Nutch unterteilt gefundene Links in so genannte Segmente, die er Stück für Stück abarbeitet. Ein Segment beinhaltet nur eine gewisse Anzahl von Links; daher kann es passieren, dass er nach dem ersten Segment bereits weitere angelegt hat, die er abarbeitet. Die dabei gefundenen neuen Links landen wieder in neuen Segmenten. Ein Ende der Ausführung des Skripts bedeutet dennoch nicht, dass nun alle Inhalte eingelesen sind, unter Umständen sind sie nur für spätere Fetcher-Prozesse aufgehoben. Doch schon nach dem ersten Lauf sollten die Inhalte zur Verfügung stehen, die das Webinterface von Solr zeigt: »http://Suchserver:8080/solr/admin/« (Abbildung 1).
Abbildung 1: Das Admin-Interface von Apache Solr ist betont einfach und klar gehalten.
Wie oft der Crawler laufen soll – jede Nacht, einmal im Monat oder am Wochenende –, ist eine Frage der Datenmenge und des Anspruchs an die Aktualität der Ergebnisse. Wichtig zu wissen ist, dass Nutch nur Daten findet, auf die ein Link zeigt – aus einer Webseite oder einem indizierten Dokument heraus. Nicht verlinkte Dokumente existieren praktisch nicht, außer in FTP- oder HTTP-Listings von Verzeichnissen.
Abfrage mit Jquery
Meist integrieren Admins die Solr-Suche direkt in ein bestehendes Intranetportal. Dafür bietet das Tool ein API, das den Datenbankzugriff regelt und Suchergebnisse ausliefert. Selbst gestrickte Abfragen mit Jquery bieten sich an. Listing 4 zeigt den HTML-Code für eine simple Webseite mit Jquery-Skripten (zu sehen in Abbildung 2). Abbildung 3 zeigt die Antwort eines Servers im übertragenen XML-Code, ein simples Beispiel mit primitiven Suchanfragen auf das Solr-Backend.
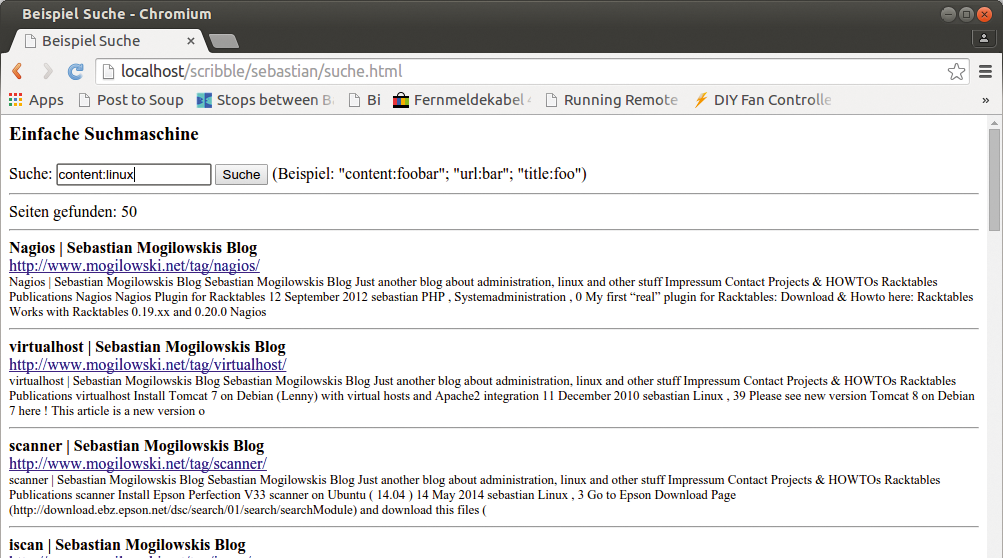
Abbildung 2: Dank Jquery lässt sich die Suchmaschine schnell und einfach in eigene Webseiten integrieren.
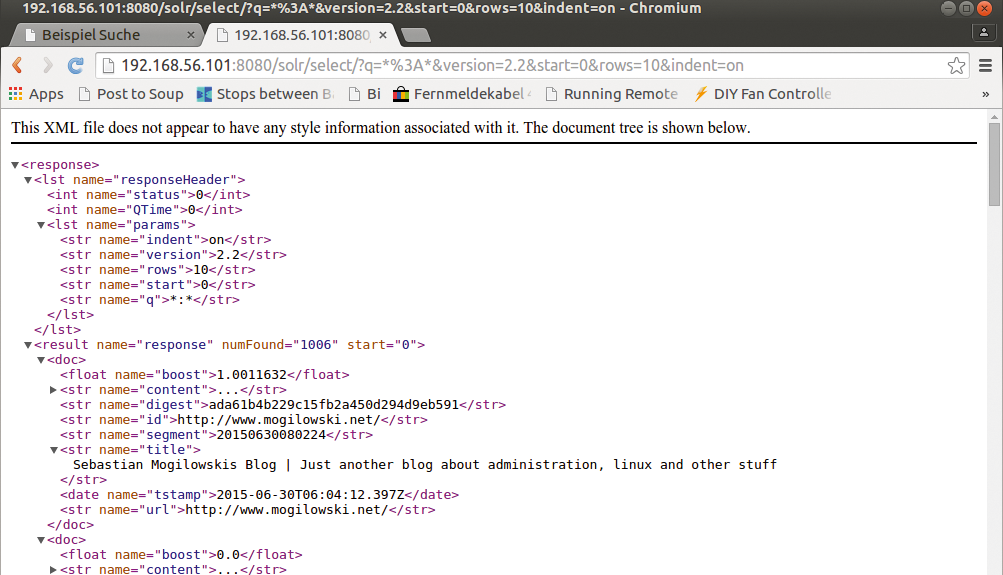
Abbildung 3: Aus dieser XML-Antwort baut das Jquery-Skript die HTML-Webseiten.
