
© Valeriy Velikov / 123RF.com
Das Training von Sprachmodellen und KI-Algorithmen erfordert eine leistungsfähige, händisch nur mühsam zu erstellende Infrastruktur. Kubeflow verspricht Abhilfe, ist aber selbst ein komplexes Monstrum. Mit den richtigen Handgriffen bringen Sie es dennoch schnell an den Start.
Künstliche Intelligenz und Machine Learning sind seit einiger Zeit in aller Munde; Dienste wie ChatGPT haben daran entscheidenden Anteil. Langfristig wird AI aber nicht auf große Unternehmen im Silicon Valley beschränkt bleiben. Je zugänglicher die Technik ist, desto mehr Entwickler werden sich mit ihr befassen und sukzessive Algorithmen entwickeln, die in den Alltag der breiten Masse vordringen und das Leben erleichtern. Längst gibt es etwa Werkzeuge für die Konstruktion und das Training von KI-basierten Sprachmodellen. Sie stammen oft aus dem Open-Source-Umfeld, das im Hinblick auf künstliche Intelligenz aus seiner Nähe zu akademischen Zirkeln und der Wissenschaft Vorteil zieht. Ein großer Teil der heute verfügbaren Sprachmodelle nutzt quelloffene Skriptsprachen und Bibliotheken und steht selbst unter einer freien Lizenz.
Die Krux an der Sache ist aber, dass interessierte Entwickler, die sich mit KI und Sprachmodellen befassen möchten, zunächst einer Herausforderung gegenüber stehen, die mit dem eigentlichen Thema gar nichts zu tun hat: dem Bereitstellen der technischen Infrastruktur. Das ist im Kontext maschinengestützten Lernens nicht wenig. Faktisch verhält sich jedes KI-Modell wie ein komplettes Programm, zu dem noch Komponenten wie das Material hinzukommen, das das Modell für das Training benötigt. Längst haben sich in der KI-Community Methoden und Regeln dafür etabliert, wie man Modelle ordentlich entwickelt und anderen zur Verfügung stellt.
Die Verfahren ähneln denen der klassischen Softwareentwicklung: Continuous Development und Continuous Delivery spielen eine ebenso große Rolle wie APIs, die Modelle über standardisierte Wege zur Außenwelt hin exponieren. Das wiederum impliziert das Nutzen von Pipelines, also von definierten Abläufen, die eine Vielzahl von Arbeitsschritten enthalten und mit deren Hilfe sich ein Modell von der ersten Evolutionsstufe bis zur Vollendung entwickeln und trainieren lässt. Auch Git als Versionsverwaltung spielt eine ganz entscheidende Rolle. Wenn KI-Modelle in Programmform vorliegen, lassen sie sich auch wie andere Programme verwalten, bearbeiten, aktualisieren und letztlich ausführen. Viel Vorarbeit also für einen Entwickler, der eigentlich “nur” mit KI experimentieren und an ihr forschen möchte.
