
© almoond, 123RF
Cloudstorage und Hyperconverged-Lösungen ergänzen den klassischen Storage – und schon seit Längerem verdrängen SSDs die traditionellen Festplatten. Oft muss sich der Admin dabei fragen, wie er die Leistungsfähigkeit einer konkreten Lösung messen kann. Aber Achtung: Benchmarks bergen Fallen.
Dem Admin, der eine konkrete Storagelösung begutachten soll, stellen sich viele Fragen. Zunächst: Was ist Storageperformance überhaupt? Den meisten Admins fällt dazu sicherlich zuerst eine Reihe von I/O-Leistungskennzahlen ein (Key Performance Indicators, KPIs), von denen mal die eine, mal eine andere im Vordergrund steht. Doch diese Kennzahlen beschreiben verschiedene Dinge: Mal geht es um das Dateisystem, mal um den unformatierten Storage, mal geht es ums Lesen, mal ums Schreiben. Mal ist ein Cache involviert, ein andermal nicht. Und dann werden die verschiedenen Kennzahlen auch noch von verschiedenen Tools gemessen.
Wer sich bis hierher durchgekämpft und das Was und Womit geklärt hat, steht vor dem nächsten Problem: Welche Komponente ist der Flaschenhals, der die Leistung des Gesamtsystems begrenzt? Und welche Storageperformance braucht seine Anwendung überhaupt? Der vorliegende Artikel will dem Admin helfen, all diese Fragen zu beantworten.
Grundlagen
Eine I/O-Anfrage durchläuft im Betriebssystem mehrere Schichten (Abbildung 1). Die Schichten bauen jeweils aufeinander auf. So basiert die Anwendungs- und Dateisystem-Schicht auf der Schicht der Blockvirtualisierung (mit Technologien wie LVM, DRBD, »mdadm« , Multipathing, »devmapper« , …). Näher an der Hardware sind die Block-Schicht, die SCSI-Schichten und schließlich die Geräte selbst (Raid-Controller, HBAs, und so weiter).

Abbildung 1: Die für einen I/O-Benchmark relevanten Schichten.
Einige der Schichten in Abbildung 1 haben ihren eigenen Cache. Jeder kann zwei Aufgaben erfüllen: Das Puffern von Daten, um dadurch eine höhere Leistung bieten zu können, als mit dem physischen Gerät alleine möglich wäre, und das Zusammenlegen von Anfragen, um aus vielen kleinen wenige große zu machen. Dies gilt sowohl für das Lesen als auch fürs Schreiben. Beim Lesen gibt es eine weitere Cachefunktion, nämlich das vorausschauende Lesen (Read ahead), das benachbarte Datenblöcke auch ohne konkrete Anforderung in den Cache holt, weil sie wahrscheinlich später noch benötigt werden.
Prozessor- und Dateisystem-Cache sind flüchtig, daher ist nur nach einer Syncoperation garantiert, dass alle Daten sicher gespeichert sind. Der Cache der Blockvirtualisierungsschicht hängt von der verwendeten Technik ab (DRBD, LVM oder ähnliche). Die Caches von Raid-Controllern und externem Storage sind meist batteriegepuffert. Was hier angekommen ist, kann also als gesichert gelten und überlebt einen Reboot.
In diesem Artikel bezeichnet der Begriff Storage-Benchmark einen I/O-Benchmark, der das Dateisystem umgeht und direkt auf die darunterliegende Schicht zugreift (etwa auf die Gerätedateien wie »/dev/sda« oder »/dev/dm-0« ).
Ein Dateisystem-Benchmark spricht dagegen das Dateisystem an, nutzt aber nicht notwendigerweise den Dateisystemcache. Die Nutzung dieses Cache wird als Buffered I/O bezeichnet, seine Umgehung als Direct I/O. Ein reiner Dateisystem-Benchmark lässt die unter dem Dateisystem liegenden Schichten unberührt. So ist es möglich, Dateisysteme miteinander zu vergleichen.
Kennzahlen
Durchsatz ist sicherlich die prominenteste Kennzahl. Als Synonyme gelten die Begriffe Bandbreite oder Transferrate. Dabei handelt es sich um die Menge an Bytes, die ein Akteur pro Zeiteinheit lesen oder schreiben kann. Daher bestimmt der Durchsatz etwa beim Kopieren großer Dateien die Dauer des Vorgangs.
IOPS (Input/Output-Operations per Second) als Kennzahl misst die Anzahl der Schreib-/Lese-Operationen, die ein Storagesystem pro Zeit leisten kann. Eine solche Operation könnte – zum Beispiel für SCSI-Storage – lauten: “Lese Block 0815 von LUN 4711.” Diese Operation kostet Zeit, was die mögliche Anzahl der Operationen pro Zeiteinheit begrenzt, selbst wenn der theoretisch mögliche maximale Durchsatz noch nicht erreicht sein sollte. IOPS sind vor allem dort interessant, wo viele relativ kleine Blöcke zu verarbeiten sind, wie das häufig bei Datenbanken der Fall ist.
Latenz ist die Verzögerungszeit zwischen dem Auslösen einer I/O-Operation und dem folgenden Commit, der bestätigt, dass die Daten tatsächlich auf dem Speichermedium gelandet sind.
