
© Vladimir Nenov, 123RF
Daten seien “das neue Öl” – sagt man. Tatsächlich haben sie aber erst dann einen Wert, wenn sie zu neuen Erkenntnissen führen. Die zu gewinnen erfordert oft Programmierkenntnisse. Nicht so bei der Open-Source-Analysesoftware Knime, die Workflows nach dem Lego-Prinzip konstruiert.
Gerne setzen Datenanalysten Skriptsprachen wie R oder Python ein, die sich dank eines großen Ökosystems an Bibliotheken und Erweiterungen oft als flexible Werkzeuge erweisen. Doch nicht jeder kann oder möchte programmieren und umfangreiche Quelltexte schreiben und debuggen.
Einen Ausweg bietet ein anderes Konzept: visuelle Workflows. Sie zerlegen Analyseprozesse in viele modulare, nacheinander auszuführende Schritte. Jeden Schritt symbolisiert ein grafisches Element. Verkettet der Anwender die Elemente auf dem Bildschirm, erzeugt er daraus Workflows für komplexe Untersuchungen – ganz ohne Code zu fabrizieren.
Alles im Flow
Solche Workflows sind das zentrale Element der Knime Analytics Platform (http://www.knime.com) [1], des Softwaretools, das dieser Artikels vorstellt. Ein Workflow ist in diesem System ein Graph, in dem Knoten für die einzelnen Schritte stehen. Jeder Knoten kann Ein- und Ausgänge besitzen, über die er mit anderen Knoten Daten austauscht. Das passiert immer dann, wenn der Anwender den Ausgang eines Knotens mit dem Eingang eines anderen Knotens verbindet. Ein Typsystem stellt sicher, dass er nur kompatible Aus- und Eingänge miteinander verbinden darf.
Erste Schritte
Die Knime Analytics Platform enthält eine grafische Benutzeroberfläche, in der der Anwender solche Workflows entwickelt und annotiert. Echter Code ist nur dann nötig, wenn er explizit auf R oder Python zurückgreifen oder eigene Module entwickeln will. Durch die Unterteilung des Prozesses in kleine Teilschritte lässt sich jedes Zwischenergebnis betrachten und die weitere Analyse gegebenenfalls anpassen. Eine einheitliche Datenhaltung macht zudem das Zusammenspiel verschiedener Werkzeuge einfacher.
Abbildung 1 zeigt die Nutzeroberfläche der Knime Analytics Platform, wie sie sich dem Nutzer nach dem ersten Start präsentiert. Auf der linken Seite befindet sich oben der so genannte Knime Explorer, also die Übersicht über die Workflows im Arbeitsbereich. Darunter ist der Workflow Coach zu finden, der Vorschläge macht, welche Knoten als nächste in Frage kommen, und so insbesondere Neulingen eine nützliche Hilfestellung bietet. Links unten listet das Node Repository die Knoten aller installierten Erweiterungen auf. Das können 1500 und mehr Knoten sein.
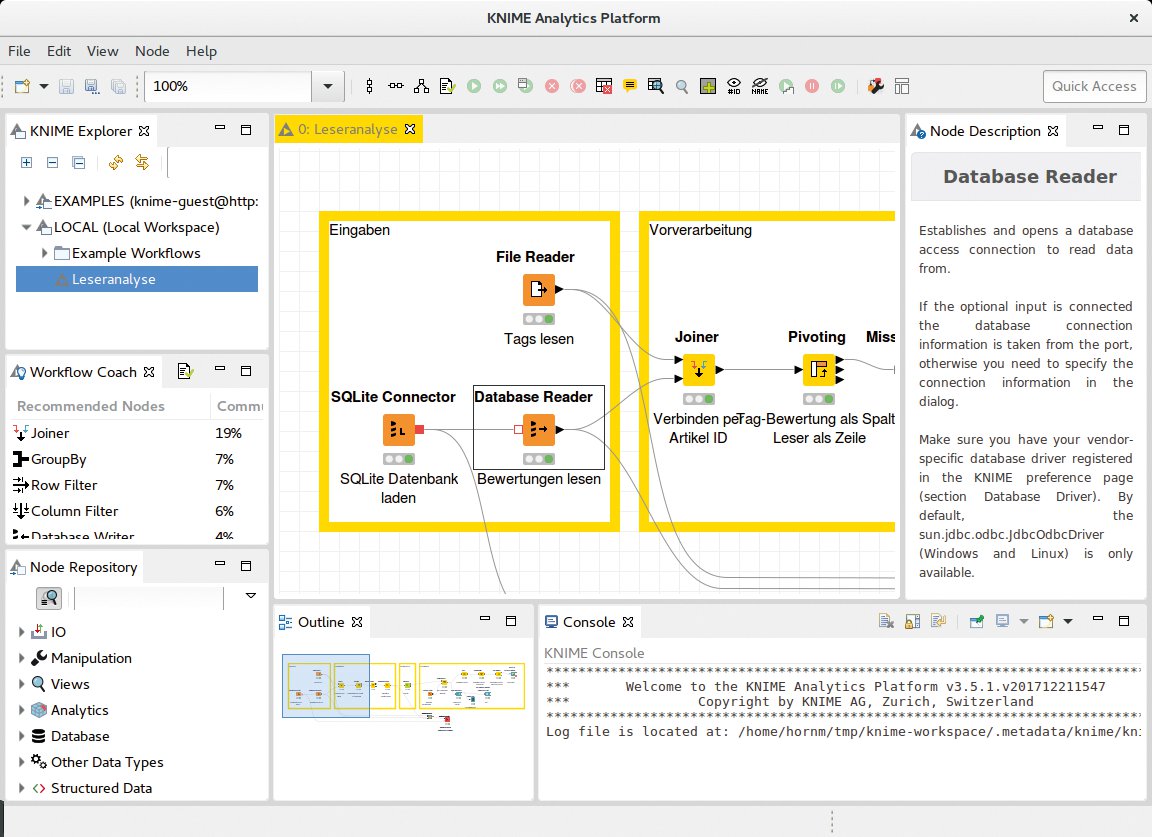
Abbildung 1: Die Benutzeroberfläche von Knime, in der die Anwender Workflows per Drag & Drop zusammenbauen.
