
© Sergey Nivens, 123RF
In der griechischen Mythologie bringt Prometheus den Menschen das Feuer. Die namensgleiche Software für verteiltes Monitoring erleuchtet hingegen den Geist von Admins in Cloud-Native-Umgebungen. Sie liefert auf recht unkomplizierte Weise Metriken der verfügbaren Systeme.
Wo sich Container-basierte Microservices verbreiten, kommen klassische Monitoring-Tools wie Nagios [1] und Icinga [2] an ihre Grenzen. Sie sind einfach nicht dafür ausgelegt, kurzlebige Objekte wie Container zu überwachen. In Cloud-Native-Umgebungen mausert sich daher Prometheus [3] mit seinem auf Zeitreihen-Daten beruhenden Ansatz zu einem unverzichtbaren Werkzeug. Die Software ist quasi ein Cousin des Container-Orchestrators Kubernetes [4]: Während der von Googles Clustersystem Borg abstammt, wurzelt Prometheus in Borgmon, dem Monitoring-Tool für Borg.
Matt Proud und Julius Volz, zwei ehemalige Site Reliability Engineers (SRE) von Google, starteten das Projekt 2012 bei Soundcloud. Ab 2014 begannen es andere Unternehmen zu nutzen, 2015 veröffentlichten es die Macher mit offizieller Ankündigung [5] als Open-Source-Projekt, obwohl es schon vorher ebenfalls als Open Source auf Github [6] existierte. Heute entwickeln Interessierte Prometheus unter dem Dach der Cloud Native Computing Foundation (CNCF, [7]), neben prominenten Projekten wie Kubernetes, Containerd, Rkt oder GRPC.
Wissen, was abgeht
Dank seiner minimalistischen Architektur und seiner unkomplizierten Installation lässt sich Prometheus einfach ausprobieren. Die Software ist in Go geschrieben, die einfachste Form ihrer Installation beschränkt sich darauf, sie von [8] herunterzuladen, sie auszupacken und zu starten:
tar xzvf prometheus-1.5.2.linux-*.tar.gz cd prometheus-1.5.2.linux-amd64/ ./prometheus
Wer danach im Webbrowser »http://localhost:9090/metrics« aufruft, sieht die in Abbildung 1 gezeigten internen Metriken von Prometheus. Das eher für Debugging-Zwecke gedachte Prometheus-Webinterface aus Abbildung 2 erreicht er über die URL »http://localhost:9090«. Beim weiteren Einstieg in Prometheus helfen inzwischen viele Artikel, Blogposts und Konferenzvorträge, etwa [9], [10] und [11]. Der Artikel konzentriert sich auf das Auslesen von Metriken.
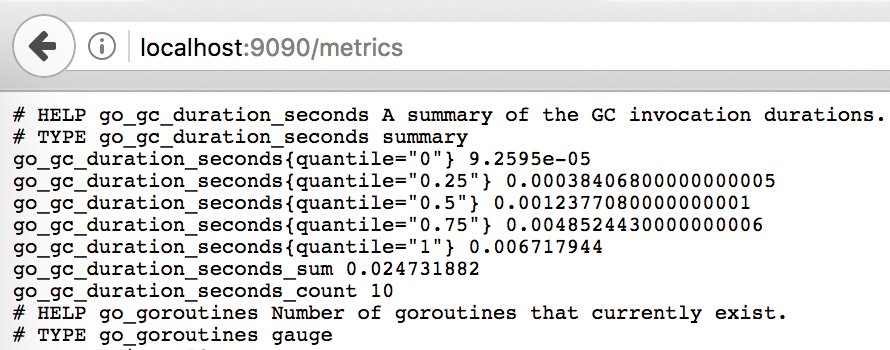
Abbildung 1: Ruft der Admin die »metrics«-Unterseite auf, liefert Prometheus eine Reihe interner Metriken.
Abbildung 2: Das eigentliche Webinterface von Prometheus ist eher simpel gestrickt.
