
© Wee hong Soon, 123RF
Performance spielt bei öffentlichen Clouds eine wichtige Rolle: Sowohl die Anbieter als auch ihre Kunden wollen die Schnellsten sein. Wie sie ihre Setups dafür frisieren müssen, verrät dieser Artikel.
Public Clouds buhlen vielerorts um die Gunst der Nutzer – und deren Anforderungen sind hoch. An erster Stelle steht Performance: Wer etwa eine Webplattform in der Cloud betreibt, will hohen Durchsatz und geringe Latenzen. Doch das Thema Performance in der Cloud ist zweischneidig: Bietet der Anbieter nicht die passende Infrastruktur, sind alle Optimierungsbemühungen vergeblich. Und umgekehrt: Ist das Setup zu langsam, bringt auch die schnellste Infrastruktur nur wenig.
Für ihr gemeinsames Ziel arbeiten der Anbieter einer Cloudplattform und sein Kunde also im besten Fall Hand in Hand. Zunächst eruiert der Anbieter, welche Performance seine Plattform zu liefern in der Lage ist, wenn er Hardware und Software ausreizt. Auf dieser Grundlage sucht im Anschluss sein Kunde nach möglichen Engpässen in seinem Deployment und beseitigt sie. Der folgende Artikel verrät, was Anbieter und Kunden jeweils tun können, um eine performante Lösung zu erreichen.
Open Stack als Beispiel
Die folgenden Beispiele gehen von Open Stack als Cloudumgebung aus. Einerseits basieren viele Clouds auf dieser freien Software, weshalb die Tipps sowohl für die Admins als auch für die Nutzer solcher Umgebungen hilfreich-sind, und andererseits lassen sich die Vorschläge und Tipps recht leicht auch auf andere Umgebungen übertragen. Denn beim Design ähneln sich die meisten Cloudansätze sehr. Im zweiten Teil des Artikels geht es dann um große Anbieter von Public Clouds wie Amazon.
Durchsatz und Latenz
Der Begriff Performance hat zwei Dimensionen: Einerseits gibt der Durchsatz darüber Auskunft, wie viele Daten sich innerhalb eines Zeitraums von A nach B transferieren lassen. Durchsatz als Performance-Dimension ist im Wesentlichen dort von Interesse, wo große Datenmengen zu übertragen sind.
Andererseits gibt es die Latenz. Bei ihr ist die spannende Frage nicht, wie viele Daten innerhalb eines Zeitraums fließen, sondern wie lange ein einzelnes Stück Information braucht, um von der Quelle zum Ziel zu gelangen. Folgt man der reinen Lehre, haben beide Dimensionen wenig miteinander zu tun.
Die Erfahrung gestandener Sysadmins zeigt, dass sich Durchsatz deutlich einfacher tunen lässt als Latenz. Denn die Latenz kann an physische Grenzen stoßen, die sich nicht ohne Weiteres umgehen lassen – etwa die inhärente Latenz von Ethernet, die zu unterbieten nicht möglich ist. Gerade diese Latenz stört die Nutzer häufig mehr als ein mäßiger Durchsatz.
Clouds bieten meist zwei unterschiedliche Dienstleistungen an: Virtuelle Maschinen für den Computing-Teil und Object Storage als On-Demand-Speicher. Der Faktor Durchsatz ist in beiden Szenarien wichtig, die Messmethoden sind jedoch andere. Bei den VMs liegt der Fokus auf der Netzwerkperformance, bei den Object Storages hängt die Performance stark von der benutzten Technologie ab.
Durchsatz zwischen VMs
Als Messwerkzeug für den Durchsatz zwischen VMs wählen die meisten Admins I-Perf [1]. Das Programm bietet die passenden Voraussetzungen: Es lässt sich im Server- wie im Client-Modus betreiben, sodass zwei Instanzen von I-Perf sich ideal ergänzen. Außerdem unterstützt I-Perf Optionen wie etwa die Angabe des Protokolls, das für den Performancetest zu nutzen ist. Mit den Kommandos »iperf -s -f M -m -i 10« auf der Server-Seite und »iperf -c IP_der_Server-VM -t 30 -f M« auf dem Client lässt sich ein 30 Sekunden dauernder Bandbreitentest starten. Alle 10 Sekunden gibt I-Perf dabei einen Zwischenstand aus. Achtung: Die Server-Seite reportiert anschließend vier Werte (Abbildung 1). Der vierte und letzte Wert beschreibt den Durchschnitt aus den vorangegangenen Messungen.
