
© Michal Bednarek, 123RF
Im aktuellen Artikel zu den C++ Core Guidelines stehen einmal mehr Regeln zur Performance im Fokus. Wer sie befolgt, den belohnt ein Software-Entwurf, der qua Design performant ist.
Beim Lesen der Kapitelüberschrift “Design to enable optimization” in den C++ Core Guidelines [1] kam dem Autor dieser Zeilen sofort die Move-Semantik in den Sinn. Warum? Programmierer sollten, wo immer möglich, Algorithmen mit Move- und nicht mit Copy-Semantik implementieren. Die Vorteile liegen auf der Hand:
- Statt einer teuren Copy- genügt eine ressourcensparende Move-Operation.
- Der Algorithmus ist deutlich stabiler, da er keinen Speicher braucht und der Code somit keine »std::bad_alloc«-Ausnahme wirft.
- Der Algorithmus deckt Datentypen wie »std::unique_ptr« ab, die sich nicht kopieren, sondern nur verschieben lassen.
Der in Listing 1 gezeigte »swap()«-Algorithmus veranschaulicht das; er basiert auf der Move-Semantik.
Listing 1
Move-Semantik mit swap()
#include <algorithm>
#include <cstddef>
#include <iostream>
#include <vector>
template <typename T>
void swap(T& a, T& b) noexcept {
T tmp(std::move(a));
a = std::move(b);
b = std::move(tmp);
}
class BigArray{
public:
BigArray(std::size_t sz): size(sz), data(new int[size]){}
BigArray(const BigArray& other): size(other.size), data(new int[other.size]){
std::cout << "Copy constructor" << std::endl;
std::copy(other.data, other.data + size, data);
}
BigArray& operator=(const BigArray& other){
std::cout << "Copy assignment" << std::endl;
if (this != &other){
delete [] data;
data = nullptr;
size = other.size;
data = new int[size];
std::copy(other.data, other.data + size, data);
}
return *this;
}
~BigArray(){
delete[] data;
}
private:
std::size_t size;
int* data;
};
int main(){
std::cout << std::endl;
BigArray bigArr1(2011);
BigArray bigArr2(2017);
swap(bigArr1, bigArr2);
std::cout << std::endl;
};
Das sieht einfach aus, ist es aber leider nicht: Das Listing verwendet den Datentyp »BigArray«, der hier ein ernsthaftes Problem aufwirft. Er unterstützt nur Copy-, aber keine Move-Semantik. Zum Beispiel stellt sich die Frage, was passiert, wenn Zeile 7 zwei »BigArray«-Variablen tauscht, während der »swap()«-Algorithmus unter der Haube Move-Semantik verwendet (Abbildung 1).
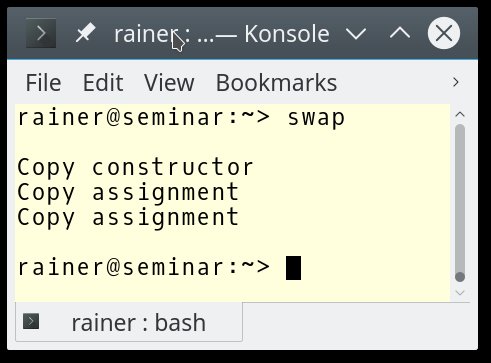
Abbildung 1: Die Move-Semantik wird hier auf einen kopierbaren Datentyp angewandt.
Überraschung! Tatsächlich passiert nichts, es funktioniert einfach. Die traditionelle Copy-Semantik springt für die Move-Semantik ein und dient als eine Art Fallback. Oder, um es anders zu formulieren: Verschieben ist ein optimiertes Kopieren. Doch warum?
Der »swap()«-Algorithmus fordert Move-Semantik an, da »std::move« [2] einen Rvalue zurückgibt. Eine konstante Lvalue-Referenz kann einen Rvalue binden. Zugleich besitzen der Copy-Konstruktor und der Copy-Zuweisungsoperator eine konstante Lvalue-Referenz als Argument. Besäße »BigArray« einen Move-Konstruktor und einen Move-Zuweisungsoperator, die jeweils eine Rvalue-Referenz erwarten würden, hätten beide eine höhere Priorität als ihre Copy-Gegenstücke.