CPU-Zyklen pro I/O-Operation ist ein wenig beachteter Indikator, aber wichtig, da er angibt, wie stark die CPU durch I/O-Operationen belastet wird. Am Beispiel Software-Raid wird dies deutlich: Für ein Raid 5 in Software werden für alle Blöcke Prüfsummen berechnet, und das beansprucht die CPU. Ebenso sind fehlerhafte Treiber dafür berüchtigt, Rechenleistung zu verbrennen.
Zwei Eselsbrücken helfen beim Merken. Die eine: Der Durchsatz entspricht der Menge Wasser, die pro Sekunde in einem Fluss fließt. Die Latenz entspricht der Zeit, die ein Stock braucht, um auf dem Gewässer eine definierte Distanz zurückzulegen. Die zweite: Die Blockgröße entspricht dem Ladevolumen eines Fahrzeugs. Dann ist ein Sportwagen zwar gut, um einzelne Gegenstände möglichst schnell von einem Ort zum anderen zu bringen (geringe Latenz). Aber in der Praxis wird man für einen Umzug einen langsameren LKW wählen, der jedoch aufgrund des größeren Ladevolumens mehr Durchsatz bietet.
Einflussfaktoren
Die Kennzahlen hängen ab von mehreren Einflussgrößen ab (Abbildung 2):
- Von der Hardware,
- der Blockgröße,
- dem Zugriffsmuster (Schreib-/Lese-Anteil und Anteil sequenzieller und zufälliger Zugriffe),
- der Verwendung der verschiedenen Caches,
- dem verwendeten Benchmarktool,
- der Parallelisierung von I/O-Operationen.
Die Storagehardware bestimmt selbstverständlich die Messergebnisse. Aber auch die Leistung von Prozessoren und RAM kann in einem Storagebenchmark einen Engpass bilden. Dieser Effekt kann bei der Programmierung der Benchmarktools nie ganz ausgeschlossen werden, weshalb man beim Vergleichen von I/O-Benchmarkergebnissen, die mit unterschiedlichen CPUs oder RAM-Konfigurationen gefahren wurden, Vorsicht walten lassen sollte.
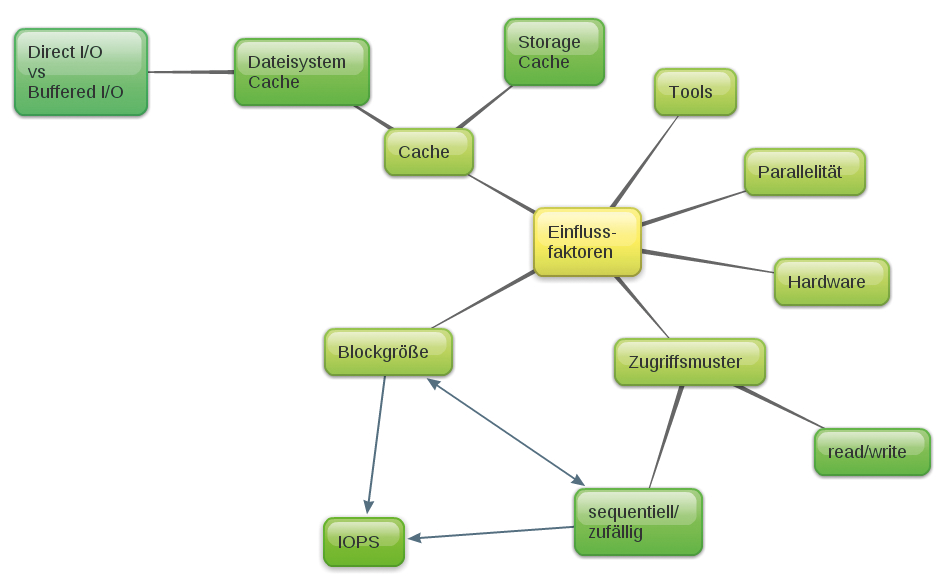
Abbildung 2: Mindmap mit Einflussfaktoren beim Benchmark und deren Assoziationen.
Die Blockgröße entscheidet darüber, wie viele Daten von einer I/O-Operation gelesen oder geschrieben werden. Eine Halbierung der Blockgröße bei gleicher Datenmenge führt zu einer Verdopplung der benötigten I/O-Operationen. Benachbarte I/O-Operationen werden zusammengelegt (Merge). Innerhalb eines Blocks wird immer sequenziell zugegriffen, daher tritt die zufällige Natur der Zugriffe bei sehr großen Blockgrößen in den Hintergrund. Die gemessenen Werte ähneln dann denen des sequenziellen Zugriffs.
Jede Operation kostet einen gewissen Aufwand, daher ergeben sich bessere Durchsatzwerte bei größeren Blöcken. Abbildung 3 zeigt den Durchsatz in Abhängigkeit von der Blockgröße auf einer Festplatte. Die Statistik ist mit dem Programm IOPS entstanden, das Random Reads durchführte. Abbildung 4 zeigt eine SSD, bei der die Seek-Zeiten des Lesekopfs entfallen. Die Blockgröße kann nicht beliebig groß sein – Linux limitiert sie durch den Wert in »/sys/block/Device/queue/max_sectors_kb« .