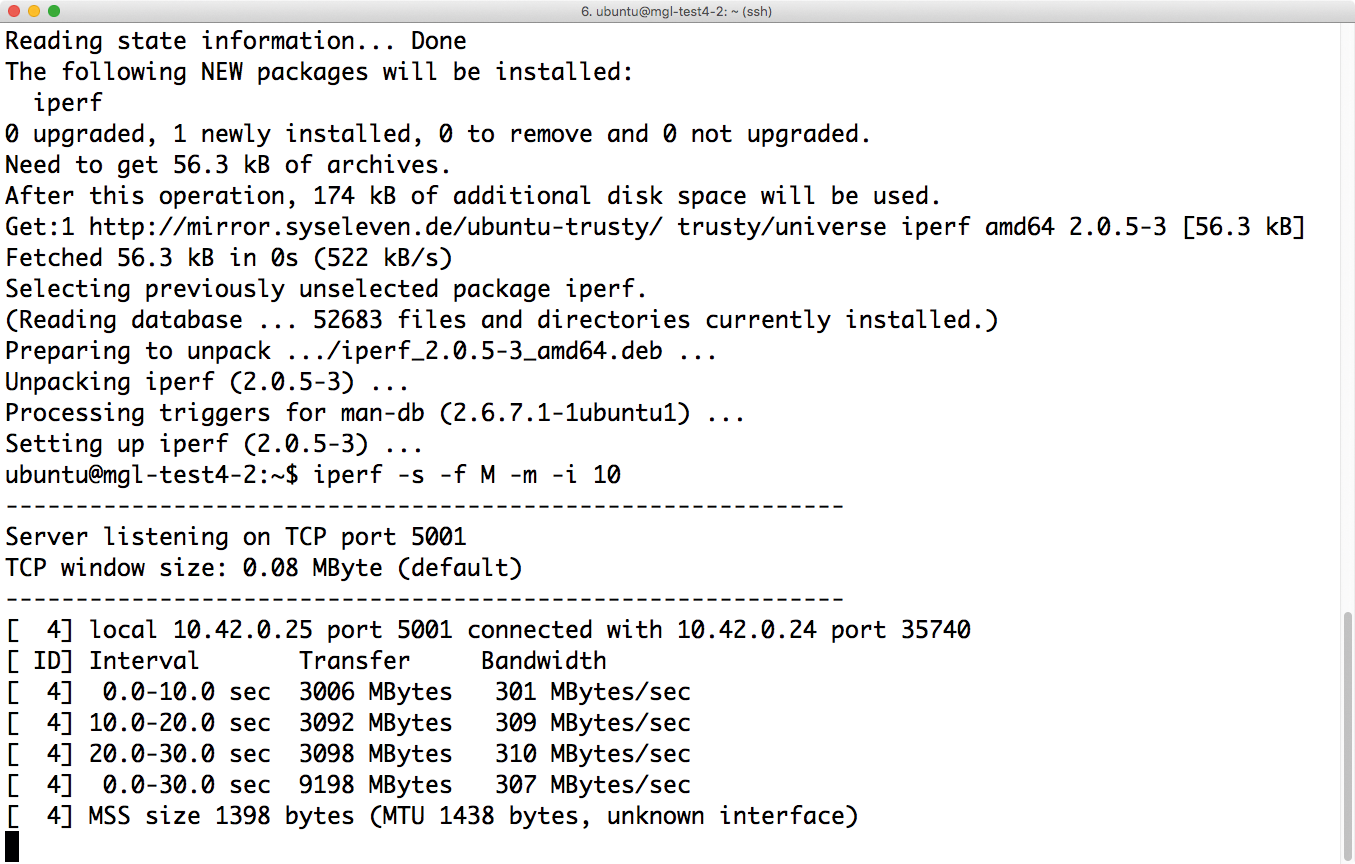
Abbildung 1: I-Perf eignet sich prima, um Netzwerke in der Cloud zu messen – hier am Beispiel Durchsatz.
