
Im Juni stellte Intel die Version 9.0 des C-, C++- sowie Fortran-Compilers für die hauseigenen Prozessoren vor, um damit die Messlatte für hochoptimierten Code höher zu legen. Die vom Linux-Magazin ermittelten Benchmarks vergleichen Anspruch und Wirklichkeit.
Der Zwischenstopp bei Version 8.1 rüstete den Intel-Compiler ICC [1] für die AMD64/x86-64-Architektur auf (bei Intel EM64T). Nun erscheint mit Version 9 eine ausgewachsene Major-Release mit neuen Erweiterungen und Optimierungen [2]. Wie in der vorherigen Version beherrscht der Compiler die Architekturen IA-32, x86-64 sowie Intel Itanium. Ein Intel-eigener Debugger, ein Code-Coverage-Tool und die Entwicklungsumgebung Eclipse runden das Paket ab. Für den Itanium-Prozessor ist zusätzlich ein Assembler enthalten, der in diesem Artikel aber nicht getestet wird. Zudem muss der Itanium-Entwickler bislang auf Eclipse-Integration verzichten.
Das Lizenzmodell gleicht dem der Vorversionen: Für Open-Source-Projekte ist eine nicht-kommerzielle Lizenz ohne Support erhältlich. Damit erstellte Binaries dürfen nicht verkauft werden. Jede kommerzielle Entwicklung erfordert eine entsprechende Lizenz. Je nach Umfang der Installation gibt man entweder die Seriennummer oder eine Lizenzdatei an. Alternativ arbeitet der Compiler auch mit einem Flex-Lizenzmanager im Netzwerk zusammen. Der C++-Compiler kostet bei deutschen Distributoren ungefähr 300 Euro, direkt bei Intel knapp 400 US-Dollar.
Profilgesteuert optimieren
Ein neues, schon im Vorfeld heiß diskutiertes Feature ist Software-based Speculative Pre-Computation (SSP) mit der zugehörigen Option »-ssp«. Dabei fügt der Compiler dem Programm einige Hilfs-Threads hinzu, die im Programm enthaltene Instruktionen vorab ausführen, um unter anderem den Instruktions-Cache der CPU mit Daten zu füllen. Besonders effektiv soll diese Methode mit Hyper-Threading arbeiten.
Das ist nur eine von mehreren so genannten profilgeleiteten Optimierungen (Profile Guided Optimizations). Dabei übersetzt der Entwickler zuerst das Programm mit spezieller Instrumentierung (»-prof-gen-sampling«), um es dann mit »profrun« auf einem repräsentativen Satz von Eingabedaten laufen zu lassen. Anschließend übersetzt er mit den gesammelten Informationen das Programm noch einmal neu, siehe [3].
Im Gegensatz zu vorherigen Versionen sind nun schon ab »-O2« standardmäßig diverse interprozedurale Optimierungen eingeschaltet und der Compiler optimiert eine größere Anzahl an Schleifen. Dabei gibt ICC jetzt noch mehr Feedback an den Entwickler: Die Reports über optimierte Schleifen und andere Warnungen sind nun detaillierter. Beim Übersetzen von mehreren Dateien bietet der Compiler mehr Möglichkeiten der Optimierung. Außerdem lassen sich in der neuen Ausgabe beim zusammengefassten Kompilieren mehrerer Dateien mit »-ipo« einzelne Objektdateien generieren.
Installation mit RPM
Die Version 8 des Intel-Compilers brachte schon 65 MByte auf die Waage, die aktuelle übertrifft dies mit satten 192 MByte bei weitem. Der Tarball enthält verschiedene RPM-Pakete für I-386, EM64T und IA64. Zusätzlich bringt er die gesamte Eclipse-Plattform mit dem C Development Toolkit (CDT) in einer GTK- sowie einer Motif-Version mit.
Ein Shellskript erledigt die Paketinstallation, die jedoch jenseits der von Intel vorgesehenen RPM-basierten Distributionen (Red Hat und Suse) durchaus Schwierigkeiten bereiten kann. Auf manchen Systemen gibt das Skript nur aus, dass es Maschinentyp, Glibc und Kernel nicht erkennt. Bei dem Debian-basierten Ubuntu verlief die Installation dagegen problemlos. Für das Entpacken der RPM-Archive ist in jedem Fall der Befehl »rpm« zuständig.