Metriken sammeln
Die klassischen Monitoring-Tools wie Icinga und Nagios überwachen Komponenten oder Anwendungen mit Hilfe kleiner Programme (Check-Plugins). Dieser Ansatz heißt auch “Blackbox-Monitoring”. Prometheus ist hingegen ein Vertreter des “Whitebox-Monitoring”. Für dies stellen Systeme und Applikationen von sich aus Metriken im Prometheus-Format bereit. Die ständig wachsende Zahl von Applikationen, die dies bereits tun – dazu gehören Docker, Kubernetes, Etcd und seit kurzem Gitlab –, heißen daher auch instrumentierte Anwendungen.
Unterstützt durch so genannte Exporter behält Prometheus aber nicht nur instrumentierte Systeme und Anwendungen im Auge. Als selbstständige Programme extrahieren Exporter Metriken aus dem überwachten System und bereiten sie für Prometheus lesbar auf. Am bekanntesten ist der »node_exporter«[12], der Betriebssystem-Metriken wie Speicherverbrauch oder Netzwerkauslastung ausliest und bereitstellt. Inzwischen gibt es eine ganze Reihe von Exportern für unterschiedlichste Protokolle und Dienste wie etwa Apache, MySQL, SNMP, V-Sphere. Eine Übersicht liefert [13].
Node transparent machen
Der »node_exporter« ist ebenfalls in Go verfasst und lässt sich analog zu Prometheus ausprobieren. Nach
tar xzvf node_exporter-0.14.0.*.tar.gz cd node_exporter-0.14.0.linux-amd64 ./node_exporter
wartet unter »http://localhost:9100/metrics« eine Liste mit Metriken zum eigenen System. Damit stellt der Admin bereits ein recht aussagekräftiges Basismonitoring auf die Beine.
Der »node_exporter« beschränkt sich per Definition auf Maschinenmetriken. Informationen über laufende Prozesse warten eher auf Applikationsebene. Für diese sind weitere Exporter notwendig. Gibt der Admin dem »node_exporter« mit der Option »–collector.textfile.directory« ein Verzeichnis mit auf den Weg, liest dieser dort abgelegte Textdateien mit der Endung »*.prom« ein und wertet darin befindliche Metriken aus. Ein Cronjob übergibt so seine Endzeit an Prometheus:
echo my_batch_completion_time $(date +%s) > /Path/to/Directory/my_batch_job.prom.$$ mv /Path/to/Directory/my_batch_job.prom.$$ /Path/to/Directory/my_batch_job.prom
Prometheus fragt in definierbaren Intervallen (Scraped) die konfigurierten Überwachungsziele ab. Die Software kennt hier Jobs und Instanzen [14]: Eine Instanz ist ein einzelnes Überwachungsziel, ein Job eine Sammlung gleichartiger Instanzen. Die Abfrage-Intervalle liegen im Regelfall zwischen 5 und 60 Sekunden, Standardwert ist 15 Sekunden. Die Übertragung der Metriken erfolgt über HTTP – sofern der Admin einen Browser nutzt. Prometheus verwendet intern die effizienteren Protocol Buffer. Die Zweigleisigkeit macht es einfach, mal eben nachzusehen, welche Metriken eine Anwendung oder ein Exporter bereitstellt.
Zielübung
Lediglich sich selbst zu überwachen ergibt oft keinen Sinn. Targets für Prometheus warten in der Datei »prometheus.yml«. Liegt die nicht im Programmverzeichnis, übergibt der Admin den Pfad zur Datei über »-config.file« an das verteilte Monitoring. Um die Metriken eines lokal gestarteten »node_exporter« abzufragen, fügt er im Abschnitt »scrape_configs« folgende Definition hinzu:
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
Weitere Instanzen ergänzt der Admin, indem er die Liste der Targets erweitert: »[‘localhost:9100’, ‘10.1.2.3:9100’, …]«. Andere Arten von Jobs, etwa instrumentierte Anwendungen oder andere Exporter, gibt er als separate »job_name«-Abschnitte an.
Als Entdecker
In Umgebungen mit kurzlebigen Instanzen, etwa Docker oder Kubernetes, kopiert der Admin Instanzen nicht manuell in eine Konfigurationsdatei. Hier hilft ein weiteres Prometheus-Feature: Service Discovery. Die Monitoring-Software findet für Azure, Google Container Engine, AWS oder Kubernetes selbstständig Überwachungsziele. Die ganze Liste und Konfigurationsparameter warten unter [15].