Die Open-Source-Community weiß wie üblich Rat. Gerade weil so viele Studierende ihren Fokus längst von den klassischen Programmierthemen hin zu modernen Aufgaben wie KI und Sprachmodellen verlegt haben, haben sich einige Menschen Gedanken über Umgebungen gemacht, die den Einstieg in die KI-Entwicklung erleichtern sollen. Jupyter ist dafür ein hervorragendes, wenn auch kommerzielles Beispiel, Lösungen wie Tensorflow (Abbildung 1) ebenso.
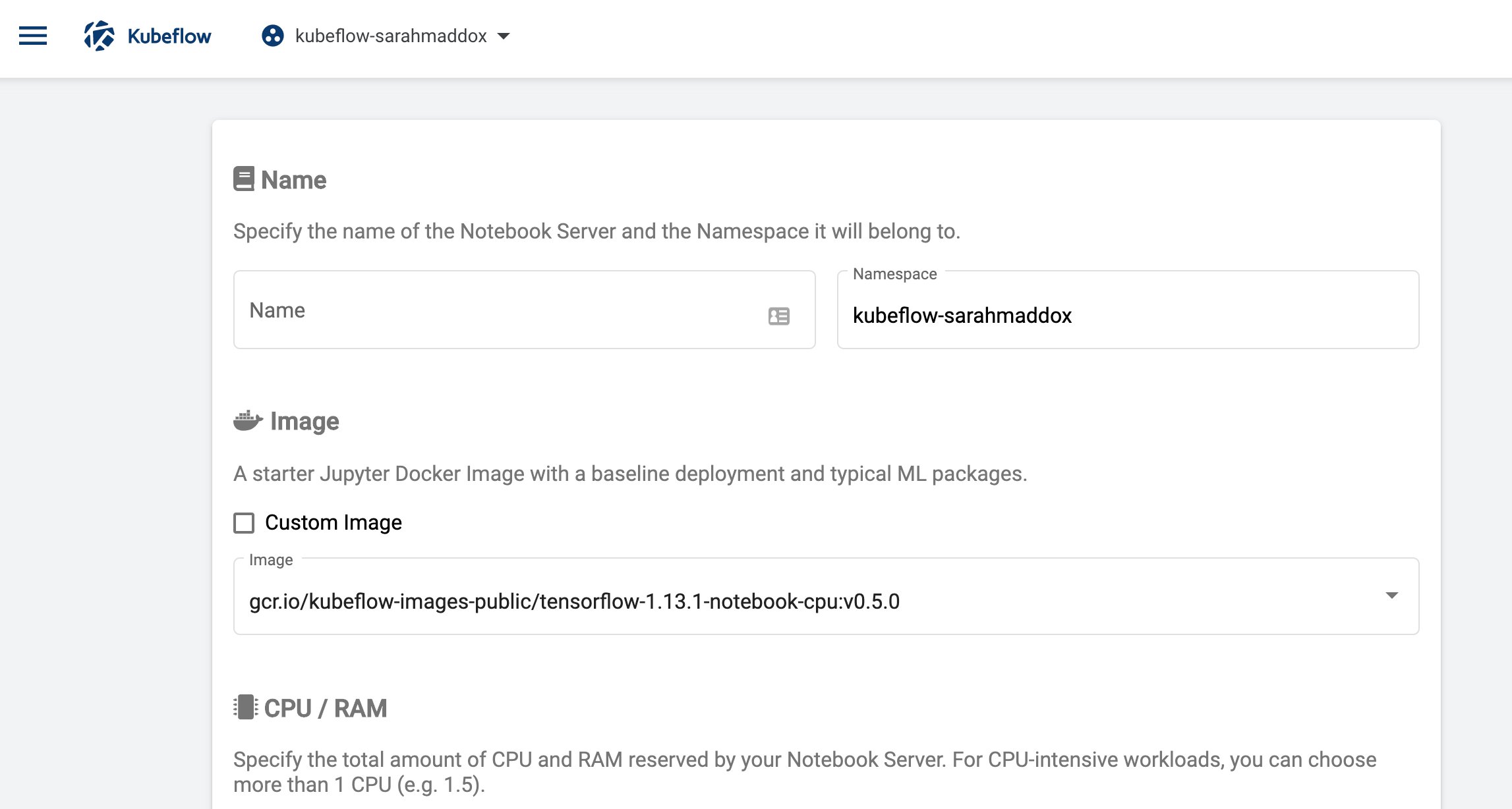
Abbildung 1: Die Notebook-Komponente von Kubeflow bietet nahtlose Integration in verschiedene KI-Frameworks, etwa Jupyter- und Tensorflow-Notebooks. Für Tensorflow implementiert Kubeflow zudem die TFServe-Funktionalität in einer eigenen Komponente. Quelle: Kubeflow
Auf dem noch immer aktuellen Hype rund um Linux-Container schwimmt zusätzlich Kubeflow [1] mit (Abbildung 2). Der Name verrät bereits, dass Kubeflow auf Kubernetes basiert, und das “flow” im Namen deutet zumindest darauf hin, dass es um die Bereitstellung von Arbeitsabläufen geht. Gerade aus KI-Sicht ist Kubeflow dabei ausgesprochen interessant, denn die Abläufe und Werkzeuge, die die Umgebung bereitstellt, beziehen sich praktisch ausnahmslos auf KI-Workloads und das Trainieren von Sprachmodellen.
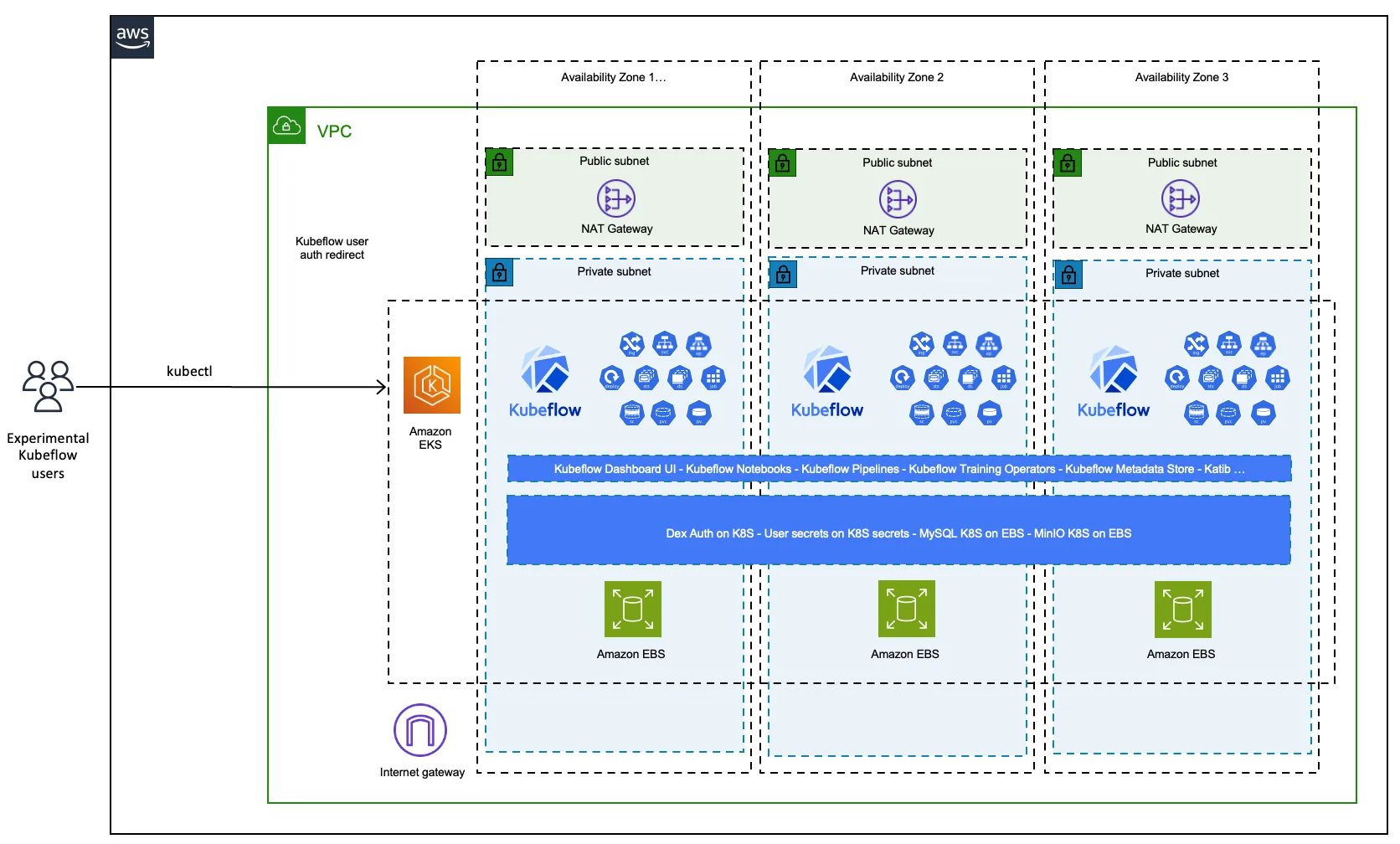
Abbildung 2: Kubeflow lässt sich in AWS EKS deutlich schneller an den Start bringen als auf einem lokalen K8s-Cluster. Dazu trägt bei, dass AWS viel Arbeit investiert hat, um dieses Setup vorzubereiten. Quelle: AWS
Die Idee ist simpel: In Form von Kubeflow sollen Entwickler alle Werkzeuge und Integrationen erhalten, um sofort mit der eigentlichen Arbeit an KI-Modellen zu beginnen, ohne sich zuvor mühsam um die dafür nötige Infrastruktur zu kümmern. Freilich hat die Sache einen Haken: Kubeflow ist äußerst umfangreich. Die Kubeflow Pipelines etwa, KFP abgekürzt, bestehen selbst ganz im Stile einer echten Mikroarchitekturanwendung aus etlichen Komponenten, die es in Kubernetes auszurollen gilt. Hinzu kommen neben klassischen Diensten wie Etcd und Istio zusätzliche Werkzeuge wie ein eigener DNS-Dienst oder eine Registry für Container-Abbilder.
