
© Mirko Vitali / 123RF.com
Der vierte Teil unseres Ansible-Workshops widmet sich der Peripherie des Automatisierers: Welche Erweiterungen existieren, und wann setzt man sie ein? Welche Community-Lösungen unterstützen Ansible und wie lassen sich Fehler schnell finden? Welche Möglichkeiten gibt es, die Automation zu überwachen?
Ansible ist ein vielseitiges, flexibles und gleichzeitig verhältnismäßig einfach nutzbares Automatisierungswerkzeug. Die drei bisherigen Teile des Workshops zeigten, wie Ansible dem Administrator mit allerlei praktischen Funktionen hilfreich unter die Arme greift. Die vorige Folge verdeutlichte zugleich, dass auch komplexe Aufgaben für Ansible keine unlösbare Herausforderung sind, weil es sich durch eigene Module und entsprechenden Code erweitern lässt.
Nun wagen wir im Anschluss daran den Blick auf das große Ganze: Im Mittelpunkt steht dabei zwar noch immer Ansible, doch geht es eher um die Frage, mit welchen Erweiterungen sich seine Effizienz weiter steigern lässt. Immerhin sind die in der Community für Ansible existierenden Lösungen und Erweiterungen fast so vielfältig und umfangreich wie Ansible selbst. Obendrein stehen die Themen Debugging und Monitoring auf dem Plan: Wie sorgt der Administrator dafür, dass die Ansible-Automation reibungslos funktioniert, und wie kommt er Fehlern möglichst schnell auf die Schliche?
Teamwork ohne AWX
Sämtliche bisher beschriebenen Arbeitsschritte basierten auf der Kommandozeile. Die für Ansible benötigten Dateien – die Playbooks, die Inventardefinition sowie die genutzten Rollen – sind Textdateien, die sich als Parameter auf der Kommandozeile übergeben lassen. Zum Einsatz kamen obendrein nur Kommandozeilenwerkzeuge wie »ansible-playbook« oder »ansible-vault«. Das bietet für viele kleinere Teams mit flacher Hierarchie bereits genug Material, um effektiv zu arbeiten, und zwar auch als Gruppe über das Arbeitsfeld eines einzelnen Administrators hinweg.
Ein elementarer Vorteil ist dabei, dass sich Textdateien hervorragend in Git verwalten lassen, sodass man stets den gesamten Inhalt der Ansible-Integration eines Unternehmens an einer zentralen Stelle pflegen kann. Vielerorts hat es sich eingebürgert, tatsächlich das gesamte Ansible-Material in Git zu pflegen und die Admins mit lokalen Kopien arbeiten zu lassen. Nimmt ein Mitglied des Teams eine Änderung vor, integriert es sie sogleich wieder ins Git-Verzeichnis. Damit steht der aktualisierte Code nach einem »git pull« sämtlichen Mitgliedern des Teams zur Verfügung.
In größeren Unternehmen hat diese Lösung allerdings ein paar Nachteile. Einerseits ist es um die Integration dieses Ansatzes in Continuous Integration und Continuous Development (CI/CD) nicht sonderlich gut bestellt. Immer mehr Unternehmen wollen aber, dass Ansible ein integraler Bestandteil ihrer CI/CD-Toolchains wird, damit eine Änderung im Git-Verzeichnis etwa das automatische Bauen von Container-Abbildern anstößt oder dafür sorgt, dass sämtliche von einer Änderung betroffenen Systeme automatisch per »ansible-playbook« aktualisiert werden. Wer im beschriebenen Szenario solche Automatismen haben will, muss sich diese allerdings mühsam händisch zusammenzimmern. Jenkins und Gitlab können dabei ein effizientes Gespann sein, doch ist der Weg zu diesem Zustand beschwerlich. Das gilt umso mehr, als er eben nicht nur umfangreiches Ansible-Wissen voraussetzt, sondern sich ohne Zusatzwissen in Sachen Git und Jenkins auch nicht implementieren lässt.
Hinzu kommt, dass Hierarchien innerhalb von Teams in größeren Unternehmen oft nicht mehr flach sind. Stattdessen sehen die Admins sich mit dem Wunsch konfrontiert, die Rechte für Ansible fein abgestimmt zu verwalten. Bestimmte Personen sollen nur den Zustand der Ansible-Integration prüfen können, anderen sollen Änderungen im Ansible-Code möglich sein, und wieder andere sollen Ansible zwar ausführen dürfen, ohne aber die Ansible-Integration auf der Codeseite zu verändern. Das lässt sich nur mittels einer rollenbasierten Zugangskontrolle (RBAC) sauber implementieren. Die Basislösung mit Ansible auf der Kommandozeile bietet dafür aber nur wenige bis gar keine Möglichkeiten. Nötig wäre eine Kontrollinstanz, die Ansible selbst in der gewünschten Art verwaltet und aufruft, sobald ein berechtigter Benutzer das anstößt.
