
© Kittipong Jirasukhanont, 123RF
Wer den immer ausgefeilteren und immer genauer auf das Opfer zugeschnittenenen Angriffen auf die Computersicherheit begegnen will, muss Gefahren auch ohne menschliches Zutun erkennen. Dabei kann KI eine Schlüsselrolle spielen.
In der Industrie kommt künstliche Intelligenz mittlerweile von der Fertigung bis zum Vertrieb zum Einsatz, um Bauteile zu prüfen, Maschinen zu überwachen oder Verkaufszahlen sowie den Bedarf an Waren vorherzusagen. In der IT dagegen scheint sie noch nicht so weitverbreitet zu sein. Zwar wird gerade dort viel automatisiert, doch erst neueste Technologien machen es möglich, aus vorhandenen Daten zu lernen und das Gelernte auf neue Daten anzuwenden.
Ein Bereich, in dem KI-Systeme schon seit Langem zum Alltag gehören, ist das Identifizieren von Spam. Dabei lernt ein Computer anhand gesammelter Beispiele, ob es sich bei einer E-Mail um unerwünschte Werbung handelt. Andere interessante Anwendungen sind weniger offensichtlich. So besitzen neue AMD-Ryzen-Prozessoren beispielsweise eine Sprungvorhersage, die auf Perzeptronen basiert, also auf vereinfachten neuronalen Netzen. Die Datenbank PostgreSQL besitzt einen Abfrageoptimierer, der genetische Algorithmen verwendet, um die effizienteste Methode für das Verbinden von Tabellen nach vorgegebenen Kriterien zu finden. Eine im wahrsten Sinn des Wortes augenfällige Anwendung von Deep Learning nutzen moderne Nvidia-Grafikkarten unter dem Namen Deep Learning Supersampling (DLSS) für die Kantenglättung. Deep Code [1] schließlich erkennt Fehler in Programmcode, noch während der Programmierer ihn tippt.
Das Beispiel aus diesem Artikel widmet sich einem weiteren Gebiet der IT, in dem künstliche Intelligenz bereits eine Rolle spielt: In der Netzwerksicherheit erkennen sogenannte Network Intrusion Detection Systems (NIDS) bösartigen Netzwerkverkehr und beugen somit potenziellen Attacken vor. Dieser Artikel zeigt, wie man mit der quelloffenen Analyse-Software Knime ein solches System selbst entwickelt.
Knime Analytics Platform
In den Ausgaben 04/2018 [2] und 10/2018 [3] wurde Knime bereits anhand von Beispielen für einfache Datenverarbeitung und maschinelles Lernen vorgestellt. Die Knime Analytics Platform entstand ursprünglich am Lehrstuhl für Bioinformatik und Information Mining an der Universität Konstanz und wird heute von der Knime AG [4] betreute. Die Software erlaubt es, datenverarbeitende Workflows Schritt für Schritt auf einer grafischen Arbeitsfläche zu konstruieren. Auf diese Weise lassen sich komplexe Aufgaben für Datentransformation, Visualisierung und Analyse auf einfache und leicht zu verstehende Weise bearbeiten.
Im Folgenden werden die Autoren nicht mehr auf jedes Detail von Knime eingehen. Wer noch nie Kontakt damit hatte, findet in den oben erwähnten Linux-Magazin-Artikeln eine gute Einführung. Zusätzlich gibt es für für die Knime Analytics Platform Videos auf Youtube [5], diverse [6] Online-Kurse [7], Beispiel-Workflows [8] sowie ein Forum [9], in dem bei Fragen gerne geholfen wird.
Gefahr erkannt?
Generell unterscheidet man zwei Varianten von NIDS: Signaturbasierte Verfahren, die sich die Eigenschaften bekannter Angriffe merken, und anomaliebasierte Verfahren, die den bekannten gutartigen Netzwerkverkehr analysieren und bei Abweichungen von der Norm einen Alarm ausgeben. Der Nachteil der Ersteren liegt darin, dass sie neue Angriffsarten nicht erkennen können. Letztere dagegen benötigen eine sehr große Menge an Trainingsdaten und leiden auch mit diesen darunter, häufig Fehlalarme zu verursachen, weil die Grenze zwischen bösartigen und gutartigen Paketen im Netzwerk oft fließend ist. Diese Eigenschaften der beiden Verfahren prägen auch die im Folgenden gezeigten Knime-Workflows.
Als Beispieldaten für die Analyse dient der CICIDS2017-Datensatz [10] des Canadian Institute for Cybersecurity an der Universität New Brunswick. Der Datensatz wurde erzeugt, indem zuerst Netzwerkverkehr mit 14 verschiedenen bekannten Attacken aufgezeichnet wurde, sowie Hintergrundverkehr, wie ihn 25 reguläre Benutzer erzeugen. Das Programm CICFlowMeter [11] hat anschließend verschiedene Merkmale (Features) des Verkehrs extrahiert und in einer CSV-Datei abgelegt.
Dieser Artikel zeigt im Folgenden zunächst, wie der Anwender die Daten mit Knime visualisiert und aus den Grafiken Rückschlüsse auf die Struktur der Daten und die erforderlichen Vorverarbeitungsschritte zieht. Im Anschluss soll die Software ein Klassifikationsmodell erlernen, das die im Datensatz enthaltenen Attacken mit über 99-prozentiger Sicherheit erkennt. Da es in der Realität jedoch auch neue Attacken zu erkennen gilt, für die wahrscheinlich keine Daten vorliegen, zeigen die Autoren außerdem, wie man nur anhand der gutartigen Beispiele ein Modell anlernt, das dann Abweichungen (Anomalien) als bösartigen Netzwerkverkehr erkennt.
Exploration der Netzwerkdaten
Als Ausgangspunkt dient eine Tabelle mit 78 numerischen und einer nominalen Spalte, die ein klassisches Klassen-Label enthält. Jede Zeile der Tabelle repräsentiert ein Netzwerkpaket, insgesamt kommen es rund 2,8 Millionen zusammen.
Oft ist es ratsam, sich zunächst einmal mit einem unbekannten Datensatz vertraut zu machen. Dazu gehört zum Beispiel, herauszufinden, ob alle Merkmale Sinn ergeben und vollständig sind, wie die Verteilung der Merkmale aussieht, und welche (linearen) Abhängigkeiten zwischen Merkmalen bestehen. Verschiedene Statistiken und Visualisierungen helfen dabei. Tipp: Der verwendete, ziemlich große Datensatz zwingt einen Laptop schnell in die Knie. Wer die Workflows einmal auf die Schnelle ausprobieren will, der sollte mit einem Row-Sampling-Knoten die Datenmenge nach dem Einlesen reduzieren.
In einem Knime-Workflow repräsentieren sogenannte Knoten Verarbeitungsschritte, die sich grafisch miteinander zu einer Kette verbinden lassen, dem Workflow. Die Ausgaben des einen können als Eingabewerte des nächsten Knotens dienen. Ein guter Startknoten ist Statistics[a][b][c][d]. Neben einem Histogramm zeigt er für jede Spalte einer Tabelle Durchschnitts- und Extremwerte sowie verschiedene weitere Statistiken an, etwa die Standardabweichung.
