
© Icetray, Fotolia.com
Automation fängt nicht erst bei Ansible & Co. an: Red Hat liefert mit RHEL einen automatischen Installer aus, der keine Wünsche offen lässt. Wie RHEL und CentOS sich damit per PXE automatisch installieren lassen, zeigt dieser Artikel.
Automation, so könnte man meinen, ist heute das, was man im süddeutschen Sprachraum gern eine gemähte Wiese nennt: Umfangreiche Frameworks für Puppet, Chef, Ansible oder Salt finden sich in vielen Setups. Der größte Teil der Konfiguration erfolgt dort durch eben diese Automatisierer.
In etlichen Ansätzen für die Automation klafft indes ein dickes Loch. Was passiert, wenn ein System erst einmal installiert und per SSH erreichbar ist, das geben Ansible und Konsorten klar vor. Doch wie kommt ein Rechner in eben diesen Zustand? Mehrere Tool-Suites handeln das Thema Bare-Metal-Deployment in verschiedener Weise ab. Die Installation des Betriebssystems gehört dann zu einem großen Aufgabenpaket, das die jeweilige Software wie von Geisterhand abarbeitet.
Aber nicht jeder will sich den Overhead solcher Lösungen antun. Auf Komfort verzichten muss man deshalb aber noch lange nicht: Linux-Systeme lassen sich in aller Regel auch mit Bordmitteln automatisiert installieren, ganz ohne Framework oder komplexe Abstraktion. Dieser Artikel zeigt, wie sich Red Hat Enterprise Linux (und analog dazu CentOS) mit den normalen Werkzeugen einer Linux-Distribution per PXE-Boot automatisch installieren lassen. Dabei kommen alle Stationen des Deployments zur Sprache.
Die Ausgangssituation
Klar ist: Es erfordert so etwas wie eine manuell installierte Keimzelle, um andere Systeme automatisiert installieren zu können. Oft ist die Rede von “Bootstrap Nodes” oder “Cluster Workstations”. Im Wesentlichen geht es um die Infrastruktur, die eine automatische Installation von Red Hat oder CentOS grundsätzlich ermöglicht. Sie umfasst gar nicht so viele Dienste, wie man vielleicht erwarten würde. Wirklich notwendig sind lediglich eine funktionierende Namensauflösung, DHCP, TFTP sowie ein HTTP-Server, der die benötigten Dateien zur Verfügung stellt. Auf Wunsch kommt noch ein Chrony oder Ntpd dazu, damit die frisch ausgerollten Server die richtige Uhrzeit kennen.
Im Folgenden geht der Artikel davon aus, dass sämtliche Dienste für den Betrieb eines automatischen Installations-Frameworks auf einem System laufen. Im Idealfall ist das eine virtuelle Maschine, die aus Redundanzgründen auf einem Hochverfügbarkeitscluster läuft. Der lässt sich unter Linux leicht mit Bordmitteln über DRBD und Pacemaker realisieren. Beide Tools sind für CentOS verfügbar. DRBD [1] und Pacemaker [2] waren im Linux-Magazin bereits einige Male Thema, sodass dieser Teil des Setups hier außen vor bleibt – zwingend notwendig ist er ohnehin nicht. Wer damit leben kann, dass das Deployment der Maschinen nicht funktioniert, wenn die VM mit der dafür nötigen Infrastruktur einmal ausfällt, der braucht sich um das Thema HA an dieser Stelle keine Gedanken zu machen.
Die Grundlage für das System, das die Bootstrap-Dienste für neu zu installierende Server anbietet, bildet CentOS in der jeweils aktuellsten Version des 8er-Zweigs. Mit einem echten RHEL lassen sich die gezeigten Arbeiten aber ebenso erledigen.
