
© vm2002, 123RF
In großen Datenmengen Muster zu erkennen und Schlussfolgerungen daraus zu ziehen ist längst der Job von Computern. Mit der Open-Source-Software Knime lassen sich viele Verfahren des maschinellen Lernens einfach und kostenlos zu Hause ausprobieren.
Knime
Den Anfang nahm Knime im Jahr 2006 am Lehrstuhl für Bioinformatik und Information Mining der Universität Konstanz unter der Leitung von Prof. Dr. Michael Berthold als “Konstanz Information Miner”. Die Grundidee war, die Datenanalyse für Benutzer verschiedener Fachrichtungen einfach zugänglich und erschwinglich zu machen. Die Entwickler starteten deshalb ein Open-Source-Projekt, bei dem sie besonders auf Anwenderfreundlichkeit und Erweiterbarkeit achteten.
Knime Analytics Platform ist in Java geschrieben und baut auf Eclipse und der Technologie der Open Services Gateway Initiative (OSGI) auf. Die neueste Version (zum Redaktionsschluss 3.6.0) lässt sich unter [2] herunterladen. Dort ist auch weiteres Material für den Einstieg zu finden (zum Beispiel Blogs, Videos, Beispielworkflows).
Knime, das sich selbst in Versalien schreibt (KNIME), wird übrigens englisch wie “Neim” ausgesprochen.
Vor einigen Monaten hat das Linux-Magazin die Open-Source-Analysesoftware Knime (siehe Kasten “Knime”) zum ersten Mal vorgestellt [1]. Sie erlaubt es, Workflows aus Funktionsbausteinen nach dem Lego-Prinzip zu konstruieren, um so anschaulich Daten zu analysieren. Dieser erste Artikel stellte bereits grundlegende Bausteine vor, beispielsweise zur Datentransformation und Visualisierung. Im zweiten Beitrag wollen die Autoren nun von fortgeschritteneren Bausteinen Gebrauch machen, um noch spannendere Probleme zu lösen. Dabei soll es um maschinelles Lernen gehen, also darum, Muster in Daten zu finden, um Vorhersagen machen zu können.
Der lernende Computer
Das automatische Erkennen von Mustern in umfangreichen Datenmengen ist eine der Paradedisziplinen von Knime. In die Schlagzeilen gerät das maschinelle Lernen hauptsächlich im Zusammenhang mit selbstfahrende Autos oder dubiosen Machenschaften datensammelwütiger Großkonzerne. Doch die Verfahren der künstlichen Intelligenz und des maschinellen Lernens können in sehr vielen Bereichen einen Mehrwert schaffen, sind es doch ihre Algorithmen, die Strukturen im Chaos erkennen und damit Daten “in das neue Öl” verwandeln.
Von Anfang an hatten die Entwickler von Knime an der Universität Konstanz Wert auf die Integration der modernsten Algorithmen fürs maschinelle Lernen gelegt. Damals begann alles mit Support Vector Machines und einfachen neuronalen Netzen. Heute beherrscht Knime auch neuere Verfahren, zum Beispiel Random Forests und Deep Learning.
Die vielen nativen Knime-Knoten zum maschinellen Lernen lassen sich außerdem leicht mit zahlreichen anderen Machine-Learning-Tools kombinieren, die ebenso in Knime integriert sind. Darunter sind Scikit-learn [3], Algorithmen aus R [4], H2O [5], Weka [6], LIBSVM [7] oder die Deep-Learning-Integrationen Keras [8], Tensorflow [9] und Deeplearning4J [10].
Unterstützt durch die vielfältigen Möglichkeiten, Daten zu im- und exportieren, zu visualisieren und zu manipulieren, bietet Knime eine Plattform, die den gesamten Analyseprozess als grafischen Workflow abbildet.
Was bisher geschah
In dem vorangegangenen Artikel ging es um einen Online-Verlag, der etwas mehr über seine Leser herausfinden wollte. Dazu wurden die von diesen hinterlassenen Bewertungen für Zeitschriftenartikel in fünf verschiedenen Kategorien verwendet, um eine Art Fingerabdruck zu berechnen, der die Vorlieben eines Lesers beschreibt. Mit Hilfe dieser Fingerabdrücke war es dann möglich, die Leser automatisch in vier Gruppen einzuteilen, diese zu visualisieren und außerdem Empfehlungen für weitere Artikel auszusprechen.