Eine Sonderstellung nimmt die Datei-basierte Diensterkennung ein: Sie liest alle auf die in »prometheus.yml« angegebenen Muster passenden Dateien ein. Das Dateiformat beschreibt auch [15]. Prometheus erkennt Änderungen an den Dateien selbstständig. Mit diesem Mechanismus lassen sich etwa Konfigurationswerkzeuge wie Ansible anzapfen – nur die Phantasie setzt hier Grenzen.
Architektonisches
Wie das Architekturdiagramm des Projekts (Abbildung 3, [16]) zeigt, kümmert sich Prometheus selbst um die Abfrage der Ziele und das Speichern in einer (lokalen) Zeitreihen-Datenbank. Darüber hinaus bietet es die intelligent gemachte Abfragesprache Prom QL an, mit deren Hilfe der Admin gespeicherte Metriken zur Visualisierung, Aggregation und Alarmierung abfragt.
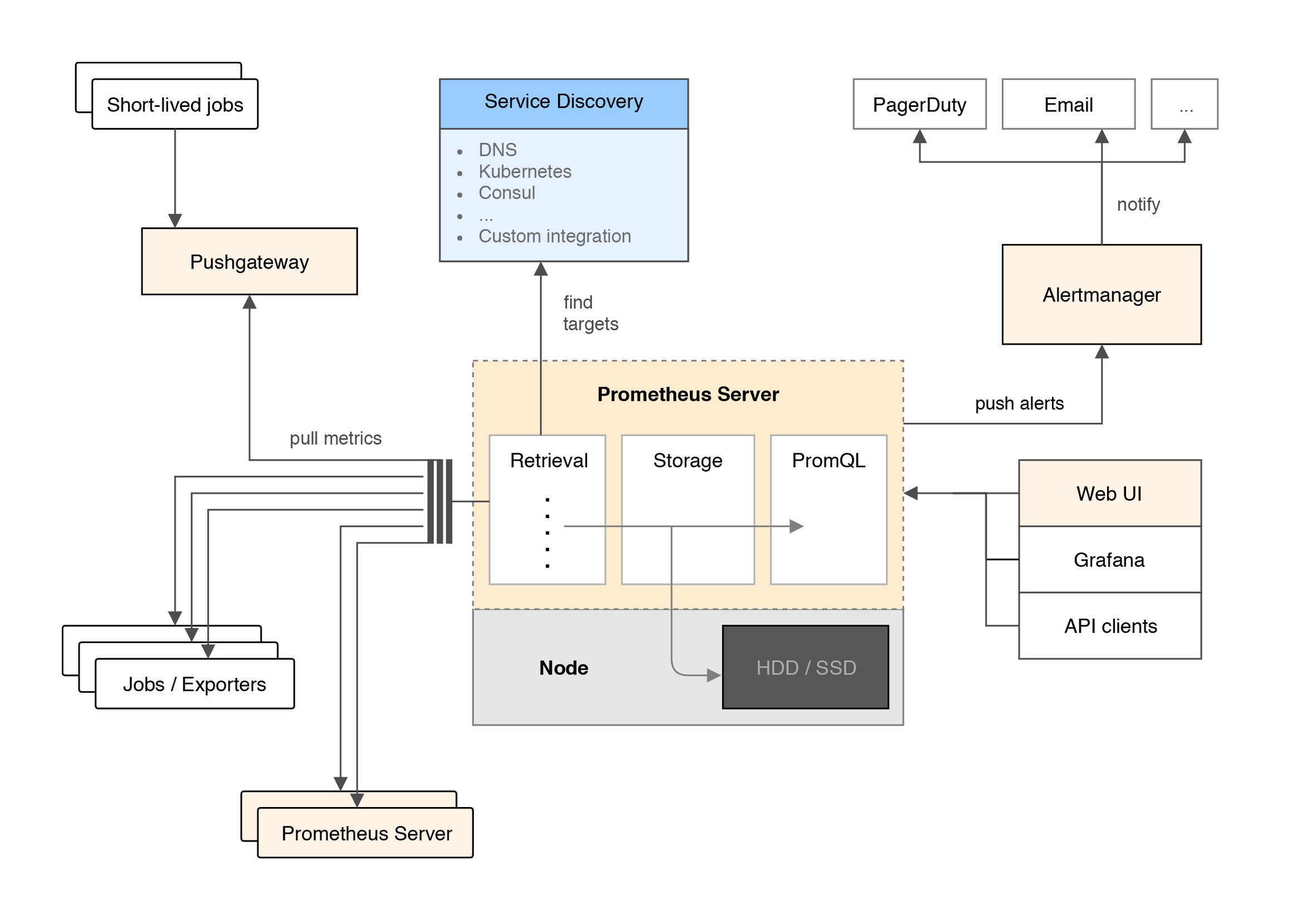
Abbildung 3: Das Zusammenspiel der einzelnen Bausteine von Prometheus zeigt ein Architekturdiagramm des Projekts.
