
© besjunior / 123RF.com
Was macht Objektorientierung eigentlich aus, und was bringt sie im Vergleich zu altbackenen Sprachen, die einfach nur nacheinander verschiedene Funktionen abrufen? Mike Schilli erklärt die Unterschiede.
Die meisten Skripts oder Programme starten als einfache Hacks mit ein paar Variablen ins Leben. Erweist sich eine Applikation als nützlich, steigen oft die Ansprüche. Ein Feature hier, noch ein Feature da, und die Codebasis wächst. Dem kritischen Beobachter fällt dann auf, dass sich bestimmte Codeabschnitte wiederholen und sich besser als Funktionen zusammenfassen und kapseln lassen. Auch die Zahl der Variablen steigt, und wenn manche Funktionsaufrufe fünf oder zehn Parameter enthalten, wächst beim Experten das Verlangen, die Variablen in kleinen Gruppen als Strukturen zusammenzufassen, und sie platzsparend als Kombipakete herumzuschicken.
Der Wunsch, Funktionen fest an Datenstrukturen zu binden, ergibt sich auch ohne explizite Objektorientierung auf ganz natürliche Weise. Der in blankem C ohne OO-Unterstützung geschriebene Code des schon leicht angestaubten Webservers Apache zeigt zum Beispiel, dass dort viele Funktionen als erstes Element eine Datenstruktur erhalten, typischerweise als erweiterter Kontext. Sie besteht aus angesammelten Daten, auf die die Funktion nicht nur lesend zugreifen kann, sondern auch schreibend.
In Abbildung 1 bekommt zum Beispiel die Funktion »ap_get_useragent_host()« als ersten Parameter eine Request-Struktur. In der hat der Server die bis dato analysierten Daten aus dem eingehenden Request abgelegt, und die Utility-Funktion fieselt daraus den User-Agent des Clients heraus. Ähnliches gilt vielleicht für eine Funktion, die an anderer Stelle einen Teil einer Webantwort zusammenbaut – immer geht es darum, dass Funktionen auf strukturierten Daten herumorgeln.
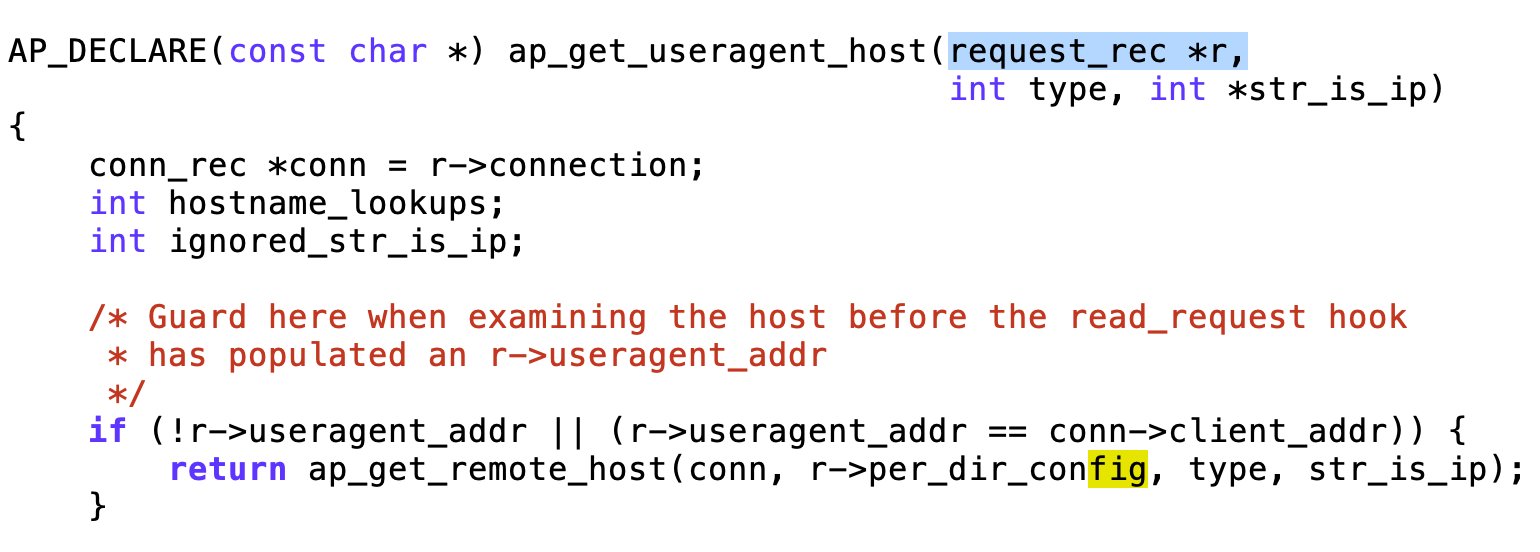
Abbildung 1: Selbst prozeduraler C-Code im Apache-Server arbeitet eigentlich auf so etwas wie Objekten.
