
Wer ganze Gruppen von Linux-Systemen verwaltet, unterscheidet sich vom Root einer einzelnen Workstation. Diese Serie widmet sich den Besonderheiten der Linux-Administration in komplexen Umgebungen. Nach der Einführung stellt dieser erste Teil ein einfaches, aber effektives Überwachungssytem vor.
Unix ist benutzerfreundlich, es sucht sich seine Freunde nur gut aus. Diesen etwas angestaubten Spruch hat jeder Linux-Anwender gewiss schon mal gehört. Er trifft die Realität aber recht gut: Bereits die ersten Annäherungsversuche bei der Installation fallen, je nach individuell zugeteiltem Glück, mehr oder minder emotionsgeladen aus. So bildet sich die Grundlage für lebenslangen Hass oder innige Freundschaft.
Admin-Know-how ist fast unvermeidbar
In der Folgezeit erlernt der Linux-Nutzer fast zwangsläufig administrative Grundkenntnisse. Fähigkeiten, die früher den langhaarigen, weiß bekittelten Fachleuten aus der EDV-Abteilung vorbehalten waren, gehören heute zum Handwerkszeug jedes PC- Eigentümers – sofern er Linux verwendet und das Betriebssystem auch selbst installiert. Bei vielen kniffligen Aufgaben unterstützen ihn die bequemen Werkzeuge der gewählten Distribution, wenn es zum Beispiel um die Konfiguration einer Netzwerkkarte oder ein halbwegs sinnvolles Backupsystem geht. Manuelle Eingriffe auf der Konsole sind immer seltener nötig, GUI-gestützte Tools decken beinahe alle wichtigen Gebiete ab.
Listing 1: Zu prüfende Services |
01 test/ping www 02 test/star dbint 03 test/mysql dbext 04 test/mysql dbext2 05 test/http www 06 test/http www2 07 test/http java 08 test/http java2 09 test/ftp ftp 10 test/smtp mail 11 test/smtp mail2 12 test/pop mail 13 test/pops mail 14 test/imap mail 15 test/imaps mail |
Menschen und Maschinen
Begriffe wie Admin und Operator haben sich in der Folge gewandelt. Den Root-User eines Einzelsystems unterscheidet vom Verwalter einer Serverfarm vor allem das Mehr an Menschen und Maschinen, das Letzterer betreuen muss. Bei der eigenen Workstation sind Admin und User in der Regel identisch – eine ideale Konstellation für die Konfliktvermeidung. Wer einen ganzen Park von Linux-Kisten unter sich hat, teilt die Geräte mit anderen. Das öffnet ungeahnte Kriegsschauplätze.
Der Admin kennt das System, seine Architektur und die daraus folgenden Notwendigkeiten. Bei den Benutzern ist das meist anders: Wer den Computer nicht versteht, akzeptiert Einschränkungen nicht so ohne weiteres. “Warum muss ich da jedes Mal ein Passwort eingeben? Wieso kann ich mein Outlook hier nicht starten? Das Ding fiept zu laut, wenn ich es einschalte!” Ein späterer Artikel dieser Reihe wird auf die besonderen Wünsche der Windows-gewohnten Angestelltenschaft eingehen.
Ganz andere Erfreulichkeiten ergeben sich, wenn umgekehrt die Nutzer noch etwas besser Bescheid wissen als der Verantwortliche für die Rechner. Klares Netzwerkdesign ade, heißt es in dieser Situation schnell. Wer sich nicht durchsetzt, findet auf jeder Maschine eine andere Installation vor.
Größenordnungen
Auch die Anzahl der Rechner wirft neue Fragen auf. Ein geübter Linux-Freund braucht für die Installation in der Nachbarschaft selten mehr als eine Stunde. Seine Technik stößt aber hart an die Grenzen der Admin-Realität, wenn hundert Server auf einmal betriebsbereit werden müssen – statt über vier Tage durchzuarbeiten, sind bessere Alternativen gefragt.