Alarme reicht Prometheus an den Alertmanager weiter, der Alarmzustände deduplizieren und etwa bei Wartungsfenstern stummschalten kann. Die Benachrichtigungen reicht der Manager etwa über E-Mail, per Slack oder generischem Webhook an den Admin weiter.
Ein weiterer Bestandteil ist das Pushgateway, das Ergebnisse kurzlebiger Programmläufe entgegennimmt und zwischenspeichert. Mit ihm senden auch Batchjobs Metriken an Prometheus.
Neben dem bereits gezeigten eingebauten Webinterface kommt für aufwändigere Dashboards das nicht zum Prometheus-Projekt gehörende Grafana [17] zum Einsatz. Das gilt inzwischen als De-facto-Standard für Visualisierung und Dashboards. Für Prometheus bietet Grafana unter [18] bereits eine Vielzahl fertiger Dashboards zum Import in die eigene Grafana-Installation an. Abbildung 4 zeigt eines, mit dem der Autor seinen VDSL-Zugang überwacht [19].
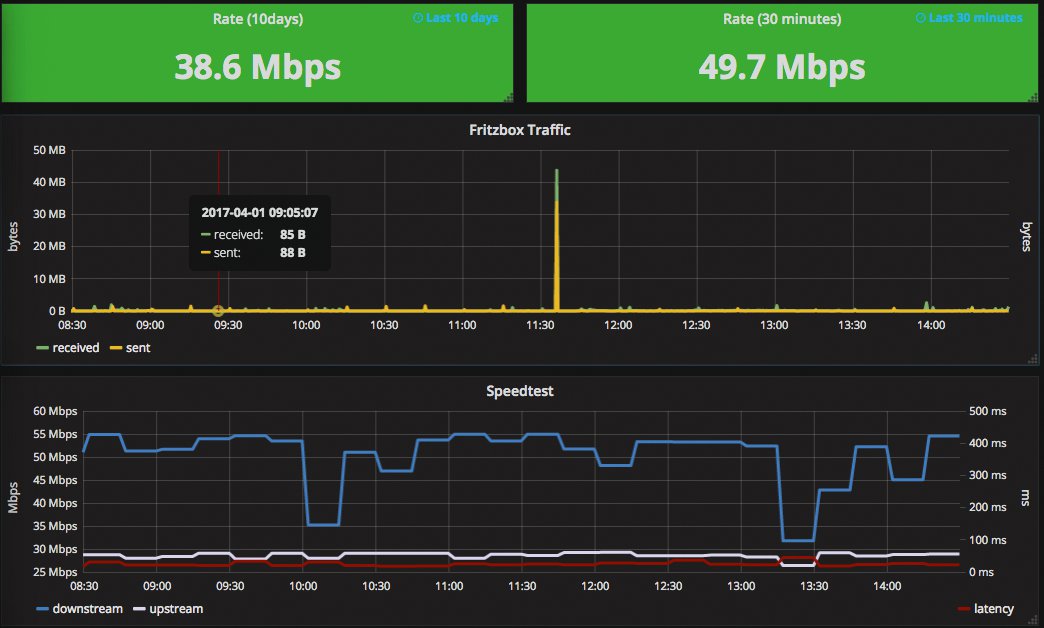
Abbildung 4: Beispiel eines Grafana-Dashboards aus Prometheus-Metriken.