Neu ist das Problem nicht, und die Open-Source-Community hält in Form von AWX (Abbildung 1) eine von Red Hat gesponserte Lösung für das Problem vor. AWX gilt vielen Anwendern in der Ansible-Community als eine Art Phantom: Gehört hat man davon zwar schon einmal, womöglich auch unter dem alten Namen Ansible Tower. Relativ wenige Admins haben AWX aber in freier Wildbahn schon im Live-Einsatz erlebt, und noch weniger nutzen den Dienst im eigenen Setup.
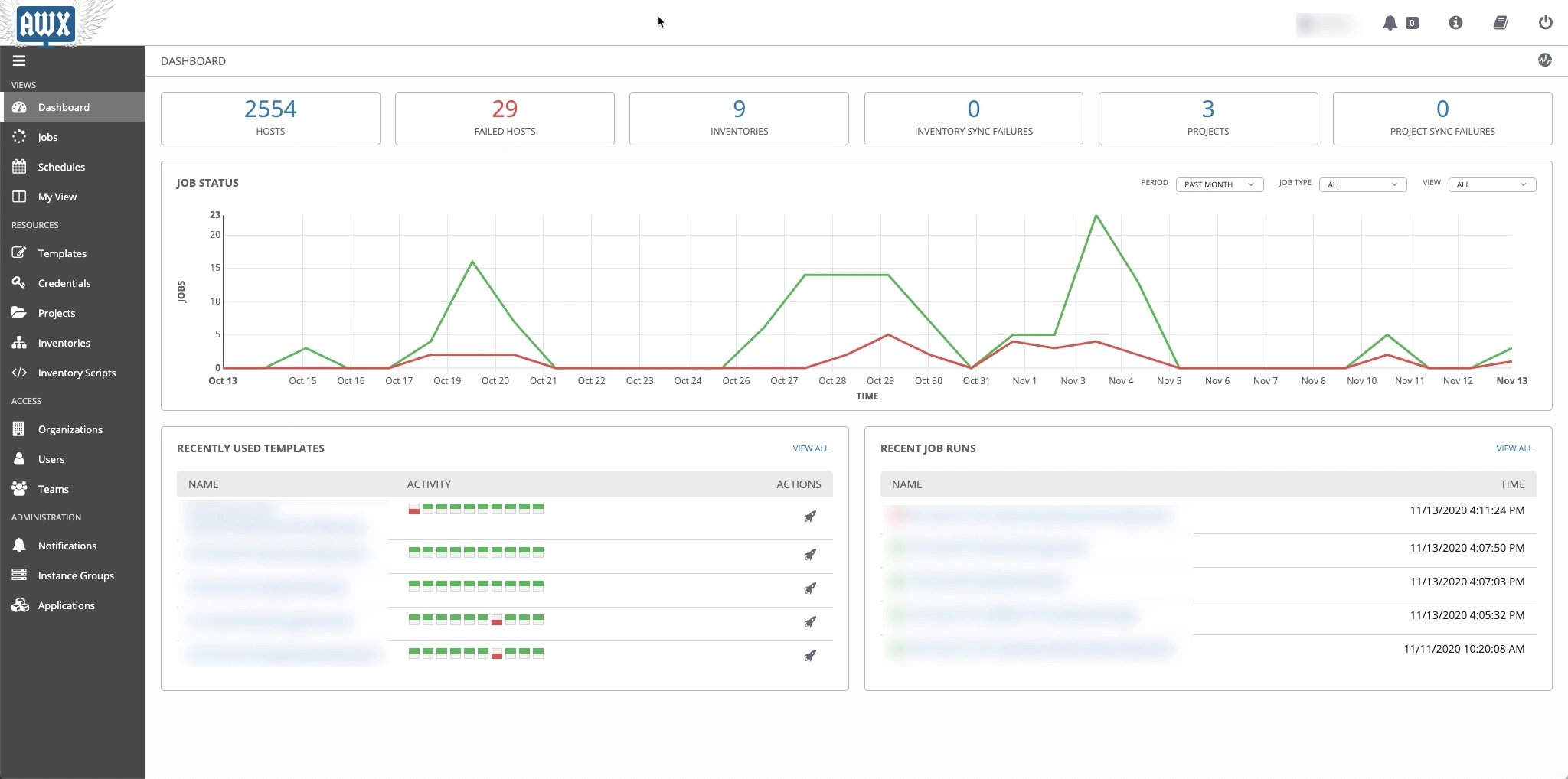
Abbildung 1: AWX ist eine nützliche Ergänzung für Unternehmen, die ihre Ansible-Tätigkeiten zentral bündeln und mit einem RBAC so wie einer grafischen Oberfläche versehen wollen. Quelle: Bryan Sullins
Sehr zu unrecht: AWX bietet neben dem beschriebenen RBAC nämlich noch zusätzliche Features für den Einsatz in CI/CD-Szenarien und viele weitere Funktionen, die in der Praxis großen Mehrwert bieten. Hinzu kommt, dass es sich bei AWX um ein Open-Source-Produkt handelt, das frei und kostenlos zur Verfügung steht. Dabei sollte man AWX nicht mit Red Hats Ansible Automation Platform verwechseln: Das ist ein kommerzielles Produkt der roten Hüte, dessen Kern AWX zwar bildet, das aber mehrere Zusatzkomponenten an Bord hat.
