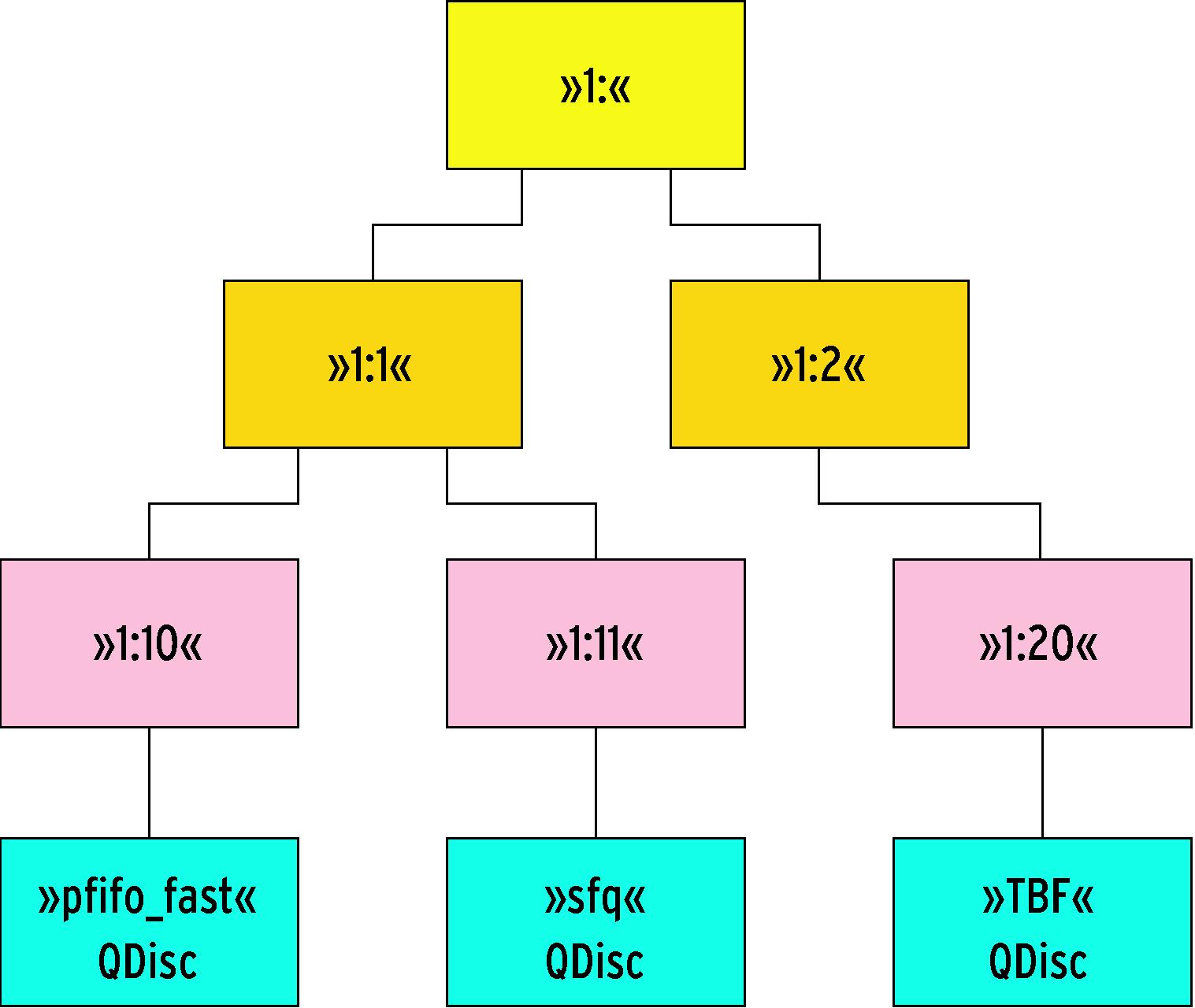
Abbildung 2: In der QDisc-Klassenhierarchie ist jede Instanz durch ein Paar aus 16-Bit-Werten gekennzeichnet. Die QDisc-Nummer steht vor dem Doppelpunkt, danach folgt die Kennung der Klasse.
Filter ordnen die Netzwerkpakete einer der Klassen zu. Jede QDisc besitzt eine eigene Liste von Filtern, die sie während des Enqueue-Vorgangs zur Klassifikation heranzieht. Das so genannte Policing ist ebenfalls mit der Klassifikation verbunden. Policer begrenzen die Rate, mit der ein Filter die ankommenden Pakete in den Rechner schleust. Treffen doch mehr Pakete ein, verwirft die QDisc das Paket (»TC_POLICE_SHOT«) oder klassifiziert es neu (»TC_POLICE_RECLASSIFY«).
