
© Steve Mann, 123RF
CMS, Wiki, Word-Files, … – selbst bei größter Disziplin aller Mitarbeiter kann kein Unternehmen seine Daten so strukturiert speichern, dass jedes Detail zügig auffindbar bleibt. Was tun? Aus den Apache-Projekten Solr, Nutch und Lucene eine eigene sauschnelle Suchmaschine bauen.
In dem Maße, in dem die gespeicherten Informationen in der Firma an Quantität und Komplexität zunehmen, wächst die Gefahr, Teile davon aus dem Radar zu verlieren. Das macht lokale Suchmaschinen für viele Firmen attraktiv. Zwar besitzt praktisch jedes Contentmanagement-System eine Suche, die hat aber nur die eignen Daten im Blick und arbeitet langsam. Irgendwo wächst noch ein Wiki Stück um Stück. Weitere Daten gibt’s als PDF oder in anderen Dokumentenformaten. Kurz: Informationen lagern an unterschiedlichen Orten in unterschiedlichen Formaten.
Mit wachsendem Datenumfang muss sich der Admin überlegen, wie er den Überblick behalten will. An dieser Stelle kommen kommerzielle Hersteller ins Spiel, die allerdings fast immer den Suchindex auf fremden Servern ablegen wollen, wie etwa Google [1]. Besser fährt, wer auf Open-Source-Tools setzt und mit einem eigenen Linux-Suchmaschinenserver die Hoheit über seine Daten behält. Denn auch die großen Hersteller setzen im Backend mit wenigen Ausnahmen auf die gleichen Open-Source-Tools: Nutch, Solr, Apache und Lucene.
Komponenten installieren
Unter dem Namen Nutch [2] bietet die Apache Foundation einen leistungsstarken Webcrawler an. In Verbindung mit Apache Solr [3], einer Searchengine basierend auf Apache Lucene [4], entsteht eine komplette Suchmaschine – ein Mini-Google. Der folgende Workshop zeigt am Beispiel von Ubuntu 14.04.2 LTS, 64 Bit, wie ein Admin ein solches Setup aufsetzt und benutzt.
Der Crawler Nutch fahndet per HTTP und FTP nach Informationen. Wer zusätzlich lokale Dateien unter die Lupe nehmen will, muss einen HTTP- oder FTP-Server vorhalten und auf die zu untersuchenden Verzeichnisse oder Netzwerkfreigaben zeigen lassen. Achtung: Der Crawler indiziert die Daten, welche die beteiligten Daemons sehen. Je nach Rechtekonzept kann das mehr sein, als normale Benutzer im Zugriff haben. Admins sollten das beim Betrieb im Blick behalten.
Auf Canonicals Enterprise-Linux ist Solr über die Paketquellen verfügbar, der Admin muss nur Nutch manuell installieren (Listing 1, Zeilen 1 bis 4). Dann sichert er das Default-XML-Schema von Solr und ersetzt es durch die mit Nutch gelieferte Datei (Zeilen 6 und 7).
Standardmäßig speichert der Server den Inhalt einer gefunden Seite oder eines Dokuments nicht. Indiziert er neu, überträgt er alle Inhalt abermals. Wer Caching wünscht, kann das in der Konfigurationsdatei »/etc/solr/conf/schema.xml« aktivieren, indem er in der Zeile
<field name="content" type="text" stored="false" indexed="true"/>
den Eintrag »stored=”false”« auf »”true”« setzt und anschließend Tomcat mit »service tomcat6 restart« neu startet.
Listing 1
Solr und Nutch installieren
01 apt-get install solr-tomcat 02 wget http://www.eu.apache.org/dist/nutch/1.9/apache-nutch-1.9-bin.tar.gz 03 tar vfx apache-nutch-1.9-bin.tar.gz 04 mv apache-nutch-1.9 /opt/nutch 05 06 mv /etc/solr/conf/schema.xml /etc/solr/conf/schema.xml.orig 07 cp /opt/nutch/conf/schema.xml /etc/solr/conf/schema.xml
Nutch-Crawler konfigurieren
Das Verhalten des Crawlers lässt sich mit der Datei »/opt/nutch/conf/nutch-default.xml« steuern. Zwar könnte der Admin die Werte in ihr einfach ändern, wie beim Webserver Apache ist es jedoch meist geschickter, diese in der Datei »/opt/nutch/conf/nutch-site.xml« zu überschreiben, die die Site-spezifischen Details beinhaltet.