Bei der Umsetzung dieser Aufgabe als Workflow hatte der Beitrag Daten aus einer SQlite Datenbank und aus einer CSV-Datei geladen, miteinander verbunden, aggregiert und pivotisiert. Nach dem Clustering, also dem automatischen Gruppieren mit Hilfe des k-Means-Algorithmus, wurden die Ergebnisse dann als Balkendiagramm, parallele Koordinaten und Voronoi-Diagramm visualisiert.
Das erweiterte Szenario
Der Online-Verlag aus dem vorigen Artikel bietet zudem Newsletter zu fünf verschiedenen Themengebieten an. Für die haben sich auch schon einige Leser angemeldet. Nun soll es darum gehen, diese Newsletter weiteren potenziell interessierten Lesern schmackhaft zu machen. Statt aber jeden Leser mit den Newslettern aller fünf Themengebiete zu überfluten und damit zu nerven, möchte der Verlag etwas geschickter vorgehen.
Basierend auf den bereits bekannten Leservorlieben und den Erfahrungen mit den bisherigen Abonnenten sollen nur jene Leser einen Newsletter empfohlen bekommen, die auch wirklich an dem Thema interessiert sein könnten. Das spart nicht nur eine Menge zu versendender E-Mails, es verärgert auch nicht jene Leser, die mit den angebotenen Themen gar nichts anzufangen wissen und dem Verlag dann vielleicht sogar ganz den Rücken kehren würden.
Als Datengrundlage dienen die bereits bekannten Leservorlieben für bestimmte Themen, wie sie aus den Bewertungen der Zeitschriftenartikel ermittelt worden sind (Abbildung 1). Zudem stehen nun auch Informationen über bereits abgeschlossene Newsletter-Abonnements als neue Datenquelle zur Verfügung. Diese Informationen lassen sich über eine so genannte REST-Schnittstelle abrufen, die die Daten im Json-Format bereitstellt.
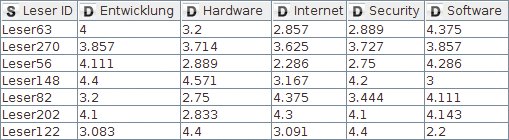
Abbildung 1: Erste Datenquelle: Leservorlieben für bestimmte Themen.
REST
REST steht für Representational State Transfer und beruht unter anderem auf dem Prinzip der Zustandslosigkeit und Adressierbarkeit von Ressourcen im Web. Im Normalfall nutzen REST-Schnittstellen das Json- oder XML-Format. Für beide Formate gibt es entsprechende Datentypen und Verarbeitungsknoten in Knime (zum Beispiel die »Json-Path«- und »XPath«-Knoten).
Doch zuerst einmal gilt es, die Daten abzufragen. Hierfür bietet Knime unter der Kategorie »Tools & Services | REST Web Services« einen Knoten namens »Get Request«. Ebenfalls in dieser Kategorie zu finden sind Knoten zum Senden von Daten an einen REST-Dienst und zum Löschen und Verändern von Ressourcen. Dem »Get Request«-Knoten gibt der Benutzer einfach die URL der Schnittstelle, dann lädt er bei der Ausführung die Daten herunter und gibt sie noch in einer Tabelle aus.
Im Beispielworkflow [11] ist der Get-Request-Knoten durch einen Json-Reader ersetzt, da die Schnittstelle für die Abonnement-Daten natürlich in der Realität nicht existiert. Die Ausgabe des Json-Reader ist in Abbildung 2 zu sehen.
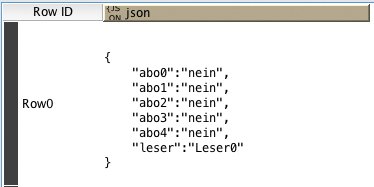
Abbildung 2: Die Tabelle mit den Abonnement-Daten im Json-Format.
Da die meisten Knime-Knoten die Daten im Tabellenformat benötigen und nicht in ein Json-Objekt hineinschauen können, ergibt es Sinn, die empfangenen Daten zu transformieren, sodass jede Leser-ID einer Zeile und jedes Abo einer Spalte entspricht. Dies lässt sich mit einer Kombination aus den Knoten »JSON to Table« und dem »RowID«-Knoten bewerkstelligen, die die Tabelle, wie sie in Abbildung 3 zu sehen ist, erzeugen. Nun lassen sich die Abo-Daten per Joiner mit den Leser-Vorlieben aus dem vorherigen Artikel verbinden, wie es im Workflow in Abbildung 4 zu sehen ist.
