
© photocase.com
Aktuelle Versionskontrollsysteme folgen dem Trend zum verteilten System. SVK gehorcht dem dezentralen Ansatz und bedient sich dabei existierender Systeme wie Subversion. Dieser Artikel beschreibt die Konzepte und zeigt, wie SVK sie auf elegante Weise umsetzt.
In einer E-Mail mit dem Subject “Eric goes to lunch” skizzierte Eric S. Raymond im Jahr 2004 auf der Subversion-Mailinglist [1] den typischen Arbeitsalltag eines Entwicklers, der viel unterwegs ist. Zwar verbringt die dort auftretende Hauptfigur ihre Nachmittage programmierend nur im Sandwich-Laden um die Ecke und nicht etwa am anderen Ende der Welt. Auf die gewohnte Internetverbindung muss sie in dieser Zeit trotzdem verzichten.
Diese Geschichte deutet bereits an, dass der zentralistische Ansatz von CVS und vergleichbaren Systemen modernen Anforderungen nicht mehr gewachsen ist. Der Grund dafür liegt in der enorm gewachsenen Mobilität der Entwickler. Vor allem in der Open-Source-Entwicklergemeinde ist es üblich, statt in einem Großraumbüro eher bei Starbucks über eine WLAN-Netzwerkverbindung zu arbeiten. Aber egal ob im Coffeeshop oder im Home-Office: Eine unterbrechungsfreie Verbindung zu einem zentralen Quellcode-Repository ist in einer solchen Umgebung nicht immer gewährleistet. Das erfordert eine Lösung, die es erlaubt, offline zu arbeiten.
Umherschweifende Programmierer
Eric S. Raymond definierte in seiner E-Mail mehrere Anwendungsfälle der verteilten Software-Entwicklung. Zu unterscheiden sind Szenarien mit Internetverbindung und solche, bei denen diese fehlt, zum Beispiel in der Eisenbahn oder in einem Restaurant. Arbeitet der Entwickler unabhängig von einem zentralen Quellcode-Repository, braucht er auf seinem Rechner ein eigenes Miniatur-Repository.
Eine einfache Lösung dafür wäre, wie Raymond beschreibt, via Rsync ein CVS- oder Subversion-Repository auf den lokalen Rechner zu spiegeln. Wesentlich eleganter wäre aber, wenn ein Versionskontrollsystem auch diesen Arbeitsschritt übernähme. Unabhängig davon wandern die Änderungen, die Entwickler offline vornehmen, irgendwann wieder in das zentrale Quellcode-Repository.
Die bereits im Linux-Magazin vorgestellten Tools Arch und Monotone [2] sowie das Kernel-VCS Git [3] sind solche verteilten Versionskontrollsysteme. SVK [4] realisiert ein verteiltes VCS, indem es auf existierende Versionskontrollsysteme wie Subversion [5] aufsetzt.
Die Installation des SVK-Systems gestaltet sich verhältnismäßig einfach, wenn sie über eines der zahlreich verfügbaren Linux-Softwarepakete erfolgt. Von einem manuellen Übersetzen der Perl-Quellen ist eher abzuraten, da SVK von diversen Perl-Softwarepakten abhängt und es ein nicht zu unterschätzender Aufwand ist, diese ordnungsgemäß zu installieren. Unter Windows ist von einer manuellen Installation gänzlich abzuraten. Stattdessen sollten Windows-Benutzer besser zur installierbaren Binärversion der SVK-Distribution greifen.
Da SVK auf Teilen des Subversion-Systems basiert, ist es notwendig, die Perl-Bindings des Subversion-Systems zu übersetzen. Dies erfordert vor allem unter Windows Werkzeuge wie Microsoft Visual Studio. Zudem stellte sich beim Schreiben dieses Artikels heraus, dass die 256-Byte-Grenze für relative Pfadangaben unter Windows wegen der zahlreichen Include-Anweisungen ein erhebliches Hindernis bildet.
Elegante Lösung
Das Rad völlig neu zu erfinden, um ein verteiltes Versionskontrollsystem zu realisieren, mag ein eher plumper Ansatz sein. Bereits existierende Lösungen erneut zu verwenden oder diese in das eigene Architekturkonzept zu integrieren, ist vergleichsweise viel eleganter.