Im vorliegenden Beispiel erkennt der Anwender anhand dieses Knotens unter anderem, dass zwei Spalten den Wert “unendlich” als Maximum besitzen. Es handelt sich um die Spalten »Flow Bytes/s« und »Flow Packets/s«. Zudem ergibt auf den ersten Blick auch deren Minimalwert keinen Sinn, der in beiden Fällen negativ ist. Wie das zustande kommt, lässt sich nicht so einfach nachvollziehen; deshalb ist es das Beste, diese beiden Spalten aus der Analyse herauszulassen. Sie würden sonst eher Ärger machen, anstatt das Modell zu verbessern. Ebenfalls für die Analyse nicht zu gebrauchen sind alle Spalten, die konstante Werte enthalten. Sie geben dem Modell über die Gut- beziehungsweise Bösartigkeit des Netzwerkverkehrs keine Auskunft.
Das Histogramm für die Label-Spalte mit der Klassifizierung der Datenpunkte zeigt, dass ein Wert besonders häufig vorkommt. Will der Anwender sehen, worum es sich dabei handelt, hilft ein Kuchendiagramm, das der Knoten Pie/Donut Chart aus dem Hut zaubert. Hier kann man erkennen, dass der Wert »BENIGN« (gutartig) das häufigste Label ist. Das war zu erwarten, dient doch ein Großteil des Netzverkehrs eben keinem Angriff.
Es ist außerdem zu sehen, dass die Labels, die mit »Web Attack« beginnen, nicht darstellbare Zeichen enthalten. Diese lassen sich mithilfe des Knotens String Manipulation und des folgenden Ausdrucks ersetzen:
regexReplace($Label$,"[^a-zA-Z ]+", "/")
Abbildung 1 zeigt das auf diese Weise verschönerte Kuchendiagramm für die jeweiligen Label-Klassen.
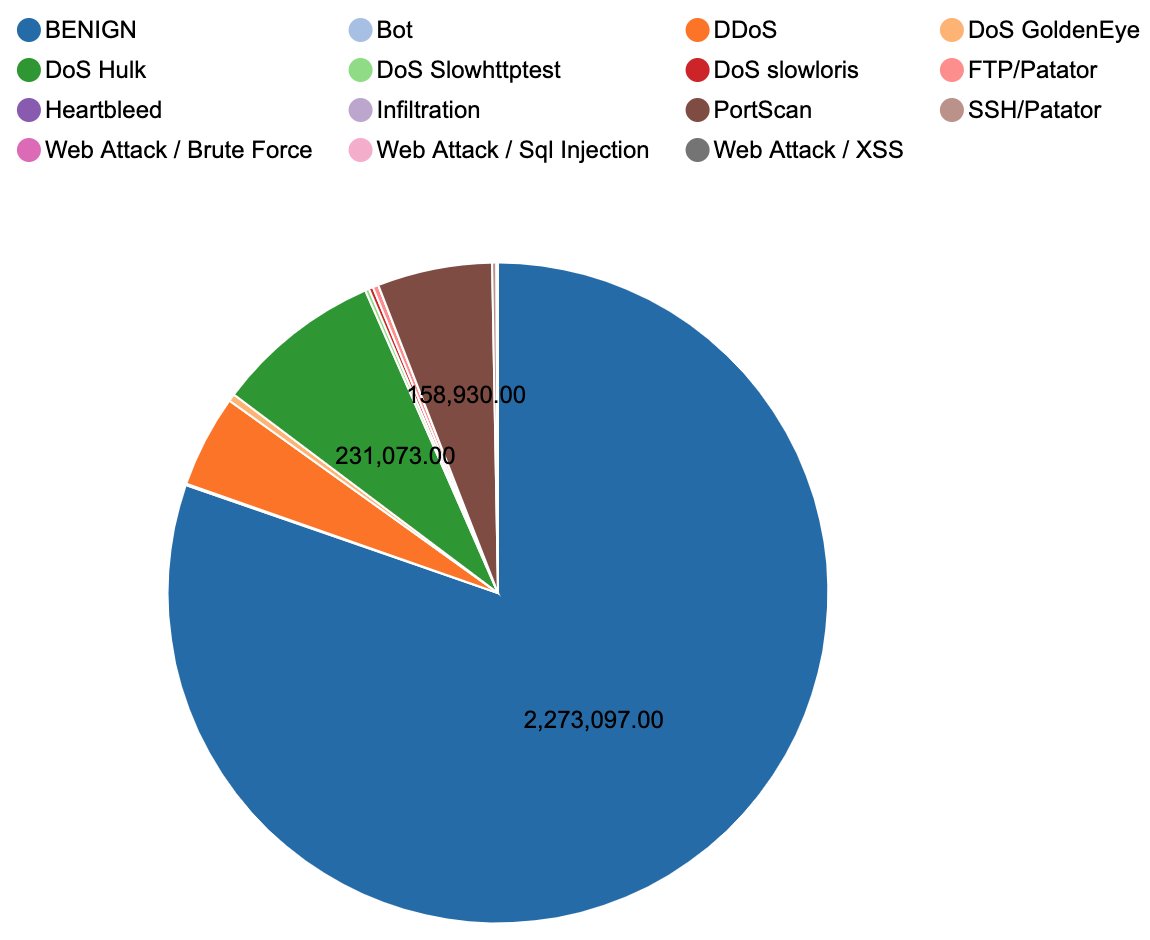
Abbildung 1: Ein Kuchendiagramm stellt dar, welchen Anteil die jeweiligen Label-Klassen an den Daten haben.
Um einen ersten Eindruck davon zu bekommen, ob eine Klassifizierung der Daten möglich ist, kann man ein Streudiagramm erstellen und es nach Labels einfärben. Dabei gibt es allerdings ein Problem: Ein Streudiagramm funktioniert in der Regel nur in 2D wirklich gut. (In seltenen Fällen sind auch 3D-Streudiagramme sinnvoll.) Im konkreten Fall gäbe es aber wesentlich mehr Dimensionen – es gilt also, die Dimensionalität der Daten zu verringern. Dabei hilft der PCA-Knoten. Das Kürzel steht für Principal Component Analysis (Hauptkomponentenanalyse). Der Knoten projiziert die Daten so in niedrigere Dimensionen, dass möglichst viel der ursprünglichen Varianz erhalten bleibt.
Aufgrund der aufwendigen Berechnung sowie der Tatsache, dass zu viele Datenpunkte das Streudiagramm zu unübersichtlich machen, sollte man hierfür nur eine Stichprobe der Daten verwenden. Der Beispiel-Workflow wählt dafür 10 000 Datenpunkte zufällig aus. Das erledigt der Knoten Row Sampling mit der Option Stratified Sampling auf der Klassenspalte, um dafür zu sorgen, dass das Verhältnis der verschiedenen Attacken auch in der gewählten Untermenge der Daten erhalten bleibt. Abbildung 2 zeigt das Streudiagramm der so transformierten Daten. Man erkennt, dass einige Klassen nur in einem bestimmten Bereich des Diagramms zu finden sind. Daraus lässt sich schließen, dass es einem Lernalgorithmus gelingen sollte, die Klassen voneinander zu unterscheiden.