Das Versprechen, die gesamte Bandbreite nötiger Werkzeuge für KI-Entwicklung anzubieten, führt zu weit über 70 Komponenten, aus denen Kubeflow besteht. Diese sind in der passenden Konfiguration sowie der korrekten und abgestimmten Reihenfolge auszurollen und zu betreiben. Nicht wenige Entwickler kommen sich deshalb etwas verschaukelt vor: Wer von Kubeflow gar keine Ahnung hat, braucht fast so viel Zeit, um sich darin einzuarbeiten, wie nötig wäre, um die notwendigen Komponenten selbst zur Verfügung zu stellen. Und dabei ist von Kubernetes selbst noch gar keine Rede. Jeder Administrator, der schon einmal K8s ausgerollt hat, weiß: Ein Selbstläufer ist das auf gar keinen Fall.
Die Hyperscaler helfen weiter
Tatsächlich stellt es sich als mühsames Unterfangen heraus, Kubernetes und Kubeflow im Gespann auf eigener Hardware zum Laufen zu bekommen. Das liegt auch daran, dass Kubeflow sich mittlerweile eher als eine Art Softwaresammlung versteht, die sich auf verschiedenste Arten und Weisen ausrollen und benutzen lässt, in ihrer Vanilla-Form aber beim Endanwender gar nicht zum Einsatz kommen soll.
Stattdessen setzt man auf Distributoren, die Kubeflow vorbereiten, die einzelnen Teile aufeinander abstimmen und dann ein fertiges Paket etwa über den Paketmanager Helm verteilen. Auf dem Markt existieren durchaus fertige Umsetzungen dieses Prinzips, darunter deployKF (Abbildung 3). Der Versuch, deployKF auf einem lokalen K8s-Cluster zum Laufen zu kriegen, zeigt aber schnell: Selbst wenn man Erfolg hat, ist man im Anschluss fertig mit der Welt.
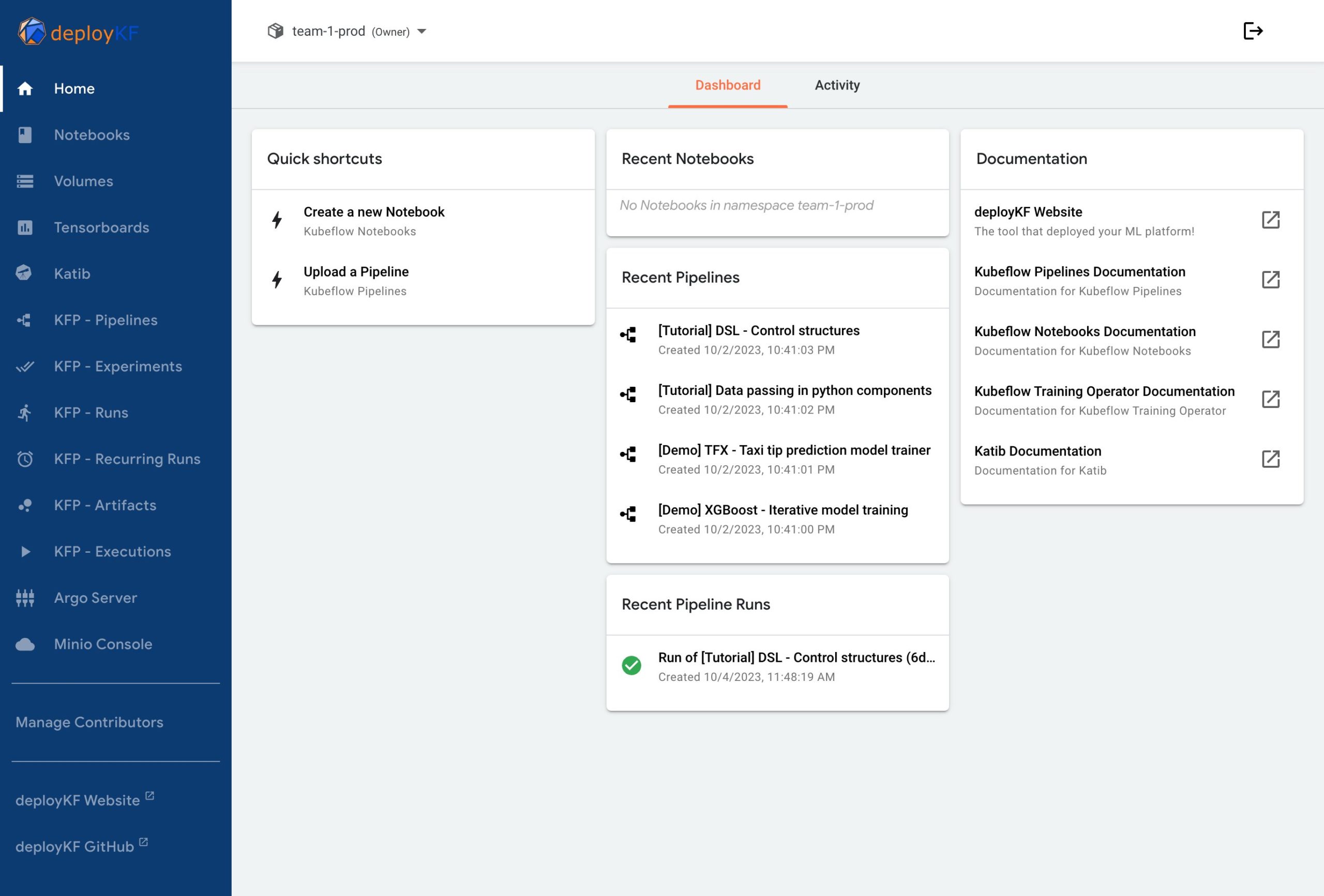
Abbildung 3: Kubeflow kommt in mehreren Distributionen daher, zum Beispiel in Form von deployKF für lokale Cluster. Wer einen schnellen Start braucht, kommt bei den Hyperscalern aber eher ans Ziel. Quelle: DeployKF
Da trifft es sich ganz gut, dass auch die Hyperscaler ein Auge auf Kubeflow geworfen haben und es tatkräftig unterstützen. Logisch: Azure, AWS und Google haben die nötige Hardware parat, führen fertige Distributionen von Kubernetes im Programm, die perfekt auf die eigene Plattform abgestimmt sind, und verfügen über genügend Manpower, um Kubeflow dafür vorzubereiten. So verwundert es nicht weiter, dass sich im Quelltext von Kubeflow etliche Commits von AWS, Azure und Google finden. Sie enthalten hier und dort Schräubchen, um Kubeflow auf der jeweiligen Plattform flott an den Start zu bekommen.