Daten zum Mitreisen gesucht
Eine objektorientierte Sprache würde die mitreisende Datenstruktur als Objekt bezeichnen, und Funktionen, die lesend oder schreibend darauf zugreifen, als Methoden definieren. Ein Request-Objekt »req« im Server, das die bis dahin analysierten Parameter des eingehenden Web-Requests enthielte, böte vielleicht eine Methode »req.UserAgent()« an, die den User-Agent des anfordernden Clients als String lieferte. Im Ergebnis wäre es das gleiche Verfahren mit anderer Syntax.
Das Objekt »req« enthält also nicht nur eine geballte Ladung an Informationen, sondern versteht sich auch darauf, mittels Methoden die Bestandteile dieser Daten herauszufiltern oder zu manipulieren. Der ausführende Code kann nun das Objekt herumschicken, unter Umständen an eine weit entfernte Stelle irgendwo im Programm. Die kann, auch wenn sie nichts von den Innereien des Objekts versteht, dessen Methoden problemlos aufrufen.
Das ist der große Vorteil von Objektorientierung: Statt immer Datenstrukturen von Pontius zu Pilatus durchzuschleifen, verpackt ein Objekt sie unsichtbar hinter seiner Fassade. Eine unscheinbare Variable, die das Objekt enthält, bietet so eine Schnittstelle für Unbedarfte an. Die sieht so aus, als würde der Aufrufer dem Objekt mit dem Methodenaufruf eine Nachricht schicken und eine Antwort darauf erwarten. Dazu braucht er weder zu wissen, noch muss er sich darum scheren, wie die Methode diese Antwort intern im Detail zusammenbaut.
Eierkopf-Jargon
Das führt dazu, dass Objekte verschiedenster Bauart die gleichen Methoden verstehen und auf ihre Weise ausführen – etwa die »draw()«-Methode von 17 verschiedenen Widgets einer UI, die ihr Widget jeweils auf den Bildschirm zaubern. Polymorphie heißt das im Jargon der Eierköpfe: Verschiedenste Erscheinungen (also Objekte) bieten die gleiche Schnittstelle.
Die Skriptsprache Ruby arbeitet durch und durch objektorientiert. In Listing 1 nimmt die Funktion »greet()« ab Zeile 14 im Parameter »speaker« ein Objekt entgegen und ruft dessen interne Methode »hello()« auf. Dabei weiß die Funktion gar nicht, ob das Objekt nun Englisch oder Deutsch spricht. Die beiden Aufrufe in den Zeilen 18 und 19 mit einem englischen und deutschen Objekt zeigen, dass dennoch beides funktioniert und »greet()« automatisch die richtige Sprache spricht.
Wer sich übrigens wundert, dass eine durch und durch objektorientierte Sprache wie Ruby überhaupt eine Funktion unterstützt, dem sei versichert: Es handelt sich gar nicht um eine Funktion, sondern um eine Methode, die auf dem sogenannten Default-Objekt arbeitet.
Listing 1
hello.rb
#!/usr/bin/ruby german = Object.new english = Object.new def english.hello puts "Hello!" end def german.hello puts "Hallo!" end def greet(speaker) speaker.hello() end greet(english) # "Hello!" greet(german) # "Hallo!"