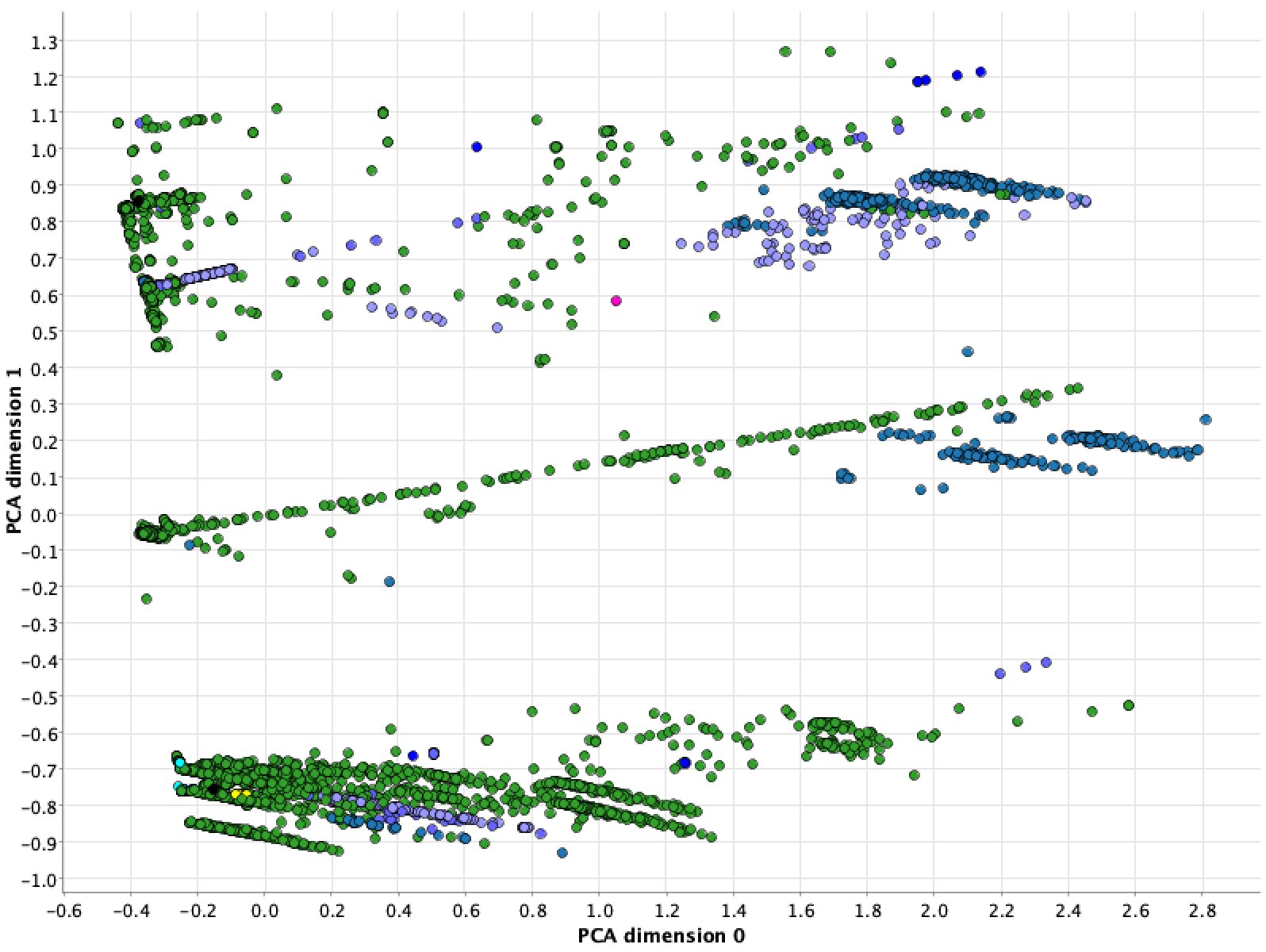
Abbildung 2: Streudiagramm der mittels Hauptkomponentenanalyse transformierten Daten.
Treten schon in zwei Dimensionen derartige Unterschiede in den Klassen auf, dann kann man davon ausgehen, dass nicht alle der ursprünglichen Dimensionen für die Unterscheidung der Klassen wirklich wichtig sind. Man geht diesem Verdacht nach, indem man sich die Korrelation der Merkmale ansieht. Dafür bietet Knime den Knoten Linear Correlation. Dessen Ausgabe, die Korrelationsmatrix in Abbildung 3, zeigt, dass viele Merkmale miteinander korrelieren. Man sollte in der Datenvorverarbeitung also prüfen, ob sich Merkmale ohne Genauigkeitsverlust bei der Klassifikation ignorieren lassen. Abbildung 4 zeigt noch einmal den ganzen Workflow für die verschiedenen Visualisierungen.

Abbildung 3: Korrelationsmatrix der Features in dem Datensatz.
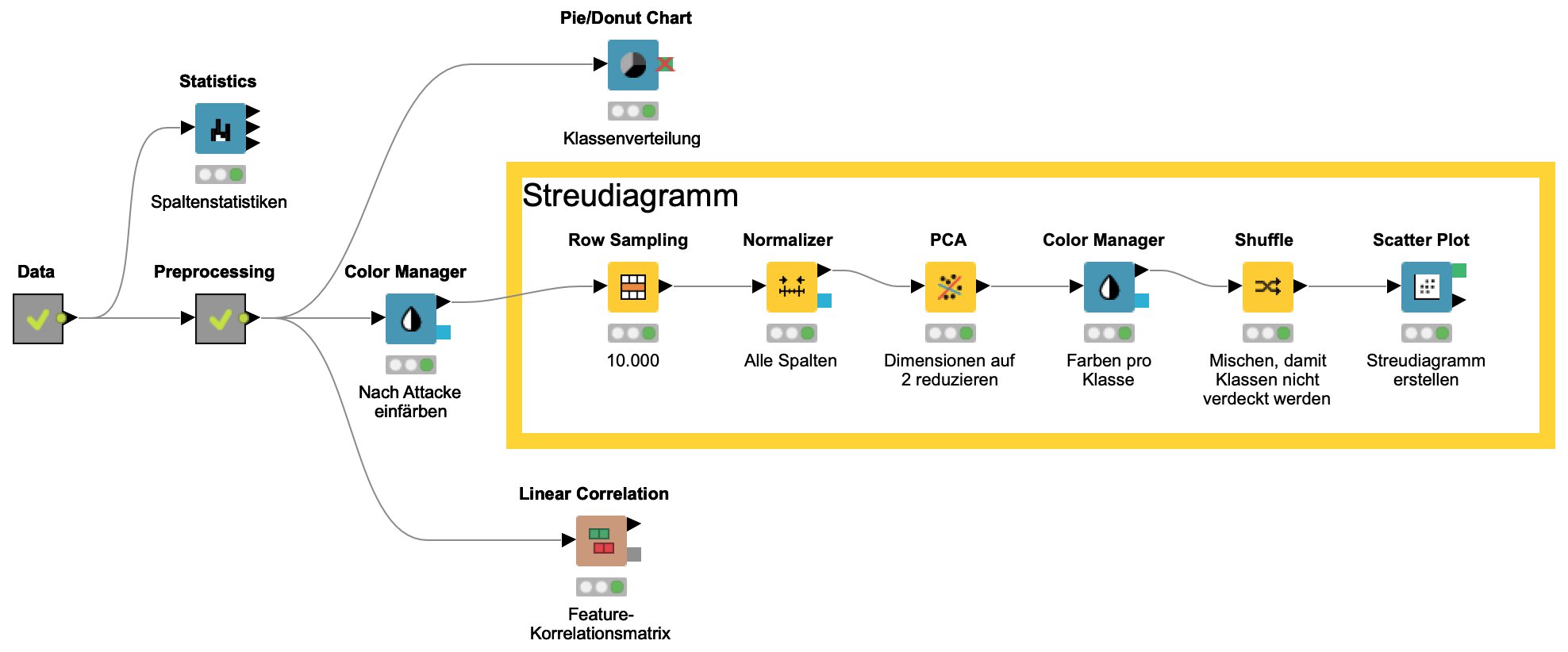
Abbildung 4: Workflow zur Exploration der Netzwerkdaten.