Die Basisdienste installieren
Im ersten Schritt installiert der Admin ein CentOS 8 und richtet es nach seinen persönlichen Bedürfnissen ein. Dazu gehört unter anderem, einen SSH-Schlüssel für den persönlichen Nutzer zu hinterlegen und diesen in die Gruppe wheel des Systems aufzunehmen, sodass er Sudo benutzen darf. Obendrein sollte auf dem Infrastrukturknoten Ansible lauffähig sein. Zwar lässt sich das Betriebssystem des Bootstrap-Systems nicht automatisch installieren, doch es spricht nichts dagegen, auch auf diesem System selbst Ansible für das Ausrollen der wichtigsten Dienste zu nutzen, um Reproduzierbarkeit zu erreichen.
Gegeben sei also ein CentOS-8-System mit funktionierender Netzwerkkonfiguration, einem Anwender, der sich per SSH einloggen und Sudo verwenden kann, sowie Ansible, sodass sich der Befehl »ansible-playbook« ausführen lässt. Um Ansible benutzen zu können, erwartet das Tool eine bestimmte Struktur im lokalen Verzeichnis. Der Admin erstellt im nächsten Schritt daher im persönlichen Verzeichnis seines Nutzers zunächst einen Ordner namens »ansible/« und innerhalb dessen die Unterordner »roles/«, »group_vars/« sowie »host_vars/«.
Er erstellt per Editor zudem ein Inventory für Ansible. Dazu legt er die Datei »hosts« mit dem Inhalt aus Listing 1 an. Der gesamte Eintrag in der Datei muss in einer langen Zeile stehen. Ob das geklappt hat, überprüft der Admin mit dem Aufruf »ansible -i hosts infra -m ping«. Verkündet Ansible danach, dass die Verbindung geklappt hat, ist es ordentlich aufgesetzt.
Listing 1
hosts-Datei
[infra] Voller_Hostname_des_Ansible-Systems ansible_host=Primäre_IP_des_Systems ansible_user=Login-Name_des_Admin-Nutzers ansible_ssh_extra_args='-o StrictHostKeyChecking=no'
DHCP und TFTP konfigurieren
Die nächsten Schritte bestehen für den Admin darin, die benötigten Dienste auf der Infrastruktur-VM zum Laufen zu bringen. DHCP, TFTP sowie Nginx genügen, um anfragenden Clients sämtliche benötigten Dateien zu servieren.
Freilich gibt es für CentOS und RHEL-basierte Systeme fertige Ansible-Rollen, die DHCP sowie TFTP aufsetzen. Dieser Artikel verwendet beide Rollen des niederländischen Entwicklers Bert van Vreckem, denn sie funktionieren gut und lassen sich mit geringem Aufwand an den Start bringen (Abbildung 1). In den Unterordner »roles/« checkt der Admin dazu per Git (das er gegebenenfalls per »dnf -y install git« zuvor installiert) die beiden Ansible-Module aus (Listing 2).
Abbildung 1: Automation hilft – auch beim Setup des Infrastrukturknotens. Denn der ist per Ansible dank fertiger Rollen aus dem Netz schnell aufgesetzt.
Listing 2
Ansible-Module auschecken
VM> cd roles VM> git clone https://github.com/bertvv/ansible-role-tftp bertvv.tftp VM> git clone https://github.com/bertvv/ansible-role-dhcp bertvv.dhcp
In der Datei »host_vars/-Hostname_des_Infrastruktursystems.yml« hinterlegt der Admin anschließend die Konfiguration des DHCP-Servers, wie sie Listing 3 exemplarisch darstellt. Wichtig ist, dass der Hostname exakt stimmt. Lautet der komplette Hostname des Systems »infrastructure.cloud.internal«, muss der Name der Datei »infrastructure.cloud.internal.yml« sein. Daneben gilt es, die Werte des in der Datei konfigurierten Subnets, die globale Adresse des Broadcasts sowie die Adresse des PXE-Boot-Servers an die lokalen Begebenheiten zu adaptieren.