Was AWX ist
Seine Autoren beschreiben Ansible AWX als Werkzeug mit drei Hauptaufgaben. Von zentraler Bedeutung ist die Webschnittstelle, über die Admins Ansible-Befehle ausführen und deren Ablauf überwachen können. Hinzu kommt eine API-Schnittstelle nach dem ReST-Prinzip, über die sich Befehle von außen an AWX senden und Informationen zu bestehendem Ansible-Code in Maschinensprache einholen lassen. Schließlich hat AWX eine Task Engine im Gepäck: Sie werkelt im Hintergrund des GUIs und kümmert sich um das Ausführen von Befehlen, die zuvor etwa über die ReST-API bei AWX eingetrudelt sind. Garniert ist der Mix aus Software mit etlichen Funktionen wie einer eigenen Benutzerverwaltung mit Anschluss an Active Directory oder LDAP sowie einer rollenbasierten Rechtevergabe. Faktisch implementiert AWX also jene zusätzlichen Features, die den Einsatz von Ansible im Enterprise-Kontext deutlich erleichtern.
Zu AWX gehört jedoch noch mehr. So verfügt das Werkzeug über eine Execution Engine, mit deren Hilfe sich Ansible-Code zielgerichtet auf einzelnen Systemen ausführen lässt. Die API erlaubt es zudem, Ansible in CI/CD-Workflows zu integrieren. Dazu verbindet der Admin den Dienst zum Beispiel per Web-Hook aus Github oder Gitlab heraus mit dem Versionskontrollsystem und sorgt auf diese Weise dafür, dass Änderungen in Git automatisch eine Aktion in eben jener Execution Engine auslösen.
Steiniger Weg
AWX ist allerdings in der jüngeren Vergangenheit Red Hats Container-Manie zum Opfer gefallen. Das macht insbesondere das Deployment der Lösung heute schwieriger und komplexer, als es eigentlich sein müsste. Red Hat als Sponsor der Entwicklung gibt auch für AWX die klare Devise aus: Container first.
Zugegeben: AWX besteht aus mehreren Teilkomponenten, die man sinnvoll konfigurieren muss, damit der Dienst seine ideale Schlagkraft entfaltet. Das wäre aber mit den handelsüblichen Werkzeugen der Systemadministration durchaus zu erreichen, beispielsweise mit Ansible selbst. Stattdessen stellt Red Hat AWX nur noch in Container-Form zur Verfügung und merkt gleich an, dass das Deployment als Stand-alone-Installation nicht mehr als empfohlenes Szenario gilt. Stattdessen soll der Administrator lieber gleich zu Kubernetes greifen. Hierfür stellt AWX mittlerweile sogar einen eigenen AWX-Operator zur Verfügung, mit dem sich innerhalb eines Kubernetes-Clusters alle benötigten Dienste schnell an den Start bringen lassen.
Dass der Admin sich dafür aber erst einmal in Kubernetes einarbeiten muss, ist ebenso ein Hemmschuh wie die Tatsache, dass auch die nötige Hardware erst einmal vorhanden sein muss. Ein im produktiven Betrieb ausgerollter Kubernetes-Cluster benötigt immerhin drei Controller-Knoten und mindestens einen Compute-Knoten für die eigentlichen AWX-Dienste. Wer den Spuk nicht mitmachen möchte, kann AWX freilich dennoch nutzen. Dann ist aber sehr viel mühsame Handarbeit angesagt, garniert mit der Tatsache, dass ein vergleichbares Setup vermutlich woanders kaum läuft. Sämtliche Probleme, in die man bei diesem Unterfangen läuft, treten im eigenen Setup also möglicherweise zum ersten Mal auf und erfordern entsprechendes Debugging.
So oder so lohnt sich die Mühe allerdings: Wer alle Ansible-Aktivitäten unter dem Dach einer zentralen Lösung vereinen möchte, findet für dieses Vorhaben auf dem Markt aktuell kein besseres Werkzeug als AWX.