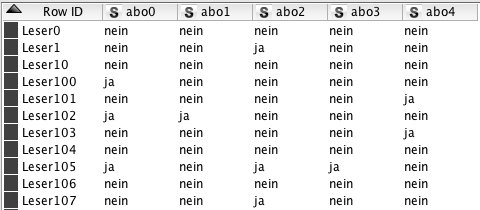
Abbildung 3: Die aus Json erzeugte Tabelle mit Informationen darüber, welcher Leser welches Abonnement abgeschlossen hat.
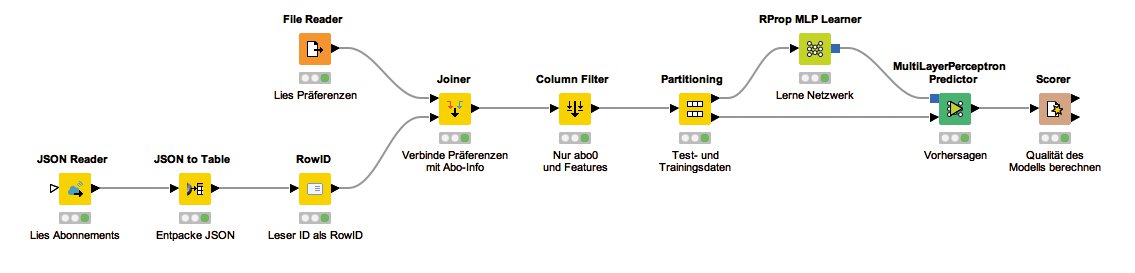
Abbildung 4: Der gesamte Workflow zum Testen eines Modells einschließlich des Einlesens der Daten. Die Daten sind aufgeteilt und ein neuronales Netz lernt die Vorhersage des Interesses für das Abonnement 0. Mit einem »Scorer«-Knoten berechnet Knime die Qualität des Modells.
Maschinelles Lernen
Nun, da alle benötigten Daten in einer Tabelle zusammengefasst sind, lassen sich Vorhersagemodelle erstellen, die es später ermöglichen, für einen Leser ohne Abo vorherzusagen, ob er an einem Newsletter-Abonnement zu einem bestimmten Thema interessiert sein könnte. Genau genommen ist für jedes Thema ein eigenes Modell nötig. Hier starten die Autoren aber zuerst einmal mit einem einzigen Modell, um die Machine-Learning-Fähigkeiten von Knime vorzustellen.
Generell wird beim maschinellen Lernen zwischen überwachtem und nicht überwachtem Lernen unterschieden. Das Clustering im ersten Artikel über Knime war ein Beispiel für das letztere, denn für die dort verarbeiteten Datenpunkte gab es keine bekannte Einordnung, beziehungsweise Label.
Beim überwachten Lernen dagegen sind für die Daten so genannte Label vorhanden, die einem Datenpunkt einen Wert zuordnen, der dann später für neue Daten vorherzusagen ist. Ist dieser Wert eine Zahl, spricht man von Regression, ansonsten von Klassifikation.
Das Vorhersagen, ob ein Leser Interesse an einem Newsletter hätte, entspricht einer Klassifikation, denn der vorherzusagende Wert ist entweder »Ja« oder »Nein«. Man spricht hier auch von binärer Klassifikation. Etwas mehr Hintergrundinformationen zu diesem Thema sind im Kasten “Klassifikation in aller Kürze” zu finden.
Klassifikation in aller Kürze
Klassifikation ist die automatische Unterscheidung von Objekten (Dingen oder Personen) nach unterschiedlichen Klassen, etwa Linux- und Windows-Nutzer. Damit ein Computer eine solche Klassifikation übernehmen kann, müssen die Objekte durch eine feste Anzahl numerischer Merkmale (etwa das Alter der Person) und/oder nominaler Merkmale (zum Beispiel das Geschlecht der Person) beschrieben sein. Auf der Grundlage dieser Merkmale kann eine Computerfunktion den entsprechenden Objekten schließlich eine Klasse zuweisen.