SVK geht diesen Weg, indem es zum einen Teile des Subversion-Systems nutzt, zum anderen Subversion um neue Funktionen erweitert. SVK verwendet nicht alle Teile der Subversion-Codebasis. Vielmehr greift es auf ausgewählte Teile wie den Libsvn_fs-Storage-Driver zurück. Andere Teile, etwa das Modul zum Verwalten einer Arbeitskopie, wurden von Grund auf neu entwickelt.
Ein weiterer interessanter Aspekt, den SVK bietet, ist die Integration anderer Versionskontrollsysteme wie Perforce, CVS oder Microsofts Visual Source Safe. Es ist also möglich, mit nur einem Werkzeug und nur einem Satz von Befehlen auf unterschiedlichen Versionskontrollsystemen zu arbeiten. Technisch wird dies auf der Basis von Treibern für das jeweilige Versionskontrollsystem umgesetzt. Ein Verfahren, wie man es von den JDBC-Datenbank-Treibern kennt. Auf diesen Punkt geht der Artikel später noch genauer ein. Weil SVK stark von den gewohnten Prinzipien der Versionskontrollsysteme abweicht, erschließen sich Funktion und Bedienung allerdings nicht von selbst.
SVK-Topologie
Zum besseren Verständnis zeigt Abbildung 1 eine schematische Darstellung des SVK-Systems. Grundsätzlich ist zwischen einem originären Serversystem zu unterscheiden, von dem der Entwickler seinen Quellcode bezieht, und einem lokalen Versionskontrollsystem, mit dessen Hilfe er auch ohne Netzanbindung arbeiten kann.
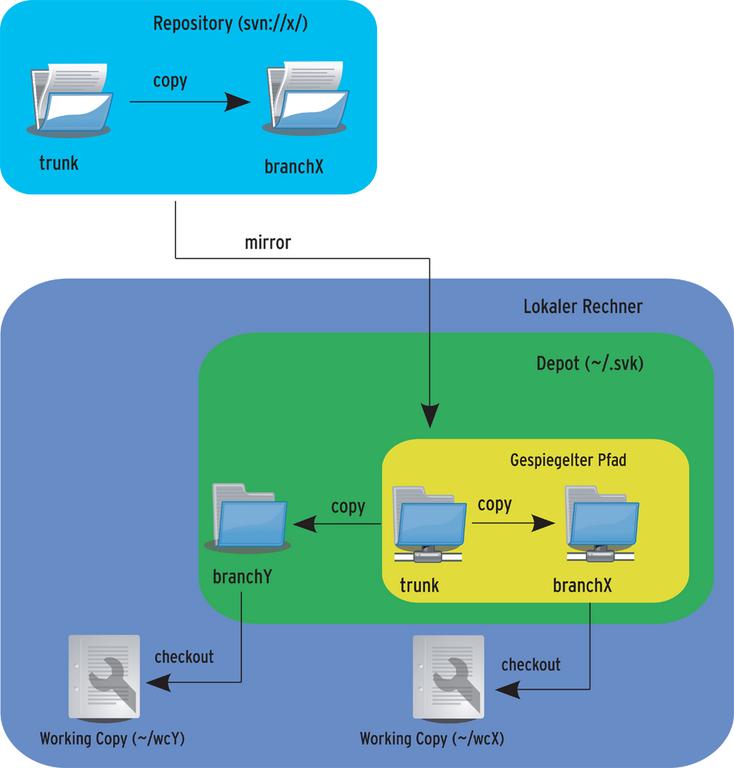
Abbildung 1: Aufbau einer SVK-basierten Infrastruktur.
Das zentral organisierte Quellcodearchiv heißt Repository. Dabei kann es sich – wie in der Abbildung dargestellt – um ein Subversion-System handeln oder um ein anderes von SVK unterstütztes VCS. Demgegenüber steht das lokale Quellcodearchiv auf dem Rechner des Entwicklers, das man als Depot bezeichnet (dunkelgrüner Bereich in Abbildung 1). Der beschriebene Aufbau zeigt, dass sich an der zugrunde liegenden Infrastruktur eines bestehenden zentralen Versionskontrollsystems nichts ändert. SVK setzt darauf auf und kommt nur auf dem Rechner des Entwicklers zum Einsatz.