Abbildung 1: Das Frontend des Intel-Compilers ist funktional, besticht aber nicht gerade durch Modernität.
Überhaupt ist die Handhabung des Compilers nicht ganz so reibungslos, wie man es vom gut ins System integrierten GCC gewohnt ist. Standardmäßig sucht der ICC nicht in den Bibliotheks- und Header-Verzeichnissen seiner eigenen Installation, sodass in vielen Fällen »-I/opt/intel/cc/9.0/include« und gegebenenfalls »-I/opt/intel/cc/9.0/include/c++« zu setzen ist. Da die Programme im Normalfall gegen die ICC-Runtime-Bibliotheken linken, empfiehlt es sich, beim Ausführen die Umgebungsvariable »LD_LIBRARY_PATH« auf »/opt/intel/cc/9.0/lib« zu setzen.
|
OpenMP |
|---|
|
OpenMP [4] ist ein umfangreicher Standard, der die Sprachen C, C++ und Fortran um Ausdrücke erweitert, die dem Compiler explizit vorgeben, wie er ein Programm in parallele Threads aufteilen soll. Zentrale Elemente sind »#pragma«-Anweisungen, die Hinweise dafür liefern, wie der Compiler den Code in nebenläufige Fragmente zerlegen kann. So markiert »#pragma omp parallel« einen Block zur parallelen Ausführung; »shared()« spezifiziert dabei gemeinsame Variablen und »private()« die für jeden Prozess exklusiv zu behandelnden. Der Ausdruck »#pragma omp for schedule« bestimmt die Verteilung auf die Threads. Auf diese Weise wird mittels der »#pragma«-Direktiven eine Daten verarbeitende Schleife zur parallelen Ausführung markiert. Die Threads teilen sich dabei die Variablen »a«, »b«, »c« und »chunk«, die Iterationsvariable »i« ist privat in jedem Thread vorhanden. Der Ausdruck weist den Compiler an, die For-Schleife parallel auszuführen und den Iterationsraum dabei in einzelne Blöcke der Größe »chunk« zu zerlegen. OpenMP definiert noch wesentlich mehr Anweisungen, um komplexe Details zur Parallelisierung vorzugeben. Zurzeit werden diese jedoch nur von speziellen Compilern implementiert, hauptsächlich im Bereich von High-Performance-Clustern. Listing 1 zeigt ein kleines Beispiel für die Verwendung von OpenMP. |
Normalerweise erfolgt das über »source /opt/intel/cc/9.0/bin/iccvars.sh«, und zwar entweder zur Datei ».profile« hinzugefügt oder manuell auf der Konsole eingegeben. Zur Vereinfachung lassen sich diese Vorgaben in den beiden Konfigurationsdateien »…/bin/icc.cfg« sowie »…/bin/icpc.cfg« einstellen. Das regelmäßige Setzen von »LD_LIBRARY_PATH« erspart ein entsprechender Eintrag in »/etc/ld.so.conf«. Standardmäßig verwendet ICC die C++-Systembibliothek, bringt aber auch eine eigene Implementierung mit. Die Optionen -»cxxlib-icc« und -»cxxlib-gcc« erlauben das explizite Umschalten.
Seit Version 8.1 versteht ICC auch die Optionen »-march« und »-mcpu« des GNU-Compilers. Intel selbst verwendet allerdings die etwas kryptische Notation »-x{K|W|N|B|P}«, die auf den Intel-internen Codenamen basiert: K steht für Pentium III (Katmai), B für Pentium M (Banias). Die Option »-ax« verarbeitet sogar mehr als einen CPU-Typ: Damit übersetzt ICC lohnende Code-Passagen mehrfach, jeweils für eine andere CPU optimiert. Beim Start des Programms aktivieren sich abhängig vom Prozessor die passend optimierten Blöcke.