Gut vorbereitet
Mit den Einsichten, die der Workflow bislang beschert hat, kann man nun konkrete Vorverarbeitungsschritte einfügen, die die Daten etwas aufräumen. Zuerst einmal können alle Spalten entfallen, in denen sich lediglich ein einziger Wert findet: Sie helfen nicht dabei, Angriffe zu erkennen. Der Constant Value Column Filter erledigt das automatisch. Händisch entfernen muss man dagegen die Spalten, die den Wert “unendlich” enthalten. Überflüssig ist auch die Spalte »Fwd Header Length(2)«, bei der es sich um eine Kopie der Spalte »Fwd Header Length« handelt. Manuell lassen sich Spalten aus einer Tabelle mit dem Knoten Column Filter entfernen.
Die Spalte »Destination Port« enthält eine sehr große Anzahl von Werten und hat den Datentyp Integer. Ein Lernalgorithmus in Knime interpretiert diese Zahlen als sortierbar und versucht sie hinsichtlich ihrer Größe zu vergleichen. Er denkt also irrigerweise, dass Port 46 doppelt so viel wie Port 23 ist. Mit dem Knoten Number to String lässt sich dieses Problem vermeiden, denn der speichert den Port als Zeichenkette und damit als kategorische Variable. Da man Ports ab 1023 beliebig belegen darf, ersetzt der Workflow bei ihnen außerdem mithilfe des Knotens Rule Engine die Port-Nummer durch einen konstanten Text.
Die übriggebliebenen numerischen Merkmale normalisiert man mithilfe des Normalizer-Knotens, um einen gleichmäßigen Einfluss auf das Modell zu gewährleisten. Für den hier verwendeten Entscheidungsbaum ist das zwar nicht nötig, aber auch nicht abträglich. Will man später verschiedene Modellarten ausprobieren, ergibt eine Normalisierung Sinn. So setzen etwa ein k-Means-Clustering oder ein neuronales Netz zwingend normalisierte Daten voraus.
Nun könnte man bereits den Lernalgorithmus direkt auf die Daten anwenden und bekäme schon brauchbare Ergebnisse. Wie jedoch die Korrelationsmatrix zeigt, sind wahrscheinlich nicht alle Merkmale für die Entscheidung relevant, zu welcher Klasse ein Eintrag in der Tabelle gehört. Um dem Algorithmus die Arbeit zu erleichtern und eventuell sogar das Ergebnis zu verbessern, kann man diese Merkmale aussortieren.
Doch welcher Algorithmus eignet sich dafür? Knime bietet hier eine Vielzahl von Möglichkeiten: Neuronale Netze, Stützvektormaschinen, Naive Bayes, Random Forests und viele mehr. In diesem Fall kommt ein Entscheidungsbaum zur Anwendung, ein relativ einfaches und gut interpretierbares Verfahren. Eine kurze Erklärung der Funktionsweise liefert der Kasten “Entscheidungsbäume”.
Entscheidungsbäume
Ein Entscheidungsbaum partitioniert die Daten so lange rekursiv, bis die einzelnen Partitionen (fast) nur noch Datenpunkte derselben Klasse enthalten. Jeder Partitionierungsschritt anhand eines Kriteriums kann als innerer Knoten in einer Baumstruktur gesehen werden – daher der Name Entscheidungsbaum. Ein zu klassifizierender neuer, bisher vom Modell nicht betrachteter Datenpunkt durchläuft diesen Baum. In jedem Knoten fällt eine Entscheidung, in welche Unterpartition er weiterwandern soll. Die Partition, in der er am Ende landet, bestimmt dann seine Klasse. Ein Beispiel eines einfachen Entscheidungsbaum zeigt Abbildung 5.
Um nun dafür geeignete Merkmale auszuwählen, bieten sich vor allem zwei einfache Verfahren an: Forward Feature Selection und Backward Feature Elimination. Ersteres beginnt mit einer leeren Tabelle und probiert für jedes Merkmal ein Modell zu lernen, das nur anhand dieses Merkmals die Klasse jedes Eintrags vorhersagt. Das Merkmal, das zu dem besten Modell (etwa bezüglich der Klassifikationsgenauigkeit auf separaten Testdaten) führt, wird als Spalte an die Tabelle angehängt. Anschließend testet das Verfahren nach und nach auf dieselbe Weise weitere Merkmale zusammen mit den bereits gewählten und hängt sie an, bis die Resultate nicht mehr oder nur noch marginal besser werden. Backward Feature Elimination funktioniert ganz ähnlich, beginnt jedoch mit einer Tabelle aller Features, aus der es nach und nach jene Features entfernt, die keinen positiven Einfluss auf die Klassifikationsgenauigkeit haben.
In Knime gibt es für beide Verfahren vorgefertigte und anpassbare Workflows, die das Programm in sogenannten Metaknoten zusammenfasst. Ein solcher Metaknoten ist ein Workflow im Workflow, der komplexere Abläufe in einem einzigen Knoten versteckt. Da beide Verfahren etwas unterschiedliche Features auswählen, kann man die beiden Ausgaben auch einfach vereinen und die so erhaltene Untermenge von Features für das nachfolgende Lernen eines Entscheidungsbaums verwenden. Die Feature Selection ist für die vorliegenden Daten in der Lage, die Anzahl der Merkmale ohne Einbußen in der Klassifikationsgenauigkeit von 69 auf 17 zu reduzieren.