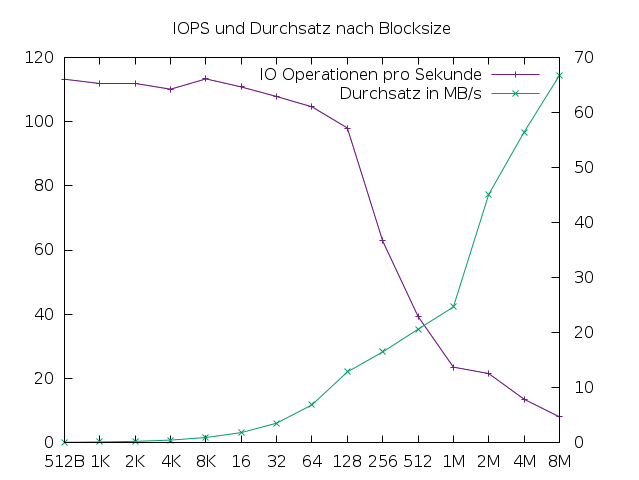
Abbildung 3: Operationen und Durchsatz mit steigenden Blockgrößen auf einer magnetischen Festplatte.
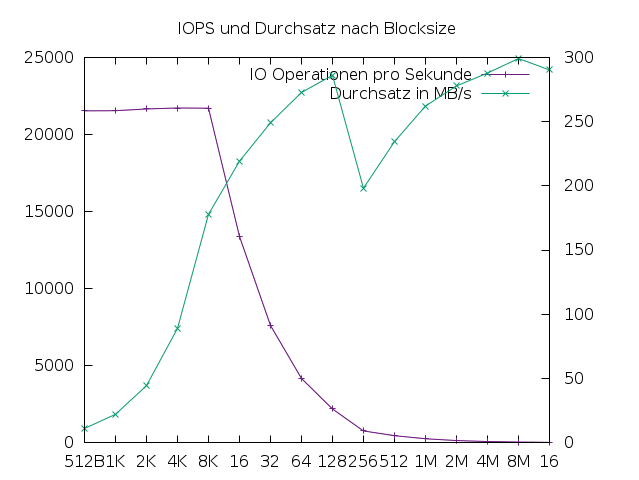
Abbildung 4: Operationen und Durchsatz mit steigenden Blockgrößen auf einer SSD-Festplatte.
Lesen geht im Allgemeinen schneller als Schreiben. Zu beachten ist aber der Einfluss der Caches. Beim Lesen füllen sich Storage- und Filesystem-Caches, wiederholte Zugriffe laufen danach schneller ab. Im Betrieb ist das wünschenswert, beim Benchmarken führt eine Vorgeschichte allerdings zu Messfehlern. Beim Schreiben verhalten sich die Caches genau umgekehrt: Zunächst wird mit hohem Durchsatz in die Caches geschrieben, später aber müssen deren Inhalte auf die Platte gelangen. Das führt zu einem unvermeidlichen Performance-Einbruch und ist beim Benchmarken auch zu beachten.
Read-ahead-Zugriffe sind eine weitere Form der Optimierung beim Lesen. Die spekulativen Operationen lesen mehr als angefordert wurde, denn wahrscheinlich wird der folgende Block ohnehin als Nächstes gebraucht.
Elevator Scheduling führt beim Schreiben dazu, dass Sektoren in optimierter Reihenfolge auf das Medium gelangen.
Dateisystem-Cache. Ist er im Spiel, spricht man von Buffered I/O, wird er umgangen von Direct I/O. Mit Buffered I/O können Daten aus dem Dateisystem-Cache bei einem Rechnerausfall verloren gehen. Mit Direct I/O kann das nicht passieren, aber die Auswirkung auf die Schreibperformance ist drastisch und lässt sich mit »dd« demonstrieren, wie Listing 1 zeigt.
Listing 1
Buffered und Direct I/O
01 # dd of=datei if=/dev/zero bs=512 count=1000000 02 1000000+0 records in 03 1000000+0 records out 04 512000000 bytes (512 MB) copied, 1.58155 s, 324 MB/s 05 06 # dd of=datei if=/dev/zero bs=512 count=1000000 oflag=direct 07 1000000+0 records in 08 1000000+0 records out 09 512000000 bytes (512 MB) copied, 49.1424 s, 10.4 MB/s
Wer Schreib- und Lesecache für Benchmark-Zwecke leeren will, kann dies tun mit dem Kommando:
sync; echo 3 > /proc/sys/vm/drop_caches
Sequenzielle Zugriffe sind schneller als zufällige, weil sie immer benachbart sind und sich mehrere Operationen mit kleiner Blockgröße zu wenigen mit großer Blockgröße im Filesystemcache zusammenlegen lassen. Zudem entfallen die Zeiten für die Neupositionierung des Lesekopfs. Die Zusammenlegung von I/O-Blöcken kann der Admin mit dem Kommando »iostat -x« beobachten. Voraussetzung ist der Einsatz des Dateisystem-Cache. »wrqm/s« steht für “Write requests merged per second”. Das Beispiel in Listing 2 legt 259 Schreibanfragen pro Sekunde (»w/s« ) zu 28 Schreiboperationen (»wrqm/s« ) zusammen.
Listing 2
Zusammenlegen von I/Os
01 Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz ... 02 sdb 0.00 28.00 1.00 259.00 0.00 119.29 939.69 ...
Parallelität. Auf einen Enterprise-Storage können mehrere Rechner zugreifen und auf eine interne Festplatte können mehrere Threads zugreifen. Nicht jeder Thread liest immer, daher sieht man bei der Erhöhung der Thread-Anzahl im Allgemeinen zunächst eine höhere CPU-Auslastung und höheren Gesamtdurchsatz. Je mehr Threads zugreifen, desto größer wird aber auch der Overhead, sodass sich die kumulierte Leistung wieder verringert. Es existiert eine optimale Anzahl an Threads, wie in den Abbildungen 5 und 6 zu sehen ist. Je nach Applikation interessiert die Single-Thread-Performance oder die Gesamtperformance des Storagesystems. Besonders relevant ist dieser Gegensatz bei Enterprise-Storages, die in einem Storage Area Network (SAN) arbeiten.