Wer mit Kubeflow noch gar nicht zu tun hatte, scheitert allerdings auch hier mit einiger Wahrscheinlichkeit. Denn während der Entwickler in diesem Fall zumindest vom größten Teil der Kubeflow-Komplexität verschont bleibt, kommt einige Arbeit hinzu, die sich aus dem Zusammenspiel von Kubeflow sowie der jeweiligen Plattform ergibt. Das umfasst beispielsweise die Benutzerverwaltung. Die bringt Kubeflow zwar mit, sie lässt sich dank einer Art Plugin-Prinzip jedoch auch gut durch IAM in AWS ersetzen. Man kann die Kubeflow-Nutzer dann unmittelbar über Amazon Cognito administrieren. Wer mit dem Dienstezirkus der jeweiligen Zielplattform nicht vertraut ist, verliert sich also schnell im Dickicht der Optionen und Möglichkeiten.
Obendrein bietet Kubeflow mehrere Ansatzpunkte, an denen sich anstelle der integrierten Lösungen externe Dienste anbinden lassen. Ab Werk nutzt Kubeflow beispielsweise MinIO als S3-artigen Speicher. Ein Deployment in AWS legt aber nahe, stattdessen das native AWS-S3 zu nutzen. Möglichkeiten über Möglichkeiten also. Der Entwickler, der eigentlich nur Kubeflow verwenden möchte, sieht am Ende den Wald vor lauter Bäumen nicht mehr.
Schluss damit: Dieser Artikel liefert im Folgenden eine Hands-on-Anleitung, um aus einem frisch angelegten AWS-Account heraus ein Kubeflow schnell an den Start zu bringen. Es nutzt wie bereits beschrieben Cognito für die Benutzerverwaltung, verzichtet darüber hinaus aber auf die Anbindung externer Komponenten wie S3. Stattdessen kommen die in Kubeflow ohnehin vorgesehenen Komponenten zum Einsatz.
Die obligatorische AWS-Warnung darf an dieser Stelle allerdings nicht fehlen: Wie beschrieben, produziert das Setup im fertigen Zustand auf AWS Kosten in Höhe von etwa 60 Euro – pro Tag. Der Preispunkt variiert je nach genutzter Region des AWS-Setups und der verwendeten Ressourcentypen. Wer hier beispielsweise in die Vollen geht und teure GPU-Instanzen für seine KI-Workloads nutzt, sprengt die 60 Euro pro Tag mit einiger Leichtigkeit.
Wer mit Kubeflow experimentieren möchte, kann das auf AWS gut tun, und auch produktiv lässt Kubeflow sich auf AWS perfekt betreiben. Es empfiehlt sich aber dringend, etwaige Teststellungen nicht sinnlos laufen zu lassen, eben weil das AWS-Taxameter mitläuft. Obendrein ist es dringend ratsam, über das AWS-Verrechnungswerkzeug Budgetgrenzen festzulegen, sodass zumindest eine Warnung per E-Mail kommt, wenn man bestimmte Beträge überschreitet.
Vorbereitungen
Bevor es mit Kubeflow auch nur losgehen kann, stehen einige Vorbereitungen in AWS an [2]. Wir gehen im Folgenden von einem nagelneuen AWS-Account mit freigeschalteter Zwei-Faktor-Authentifizierung und hinterlegtem Zahlungsmittel aus. Zwar lassen sich die kostenlosen Probekontingente bei AWS auch mit Kubeflow nutzen, bestimmte Dienste kann man dann aber ohne hinterlegte Kreditkarte nicht verwenden. Einige davon setzt Kubeflow allerdings voraus – keine Kreditkarte, kein Kubeflow also.