Durchsatz mit der Außenwelt
Die Frage, wie viel Traffic sich zwischen einer VM und der Außenwelt realisieren lässt, ist oft noch wichtiger als die nach dem Durchsatz zwischen VMs. Denn die meisten Kundensetups bewegen größere Datenmengen nach außen als zwischen den Instanzen hin und her. Anbieter realisieren den Internetzugriff in Clouds meist über Gatewayknoten, die leicht zum Nadelöhr werden.
Auch das Messen dieser Bandbreite bereitet keine nennenswerten Probleme: Abermals leistet I-Perf wertvolle Dienste. Anbieter oder Kunde kommen wie folgt schnell zu aussagekräftigen Werten: Zunächst ist innerhalb der Cloud eine VM zu starten, in der ein I-Perf-Server läuft. Die Parameter lassen sich vom Test zwischen VMs übernehmen.
Danach bekommt die VM mit dem I-Perf-Server eine öffentliche IP-Adresse: In Open Stack heißen diese flexiblen öffentlichen IP-Adressen Floating-IPs. Die Network Address Translation der Floating-IP in die private IP der I-Perf-VM passiert im Innern der Cloud. Schließlich muss sichergestellt sein, dass ein I-Perf-Client außerhalb des VM-Netzwerks sich mit der Serverinstanz verbinden kann.
In Open Stack ist jede virtuelle Maschine einer Security Group zugeordnet, für die Firewallregeln gelten. Ab Werk sind die Security Groups aber total abgeschirmt, nicht mal ICMP- oder SSH-Verbindungen sind erlaubt. Damit der I-Perf-Test klappt, muss für die Security Group, zu der die Server-VM gehört, der Port 5001 freigegeben sein. Dann kann das Messen losgehen: Der Befehl ist der gleiche wie oben beim Inter-VM-Benchmark, aber anstelle der privaten IP der VM ist die zuvor zugewiesene Floating-IP zu nutzen. Am Ende erhalten User wie Anbieter einen Durchschnittswert, der die verfügbare Bandbreite im Mittel angibt.
VM-Durchsatz optimieren
Wenn Anbietern und Kunden klar ist, welchen Durchsatz das Setup bieten kann, geht es an die Verbesserung der Situation. Freilich hat der Anbieter deutlich mehr Möglichkeiten als der Nutzer: Wenn etwa der Durchsatz zwischen zwei VMs nicht den Erwartungen entspricht, ist meist die physische Hardware nicht leistungsfähig genug. So machen Hypervisor-Hosts, die nur mit Gigabit-LAN angebunden sind, keine Freude – 10 GBit pro Sekunde sollten es sein. Eventuell ist durch mehrere Links und Bonding die Situation so zu verbessern, dass der Durchsatz genügt.
Gleiches gilt für die Netzwerkgateways: Reicht ihr Durchsatz nicht aus, sind potentere Netzwerkkarten der erste logische Schritt. Alle gängigen Clouds unterstützen auf Ebene der Netzwerkgateways außerdem das Skalieren in die Breite: Wenn sich die Last eines Setups auf fünf statt auf drei Knoten verteilt, bekommen alle VMs ein größeres Stück Durchsatz ab.
SDN-Konfiguration
Ein häufiges Problem bei Cloud-Computing-Setups sind falsche Einstellungen in der SDN-Konfiguration. Klassisch teilt sich das Netz in Underlay und Overlay; das Underlay bezeichnet die physische Hardware, das Overlay die Tunnelmechanismen, die die jeweilige SDN-Lösung auf der Hardware nutzt.
Fast alle SDN-Anbieter empfehlen, auf der physischen Ebene Jumbo-Frames zu nutzen. Das muss der Admin jedoch sowohl auf den Switches als auch auf den Netzwerkkarten innerhalb der Hypervisoren konfigurieren. Durch die größeren Frames sinkt dann der Overhead im TCP/IP-Stack deutlich, und das macht sich beim Durchsatz klar bemerkbar.
Der Kunde hat weniger Möglichkeiten, den Durchsatzes zu verbessern, sie sind aber trotzdem vorhanden. Gerade die MTU-Thematik lässt sich auch innerhalb von VMs nutzen: Setzt der eigene Anbieter auf Ebene der Hardware auf Jumbo-Frames, lässt sich der Durchsatz zwischen VMs nämlich mit höheren MTU-Werten steigern (Abbildung 2). Das ist aber nur bei VMs sinnvoll, die nicht mit Clients in der Außenwelt reden, denn dabei würde der Gatewayknoten der Cloud die Pakete höchstwahrscheinlich so oder so zurechtstutzen.