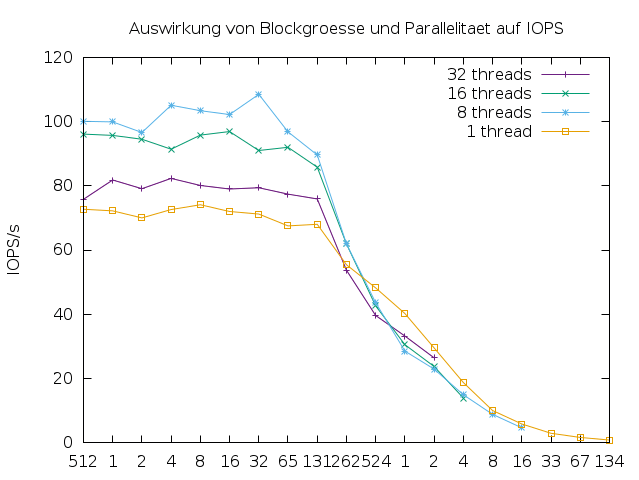
Abbildung 5: I/O-Operationen nach Blockgröße und Parallelität auf einer magnetischen Festplatte, gemessen mit dem Programm IOPS.
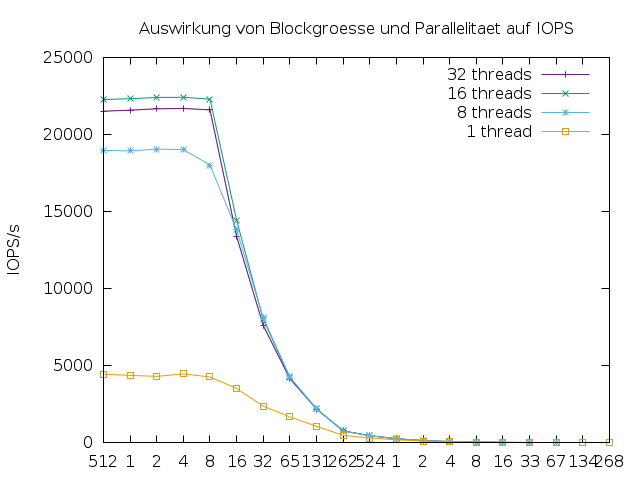
Abbildung 6: Operationen nach Blockgröße und Parallelität auf einer SSD, gemessen mit dem Programm IOPS.
Benchmarktools selbst üben auch einen Einfluss auf das Messergebnis aus. Unterschiedliche Benchmarkprogramme messen, so sehr man es beklagen mag, unterschiedliche Werte bei sonst gleichen Konstellationen. Im vorliegenden Test maß das Tool IOPS 20 Prozent mehr I/O-Operationen pro Sekunde als IO Meter – bei gleicher Thread-Anzahl und jeweils hundertprozentig zufälligem lesenden Zugriff. Hinzu kommen zufällige Schwankungen der Messergebnisse, die aus vielen Einflüssen herrühren, etwa dem Status parallel laufender Programme oder des Betriebssystems, die nicht bei jedem Durchlauf exakt wiederholbar sind.
Das Programm IOPS
Das Programm IOPS [1] zeigt schnell und einfach, wie viele I/O-Operationen pro Sekunde eine Platte in Abhängigkeit von Blockgröße und Parallelität bewältigen kann. Es liest zufällige Blöcke unter Umgehung des Dateisystems. Es kann auf ein virtualisiertes Blockgerät wie etwa »/dev/dm-0« oder auf ein reales Blockgerät wie »/dev/sda« zugreifen.
IOPS ist in Python geschrieben und schnell installiert:
cd /usr/local/bin curl -O https://raw.githubusercontent.com/cxcv/iops/master/iops chmod a+rx iops
In Listing 3 läuft IOPS mit 32 Threads auf einer langsamen Festplatte. IOPS liest hier zufällige Blöcke und verdoppelt die Blockgröße Stück für Stück. Für kleine Blöcke (512 Bytes bis 128 KBytes) bleibt die Anzahl der möglichen Operationen nahezu konstant, aber die Transferrate verdoppelt sich parallel zur Blockgröße. Das liegt am Read-ahead-Verhalten der getesteten Platte – sie liest immer 128-KByte-Blöcke, auch wenn weniger Daten angefragt wurden.