Community-Schätze
Um eine ganz andere Art von Drittanbietererweiterung geht es nun, nämlich um die Schätze in Sachen Ansible, die auf diesem Planeten existieren, die aber nirgendwo katalogisiert oder verzeichnet sind.
Ab Werk kommt Ansible bereits mit einer ordentlichen Anzahl von Funktionen daher. Die bleiben jedoch (wie in den bisherigen Folgen des Ansible-Workshops erläutert) ohne eine entsprechende Einbindung weitgehend nutzlos. Eine Funktion ohne ein Playbook, das sie direkt oder indirekt – etwa durch eine Rolle – aufruft, entfaltet in Ansible keinerlei Wirkung. Genau da liegt der Hase im Pfeffer: Wer einen speziellen Dienst aus der Open-Source-Welt mit Ansible automatisieren möchte, findet dazu in Ansible zwar das gesamte Werkzeug vor, adäquat einsetzen muss er es aber selbst.
An dieser Stelle biegen nicht wenige unerfahrene Ansible-Admins falsch ab und beginnen damit, Ansible-Rollen für Standarddienste der Open-Source-Szene zu verfassen. Zu akademischen Zwecken, etwa weil man das eigene Ansible-Wissen festigen und ausbauen möchte, ist das legitim. Ansonsten gibt es aber keinen triftigen Grund dafür, die zwanzigste Ansible-Rolle zu erstellen, die ISC-DHCP, Postfix, PowerDNS oder andere Dienste steuert.
Wie aber findet man heraus, welche Implementierungen schon existieren? Das Ansible-Projekt selbst liefert dafür einen Ansatz: Ansible Galaxy, eine Art Marktplatz für Ansible-Lösungen wie Rollen und Playbooks. Längst nicht jeder Autor von Ansible-Lösungen macht sich aber die Mühe, die eigenen Schöpfungen auf Galaxy hochzuladen und sie so dem Rest der Welt zur Verfügung zu stellen. Ein anderer Ansatz ist beliebter: Die meisten Entwickler von Ansible-Bausteinen laden diese als komplettes Git-Verzeichnis einfach in Github oder das firmeneigene Gitlab hoch.
Das ist für den Administrator allerdings nur bedingt eine gute Nachricht. Zwar lassen sich die etwaigen Module gut mit einer normalen Suchmaschine finden. Wer aktuell bei Google jedoch “postfix” und “ansible” eingibt, stolpert sogleich über etliche Implementierungen von verschiedenen Autoren. Dem ausführenden Administrator kommt dann die zweifelhafte Freude zu, die einzelnen Module zu bewerten und sich für das zu entscheiden, das er für das geeignetste hält.
Zumindest ein paar Erfahrungswerte helfen dabei, die Nieten rechtzeitig zu erkennen. Hat an einem Modul etwa seit Monaten oder gar Jahren niemand mehr gearbeitet, ist das kein gutes Zeichen. Falls es sich nicht um einen uralten Dienst wie ISC-DHCP handelt, bei dem sich quasi nichts mehr ändert, könnte der ursprüngliche Autor das Interesse an der Rolle verloren haben, sodass diese nun verwaist ist. Aufschlussreich kann auch ein Blick auf die Issues-Seite in Github für ein Modul sein. Gibt es hier Einträge über kolossale Funktionsmängel, auf die der Autor der Rolle über einen längeren Zeitraum nicht eingegangen ist, spricht auch das nicht gerade für erhöhtes Interesse an regelmäßiger Pflege des Codes.
Doch Vorsicht: Manchmal sind Suchergebnisse etwa auf Google verschiedene Links auf diverse Forks desselben Ursprungsquelltexts. Hier ist genaueres Hinsehen Pflicht: Manche Entwickler laden solche Forks wieder auf Github hoch, um die eigene Arbeit zu tracken, passen dabei den Quelltext aber eng an die Bedürfnisse des eigenen Unternehmens an. Genau das ist aus Sicht des Admins, der lediglich eine generische Implementierung benötigt, meist nicht hilfreich.
Das Augenmerk des Admins sollte bei jedem Fund im Netz zudem der Frage gelten, ob sich die jeweilige Lösung für die eigene Distribution eignet. Hier haben sich in den vergangenen Jahren mehrere Ansätze herausgebildet. Viele Entwickler entwerfen Ansible-Rollen nur für die Distribution, die sie selbst nutzen. Dann finden sich entsprechend Rollen, die nur auf Debian, Ubuntu, RHEL, Suse oder einer anderen Distribution überhaupt funktionieren. Andere Entwickler bauen All-in-Rollen: Die sind mit If- und When-Konstrukten gespickt und führen so auf der jeweiligen Distribution die benötigten Arbeitsschritte aus.