Um mit SVK arbeiten zu können, muss das lokale Depot zunächst initialisiert werden. Das lokale Depot entsteht auf folgende Weise:
svk depotmap --init Repository /homne/haischt/.svk/local does not exist, create? (y/n)y ls ~/.svk/ cache config local
Im Gegensatz zu Git oder Subversion liegen Versionsinformationen nicht in der eigentlichen Arbeitskopie, sondern in einem Verzeichnis. Die Information zur Versionskontrolle bleibt also von den Dateien der Arbeitskopie getrennt.
Repositories spiegeln
Nach dem Anlegen des Depots kann der Entwickler ein neues Projekt hinzufügen. Es ist ebenfalls möglich, bereits bestehende Projekte aus einem zentralen Subversion-Repository zu spiegeln. Solche gespiegelten Projekte sind in Abbildung 1 als »trunk« und »branchX« dargestellt. Beide Projektversionen sind nach wie vor mit dem Subversion-Repository verbunden.
Der Unterschied zu dem in der Abbildung dargestellten Projekt »branchY« besteht darin, dass der »svk mirror«-Befehl »trunk« ins lokale Depot gespiegelt hat. Die davon abgeleitet Kopie »branchX« entstand mit dem Befehl »svk copy svn: //x/trunk //branchX«. Der »branchY«-Zweig ist dagegen das Ergebnis des Befehls »svk copy //trunk //branchY«.
Das führt dazu, dass diese Projektversion keine direkte Verbindung zun originären Subversion-Repository hat. Folglich wirkt sich ein »svk commit« auch nicht auf das eigentliche Subversion-Repository aus. Ein »commit« innerhalb von »branchX« jedoch sehr wohl. Natürlich ist es auch denkbar, die Kopie »branchX« direkt auf dem Subversion-Server zu erstellen, um diese anschließend zu spiegeln:
svk cp svn://x/trunk svn://x/branchX svk mirror svn://x/trunk //trunk svk mirror svn://x/branchX //branchX
Abbildung 1 zeigt außerdem die beiden Arbeitskopien »~/wcY« und »~/wcX«, die wie folgt erzeugt wurden:
svk co //branchX ~/wcX svk co //branchY ~/wcY
Bis zu diesem Zeitpunkt sind noch keine Dateien vom Subversion-Repository ins lokale Depot gewandert.
Synchronisation
Die bisherigen Befehle legen nur fest, was gespiegelt werden soll, der eigentlich Abgleich zwischen Subversion-Repository und lokalem Depot erfolgt über den Befehl »svk sync«:
svk mirror http://x/ // svk sync //
Die zuvor genannten Konstellation spiegelt ein komplettes Repository, da nur die Wurzel und kein spezieller Trunk oder Branch in der URL spezifiziert ist. Bestehen auf dem Subversion-Server sowohl »trunk« als auch »branchX«, werden diese beiden synchronisiert.
Natürlich lassen sich auch nur einzelne Branches spiegeln. Weil ein Repository sehr groß sein kann und zum Arbeiten an einem bestimmten Problem normalerweise nicht sämtliche Versionsstände erforderlich sind, ist ein Spiegel des kompletten Repositoriy in der Regel überflüssig.
Benötigt ein Programmierer zum Beispiel nur die neueste Version, so kann er dies folgendermaßen bewerkstelligen:
svk sync --skipto HEAD //
Abbildung 2 zeigt den Ablauf schematisch. In diesem Zusammenhang ist auch zu berücksichtigen, dass beim Synchronisieren eines großen Repository auf dem Server eine gewisse Last entsteht. Das ist vor allem dann der Fall, wenn mehrere Benutzer gleichzeitig ein Repository spiegeln. Es ist also angebracht, »svk mirror« überlegt einzusetzen.