Listing 3
IOPS auf Festplatte
01 # iops /dev/sdb 02 /dev/sdb, 1.00 TB, 32 threads: 03 512 B blocks: 76.7 IO/s, 38.3 KiB/s (314.1 kbit/s) 04 1 KiB blocks: 84.4 IO/s, 84.4 KiB/s (691.8 kbit/s) 05 2 KiB blocks: 81.3 IO/s, 162.6 KiB/s ( 1.3 Mbit/s) 06 4 KiB blocks: 80.2 IO/s, 320.8 KiB/s ( 2.6 Mbit/s) 07 8 KiB blocks: 79.8 IO/s, 638.4 KiB/s ( 5.2 Mbit/s) 08 16 KiB blocks: 79.2 IO/s, 1.2 MiB/s ( 10.4 Mbit/s) 09 32 KiB blocks: 81.8 IO/s, 2.6 MiB/s ( 21.4 Mbit/s) 10 64 KiB blocks: 78.0 IO/s, 4.9 MiB/s ( 40.9 Mbit/s) 11 128 KiB blocks: 76.0 IO/s, 9.5 MiB/s ( 79.7 Mbit/s) 12 256 KiB blocks: 53.9 IO/s, 13.5 MiB/s (113.1 Mbit/s) 13 512 KiB blocks: 39.8 IO/s, 19.9 MiB/s (166.9 Mbit/s) 14 1 MiB blocks: 33.3 IO/s, 33.3 MiB/s (279.0 Mbit/s) 15 2 MiB blocks: 25.3 IO/s, 50.6 MiB/s (424.9 Mbit/s)
Bei weiterwachsender Blockgröße gewinnt die Transferrate zunehmend an Bedeutung, ein Spurwechsel ist erst möglich, wenn der aktuelle Block vollständig gelesen ist. Bei noch größeren Blöcken, etwa ab 2 MBytes, dominiert schließlich die Transferrate – die Messung ist dann im Bereich des sequenziellen Lesens angekommen.
Listing 4 wiederholt den Test auf einer SSD. Wieder sieht man zunächst konstante IOPS (zwischen 512 Bytes bis 8 KBytes) und eine Verdopplung der Transferrate analog zur Blockgröße. Doch reduziert sich Anzahl der möglichen Operationen bereits ab 8 KByte Blockgröße. Ab 64 KByte ist außerdem die maximale Transferrate erreicht, die Blockgröße hat keinen weiteren Einfluss auf die Transferrate. Beide Beispiele sind typisch: Meist sind SSD-Platten im sequenziellen Zugriff schneller als magnetische Festplatten – und im zufälligen Zugriff viel schneller.
Listing 4
IOPS auf SSD
01 # iops /dev/sda 02 /dev/sda, 120.03 GB, 32 threads: 03 512 B blocks: 21556.8 IO/s, 10.5 MiB/s ( 88.3 Mbit/s) 04 1 KiB blocks: 21591.8 IO/s, 21.1 MiB/s (176.9 Mbit/s) 05 2 KiB blocks: 21556.3 IO/s, 42.1 MiB/s (353.2 Mbit/s) 06 4 KiB blocks: 21654.4 IO/s, 84.6 MiB/s (709.6 Mbit/s) 07 8 KiB blocks: 21665.1 IO/s, 169.3 MiB/s ( 1.4 Gbit/s) 08 16 KiB blocks: 13364.2 IO/s, 208.8 MiB/s ( 1.8 Gbit/s) 09 32 KiB blocks: 7621.1 IO/s, 238.2 MiB/s ( 2.0 Gbit/s) 10 64 KiB blocks: 4162.3 IO/s, 260.1 MiB/s ( 2.2 Gbit/s) 11 128 KiB blocks: 2176.5 IO/s, 272.1 MiB/s ( 2.3 Gbit/s) 12 256 KiB blocks: 751.2 IO/s, 187.8 MiB/s ( 1.6 Gbit/s) 13 512 KiB blocks: 448.7 IO/s, 224.3 MiB/s ( 1.9 Gbit/s) 14 1 MiB blocks: 250.0 IO/s, 250.0 MiB/s ( 2.1 Gbit/s) 15 2 MiB blocks: 134.8 IO/s, 269.5 MiB/s ( 2.3 Gbit/s) 16 4 MiB blocks: 69.2 IO/s, 276.7 MiB/s ( 2.3 Gbit/s) 17 8 MiB blocks: 34.1 IO/s, 272.7 MiB/s ( 2.3 Gbit/s) 18 16 MiB blocks: 17.2 IO/s, 275.6 MiB/s ( 2.3 Gbit/s)
Das Programm “iometer”
IO Meter [2] ist ein grafisches Tool zum Testen von Disk- und Netzwerk-I/O auf einem oder mehreren Computern. Etwas gewöhnungsbedürftig ist die Terminologie, zum Beispiel wird der Ausdruck “Manager” für “Computer” gebraucht und “Worker” für “Thread”. IO Meter ist unter Windows und Linux einsetzbar und bietet ein grafisches Frontend, wie Abbildung 7 zeigt.
Abbildung 7: IO Meter ermöglicht das Messen von verschiedenen Geräten mit mehreren Threads (Workers).
Es kann sowohl zufällige als auch sequenzielle und sowohl lesende als auch schreibende Zugriffe messen, für beide kann der Benutzer ein prozentuales Verhältnis angeben. Abbildung 8 zeigt, wie das aussieht. Schreibtests sollten nur auf leeren Festplatten ablaufen, denn das Dateisystem wird nicht beachtet und überschrieben. Die Ergebnisanzeige ist umfangreich, wie Abbildung 9 zeigt. Das Tool zeigt IOPS, Durchsatz, Latenz und CPU-Nutzung.