Haben Sie Ihren neuen AWS-Account wohnlich gestaltet, steht die erste echte Aufgabe auf dem Plan: Um später Zugriff auf die noch zu bauende Kubeflow-Instanz zu erhalten, muss diese aus dem Netz erreichbar sein. Die für das Kubeflow-Deployment auf AWS verfügbaren Deployment-Werkzeuge gehen davon aus, dass zu diesem Zweck eine eigene Domain in AWS Route 53 zur Verfügung steht, also in der AWS-eigenen DNS-Verwaltung mit integriertem Load Balancer. Nur so haben die Kubeflow-Setup-Werkzeuge später die Gelegenheit, einen virtuellen Load Balancer in AWS anzulegen, der dann auch eine öffentliche IP-Adresse bekommt und sich mittels definiertem Host-Namen erreichen lässt. Es genügt an dieser Stelle in der Theorie eine Subdomäne einer bestehenden Domain, die per DNS subdelegiert ist.
Weil gerade http://.cloud-Domänen recht günstig zu bekommen sind, hat es sich nach der Erfahrung des Autors aber als praktikabler herausgestellt, eine separate Domäne für die eigenen Kubeflow-Abenteuer zu delegieren und vollständig unter die AWS-Fittiche zu stellen. Kubeflow legt im Rahmen seiner Installation dann in Route 53 später eine Subdomäne dieser Domain an, über die sich der Load Balancer unmittelbar erreichen lässt. Wichtig: Haben Sie eine eigene Domäne für den Einsatz in Route 53 konfiguriert oder eine Subdomäne einer bestehenden Domäne entsprechend delegiert, benötigen Sie die ID der Domäne in Route 53. Die finden Sie heraus, indem Sie die gehostete Domain in Route 53 öffnen und auf Details zur gehosteten Zone klicken. Im Feld ID der gehosteten Zone findet sich die benötigte Information (Abbildung 4).
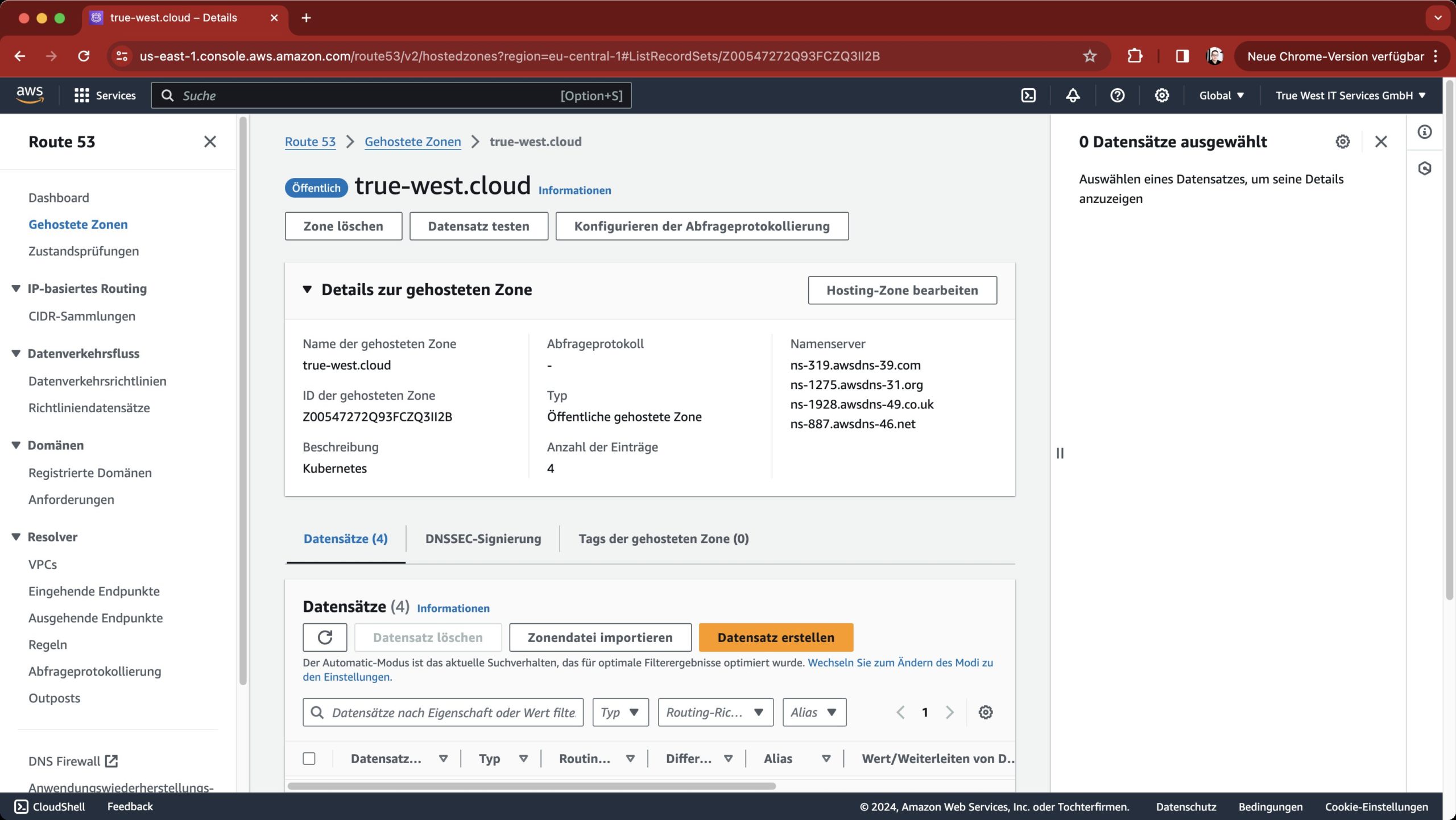
Abbildung 4: Damit das vorbereitete Cognito-Kubeflow-Setup auf EKS funktioniert, benötigen Sie die ID der Zone in Route 53, in deren subdelegierter Zone später der Eintrag für den Kubeflow-Load-Balancer stehen soll.