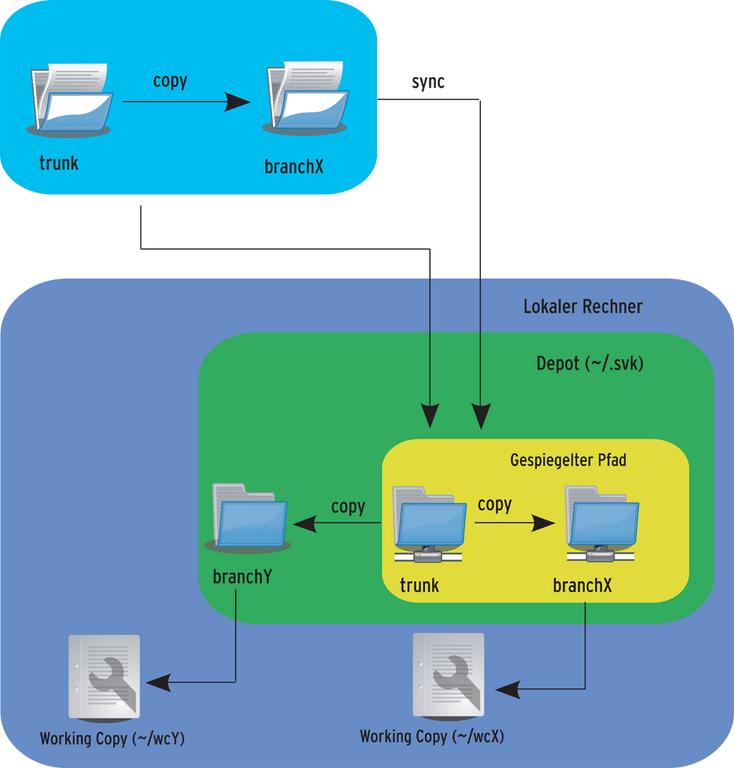
Abbildung 2: Das Synchronisieren befüllt ein anfänglich leeres Depot.
Erstes Arbeiten
Um letztlich mit den Dateien, die sich in einem lokalen Depot befinden, arbeiten zu können, muss der Entwickler auch diese entsprechend auschecken.
~$ svk co //x/ A x/trunk A x/trunk/httpd.conf A x/branches A x/branches/branchX A x/branches/branchX/httpd.conf A x/tags
Hier enthält die Arbeitskopie die Datei »httpd.conf«, an der der Entwickler nun etwas ändern möchte. Um sicherzugehen, dass sie im Subversion-Repository nicht verändert wurde, kann er das bei vorhandener Netzanbindung nochmals überprüfen (Listing 1).
|
Listing 1: Erster |
|---|
~$ svk update --sync Syncing file:///home/haischt/svnroot/x Syncing //x(/x/trunk) in /home/haischt/svk-artikel/x/trunk to 6. U httpd.conf $ echo "Listen 192.168.120.1" >> httpd.conf $ svk commit -m "Erster Commit" Commit into mirrored path: merging back directly. Merging back to mirror source file:///home/haischt/svnroot/x. Merge back committed as revision 6. Syncing file:///home/haischt/svnroot/x Retrieving log information from 6 to 6 Committed revision 7 from revision 6. |
Wichtig ist an dieser Stelle, dass der Befehl »update« ohne weiteres keinen Abgleich gegen das zentrale Subversion-Repository durchführt. Es sei denn, der Entwickler verwendet die Option »-s«. Andernfalls führt »update« nur einen Abgleich der Arbeitskopie mit dem lokalen Depot durch. Abbildung 3 zeigt diesen Zusammenhang. Ein weiterer Schritt soll nun eine zweite Datei mit dem Namen »httpd2.conf« anlegen und dann dem lokalen Depot hinzufügen, wie in Listing 2 zu sehen.