Das TC-Programm
Um einer Netzwerkschnittstelle eine spezielle QDisc zuzuordnen und sie zu steuern, braucht der Admin das Programm »tc« aus dem IProute2-Softwarepaket[1]. Zum Installieren muss er nach dem Auspacken des Archivs im »Makefile« eventuell die Pfade zu den Kernel-Include-Dateien anpassen. »make« übersetzt die Programme »ip/ip«, »ip/rtmon« und »tc/tc«. Root steuert eine QDisc mit dem TC-Befehl nach folgender Syntax:
tc qdisc [add|del|replace|change|link] dev Gerät [root|parent ID] [handle ID] QDisc QDisc-Optionen
Will er der Schnittstelle »eth0« eine QDisc hinzufügen, tippt er: »tc qdisc add dev eth0 root handle 1: Qdisc QDisc-Optionen«. Durch den »root«-Parameter ordnet TC die QDisc der Netzwerkschnittstelle »eth0« direkt zu.
Soll die QDisc stattdessen zu einer Klasse gehören, wäre der »parent«-Parameter mit einer bereits existierenden Klassen-ID zu verwenden. Die Angabe »handle 1:« legt für die QDisc-Instanz die ID »1:« fest. Der zweite Teil der ID einer QDisc lautet immer Null und darf entfallen. Der folgende Befehl listet die aktuelle Konfiguration:
tc [-s] qdisc show [dev Gerät]
Mit dem optionalen Parameter »-s« zeigt TC zusätzliche Statistiken zu den QDiscs. Zudem lässt sich die Anzeige per »dev«-Option auf einzelne Netzwerkschnittstellen beschränken.
Klassenlose QDisc-Gesellschaft
Die klassenlosen QDisc-Implementationen verwalten meist nur zwischengespeicherte Pakete. Die am meisten genutzte QDisc-Implementation ist »pfifo_ fast«, da sie der Kernel standardmäßig jeder physikalischen Netzwerkschnittstelle zuordnet. Sie lässt sich nicht mit »tc« steuern. Die QDisc unterhält drei unterschiedlich priorisierte Bänder, die nach dem Fifo-Prinzip arbeiten. Befinden sich Pakete in Band 0 und Band 1, sendet »pfifo _fast« zunächst nur Pakete aus Band 0. Die Pakete in Band 1 müssen so lange warten, bis Band 0 leer ist. Band 1 und Band 2 verhalten sich analog.
Die Zuordnung eines Pakets zu einem Band erfolgt anhand des DS-Felds im IP-Header (Differentiated Services, ursprünglich mal TOS-Feld, Type of Service). Der Absender kann Pakete im DS-Feld markieren – RFC 2474[5] beschreibt wie. Innerhalb administrativer Grenzen eignet sich das gut, um alle Instanzen über die Klassifikation eines Pakets zu informieren.
Stochastic Fairness Queueing
Der SFQ-Algorithmus sorgt bei einer voll ausgelasteten Leitung für Fairness unter allen aktiven Verbindungen. Dafür setzt er 127 Fifo-Warteschlangen ein, die abwechselnd senden. Ein Hashverfahren entscheidet, welche Verbindung in welcher Warteschlange landet. Jedoch müssen sich gelegentlich mehrere Verbindungen eine Warteschlange teilen, während andere eine Warteschlange allein nutzen. Um diese Ungleichheit rasch auszugleichen, wechselt SFQ die Hashfunktion oft und garantiert so wenigstens eine stochastische Fairness.
Eine SFQ-QDisc ist schnell eingerichtet: »tc qdisc add dev eth0 root sfq«. Wer ihr Verhalten steuern will, macht das per:
tc ... sfq [perturb Sekunden] [quantum Bytes]
Beide Parameter sind optional. Die »perturb«-Option bestimmt die Zeitspanne für die Hashfunktion-Wechsel. Das »quantum« legt die Anzahl Bytes fest, die eine Warteschlange am Stück senden darf. Dieser Wert muss mindestens so groß sein wie die aktuellen Paketgröße (MTU, Maximum Transfer Unit). Andernfalls bleiben größere Pakete in der Queue hängen.
QDiscs mit Klasse
Klassenbasierte QDisc-Implementationen lassen der Konfiguration einen größeren Spielraum als ihre klassenlosen Gegenstücke. Es sind zwei Arten zu unterscheiden: Einfache QDiscs legen automatisch die erforderliche Anzahl von Klassen an, der sich in der Regel auch keine weiteren hinzufügen lassen. Im Gegensatz dazu gibt es QDisc-Implementationen, die keine oder nur eine einzelne Klasse automatisch anlegen. Deren Funktionsweise erwartet, dass der Anwender alle weiteren Klassen selbst erstellt und konfiguriert.
Eine Klasse kann selbst keine Pakete aufnehmen. Daher gehört zu jeder Klasse, der keine weiteren untergeordnet sind, automatisch eine »pfifo -fast«-QDisc (Abbildung 3). Diese QDisc nimmt die Pakete auf und gibt sie auch wieder frei. Der Admin darf diese QDisc aber durch beliebige andere Implementationen ersetzen, etwa einen Token Bucket Filter. Ein TBF begrenzt die Senderate der QDisc.