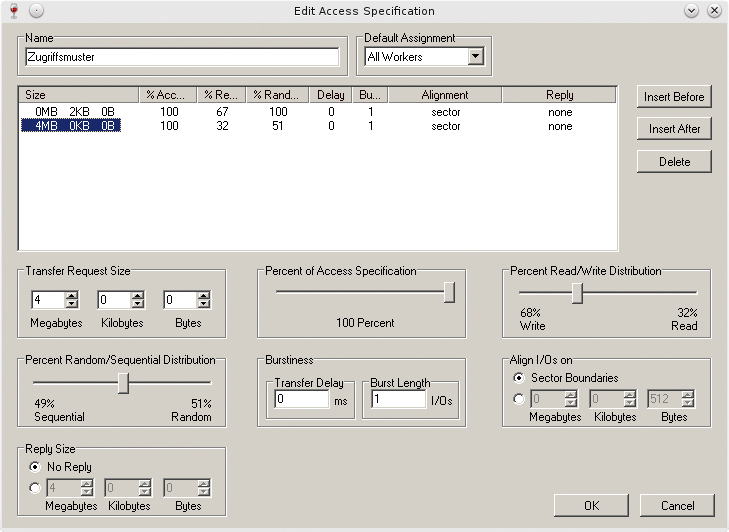
Abbildung 8: IO Meter ermöglicht die Definition von mehreren Zugriffsmustern mit unterschiedlichen Blockgrößen.
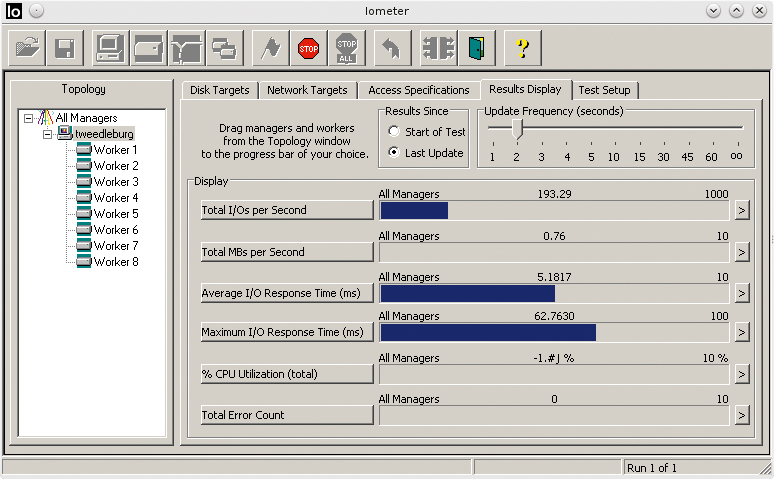
Abbildung 9: IO Meter misst Durchsatz, Operationsanzahl, Latenz und CPU-Belastung.
Das Kommando “dd”
»dd« ist ein universelles Kopierwerkzeug, das auch für Benchmarks verwendbar ist. Von Vorteil bei »dd« ist, dass es im Batchbetrieb arbeitet, die Wahl zwischen Direct I/O und Buffered I/O bietet und es erlaubt, die Blockgröße zu wählen. Nachteilig ist, dass es keine Informationen über die Anzahl der I/O-Operationen liefert. Es lassen sich aber aus der Blockgröße und dem Durchsatz Rückschlüsse auf die I/O-Anzahl ziehen. Wie der Admin »dd« als Dateisystem-Benchmark einsetzen kann, zeigt ein Beispiel:
dd if=datei of=/dev/null
Oder er umgeht den Dateisystem-Cache:
dd if=datei iflag=direct of=/dev/null
Er kann sogar das Dateisystem ganz umgehen und direkt auf der Platte aufsetzen:
dd if=/dev/sda of=/dev/null
Fluch und Segen von »dd« ist seine universelle Ausrichtung. Es ist kein dediziertes Benchmarktool. Der Nutzer muss mitdenken, wenn er es anwendet. Zur Illustration, wie leicht man nicht das misst, was man zu messen glaubt, hier nur ein Beispiel. Das Kommando
dd if=/dev/sdb
ergab auf dem verwendeten Testrechner einen Wert von 44,2 MByte/s. Wer daraus folgert, dass die Lesegeschwindigkeit der zweiten SCSI-Platte bei Default-Blockgröße eben dieser Wert ist, wird enttäuscht von dem Kommando
dd if=/dev/sdb of=/dev/null
das 103 MByte/s liefert. Ein reproduzierbarer Unterschied von mehr als 100 Prozent. Das erste Kommando misst in Wirklichkeit, wie schnell das System Daten (zum Beispiel Nullen) auf die Konsole ausgeben kann. Ein simples Umleiten der Ausgabe auf »/dev/null« korrigiert das Ergebnis.
Generell gilt es, alle Ergebnisse auf Plausibilität zu überprüfen. Tests sollten mehrmals laufen, um zu sehen, ob die Ergebnisse annähernd konstant bleiben, und um Caching-Effekte frühzeitig zu erkennen. Immer empfiehlt sich ein Vergleich mit einem Real-World-Benchmark. So sollten Benutzer synthetischer Benchmarks, um die Plausibilität einer Durchsatzmessung festzustellen, auch einmal eine große Datei kopieren.
Das Kommando “iostat”
Sinnvollerweise ermittelt der Admin zuerst mit Benchmarks die Leistungsgrenzen eines Systems und überprüft dann mit Monitoringtools, inwieweit diese ausgereizt sind. Hierzu eignet sich »iostat« , das I/O-spezifische Kennzahlen der Blockschicht ermittelt. Einen exemplarischen Aufruf zeigt Listing 5.