Im Fenster der Node Description rechts erhält der Nutzer die nötige Dokumentation zu Funktion und Benutzung eines Knotens. In der Mitte befindet sich der Workflow-Editor, in dem Nutzer den eigentlichen Workflow entwickeln.
Im Lauf der Entwicklung eines Workflow verbindet der Anwender die Knime-Knoten – also die modularen Prozessierungseinheiten – miteinander, konfiguriert sie und führt sie dann einzeln oder gemeinsam aus (Abbildung 2).
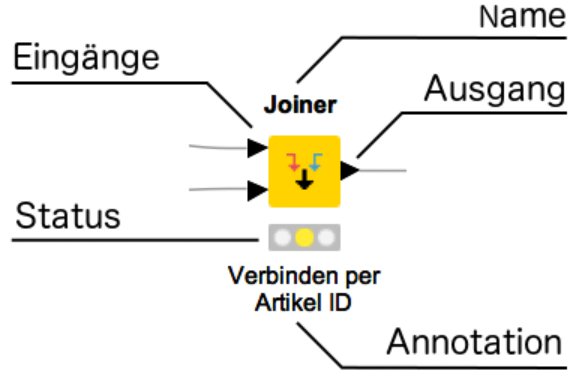
Abbildung 2: Anatomie eines Knime-Knotens.
Ist ein Knoten erst einmal ausgeführt, was ein grünes Ampelsymbol unter dem Knoten signalisiert, lassen sich dessen Ergebnisdaten anzeigen (etwa als Tabelle oder auch als Balkendiagramm). Ist das Ampelsymbol rot, ist der Knoten noch nicht konfiguriert. Gelb bedeutet, dass der Knoten bereit für die Ausführung ist.
Knoten können keine oder beliebig viele Ein- und Ausgänge (Ports) haben. Die Form und Farbe der Ports gibt einen Hinweis darauf, welche Art von Daten der Knoten an einem bestimmten Ein- oder Ausgang benötigt oder ausgibt (im Fall eines schwarzen Dreiecks ist dies eine normale Tabelle).
Ein Beispielszenario
Die Funktionsweise von Knime erläutert der vorliegende Artikel im Folgenden anhand eines Beispiel-Workflow (Abbildung 3). Der vollständig dokumentierte Workflow ist steht unter [2] zum Download bereit und kann danach in Knime importiert werden.

Abbildung 3: Der Beispiel-Workflow, mit dem sich die Vorlieben der Leser analysieren lassen.
Die Herausgeber eines fiktiven Online-Magazins möchten etwas mehr über die Vorlieben ihrer Leser erfahren. Als Grundlage dienen hierfür die Daten eines Bewertungssystems, das jedem Leser die Möglichkeit gibt, Magazin-Artikel mit bis zu fünf Sternen zu bewerten. Jeder Artikel ist zudem in mindestens eine der fünf Kategorien oder Rubriken Hardware, Software, Entwicklung, Security und Internet eingeordnet.
Die Herausgeber hoffen, aus den Bewertungen Rückschlüsse auf die Vorlieben der Leser ziehen und Gruppen von Lesern mit gemeinsamen Interessen identifizieren zu können. Jedem Leser wollen sie dann gezielt weitere Artikel vorschlagen, die zu ihren Interesse passen.
Ausgangspunkte der Analyse sind eine SQlite-Datenbank mit den Bewertungen der Artikel sowie eine CSV-Datei mit der Zuordnung der Rubriken zu den Artikeln. Beide Datenquellen liegen also in einem Tabellenformat vor und sind auszugsweise in den Tabellen 1 und 2 dargestellt.
| Leser-ID | Artikel-ID | Bewertung |
|---|---|---|
| Leser 1 | Artikel 11 | 1 |
| Leser 93 | Artikel 31 | 3 |
| Leser 45 | Artikel 3 | 4 |
| … |
Die Daten laden
Der erste Schritt jeder Datenanalyse ist das Einlesen der benötigten Daten (die roten Knoten in Abbildung 3). Diese können bei Knime aus verschiedensten Quellen stammen, zum Beispiel Textdateien, Dokumenten, Datenbanken oder Webservices.