Das Beispiel in Listing 2 demonstriert, wie sich der Name des HTTP-Agent konfigurieren lässt. Mit dieser Kennung hinterlässt der Crawler seine Spuren in den Logfiles des Webservers. Anhand solcher Agent Names kann ein Admin derlei Einträge gegebenenfalls auch ausfiltern oder weiterverarbeiten.
In »nutch-default.xml« finden sich zahlreiche Einstellungen, die das Verhalten des Crawlers steuern, so auch das Pendant zum oben für Solr erwähnten Aktivieren des Caching. In »nutch-site.xml« erledigt das:
<property> <name>file.content.ignored</name> <value>false</value> </property>
Außerdem soll Nutch alle Dokumente, die Anwender in der Zwischenzeit gelöscht haben, auch aus der Datenbank der Suchmaschine entfernen:
<property> <name>db.update.purge.404</name> <value>true</value> </property>
Im lokalen Netz, wo es im Vergleich zum Internet nur wenige Server und Clients gibt, führen die 5 Sekunden Defaulteinstellung bei der Wartezeit zwischen zwei Anfragen an denselben Server zu einer unnötig hohen Anzahl inaktiver Threads und bremsen die Suchmaschine deutlich aus, wenn beispielsweise nur ein Server zu indizieren ist. Der Parameter »fetcher.server.delay« ist geeignet sicherzustellen, dass die Suchmaschine dennoch keinen Server mit Anfragen überlastet:
<property> <name>fetcher.server.delay</name> <value>0.0</value> </property>
Es empfiehlt sich, diesen Wert zu deaktivieren und ihn erst wieder zu ändern, wenn Probleme auftreten.
Listing 2
nutch-site.xml
01 <?xml version="1.0"?> 02 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 03 <!-- Put site-specific property overrides in this file. --> 04 <configuration> 05 <property> 06 <name>http.agent.name</name> 07 <value>Company Search Agent</value> 08 </property> 09 </configuration>
Große Dokumente
Innerhalb des Intranets ist es möglich und oft sinnvoll, große Dokumente zu indizieren. Nutch unterstützt dieses Anliegen mit den Parametern der »content.limit« -Klasse, welche die Maximalgröße des Inhalts definiert, die der Crawler verarbeitet (Listing 3). Auch die Länge des Dokumenten-Titels lässt sich definieren, etwa um eine informativere Darstellung in den Suchergebnissen zu erreichen – hier nicht in Byte, sondern in Zeichen:
<property> <name>indexer.max.title.length</name> <value>150</value> </property>
Eine weitere nützliche Variable ist »fetcher.threads.fetch« , die die Anzahl gleichzeitig laufender Threads definiert, die Inhalte einlesen. »http.timeout« verringert die Zeit, die der Thread auf den Timeout einer Anfrage wartet.
Listing 3
Dateilängen
01 <property> 02 <name>file.content.limit</name> 03 <value>131072</value> 04 </property> 05 <property> 06 <name>http.content.limit</name> 07 <value>131072</value> 08 </property> 09 <property> 10 <name>ftp.content.limit</name> 11 <value>131072</value> 12 </property>
Auf dem Index
Wer dem Suchmaschinenserver den Zugriff aufs Internet sperrt, etwa weil er Wikipedia nicht auch indiziert haben möchte, kann den Zugriff via Firewall unterbinden, sollte aber den HTTP-Timeout sehr kurz einstellen. Der Suchserver wird ja externe URLs in den Dokumenten finden, aber seine Verbindungsversuche scheitern, und der Timeout bestimmt, wie lange das dauert. Der Crawler findet zwar weiterhin externe URLs, erreicht sie aber nicht und nimmt sie darum nicht in seine Datenbank auf.