Listing 3
Konfiguration der Host-Variablen
dhcp_global_domain_name: cloud.internal
dhcp_global_broadcast_address: 10.42.0.255
dhcp_subnets:
- ip: 10.42.0.0
netmask: 255.255.255.0
domain_name_servers:
- 10.42.0.10
- 10.42.0.11
range_begin: 10.42.0.200
range_end: 10.42.0.254
ntp_servers:
- 10.42.0.10
- 10.42.0.11
dhcp_pxeboot_server: 10.42.0.12
Das Subnet muss ein Teilbereich des Subnets sein, in dem sich die VM mit den Infrastrukturdiensten selbst befindet. Der Admin muss bei der Konfiguration des Rangs jedoch darauf achten, dass Adressen, die der DHCP-Server an anfragende Clients vergibt, nicht mit solchen IPs kollidieren, die lokal bereits in Verwendung stehen. Wichtig ist außerdem, dass der Wert von »dhcp_pxeboot_server« die IP-Adresse der Infrastruktur-VM wiedergibt, denn sonst klappt später der Download der nötigen Dateien per TFTP nicht (Abbildung 2).
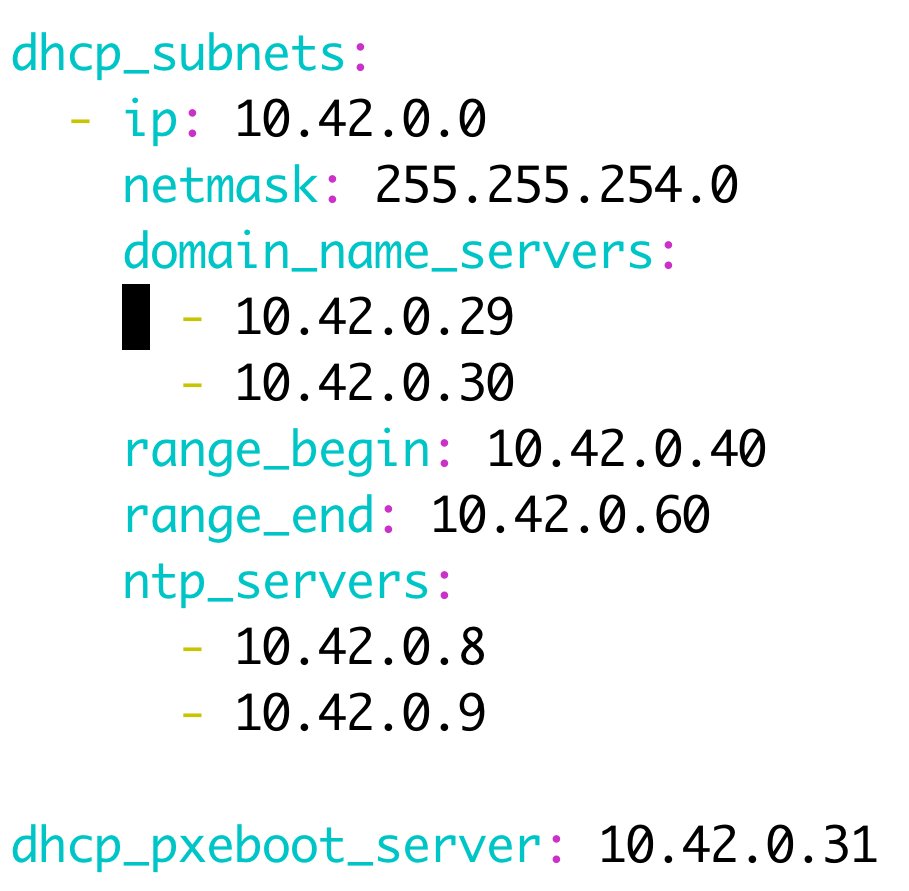
Abbildung 2: Damit die DHCP-Rolle von Bert van Vreckem weiß, wie sie den Dhcpd aufsetzen soll, definiert der Admin die Konfiguration in den Host-Variablen des Servers mit den Infrastrukturdiensten.