Verwenden Algorithmen Move-Semantik, kommt diese automatisch zum Einsatz, sofern die Datentypen sie unterstützen. Tun sie das nicht, springt die Copy-Semantik ein. Im Worst Case besitzt das Programm dieselben Performance-Charakteristiken wie ein vor C++11 entstandenes Programm.
Rechne zur Compile-Zeit
Einen ähnlichen allgemeinen Fokus wie die vorgestellte Performance-Regel “Design to enable optimization” besitzt die Aufforderung: “Move computation from run time to compile time” [3]. Ein Beispiel für die damit verbundene Regel zeigt Listing 2. Der altbekannte »gcd()«-Algorithmus ermittelt dort zur Laufzeit des Programms den größten gemeinsamen Teiler zweier Zahlen. »gcd()« verwendet für seine Berechnung den euklidischen Algorithmus [4].
Listing 2
Der gcd()-Algorithmus
int gcd(int a, int b){
while (b != 0){
auto t= b;
b= a % b;
a= t;
}
return a;
}
Wenn Sie »gcd()« als konstanten Ausdruck deklarieren, können Sie ihn so zur Funktion erklären, die C++ auch zur Übersetzungszeit ausführt. Es gibt in C++14, im Gegensatz zu C++11, nur noch wenige Einschränkungen für »constexpr«-Funktionen. So darf »gcd()« keine statischen oder Thread-lokalen Variablen verwenden. Ebenfalls nicht zulässig sind Ausnahmebehandlungen und »goto«-Anweisungen. Sie müssen Variablen direkt initialisieren, und diese müssen einen literalen Typ besitzen. Listing 3 demonstriert eine Implementierung und Anwendung der »constexpr«-Variante des »gcd()«-Algorithmus.
Listing 3
gcd()-Algorithmus zur Compile-Zeit
#include <iostream>
constexpr int gcd(int a, int b){
while (b != 0){
auto t= b;
b= a % b;
a= t;
}
return a;
}
int main(){
std::cout << std::endl;
constexpr auto res = gcd(121, 11);
std::cout << "gcd(121, 11) = " << res << std::endl;
auto val = 121;
auto res2 = gcd(val, 11);
std::cout << "gcd(val, 11) = " << res2 << std::endl;
std::cout << std::endl;
}
Wenn Sie den »gcd()«-Algorithmus zur »constexpr«-Funktion erklären, bedeutet das jedoch nicht, dass C++ ihn automatisch zur Übersetzungszeit ausführt. Vielmehr erhält die Funktion »gcd()« auf diesem Weg lediglich das Potenzial dafür. C++ führt eine »constexpr«-Funktion nur dann zwangsläufig zur Übersetzungszeit aus, wenn sie in einem konstanten Ausdruck auftritt.
In Zeile 16 steht ein konstanter Ausdruck, der das Ergebnis mit der »constexpr«-Variablen »res« aufpickt, in Zeile 20 hingegen nicht: »res2« ist kein konstanter Ausdruck. Hätten Sie also »res2« als »constexpr auto res2« deklariert, würde der Compiler das postwendend mit einer Fehlermeldung quittieren. Der Grund: »val« in Zeile 20 ist kein konstanter Ausdruck. Abbildung 2 zeigt das Programm in Aktion.
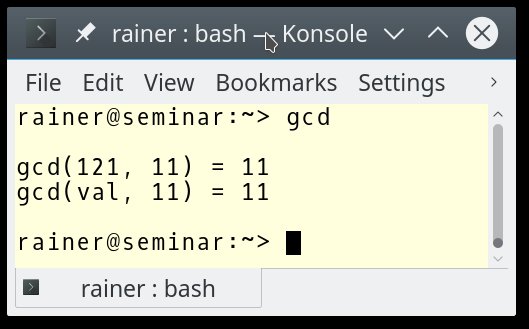
Abbildung 2: Der »gcd()«-Algorithmus lässt sich so umsetzen, dass C++ ihn zur Übersetzungszeit ausführt.
Lässt sich beweisen, dass C++ die Zeile 16 zur Übersetzungszeit ausführt? Klar: Abbildung 3 zeigt die der Zeile entsprechenden Assembler-Anweisungen, die GCC 7.3 mit maximaler Optimierung erzeugt. Die Ausgabe hat der Compiler Explorer von Matt Godbolt festgehalten. Der Funktionsaufruf »gcd(121, 11)« reduziert sich direkt auf das Ergebnis »11«.