Sauberer ist es, die Datei »regex-urlfilter.txt« im »conf« -Verzeichnis von Nutch zu benutzen. Hier lassen sich Ausnahmen definieren, bereits vorhanden sind Regeln die etwa das Einlesen von CSS-Dateien oder Bildern verhindern. So veranlasst
-^(http|https)://www.wikipedia.de
beispielsweise den Crawler dazu, Links auf http://www.wikipedia.de gar nicht zu verfolgen. Noch besser ist es jedoch, eine Whitelist zu definieren und so nur einzelne Server zu erlauben:
+^(http|https)://intranet.company.local
Oder auch mehrere Adressen, mit Regex-Ausdrücken spezifiziert:
+^http://([a-z0-9\-A-Z]*\.)*.company.local/([a-z0-9\-A-Z]*\/)*
Wichtig ist dabei, die letzte Zeile zu korrigieren – sie gibt die generelle Policy vor:
# accept anything else +.
ersetzt der Admin am besten durch:
# deny anything else -.
Nur auf diese Weise greift die Whitelist, der Kommentar in der vorletzten Zeile erleichtert beispielsweise der Urlaubsvertretung die Arbeit.
Es kann losgehen
Nun ist alles bereitet, der Suchvorgang kann starten, wenn der Admin dem Crawler noch das Ziel – oder besser den Startpunkt – seiner Recherche nennt. Dazu legt er unter »/opt/nutch/« Unterverzeichnisse und Dateien an, die die URLs enthalten:
mkdir /opt/nutch/urls echo "http://intranetserver.company.local" > /opt/nutch/urls/seed.txt
Beliebig viele URLs sind hier erlaubt. Als Nächstes startet der Crawler:
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64/jre/ /opt/bin/crawl /opt/nutch/urls/ /opt/nutch/IntranetCrawler/ http://localhost:8080/solr/ 10
Der erste Parameter des Crawl-Befehls nennt das Verzeichnis, in dem sich die oben angelegte »seed.txt« -Datei befindet. Nach dem Crawler ruft Nutch so genannte Fetcher-Prozesse auf. Diese laden und parsen die gefundenen Inhalte. Die Option »/opt/nutch/IntranetCrawler« gibt ein Verzeichnis an, in das Nutch diese Inhalte legen soll. Es folgt die Adresse samt Port des Solr-Servers, in dem Nutch die Suchergebnisse ablegt.
Die Zahl 10 am Ende beziffert die Durchläufe des Crawlers. Je nach gefundenen Seiten sowie Suchtiefe kann es einige Zeit dauern, bis der Befehl fertig ist. Für initiale Tests mag es besser sein, mit 1 oder 2 zu beginnen.
Wenn der Fetcher die Inhalte herunterlädt und parst, findet er in der Regel weitere Links auf andere Inhalte. Diese landen in seiner Link-Datenbank im oben erwähnten Verzeichnis. Beim nächsten Durchlauf liest der Crawler auch diese URLs und übergibt sie an Fetcher-Prozesse. Das führt dazu, dass diese To-do-Liste mit Links für den Crawler am Anfang sehr schnell anwächst, weil dieser pro Durchlauf immer nur eine gewisse Menge an Inhalten verarbeitet, dabei aber immer wieder neue Links findet.
Nutch unterteilt gefundene Links in so genannte Segmente, die er Stück für Stück abarbeitet. Ein Segment beinhaltet nur eine gewisse Anzahl von Links; daher kann es passieren, dass er nach dem ersten Segment bereits weitere angelegt hat, die er abarbeitet. Die dabei gefundenen neuen Links landen wieder in neuen Segmenten. Ein Ende der Ausführung des Skripts bedeutet dennoch nicht, dass nun alle Inhalte eingelesen sind, unter Umständen sind sie nur für spätere Fetcher-Prozesse aufgehoben. Doch schon nach dem ersten Lauf sollten die Inhalte zur Verfügung stehen, die das Webinterface von Solr zeigt: »http://Suchserver:8080/solr/admin/« (Abbildung 1).