Deutlich weniger anspruchsvoll als DHCP ist im Hinblick auf seine Konfiguration TFTP. Das Modul von van Vreckem kommt mit für CentOS sinnvoll gewählten Defaults daher und richtet den TFTP-Server so ein, dass dessen Wurzelverzeichnis anschließend in »/var/lib/tftpboot/« liegt, was dem gängigen Linux-Standard entspricht.
Sobald beide Rollen lokal vorhanden sind und der Admin für DHCP eine Konfiguration in den Host-Variablen hinterlegt hat, legt er ein Ansible-Playbook an, das für den Infrastruktur-Host beide Rollen aufruft. Im Beispiel sieht das Playbook aus, wie im Listing 4 gezeigt. Grundsätzlich gilt: Für die Playbooks, die in diesem Artikel noch hinzukommen, erweitert der Admin die Einträge bei »roles« jeweils um eine neue Zeile mit dem entsprechenden Wert. Der Name der Rolle entspricht dem Namen des Ordners im Verzeichnis »roles/« (Abbildung 3).
Listing 4
infra.yml-Playbook
- hosts: infra
become: yes
roles:
- bertvv.dhcpd
- bertvv.tftp

Abbildung 3: Das Playbook für die Infrastrukturdienste ist im Endausbau simpel – auch dann, wenn man per Ansible automatisch die Konfiguration für Grub und Kickstart generieren lässt.
DHCP und TFTP ausrollen
Nun geht es ans Eingemachte: Ansible ist so weit vorbereitet, dass es den TFTP- und den DHCP-Server ausrollen kann. Der Admin forciert das mittels des Kommandos »ansible-playbook -i hosts infra.yml«. Über den Bildschirm fliegen dann die einzelnen Arbeitsschritte der beiden Playbooks.
Wer sich wundert, warum dieser Artikel auf die Konfiguration der Firewall, also von Firewalld, nicht genauer eingeht: Die Rollen von Bert van Vreckem kümmern sich darum automatisch und öffnen die benötigten Ports für die jeweiligen Dienste. Der Admin erspart sich hier also durch die Verwendung von Ansible und der fertigen Module einige Arbeit.
Nginx in Position bringen
Nicht alle Dateien für die automatisierte RHEL- oder CentOS-Installation lassen sich dem Installer per TFTP unterjubeln. Dafür ist das Protokoll ja letztlich auch gar nicht gemacht. Der Admin stellt seinem TFTP-Dienst deshalb einen Nginx zur Seite, der beispielsweise die Kickstart-Dateien für Anaconda hosten kann.
Auch dafür gibt es eine fertige Ansible-Rolle, die auf CentOS-Systemen wunderbar ihre Arbeit erledigt. Diesmal kommt sie jedoch nicht von Bert van Vreckem, sondern direkt von den Ansible-Entwicklern. Der Admin klont die Rolle also zunächst in den Ordner »roles/« (Listing 5).
Danach öffnet er erneut die Datei »host_vars/Hostname.yml« und hinterlegt die Konfiguration für Nginx (Listing 6). Den Eintrag für »server_name« passt er dabei an den vollen Hostnamen des Infrastruktursystems an.
Listing 5
Nginx-Rolle klonen
$ cd roles $ git clone https://github.com/nginxinc/ansible-role-nginx nginxinc.nginx
Listing 6
Konfiguration für Nginx
nginx_http_template_enable: true
nginx_http_template:
default:
template_file: http/default.conf.j2
conf_file_name: default.conf
conf_file_location: /etc/nginx/conf.d/
servers:
server1:
listen:
listen_localhost:
port: 80
server_name: infrastructure.cloud.internal
autoindex: true
web_server:
locations:
default:
location: /
html_file_location: /srv/data
autoindex: true
http_demo_conf: false
Dem Playbook »infra.yml« fügt der Admin anschließend die Rolle »nginxinc.nginx« hinzu und führt den Befehl »ansible-playbook« erneut aus. Wichtig: Auf dem Infrastrukturknoten ist im Anschluss noch der Ordner »/srv/data/« anzulegen, wahlweise händisch oder per Playbook. Der Ordner sollte dem Nutzer >nginx und der Gruppe nginx gehören, damit Nginx darauf zugreifen darf.