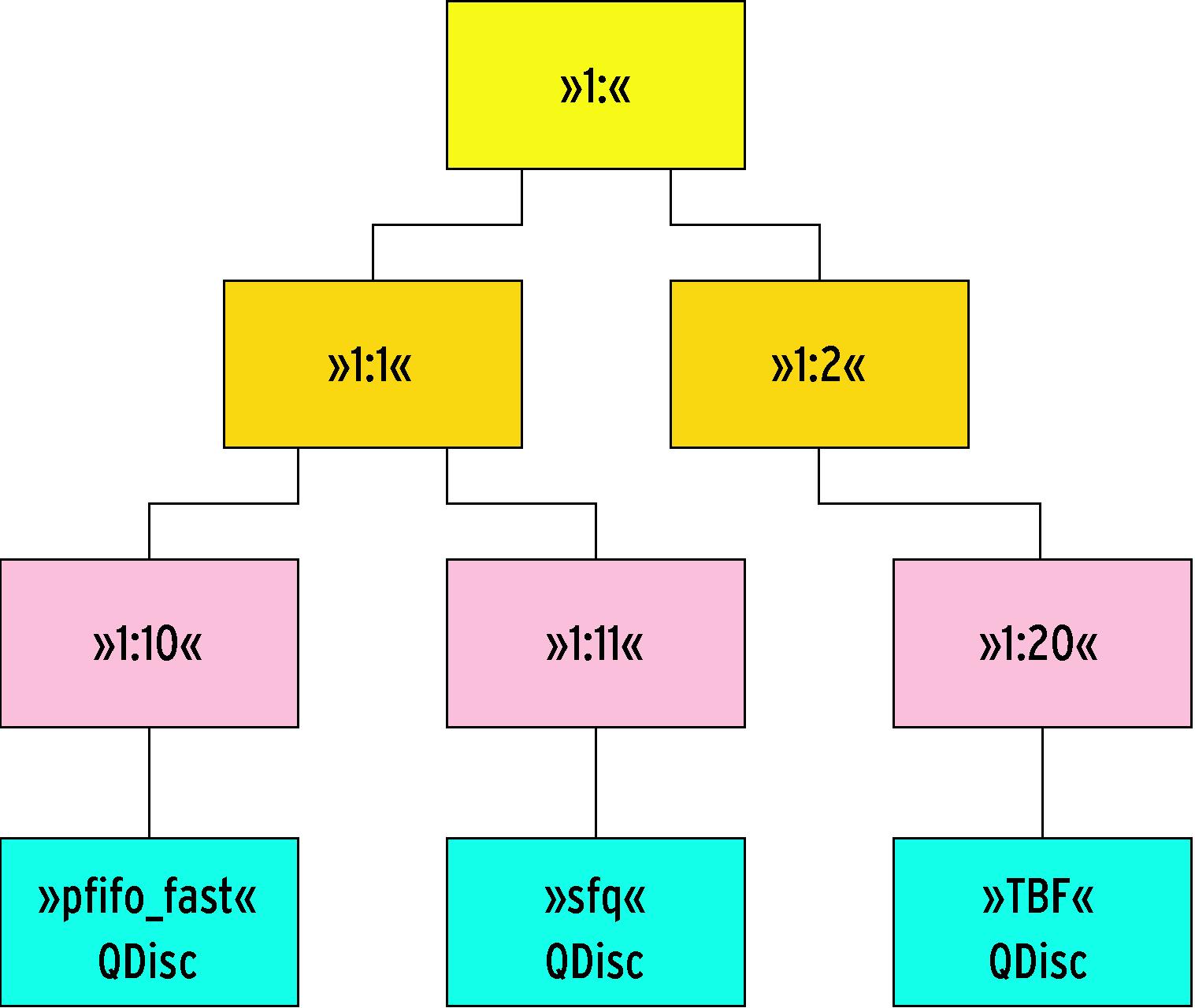
Abbildung 3: Die Klassenhierarchie endet in jedem Zweig bei einer QDisc. Klassen können selbst keine Pakete verarbeiten, daher brauchen sie die QDisc.
Die Grundlage seiner Implementation ist ein Bucket, ein virtuelles Gefäß, in das in konstantem Rhythmus Tokens fallen. Jedes Token symbolisiert eine feste Anzahl von Bytes. Wenn die QDisc ein Paket freigibt, verbraucht sie die entsprechende Menge Tokens. Stehen noch nicht genügend Tokens bereit, muss das Paket warten. Ein TBF besitzt genau eine innere Klasse, per Default eine einfache Warteschlange. Der Admin darf sie durch eine beliebige QDisc-Implementationen ersetzen.
