Ausgabe September 2005

Artikel
Freie Projekte legen Wert auf ihre Offenheit für neue Entwickler. Die Dokumentation spielt eine gernunterschätzte, oft aber entscheidende Rolle für die Motivation zur Mitarbeit.

Leafnode ist ein Usenet-Server für kleine Sites, wo wenige User eine große Zahl von Gruppen wünschen. Die Software ist so entworfen, dass sie Fehler selbstständig repariert und kaum Pflege benötigt.

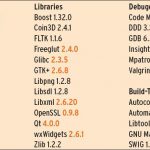
Musikprogrammen stehen unter Linux viele Möglichkeiten zur Ein- und Ausgabe zur Verfügung. Der Wildwuchs an Audiobibliotheken ist allerdings verwirrend. Das ist, wie häufig, historisch bedingt.

Heute ist es mir ein bisschen peinlich, aber ich bekenne es: In der Erinnerung der Leute, die mich damals kannten, und auch in der meinen war ich ein superbraves Kind. Kein Erwachsener musste mich von einer Fahrbahn vor einem herannahenden Auto retten, nie ging eine Scheibe durch einen von mir...

Diese Kolumne berichtet aus der Perspektive von GNU-Projekt und FSF über Projekte und aktuelle Geschehnisse aus dem Umfeld freier Software. In dieser Ausgabe dreht sich alles um Frauen in der Informationstechnologie und der freien Software sowie um Softwarepatente.

Die lange geplante europäische Richtlinie zur Patentierung so genannter computerimplementierter Erfindungen ist tot und sowohl ihre Befürworter als auch ihre Gegner scheinen zufrieden - vorerst.

Wollen mehrere Anwendungen gleichzeitig auf Audiohardware zugreifen, wird das unter Linux zum Problem. Die gängige Lösung ist ein Soundserver, der direkte Hardwarezugriffe kapselt. Jack ist ein Exemplar dieser Gattung, das alle Qualitäts- und Geschwindigkeitsansprüche befriedigt.

Wer mit Linux auf professionellem Niveau Musik machen will, muss zuerst für die nötige Infrastruktur sorgen. Dieser Artikel gibt Tipps zur Hardware-Auswahl und stellt die besten freien Soundprogramme vor.

Der Alsa-Standard hat das Open Sound System weitgehend verdrängt. Die Alsa-Module verhüllen eine Plugin-Schicht, die umfassende Konfigurationsmöglichkeiten bietet.

Kaum jemand denkt darüber nach, doch wer eine URL im Browser abschickt, setzt eine Maschinerie in Gang, an der sich in derselben Sekunde oft weltweit Rechner beteiligen - allein schon für die Übersetzung des Hostnamens in eine maschinenlesbare Adresse via DNS.

Der Desktop mit der Pfote findet auch hierzulande immer mehr Anhänger. Damit wächst die Bedeutung von Gnome als Entwicklungsplattform, deren GUI-Toolkit GTK sogar auf Windows und Mac läuft. Dieser Artikel verhilft zur Orientierung auf den verschlungenen Entwicklungswegen.

Tcl 8.5 steht kurz vor der Fertigstellung und bringt neben 50 Verbesserungen eine echte Überraschung mit: Die Basissprache erhält einen neuen Datentyp. Auch das eindrucksvolle Tile-Paket reift zusehends. Mit ihm nähert sich das Aussehen von Tk-GUIs dem anderer Widget-Bibliotheken.

Es ist ärgerlich, wegen eines kleinen Bugfix ein 50 MByte großes Paket neu herunterladen zu müssen. Abhilfe schafft der Delta-RPM-Mechanismus von Suse. Delta-RPMs enthalten neben einem vollständigen Header ein binäres Diff des Hauptinhalts. Seit neuestem stellen die Tools auch Deltas von...

Der noch junge Firefox will sich nicht nur mit seinen Brüdern Mozilla und Galeon messen, sondern auch gegen den KDE-Günstling Konqueror und den Edelpelz Opera antreten.

Red Hat zündet mit dem Directory Server auf einer Basis aus altem Netscape-Code einen Treibsatz in Richtung Enterprise-Markt. Auch das Fedora-Projekt bekommt in Sachen LDAP-Verzeichnisdienste gut Schub.
| LINUX-MAGAZIN KAUFEN | ||
|---|---|---|
| EINZELNE AUSGABE | Print-Ausgaben | Digitale Ausgaben |
| ABONNEMENTS | Print-Abos | Digitales Abo |
| TABLET & SMARTPHONE APPS |  Bald erhältlich |  Deutschland |