Abbildung 3: Der Compiler Explorer zeigt die Assembler-Anweisungen zur Zeile 16 von Listing 3.
Kosten sparen
Entwickler setzen gern Templates ein, um Entscheidungen zur Übersetzungszeit zu treffen. Auch dazu stellen die C++ Core Guidelines ein schönes Beispiel vor. Eine beliebte Technik besteht etwa darin, einen Handle für das Speichern von Daten auf dem Stack anzulegen, wenn die Daten klein genug sind. Falls nicht, verwaltet C++ sie auf dem Heap.
Diese Idee setzt zum Beispiel die SSO (Small String Optimization [5]) um. Das heißt, dass der Code einen »std::string« nur dann auf dem Heap anlegt, wenn er eine gewisse Größe übersteigt. Der entscheidende Grund für diese Optimierung besteht darin, dass das Allozieren von Speicher eine relativ teure Angelegenheit ist. Listing 4 skizziert die Idee.
Listing 4
Teure Speicherallozierung vermeiden
template<typename T>
struct Scoped { // store a T in Scoped
// [...]
T obj;
};
template<typename T>
struct On_heap { // store a T on the free store
// [...]
T* objp;
};
template<typename T>
using Handle = typename std::conditional<(sizeof(T) <= on_stack_max),
Scoped<T>, // first alternative
On_heap<T> // second alternative
>::type;
void f()
{
Handle<double> v1; // the double goes on the stack
Handle<std::array<double, 200>> v2; // the array goes on the free store
[...]
}
Wie funktioniert das Ganze? »std::conditional« in Zeile 14 ist ein ternärer Operator aus der Type-Traits-Bibliothek [6]. Im Gegensatz zum ternären Operator »(a ? b : c)« führt das Listing ihn aber zur Übersetzungszeit aus. Evaluiert Zeile 14 »std::condition<sizeof(T)…« zu »true«, kommt die erste Alternative zum Zug, falls nicht, die zweite.
Zugriffsfrage
Die letzte vorgestellte Regel zur Performance beschäftigt sich mit der Vorhersagbarkeit von Speicherzugriffen, der Access Memory Predictability [7].
Liest der Prozessor eine Variable vom Datentyp »int«, umfasst das tatsächlich deutlich mehr als 4 Bytes: Er liest eine ganze Cacheline und speichert sie im Cache. Auf modernen Architekturen umfasst eine solche Cacheline typischerweise 64 Bytes. Fordert die CPU nun nochmals eine Variable aus dem Hauptspeicher an und befindet sich diese bereits im Cache, verwendet die Leseoperation direkt den Cache und wird damit deutlich schneller.
Ein Container wie »std::vector«, der seine Daten in einem kontinuierlichen Speicherbereich ablegt, nutzt als Datenstruktur Cachelines optimal aus. Er besitzt eine definierte Größe und Kapazität und wächst nur in eine Richtung. Seine Kapazität ist nicht nur größer als seine Größe, sondern zeigt auch an, wann er Speicher neu allozieren muss. Das greift auch für »std::string« und »std::array«, wobei »std::array« keine Kapazität besitzt.
Meine Argumente für »std::vector« gelten nicht für die weiteren Sequenzcontainer »std::list« oder »std::forward_list«. Beide bestehen aus doppelt oder einfach verknüpften Knoten (Abbildung 4). Die »std::forward_list« wächst aber im Gegensatz zu einer »std::list« nur in eine Richtung.
Abbildung 4: Die Struktur einer »std::forward_list«, die nur in eine Richtung wachsen kann.
Ein »std::deque« bewegt sich zwischen beiden Extremen, denn es ist eine Art doppelt verkettete Liste von Speicherbereichen (Abbildung 5).
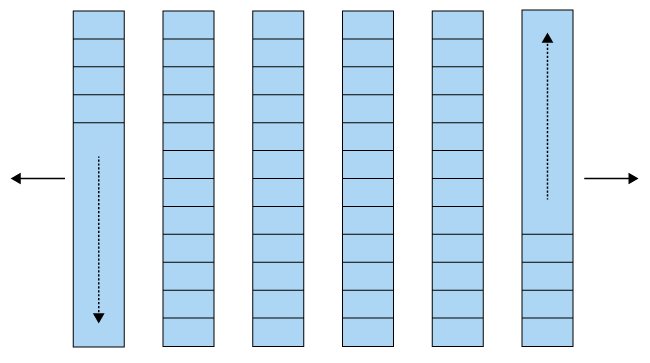
Abbildung 5: Ein »std::deque« ist eine doppelt verkettete Liste und ein Mittelding zwischen »std::list« und »std::forward_list«.