Klasse als Bauplan
Kurioserweise definiert Listing 1 die beiden Sprecherobjekte testweise einfach ad hoc, eingangs in den Zeilen 3 und 4. Welche Daten ein Objekt kapselt und welche Methoden es darauf anbietet, bestimmt aber normalerweise seine Klassendefinition. Nach diesem Bauplan montiert der Code anschließend ein oder mehrere gleichartige Objekte, aber jede dieser Instanzen führt ein Eigenleben. Gehen zehn Anfragen an den Webserver ein und arbeitet der sie gleichzeitig ab, jongliert er unter Umständen mit zehn Request- und zehn Response-Objekten.
Listing 2 definiert als Bauplan für Speaker-Objekte die Klasse »Speaker«. Die nach dieser Schablone später in den Zeilen 12 und 13 generierten Objekte »hans« und »franz« nehmen in ihrem Konstruktor »new()« ihren zukünftigen Namen jeweils als String entgegen. Gemäß den Ruby-Regeln durchläuft »new()« die ab Zeile 4 definierte Methode »initialize()«, die in »@name« eine Instanzvariable setzt. Der Wert gilt nur für die gerade erzeugte Objektinstanz, andere Objekte setzen ihn nach ihren eigenen Vorstellungen. Dementsprechend stellen sich Hans und Franz [1] in den Zeilen 15 und 16 unterschiedlich vor, obwohl beide dieselbe Methode »hello()« aufrufen.
Listing 2
class.rb
#!/usr/bin/ruby
class Speaker
def initialize(name)
@name = name
end
def hello
puts "Hello, I'm #{@name}."
end
end
hans = Speaker.new("Hans")
franz = Speaker.new("Franz")
hans.hello() # "Hello, I'm Hans."
franz.hello() # "Hello, I'm Franz."
Erben und erben lassen
Um den Bauplan einer Klasse zu erweitern, bieten objektorientierte Sprachen die Möglichkeit, Methoden von anderen, sogenannten Basisklassen zu erben. Das dient meist dazu, die ursprüngliche Klasse für Spezialaufgaben zu erweitern, etwa durch zusätzliche Methoden oder Datenelemente.
In Listing 3 erbt die Klasse »Speaker« in Zeile 15 von der Klasse »German«. Deshalb spricht sie Deutsch, denn »German« (ab Zeile 3) definiert ihre Methode »hello()« mit einem deutschen Satz. Würde »Speaker« in Zeile 9 hingegen von der Klasse »English« erben, spräche sie Englisch, denn Zeile 11 gibt einen englischen Satz aus.
Listing 3
inherit.rb
#!/usr/bin/ruby
class German
def hello
puts "Hallo, ich bin #{@name}."
end
end
class English
def hello
puts "Hello, I'm #{@name}."
end
end
class Speaker < German
def initialize(name)
@name = name
end
end
hans = Speaker.new("Hans")
franz = Speaker.new("Franz")
hans.hello() # "Hallo, ich bin Hans."
franz.hello() # "Hallo, ich bin Franz."
Findet Ruby eine Methode nicht in der Klassendefinition, verfolgt es die Vererbungshierarchie nach oben, bis es sie findet. Das kann auch über mehrere Stufen erfolgen, denn eine Klasse kann von einer Klasse erben, die wiederum von einer Klasse erbt, und so weiter. Eine Klasse kann jedoch nicht von zwei Elternklassen erben: Das wäre Multiple Inheritance, was die meisten Programmiersprachen verbieten, weil es zu Komplikationen bei der Auflösung von Methodenaufrufen führt.
In der Praxis kommt es aber oft vor, dass eine Klasse die Methoden mehrerer Klassen verwenden möchte. Das geht über sogenannte Mixins, bei denen eine Klasse lediglich die Methoden einer anderen Klasse einbindet, ohne weitere Vererbung wie das Hochsteigen in deren Basisklassen. Ruby bindet mit dem Schlüsselwort »module« gekennzeichnete Mixins mittels »include« ein.
Listing 4 definiert in Zeile 3 mit »module« einen Mixin namens »HelloGoodbye«. Er bietet die Methoden »hello()« und »goodbye()« an, die hallo und auf Wiedersehen sagen. Beide greifen auf die Instanzvariable »@name« zu, die die nutzende Klasse später setzt. Zeile 16 zieht den Mixin mit »include« herein, und weiter unten ab Zeile 22 dürfen die Objekte »hans« und »franz« die Methoden aufrufen. Heraus kommt tatsächlich der entsprechende Willkommens- oder Abschiedsgruß samt gesetztem Namen.