Listing 5
iostat-Beispiel
01 # iostat -xmt 1 /dev/sda 02 Linux 3.16.7-21-desktop (tweedleburg) 08/07/15 _x86_64_ (8 CPU) 03 04 08/07/15 17:25:13 05 avg-cpu: %user %nice %system %iowait %steal %idle 06 1.40 0.00 0.54 1.66 0.00 96.39 07 08 Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util 09 sda 393.19 2.17 137.48 2.73 2.11 0.07 31.82 0.32 2.32 2.18 8.94 0.10 1.46
»rMB/s« und »wMB/s« geben den Durchsatz an, den das System für Lese- beziehungsweise Schreibzugriffe verbucht. »r/s« und »w/s« stehen für die Lese- beziehungsweise Schreiboperationen (IOPS), die nach unten an die SCSI-Schichten weitergegeben werden. »await« gibt die Average Wait Time einer I/O-Operation an. »await« – vermehrt um die Service-Time »svctm« – ergibt die Latenz. Sie hängt eng zusammen mit »avgqu-sz« , der durchschnittlichen Größe der Requestqueue.
Die Angabe »%util« benennt, wie hoch die CPU-Auslastung durch I/O ist. »rrqm/s« und »wrqm/s« sind die zusammengelegten Operationen (Read Requests merged per Second beziehungsweise Write Requests merged per Second), welche die darüber liegenden Schichten angefordert haben.
Die durchschnittliche Größe der I/O-Requests in der Queue gibt »avgrq-sz« an. Dadurch lässt sich feststellen, ob die gewünschte Blockgröße auch beim Storage (genauer: bei den SCSI-Schichten) ankommt. Das Betriebssystem limitiert die Blockgröße nämlich anhand der Einstellung »/sys/block/sdb/queue/max_ sectors_kb« . Im folgenden Fall ist die Blockgröße auf 512 KByte beschränkt:
# cat /sys/block/sdb/queue/max_sectors_kb 512
Die maximale Blockgröße lässt sich durch dieses Kommando auf 1 MByte ändern:
# echo "1024" > /sys/block/sdb/queue/max_sectors_kb
In der Praxis ist »iostat« vielseitig nutzbar. Wenn Beschwerden über hohe Antwortzeiten mit großen Werten von »avgqu-sz« korrelieren, typischerweise verbunden mit hoher I/O-Wartezeit »await« , bildet der Storage wahrscheinlich den Leistungsengpass. Der Zukauf von mehr CPU-Leistung, wie er in Cloud-basierten Systemen typischerweise möglich ist, läuft dann ins Leere. Stattdessen lässt sich zum Beispiel erforschen, ob die I/O-Requests zerstückelt werden und nahe an der Grenze von »/sys/block/sdb/queue/max_sectors_kb« liegen.
Ist dies der Fall, kann eine Erhöhung dieses Wertes helfen. Denn wenige große Operationen pro Sekunde bieten einen höheren Durchsatz als viele kleine. Wenn das nicht hilft, bietet die Messung wenigstens ein belastbares Argument, in einen leistungsstärkeren Storage oder Storage-Service zu investieren.
Des Weiteren ermöglicht »iostat« Aussagen, wie weit der Storage ausgelastet ist. Und zwar in Bezug auf Durchsatz, IOPS und Latenz. Das ermöglicht Prognosen der Form “Eine Verdopplung der Nutzerzahl bei gleichem Datenhunger pro Nutzer wird der Storage nicht mitmachen” oder “Der Storage könnte mehr Durchsatz bringen, die Masse an IOPS bremst ihn aber herunter”.
Weitere Tools
Weitere Benchmarktools sind zum Beispiel »fio« (Flexible I/O Tester) [3], »bonnie++« [4] und »iozone« [5]. Hdparm [6] ermittelt die Harddisk-Parameter. Unter anderem kann »hdparm -tT /dev/sda« den Durchsatz für das Lesen aus dem Cache messen, was Rückschlüsse auf die Busbreite zulässt.
Was IO angeht, schafft »iostat« alles, was »vmstat« kann, weshalb »vmstat« hier nicht weiter Thema ist. Iotop erlaubt Rückschlüsse darauf, welche Prozesse I/O-Last erzeugen. Auch »cat« und »cp« aus dem Linux-Baukasten lassen sich für Real-World-Benchmarks wie das Kopieren einer großen Datei einsetzen. Sie liefern aber nur Anhaltspunkte für den Durchsatz.
Profiling
In den meisten Fällen plant der Admin keine Systeme auf der grünen Wiese, sondern will ein existierendes System ablösen oder optimieren. Die Anforderungen sind typischerweise nicht technisch formuliert (“Latenz < 1 Millisekunde, 2000 IO/s”), sondern spiegeln die Anwendersicht (“Es soll halt schnell laufen”).
Da in diesem Fall das Speichersystem bereits aktiv ist, kann man sein Lastprofil ermitteln. Hervorragende Tools auf der Betriebssystem-Seite hierfür sind »iostat« und »blktrace« . Iostat wurde schon vorgestellt. »blktrace« liefert nicht nur die durchschnittliche Größe der I/O-Operationen, sondern zeigt jede Operation separat mit ihrer Größe an. Listing 6 enthält einen Auszug der Ausgabe von:
blktrace -d /dev/sda -o - | blkparse -i -
Mit Plus (»+« ) versehene Werte geben die Blockgröße der Operation an, in diesem Beispiel 16, 32 und 8 Sektoren. Das entspricht 8192, 16384 und 4096 Bytes. So wird ermittelbar, welche Blockgrößen wirklich relevant sind – und die Storageleistung für diese Werte lässt sich gleich mit IOPS messen. Blktrace zeigt noch viel mehr, denn es lauscht an der Linux-I/O-Schicht. Hier interessiert die Möglichkeit, die angefragten I/O-Blockgrößen und die Verteilung der Read- und Write-Zugriffe zu betrachten.