Einmal in Knime geladen ist es egal, aus welcher Quelle die Daten bezogen wurden, denn die Software konvertiert sie immer in ein internes Format. Im vorliegenden Fall gilt es, Daten aus einer SQlite-Datenbank sowie einer CSV-Datei zu laden. Für den Zugriff auf Datenbanken bietet Knime eine ganze Reihe von Knoten und unter anderem den »Database Reader«, der das Ergebnis einer SQL-Abfrage als Knime-Tabelle zur Verfügung stellt.
Der Knoten funktioniert mit verschiedenen Datenbanktypen, die Verbindungsinformationen erhält er über seinen Eingang. Hier lässt sich ein »SQLite-Connector« voranstellen, der mit den Verbindungsinformationen konfiguriert wird und sie an andere Knoten weitergibt.
Textdateien liest Knime am einfachsten mit dem »File Reader« ein. Dieser Knoten versucht automatisch, das Dateiformat inklusive Spaltenseparatoren und Zeilenlänge zu erraten und zeigt in seinem Konfigurationsdialog eine Vorschau der zu ladenden Tabelle an.
Verbindung herstellen
Die eingelesenen Daten sind im nächsten Schritt miteinander in Beziehung zu setzen. Wer sich mit Datenbanken auskennt, der weiß, dass dies am besten mit einem Join gelingt. Ein Join besteht aus einem oder mehreren Prädikaten, die bestimmen, welche Zeilen zweier Tabellen zusammengehören. Die zusammengehörigen Zeilen landen dann zusammengefasst in einer Ausgabetabelle.
Das vorliegende Beispiel muss die beiden Tabellen – basierend auf der Artikel-ID – vereinigen. Das Prädikat des Join bestimmt hier also, dass Bewertungen für einen Artikel mit den Rubriken zu verbinden sind, in die derselbe Artikel eingeordnet ist. Der Knoten, den Knime dafür verwendet, ist der »Joiner«. Seine Ausgabetabelle ist in Abbildung 4 zu sehen. Wie sein Datenbank-Pendant unterstützt der Knime-Join verschiedene Modi, inklusive Inner-, Outer-, Left- und Right-Join. Zudem kann der Benutzer auswählen, welche Spalten aus welcher Tabelle in die Ausgabe zu übernehmen sind.
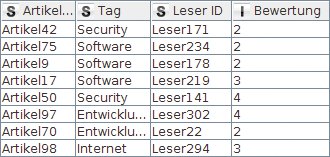
Abbildung 4: Ausgabetabelle des »Joiner«-Knotens.
Pivoting
Der nächste Schritt besteht darin, für jeden Leser eine Art Fingerabdruck zu erzeugen, der seine Vorlieben beschreibt, indem er für jede Rubrik berechnet, welche Bewertung der Leser Artikeln in dieser Rubrik durchschnittlich gegeben hat.
Im Ergebnis entsteht eine Tabelle, in der jeder Leser zu einer Zeile und jede Rubrik zu einer Spalte wird. In den Zellen der jeweiligen Kreuzungspunkte ist dann die durchschnittliche Bewertung des Lesers für Artikel dieser Rubrik zu finden (Abbildung 5).
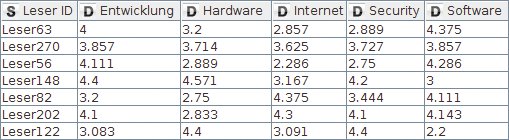
Abbildung 5: Ergebnis des Pivoting.
Diese Transformation erledigt der Pivoting-Knoten. Sein Dialog mag den Anwender auf den ersten Blick erschlagen, verlangt er doch auf drei Tabs verteilte Angaben zu Gruppen-, Pivot- und Aggregierungsspalten. Die Werte in den Gruppenspalten bestimmen, welche Zeilen zu einer einzigen Zeile zusammenzufassen sind, nämlich all jene, die in diesen Spalten die gleichen Werte aufweisen. Für den Beispiel-Workflow ist die Leser-ID eine Gruppenspalte, die Rubrik die Pivotspalte, und die Aggregierungsspalte enthält die Bewertungen, die eine Durchschnittsfunktion mittelt.
Wenn ein Leser keinen einzigen Artikel einer Rubrik bewertet hat, enthält die pivotisierte Tabelle in der entsprechenden Zelle keinen Wert. Das symbolisiert Knime durch ein rotes Fragezeichen. Mit dem »Missing Value«-Knoten lassen sich fehlende Werte ersetzen. Im Beispiel ist die Annahme sinnvoll, dass dem Leser eine Rubrik, in der er nie einen Artikel bewertet hat, nicht gefällt. Statt des fehlenden Werts steht hier also null.
Häufig kommt es vor, dass ein Knoten eine Tabelle mit langen oder unverständlichen Spaltennamen hervorbringt. So erzeugt zum Beispiel der Pivoting-Knoten aus dem vorherigen Abschnitt Spalten im Format “Rubrik + Bewertung”, dabei ist das Suffix, das sowieso in jeder Spalte gleich ist, nicht wichtig. Um Spalten umzubenennen gibt es in Knime zwei wichtige Knoten: »Column Rename« und »Column Rename (Regex)«. Während man mit dem ersteren jeden Spaltennamen manuell umbenennen kann, erlaubt letzterer das Ändern der Spaltennamen mit Hilfe von regulären Ausdrücken.