PXE-Boot ermöglichen
Weiter geht es nun mit einer Reihe spezifischer Befehle, um PXE-Boot der Systeme zu ermöglichen. Der Artikel geht dabei davon aus, dass auf den Zielsystemen UEFI mitsamt der Secure-Boot-Funktion aktiviert ist.
Der Boot-Vorgang läuft später in etwa folgendermaßen ab: Das System ist per IPMI oder händisch durch den Admin darauf konfiguriert, per PXE-Protokoll über das Netzwerk zu booten. Es schickt dazu zunächst einen DHCP-Request ab, der in seiner Antwort auch den Dateinamen des Bootloaders enthält. Den fragt die PXE-Firmware der Netzwerkkarte dann ab, und sobald sie den Bootloader lokal geladen hat, führt sie ihn aus. Der Bootloader lädt danach seine Konfigurationsdatei nach.
Wichtig: Je nach anfragender MAC-Adresse lässt sich die Bootloader-Konfiguration beeinflussen, was für die Konfiguration des fertigen Systems von großer Bedeutung ist. Zunächst hat der Admin jedoch ein Interesse daran, den ganzen Vorgang grundsätzlich zu konfigurieren. Praktischerweise hat Bert van Vreckems DHCP-Rolle den DHCP-Server bereits so konfiguriert, dass er als Dateinamen für den Bootloader stets »pxelinux/shimx64.efi« für UEFI-Systeme ausliefert.
Im ersten Schritt legt der Admin deshalb in »/var/lib/tftpboot/« den Unterordner »pxelinux/« und darin die Unterverzeichnisse »centos8/« und »pxelinux.cfg/« an. Dann kopiert er in den Ordner »pxelinux/« die Datei »/boot/efi/EFI/centos/shimx64.efi«. Sollte sie fehlen, installiert der Admin das Paket »shim-x64«.
Ebenfalls in den Ordner »pxelinux/« muss die Datei »grubx64.efi«, die der Admin unter http://mirror.centos.org/centos/8/BaseOS/x86_64/os/EFI/BOOT/ findet. Und wenn der Admin gerade schon auf dem CentOS-Mirror herumturnt, kann er von dort auch gleich die beiden Dateien aus http://mirror.centos.org/centos/8/BaseOS/x86_64/os/images/pxeboot/ laden und sie nach »pxeboot/centos8/« packen.
Nun fehlt noch eine Konfigurationsdatei für Grub, damit dieser weiß, welchen Kernel er verwenden soll. Im Ordner »pxeboot/« hinterlegt der Admin daher die Datei »grub.cfg«, die dem Strickmuster von Listing 7 folgt.
Listing 7
Eine generische Grub-Konfiguration
set default="0"
function load_video {
insmod efi_gop
insmod efi_uga
insmod video_bochs
insmod video_cirrus
insmod all_video
}
load_video
set gfxpayload=keep
insmod gzio
insmod part_gpt
insmod ext2
set timeout=10
menuentry 'Install CentOS 8' --class centos --class gnu-linux --class gnu --class os {
linuxefi pxelinux/centos8/vmlinuz devfs=nomount method=http://mirror.centos.org/centos/8/BaseOS/x86_64/os inst.ks=http://172.23.48.31/kickstart/ks.cfg
initrdefi pxelinux/centos8/initrd.img
}
Würde der Admin nun einen Server in einen PXE-Bootvorgang schicken, bekäme der bereits einen Bootloader, einen Kernel und ein Initramfs. Noch fehlte ihm aber die Kickstart-Datei. Diese stellt Listing 8 exemplarisch dar.