In der Regel bedient sich nun diese Funktion (also der Klassifikationsalgorithmus) eines so genannten Modells, in dem das eigentliche Wissen zur Klassifikation enthalten ist. Dieses Modell wiederum ist a priori nicht bekannt und wird meistens aus so genannten Trainingsdaten erst ermittelt.
Was dabei herauskommt, ist natürlich selten perfekt, sei es aufgrund der Trainingsdaten oder des gewählten Algorithmus. Seine Güte wird daher oft mit Hilfe von Testdaten bestimmt. Das sind Objekte, deren Klassen bekannt sind, sodass sich die Modellvorhersage überprüfen lässt.
Um zu sehen, ob das zu lernendes Modell gut funktioniert, gilt es, die Daten zuerst in einen Test- und einen Trainings-Datensatz aufzuteilen. Während letzterer für das Lernen des Modells verwendet wird, ist ersterer dafür da, dessen Generalisierungsfähigkeit abzuschätzen, also zu sehen, wie gut die Vorhersagen über bisher ungesehenen Daten sind.
Eine Evaluation auf den gleichen Daten, die auch beim Training zum Zuge kommen, führt im Allgemeinen zu viel zu optimistischen Resultaten. Der »Partitioning«-Knoten teilt die Daten also in zwei Tabellen auf. Dabei ist ein Split von 80 zu 20 meist ein guter Richtwert, wobei 80 Prozent dem Lernen dienen und 20 Prozent dem Evaluieren.
Machinelles Lernen ist ein großes Forschungsgebiet und entsprechend gibt es sehr viele verschiedene Ansätze für statistische Modelle. Ein sehr beliebter Ansatz sind die so genannten neuronalen Netzwerke. In Knime wird ein neuronales Netz mit dem »RProp MLP Learner«-Knoten angelernt (RProp steht für den verwendeten Algorithmus, MLP für Multilayer Perceptron, ein Netz mit vielen Schichten).
Bei der Konfiguration des Lerners wählt der Knime-Benutzer lediglich aus, welche Spalte den vorherzusagenden Wert enthält. Wird also der Lerner mit dem 80-Prozent-Ausgang des Partitioning-Knotens verbunden und ausgeführt, trainiert der Knoten ein neuronales Netz, das gelernt hat, aus den Präferenzen der Leser zu bestimmen, für welche Abonnements sie sich interessieren. Mit dem »Multilayer Perceptron Predictor« und einem »Scorer«-Knoten lässt sich mit Hilfe der zuvor ignorierten 20 Prozent der Daten überprüfen, wie gut das Modell wirklich ist. Der Workflow zum Testen des Modells ist in Abbildung 4 zu sehen. Andere geeignete Lerner sind zum Beispiel »Random Forest«, »Gradient Boosted Trees« und »Support Vector Machines«.
In Schleifen
Da es nun aber fünf verschiedene Newsletter gibt, ist für jeden ein eigenes Modell zu lernen. Die simple Lösung hierfür wäre das Erstellen von fünf Workflows. Wirklich praktisch ist das aber nicht, denn ändert sich später der Lernprozess, sind mehrere Workflows (oder Workflow-Teile) gleichzeitig anzupassen. Einfacher ist es, Schleifen (Loops) zu verwenden, die einen Teil des Workflow mehrfach und mit unterschiedlichen Parametern ausführen.
Solch einen mehrfach auszuführenden Teil fasst der Knime-Benutzer durch so genannte »Loop Start«- und »Loop End«-Knoten ein. Für jeden »Loop Start« muss es genau ein »Loop End« geben. Je nach Typ des Startknotens wird der Workflow-Teil zwischen den Schleifenknoten einmal pro Zeile oder für bestimmte Spalten ausgeführt oder bis eine bestimmte Bedingung eintritt. Der Endknoten soll die Daten aus den Schleifendurchläufen sammeln und gegebenenfalls aggregieren.
Für jeden Newslettertyp (1 bis 5) hat die Tabelle (Abbildung 5), mit deren Hilfe die Modelle lernen sollen, eine extra Spalte. Das Ziel ist es also, pro Spalte ein Modell zu lernen, das deren Wert vorhersagt. Um über Spalten zu iterieren, bietet Knime den »Column List Loop Start«-Knoten an. In dessen Konfigurationsdialog lassen sich die Spalten auswählen, für die der Workflow-Teil der Schleife auszuführen ist.