Clusteranalyse
Nun, da die Daten in ein Format gebracht sind, mit dem sich gut arbeiten lässt, kann der Analyst anfangen, die Leser anhand ihrer Präferenzen in Gruppen einzuteilen. Dabei sollen Leser mit ähnlichen Vorlieben in derselben Gruppe landen. Dieses Ziel verfolgt die Clusteranalyse, für die Knime unterschiedliche Knoten mitbringt, darunter k-Means, Fuzzy c-Means, Hierarchical Agglomerative Clustering oder k-Medoids.
Hinter jedem dieser Knoten versteckt sich ein anderer Algorithmus, der die Gruppen nach bestimmten Kriterien zu finden versucht und andere Vor- beziehungsweise Nachteile hat.
Knime
Den Anfang nahm Knime im Jahr 2006 am Lehrstuhl für Bioinformatik und Information Mining der Universität Konstanz unter der Leitung von Prof. Dr. Michael Berthold als “Konstanz Information Miner”. Die Grundidee war, die Datenanalyse für Benutzer verschiedener Fachrichtungen einfach zugänglich und erschwinglich zu machen. Die Entwickler starteten deshalb ein Open-Source-Projekt, bei dem sie besonders auf Anwenderfreundlichkeit und Erweiterbarkeit achteten.
Knime Analytics Platform ist in Java geschrieben und baut auf Eclipse und der OSGI-Technologie (Open Services Gateway Initiative) auf. Die neueste Version (bei Redaktionsschluss 3.5.1) lässt sich unter [1] herunterladen. Dort ist auch weiteres Material für den Einstieg zu finden (zum Beispiel Blogs, Videos, Beispiel-Workflows).
Knime, das sich selbst in Versalien schreibt (KNIME), wird übrigens “Neim” ausgesprochen, also englisch und mit stummem “K”.
Allen diesen Clusteralgorithmen ist gemeinsam, dass der Benutzer selbst bestimmen muss, wie viele Gruppen er schließlich erhalten will. Außerdem brauchen sie alle eine Möglichkeit, um die Ähnlichkeit zwischen zwei Datenpunkten zu berechnen. Im vorigen Abschnitt wurde für jeden Leser eine Tabellenzeile erzeugt, die fünf numerische Werte – einen für jede Rubrik – enthält.
Der Workflow für das Beispiel nutzt den k-Means-Knoten, der recht schnell ist und generell gute Ergebnisse liefert. Der Algorithmus funktioniert mit verschiedenen Distanzmaßen, in Knime ist er mit der Euklidischen Distanz implementiert (siehe Kasten “Distanz berechnen”). Der k-Means-Knoten in Knime, der den Algorithmus ausführt, hängt an die Eingabetabelle eine weitere Spalte an, die die Gruppe vermerkt, in die der Datenpunkt fällt.
Die Clusteranalyse offenbart, dass Leser, die Artikel aus den Rubriken Hardware und Security oft gut bewerten, meist in Cluster 0 fallen, während die Leser aus Cluster 1 die Rubriken Internet und Software und aus Cluster 2 Entwicklung und Software bevorzugen. Hat man das herausgefunden, bietet es sich an, den Clustern sprechende Namen zu geben. Aufgrund ihrer Präferenzen lassen sich zum Beispiel die Leser in Cluster 0 als Admins ansprechen, die in Cluster 1 als Poweruser und die in Cluster 2 als Entwickler. Diese Bezeichner ersetzt der »Cell Replacer«-Knoten in der Tabelle.
Visualisierung: Histogramm
Einen Überblick darüber, wie viele Leser in welche Gruppe fallen, verschafft ein Histogramm, dass der Histogram-Knoten erstellt. Der lässt sich direkt mit dem »Cell Replacer« aus dem vorherigen Schritt verbinden, aber das Ganze sieht dann noch ein bisschen farblos aus. Um das zu ändern, steht der »Color Manager«-Knoten bereit, der den Zeilen einer Tabelle eine Farbe – basierend auf dem Wert einer Spalte – zuweisen kann. Benutzt man dieselbe Spalte auch für die x-Achse des Histogramms, übernimmt Knime die Farbe automatisch für die Balken (Abbildung 6).
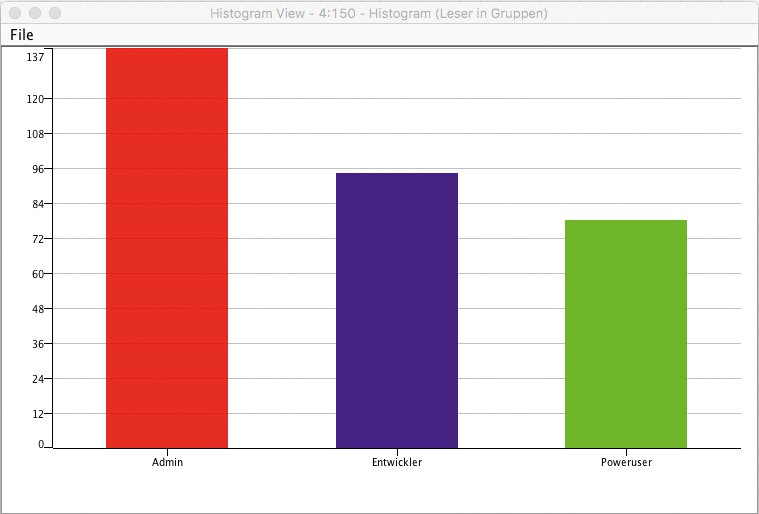
Abbildung 6: Histogramm der Lesergruppen, wie sie durch die Clusteranalyse ermittelt wurden.