Soweit die Theorie zu den Cachelines. Listing 5 wirft implizit die Frage auf, ob es einen Performance-Unterschied bringt, alle Elemente eines »std::vector«, eines »std::deque«, einer »std::list« oder einer »std::forward_list« zu lesen und mithilfe des Algorithmus »std::accumulate« aufzusummieren. Das kleine Programm liefert auch gleich die Antwort dazu.
Listing 5
Speicherzugriff mit mehreren Sequenzcontainern
#include <forward_list>
#include <chrono>
#include <deque>
#include <iomanip>
#include <iostream>
#include <list>
#include <string>
#include <vector>
#include <numeric>
#include <random>
const int SIZE = 100'000'000;
template <typename T>
void sumUp(T& t, const std::string& cont){
std::cout << std::fixed << std::setprecision(10);
auto begin= std::chrono::steady_clock::now();
std::size_t res = std::accumulate(t.begin(), t.end(), 0LL);
std::chrono::duration<double> last= std::chrono::steady_clock::now() - begin;
std::cout << cont << std::endl;
std::cout << "time: " << last.count() << std::endl;
std::cout << "res: " << res << std::endl;
std::cout << std::endl;
std::cout << std::endl;
}
int main(){
std::cout << std::endl;
std::random_device seed;
std::mt19937 engine(seed());
std::uniform_int_distribution<int> dist(0, 100);
std::vector<int> randNumbers;
randNumbers.reserve(SIZE);
for (int i=0; i < SIZE; ++i){
randNumbers.push_back(dist(engine));
}
{
std::vector<int> myVec(randNumbers.begin(), randNumbers.end());
sumUp(myVec,"std::vector<int>");
}
{
std::deque<int>myDec(randNumbers.begin(), randNumbers.end());
sumUp(myDec,"std::deque<int>");
}
{
std::list<int>myList(randNumbers.begin(), randNumbers.end());
sumUp(myList,"std::list<int>");
}
{
std::forward_list<int>myForwardList(randNumbers.begin(), randNumbers.end());
sumUp(myForwardList,"std::forward_list<int>");
}
}
Das Programm erzeugt zuerst 100 Millionen Zufallszahlen zwischen 0 und 100 (Zeile 35). Dann summiert es die Zahlen mit einem »std::vector« (Zeile 46), einem »std::deque« (Zeile 52), einer »std::list« (Zeile 57) sowie einer »std::forward_list« (Zeile 62). Die eigentliche Arbeit findet in der Funktion »sumUp()« in Zeile 15 statt.
Listing 6 stellt eine typische Implementierung des »std::accumulate«-Algorithmus [8] vor. Alle vier Container verwenden dieselbe Implementierung, ihr Laufzeitverhalten unterscheidet sich aber deutlich. Abbildung 6 und Abbildung 7 stellen die Ausführungszeiten der Programme unter Linux und Windows dar. Beide Programme wurden mit maximaler Optimierung übersetzt. Im Gesamtbild führt das zu drei einfachen Beobachtungen:
- »std::vector« läuft unter Linux 10-mal schneller als »std::list« oder »std::forward_list«, unter Windows sogar 30-mal schneller.
- »std::vector« läuft unter Linux 1,5-mal schneller und unter Windows 5-mal schneller als »std::deque«. Der Grund liegt vermutlich darin, dass die zusammenhängenden Speicherbereiche unter Linux größer sind als unter Windows. Damit ähnelt die Zugriffszeit unter Linux der eines »std::vector«.
- »std::deque« ist unter Linux und Windows gleichermaßen 6-mal schneller als »std::list« oder »std::forward_list«.
Die Grafik mit den verschiedenen Ausführungszeiten in Abbildung 8 unterfüttert die Beobachtung direkt mit Daten.