Ansible erleichtert dabei das Werken zum Teil massiv: Funktionen wie »package« aus dem Ansible-Kern tun im Hintergrund nämlich in Abhängigkeit der genutzten Distribution wie von Zauberhand das Richtige. Auf einem RHEL-basierten System rufen sie etwa »dnf« auf, auf einem Debian-System hingegen »apt«. Die schlechte Nachricht: Auch hier steckt der Teufel im Detail. Eine Distributionsweiche wird der Autor des entsprechenden Moduls nämlich trotzdem bauen müssen, schon weil die allermeisten Pakete in den verschiedenen Distributionen unterschiedliche Namen verwenden.
Debugging
Apropos Ansible-Erweiterungen: Nicht nur Rollen und Playbooks finden sich im Netz, sondern auch manches äußerst hilfreiche Modul. Wie in Teil 3 des Workshops gezeigt, haben Ansible-Module vor allem den Vorteil, dass sie Teil einer lokalen Ansible-Umgebung sein müssen. Um ihre Funktionen zu nutzen, muss man sie nicht systemweit ausrollen – was unter Umständen schon an fehlenden Berechtigungen auf dem Host scheitert, auf dem Ansible laufen soll. Noch besser: Verschiedene Eigenschaften wie die Ein- und Ausgabeoptionen von Ansible lassen sich über Module steuern und verändern.
Das erweist sich insbesondere beim Debugging als praktisch. Hier genießt Ansible wegen seines Standardausgabeformats nur einen bedingt guten Ruf: Läuft es auf einem der Zielsysteme in einen Fehler, zeigt es eine entsprechende Failed-Meldung an, führt die verbliebenen Arbeitsschritte auf den anderen Systemen aber erst einmal weiter aus. Ganz am Ende des Ansible-Laufs präsentiert Ansible dem Administrator dann schlimmstenfalls noch eine ellenlange Fehlermeldung, aus der schlau zu werden leichter gesagt als getan ist (Abbildung 2). Weil sich in einem solchen Fall aber je nach Länge der Fehlermeldung das gesamte Terminal in dunkles Rot hüllt, misst mancher Ansible-Enthusiast die Qualität seines Codes in Form von roten Zeilen, stets in der Hoffnung, davon möglichst wenige zu sehen. Anders herum gilt es in Kreisen von Ansible-Profis als verpönt, wenn Ansible überhaupt auf einem System mit einer entsprechenden Fehlermeldung aussteigt.

Abbildung 2: Die Standardausgabe von Ansible nimmt viel Platz auf dem Bildschirm für Weißraum in Anspruch. Das macht die Ausgabe schwieriger zu lesen und ihren Inhalt schwieriger zu interpretieren.