Abbildung 5: Die Tabelle mit den Trainingsdaten. Mit Hilfe der ersten fünf Spalten lassen sich die Werte der letzten fünf anhand jeweils eines eigenen Modells vorhersagen.
Innerhalb der Schleife stehen dann die Spalten für die Leserpräferenzen und eine der Spalten »abo0« bis »abo4« zur Verfügung. Nun kann der Anwender den »RProp MLP Learner« mit dem »Column List Loop Start«-Knoten verbinden, um das entsprechende Modell zu lernen.
Die Aufteilung in Test- und Trainings-Daten in der Schleife ist unnötig, denn sie ist nur dazu da, zu bewerten, ob ein Modell überhaupt in der Lage ist gute Ergebnisse zu liefern. Nachdem dies festgestellt wurde, steht zum Lernen der gesamte verfügbare Datensatz bereit. Der geänderte Workflow, der die Loops verwendet, ist in Abbildung 7 zu sehen.
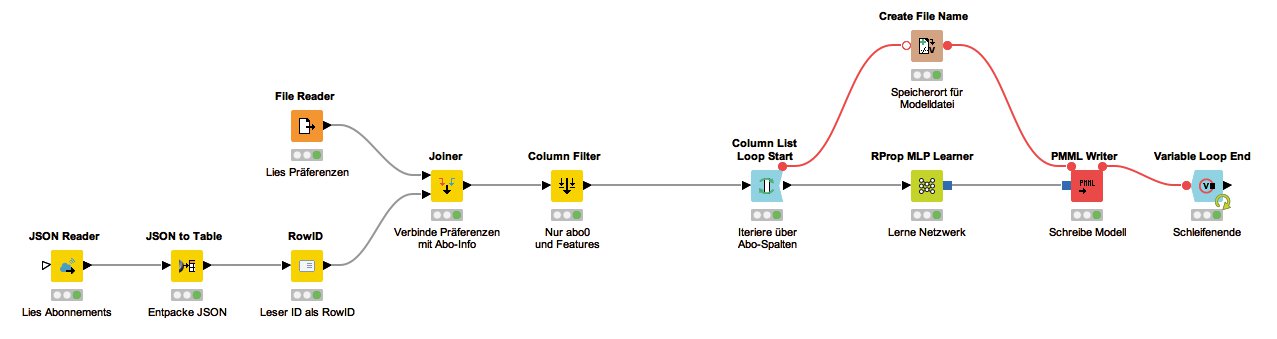
Abbildung 7: Der Workflow zum Lernen von neuronalen Netzen für die Klassifikation von Lesern.
Den Flow kontrollieren und konfigurieren
Allerdings gibt es mit dem Column Loop noch ein Problem: Der Lerner muss wissen, welche Spalte die vorherzusagende ist. Dies lässt sich aber nicht fest konfigurieren, weil sich der Spaltenname ja mit jeder Iteration ändert (»abo0«, »abo1«, …). Hier kommen die so genannten Flow-Variablen ins Spiel.
Bei ihnen handelt es sich im Grunde um Schlüssel-Wert-Paare, die der Anwender zusammen mit den Daten durch den Workflow schickt. Zu sehen sind diese Variablen zum Beispiel im Fenster für die Ausgabedaten eines Knotens im Tab »Flow Variables«. Innerhalb der Schleife steht der Name der aktuell verarbeiteten Spalte als Flow-Variable »currentColumnName« zur Verfügung.
Es gilt also, nun den »RProp MLP Learner« so zu konfigurieren, dass er den Wert dieser Variablen verwendet, um die Spalte mit den Klasseninformationen (also »abo0«, »abo1«, …) zu bestimmen. Dazu öffnet der Benutzer den Konfigurationsdialog des Knotens und besucht den Tab »Flow Variables«. Hier ist eine Liste mit Einstellungen zu sehen.
Im Falle des »RProp MLP Learner« gibt es pro Einstellung zwei Einträge: einen für den internen Gebrauch und einen normalen, zu erkennen an der Auswahlbox rechts daneben. In dieser Box ist eine Flow-Variable bestimmbar, die anstelle des gerade ausgewählten Werts für diese Einstellung zu verwenden ist. Soll also »currentColumnName« als Klassenspalte ins Spiel kommen, ist dieser Eintrag unter »classcol« auszuwählen. Wie das aussieht, zeigt Abbildung 6.