Token Bucket Filter
Aus der Funktionsweise ergeben sich drei Szenarien: Treffen die zu sendenden Netzwerkpakete mit der gleichen Rate ein, wie TBF neue Tokens erzeugt, darf die QDisc jedes Paket sofort senden. Treffen die Pakete schneller ein, müssen sie warten, bis wieder ausreichend Tokens vorhanden sind. Das drosselt die Senderate auf die Token-Rate. Erreichen die Pakete den TBF mit einer geringeren Rate oder kommen gar keine Pakete an, tröpfeln die überschüssigen Tokens wieder in den Bucket. Ist der irgendwann voll, fließen alle folgenden Tokens in den elektronischen Gully.
Kommen nun wieder Pakete mit einer hohen Rate an, verbrauchen sie die angesammelten Tokens. Bis zur Bucketgröße darf die QDisc also mit einer höheren Rate senden, als dem TBF eigentlich zusteht. Es kommt zu einem so genannten Burst. Ein TBF lässt sich durch folgende Parameter konfigurieren:
tc ... tbf limit Bytes burst Bytes rate Bytes [mtu Bytes] [peakrate KBit] [latency Zeit]
Der »limit«-Parameter begrenzt die Menge der Pakete (in Bytes), die mangels verfügbarer Tokens warten dürfen. Weitere Pakete gehen verloren. Zusammen mit der Rate des TBF (»rate«) ergibt sich aus dem Limit-Parameter eine maximale Verzögerung, um die sich ein Paket verspätet. Alternativ ist die maximale Verzögerung auch mit dem »latency«-Parameter steuerbar. Beide Parameter gibt es heute nur noch aus Kompatibilitätsgründen. Der TBF gibt sie an die automatisch erzeugte innere Warteschlange weiter. Beim Austausch der inneren QDisc werden sie unwirksam.
Der »burst«-Parameter bestimmt die Bucketgröße und begrenzt damit die Datenmenge bei einem Burst. Wer nicht will, dass sein Rechner während des Bursts die Pakete mit voller Leitungsgeschwindigkeit aussendet, setzt eine »peakrate«. Die ist leider durch die Paketgröße und Kernel-Zeitintervalle beschränkt. Linux tickert auf X86 bis einschließlich Kernel 2.4 nur mit 100 Hertz, ab Version 2.6 sind es 1000 Hertz. Die maximale Peakrate ergibt sich aus der durchschnittlichen Paketgröße multipliziert mit der Timerfrequenz. Wer eine höhere Rate braucht, kann per »mtu«-Parameter die Anzahl der zu sendenden Pakete pro Timertick vergrößern.
DSL stellt sich dumm an
TBF-QDiscs lassen sich recht sinnvoll auf die relativ langsamen DSL-Modems loslassen, die lokal an einer wesentlich schnelleren Ethernet-Schnittstelle hängen. Viele Modems verfügen über einen Sendepuffer, der sich bei übergroßer DSL-Auslastung zu füllen beginnt. Interaktive Verbindungen geraten deswegen aber – im Wortsinne – ins Hintertreffen, da auch ihre kleinen Pakete sich ans Ende der mit FTP- und HTTP-Paketen vollgestopfte Modem-Warteschlange anstellen müssen. Der kluge Admin begrenzt darum die Sendeleistung der schnellen Schnittstelle; so bleibt die Modem-Warteschlange leer und überlässt es dem Kernel, den Paketefluss intelligenter zu steuern. Beispiel:
tc qdisc add dev ppp0 root tbf rate 128kbit latency 40ms burst 1540 tc qdisc add dev ppp0 parent 1:1 handle 10: sfq
Das erste TC-Kommando begrenzt per TBF die Sendegeschwindigkeit der PPP-Schnittstelle auf 128 KBit, passend zum Upstream einer TDSL-Leitung. Der zweite Aufruf ordnet der inneren Klasse eine SFQ-QDisc zu. Das sorgt für eine faire Behandlung aller Verbindungen.
Prio mit sichtbaren Bändern
Eine Prio-QDisc ist der Pfifo_fast-QDisc sehr ähnlich. Sie legt ebenfalls Bänder an, die sie abhängig von den Prioritäten leert. Im Gegensatz zu Pfifo_fast sind die Bänder aber als Klassen sichtbar: Band 0 bekommt die Klassen-ID »:1«, Band 1 die »:2« und so fort. Jeder dieser Klassen darf man eine beliebige QDisc zuordnen. Die Prio-QDisc kennt zwei Parameter:
tc ... prio bands n [priomap a b ... p]
Der »bands«-Parameter bestimmt, wie viele Bänder die QDisc anlegt. Wer mehr oder weniger als die voreingestellten drei braucht, muss noch eine »priomap« mit 16 Werten angeben. Sie legt fest, welche Bänder zu den verschiedenen DS-Bit-Kombinationen gehören. Folgendes Beispiel legt eine Prio-QDisc mit zwei Bändern an:
tc qdisc add dev eth0 root handle 1: prio bands 2 priomap 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
Unabhängig vom DS-Feld landen alle Pakete in Band 1. Ein solche Konfiguration kann sinnvoll sein, wenn zusätzlich Filter bestimmte Pakete in das höher priorisierte Band 0 klassifizieren. Beide Klassen können eine eigene QDisc erhalten:
tc qdisc add dev eth0 parent 1:1 handle 10: tbf rate 512kbit burst 4096 tc qdisc add dev eth0 parent 1:2 handle 20: sfq
Die beiden Algorithmen Prio und TBF besitzen eine vorher festgelegte Anzahl von Klassen und ein spezielles Verhalten, was ihr Einsatzgebiet etwas beschränkt. Bei hierarchisch organisierten Algorithmen bestimmt dagegen der Admin die Anzahl und strukturelle Anordnung der Klassen selbst.