Abbildung 2: Anbieter sollten darauf achten, dass sie im Underlay eine MTU von 9000 nutzen – also Jumbo-Frames. So hält sich der Overhead in Grenzen.
Hilfe von der Hardware
Auch die Latenz spielt eine Rolle, wenn es um Netzwerkperformance geht. Besonders die Netzwerkkarten sind wichtig – und dort die Funktionen, die die verbauten Netzwerkchips unterstützen. Praktisch alle SDN-Lösungen für Open Stack setzen im Hintergrund auf VXLAN, um eine saubere Trennung zwischen Overlay und Underlay zu erzielen. Ein Paket, das von einer VM auf Host 1 zu einer VM auf Host 2 fließt, passiert dabei mehrere Netzwerkstacks.
Die Verkapselung zu VXLAN findet auf Software-Ebene statt – wenn die Hardware diese Funktion nicht bietet. NICs, die das so genannte VXLAN-Offloading beherrschen, gibt es aber mittlerweile in guter Qualität. Der Einsatz entsprechender Karten sorgt in vielen Fällen für geringere Latenzen, weil die Hardware die VXLAN-Verkapselung übernimmt und die einzelnen Betriebssystemschichten an dem Vorgang nicht mehr beteiligt sind. So schafft es der Anbieter, auf der Latenz-Ebene zumindest eine kleine Optimierung zu erreichen. Wer noch bessere Latenzen braucht, kommt um Spezialhardware wie Infiniband nicht herum.
Latenz messen
Ähnlich wie das Optimieren ist auch das Messen der Netzwerklatenz in Clouds eine Herausforderung. Ein simples Ping liefert oft trügerische Resultate in Form besonders hoher Latenzen. Das liegt daran, dass viele SDN-Lösungen beim ersten Aufbau einer Verbindung intern einen so genannten Flow anlegen – und das dauert. Beim Ping mit ICMP ist aber jeder Request eine neue Verbindung.
Eine Alternative wäre etwa »owping« , das aber NTP-Zeitangaben braucht, die in VMs nicht zuverlässig verfügbar sind. Letztlich muss sich der Admin also selbst eine Lösung in Shell oder in Python basteln, die per UDP Timestamps zwischen den Hosts hin und her schickt und dabei den Zeitunterschied gleich mitbestimmt – alles andere als trivial.
Wenn beim Latenztuning das Ende der Fahnenstange erreicht ist, aber bei den eigenen VMs noch immer nicht die gewünschte Performance ankommt, sind konzeptionelle Änderungen möglicherweise noch eine Option. Ein Beispiel im Hinblick auf das zuvor schon angesprochene Delay beim Anlegen von Flows: Nur das erste Paket ist hier langsam, alle weiteren Pakete gehen praktisch mit Ethernet-Latenz übers Kabel. Das beißt sich mit einer Webanwendung, die für jeden einzelnen Datenbank-Request eine eigene Verbindung aufbaut.
Im Beispiel könnte Max Scale (siehe den entsprechenden Artikel in dieser Ausgabe) das Problem lösen: Denn Max Scale kann in der aktuellen Version einen Pool persistenter Verbindungen für lokale Applikationen aufbauen. Läuft auf jeder Webserver-VM Max Scale und bauen die Clients ihre Datenbankverbindung über die Localhost-Adresse auf, wäre das Latenzproblem zu umgehen. Doch solche Ansätze sind hochspezifisch und setzen entsprechende Software voraus. Wer geringe Latenzen und viel Durchsatz in der Cloud will, kommt auf lange Sicht um sie aber nicht herum.
Storage: Das Menetekel
Neben der Netzwerkperformance spielt in Clouds die Storageperformance die größte Rolle. Im Linux-Magazin 3/2016 gingen Thorsten Stärk und Benjamin Schweizer bereits ausführlich auf die Frage ein, wie sich Performance sinnvoll und zielgerichtet messen lässt [2]. In diesem Artikel geht es dagegen mehr ums Optimieren. Für das simple Messen eignen sich praktisch alle im genannten Artikel erwähnten Werkzeuge: »dd« mit den richtigen Parametern, »fio« , »bonnie++« oder »iops« .