Listing 4
mixin.rb
#!/usr/bin/ruby
module HelloGoodbye
def hello
puts "Hello, I'm #{@name}."
end
def goodbye
puts "#{@name}, peace out!"
end
end
class Speaker
def initialize(name)
@name = name
end
include HelloGoodbye
end
hans = Speaker.new("Hans")
franz = Speaker.new("Franz")
hans.hello() # "Hello, I'm Hans."
hans.goodbye() # "Hans, peace out!"
franz.hello() # "Hello, I'm Franz."
franz.goodbye() # "Franz, peace out!"
Mixins kann eine Klasse in beliebiger Anzahl hereinziehen, im Gegensatz zur Vererbung, bei der jede Klasse jeweils nur eine direkte Basisklasse referenzieren darf. Programme nutzen solche Mixins, um Klassen mit Utility-Funktionen auszustatten, die eigentlich nicht mit der Klasse verwandt sind. Dabei geht es meist um Sonderausstattung wie etwa das Logging oder das Abarbeiten von Daten mittels eines Stacks oder einer Warteschlange. Man spricht hier von Aggregation oder Komposition, nicht mehr von Vererbung.
Interessanterweise bildet Ruby wirklich (fast) alles als Objekte ab: Sogar Strings oder Integer hören auf Methoden. So gibt »”abc”.upcase()« den String »ABC« zurück, und »2.+(2)« ergibt »4«, da die Plus-Methode mit dem Argument »2« zum Wert »2« den Wert »2« addiert, was nach Adam Riese »4« ergibt. Dass auch in Ruby »2 + 2« funktioniert, hängt einzig und allein an Rubys syntaktischem Zucker, der es erlaubt, sowohl den Punkt als auch die Klammern in »2.+(2)« wegzulassen [2].
OO in Go
Was macht nun eine Sprache wie Go, die explizit keine Objektorientierung unterstützt? Gerade in Gos Spezialdisziplin, der Systemprogrammierung, fallen ebenfalls Datenstrukturen an, auf die das Programm mit Funktionen zugreift. Daher haben sich die Go-Väter den Receiver-Mechanismus für Go-Funktionen ausgedacht.
Dazu definiert Listing 5 eine Struktur »Hello«, die unter dem Schlüssel »name« ein Feld mit dem Namen einer Person als String enthält. Das Hauptprogramm initialisiert jeweils eine solche Struktur in den Variablen »hans« und »franz« und ruft anschließend deren “Methode” »hello()« auf. Das ist allerdings nur syntaktischer Zucker der weiter unten in Zeile 19 definierten Funktion »hello()«. Deren Deklaration enthält zwischen dem Schlüsselwort »func« und dem Funktionsnamen in runden Klammern einen sogenannten Receiver. Das entpuppt sich in der Praxis übrigens als äußerst unglückliche Designidee: So kann man Funktionen im Editor nicht mehr via “func Name” suchen, weil im Code der Receiver dazwischensteht.
Im vorliegenden Fall handelt es sich um eine Struktur vom Typ »Hello«, die der Go-Code während des Aufrufs in den Zeilen 15 und 16 aus dem »main«-Programm mit den vorher initialisierten Strukturen besetzt und wegen der Receiver-Deklaration in Zeile 19 im Parameter »h« an die Funktion »hello()« übergibt. Fertig ist die Objektorientierung!
Listing 5
hello.go
package main
import (
"fmt"
)
type Hello struct {
name string
}
func main() {
hans := Hello{name: "Hans"}
franz := Hello{name: "Franz"}
hans.hello()
franz.hello()
}
func (h Hello) hello() {
fmt.Printf("Hello, I'm %s.\n", h.name)
}
So elegant und kompakt wie mit dem Konstruktor »new()« im Ruby-Code sieht das freilich nicht aus, aber Go-Programmierer behelfen sich mit einem Trick. Listing 6 zeigt, wie die zusätzliche Funktion »NewHello()« ab Zeile 19 einen Konstruktor implementiert. Wohlgemerkt, »NewHello()« erhält keinen Receiver, sondern es handelt sich um eine ganz normale Funktion, die eine initialisierte Datenstruktur vom Typ »Hello« zurückgibt.