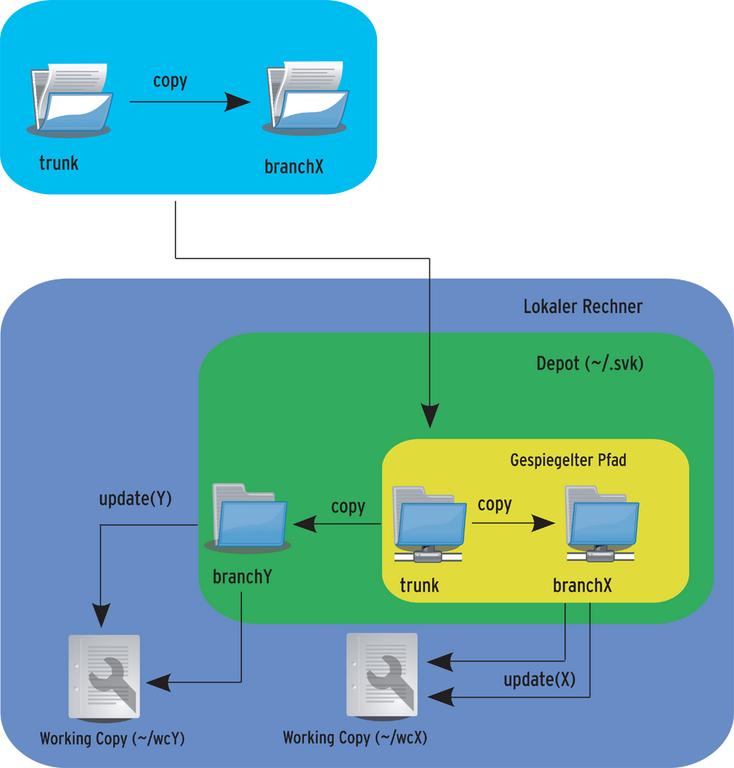
Abbildung 3: Ein SVK-Update führt in der Regel eine lokale Aktualisierung durch und lässt das zentrale Repository außer Acht.
|
Listing 2: Zweiter |
|---|
~$ echo "Listen 192.168.120.2" > httpd2.conf ~$ svk add httpd2.conf A httpd2.conf ~$ svk commit -m "Apache2 Konfigurationsdatei" Commit into mirrored path: merging back directly. Merging back to mirror source file:///home/haischt/svnroot/x. Merge back committed as revision 7. Syncing file:///home/haischt/svnroot/x Retrieving log information from 7 to 7 Committed revision 8 from revision 7. |
In allen beiden Beispielen ist deutlich zu erkennen, dass der Commit sich nicht darauf beschränkt, nur das lokale SVK-Depot abzugleichen, sondern zuerst das originäre Subversion-Repository. Da es sich bei dem lokalen Depot um ein gespiegeltes Subversion-Repository handelt, ist es wichtig, Änderungen der Arbeitskopie zuerst mit dem Subversion-Repository abzugleichen, um bei einem erfolgreichen Abgleich die Änderungen anschließend auch mit dem lokalen Depot zu synchronisieren.
Dieser Schritt, der sich über mehrere Transaktions-Einzelschritte erstreckt, ist in Abbildung 4 detailliert dargestellt. Aus der Illustration geht auch die Abfolge der einzelnen Transaktionsschritte »X1« und »X2« hervor. Von Bedeutung ist zudem, dass ein Commit innerhalb der Arbeitskopie »wcY« keinen Abgleich mit einem Subversion-Repository vornimmt, da es ja nicht gespiegelt ist.
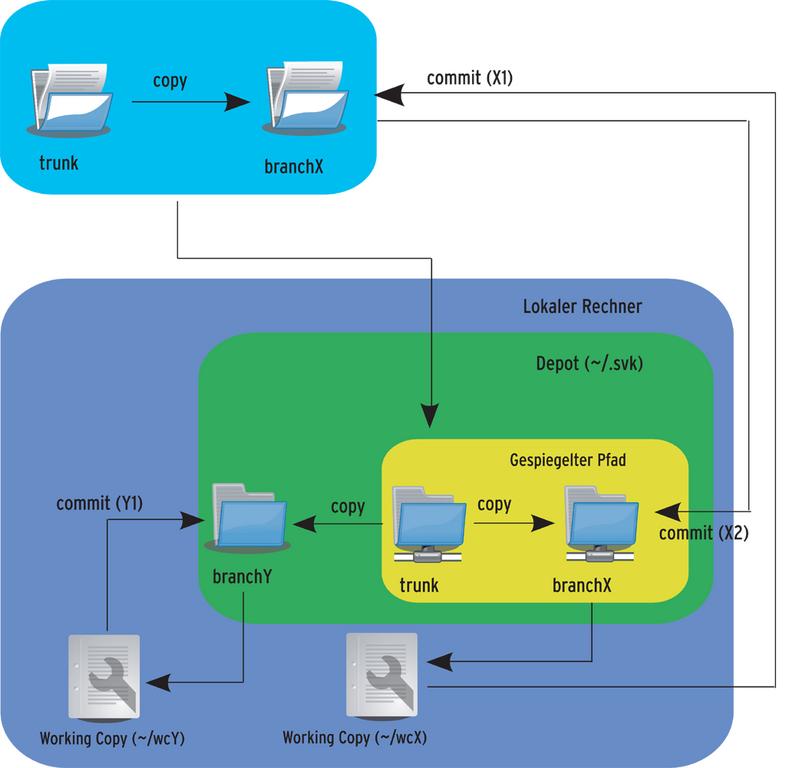
Abbildung 4: Ein Commit erfolgt bei einem SVK-Mirror in mehreren Transaktionsschritten. Der Commit besitzt dabei gegenüber dem Subversion-Server Vorrang.