EKS starten
Weil Kubeflow auf Kubernetes basiert, ist ein funktionierender EKS-Cluster (Elastic Kubernetes Service) für Kubeflow auf AWS eine zwingende Voraussetzung. Hierzu empfiehlt sich die Verwendung des Kommandozeilenwerkzeugs »eksctl«, das unmittelbar mit der AWS-EKS-API kommuniziert und den benötigten Cluster in wenigen Minuten aus dem Boden stampft. Das folgende Beispiel geht davon aus, dass sämtliche Befehle auf einem Ubuntu 22.04 zur Anwendung kommen. Die meisten Anweisungen dürften sich jedoch, wenn auch mit kleinen Änderungen, auf andere Distributionen übertragen lassen. Um Eksctl unter Ubuntu zu verwenden, installieren Sie zuerst das entsprechende Binary direkt von Amazon mittels der Befehle aus Listing 1.
Listing 1
Installation von Eksctl und AWS
$ ARCH=amd64 $ PLATFORM=$(uname -s)_$ARCH $ curl -sLO "https://github.com/eksctl-io/eksctl/releases/latest/download/eksctl_$PLATFORM.tar.gz" $ curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" $ tar -xzf "eksctl_$PLATFORM.tar.gz" -C /tmp && rm "eksctl_$PLATFORM.tar.gz" $ unzip -u awscliv2.zip $ sudo mv /tmp/eksctl /usr/local/bin $ sudo ./aws/install
Der Aufruf von »eksctl –version« sollte im Anschluss bereits die Versionsinformation des Werkzeugs auf die Konsole bringen. Damit ist Eksctl grundsätzlich einsatzbereit. Noch fehlen ihm allerdings die Zugangsdaten, die es für den Zugang in AWS verwenden soll. Die hinterlegen Sie mittels »aws configure«. AWS fragt hier nach der Access Key ID sowie nach dem Secret Access Key, zwei Informationen, die sich unmittelbar in der Übersichtsseite Ihres AWS-Accounts finden. Je nach persönlicher Präferenz lassen sich für AWS hier auch eine Standardregion und ein Standardausgabeformat festlegen. Das ist aber nicht verpflichtend. Sind AWS und Eksctl startklar, geht es mit der Erstellung eines EKS-Clusters weiter. Das erledigen die Befehle aus Listing 2.
Listing 2
EKS-Cluster erstellen
export AWS_ACCOUNT=Access Key ID
export CLUSTER_REGION=eu-central-1
export CLUSTER_NAME=kubeflow-1
export PROFILE_NAME=kubeflow-user
export PROFILE_CONTROLLER_POLICY_NAME=kubeflow-user
eksctl create cluster \
--name ${CLUSTER_NAME} \
--version 1.25 \
--region ${CLUSTER_REGION} \
--nodegroup-name linux-nodes \
--node-type m5.xlarge \
--nodes 5 \
--nodes-min 5 \
--nodes-max 10 \
--managed \
--with-oidc
eksctl create iamserviceaccount \
--region ${CLUSTER_REGION} \
--name ebs-csi-controller-sa \
--namespace kube-system \
--cluster ${CLUSTER_NAME} \
--attach-policy-arn arn:aws:iam::aws:policy/service-role/AmazonEBSCSIDriverPolicy \
--approve \
--role-only \
--role-name AmazonEKS_EBS_CSI_DriverRole
eksctl create addon \
--name aws-ebs-csi-driver \
--cluster ${CLUSTER_NAME} \
--service-account-role-arn arn:aws:iam::$(aws sts get-caller-identity --query Account --output text):role/AmazonEKS_EBS_CSI_DriverRole \
--force
Einige Angaben im gezeigten Kommando sind variabel, Sie können oder müssen sie anpassen. Dazu gehört insbesondere der Wert für »AWS_ACCOUNT«, der festlegt, welchen der hinterlegten Sätze von Zugangsdaten Eksctl nutzt. Der Parameter für »–node-type« lässt sich ebenfalls verändern. Der klare Rat lautet hier allerdings, höchstens für Test-Cluster eine kleinere Instanzengröße zu wählen. Produktive Systeme hingegen sollten je nach Workload womöglich einen noch größeren Instanzentyp wählen, wobei auch hier ein wachsames Auge auf die Rechnungsbeträge in AWS nicht schadet.
Haben Sie diesen Arbeitsschritt erledigt, geht es mit dem Erstellen des Kubeflow-Clusters weiter. Dazu besorgen Sie sich zunächst aus dem Kubeflow-Git-Verzeichnis den Ordner mit den für AWS vorbereiteten Skripten und Integrationen (Listing 3, erste Zeile) und navigieren in einen Unterordner des frisch ausgecheckten Quelltexts (zweite Zeile). Hier liegt eine Datei von besonderem Interesse, »config.yaml«, die ab Werk jedoch weitgehend leer ist.
In dieser Datei passen Sie nun mehrere Werte an: »hostedZoneId« sowie »name« unterhalb des Elements »route53.rootDomain« sowie »cluster.name«, »cluster.region« und »name« unterhalb des Elements »cognitoUserpool«. Der letzte Wert ist variabel, es empfiehlt sich aber ein aussagekräftiger Name. Die Bezeichnungen hinter »cluster.name« und »cluster.region« jedoch müssen den Werten entsprechen, die Sie zuvor bereits beim Anlegen des EKS-Clusters verwendet haben. Schließlich verändern Sie auch den Wert von »name« unterhalb des Elements »route53.subDomain«. Er legt die Subdomäne fest, unterhalb derer später die Kubeflow-API zu erreichen ist. Es muss sich also um eine Subdomäne der in Route 53 hinterlegten Hauptdomäne handeln, beispielsweise »true-west.cloud« und »kubeflow.true-west.cloud«.