Die spätere Software-Installation und die Updates gegen Sicherheitslücken sind ein ähnliches Problem. Per Hand durchgeführt (Abbildungen 1 und 2) kosten sie auf einem einzelnen Rechner kaum Zeit – aber viele Male wenig Zeit bedeutet schnell einen verlorenen Tag. Gut, wenn sich der Admin zu helfen weiß. Dass einige der hübschen grafischen Tools in einem größeren Netzwerk ihren Wert verlieren, ist eine Herausforderung für den echten Profi.
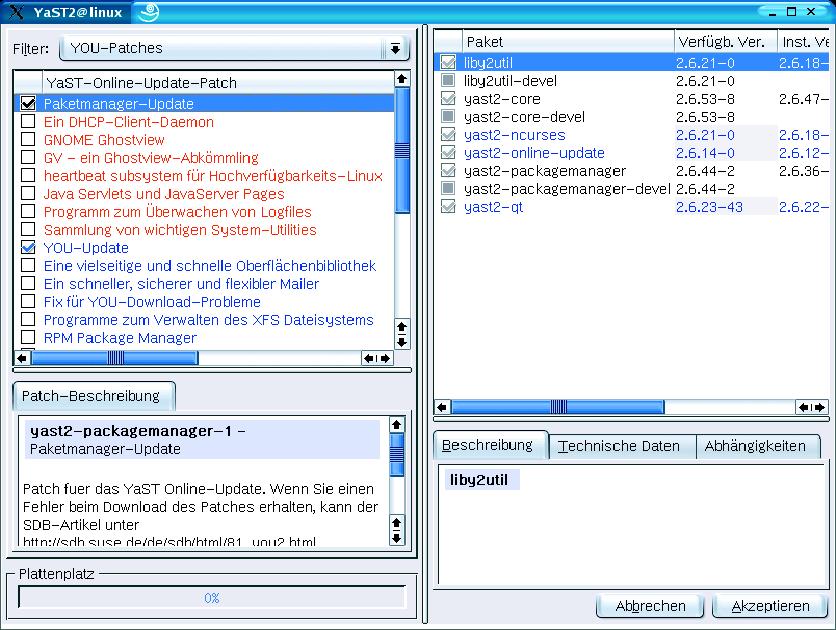
Abbildung 1: Manuelle Online-Updates wie hier bei SuSE Linux sind für Einzelplatzsysteme eine hervorragende Lösung, um Sicherheits-Updates (rot) rasch einzuspielen. Admins großer Netze brauchen andere Techniken.
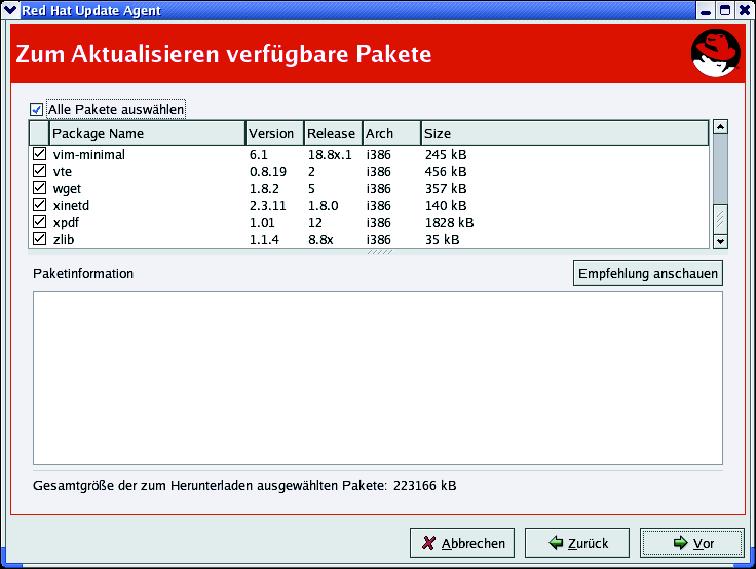
Abbildung 2: Auch Red Hat bietet ein halbautomatisches Online-Update an. Im Gegensatz zur SuSE-Variante ist leider nicht zu sehen, ob es sich um normale Bugfixes oder um Sicherheitspatches handelt.