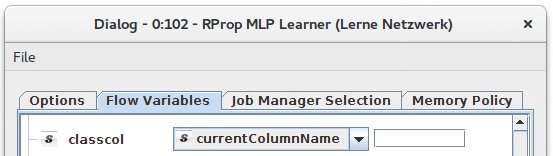
Abbildung 6: Auswahlbox, die den Wert einer Flow-Variablen der Einstellung für die Klassenspalte zuweist.
Modelle speichern und teilen
Nun ist das neu gelernte Modell noch abzuspeichern, damit es der Anwender später wiederverwenden kann. Die Ausgabe des »RProp MLP Learner«, also das Modell, ist ein neuronales Netzwerk im Format Predictive Model Markup Language (PMML, [12]). Dies standardisierte Format für Vorhersagemodelle im maschinellen Lernen ist weit verbreitet und eignet sich daher auch gut für den Austausch von Modellen zwischen verschiedenen Plattformen und Tools.
Um das Modell auf die Festplatte zu schreiben, wird der »PMML Writer«-Knoten benötigt. Da der aber innerhalb der Schleife läuft, hängt der Dateiname im Konfigurationsdialog von der aktuellen Iteration beziehungsweise der gerade zu lernenden Spalte ab. Das Tool muss also aus einem Ordner und einem dynamischen Dateinamen einen Pfad zusammensetzen.
Das lässt sich am besten mit dem »Create File Name«-Knoten erledigen. Dessen Eingang ist grafisch mit einem nicht ausgefüllten roten Kreis markiert, was bedeutet, dass es sich um einen optionalen Eingang für Flow-Variablen handelt. Der Anwender sollte ihn mit dem »Column List Loop Start« verbinden, aber dieser besitzt auf den ersten Blick keinen kompatiblen Ausgang.
Doch der Schein trügt. Die Flow-Variablen-Aus- und -Eingänge der meisten Knoten sind nämlich lediglich versteckt. Durch einen Rechtsklick auf den Loop-Start-Knoten und Auswahl des Menüpunkts »Show Flow Variable Ports« lassen sie sich sichtbar machen.
In seinem Konfigurationsdialog lässt sich nun ein beliebiger Ordner und als Datei-Endung (File Extension) ».pmml« angeben. Den »Base file name« dagegen bestimmt die aktuellen Spalte (»abo0«, »abo1«, …), die in der Flow-Variablen »currentColumnName« zu finden ist. Der Anwender weist sie dem Konfigurationsfeld zu, indem er den kleinen Button neben dem Textfeld anklickt, das Häkchen bei »Use variable« setzt und die Flow-Variable in der Liste daneben auswählt.
Der Ausgang des Knotens ist mit dem entsprechenden Eingang des »PMML Writer« zu verbinden. Um dies zu tun, muss der Flow-Variablen-Eingang nicht unbedingt sichtbar sein. Es reicht, eine Verbindung in die linke obere Ecke des Knotens zu ziehen. Im Dialog des »PMML Writer« kann man dann unter »Output location« wieder über den Flow-Variablen-Button die Variable »filePath« auswählen, um das Modell an diesem Ort zu speichern.
Ihr Ende findet die Schleife schließlich mit einem »Variable Loop End«-Knoten, der mit dem Flow-Variablen-Ausgang des »PMML Writer« verbunden ist. Nun durchläuft Knime die Schleife für jede der fünf Abo-Spalten einmal, und in dem im »Create File Name« angegebenen Ordner landen fünf Vorhersagemodelle. Den Workflow für das Lernen und Speichern von Modellen zeigt Abbildung 7.
Vorhersage
Die ermittelten fünf Modelle erhalten nur dann einen wahren Nutzen, wenn man sie für die Vorhersage auch verwendet. Daher kommen sie nun zum Zuge, um für Leser ohne Newsletter-Abo vorherzusagen, ob und an welchem Abo sie interessiert sein könnten.
Dazu erzeugt der Anwender am besten einen neuen Workflow. Der liest zunächst die zuvor ermittelten Modelle mit Hilfe des »List Files«-Knotens ein. Als Filter ist hier ».pmml« und »file extension(s)« anzugeben. Der Ordner, der zu durchsuchen ist, ist natürlich der gleiche wie der, in welchen zuvor die Vorhersagemodelle geschrieben wurden.