Zusammenspiel mit GCC
Es ist prinzipiell möglich, Objektdateien eines Programms gemischt mit ICC und GCC zu übersetzen, zum Beispiel wenn der ICC eine Datei nicht übersetzen will oder der GCC in einem Fall deutlich besseren Code generiert. Verwendet man »icc« fürs Linken, bindet er ohne weitere Parameter die nötigen Intel-Laufzeit-Bibliotheken ein:
icc -o prog main.o math.o
Wer seine Objektdateien dagegen mit »gcc« linken möchte, muss die Hilfsbibliotheken explizit angeben. Mit GCC sind zusätzliche Linker-Parameter nötig:
-L/opt/intel/cc/9.0/lib/ -lirc
Hinter den Kulissen verwendet der Intel-Compiler für IA-32 ohnehin die GNU Binutils.
|
Listing 1: |
|---|
01 #include <omp.h>
02 main ()
03 {
04 const int N = 10000;
05 int i;
06 float a[N], b[N], c[N];
07 const int chunk = 100;
08
09 #pragma omp parallel shared(a,b,c,chunk) private(i)
10 {
11 #pragma omp for schedule(dynamic,chunk) nowait
12 for (i=0; i < N; i++)
13 c[i] = a[i] + b[i];
14
15 } /* Ende des parallelen Blocks */
16 }
|
Parallelisierung von Hand und automatisch
Die OpenMP-Arbeitsgruppe [4] arbeitet Spezifikationen aus, um bei C-, C++- oder Fortran-Programmen dem Compiler Hilfen für die Parallelisierung von Applikationen zu geben. Mit der Option »-openmp« aktiviert erzeugt der Intel-Compiler auf Unix-Systemen Programme, die CPU-intensive Fragmente (beispielsweise Schleifen) parallelisieren. Beim Programmstart erzeugt das Binary dazu mit Hilfe der Pthread-Bibliothek mehrere Threads, die solche Fragmente dann parallel bearbeiten. So werden Mehrprozessorsysteme besser ausgenutzt (siehe Kasten “OpenMP”).
Der ICC 9 erkennt inzwischen auch ohne OpenMP selbstständig Abschnitte, die sich in eigenständigen Threads parallelisieren lassen. Die Option »-parallel« schaltet die automatische Parallelisierung ein. So können vor allem Anwender, die ohne Änderungen am Quellcode mehrere Prozessoren oder CPU-Cores bedienen wollen, vom Compiler eine Beschleunigung ihres Code erwarten. Tabelle 1 führt die Anzahl der Schleifen an, die der Compiler pro Benchmark vektorisierte. Die Werte in Klammern sind die durch Code in der C++-STL-Bibliothek entstandenen Ausdrücke.
|
Listing 2: Detaillierte |
|---|
01 lib/__dtostr.c(47): remark #1572: floating-point
02 equality and inequality comparisons are unreliable
03 if (d==0.0) {
04 ^
|
Hinweise zur Fehlersuche
Eine weitere Hilfe für Entwickler sind die detaillierten Warnungen des Intel-Compilers. Sie gehen teils deutlich über die des GNU-Compilers hinaus und warnen insbesondere bei konstanten Ausdrücken, Verwendung von temporären Objekten, Vergleichen von Fließkommazahlen oder Verlust von Präzision in Berechnungen und Zuweisungen. Dabei zitiert der Intel-Compiler, wie in der vorigen Version, den Quellcode und markiert genau das Zeichen, bei dem die Warnung oder der Fehler auftrat, das hilft bei der Fehlersuche (Listing 2, Zeilen 3 und 4).
Der im ICC-Paket enthaltene Debugger ist wie GDB mit einem Text-Interface zu bedienen, bringt aber auch ein minimalistisches grafisches Frontend mit. Der Debugger IDB startet normalerweise in einem DBX genannten Modus, in dem er Eingaben in einer von Intel definierten Syntax erwartet. Mit der Option »-gdb« gestartet bietet er Kompatibilität zum GDB (mindestens Version 6.1).
Spartanische Oberfläche
Startet IDB mit der Option »-gui«, erscheint er mit einer recht altmodischen grafische Oberfläche (siehe Abbildung 1). Leider unterstützt das GUI nur wenige Automatismen, sodass es die Arbeit gegenüber der Konsole kaum vereinfacht. Besondere Visualisierungen bietet der grafischer Debugger nicht.
Im Gegensatz zu GDB kennt der IDB keine Vervollständigung über die Tab-Taste. Immerhin lassen sich Breakpoints in Instanziierungen von C++-Templates setzen, vorausgesetzt dass diese nicht vom Compiler inline gesetzt wurden. Im Gegensatz dazu nimmt der GDB solche Breakpoints zwar manchmal an, stoppt aber nicht bei der Ausführung.