Folgende Calls mittels »obj.hello()« rufen dann die ab Zeile 23 definierte Funktion »hello()« mit der Receiver-Variablen »obj« auf. Das Ergebnis ist dasselbe: Sowohl Listing 5 als auch Listing 6 geben »Hello, I’m Hans.« und »Hello, I’m Franz.« aus.
Listing 6
hello-const.go
package main
import (
"fmt"
)
type Hello struct {
name string
}
func main() {
hans := NewHello("Hans")
franz := NewHello("Franz")
hans.hello()
franz.hello()
}
func NewHello(name string) Hello {
return Hello{name: name}
}
func (h Hello) hello() {
fmt.Printf("Hello, I'm %s.\n", h.name)
}
Wie sieht nun Gos Ansatz zum Vererben von Daten und Funktionen aus, wie das objektorientierte Sprachen durch Vererbung von der Basisklasse zur abgeleiteten Klasse erlauben? Durch das sogenannte Struct Embedding darf der Go-Programmierer Teile einer bereits vorher definierten Struktur einschließlich der sie als Receiver nutzenden Funktionen in eine erweiterten Struktur übernehmen.
Listing 7 definiert zum Beispiel in der Struktur »HelloGerman« ab Zeile 11, dass es sich bei dieser einfach um eine Erweiterung der Struktur »Hello« aus Zeile 7 handelt. Letztere verfügt bereits über eine Funktion »hello()« (ab Zeile 21), die mittels des Receivers vom Typ »Hello« die dahintersteckende Person dazu bringt, sich auf Englisch vorzustellen.
Andererseits definiert die Funktion »hallo()« (die deutsche Version von »hello()«) ab Zeile 25 einen Receiver vom Typ »HelloGerman«, und ihr Code veranlasst die Person, sich auf Deutsch vorzustellen. Prompt kann das Hauptprogramm dann hintereinander »hans.hello()« und »hans.hallo()« aufrufen, und die Ausgabe ist wie erwartet: »Hello, I’m Hans.« und »Hallo, ich bin Hans.«
Listing 7
hello-german.go
package main
import (
"fmt"
)
type Hello struct {
name string
}
type HelloGerman struct {
Hello
}
func main() {
hans := HelloGerman{Hello: Hello{name: "Hans"}}
hans.hello() // "Hello, I'm Hans."
hans.hallo() // "Hallo, ich bin Hans."
}
func (h Hello) hello() {
fmt.Printf("Hello, I'm %s.\n", h.name)
}
func (h HelloGerman) hallo() {
fmt.Printf("Hallo, ich bin %s.\n", h.name)
}
Einen Schönheitsfehler hat die Syntax noch: Bei der Initialisierung der »HelloGerman«-Struktur in Zeile 16 kann Go nicht einfach auf das Feld »name« zugreifen, weil das ein Feld von »Hello« ist und nicht von »HelloGerman«. Also schreibt der Initialisierer »Hello: Hello{name: “Hans”}« und weist den Compiler damit an, das Feld »name« in der eingebetteten Struktur »Hello« zu initialisieren, nicht in der darumgewickelten Struktur »HelloGerman«.
Noch etwas gilt es zu beachten: Ein Konstruktor kann einen Pointer auf die initialisierte Struktur zurückgeben oder aber die Struktur selbst. Bei einer Monsterstruktur wie »http.Request« bietet sich ein Pointer an, bei einer Mini-Struktur eher nicht.
Ganz kritisch wird es beim Aufruf des Receivers: Nutzt die Receiver-Definition einen Pointer (»func (t* type) fu()«), dann kann die Funktion die Felder der Struktur dauerhaft verändern. Nutzt sie die Struktur selbst (»func (t type) fu()«), dann steigert sich der Programmierer unter Umständen in panikartige Zustände hinein, denn Veränderungen nimmt die Funktion dann an einer Kopie der Struktur vor und verwirft sie nach Ablauf der Methode kommentarlos.