Homogene Netze, in denen beispielsweise nur Red-Hat-Systeme stehen, sind die Ausnahme. In der Regel koexistieren Windows- mit Unix-Maschinen, oft sind mehrere verschiedene Unix-Varianten parallel im Einsatz. Selbst die Entscheidung für eine konkrete Linux-Distribution gelingt nicht überall. Recht häufig ist aber nur ein Team oder eine Person für die Vielfalt verantwortlich. Gut beraten ist, wer Aufgaben und Arbeitsabläufe trotzdem vereinheitlicht.
Ein echter Admin erledigt eine Vielzahl von Aufgaben in äußerst knapp bemessener Zeit. Effizienz ist das Zauberwort – Admins selbst umschreiben das gerne mit Faulheit. Sie sind zu faul, dieselbe Aktion mehrfach manuell auszuführen, also schreiben sie ein Skript, das ihnen die Arbeit abnimmt.
Immer verfügbar
Die Anzahl der Maschinen ist ein Problem, ein anderes sind die Anforderungen, die an sie gestellt werden. Stürzt der Heim-PC einmal ab, schimpft im schlimmsten Falle der Sohnemann, weil sein Onlinespiel nicht mehr funktioniert. Lösen kann man das Problem später mal. Steht jedoch ein Printserver in der Firma, drehen die Angestellten Däumchen und der Admin bangt um seine Stelle. Fällt gar eins der kritischen Systeme aus, kommt es schnell zu großen Verlusten an Geld und Daten. Der perfekte Admin sei derjenige, so heißt es, dessen Existenz man nicht bemerkt. Damit nun wirklich kein Stein des Anstoßes entsteht, gilt es vorzubeugen. Und das auf mehreren Ebenen.
Häufig unterschätzt, aber von zentraler Bedeutung ist die Dokumentation. Die Anforderungen an sie variieren stark – je komplexer das Netzwerk, desto detaillierter muss es beschrieben sein. Eine kleine Werkstatt mit zwei Teilzeit-Admins kommt vielleicht mit einem Schnellhefter im Serverraum aus, in dem die geplante und die tatsächliche Architektur verzeichnet sind. Änderungen werden sofort nachgetragen (siehe Abbildung 3) und neu ausgedruckt. Dokumentation mit Tinte und Papier hat den Vorteil, dass sie auch im Ernstfall verfügbar ist, wenn sich der Fileserver längst verabschiedet hat.
Sorgfältige Planung
Alle Änderungen an Systemen müssen deren Admins sorgfältig planen und testen, bevor sie sie in die Praxis umsetzen. Der private Apache darf beim Laden der geänderten Konfiguration schon mal blockieren. Einem öffentlichen Webserver sollte das tunlichst nicht passieren. Falls wider Erwarten doch etwas schief geht, muss ein durchdachter Notfallplan beim Wiederherstellen des vorigen Zustands helfen.
In weniger kritischen Situationen ist es schon mal üblich, dass ein erfahrener Admin neue Software über die Vorversion installiert oder Konfigurationsdateien an Ort und Stelle ändert. Mehr Vorsicht spart Nerven und sichert Arbeitsplätze: Wenn dem frisch übersetzten Modul noch eine Shared Library fehlt, sollte die Vorversion binnen Sekunden wieder zur Stelle sein.
Ausfälle vermeiden erreicht man nicht allein durch Umsicht. Gewisse Fehler mögen vermeidbar sein, Hardware-Ausfälle und gekappte Versorgungsleitungen gehören zu den ärgerlichen Unvermeidbarkeiten. Hier hilft ein konsequent redundantes Design, mit Blick auf Funktionen wie auch auf Systeme. Verschwindet eine Komponente von der Bildfläche, übernimmt die nächste. Aber nicht jeder Betrieb kann sich diese Materialschlacht leisten.