Innerhalb der Such-Query hat der Anwender viele Möglichkeiten: Wenn er ein Suchwort im Titel einer Seite höher bewerten möchte als im Content, greift er zu »content:(linux) title:(linux)^1.5« , was einem Treffer im Titel anderthalbmal mehr Gewicht verleiht als etwa im Body eines Dokuments. Er kann aber auch nach Seiten suchen, auf denen zwar das Wort “Linux” vorkommt, nicht aber “Debian”. Zugleich möchte er den Titel trotzdem bevorzugt behandelt wissen:
content:(linux -debian) title:(linux -debian)^1.5
Logische Und-Verknüpfungen gelingen mit einem simplen Pluszeichen, die Oder-Verknüpfung ist der Standard. »content:(+linux +debian)« sucht also nach “Linux” und “Debian”. Ohne die Pluszeichen würde das Tandem Solr-Nutch alle Dokumente anzeigen, die “Linux” oder “Debian” enthalten. Anführungszeichen erlauben es, nach kompletten Begriffen (»content:(“Linux Live USB Stick”)« zu suchen.
Listing 4
Jquery-Abfrage
01 <html>
02 <head>
03 <title>Beispiel Suche</title>
04 </head>
05 <body>
06 <h3>Einfache Suchmaschine</h3>
07 Suche: <input id="query" />
08 <button id="search">Suche</button> (Beispiel: "content:foobar"; "url:bar"; "title:foo")
09 <hr/>
10 <div id="results">
11 </div>
12 </body>
13 <script src="http://ajax.googleapis.com/ajax/libs/jquery/1.4.2/jquery.min.js"></script>
14 <script>
15 function on_data(data) {
16 $('#results').empty();
17 var docs = data.response.docs;
18 $.each(docs, function(i, item) {
19 if (item.content.length > 400)
20 contentpart = item.content.substring(0,400);
21 else
22 contentpart = item.content
23 $('#results').prepend($(
24 '<strong>' + item.title + '</strong><br/>' +
25 '<a href="http://'+%20item.url%20+'" target="_blank">'+ item.url +'</a>' +
26 '<br/><div style="font-size:80%;">'+ contentpart +'</div><hr/>'));
27 });
28 var total = 'Seiten gefunden: ' + docs.length + '<hr/>';
29 $('#results').prepend('<div>' + total + '</div>');
30 }
31
32 function on_search() {
33 var query = $('#query').val();
34 if (query.length == 0) {
35 return;
36 }
37 }
38 var solrServer = 'http://SUCHSERVER:8080/solr';
39 var url = solrServer + '/select/?q='+encodeURIComponent(query) + '&version=2.2&start=0&rows=50&indent=on&wt=json&callback=?&json.wrf=on_data';
40 $.getJSON(url);
41 function on_ready() {
42 $('#search').click(on_search);
43 /* Hook enter to search */
44 $('body').keypress(function(e) {
45 if (e.keyCode == '13') {
46 on_search();
47 }
48 });
49 }
50 $(document).ready(on_ready);
51 </script>
52 </html>
Diese einfachen Formen der Nutzerinteraktion lassen ahnen: Hier schlummert viel Potenzial für Jquery- und Webprogrammierer. Zum professionell anmutenden Suchmaschinen-Frontend fehlen noch Formulare und zusammenklickbare Abfragen, aber auch Eingabeprüfungen und das Hervorheben der gesuchten Begriffe in den Resultaten – so wie das der Open Search Server macht [5]. (jk)
Infos
- Google Search: https://www.google.com/work/search/
- Nutch: https://nutch.apache.org
- Solr: https://www.linux-magazin.de/Ausgaben/2013/07/SQL-Suchmaschinen/,https://lucene.apache.org/solr/
- Lucene: https://lucene.apache.org
- Markus Feilner, Thomas Pfeiffer, Markus Heller, “Gut sortiert”: Linux-Magazin 06/11, S.60.