Hierarchische Algorithmen
Um die Klassen für hierarchische QDisc-Algorithmen zu erstellen und zu organisieren, bedarf es zusätzlicher TC-Befehle. Die Kommandos ähneln jenen, die eine klassenbasierte QDisc steuern:
tc class [add|change|replace] dev Gerät parent ID [classid ID] QDisc Class-Optionen
Um eine neue Klasse »1:1« der QDisc »1:« hinzuzufügen, lautet der Aufruf »tc class add dev eth0 parent 1: classid 1:1 QDisc Class-Optionen«. Der QDisc-Parameter entspricht dem Typ der übergeordneten QDisc. Die Konfiguration von hierarchisch organisierten QDiscs findet üblicherweise auf der Ebene von Klassen statt. Daher begnügen sich diese Implementationen bereits mit sehr wenigen Parametern.
Hierarchische Algorithmen verfolgen zwei Ziele: Erstens sollen sie die verfügbare Bandbreite an die einzelnen Klassen verteilen und ihnen den Anteil bei Bedarf garantieren. Um das einzuhalten, dürfen die Klassen zusammen nicht mehr Bandbreite erhalten, als tatsächlich vorhanden ist. Zweitens muss der Algorithmus die ungenutzten Bandbreite verteilen. Bleiben einige Klassen hinter ihrem zugestandenen Anteil zurück, soll die ungenutzte Sendeleistung den andere Klassen zugute kommen.
Die Pakete landen immer in den Leaf-Klassen der Hierarchie, da nur diese Klassen der untersten Ebene tatsächlich Pakete in ihren zugeordneten QDiscs zwischenspeichern. Die übergeordneten Klassen klassifizieren die Pakete nur passend.
Geteilter Zugang
Schon bei einem Netzzugang, den sich zwei Benutzer teilen, lohnt der Einsatz hierarchischer QDisc-Algorithmen. Als Beispiel soll Teilnehmer A ein Anrecht auf 500 KBit/s der verfügbaren 1000 KBit/s Sendeleistung haben und Teilnehmer B sollen die restlichen 500 KBit/s zustehen. Auch möchte Teilnehmer A eine weitere Unterteilung seiner Bandbreite in 100 KBit/s für Internettelefonie und 400 KBit/s für allgemeine Daten.
Daraus ergeben sich zwei mögliche Klassenhierarchien. Sie könnte aus den drei Geschwisterklassen A1, A2 und B bestehen, die alle Kinder der Root-Klasse sind (Abbildung 4a). Sie könnte zunächst die Klassen A und B als Kinder der Root-Klasse installieren, um dann Klasse A eine Ebene tiefer feiner aufzuteilen (Abbildung 4b). Solange alle Klassen maximal ihre garantierte Bandbreite nutzen, arbeiten beide Hierarchien identisch. Erst wenn eine Klasse wenig oder nichts sendet, die anderen aber wesentlich mehr wünschen, würde die erste Klassenhierarchie die überschüssige Bandbreite an andere Klassen verteilen.