Listing 8
Beispielhafte Kickstart-Konfiguration
ignoredisk --only-use=sda # Use text install text # Keyboard layouts keyboard --vckeymap=at-nodeadkeys --xlayouts='de (nodeadkeys)','us' # System language lang en_US.UTF-8 # Network information network --device=bond0 --bondslaves=ens1f0,ens1f1 --bondopts=mode=802.3ad,miimon-100 --bootproto=dhcp --activate network --hostname=server.cloud.internal network --nameserver=10.42.0.10,10.42.0.11 # Root password rootpw --iscrypted <C>Passwort<C> # Run the Setup Agent on first boot firstboot --enable # Do not configure the X Window System skipx # System timezone timezone Europe/Vienna --isUtc --ntpservers 172.23.48.8,172.23.48.9 # user setup user --name=example-user --password=<C>Passwort<C> --iscrypted --gecos="example-user" # Disk partitioning information zerombr bootloader --location=mbr --boot-drive=sda --driveorder=sda clearpart --all --initlabel --drives=sda part pv.470 --fstype="lvmpv" --ondisk=sda --size 1 --grow part /boot --size 512 --asprimary --fstype=ext4 --ondisk=sda volgroup cl --pesize=4096 pv.470 logvol /var --fstype="xfs" --size=10240 --name=var --vgname=cl logvol / --fstype="xfs" --size=10240 --name=root --vgname=cl logvol swap --fstype="swap" --size=4096 --name=swap --vgname=cl reboot %packages @^server-product-environment kexec-tools %end %addon com_redhat_kdump --enable --reserve-mb='auto' %end %anaconda pwpolicy root --minlen=6 --minquality=1 --notstrict --nochanges --notempty pwpolicy user --minlen=6 --minquality=1 --notstrict --nochanges --emptyok pwpolicy luks --minlen=6 --minquality=1 --notstrict --nochanges --notempty %end
Wer wissen möchte, welches Format das Passwort in den Zeilen »user« sowie »rootpw« haben muss, findet im Web [3] entsprechende Informationen. Die Datei hinterlegt der Admin unter dem Namen »ks.cfg« im Ordner »/srv/data/kickstart/« auf dem Infrastruktur-Host; die Berechtigungen setzt er auf »0755«, sodass Nginx auf die Datei zugreifen darf.
Nach Abschluss dieses Arbeitsschritts gelingt der PXE-Boot eines 64-Bit-Systems mit aktiviertem UEFI und Secure-Boot. Einen Haken hat die Sache momentan allerdings noch: Die installierten Systeme würden ihre IP-Adressen per DHCP beziehen, und das Standard-Kickstart-Template geht davon aus, dass alle Server dasselbe Hardware-Layout nutzen.
Der Trick mit der MAC
Das Problem lässt sich auf mehrere Arten umgehen. Das Netzwerk-Thema ist dabei eine heikle Geschichte, denn hier gibt es mehrere potenzielle Lösungen. Denkbar wäre etwa, konfigurierte Systeme auf der Switch-Ebene in ein eigenes VLAN zu packen und das System durch den Auto-Installer Anaconda entsprechend konfigurieren zu lassen. Es könnte dann ein anderer DHCP-Server im Netz für dieses VLAN so eingerichtet werden, dass er passende IP-Adressen vergibt.
Denkbar wäre aber auch, für jeden Host eine passende Kickstart-Konfiguration zu hinterlegen, die die gewünschte Konfiguration des Netzwerks enthält. Hierbei kommt ein Trick zur Hilfe: Der Grub-Bootloader sucht beim Start des Systems nämlich nicht zuerst nach der Datei »grub.cfg«, sondern nach der Datei »grub.cfg-01-MAC_der_Netzwerkkarte_der_Anfrage«, also zum Beispiel nach »grub.cfg-01-0c-42-a1-06-ab-ef«. Mittels des Parameters »inst.ks« kann der Admin in dieser bestimmen, welche Kickstart-Datei der Client nach dem Start des Installers abruft.