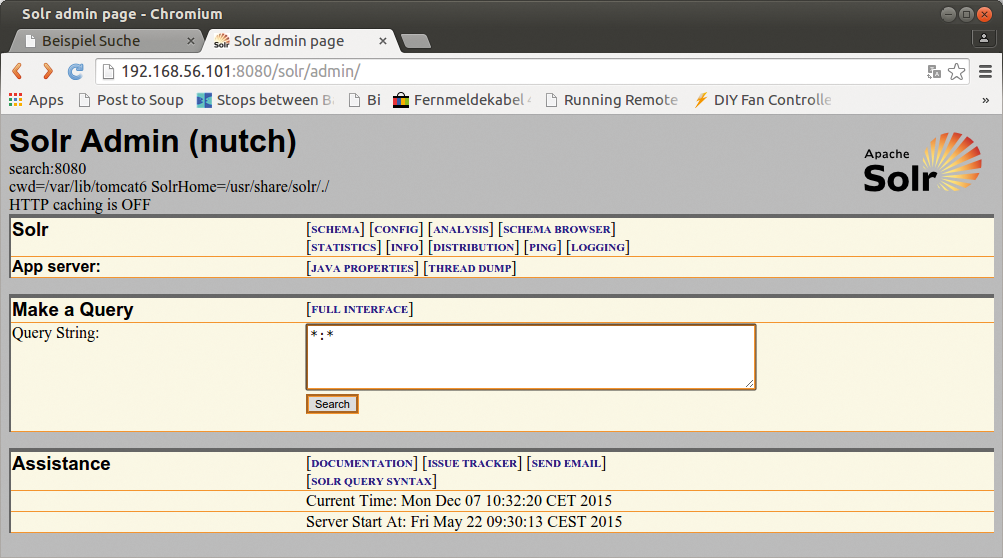
Abbildung 1: Das Admin-Interface von Apache Solr ist betont einfach und klar gehalten.
Wie oft der Crawler laufen soll – jede Nacht, einmal im Monat oder am Wochenende –, ist eine Frage der Datenmenge und des Anspruchs an die Aktualität der Ergebnisse. Wichtig zu wissen ist, dass Nutch nur Daten findet, auf die ein Link zeigt – aus einer Webseite oder einem indizierten Dokument heraus. Nicht verlinkte Dokumente existieren praktisch nicht, außer in FTP- oder HTTP-Listings von Verzeichnissen.
Abfrage mit Jquery
Meist integrieren Admins die Solr-Suche direkt in ein bestehendes Intranetportal. Dafür bietet das Tool ein API, das den Datenbankzugriff regelt und Suchergebnisse ausliefert. Selbst gestrickte Abfragen mit Jquery bieten sich an. Listing 4 zeigt den HTML-Code für eine simple Webseite mit Jquery-Skripten (zu sehen in Abbildung 2). Abbildung 3 zeigt die Antwort eines Servers im übertragenen XML-Code, ein simples Beispiel mit primitiven Suchanfragen auf das Solr-Backend.
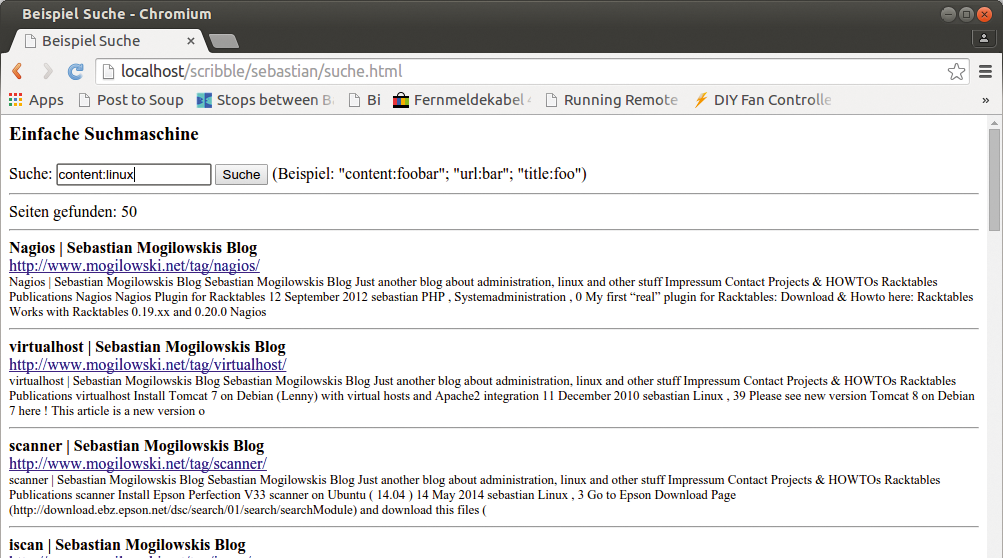
Abbildung 2: Dank Jquery lässt sich die Suchmaschine schnell und einfach in eigene Webseiten integrieren.