Beim Optimieren liegt der Ball zuerst im Feld des Plattformanbieters: Wie lässt sich Storageperformance sinnvoll an VMs innerhalb der Cloud weitergeben? Dabei spielen zwei Typen von Storage eine Rolle. Einerseits gibt es den Ephemeral-Speicher, der als volatiler Speicher konzipiert ist. Starten Nutzer eine VM in einer Cloud, ohne andere Vorgaben zu machen, landet das gesamte Root-Dateisystem auf jenem Speichertyp (Abbildung 3). Volatil meint, dass Ephemeral-Speicher nicht persistent ist. Löscht ein Kunde seine VM, ist das zugehörige Ephemeral-Image weg.

Abbildung 3: Clouds nutzen für die Rootdisks von Platten oft volatilen Speicher (Ephemeral Disk) – hier am Beispiel von Open Stack.
Im Hinblick auf die Performance des Ephemeral-Speichers ist deshalb vorrangig die Leistungsfähigkeit der lokalen Platten in den Hypervisoren relevant. Landet das Ephemeral-Verzeichnis auf einer SSD, nutzt es deren Performance.
Weil Kunden darüber hinaus zwingend eine Möglichkeit brauchen, in einer Cloud auch persistenten und redundanten Speicher zu nutzen, existiert neben Ephemeral-Speicher auch Volume-Speicher – der ist persistent. Anbieter realisieren diesen Speicher im Hintergrund meist mittels einer speziellen Speichertechnik, zum Beispiel als typischen Objektspeicher (Abbildung 4).
Abbildung 4: Wer in Clouds persistenten Speicher braucht, nutzt Volumes statt Ephemeral Disks.
Die Frage nach Performance hat hier mehrere Facetten: Sie hängt einerseits von der Speichertechnik selbst ab und andererseits von der Anbindung zwischen Speicher und Ziel-Host, also dem Host mit den VMs. Klassischer Vertreter der Objektspeicher ist Ceph: An Ceph lassen sich mehrere Probleme von Cloudspeicher exemplarisch gut dokumentieren.
Ceph: Durchsatz, Latenz und Flash
Objektspeicher nutzen die Netzwerkinfrastruktur. Das Thema Durchsatz ist damit im Grunde schon geklärt, denn hier verhält es sich ähnlich wie bei der Netzwerkperformance in der Cloud selbst: Je mehr Bandbreite vorhanden ist, desto mehr Requests kann der Objektspeicher bearbeiten.
Bei den meisten Workloads spielt der Storage-Durchsatz aber gar keine große Rolle. Viel wichtiger ist auch hier die Latenz. Paradebeispiel dafür sind Datenbanken: Sie verursachen in der Regel keinen hohen Durchsatz, aber die Latenz für einzelne Requests macht sich deutlich bemerkbar.
Bei Ceph ist da zunächst die Latenz bei regulären Ceph-Zugriffen. Weil Ceph sich nur im synchronen Modus betreiben lässt, verzögert sich jeder Schreibzugriff um die Latenz zwischen dem Client und der Ceph-Platte (OSD), auf die er schreibt. Hinzu kommt die Latenz, die im Hintergrund bei der Synchronisation der Daten im Ceph-Cluster anfällt und die entsteht, während der Client Objekte auf das erste OSD lädt.
Schließlich entsteht auch bei der Verarbeitung von Daten durch Ceph weitere Latenz, die es letztlich an den Client weitergibt. Dabei ist vor allem die Zeit wichtig, die ein Ceph-Client braucht, um sich für einzelne Binärobjekte die passende Platte zu errechnen. Das tut Ceph bekanntlich mit einem Algorithmus (Crush, [3]), der ausgesprochen komplex ist und gern viel Zeit frisst. Für den Admin ergibt sich damit mindestens ein Ansatzpunkt, um Latenz zu optimieren.
OSD-Journale auf schnellen SSDs
Ein Trick, der sich in der Ceph-Welt herumgesprochen hat, ist der Betrieb von schnellen SSDs als Cache für OSDs. Ceph legt Daten nicht direkt auf den OSDs ab, sondern in dem diesen vorgelagerten OSD-Journal. Der Clou: Das Journal eines OSD muss nicht zwingend auf diesem beheimatet sein. Indem man das Journal also auf eine SSD auslagert, erbt jeder Schreibzugriff auf ein Ceph-OSD die Performance, die jene SSD liefert.