Zu guter Letzt springen Sie zwei Verzeichnisebenen höher und starten das Integrationsskript (Listing 3, Zeilen 4 und 5). Es legt in AWS Route 53 und AWS Cognito automatisiert Ressourcen an, die Kubeflow später benötigt, um sowohl einen funktionalen Load Balancer herzustellen als auch eine Integration mit AWS Cognito zu erzielen. Dabei legt das Skript auch die nötige Subdomäne in Route 53 automatisiert an und erweitert die zuvor händisch editierte Datei »config.yaml« so, dass sie die aktuell gültigen Werte enthält: Nach dem Schritt des Pre-Deployment gibt es später – der erfahrene Administrator ahnt es schon – auch einen Post-Deployment-Schritt.
Wohlgemerkt: Je nach Tageszeit und genutzter Instanzen in AWS kann sowohl das Anlegen des EKS-Clusters als auch das Abhandeln der nötigen Vorbereitungen 20 Minuten und länger dauern. Sofern die Werkzeuge nicht ausdrücklich eine Fehlermeldung anzeigen, müssen Sie sich jedoch keine Sorgen machen, AWS ist manchmal einfach etwas träge. Nach dem erfolgreichen Abschluss dieses Vorbereitungsschritts geht es mit dem eigentlichen Kubeflow-Deployment weiter.
Listing 3
Kubeflow vorbereiten und ausrollen
$ git clone https://github.com/awslabs/kubeflow-manifests/ $ cd kubeflow-manifests/tests/e2e/utils/cognito_bootstrap/[... config.yaml editieren ...] $ cd kubeflow-manifests/tests/e2e/ $ PYTHONPATH=.. python utils/cognito_bootstrap/cognito_pre_deployment.py[... Vorbereitungslauf ...] $ cd kubeflow-manifests/charts/apps/central-dashboard/templates/ConfigMap/[... centraldashboard-parameters-kubeflow-ConfigMap.yaml editieren ...] $ cd kubeflow-manifests/ $ make deploy-kubeflow INSTALLATION_OPTION=kustomize DEPLOYMENT_OPTION=cognito[... Kubeflow-Deployment ...] $ cd kubeflow-manifests/tests/e2e/ $ PYTHONPATH=.. python utils/cognito_bootstrap/cognito_post_deployment.py
Namespaces erstellen
Zuvor steht allerdings noch eine kleine Anpassung an. Das liegt an der Art und Weise, wie Kubeflow intern eine Form der Mandantenfähigkeit implementiert und wie die Integration in Cognito umgesetzt ist.
Kubeflow fußt unter der Haube auf dem Konzept von Namespaces. Der Begriff kommt manchem aus dem Kubernetes-Universum vermutlich bekannt vor, denn auch dort gibt es Namespaces. Ein Kubernetes-Namespace ist zwar stets auch Bestandteil eines Kubeflow-Namespaces. Der Kubeflow-Namespace umfasst jedoch zusätzlich eine Benutzerkonfiguration und einen Satz von Regeln, die dem frisch angelegten Cognito-Benutzer Zugriff auf einen Kubeflow-Namespace einräumen.
Kubeflow legt ab Werk für einen Benutzer einen Namespace an, falls der beim ersten Login noch keinen hat. Genau das ist in der Standardkonfiguration von Kubeflow aber deaktiviert. Nach dem Setup ohne Anpassung könnten Nutzer sich also in Kubeflow einloggen, darin aber nicht arbeiten. Um das zu ändern, wechseln Sie in das entsprechende Unterverzeichnis des Ordners »kubeflow-manifests/« (Listing 3, Zeile 7) und ändern dort in der Datei »centraldashboard-parameters-kubeflow-ConfigMap.yaml« den Wert von »CD_REGISTRATION_FLOW« auf »true«.
Dann folgt das eigentliche Kubeflow-Deployment (Zeile 9 und 10). Hier heißt es einmal mehr, sich zu gedulden: Weil über 70 verschiedene Dienste und weit über 100 Container heruntergeladen und gestartet werden müssen, dauert der Vorgang in der Regel 15 Minuten und mehr. Die Mühe lohnt sich allerdings: Anschließend ist Kubeflow grundsätzlich ausgerollt und bereit für den Einsatz. Nur darauf zugreifen können Sie noch nicht, denn es fehlen die Cognito-Konfiguration sowie der zugehörige Load Balancer.
Beide legen Sie im letzten Schritt des Prozesses an (Listing 3, Zeilen 12 und 13), der das Setup abschließt. Anschließend steht das Kubeflow-Dashboard unter der URL http://kubeflow.<I>Subdomäne<I> zum Login bereit, also beispielsweise unter https://kubeflow.k8s.true-west.cloud. Nun fehlt bloß noch der Benutzer in AWS Cognito, den Sie ganz regulär über das AWS-GUI erstellen.
Anders als bei einem handgestrickten Kubeflow etwa auf Grundlage von deployKF funktionieren bei der EKS-basierten Variante unmittelbar nach Abschluss des Setups alle Komponenten reibungslos. Pipelines lassen sich also ebenso anlegen und verwalten wie neue Notebooks oder Server-Anwendungen, um (trainierte) Modelle zu servieren und so der Außenwelt zur Verfügung zu stellen. Einige Beispiele für Pipelines sind in Kubeflow ab Werk sogar hinterlegt; sie lassen sich sofort nach dem erfolgreichen Deployment in EKS starten und benutzen.
Es würde den Rahmen dieses Artikels sprengen, genauer auf die Art und Weise einzugehen, wie Kubeflow funktioniert und wie sich darin Modelle erstellen und trainieren lassen. Dazu finden sich im Netz allerdings sowohl konkrete Beispielprojekte als auch umfassende Anleitungen.
Aufräumarbeiten
Um nach erfolgter Arbeit mit Kubeflow hinter sich aufzuräumen, müssen Sie nicht durch annähernd so viele Reifen springen wie für die Installation der Umgebung. Stattdessen genügen die wenigen in Listing 4 gezeigten Befehle.