Prometheus’ Metriken
Prometheus kennt als Metriken im Prinzip Zähler (»counter«) und Messwerte (»gauge«), die als Einträge in der Zeitreihen-Datenbank landen. Eine Zählermetrik kann so aussehen:
http_requests_total{status="200", method="GET"}@1434317560938 = 94355
Die Metrik besteht aus einem beschreibenden Namen, einem 64-Bit-Zeitstempel und einem als Float64 gespeicherten Wert. Eine Metrik darf darüber hinaus »labels« enthalten und diese als Schlüssel-Wert-Paare speichern. Labels machen eine Metrik sehr einfach multi-dimensional. Das obige Beispiel erweitert etwa die Zahl der HTTP-Requests um die Eigenschaften »status« und »method«. Auf diese Weise sucht der Admin gezielt nach Häufungen von HTTP-500-Fehlern.
Aber Vorsicht ist geboten: Jedes Schlüssel-Wert-Paar von Labels erzeugt eine eigene Zeitreihe, was den Platzbedarf der Zeitreihen-Datenbank drastisch erhöht. Die Autoren von Prometheus raten daher davon ab, Labels zum Speichern von Eigenschaften mit hoher Kardinalität zu verwenden. Als Faustregel sollte die Anzahl möglicher Werte zehn nicht überschreiten. Für Daten hoher Kardinalität, etwa Kundennummern, empfehlen die Entwickler, Logdateien zu analysieren. Es ist zudem denkbar, mehrere spezialisierte Prometheus-Instanzen zu betreiben.
An dieser Stelle auch der Hinweis, dass Admins für einen Prometheus-Server mit einer hohen Anzahl von Metriken am besten einen Bare-Metal-Server mit viel Arbeitsspeicher und schnellen Festplatten einplanen. Für kleinere Projekte lässt sich die Monitoring-Software aber auch ohne Bedenken auf schwächerer Hardware einsetzen: Den VDSL-Anschluss zu Hause beobachtet Prometheus von einem Raspberry Pi 2 aus [19].
Metriken speichert Prometheus nicht unbegrenzt. Die Kommandozeilen-Option »storage.local.retention« gibt an, nach welchem Zeitraum es die gesammelten Daten löscht. Standardeinstellung ist hier ein Monat. Wer Daten länger speichern möchte, reicht einzelne Datenreihen per Federation an einen Prometheus-Server mit längerer Speicherzeit weiter.
Im Umbruch befinden sich noch die Möglichkeiten, Daten in anderen Zeitreihen-Datenbanken wie Influx DB oder Open TSDB zu lagern. Die Entwickler ersetzen außerdem die bisher vorhandenen schreibenden Funktionen zurzeit durch einen generischen Ansatz, der auch Lesezugriffe erlauben soll. Für Influx DB ist beispielsweise ein Zusatzprogramm mit Schreib- und Lese-Funktionalität angekündigt.
Eine sehr nützliche Lektüre sind auch die offiziellen Best Practices der Prometheus-Autoren [20], die einige Probleme schon im Vorfeld ersparen. Wer selbst Prometheus-Metriken bereitstellt, sollte darauf achten, Zeitmesswerte nur in Sekunden und den Datendurchsatz nur in Bytes anzugeben.