Aus Kostengründen sieht das typische Setup meist vor, mehrere Ceph-Journale auf eine SSD zu packen. An dieser Stelle sollte der Nutzer es nicht übertreiben, denn bis heute kann Ceph ein OSD nicht mehr nutzen, wenn dessen Journal weg ist. Wer also Journale von zehn OSDs auf einer SSD hat, verliert dann zehn Platten aus dem Cluster.
Die anderen beiden Faktoren, die die Latenz bestimmen, lassen sich hingegen kaum beeinflussen. Gerade die Latenz, die Ceph selbst verursacht, erweist sich im Cloudkontext als großes Problem: Eine Datenbank, deren Daten etwa auf einem Ceph-Volume liegen, kommt über wenige Hundert IOPS nicht hinaus. Kein Vergleich mit einem MySQL auf echtem Blech. Die Werte, die mit MySQL auf einer Fusion-IO-Karte möglich sind, wirken vor diesem Maßstab fast fantastisch. Bei anderen Objektspeichern ist das übrigens kaum anders – es variiert das Ausmaß der Katastrophe, aber das Problem bleibt grundsätzlich gleich.
Kunden Alternativen bieten
Die schlechte Nachricht für Kunden ist, dass sie ihrem Cloudanbieter hier beinahe hilflos ausgeliefert sind. Nur wenn dieser zusätzliche Angebote hat, um etwa eine Datenbank auf schnellem lokalen Speicher zu betreiben, gibt es einen Ausweg aus dem Dilemma. Die großen Cloudanbieter präsentieren daher Database-as-a-Service-Angebote (DBaaS), die intern letztlich auf eben solchen schnellen lokalen Speicher setzen.
DBaaS richtig implementieren ist leider nicht so einfach, wie es sich zunächst anhört: Sobald etwa synchrone Replikation im Hintergrund notwendig ist, kommen zwangsläufig Themen wie Infiniband wieder auf den Tisch – nur damit sind geringe Latenzen oder jedenfalls deutlich geringere Latenzen als bei Ethernet überhaupt machbar.
Wer als Anbieter eine private oder öffentliche Cloud baut, muss sich also zuerst fragen, welches Level an I/O-Performance er seiner Kundschaft anbieten möchte. Denn danach richtet sich der Aufwand, der notwendig ist, um das Problem zu lösen.
Performance bei Public Clouds
Bis hierhin bezog sich dieser Artikel vornehmlich auf private Clouds oder kleine Public Clouds. Erwähnenswert sind aber auch die großen öffentlichen Clouds, etwa das Angebot von Amazon oder der öffentliche Clouddienst von Rackspace. Hier ist der Kunde beinahe vollständig den vorhandenen Strukturen des Anbieters ausgeliefert. Zwar kann er vergleichende Messungen durchführen, doch ändern kann er an den Resultaten in der Regel nichts.
Die Struktur des Setups und die Art des Deployments sind hier noch wichtiger als bei den privaten Clouds. Schon die Frage, in welcher Amazon-Region etwa eine VM mit einem spezifischen Dienst ausgerollt ist, kann mitentscheidend für die erreichbare Performance sein.
Wer auf die großen Public Clouds setzt, sollte sich also schon im Vorfeld des Deployments Gedanken über besondere Performance-Ansprüche seiner Anwendung machen. Braucht eine Applikation etwa besonders viele CPU-Ressourcen? Verlangt sie viel RAM und Disk-I/O oder ist das Netzwerk der Engpass? Die folgenden Tipps beziehen sich auf Amazon, lassen sich aber auch auf andere große Public Clouds übertragen.
Eine Frage des Typs
Amazon EC2 bietet eine ganze Reihe vorgefertigter Instanzen-Arten, etwa die M- und T-Typen, die sich an allgemeine Workloads richten, oder die C- und R-Typen, die für CPU- oder speicherintensive Aufgaben besser geeignet sind. Wer weiß, dass in einer Cloud-VM sehr viel CPU-Leistung nötig ist, der sollte also den Typ C3 einem allgemeinen Typ wie M3 vorziehen (Abbildung 5).
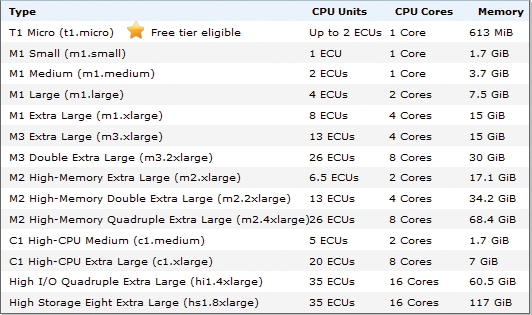
Abbildung 5: Bei Amazon hat schon der gewählte Instanzentyp erheblichen Einfluss darauf, wie gut eine VM später performt.