Dem weniger erfahrenen Ansible-Admin nützt das alles nicht viel. Er wird im Regelfall ein Interesse daran haben, die Ursache des Fehlers schnell zu identifizieren. Hier kommt ihm eine Ansible-Erweiterung zu Hilfe, die die Ausgabe des Werkzeugs nicht nur viel weniger umfangreich gestaltet und rafft, sondern auch sinnvoll interpretiert: der Compact Logger (Abbildung 3) für die Standardausgabe von Ansible.
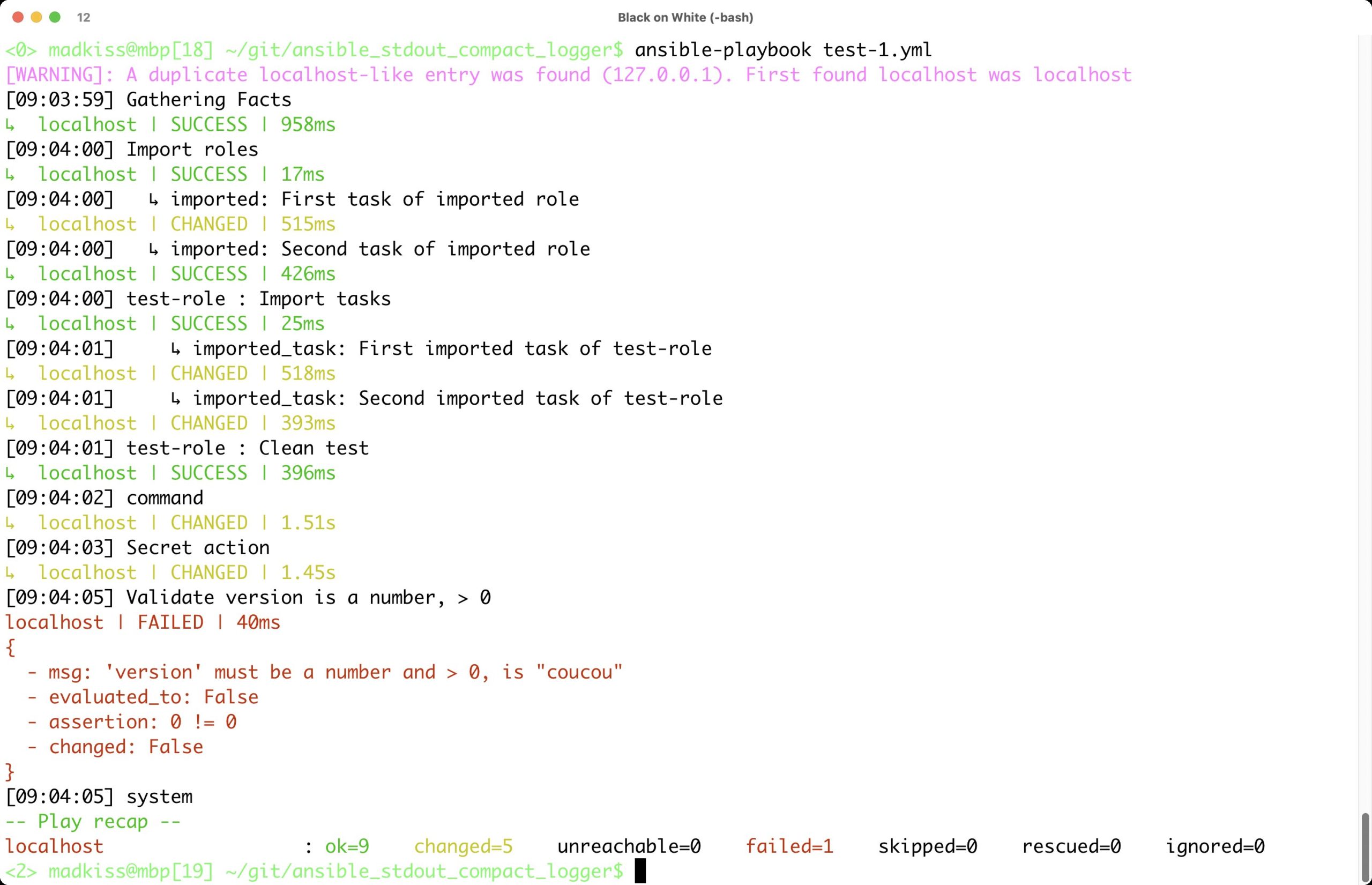
Abbildung 3: Der Compact Logger setzt dem verschwenderischen Umgang von Ansible mit Platz im Terminal ein Ende. Die Ausgabe ist dadurch weniger umfangreich und einfacher zu interpretieren.
Es erfordert etwas Handarbeit, das Plugin zum Laufen zu bekommen. Zunächst legt der Administrator in seinem Ansible-Verzeichnis den Ordner »callbacks/« an. Danach genügt eine lokale »ansible.cfg« wie die in Listing 1, den Compact Logger zu verwenden.
Listing 1
Compact Logger konfigurieren
[defaults] callback_plugins= ./callbacks inventory = hosts interpreter_python = /usr/bin/python3 stdout_callback = anstomlog # Silence retry_files_enabled = False
Der nächste Aufruf etwa von »ansible-playbook« mag den Administrator dann verwirren, wenn er bisher die Textflut des Werkzeugs gewohnt war: Nicht nur vermeidet der Compact Logger leere Zeilen, die Ansible selbst gern exzessiv nutzt. Es rafft zudem die Playbook-Meldungen derart, dass ein erfolgreich ausgeführter Arbeitsschritt auf allen Systemen nur noch eine Zeile insgesamt produziert statt eine Zeile pro abgearbeitetem System. Lediglich das Farbschema dürfte dem Administrator auch beim Compact Logger bekannt vorkommen, denn es ist das des Standard-Loggings in Ansible. Hier planen die Autoren des Compact-Logger-Plugins aber schon Verbesserungen, die hoffentlich bald auch in neuen Code münden. Insgesamt erleichtert der Compact Logger das Ansible-Debugging ganz erheblich, weil er die Fehlerausgabe einfach viel lesbarer macht.
Wer ein eigens gezimmertes Modul debuggt, steht manchmal vor dem Problem, dass er insbesondere bei großen Rollen gar nicht genau weiß, wo der Fehler nun eigentlich liegt. Mittels eines simplen Tricks lassen sich in Playbooks jedoch Marker einfügen, die auf der Kommandozeile den Ausführungsgrad einer Datei wiedergeben und ein Tracking Aufgabe für Aufgabe ermöglichen. Die dafür nötige Funktion »message« gehört zur Ansible-Grundbibliothek und liegt entsprechend auf jedem Ansible-System vor.