Listing 6
Auszug aus der Ausgabe von blktrace
01 8,0 0 22 0.000440106 0 C WM 23230472 + 16 [0] 02 8,0 0 0 0.000443398 0 m N cfq591A / complete rqnoidle 0 03 8,0 0 23 0.000445173 0 C WM 23230528 + 32 [0] 04 8,0 0 0 0.000447324 0 m N cfq591A / complete rqnoidle 0 05 8,0 0 0 0.000447822 0 m N cfq schedule dispatch 06 8,0 0 24 3.376123574 351 A W 10048816 + 8 <- (8,2) 7783728 07 8,0 0 25 3.376126942 351 Q W 10048816 + 8 [btrfs-submit-1] 08 8,0 0 26 3.376136493 351 G W 10048816 + 8 [btrfs-submit-1]
Mit dem Kommando »strace« lässt sich feststellen, ob der Workload Async-I/O oder Sync-I/O anfordert. Async-I/O basiert auf dem Prinzip, dass ein Request für einen Datenblock losgeschickt wird und das Programm schon weiterarbeitet, bevor die Antwort eingetroffen ist. Wenn der Datenblock dann eintrifft, bekommt die konsumierende Applikation ein Signal und kann reagieren. Dadurch ist die Applikation gegenüber hohen Storagelatenzen weniger empfindlich und es kommt mehr auf den Durchsatz an.
Fazit
I/O-Benchmarks haben im Wesentlichen drei Ziele: Die optimalen Einstellungen zu ermitteln, um der Anwendung die bestmögliche Leistung zu bieten; Storage zu beurteilen, um die bestmögliche Storage-Umgebung zu kaufen oder zu mieten; sowie Leistungsengpässe zu identifizieren.
Die Beurteilung von Storagesystemen – ob in der Cloud oder im Rechenzentrum – sollte nicht losgelöst von den Bedürfnissen der Anwendung erfolgen. Je nach Anwendung sollte ein Durchsatz-, Latenz-, IOPS- oder CPU-optimierter Storage gewählt werden. Datenbanken benötigen für ihre Logdateien niedrige Latenz, für die Datendateien viele IOPS. Dateiserver brauchen einen hohen Durchsatz. Für andere Anwendungen lassen sich die Anforderungen mit Programmen wie »iostat« , »strace« und »blktrace« ermitteln.
Sind die Anforderungen einmal bekannt, lassen sich die genauen Ausprägungen der Kennzahlen mit Benchmarks testen. Je nach Fragestellung interessiert die Leistung des I/O-Stack mit oder ohne Dateisystem. IOPS und IO Meter umgehen das Dateisystem.
Beim Untersuchen von Performance-Engpässen hilft die Konzentration auf dieselben Kennzahlen. Häufig besteht eine Korrelation zwischen hoher Latenz, langen Request-Queues (messbar mit »iostat« ) und negativer Nutzer-Wahrnehmung. Auch wenn der Durchsatz längst nicht ausgereizt ist, können die IOPS einen Engpass bilden, der die Storageleistung herunterbremst.
Schreib- und Lesecache arbeiten entgegengesetzt. Als Caching-Effekt steigen die Performancedaten beim Lesecache innerhalb mehrerer Messungen zunächst an und sinken beim Schreibcache nach einer Zeit wieder ab. Viele Caches arbeiten mit Read-ahead beim Lesen. Beim Schreiben kommen die Effekte vom I/O-Elevator-Scheduling hinzu. Sowohl beim Schreiben als auch beim Lesen werden benachbarte Operation im Cache zusammengelegt. Zufällige I/O-Zugriffe verringern die Wahrscheinlichkeit, dass benachbarte Blöcke betroffen sind – und damit die Zugriffsleistung. Zufällige I/O-Operationen benachteiligen magnetische Festplatten noch mehr als SSDs.
Wer die Kennzahlen und die Einflussfaktoren im Blick behält, kann sich an die Benchmarktools wagen. Davon stellte der Artikel die beiden Storage-Benchmarktools IO Meter und IOPS vor. Reine Dateisystem-Benchmarks sind dagegen »fio« , »bonnie« oder »iozone« . Hdparm ist sinnvoll zur Vermessung der physischen Ausgangslage.
Für das Monitoring eignen sich »blk-trace« , »strace« und »iostat« . Iostat gibt einen guten Überblick aller Kennzahlen, während »blktrace« einzelne Operationen belauscht. Strace kann aufzeigen, ob Async-I/O im Spiel ist, was den Fokus von der Latenz auf den Durchsatz verschiebt.
Wichtig zu wissen: Im Benchmark-Umfeld lauern viele Denkfallen, die sich aus der Komplexität der Sache ergeben. Es hilft dann nur eins: Die Messergebnisse immer wieder auf ihre Plausibilität hinterfragen.
Infos
- IOPS: https://github.com/cxcv/iops
- IO Meter: http://www.iometer.org
- Fio: https://github.com/axboe/fio
- Bonnie++: http://www.coker.com.au/bonnie++
- Iozone: http://www.iozone.org
- Hdparm: http://sourceforge.net/projects/hdparm