Daten melken mit Prom QL
Mit der Abfragesprache Prom QL holen Admins Daten aus der Prometheus-Zeitreihen-Datenbank. Die einfachste Möglichkeit, mit Prom QL zu experimentieren, bietet das Webinterface (Abbildung 2). Im Tab »Graph« testen sie Prom-QL-Abfragen und schaut sich die Ergebnisse an. Eine einfache Abfrage einer vom »node_exporter« gelieferten Metrik sieht zum Beispiel so aus:
node_network_receive_bytes
Diese Metrik verfügt über mehrere Eigenschaften, dazu gehören unter anderem die Namen der Netzwerk-Interfaces. Will der Prometheus-Betreiber nur die Werte für »eth0« erhalten, ändert er die Abfrage zu:
node_network_receive_bytes{device='eth0'}
Alle gesammelten Werte einer Metrik für die letzten fünf Minuten liefert die Abfrage:
node_network_receive_bytes{device='eth0'}[5m]
Auf den ersten Blick ähnlich wirkt die folgende Abfrage:
rate(node_network_receive_bytes {device='eth0'}[5m])
Hier passiert aber deutlich mehr: Prometheus wendet die Funktion »rate()« auf die Daten der letzten fünf Minuten an. Auf diese Weise ermittelt es die Datenrate pro Sekunde für den Zeitraum.
Diese Aggregation von Daten ist eine der Hauptaufgaben von Prometheus. Die Monitoring-Software geht davon aus, dass instrumentierte Anwendungen und Exporter lediglich Zähler oder Messwerte zurückliefern. Sämtliche Aggregationen übernimmt dann Prometheus.
Die Datenraten aller Netzwerkinterfaces ermittelt für die einzelnen Interfaces zum Beispiel folgende Abfrage:
sum(rate(node_network_receive_bytes[5m])) by (device)
Diese Beispiele schneiden die Möglichkeiten von Prom QL nur an. Admins können die unterschiedlichsten Funktionen auf Metriken anwenden, unter anderem statistische wie »predict_linear()« und »holt_winters()«. Eine komplette Übersicht der Funktionen liefert [21].
Alarm schlagen
Um Alarmzustände festzustellen, verwendet Prometheus die Alarmierungsregeln (Alerting Rules). Eine solche Regel enthält einen Prom-QL-Ausdruck – optional eine Angabe zur Dauer – sowie Labels und Anmerkungen, die der Alertmanager zum weiteren Verarbeiten heranzieht. Listing 1 zeigt eine Alarmierungsregel, die zutrifft, wenn für ein Überwachungsziel mehr als fünf Minuten der Prom-QL-Ausdruck »up == 0« zutrifft. Wie das Beispiel zeigt, lassen sich in den Anmerkungen auch Variablen verwenden.
Listing 1
Alarmierungsregel
01 # Überwachungsziel ist länger als fünf Minuten down
02 ALERT InstanceDown
03 IF up == 0
04 FOR 5m
05 LABELS { severity = "page" }
06 ANNOTATIONS {
07 summary = "Instance {{ $labels.instance }} down",
08 description = "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.",
09 }
Trifft nun eine Alarmierungsregel zu, löst Prometheus einen Alarm aus (»is firing«). Ist ein Alertmanager angegeben, leitet Prometheus die Informationen zum Alarm per HTTP an diesen weiter. Dies passiert, solange der Alarmzustand der Alarmierungsregel anhält und bei jeder Regelauswertung erneut. Eine Benachrichtigung direkt von Prometheus aus wäre daher auch keine gute Idee.
Eigene Anwendung instrumentieren
Das Prometheus-Projekt bietet für einige Programmiersprachen fertige Bibliotheken, um die Instrumentierung eigener Anwendungen mit Metriken zu vereinfachen. Bibliotheken gibt es unter anderem für Go, Java, Ruby und Python. Listing 2 zeigt beispielhaft, wie sich eine Python-Anwendung für Prometheus instrumentieren lässt [22]. Wer die Demo-Anwendung startet, kann die erzeugten Metriken unter »http://localhost:8000« begutachten.
Listing 2
Python-Anwendung instrumentieren
01 from prometheus_client import start_http_server, Summary
02 import random
03 import time
04
05 # Create a metric to track time spent and requests made.
06 REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
07
08 # Decorate function with metric.
09 @REQUEST_TIME.time()
10 def process_request(t):
11 """A dummy function that takes some time."""
12 time.sleep(t)
13
14 if __name__ == '__main__':
15 # Start up the server to expose the metrics.
16 start_http_server(8000)
17 # Generate some requests.