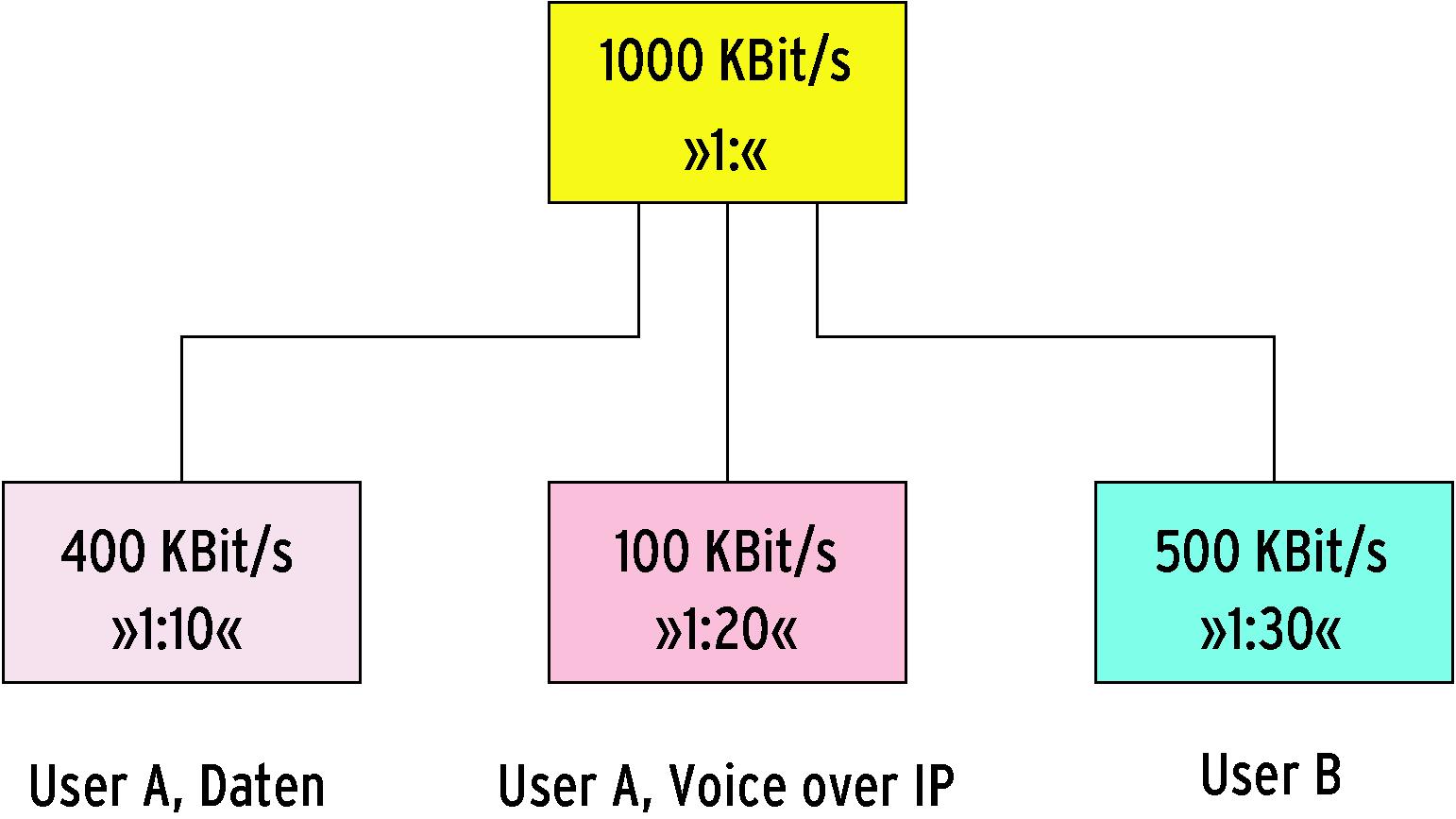
Abbildung 4a: Die beiden Benutzer A und B teilen sich einen Internetzugang. User A erhält zwei Subklassen, die zusammen ebenso 500 KBit/s ergeben wie die eine Klasse des Benutzers B. Alle drei Klassen teilen sich ungenutzte Bandbreite.
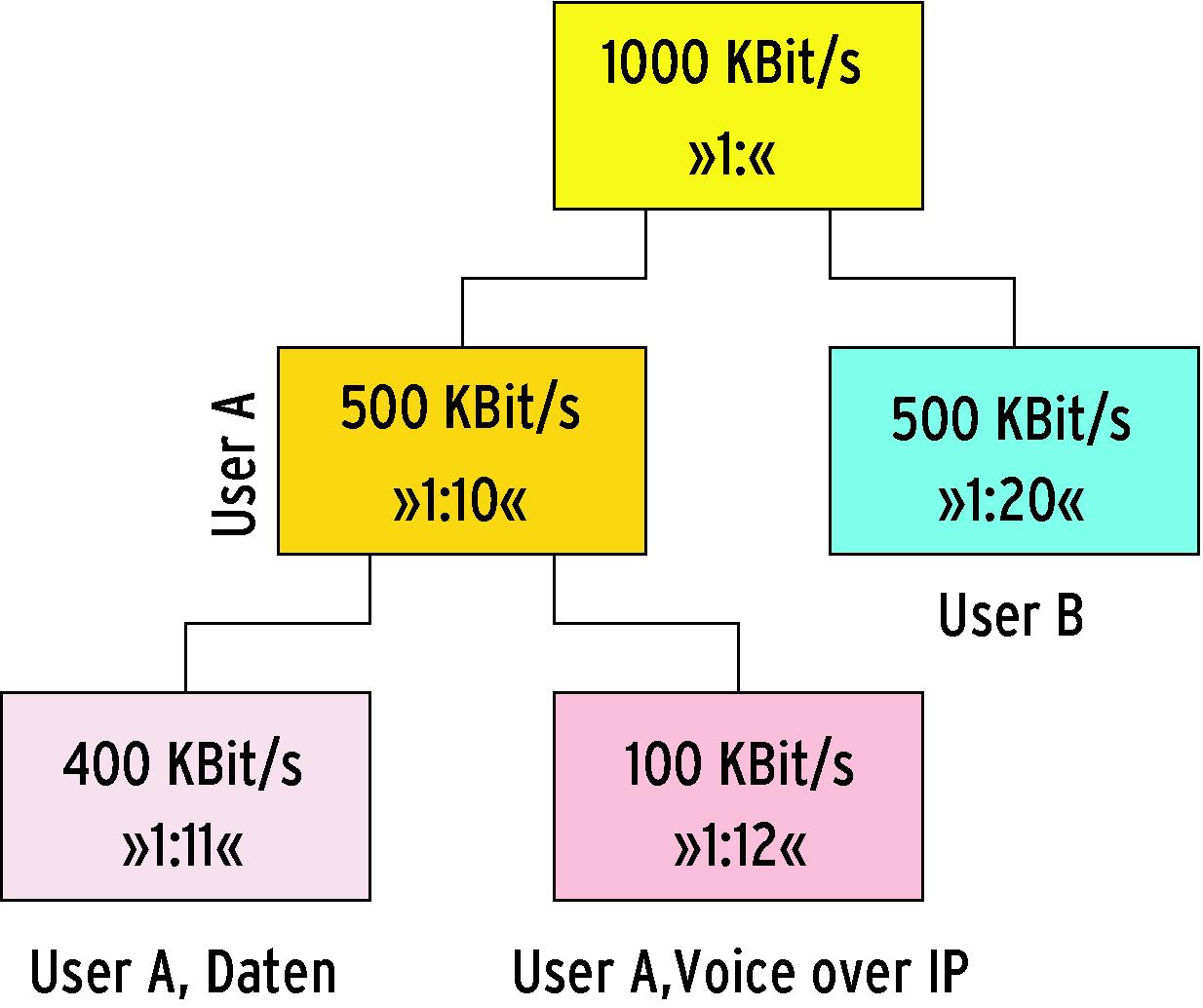
Abbildung 4b: Die hierarchische Klassenstruktur von Abbildung 4a ist hier in zwei Ebenen aufgeteilt. Die obere Ebene trennt nach User, die untere nach Anwendung. In dieser Variante verteilt der Kernel überschüssige Bandbreite gerechter.
Eventuell ist Teilnehmer A aber nicht gewillt, die ungenutzten Bandbreite an Teilnehmer B zu verschenken, wenn eine andere Klasse von A noch Bedarf an Bandbreite hat. In diesem Fall ist für Teilnehmer A das zweite Konfigurationsszenario optimal, da es so lange die Unterklassen von A mit Bandbreite bedient, bis die garantierte Bandbreite vergeben ist.
Hierarchical Token Bucket
Der HTB-Algorithmus (Hierarchical Token Bucket) gehört seit Version 2.4.20 zur Standardausstattung des Kernels[2]. Eine HTB-QDisc kommt mit wenigen Optionen aus. Der Default-Parameter gibt eine Klasse an, die alle nicht klassifizierten Pakete erhält: »tc … htb [default Class-ID]«. Die Hierarchie und die Konfiguration der einzelnen Klassen bestimmen das Verhalten einer HTB-QDisc.