Fernab von möglichen Fehlfunktionen in Playbooks und Rollen kann es bei Ansible auch vorkommen, dass die benötigte SSH-Verbindung zu den Zielsystemen erst gar nicht zustande kommt. Das Problem dabei: Ansible zeigt in der Standardkonfiguration den Verbindungsaufbau per SSH nicht an. Im schlimmsten Fall sieht der Administrator also nur eine kryptische Fehlermeldung, aber nicht den eigentlichen Fehler, der diese produziert. Abhilft lässt sich schaffen, indem man dem Aufruf von »ansible-playbook« den Parameter »-vvvv« mitgibt. Dann zeigt das Werkzeug alle geleisteten Arbeitsschritte inklusive des Aufbaus der SSH-Verbindung an.
Der Task Debugger
Zusätzlich kommt Ansible mit dem sogenannten Task Debugger daher. Er soll den Admin vor dem typischen Teufelskreis aus Playbook-Aufruf – Fehler – Änderung – neuer Playbook-Aufruf schützen, indem er eine Art interaktives Debugging ermöglicht.
Der Task Debugger lässt sich auf den verschiedenen Ebenen eines Ansible-Aufrufs aktivieren, also für ganze Playbooks, Rollen oder nur für einzelne Tasks. Dazu genügt es, der jeweiligen Ressourcendefinition die Zeile »debugger: on_failed« hinzuzufügen. Sie sorgt dafür, dass Ansible selbst den Debugger bei fehlgeschlagenen Aufrufen aktiviert.
Für Ressourcen mit aktiviertem Task-Debugger (Abbildung 4) stehen im Anschluss sieben Kommandos innerhalb der Ressource zur Verfügung, von denen das wichtigste wohl »print« sein dürfte. Es zeigt im Fehlerfall detaillierte Informationen über den ausgeführten Task an. Mittels »task.args« und »task_vars« lassen sich während des Aufrufs die Inhalte von Modulargumenten oder Task-Variablen verändern, Letzteres im Gespann mit »update_task«. Die quasi selbsterklärenden Kommandos »continue« und »quit« fahren nach anderen Aktionen mit dem Ausführen des veränderten Tasks fort beziehungsweise deaktivieren den Debugger. Nähere Details samt Beispielen finden sich in der Ansible-Dokumentation [1].

Abbildung 4: Der Task Debugger in Ansible ermöglicht das interaktive Suchen von Fehlern ohne den ewigen Kreislauf aus Änderungen und Try and Fail. Er gibt unter anderem detaillierte Meldungen über Fehler aus.
Schließlich stehen viele Administratoren vor der Herausforderung, ihren Ansible-Workload zu überwachen. Die schlechte Nachricht gleich vorab: Ansible selbst bietet wenig bis gar keine Möglichkeiten, beispielsweise selbst produzierte Fehlermeldungen an einen Monitoring-Dienst zu exportieren. Wollte man entsprechende Funktionen haben, müsste man also eine Integration für die eigene Monitoring-Lösung bauen, die Ansible aufruft und entsprechende Fehlermeldungen abfängt. Sinnvoll oder effizient erscheint das aber kaum.
Einmal mehr kommt dem Administrator an dieser Stelle Ansible AWX zur Hilfe. Das fungiert ja im Grunde als Wrapper um Ansible, der aber eben auch eine native Schnittstelle für die Zeitreihendatenbank Prometheus im Gepäck hat. AWX lässt sich also als natives Scraping-Target unmittelbar aus Prometheus heraus abfragen – mit gutem Erfolg: AWX bietet etliche Metrikwerte über die ausgeführten Aufgaben und sich selbst an. Bei Bedarf lassen die sich zudem mit Grafana gut visualisieren (Abbildung 5).