Listing 4
Aufräumen
$ kubectl get svc --all-namespaces
$ kubectl delete svc Dienst
$ eksctl delete cluster --name ${CLUSTER_NAME}
Mit dem Kommando aus der ersten Zeile lassen Sie sich zunächst alle im jeweiligen Cluster hinterlegten Dienste anzeigen. Kubectl funktioniert nach dem Anlegen eines Clusters mittels Eksctl problemlos, denn Letzteres hinterlegt für jeden frisch angelegten Cluster die Zugangsdaten lokal und richtet die Umgebungsvariablen so ein, dass die richtigen Credentials zum Einsatz kommen.
Nicht benötigte Dienste löschen Sie wieder (Listing 4, zweite Zeile) und räumen zu guter Letzt per Eksctl den Cluster wieder ab (letzte Zeile), sofern er wie im Beispiel beschrieben aufgesetzt wurde. Gibt der Löschbefehl den Wert »0« zurück, ist der Cluster erfolgreich entfernt und nutzt auch keine Ressourcen mehr, die die Rechnung in die Höhe treiben (Abbildung 5).
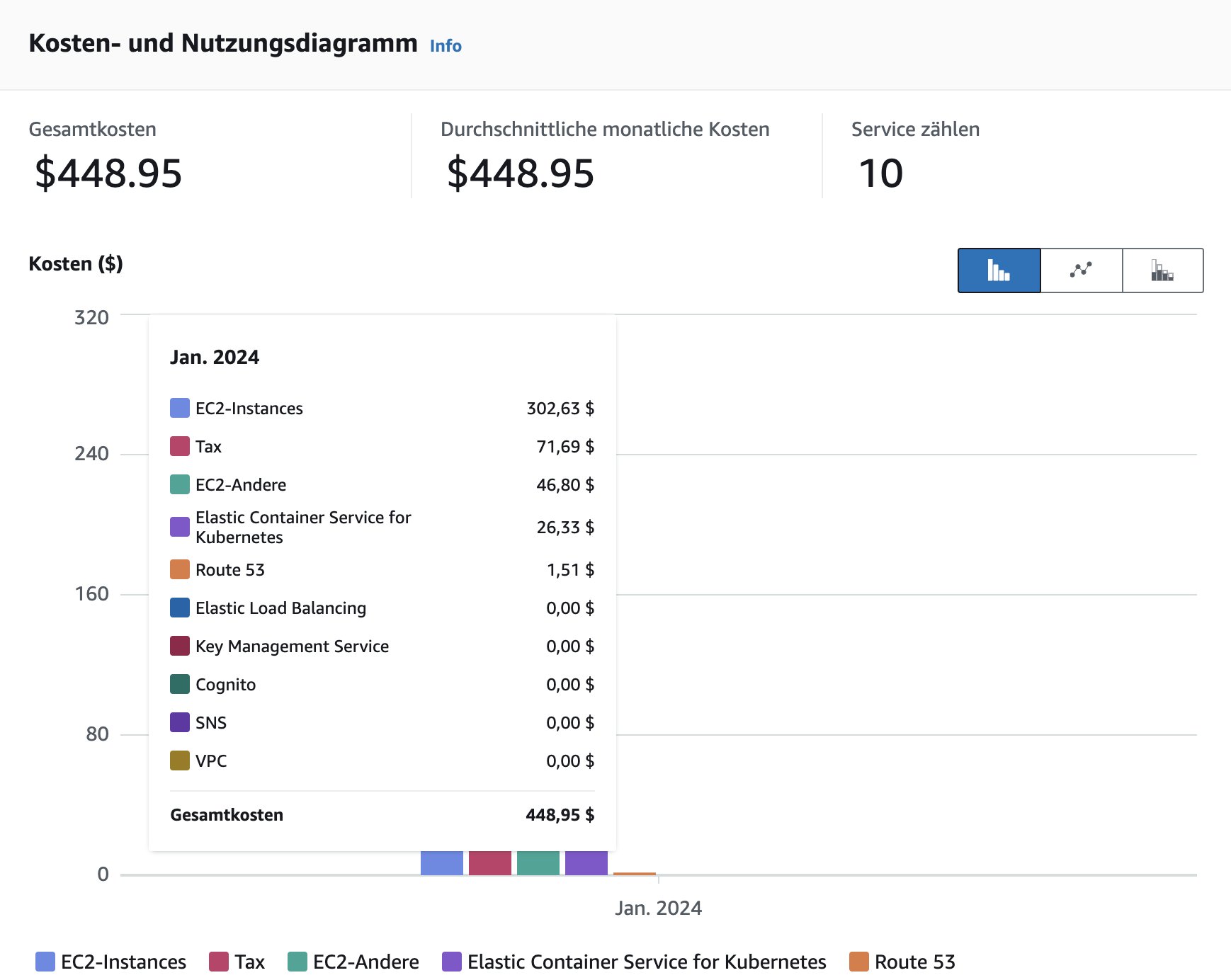
Abbildung 5: Beim Experimentieren mit Kubeflow auf EKS ist Vorsicht geboten: Wer eine Teststellung vergisst, produziert sehr schnell horrende Rechnungen.
Auf der Grundlage des beschriebenen Prozesses lässt sich eine Kubeflow-Installation später übrigens jederzeit wieder von null aus dem Boden stampfen. Wichtig ist lediglich, dass Sie vor dem Pre-Deployment-Schritt für Cognito dessen »config.yaml« so zurücksetzen, dass sie lediglich die nötigen Angaben für die zu nutzende Domäne enthält. Die Deployment-Werkzeuge verändern die Datei während des Setups mehrmals. Nach einem abgeschlossenen Kubeflow-Deployment lässt sie sich daher nicht mehr für einen anderen, neuen Cluster nutzen. (jcb/jlu)
Infos
- Kubeflow: https://www.kubeflow.org
- Kubeflow-AKS-Anleitung: https://awslabs.github.io/kubeflow-manifests/docs/deployment/cognito/