Auch die Instanzen-Generationen spielen in diesem Zusammenhang eine wichtige Rolle: Eine Instanz des Typs M1.large ist einer Instanz des Typs M3.large in Sachen CPU-Performance nämlich hoffnungslos unterlegen und obendrein auch noch deutlich teurer. Wer kann, migriert also zu den Instanzen der neueren Generationen. Dass auch die Dimensionierung einer Instanz wichtig ist, versteht sich von selbst: Mit einer C3.small werden sich vermutlich keine Berge versetzen lassen, eine C3.xlarge hingegen hat schon deutlich mehr Dampf unter der Haube.
SSDs und SR-IOV
Große Bedeutung kommt den Volumes von Amazons Elastic Block Storage (EBS) zu, die innerhalb von Amazon persistente Daten speichern. Abhängig vom Preis unterscheidet Amazon zwischen Volumes auf rotierenden Disks, provisionierten SSDs und General-Purpose-SSDs [4]. Letztere sind ein guter Kompromiss: Sie sind zwar nicht so schnell wie ihre provisionierten Kollegen, kosten dafür aber auch um ein Vielfaches weniger. Sobald eine virtuelle Maschine eine solche General-Purpose-SSD als Volume für ihr Root-Dateisystem bekommt, erhöht sich der verfügbare Durchsatz deutlich.
Wer Netzwerk-intensive Anwendungen auf Amazon betreibt, braucht Instanzen, die “Single Root I/O Virutalization” nutzen, im Amazon-Sprech SR-IOV. Gemeint sind Instanzen, die Amazon auf speziellen physischen Hosts betreibt und die dort besondere Bedingungen vorfinden. Die Instanzen-Typen, die diese Funktionen bieten, sind R3, C3 und I2.
Ganz unabhängig von Instanzentypen bietet Amazon mehrere Zusatzdienste, die ausgesprochen nützliche Features bieten: Als Cloudfront etwa ist bei Amazon ein eigenes Content Delivery Network (CDN) verfügbar, das auf Performance und Latenz optimiert ist. Es kann sich auszahlen, Inhalte nicht auf den eigenen VMs innerhalb von AWS vorzuhalten, sondern dafür das CDN von Amazon zu verwenden.
Ähnlich verhält es sich mit dem Elastic Load Balancing: Statt einer VM mit integriertem Load Balancer kann ein von Amazon gestellter Load Balancer sich des Themas annehmen und etwa SSL deutlich effizienter behandeln als das ein selbst gebauter HA-Proxy könnte.
Fazit: Alles sehr kompliziert
Performance ist in der Cloud ein bedeutsamer Faktor. Wer darauf aus ist, der muss sich im ersten Schritt zunächst nach dem Workload seiner Anwendung fragen. In den meisten Fällen lässt sich hohe Performance in der Cloud nämlich durch geschickte Kombination von Werkzeugen erreichen, die der Anbieter für die Nutzer zur Verfügung stellt.
Wer dagegen selbst eine Cloud betreibt, muss schon bei deren Planung und der eingesetzten Hardware die richtigen Entscheidungen treffen. Probleme etwa bei der Storage-Performance lassen sich später nur schwer und nur mit sehr viel Aufwand wieder korrigieren.
Infos
- I-Perf: https://iperf.fr
- Stärk/Schweizer: Wer misst, misst Mist?: https://www.linux-magazin.de/Ausgaben/2016/03/I-O-Benchmarking
- Crush: http://docs.ceph.com/docs/master/rados/operations/crush-map
- Amazon-Erläuterungen zu verfügbaren SSDs: http://docs.aws.amazon.com/de_de/AWSEC2/latest/UserGuide/EBSVolumeTypes.html
Der Autor

Martin Gerhard Loschwitz arbeitet als Cloud Architect bei Sys Eleven. Er beschäftigt sich dort intensiv mit den Themen Open Stack, Distributed Storage und Puppet. Außerdem pflegt er in seiner Freizeit Pacemaker für Debian.