Viele Dimensionen visualisieren
Aus dem Histogramm ist allerdings nicht ersichtlich, ob die Clusterung sinnvoll war. Dazu dient eine Visualisierung, die auch Daten mit vielen Dimensionen darstellen kann und in der außerdem erkennbar ist, ob die gefundenen Cluster auch eine Bedeutung haben. In den vorigen Jahren wurden viele Visualisierungen in Knime mit Hilfe von Javascript und dem D3.js-Framework http://3 implementiert, weil sich damit relativ einfach auch anspruchsvolle interaktive Anwendungen erstellen lassen.
Zu entdecken sind diese Visualisierungen in der Erweiterung »Knime Javascript Views« (Installationsanleitung siehe Kasten “Knime und Erweiterungen installieren”). Hier findet sich auch die Visualisierung »Parallel Coordinates«. Sie stellt Eigenschaften der Daten durch parallele y-Achsen dar und repräsentiert jeden Datenpunkt durch eine Kurve, die die Achsen an der entsprechenden Stelle schneidet. Zusätzlich lässt sich die Zugehörigkeit zu einer Gruppe farblich darstellen (Abbildung 7).
Knime und Erweiterungen installieren
Die Knime Analytics Platform ist Open Source, jeder kann sie kostenlos herunterladen und benutzen.
- Unter [2] stehen passende Installationspakete für verschiedene Betriebssysteme bereit.
- Den Installer starten oder das Archiv entpacken.
- Anschließend ist Knime bereits startbereit.
Allerdings sind viele zusätzliche Knoten in Erweiterungen zu finden, die noch zu installieren sind.
- Im Menü auf »File | Install Knime Extensions« gehen.
- In der Liste einen Haken an die gewünschten Erweiterungen setzen und den Instruktionen des Dialogs folgen.
- Nach einem Neustart von Knime sind die Knoten der Erweiterungen im Node Repository verfügbar.
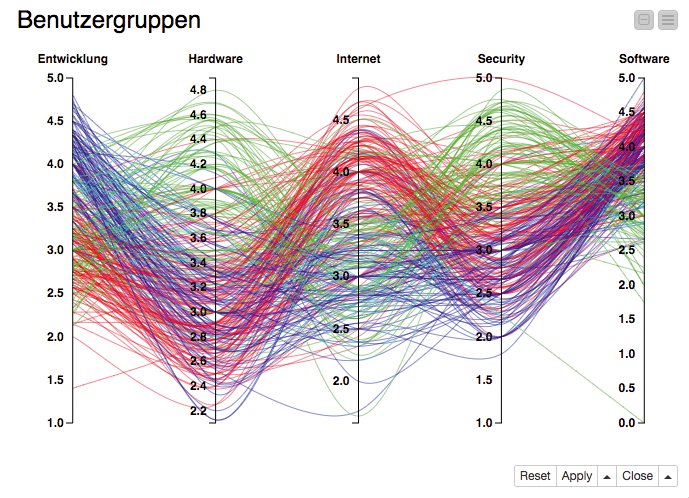
Abbildung 7: Ein Paralelle-Koordinaten-Diagramm der Leservorlieben. Jede Farbe steht für eine Lesergruppe.
D3.js, die den meisten Knime-Javascript-Visualisierungen zugrunde liegende Javascript-Bibliothek, ist eine der am meisten genutzten Bibliotheken fürs Erstellen interaktiver Datenvisualisierungen im Browser. Der Knime-Anwender kann allerdings nur einen Teil ihrer Möglichkeiten nutzen.
Für alle Fälle, die Knime noch nicht abdeckt, gibt es die »Generic Javascript View.« Die Konfiguration dieses Knotens ermöglicht die Eingabe beliebigen Javascript- und CSS-Codes, der aus einer Tabelle ein buntes Bild errechnet. Der von dem Knoten ausgeführte Code hat Zugriff auf die Knime-Tabelle und das Browser-DOM (Document Object Model) und kann entsprechend HTML- und SVG-Elemente auf Grundlage der Daten erzeugen.
So lässt sich mit der Generic Javascript View beispielsweise ein Voronoi-Diagramm anlegen (Abbildung 8), das die geclusterten Lesergruppen in 2-D visualisiert. Damit die Daten in einem für die Visualisierung passenden Format sind, ist aber zuerst die Anzahl der Dimensionen zu reduzieren. Bisher wurde pro Leser mit fünf Dimensionen (eine für jede Rubrik) gearbeitet, die nun auf zwei herunterzubrechen sind. Dazu lässt sich die Hauptkomponenten-Analyse verwenden, wie sie der Knoten »PCA« (Principal Component Analysis) berechnet. Diese Art der Transformation reduziert die Dimensionalität, versucht aber gleichzeitig die Varianz in den Daten so vollständig wie möglich beizubehalten, sodass so wenig wie möglich Informationen verloren gehen.