Listing 6
std::accumulate-Implementierung
template<class InputIt, class T>
T accumulate(InputIt first, InputIt last, T init)
{
for (; first != last; ++first) {
init = init + *first;
}
return init;
}
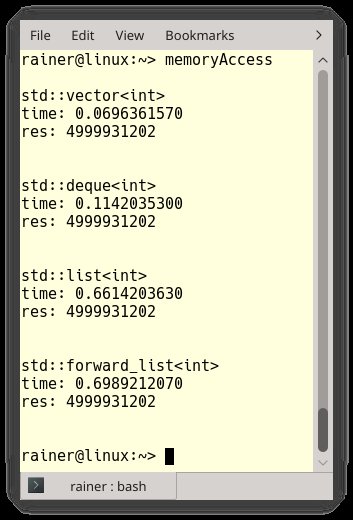
Abbildung 6: Ausführungszeit für die Summation unter Linux.
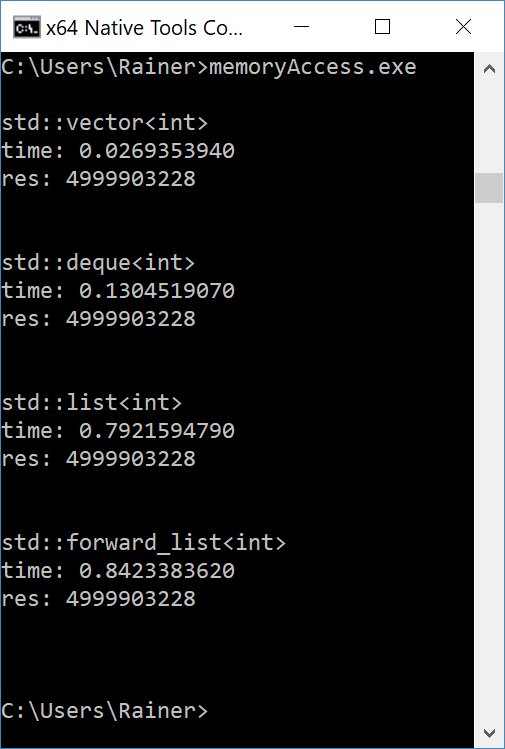
Abbildung 7: Ausführungszeit für die Summation unter Windows.
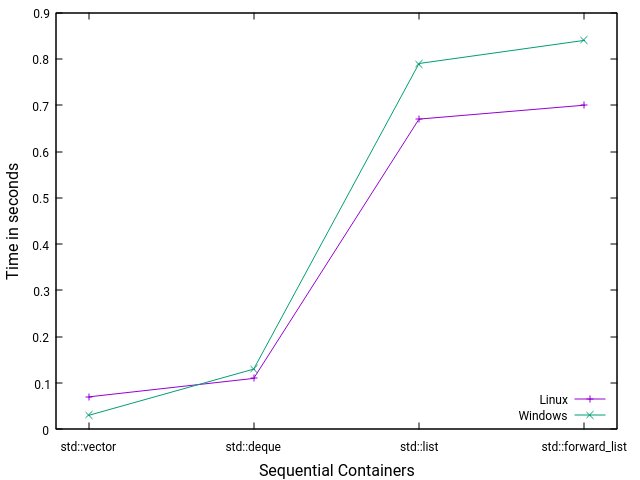
Abbildung 8: Ausführungszeit für die einzelnen Summationen.
Die Messungen legen eine einfache Schlussfolgerung nahe: Die Zugriffszeit auf die Elemente der Container ist der dominante Faktor für die Gesamt-Performance. Je besser eine Datenstruktur für Cachelines optimiert ist, desto kürzer die Zugriffszeit. Also: »std::vector« ist schneller als »std::deque«, das wiederum ist schneller als »std::list« und »std::forward_list«. (kki/jlu)
Infos
-
“Design to enable optimization”: https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Rper-efficiency
-
»std::move«: https://en.cppreference.com/w/cpp/utility/move
-
“Move computation from run time to compile time”: https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Rper-Comp
-
Small String Optimization: https://www.grimm-jaud.de/index.php/blog/c-17-vermeide-kopieren-mit-std-string-view
-
Type-Traits-Bibliothek: https://en.cppreference.com/w/cpp/header/type_traits
-
“Access memory predictably”: https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Rper-access
-
»std::accumulate«: https://en.cppreference.com/w/cpp/algorithm/accumulate