Der Algorithmus verwendet das Token-Bucket-Prinzip, um die Sendeleistung der einzelnen Klassen zu begrenzen. Daher ähneln die Parameter einer HTB-Klasse denen einer TBF-QDisc:
tc ... htb rate r [burst b] [prio p] [ceil r2] [cburst b2]
Die Parameter »rate« und »burst« limitieren die garantierte Sendeleistung der Klasse. Andere Parameter legen fest, wie HTB die ungenutzte Bandbreite an die übrigen Klassen verteilt: Sie dürfen nur bis zum »ceil«-Wert von ungenutzter Bandbreite profitieren. In welcher Reihenfolge die Klassen Bandbreite erhalten, hängt von deren »prio«-Wert ab. Die »tc«-Umsetzung der Beispiele aus den Abbildungen 4a und 4b ist in den Listings 1a und 1b zu sehen. Sie erzeugen die Root-QDisc und ergänzen dann die Klassen der einzelnen Ebenen.
Kurvenreich: HFSC
Nicht alle Probleme, die beim Aufteilen eines Netzzugangs auftreten, sind durch Verteilen und Garantieren von Bandbreite lösbar. Voice over IP und Streaming-Anwendungen brauchen ein Queueing, das Verzögerungen vermeidet. Die Vergabe von Bandbreite hilft nur bedingt, ist aber ein wichtiger Faktor.