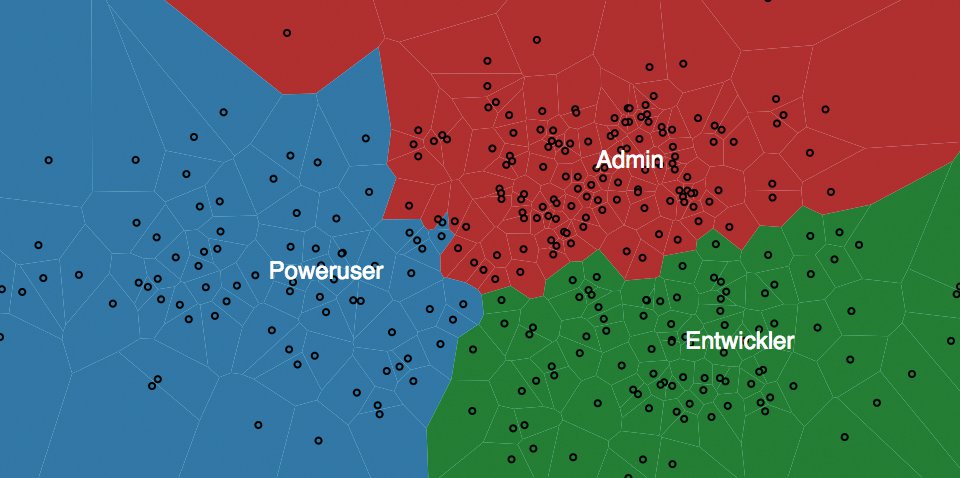
Abbildung 8: Ein mit der Generic Javascript View erstelltes Voronoi-Diagramm der Benutzer.
Bis hierhin ist schon ein richtiger Datenanalyse-Workflow entstanden: vom Einlesen der Daten über die Transformation und Gruppierung bis zur Visualisierung der Ergebnisse. All das hilft bereits interessante Einsichten in die Rohdaten zu gewinnen. In einem weiteren Schritt ließen sich nun pro Leser noch jene Artikel identifizieren, die er noch nicht gelesen hat, die aber aufgrund seiner Interessen für ihn ebenfalls interessant sein könnten. Diese Artikel kann dann eine Webanwendung dem Leser vorschlagen.
Den Überblick behalten
Doch mit jedem weiteren Schritt droht der Workflow immer komplexer und unübersichtlicher zu werden. Damit er noch verständlich bleibt, bietet es sich an, einzelne Teile in Module zu kapseln, die die Komplexität verbergen. Das erlauben so genannten Meta-Nodes. Teile des Workflow lassen sich damit in Metaknoten unter eigenem, aussagekräftigen Namen zusammenfassen. Eine mögliche Umstrukturierung des Workflow mit Hilfe von Metaknoten zeigt Abbildung 9.
Distanz berechnen
Jeder Leser sei ein fünfkomponentiger Vektor, der sich aus den Bewertungen in den fünf Rubriken zusammensetzt. Dann berechnet die folgende Formel die Distanz der beiden Leser »x« und »y«:
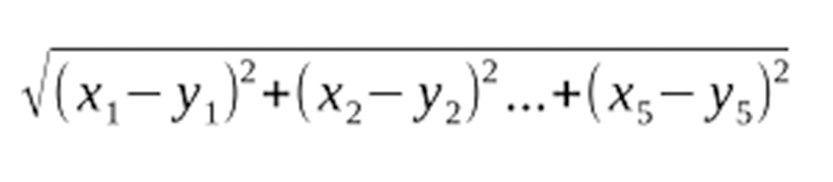
Der k-Means Algorithmus veranlasst nun folgende Schritte, um homogene Gruppen zu finden:
1. Initialisiere die Clusterzentren mit zufälligen Datenpunkten.
2. Berechne für jeden Datenpunkt das nächstgelegene Clusterzentrum.
3. Berechne für jede Gruppe von Datenpunkten, die in Schritt 2 einem Zentrum zugewiesen wurden, den Mittelpunkt.
4. Aktualisiere die Clusterzentren mit den neu gefundenen Mittelpunkten.
5. Bleiben die Zentren unverändert, stoppe die Berechnungen, sonst gehe zu Schritt 2.
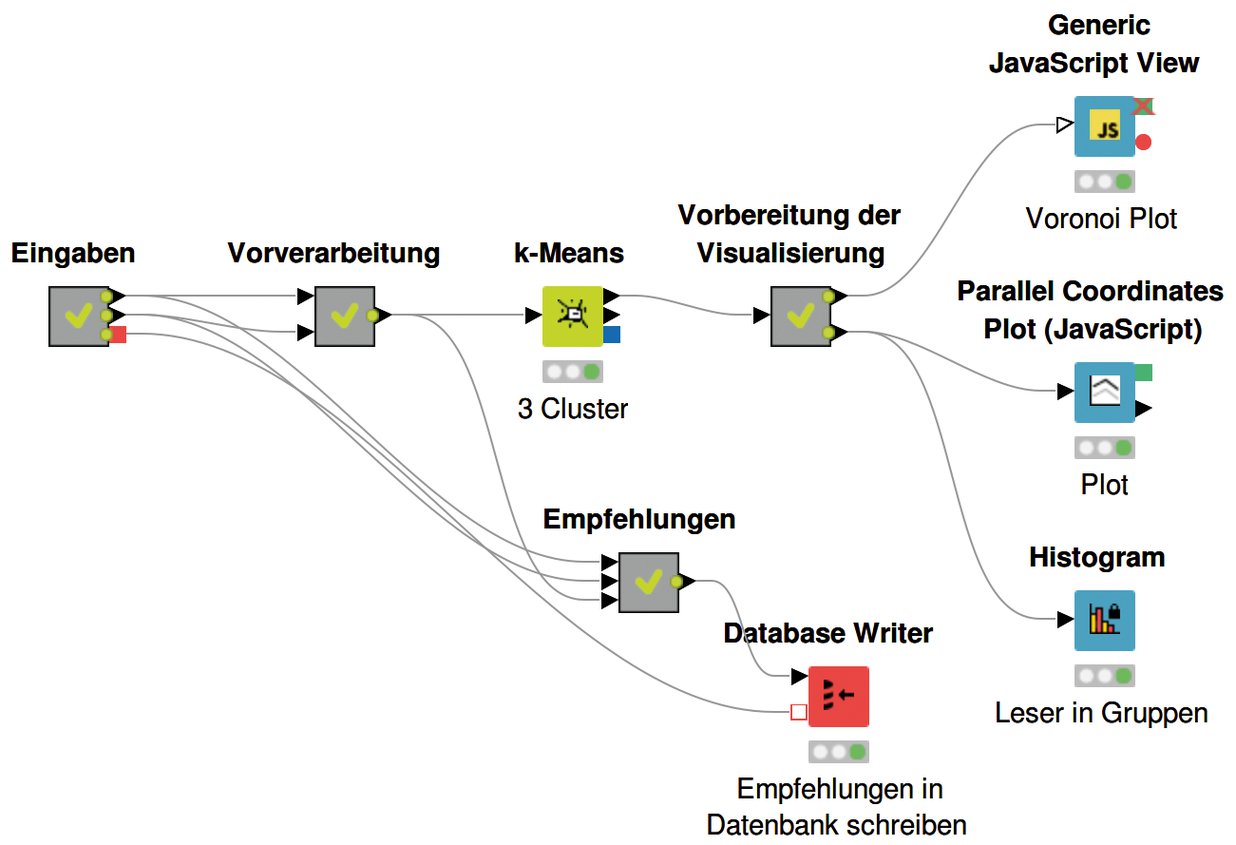
Abbildung 9: Der Beispiel-Workflow aus Abbildung 3, mit Teilen des Workflow als Metaknoten zusammengefasst.
Artikelempfehlungen
Für Artikelempfehlungen sind jene Artikel zu identifizieren, die den Vorlieben des Lesers am nächsten kommen. Hat der Leser zum Beispiel besonderes Interesse an Hardware und Security, dann liegt es nahe, ihm Artikel aus diesen Rubriken vorzuschlagen – bestenfalls sogar Artikel, die in beide Rubriken zugleich eingeordnet sind. Wie stark die Vorliebe eines bestimmten Lesers für jede Rubrik ist, hat der bisherige Workflow bereits erkundet, das Ergebnis liegt in Form eines Vektors vor (Abbildung 5).
Nun lässt sich ein ganz ähnlicher Vektor auch für jeden Artikel erzeugen, bei dem die Spalten jener Rubriken eine »1« enthalten, denen der Artikel zugeordnet ist. Rubriken-Spalten ohne Verbindung zum Artikel enthalten dagegen eine »0«. Der »One-to-Many«-Knoten ermöglicht genau dies: Die Umwandlung der Artikel-Rubriken-Zuordnungen (Tabelle 2) in eine Repräsentation durch einen binären Vektor pro Artikel (Abbildung 10).
| Artikel-ID | Kategorie |
|---|---|
| Artikel 11 | Hardware |
| Artikel 11 | Software |
| Artikel 31 | Entwicklung |
| … |
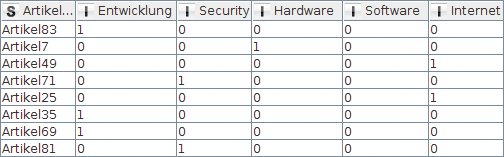
Abbildung 10: Ausgabetabelle des One-to-Many-Knotens.
Sind die beiden Arten von Vektoren erstellt, kann der »Similarity Search«-Knoten einfach zwischen dem Vektor eines Lesers (der dessen Vorlieben repräsentiert) und dem Vektor eines Artikels (der anzeigt, welchen Rubriken er zugeordnet ist) eine Distanz ermitteln. Je kleiner die Distanz ist, desto mehr entspricht die Vorliebe des Lesers den Rubriken, in denen der Artikel eingeordnet ist.
Aus allen Artikeln, die ein bestimmter Leser noch nicht gelesen hat (siehe »Row Reference Filter«-Knoten), ist daher nun einfach jener zu ermitteln, der die kleinste Distanz zu den Vorlieben des Lesers aufweist. Dieser Artikel wird schließlich zur Lektüre empfohlen.
Ein so genannter Loop (bestehend aus Chunk-Loop-Start- und Loop-End-Knoten) entspricht einer For-Schleife über alle Zeilen der Tabelle. Er ermittelt die kleinste Distanz der Vektoren für jeden Leser. Das Gesamtergebnis mit einer Artikelempfehlung pro Leser (Abbildung 11) ließe sich dann zum Beispiel zurück in eine Datenbank schreiben. Hier hilft der Knoten »Database Writer«.