Drei Wege
Die komplexeste und zugleich mächtigste SVK-Eigenschaft ist es, Änderungen aus verschiedenen Projektversionen in einem Drei-Wege-Merge (Star-Merge) zusammenzuführen. Angenommen ein Entwickler hat parallel zur Arbeitskopie »wcX« auch an der Arbeitskopie »wcY« gearbeitet, die ebenfalls eine Datei »httpd.conf« enthält. Beide Dateien will er nun miteinander vereinigen.
Abbildung 5 veranschaulicht, dass er sich dazu entschlossen hat, das lokale Projekt »branchY« mit dem gespiegelten Subversion-Projekt zu vereinigen. Wie die Abbildung ebenfalls zeigt, findet die Synchronisation mit dem eigentlichen Subversion-Repository im Schritt »commit (2)« statt. Erst der folgende Schritt »sync (3)« synchronisiert Subversion-Repository und lokales Depot.
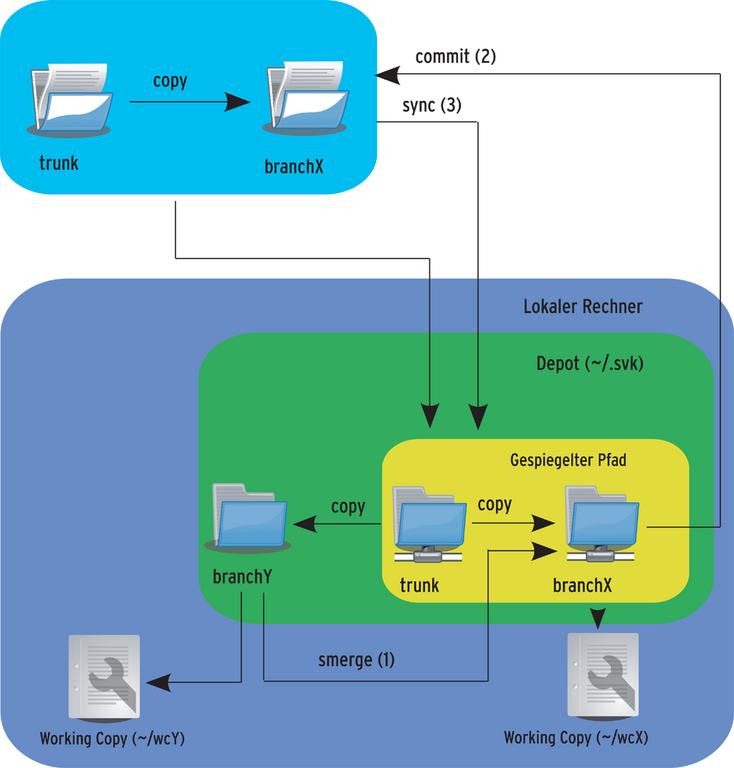
Abbildung 5: Durch eine Star-Merge wird »branchY« Teil des Subversion-Repository. Das erfordert einen lokalen Commit- und einen abschließenden Sync-Vorgang.
Listing 3 dokumentiert den eigentlichen Merge-Vorgang. Auffällig ist, dass es dabei zu Konflikten zwischen den verschiedenen Dateiversionen kommt (Zeilen 8 bis 12 und 22 bis 26). Wie bereits beschrieben, muss zwischen dem Subversion-Repository und dem lokalen Depot ein Quellcode-Abgleich erfolgen. Aus diesem Grund meldet SVK auch an zwei Stellen einen Konflikt. Listing 4 enthält die Datei »httpd.conf«, die ihn verursacht hat, mit den jeweiligen Versionsständen der Datei.
|
Listing 3: Ein |
|---|