Angenommen jedes zu sendende Paket ist 1500 Byte groß und alle Klassen senden mit maximaler Kapazität. Aufgrund der Leitungskapazität von 1000 KBit/s dauert es 12 Millisekunden, um ein Datenpaket zu versenden: 1500 Byte/Paket * 8 Bit/Byte / 1000000 Bit/s = 12 ms/Paket. Sendet die VoIP-Anwendung mit 100 KBit/s, dann sind das bei 1500-Byte-Paketen etwa acht Pakete pro Sekunde: 100000 Bit/s / (1500 Byte/Paket * 8 Bit/Byte) = 8,33 Pakete/s. Um die garantierte Rate von 100 KBit/s für diese Klasse einzuhalten, muss die QDisc spätestens alle 120 Millisekunden ein Datenpaket der Klasse versenden: 1 Paket / 8,33 Pakete/s = 0,12 s. Daraus ergibt sich eine maximale Verzögerung von etwa 132 Millisekunden pro Paket (120 ms + 12 ms). Das Beispiel illustriert die enge Verflechtung von Bandbreite und Verzögerungszeit.
Der HFSC-Algorithmus (Hierarchical Fair Service Curve,[3]) behandelt die beiden Ressourcen Bandbreite und Verzögerungszeit getrennt und vergibt sie nach dem Servicekurven-Modell. Eine Servicekurve S(t) repräsentiert die geleistete Arbeit (Service) in gesendeten Bits zu einem Zeitpunkt t. Die Steigung der Kurve entspricht der Senderate.
Steigung auf Raten
Die Verzögerungszeiten beeinflusst HFSC durch die Form der Servicekurven für die einzelnen Klassen. Für die VoIP-Klasse eignet sich eine zweiteilige, stückweise lineare Servicekurve. Deren erster Abschnitt weist eine Steigung von 400 KBit/s auf und ist 30 Millisekunden lang. Die Steigung des zweiten Abschnitts beträgt 100 KBit/s. Die Kurve reduziert die Sendeverzögerung auf 30 Millisekunden (Abbildung 5b). Der Gewinn von etwa 78 Millisekunden Verzögerungszeit geht jedoch zu Lasten der anderen Klassen: Zu keinem Zeitpunkt darf die Summe aller Kurven über der Servicekurve der Leitung liegen.
In obigem Beispiel soll die geringere Verzögerung der VoIP-Klasse auf Kosten der unspezifizierten Daten von Partei A gehen. Dazu braucht sie eine angepasste Servicekurve, die das globale Limit einhält. Die maximale Sendeverzögerung dieser Klasse erhöht sich von 30 auf 52,5 Millisekunden. Für reinen Datentransport, zum Beispiel FTP, spielt die Verzögerung kaum eine Rolle. Hier ist der Datendurchsatz wichtig, den die angepasste Servicekurve nicht beeinträchtigt.
|
Listing 1a: Flache |
|---|
01 tc qdisc add dev eth0 root handle 1: htb default 30 02 tc class add dev eth0 parent 1: classid 1:1 htb rate 1000kbit ceil 1000kbit 03 tc class add dev eth0 parent 1:1 classid 1:10 htb rate 400kbit ceil 1000kbit 04 tc class add dev eth0 parent 1:1 classid 1:20 htb rate 100kbit ceil 1000kbit 05 tc class add dev eth0 parent 1:1 classid 1:30 htb rate 500kbit ceil 1000kbit |
|
Listing 1b: HTB-Hierarchie mit |
|---|
01 tc qdisc add dev eth0 root handle 1: htb default 20 02 tc class add dev eth0 parent 1: classid 1:1 htb rate 1000kbit ceil 1000kbit 03 tc class add dev eth0 parent 1:1 classid 1:10 htb rate 500kbit ceil 1000kbit 04 tc class add dev eth0 parent 1:1 classid 1:20 htb rate 500kbit ceil 1000kbit 05 tc class add dev eth0 parent 1:10 classid 1:11 htb rate 400kbit ceil 1000kbit 06 tc class add dev eth0 parent 1:10 classid 1:12 htb rate 100kbit ceil 1000kbit |
Abschlusskontrolle
Der Linux-Kernel kann den Netzwerkverkehr sehr flexibel kontrollieren und nach festen Vorgaben formen. Er bietet für die denkbaren Szenarien verschiedene Lösungen an, die er zudem untereinander (fast beliebig) zu kombinieren weiß. Mehr Informationen und Anwendungsbeispiele sind im Linux Advanced Routing and Traffic Control Howto[4] zusammengefasst. An gleicher Stelle ist eine Mailingliste für Fragen, Diskussion und Hilfestellung eingerichtet. (fjl)
|
Infos |
|---|
|
[1] IProute2: [http://developer.osdl.org/dev/iproute2/] [2] HTB: [http://luxik.cdi.cz/~devik/qos/htb/] [3] HFSC: [http://trash.net/~kaber/hfsc/] [4] Linux Advanced Routing and Traffic Control Howto: [http://www.lartc.org] [5] RFC 2474, “Definition of the Differentiated Services Field (DS Field) in the IPv4 and IPv6 Headers”: [http://www.ietf.org/rfc/rfc2474.txt] |
|
Die Autoren |
|---|
|
Klaus Rechert beendet gerade seine Diplomarbeit an der Uni Freiburg. Patrick McHardy ist aktiver Kernelentwickler und Autor der Linux-Implementierung von HFSC. |