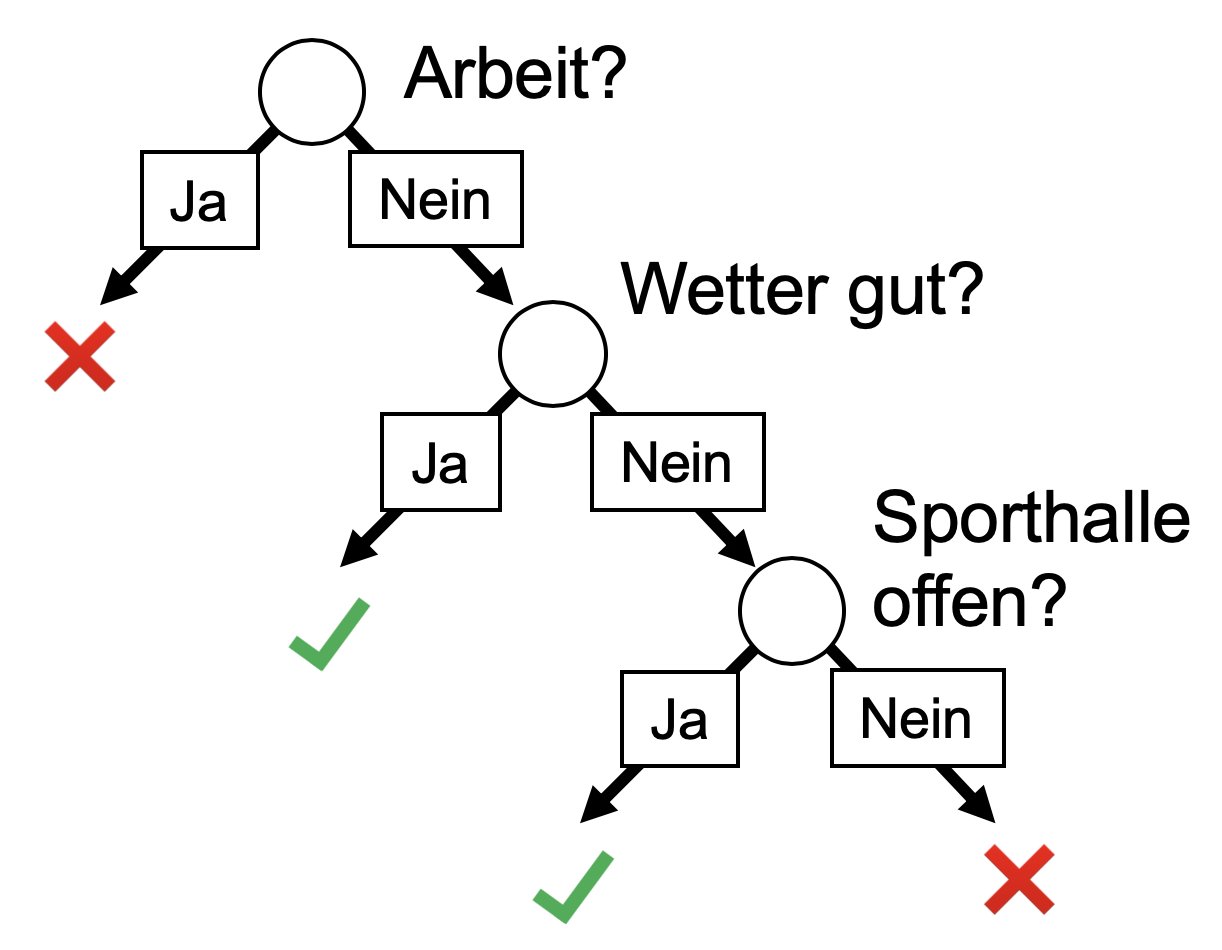
Abbildung 5: Ein vereinfachtes Beispiel für einen Entscheidungsbaum. In ähnlicher Weise kann das hier verwendete Modell entscheiden, ob ein Paket gut- oder bösartig ist.
Erkennung von Netzwerkattacken
Im vorigen Abschnitt halfen bereits einige Entscheidungsbäume, die richtigen Merkmale für die spätere Analyse auszuwählen. Davon ausgehend lässt sich nun evaluieren, welche Ergebnisse bei der Verwendung eines Entscheidungsbaums zur Klassifikation zu erwarten sind. Der zu lernende Entscheidungsbaum soll erkennen, ob es sich bei einem Datenpunkt um eine Attacke handelt, und falls ja, um welche.
Um die Genauigkeit dieses Modells zu schätzen, kommt hier eine zehnfache Kreuzvalidierung zur Anwendung. Dabei teilt man die Daten zufällig in zehn Gruppen auf und entnimmt dem Datensatz in einer Schleife jeweils eine dieser Gruppen. Die restlichen neun Gruppen lernen ein Modell, dessen Vorhersagen man anschließend mit den Werten der herausgenommenen Gruppe vergleicht. Insgesamt werden somit zehn Modelle auf jeweils 90 Prozent der Daten gelernt. Anhand der Klassifikationsgenauigkeit auf den restlichen 10 Prozent kann man erkennen, ob sich das gewählte Verfahren für das Klassifikationsproblem eignet.
Knime bietet mit dem Metaknoten Cross Validation ein vorkonfiguriertes Verfahren für die Kreuzvalidierung. Ein Scorer-Knoten erlaubt dann das Auswerten der gemachten Fehler und das Einschätzen der Klassifikationsgenauigkeit. Die in der Kreuzvalidierung mit den Netzwerkdaten gelernten Modelle weisen mit über 99 Prozent eine sehr gute Genauigkeit auf. Hier gilt es jedoch, zu beachten, dass über 75 Prozent der Daten der Klasse »gutartig« angehören. Ein Modell, das immer »gutartig« vorhersagt, hätte also schon eine Genauigkeit von 75 Prozent.
Der Scorer zeigt deshalb außerdem noch Cohen’s Kappa an. Dieses Maß vergleicht die Übereinstimmung der Vorhersage und der echten Werte mit der Übereinstimmung, die bei einer zufälligen Klassifikation erwartet wird. Auch dieser Wert liegt in diesem Fall sehr gut. Trotzdem sollte man zusätzlich einen Blick auf die Konfusionsmatrix (Abbildung 6) werfen, die der Scorer ebenfalls ausgibt. Sie zeigt, welche Klassen die Klassifikation wie oft richtig vorhergesagt hat, und außerdem, wie oft die Klasse mit jeder anderen Klasse verwechselt wurde.
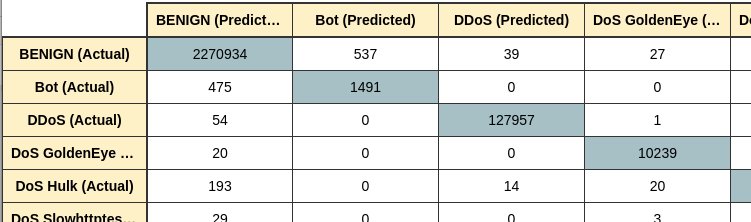
Abbildung 6: Eine Konfusionsmatrix (Ausschnitt) nach einer Kreuzvalidierung.
Fallen die Ergebnisse zufriedenstellend aus, kann man einen letzten Entscheidungsbaum auf den gesamten verfügbaren Daten lernen. Mit dem PMML Writer speichert man dieses Modell dann für die spätere Wiederverwendung. Beim PMML-Format handelt es sich um eine standardisierte, XML-basierte Beschreibungssprache für Data-Mining-Modelle, die auch von anderer Software verarbeitet werden kann. Abbildung 7 zeigt den finalen Workflow für die Klassifikation.