Im konkreten Beispiel könnte die beschriebene Grub-Konfiguration etwa den Parameter »inst.ks=http://172.23.48.31/kickstart/ks01-0c-42-a1-06-ab-ef.cfg« enthalten. Damit würde Anaconda eben nicht mehr die generische »ks.cfg« herunterladen, sondern die spezifisch auf den jeweiligen Host zugeschnittene Variante. In der kann der Admin sich dann entlang des Anaconda-Handbuchs so austoben, wie er will, indem er etwa statische IP-Adressen konfiguriert.
Hilfreich ist es in diesem Kontext, sich einen Mechanismus zu überlegen, um sowohl die benötigten »grub.cfg«-Dateien als auch die Kickstart-Dateien so an Ort und Stelle zu bekommen, wie sie benötigt werden. Ansibles Template-Funktionen helfen hier gegebenenfalls enorm: Der Admin baut sich dann eine eigene Rolle, die ein Template für »grub.cfg« und »ks.cfg« enthält, und hinterlegt für jeden Host in seiner Konfiguration die Parameter, die in beiden Templates zum Einsatz kommen. Im Anschluss nutzt er die »template«-Funktion in Ansible, um die Dateien ausgefüllt an der richtigen Stelle im Dateisystem zu hinterlegen. Für jeden Host, der in der Ansible-Konfiguration hinterlegt ist, gäbe es dann eine stets funktionale, permanent hinterlegte Autoinstallationskonfiguration. Mehr dazu findet der Admin bei Interesse in der Anaconda-Doku [4].
Der Nachgang der Installation
Der eigentliche Hauptakteur des Prozederes, Anaconda, kam hier bisher nur implizit zur Sprache. Doch Ehre, wem Ehre gebührt: Anaconda ist Bestandteil der CentOS- und RHEL-Initramfs-Dateien und tritt automatisch auf den Plan, sobald der Admin einen Anaconda-Parameter wie »method« oder »inst.ks« in der Kommandozeile des Kernels angibt (Abbildung 4).
Abbildung 4: Anaconda geht wahlweise auf der Kommandozeile oder grafisch ans Werk, auf das installierte System wirkt sich das aber nicht aus. Quelle: Fedora
Hat er eine Anaconda-Konfiguration vorbereitet, darf der Admin erwarten, dass er hinterher ein System mit den entsprechenden Parametern vorfindet. Das vorgestellte Anaconda-Template reizt keineswegs alle Möglichkeiten des Programms aus. Es wäre etwa auch möglich, in Anaconda Sudo zu konfigurieren oder für Benutzer einen SSH-Schlüssel zu hinterlegen, sodass ein passwortloses Login funktioniert. Es empfiehlt sich jedoch, seine Kickstart-Templates so übersichtlich und einfach wie möglich zu gestalten und den Rest einem echten Automatisierer zu überlassen.
Setup im Nachgang erweitern
Bis hierhin hat der Artikel herausgearbeitet, wie der Admin von blankem Blech hin zu einem installierten Grundsystem kommt. Zwar ist Automation gut, mehr Automation aber noch besser. Daher gilt es, quasi das letzte kleine Stück vom installierten Grundsystem bis zu dem Schritt zu implementieren, an dem das System automatisch Teil der Automation wird. Im Ansible-Sprech wäre dieses Ziel etwa erreicht, wenn ein Host nach der Grundinstallation automatisch im Ansible-Inventory auftaucht.
Hier kommt ein Werkzeug zur Hilfe, das im Linux-Magazin bereits mehrfach Thema war: Netbox, ein kombiniertes DCIM- und IPAM-System. Die Abkürzungen stehen für Datacenter Inventory Management und IP Address Management. In Netbox (Abbildung 5) lassen sich also Server verzeichnen, die im eigenen Rechenzentrum stehen, und ebenfalls die IPs ihrer verschiedenen Netzwerkkarten. Treibt man das Spiel auf die Spitze, lassen sich aus Netbox heraus die Konfigurationsdatei des DHCP-Servers ebenso generieren wie die Kickstart-Dateien für einzelne Systeme.