Das Ergebnis ist eine Tabelle, in der jede Zeile einer passenden Datei in dem Ordner entspricht. Verbindet man diese mit einem »Chunk Loop Start«-Knoten, läuft der folgende Teil des Workflow für jede Datei einzeln. Mit einem »Table Row to Variable«-Knoten ist die einzelne Zeile in Flow-Variablen umwandelbar, wobei aus jeder Spalte eine Variable wird. Die Variable »URL« ist anschließend in einem »PMML Reader«, dem Gegenstück zum »PMML Writer«, als Wert für die Eingabedatei verwendbar.
Das Modell, das am Ausgang des Knotens zur Verfügung steht, kann der Anwender nun zusammen mit den vorherzusagenden Daten, den Präferenzen von Lesern ohne Abo, an einen »MultiLayer Perceptron Predictor« übergeben. Der wendet das Modell auf die neuen Daten an und sagt voraus, ob der Leser an dem von dem Modell repräsentierten Abonnement interessiert sein könnte.
Von der Ausgabetabelle des Vorhersageknotens will der Anwender nur die Spalte mit der Vorhersage behalten. Dafür benötigt er den »Column Filter«-Knoten. Er wählt in dessen Konfiguration die Option »Wildcard/Regex Selection« und gibt als Muster den Text »Prediction (abo*)« ein. Der Ausgang des »Column Filter« wird mit einem »Loop End (Column Append)«-Knoten verbunden, um eine Tabelle zu erhalten, die für jedes Newsletter-Abo vorhersagt, ob ein Leser an diesem Interesse hat. Die Tabelle zeigt Abbildung 8, Abbildung 9 den Workflow.

Abbildung 8: Die Tabelle mit den Vorhersage-Ergebnissen.
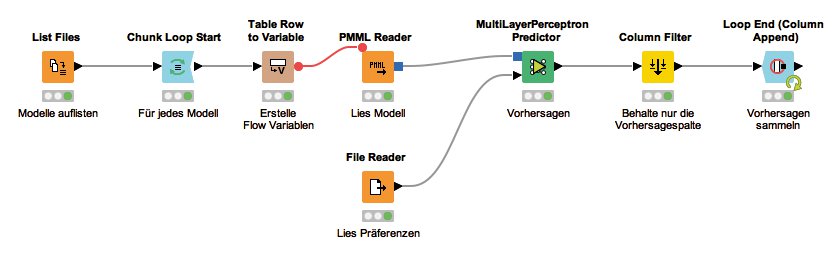
Abbildung 9: Der Workflow zum Vorhersagen von Leserinteresse an Abonnements.
Knime kann noch mehr
Zwei Artikel haben nun gezeigt, wie ein Anwender Daten in Knime verarbeiten, visualisieren und analysieren kann. Dabei handelte es sich um einfache Tabellen aus Zahlen und Texten. Aber durch kostenlose Erweiterungen, die Knime selbst und andere Entwicklern bereitstellen, ist noch viel mehr möglich. So lassen sich zum Beispiel auch Massenspektrometrie- und Gensequenz-Daten in Knime-Tabellen speichern und verarbeiten.
Allen, die wissen wollen, was mit Knime möglich ist, sei ein Blick in den Node Guide [13] empfohlen. Auch lohnt sich eine Konsultation der Seite der Knime-Community [14]. Eine Menge Videos, die Funktionen und Konzepte anschaulich erklären, finden sich auf Youtube [15]. Wer doch mal nicht weiterkommt, ist im Knime-Forum [16] gut aufgehoben, wo ausgewiesene Experten gerne Hilfestellung geben. (jcb)
Infos
-
Alexander Fillbrunn, Martin Horn, “Das Analyse-Lego”: Linux-Magazin 04/18, S. 82
-
Knime: https://www.knime.com
-
Scikit-learn: http://scikit-learn.org/stable/index.html
-
H2O.ai: http://www.h2o.ai
-
Keras: http://keras.io
-
Tensorflow: http://www.tensorflow.org
-
Beispiel: https://www.linux-magazin.de/static/listings/magazin/20/8/10/knime
-
Node-Guide: https://www.knime.com/nodeguide
-
Knime-Community: https://www.knime.com/knime-community
-
Knime-TV: https://www.youtube.com/user/KNIMETV
-
Knime-Forum: https://forum.knime.com