Kommt es trotz allem zum GAU, sollte der Admin ihn wenigstens rechtzeitig bemerken. Aber wer sitzt schon in der Nacht an der Konsole und prüft ständig die Syslogs? Kritische Dienste müssen vollautomatisch überwacht werden und gegebenenfalls selbsttätig auf Probleme aufmerksam machen.
Der große Bruder
Ein relativ einfaches, aber effektives System zur Überwachung ist schnell realisiert. Die aus Abbildung 3 bekannten Services sind in Listing 1 wiederholt: Die erste Spalte nennt den Pfad zu einem Skript, das den Dienst überprüft, Spalte zwei ergänzt den Namen des Hosts, auf dem der Service laufen sollte. Listing 2 zeigt als Beispiel die Datei »test/smtp«, ein Mini-Testskript für den Mailservice. Wenn die Verbindung zum SMTP-Port fehlschlägt oder die Begrüßungsmeldung nicht mit der Ziffer »2« beginnt, gibt das Skript eine Alarmmeldung aus (Zeile 11), sonst nichts (8).
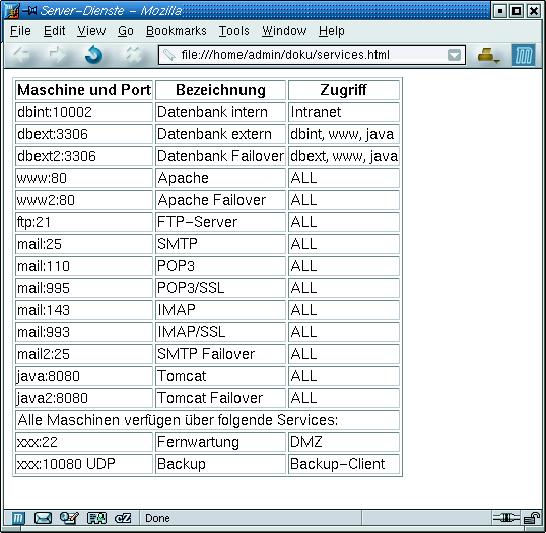
Abbildung 3: Genaue Dokumentation gehört zu den Aufgaben eines Admin: Diese Liste mit Serverdiensten hilft im Notfall der Aushilfskraft bei ihrer Arbeit.
Listing 2: SMTP-Test |
01 #!/usr/bin/perl -w
02
03 use Socket;
04 die "No host name given" if not defined $ARGV[0];
05 if (socket(SOCK, PF_INET, SOCK_STREAM, getprotobyname('tcp')) and
06 connect(SOCK, sockaddr_in(25, inet_aton($ARGV[0])))) {
07 my $line = <SOCK>;
08 exit 0 if defined $line and $line =~ /^2/;
09 }
10 # Fehler:
11 print "smtp auf $ARGV[0]n";
12 exit 1;
|
Ein Steuerskript (Listing 3) liest in Zeile 6 die Datei aus Listing 1 und führt ihren Inhalt aus. Dieser Shellprogrammierer-Trick fasst gleichzeitig die Ausgaben aller Testskripte im String »$RES« zusammen. Wenn einer der Tests fehlschlägt, sendet der Master eine Mail an die in Zeile 4 genannten Adressen. Da viele Mail-to-SMS-Gateways nur das Subject weiterleiten, hängt das Skript in Zeile 11 die Fehlermeldungen dort an.
Aus der Ferne
Das Skript kann mehrmals pro Stunde laufen und verschickt nur im Fehlerfall eine E-Mail an eine bestimmte Adresse. Wer sein Handy als Ziel angibt, erhält selbst in der Oper eine Nachricht, wenn der Webserver in der Firma hängt. Freilich sollte das Überwachungssystem nicht gerade auf dem eigenen Webserver laufen und zusammen mit ihm ausfallen. Externe Failover-Systeme gibt es für die meisten Profi-Websites, sie bieten sich als Basis für die Überwachung geradezu an. Es gibt auch einige entsprechende Anbieter im Internet.