Abbildung 5: Netbox ist eine Kombination aus DCIM- und IPAM und ergänzt das Gespann aus DHCP, TFTP und HTTP bei Bedarf. Quelle: Netbox
Das Abfragen einzelner Werte aus Netbox ist dabei alles andere als kompliziert, denn der Dienst kommt mit einer REST-API, die sich maschinell abfragen lässt. Mehr noch: Insbesondere für Python gibt es eine Bibliothek, die als Netbox-Client fungiert, sodass sich Werte direkt in einem Python-Skript aus Netbox abfragen und verarbeiten lassen. Wer den ganz großen Wurf in der Automation plant, orientiert sich in diese Richtung und kann letztlich sogar Tags in Netbox nutzen, um bestimmten Systemen bestimmte Aufgaben zuzuweisen.
Ein Netbox-Client, der die Parameter der Server in Netbox regelmäßig abfragt, kann auf Basis dieser Details dann spezifische Kickstart-Files generieren und dafür sorgen, dass etwa ein spezieller Paketsatz auf dem einen System ausgerollt wird, auf dem anderen aber nicht. Als der Mühe Lohn winkt ein Workflow, bei dem der Admin einen Rechner bloß noch ins Rack schraubt, in Netbox einträgt sowie mit den richtigen Tags versieht, um die Installation komplett automatisiert zu erledigen.
Wer es etwas weniger aufwendig haben möchte, gibt sich aber möglicherweise bereits mit einem Zwischending zufrieden. Viele Automatisierer, darunter Ansible, können ihr Inventar heute direkt aus Netbox generieren. Sobald ein System also in Netbox auftaucht, ist es auch im Inventar einer Umgebung vorhanden, und der nächste Ansible-Lauf würde jenen neuen Server mit einbeziehen.
Fazit
Es ist weder Hexenwerk, Red Hat oder CentOS automatisiert mit Bordmitteln zu installieren, noch handelt es sich um eine Aufgabe, für die komplexe Frameworks notwendig wären. Wer auf der Konsole sattelfest ist, hat mit dem Einrichten der benötigten Komponenten keinerlei Probleme.
Sehr sinnvoll ist es zudem, die Automation im eigenen Setup mit Anaconda zu kombinieren, damit frisch installierte Systeme gleich Teil der Automation werden. Zwar bieten Kickstart-Dateien Absätze für beliebige Shell-Befehle, die es vor, während oder nach der Installation aufzurufen gilt. Über diesen Weg lassen sich in der Theorie sogar Konfigurationsdateien beliebiger Programme ausrollen. In der Praxis ist es aber eine gute Idee, diese Arbeit lieber den echten Automatisierern zu überlassen, denn diese sind darauf ausgelegt. Inventar-Systeme wie Netbox mit abfragbarer API erweisen sich hier als ausgesprochen nützlich, auch wenn sich ihr initiales Setup oft zäh und langwierig gestaltet. (jcb)
Der Autor
Martin Gerhard Loschwitz ist Cloud Platform Architect bei Drei Austria und beackert dort Themen wie OpenStack, Kubernetes und Ceph.
Infos
- DRBD 9: Martin Loschwitz, “Neue Wege”, LM 07/2015, S. 68, https://www.lm-online.de/34584
- Pacemaker: Martin Loschwitz, “Dabeibleiben ist alles”, LM 05/2012, S. 40, https://www.lm-online.de/25577
- Erläuterung zu Passwörtern in Anaconda: https://thornelabs.net/posts/hash-roots-password-in-rhel-and-centos-kickstart-profiles.html
- Anaconda-Referenz: https://docs.fedoraproject.org/en-US/fedora/rawhide/install-guide/install/Installing_Using_Anaconda/