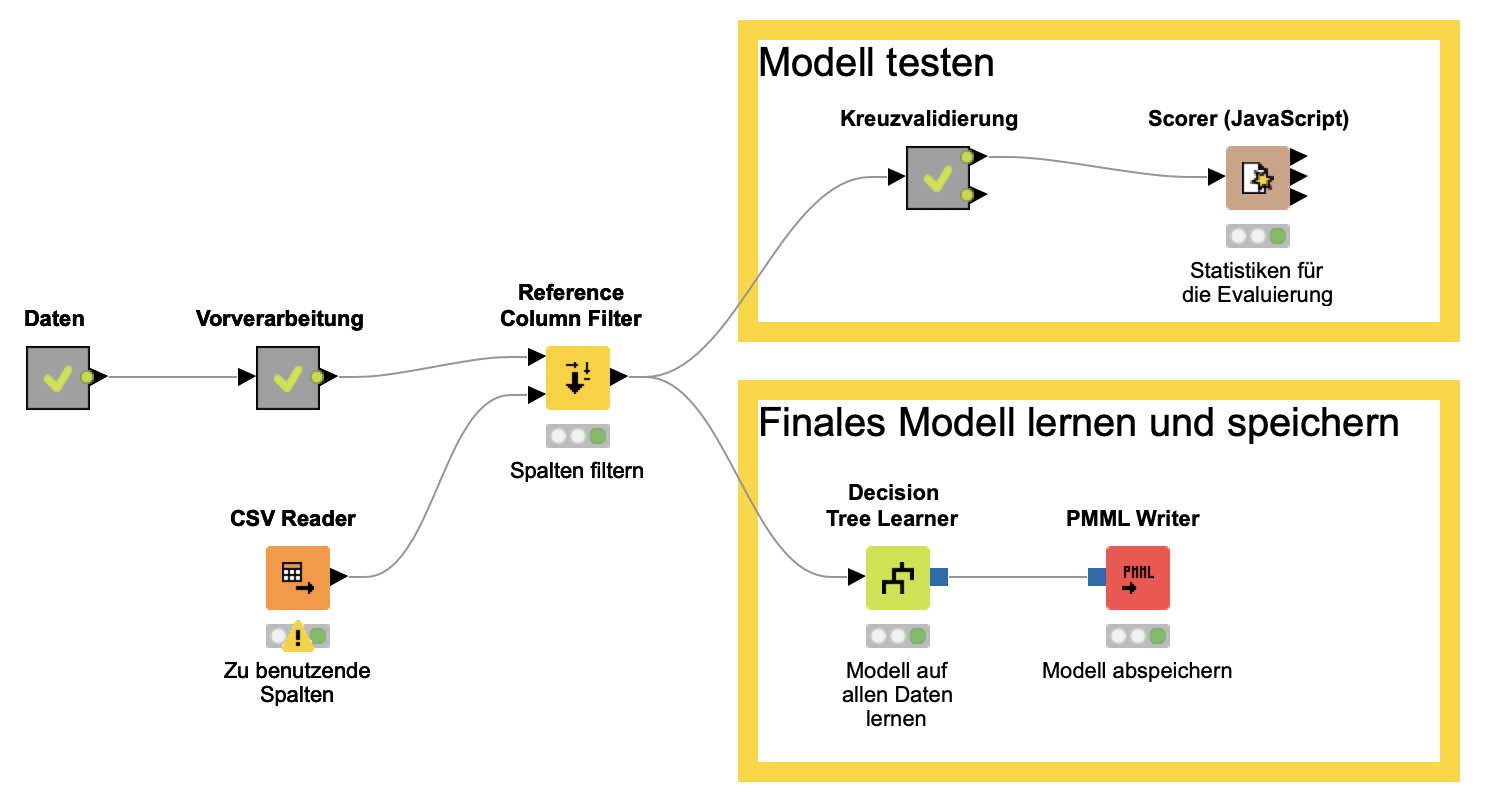
Abbildung 7: Der Knime-Workflow für das Lernen eines Entscheidungsbaums für die Klassifizierung von Netzwerkattacken.
Ist das normal?
Wie eingangs angedeutet, gibt es noch einen weiteren Ansatz, um mithilfe von Methoden des maschinellen Lernens Netzwerkattacken zu identifizieren: die Erkennung von Anomalien im Netzwerkverkehr. Hier definieren nicht starre Regeln, was eine Attacke definiert. Stattdessen lernt das Modell, wie normale Daten aussehen, und schlägt Alarm, sobald etwas nicht zu dem erkannten Muster passt. Für den vorliegenden Anwendungsfall bedeutet das, dass ein Modell nur auf unseren als gutartig markierten Datenpunkten gelernt wird.
Als Lernverfahren soll ein sogenannter Isolation Forest aus Knimes H2O-Integration verwendet werden. Bei H2O handelt es sich um eine Bibliothek für verteiltes, hochperformantes maschinelles Lernen. Hinter einem Isolation Forest steht folgende Idee: Landet ein Datenpunkt in einem Entscheidungsbaum sehr früh in einem Blattknoten, das heißt nach wenigen Verzweigungen, lässt er sich sehr gut von den anderen Punkten trennen und ist somit mit höherer Wahrscheinlichkeit eine Anomalie.
Da es in den Trainingsdaten jedoch nur Positivbeispiele gibt, ist es hier nicht das Ziel, die Daten möglichst gut in unterschiedliche Klassen aufzuteilen. Stattdessen erfolgt die Aufteilung hier komplett zufällig (Abbildung 8). Da die Aussagekraft eines einzelnen Baums aber nicht ausreicht, um eine Anomalie zu bestimmen, wird ein ganzer Wald an Bäumen verwendet – daher der Name Isolation Forest. Identifizieren in diesem Wald viele Bäume den Datenpunkt als Anomalie, kann man davon ausgehen, dass es sich tatsächlich um eine solche handelt. Wer weitere Informationen zu diesem Verfahren möchte, dem sei die H2O-Dokumentation [12] empfohlen.
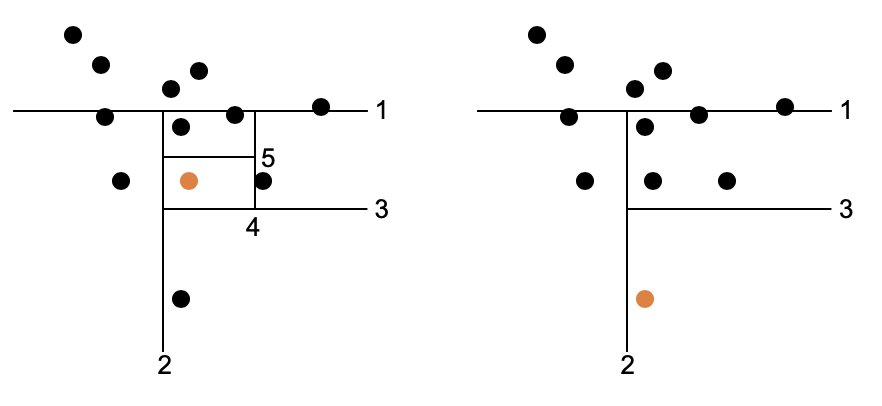
Abbildung 8: Das Erkennen von Anomalien in einem einzelnen Baum eines Isolation Forest. Links ein normaler Punkt (orangefarben), der sich erst durch viele Teilungen der Daten separieren lässt. Rechts eine Anomalie, bei der dazu weniger Teilungen ausreichen.