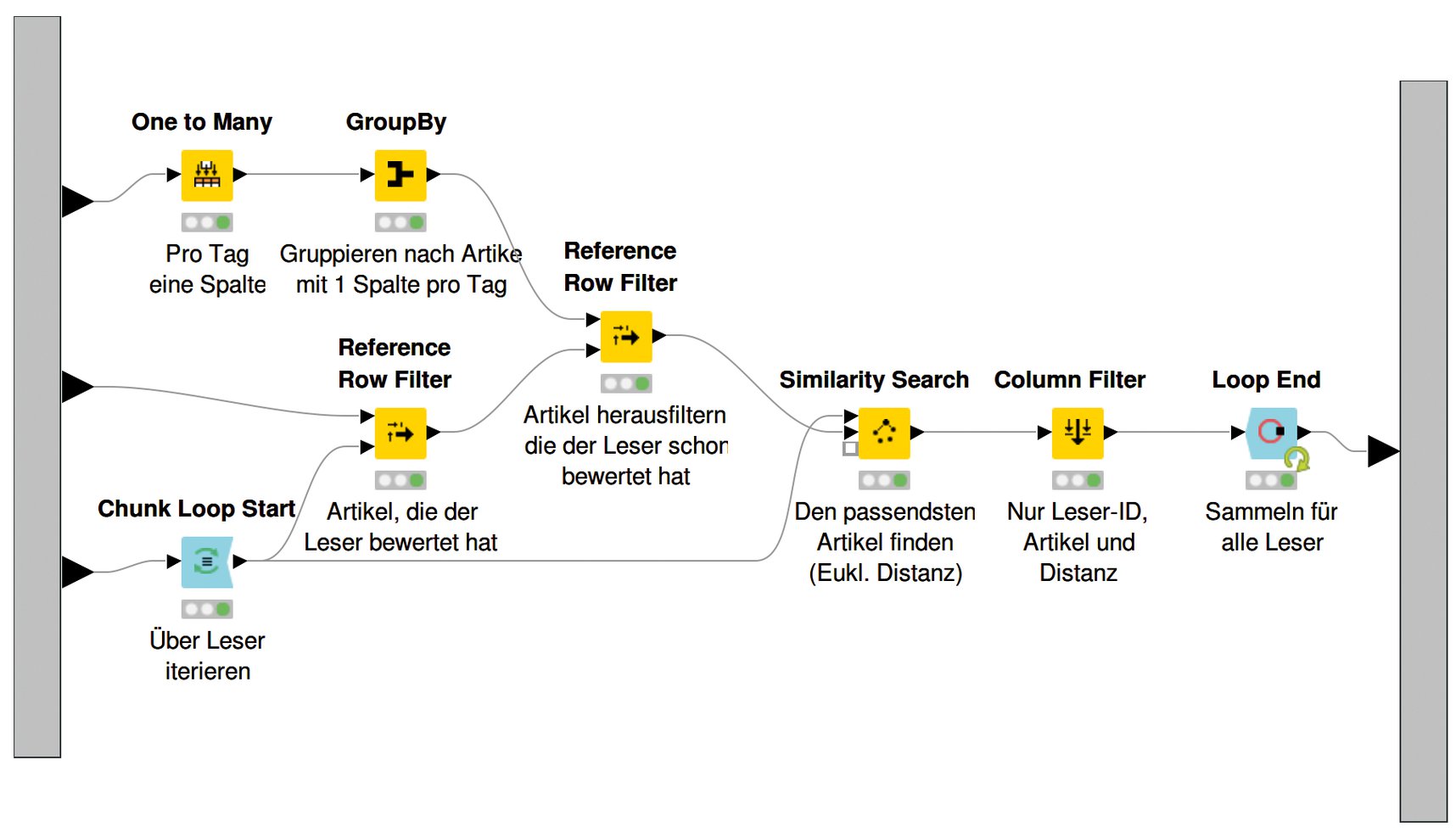
Abbildung 11: Der Inhalt des Metaknotens für die Artikelempfehlungen.
Ausblick
Dieser Artikel konnte nur auf einen Bruchteil der fast 2000 Knoten eingehen, die für Knime verfügbar sind. Spannende Features wie Flow-Variablen, der Workflow Coach, weitere Loop-Knoten, Streaming oder die Verarbeitung von Texten und Bildern sowie das zur Zeit stark gehypte Deep Learning blieben zunächst außen vor. In Folgeartikeln wollen die Autoren einige dieser Features in kommenden Ausgaben vorstellen.
Bis dahin kann sich jeder selbst ein Bild von Knime Analytics Platform machen, indem er die Software herunterlädt und ausprobiert. Fragen beantwortet beispielsweise die Community im Knime-Forum [4] gerne.
Infos
- Knime: https://www.knime.com
- Download Beispiel-Workflow:https://www.linux-magazin.de/static/listings/magazin/2018/04/KNIME/
- D3.js-Framework: https://d3js.org
- Knime-Forum: https://www.knime.com/forum






Den Beispiel-Workflow konnte ich ohne Probleme Schritt für Schritt ausführen.