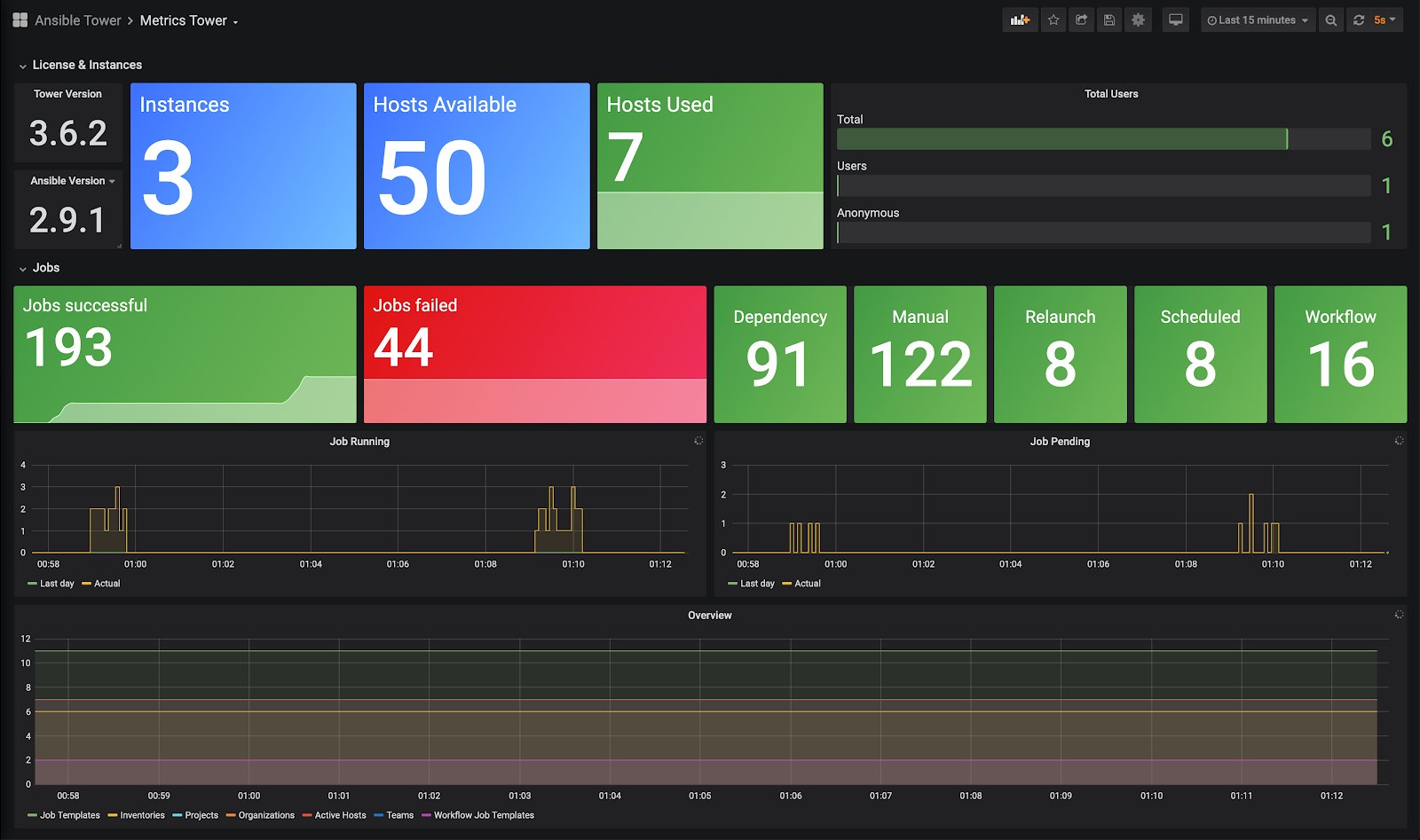
Abbildung 5: Während es nicht so trivial ist, Ansible selbst in ein Monitoring-System zu integrieren, bietet AWX für die Integration in die Zeitreihendatenbank Prometheus sogar eine native Schnittstelle. Quelle: Red Hat
Fazit
In den insgesamt vier Folgen dieses Workshops hat Ansible sich als vielseitiges, recht unkompliziertes und schnell zu erlernendes Automationswerkzeug präsentiert. Die einfache Nutz- und Erlernbarkeit des Programms führt dabei aber gerade nicht zu Abstrichen in Sachen Qualität oder Funktionsumfang: Mit Ansible lassen sich die meisten Aufgaben ebenso gut oder sogar besser erledigen als mit den deutlich älteren Lösungen Puppet oder Chef oder dem ebenfalls prominenten Mitbewerber Salt.
Als Kandidat für die Implementierung einer Automationslösung ist Ansible damit vor allem für jene Unternehmen interessant, die bis dato wenig oder gar keine Automation im Haus haben. Dank Ansible gelingt der schnelle Einstieg in das Thema inklusive schnell vorzeigbarer, produktiv nutzbarer Ergebnisse.
Dass Ansible bis heute als Open-Source-Werkzeug in der Open-Source-Community verankert ist, tut ein Übriges: Für die gängigen Programme dürften im Netz bereits fertige Implementierungen für Ansible existieren. Die Kunst, sie zu finden und dabei die Spreu vom Weizen zu trennen, ist dabei noch eine der komplizierteren Lernaufgaben im Kontext von Ansible. Nach der Lektüre des Ansible-Workshops im Linux-Magazin sind Administratoren aber auch für diese Aufgabe ideal gewappnet. (jcb/uba)
Infos
- Ansible Task Debugger: https://docs.ansible.com/ansible/latest/playbook_guide/playbooks_debugger.html