Um das Verfahren zu testen, teilt man die Daten zuerst in gutartige und bösartige Datenpunkte aufgeteilt. Damit man nicht nur die Erkennungsrate für Attacken bestimmen kann, sondern auch, wie oft gutartiger Netzwerkverkehr als Anomalie klassifiziert wird, vermischt man einige der gutartigen Beispiele mit den bösartigen, sodass das Verhältnis 1:1 beträgt. Dieser Test-Datensatz dient später dazu, die Genauigkeit des Verfahrens zu bestimmen. In der Realität gelingt das allerdings nicht so einfach, da dort fast nur gutartiger Netzwerkverkehr für das Training zur Verfügung steht.
Mit dem Datensatz, der nur gutartige Beispiele enthält, kann man nun das Isolation-Forest-Modell lernen und auf den zweiten Datensatz anwenden. Als Ergebnis erhält man für jeden Datenpunkt eine Zahl zwischen 0 und 1, die angibt, wie wahrscheinlich es sich dabei um eine Anomalie handelt. Als Grenzwert für die Unterscheidung fungiert hier der Median aller auf den Trainingsdaten berechneten Werte.
Das bedeutet zwar, dass das Modell 50 Prozent der Trainingsdaten fälschlicherweise als Anomalie einstuft, dafür werden aber auch die echten Attacken häufiger erkannt. In diesem Fall liegt der Median bei 0,223. Mit dem Knoten Rule Engine lassen sich die Datenpunkte basierend auf diesem Schwellwert in Anomalien und Nicht-Anomalien einteilen, ein Scorer-Knoten kann die Genauigkeit berechnen. Sie liegt hier bei knapp 64 Prozent. Das ist zwar besser als eine zufällige Einteilung, aber lange nicht so gut wie das Ergebnis der Klassifikation im vorangegangenen Abschnitt.
Welche Typen von Attacken erkennt der Detektor gut und welche findet er nicht? Um das herauszufinden, zählt man für jeden Typ die Anzahl der richtig und falsch erkannten Datenpunkte und erstellt daraus ein Balkendiagramm. Beim Beispiel aus Abbildung 9 fallen demnach Port-Scans und Bots häufig durchs Raster. Dasselbe gilt für Attacken mit dem Tool Patator, das versucht, SSH-Passwörter zu erraten.
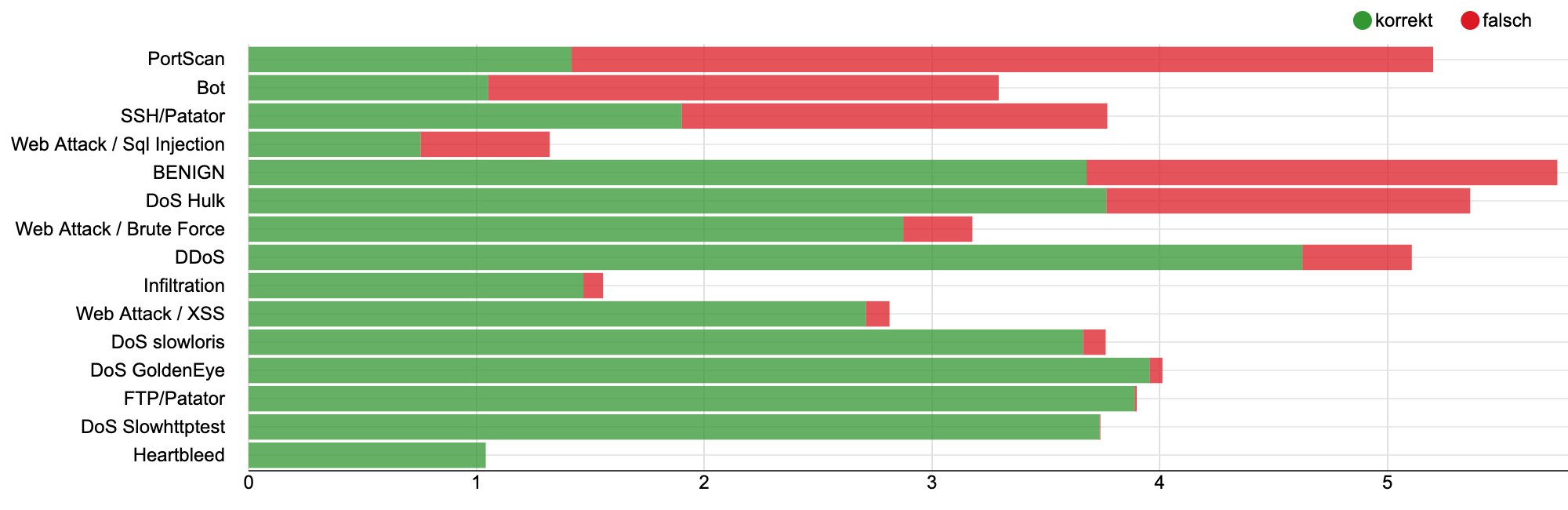
Abbildung 9: Ein Balkendiagramm der Fehler pro Attackentyp. Port-Scans und Bots fallen häufig durchs Raster.
An fünfter Stelle erscheinen gutartige Beispiele, was bedeutet, dass der Detektor zu fein eingestellt ist. Ein Anheben des Schwellwerts kann das beheben – allerdings nur auf Kosten der Erkennung echter Attacken. Einige andere Angriffe, wie zum Beispiel die verschiedenen DoS-Attacken, erkennt das aktuellen Modell dagegen sehr gut als Ausreißer. Abbildung 10 zeigt den gesamten Workflow, Abbildung 11 den Inhalt des Metaknotens für das Lernen des Isolation Forest. Zu den weiteren Methoden zur Erkennung von Anomalien zählen der Local Outlier Factor (LOF), Autoencoder oder Ein-Klasse-Stützvektormaschinen.