Listing 3: Überwachungsskript |
01 #!/bin/sh 02 03 # Zieladressen für die Mails 04 DEST="01712345678@t-d1-sms.de, musikfan@imail.de" 05 06 RES=`. liste` 07 if [ "$RES" != "" ]; then 08 cat <<EOF | /usr/lib/sendmail -t -U 09 From: root@localhost 10 To: $DEST 11 Subject: URGENT: Server-Problem: $RES 12 13 Hallo, 14 15 auf dem Webcluster sind Probleme aufgetreten, und zwar bei folgenden 16 Services: 17 18 $RES 19 EOF 20 fi |
Der Ausfall des überwachenden Systems ist schwer zu bemerken – denn es kann ja nichts mehr verschicken. Erfolgsmails, wenn alles glatt geht, sind bei zehn Tests in der Stunde schnell ermüdend. Eine Alternative ist es, alle Tests zu protokollieren und ein- oder zweimal täglich zusammenzufassen. Sofort, wenn ein Fehler auftritt, sonst jeweils um acht und zwanzig Uhr. Dann bleibt nur noch zu hoffen, dass innerhalb von zwölf Stunden nicht sowohl die Überwachungsmaschine als auch ein kritischer Dienst ausfallen.
Backup, Datenschutz und Datensicherheit
Last, but not least treibt das ungeliebte Thema der Backups an die Oberfläche. Sicherungskopien sind auf einem einzelnen Rechner schon so lästig, dass viele Leute in sträflichem Optimismus auf sie verzichten. Bei einer größeren Zahl von Computern steigen das Datenvolumen und vor allem der logistische Aufwand. Ein Trost bleibt: Mehr Geräte heißt mehr Ausfallwahrscheinlichkeit, die Backups lohnen sich also früher.
Sicherheit spielt in komplexen Umgebungen eine ungleich größere Rolle als daheim. Die wichtigste Security-Strategie für den Privatrechner lautet: alle Server abschalten und über den Paketfilter alle ankommenden Verbindungen blockieren. Auf eine Serverfarm lässt sich das Konzept nicht übertragen, Netzwerkdienste sind Inhalt und Aufgabe dieser Maschinen. Statt sie einfach zu blockieren, muss man sie absichern. Die Firewall hilft jetzt nicht mehr so leicht.
Kritische Bedeutung erhalten nun die Updates und Patches. Ist eine Sicherheitslücke gefunden und publiziert, muss der Admin sie möglichst bald schließen. Das heißt nicht, in blindem Aktionismus jede Software aktualisieren. Neue Versionen enthalten meist auch neue Fehler oder Idiosynkrasien. Was einmal funktioniert hat, wird nicht für immer gut gehen. Es gilt, sich sorgfältig zu informieren und in jedem Einzelfall verantwortungsbewusst zu entscheiden, ob und wann ein Update fällig ist.
Angriffsversuche oder gar Einbrüche erkennen ist zurzeit ein heiß diskutiertes Thema. Jeder hat sein privates Erfolgsrezept und fragt sich, warum nicht alle auf den gleichen Zug springen. Unbestritten ist: Zum fachmännischen Management von Computern im professionellen Umfeld gehört eine durchdachte Lösung dieses Problems. Die händische Durchsicht von 25 MByte Logfiles täglich wird sich nicht qualifizieren.
Ausblick
Selbst wenn der Umgang mit Linux an sich problemlos geworden ist, erwarten den Administrator auch heute noch genügend Aufgaben, die seinen Job interessant und reizvoll machen. Trotz KDE, Gnome und Yast sind seine besonderen Kenntnisse weiterhin gefragt. Es ist kein Zufall, dass fähige Systemverwalter nach wie vor heiß umworben sind. In den kommenden Ausgaben wird diese Serie in verschiedene Themenkomplexe rund um das Administrieren einführen. Die soeben angesprochenen Punkte sind sicherlich dabei, ergänzt um weitere wichtige Aufgaben. (fjl)