18 while True:
19 process_request(random.random())
Als sehr einfach entpuppt sich auch das Senden der Metriken von Batchjobs an Prometheus. Ein Beispiel liefert der »speedtest_exporter«[23]. Das einfache Perl-Skript verarbeitet die Ausgabe eines anderen Programms (hier »speedtest_cli«) und schickt die Ergebnisse per »curl« an das Pushgateway. Von dort holt sich Prometheus die erfassten Daten ab. Dabei schickt es zeilenweise einen String mit einer oder mehreren Metriken per HTTP-»POST« an das Pushgateway. Die gesendeten Metriken des »speedtest_exporter« sehen beispielsweise so aus:
speedtest_latency_ms 22.632
speedtest_bits_per_second {direction="downstream"} 52650000speedtest_bits_per_second{direction="upstream"} 29170000
Die URL gibt dabei einen eindeutigen Jobnamen an, etwa »http://localhost:9091/metrics/job/speedtest_exporter«.
Fazit
Prometheus besticht durch Einfachheit und die extrem vielfältigen Möglichkeiten von Prom QL. Für Entwickler, die ihre Applikation überwachen wollen, oder im Containerumfeld ist Prometheus sicherlich eine sehr gute Wahl. Wie [24] zeigt, überwacht es problemlos und einfach einen kompletten Kubernetes-Cluster.
Im Unternehmenseinsatz müssen Admins allerdings ein paar Kröten schlucken: Die Langzeitarchivierung von Metriken ist noch eine Baustelle, Verschlüsselungen oder Zugriffskontrollen müssen sie um Prometheus herumbauen. Wer damit leben kann, bekommt ein wirkungsmächtiges Werkzeug an die Hand, das in den nächsten Jahren mit ziemlicher Sicherheit auch die genannten Schwachpunkte behebt.
Infos
-
Nagios: https://www.nagios.org
-
Icinga: https://www.icinga.com
-
Prometheus-Website: https://prometheus.org
-
Kubernetes: https://kubernetes.io
-
Offizielle Prometheus-Ankündigung: https://developers.soundcloud.com/blog/prometheus-monitoring-at-soundcloud
-
Prometheus auf Github: https://github.com/prometheus
-
CNCF: https://www.cncf.io
-
Prometheus-Download: https://prometheus.io/download/
-
Blog von Brian Brazil: https://www.robustperception.io/blog/
-
Vorträge der Promcon 2016: https://www.youtube.com/playlist?list=PLoz-W_CUquUlCq-Q0hy53TolAhaED9vmU
-
Weaveworks Blog: https://www.weave.works/tag/prometheus/
- »node_exporter«: https://github.com/prometheus/node_exporter
-
Liste von Exportern: https://prometheus.io/docs/instrumenting/exporters/
-
Jobs und Instanzen: https://prometheus.io/docs/concepts/jobs_instances/
-
Service Discovery: https://prometheus.io/docs/operating/configuration/
-
Architekturdiagramm des Projekts: https://github.com/prometheus/prometheus/blob/master/documentation/images/architecture.svg
-
Fertige Grafana-Dashboards für Prometheus: https://grafana.com/dashboards?dataSource=prometheus
-
Prometheus und die Fritzbox: https://labs.consol.de/monitoring/2017/03/08/prometheus-und-die-fritzbox.html
-
Best Practices beim Einsatz von Prometheus: https://prometheus.io/docs/practices/naming/
-
Funktionen von Prom QL: https://prometheus.io/docs/querying/functions/
-
Demo-Anwendung instrumentiert Python: https://github.com/prometheus/client_python
- »speedtest_exporter«: https://github.com/RichiH/speedtest_exporter
-
Kubernetes mit Prometheus überwachen: https://coreos.com/blog/prometheus-and-kubernetes-up-and-running.html
Der Autor

Michael Kraus ist Senior Consultant für Open-Source-Monitoring bei ConSol in München. Seit 2005 entwickelt und betreut er die Monitoring-Umgebungen mit Nagios und seinen Nachfolgern. Sein Hauptaugenmerk gilt der Integration neuer Komponenten in ein sinnvolles Monitoring – nur Open Source Software sollte es sein.