Benchmark-Hürden
Zur Geschwindigkeitsmessung kam die bereits aus den letzten Compiler-Tests ([5], [6]) bekannte Benchmark-Suite zum Einsatz. Bei den C-Benchmarks traten keine Schwierigkeiten auf. Bei C++ hingegen gab es unerwartet Probleme: Beim Übersetzen des aus ungefähr 2 MByte modernem C++-Code mit Templates bestehenden Tramp-3D brauchte der ICC derart viel Speicher, dass der Kernel des Testsystems ihn beendete. Erst nach einer Vergrößerung des virtuellen Speichers auf über 1 GByte schaffte es der Compiler, ein Binary zu erzeugen. Der maximale Speicherbedarf betrug 1,3 GByte! Intel zeigte sich auf Nachfrage interessiert an dem Problem und will seine Ursachen untersuchen.
Auch der Botan-Benchmark bereitete dem ICC Probleme: Das Testprogramm ließ sich zwar ohne Argumente zur Ausgabe des Hilfetextes starten, mit »–validate« oder »–benchmark« stürzte es jedoch sofort in der Intel-C++-Bibliothek ab. Zur Überraschung der Tester mussten sie die für Botan verwendete Option »-fpermissive« entfernen, die beim GCC für weniger strenge Fehlerbehandlung sorgt. Mit ihr brach der ICC bei mehreren Fehlern die Arbeit ab.
|
Tabelle 1: |
|||
|---|---|---|---|
|
|
ICC -O2 |
-O2 -ip |
GCC |
|
Botan |
(171) 36 |
2 |
|
|
Bzip2 |
58 |
6 |
|
|
GnuPG |
132 |
192 |
6 |
|
Gzip |
48 |
62 |
2 |
|
Lame |
118 |
112 |
22 |
|
Libmad |
24 |
24 |
4 |
|
OpenSSL |
148 |
170 |
30 |
|
Tramp-3D |
(30) 8 |
2 |
|
Die Benchmark-Ergebnisse sind nicht eindeutig (Abbildungen 2 und 3): Bei OpenSSL, Libmad, Bzip2 sowie Gzip konnte der Intel-Compiler teils deutlich höhere Ausführungsgeschwindigkeit erzielen. Bei Lame und GnuPG ist der erzeugte Code jedoch langsamer als der vom GCC generierte. Dass auch der ICC nicht immer perfekten Code übersetzt, zeigt sich bei Tramp-3D: Der Compiler brauchte nicht nur extrem viel Speicher, das Resultat kann auch nicht mit dem des GCC mithalten.
Die Übersetzungszeiten der Compiler unterscheiden sich nicht wesentlich, außer beim Tramp-3D-Benchmark. Dabei liegen im Durchschnitt der ICC und die aktuelle GCC-Version etwa gleichauf.
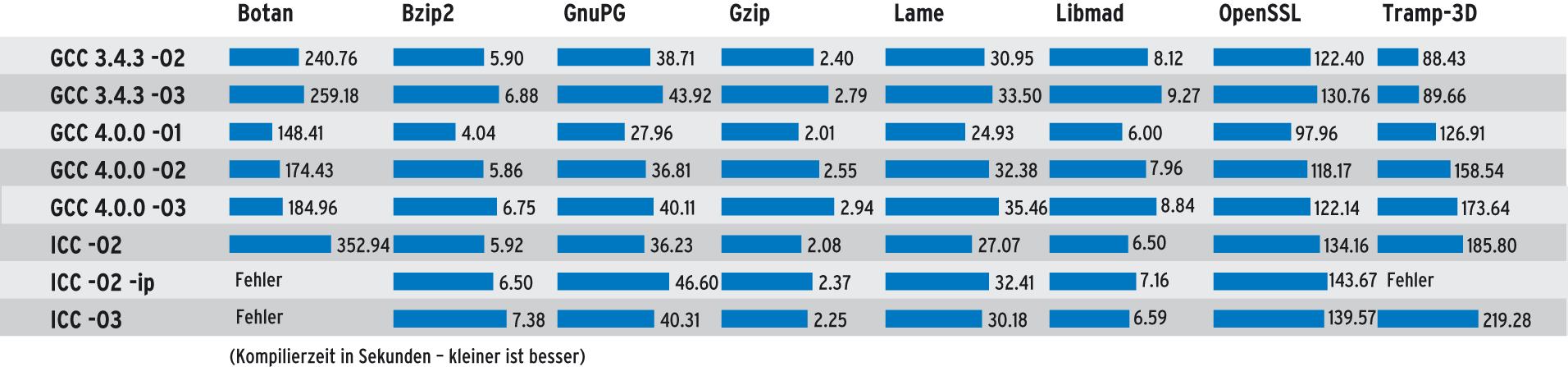
Abbildung 2: Der Intel-Compiler ICC 9.0 übersetzt in einigen Fällen schneller als der GNU-Compiler 4.0. Mehr Zeit braucht aber die Optimierungsoption »-ip«.