Polymorphes Go
Gos strenge Typprüfung verbietet es eigentlich, einer Funktion eine Variable beliebigen Typs zu übergeben, auf dass diese auf gut Glück darauf eine Methode aufruft. Listing 8 zeigt aber, wie Funktionen im Namen des Polymorphismus trotz Gos strenger Typprüfung verschiedenste Parameter annehmen können.
Die Funktion »printNine()« ab Zeile 27 nimmt dazu entweder eine offene Datei, einen String-Reader oder die Antwort auf eine Webabfrage der Google-Homepage entgegen und schickt die ersten neun Bytes daraus auf die Standardausgabe. Alle drei Typen haben gemeinsam, dass sie die Funktion »Read()« implementieren, die von wo auch immer ankommende Bytes häppchenweise einliest und an den Aufrufer zurückgibt. Zeile 30 druckt die Ausgabe aus Datei, String und Webantwort testhalber mit »fmt.Printf« in die Standardausgabe (Listing 9).
Listing 8
reader.go
package main
import (
"fmt"
"net/http"
"os"
"strings"
)
func main() {
f, _ := os.Open("/usr/bin/fg")
defer f.Close()
printNine(f) // File type implements Read()
s := strings.NewReader("abc def")
printNine(s) // strings.Reader implements Read()
resp, _ := http.Get("https://google.com/")
defer resp.Body.Close()
printNine(resp.Body) // io.ReadCloser implements Read()
}
type Reader interface {
Read(p []byte) (n int, err error)
}
func printNine(r Reader) {
b := make([]byte, 9)
r.Read(b)
fmt.Printf("printNine: [%s]\n", string(b))
}
Listing 9
Druckausgabe
$ ./reader
printFive: [#!/bin/sh]
printFive: [abc def]
printFive: [<!doctype]
Dabei handelt es sich bei den Datenstrukturen um höchst unterschiedliche “Objekte”. Der String-Reader kann zum Beispiel mit »Len()« feststellen, wie lang der gesamte einzulesende String ausfällt, während der Reader der Webantwort diese Funktion nicht anbietet.
Der Trick an der Sache: Die Funktion »printNine()« nutzt keinen Parameter eines Datentyps als Aufrufparameter, sondern ein Interface. Ab Zeile 23 definiert Listing 7 ein Interface vom Typ »Reader«, das nur eine Funktion unterstützt, nämlich »Read()«. Die nimmt einen »[]byte«-Array-Slice entgegen, den sie mit Daten füllt, und gibt dann die Anzahl der im Slice zurückgegebenen Daten als Integer zurück sowie einen möglichen Fehlerwert vom Type »error«. Wie groß der Puffer »b« ist, weiß Go (und damit auch »Read()«) übrigens, also gibt es keinen Überlauf. Die maximale Anzahl eingelesener Bytes steht von vorneherein fest, ohne dass der Programmierer das festlegen müsste.
Dieses Reader-Interface nutzen verschiedenste Go-Funktionen aus der Standardbibliothek: Zeile 11 öffnet eine Datei auf der Festplatte, und der zurückkommende Datentyp liefert mit »Read()« schubweise Zeichen aus der Datei an. Zeile 15 setzt einen String-Reader auf, der Zeichen häppchenweise aus einem ihm übergebenen String liest. Zeile 18 setzt schließlich einen HTTP-Request ab, und dessen Antwort in »resp« speichert im Feld »Body« einen Reader, der auf Anfrage den Inhalt der eingeholten Webseite Stück für Stück ausspuckt.
Alle diese Datenquellen – ob Datei, String oder Datenstrom aus dem Internet – kann »printNine()« ab Zeile 27 anzapfen, dank der Interface-Definition. Pure Polymorphie, selbst bei strengster Typprüfung! So zeigt sich Go von seiner praktischen Seite. Volle Objektorientierung ist das freilich nicht, aber selbst komplexe Systeme wie GUIs mit Dutzenden von Widgets lassen sich damit problemlos und sauber programmieren. (uba/jlu)
Infos
- “Pumpin’ up with Hans & Franz – SNL”: https://youtu.be/7Mk1nykjnYA
- “The Well Grounded Rubyist”: https://www.manning.com/books/the-well-grounded-rubyist-third-edition?query=the%20well-grounded