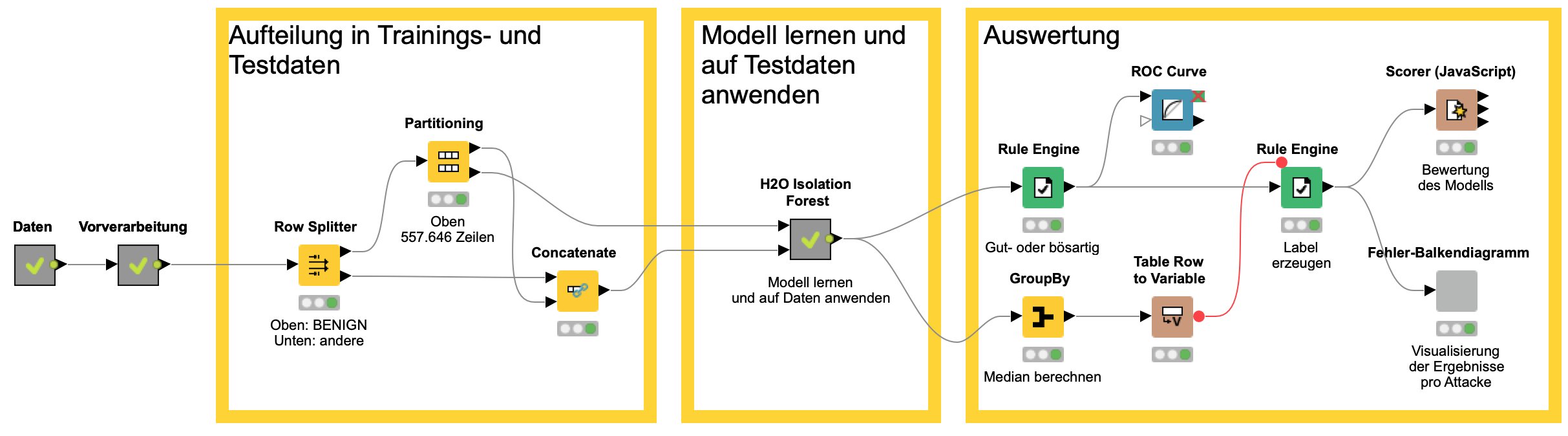
Abbildung 10: Der komplette Workflow zur Anomalieerkennung mit einem H2O Isolation Forest.
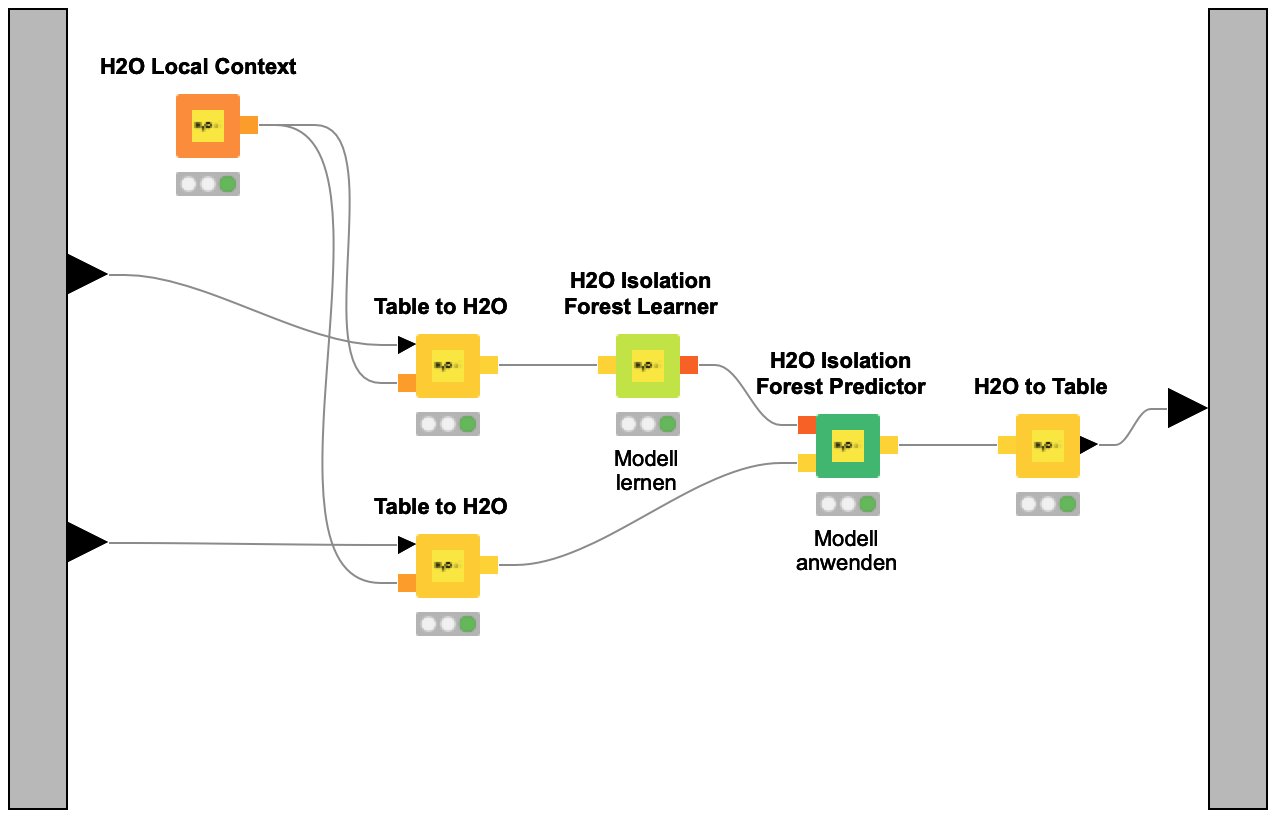
Abbildung 11: Der Inhalt des H2O-Isolation-Forest-Metaknotens, in dem das Modell zur Anomalieerkennung gelernt wird.
Zusammenfassung
Wie dieser Artikel zeigt, führt das Lernen mit annotierten Daten zu einer höheren Erkennungsgenauigkeit als die etwas flexiblere Anomalieerkennung. Allerdings erfordert es eine hohe Datenmenge, und oft hat man entsprechende Daten über Attacken auf das eigene Netzwerk nicht zur Hand. Eine Anomalieerkennnung wie die mittels Isolation Forest kann jedoch bei der Vorbereitung auf zukünftige Gefahren helfen. Sie produziert zwar je nach Einstellung viele Fehlalarme oder erkennt nicht jede Attacke, identifiziert aber wirklich auffällige Vorkommnisse gut und ohne menschliches Zutun.
Für beide Arten von Detektoren bietet die Knime Analytics Platform verschiedene Algorithmen, die der Administrator durch einfaches Drag & Drop ausprobieren kann. Was hier auf künstlichen Daten demonstriert wurde, lässt sich in Knime durch die Anbindung an andere Dateiformate, Datenbanken oder REST-Schnittstellen auch einfach auf echte Daten anwenden. Dass die Analyseplattform kostenlos als Open Source bereitsteht, sollte jeden ermutigen, Knime einfach einmal herunterzuladen und auszuprobieren. (jcb/jlu)
Infos
-
Deep Code: https://www.deepcode.ai
-
Knime: Alexander Fillbrunn, Martin Horn, “Das Analyse-Lego”, LM 04/2018, S. 84, https://www.linux-magazin.de/40570
-
Knime-Workshop: Alexander Fillbrunn, Martin Horn, “Vorliebenforschung”, LM 10/2018, S. 64, https://www.linux-magazin.de/41503
-
Homepage der Knime AG: https://www.knime.com
-
Knime-TV: https://www.youtube.com/user/KNIMETV
-
Knime-Einführung: https://www.knime.com/knime-introductory-course
-
Knime-Bootcamp: https://www.udemy.com/course/knime-bootcamp
-
Knime-Beispiele: https://hub.knime.com
-
Knime-Forum: https://forum.knime.com
-
Intrusion Detection Evaluation Dataset: https://www.unb.ca/cic/datasets/ids-2017.html
-
CICFlowMeter: https://github.com/ahlashkari/CICFlowMeter
-
H2O-Dokumentation: http://docs.h2o.ai/h2o/latest-stable/h2o-docs/data-science/if.html