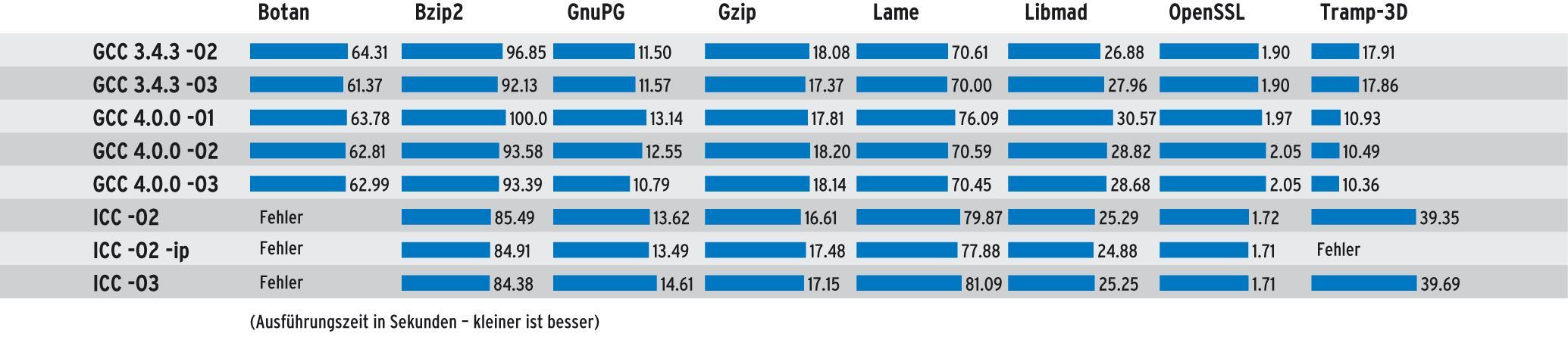
Abbildung 3: Bei OpenSSL, Libmad, Bzip2 sowie Gzip erzielt der Intel-Compiler in Version 9 teils deutlich höhere Ausführungsgeschwindigkeiten als der GNU-Kollege.
Fazit
Konnte der ICC vor ein paar Jahren noch große Gewinne bei Benchmarks verbuchen, haben die modernen GCC-Versionen inzwischen aufschließen können. Bei der automatischen Vektorisierung liegt der ICC 9.0 aber weiterhin vorn und zeigt, wie gut sich kompilierter C- und C++-Code auf die SIMD-Einheiten (Single Instruction, Multiple Data) moderner CPUs verteilen lässt. Unterstützung für OpenMP oder automatische Parallelisierung sind beim High Performance Computing von Vorteil. Hilfreich für Entwickler sind die umfangreichen Warnungen des Intel-Compilers: So lassen sich potenzielle Probleme schon bei der Entwicklung erkennen und die Fehlersuche beim Testen minimieren. (ofr)
|
Infos |
|---|
|
[1] Intel C++-Compiler: [http://www.intel.com/software/products/compilers/clin/] [2] Übersicht der ICC-Optimierungen: [http://www.intel.com/software/products/compilers/docs/qr_guide.htm] [3] Ingo A. Kubbilun, “Kernel kompilieren mit dem ICC”: Linux-Magazin 07/04, S. 34 [4] OpenMP: [http://www.openmp.org] [5] René Rebe, “GCC 3 und 4 im Vergleich” (4), Linux-Magazin 08/04, S. 50 [6] René Rebe, “GCC 4 im Test”: Linux-Magazin 07/05, S. 100 |
|
Der Autor |
|---|
|
René Rebe ist seit 1997 im Linux-Umfeld aktiv. Er ist einer der Hauptentwickler des Distributionsbaukastens T2. |