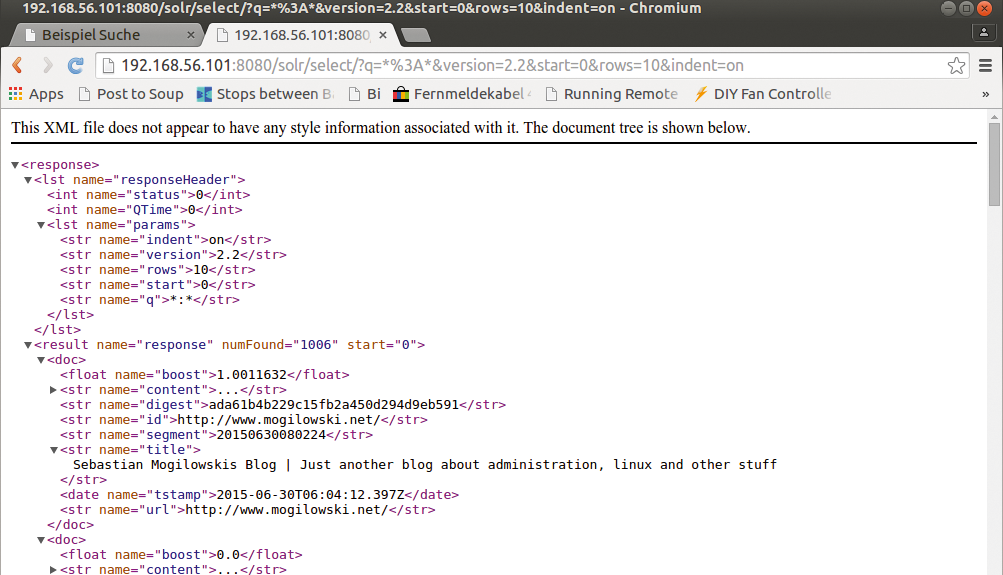
Abbildung 3: Aus dieser XML-Antwort baut das Jquery-Skript die HTML-Webseiten.
Innerhalb der Such-Query hat der Anwender viele Möglichkeiten: Wenn er ein Suchwort im Titel einer Seite höher bewerten möchte als im Content, greift er zu »content:(linux) title:(linux)^1.5« , was einem Treffer im Titel anderthalbmal mehr Gewicht verleiht als etwa im Body eines Dokuments. Er kann aber auch nach Seiten suchen, auf denen zwar das Wort “Linux” vorkommt, nicht aber “Debian”. Zugleich möchte er den Titel trotzdem bevorzugt behandelt wissen:
content:(linux -debian) title:(linux -debian)^1.5
Logische Und-Verknüpfungen gelingen mit einem simplen Pluszeichen, die Oder-Verknüpfung ist der Standard. »content:(+linux +debian)« sucht also nach “Linux” und “Debian”. Ohne die Pluszeichen würde das Tandem Solr-Nutch alle Dokumente anzeigen, die “Linux” oder “Debian” enthalten. Anführungszeichen erlauben es, nach kompletten Begriffen (»content:(“Linux Live USB Stick”)« zu suchen.
Listing 4
Jquery-Abfrage
01 <html>
02 <head>
03 <title>Beispiel Suche</title>
04 </head>
05 <body>
06 <h3>Einfache Suchmaschine</h3>
07 Suche: <input id="query" />
08 <button id="search">Suche</button> (Beispiel: "content:foobar"; "url:bar"; "title:foo")
09 <hr/>
10 <div id="results">
11 </div>
12 </body>
13 <script src="http://ajax.googleapis.com/ajax/libs/jquery/1.4.2/jquery.min.js"></script>
14 <script>
15 function on_data(data) {
16 $('#results').empty();
17 var docs = data.response.docs;
18 $.each(docs, function(i, item) {
19 if (item.content.length > 400)
20 contentpart = item.content.substring(0,400);
21 else
22 contentpart = item.content
23 $('#results').prepend($(
24 '<strong>' + item.title + '</strong><br/>' +
25 '<a href="http://'+%20item.url%20+'" target="_blank">'+ item.url +'</a>' +
26 '<br/><div style="font-size:80%;">'+ contentpart +'</div><hr/>'));
27 });
28 var total = 'Seiten gefunden: ' + docs.length + '<hr/>';
29 $('#results').prepend('<div>' + total + '</div>');
30 }
31
32 function on_search() {
33 var query = $('#query').val();
34 if (query.length == 0) {
35 return;
36 }
37 }
38 var solrServer = 'http://SUCHSERVER:8080/solr';
39 var url = solrServer + '/select/?q='+encodeURIComponent(query) + '&version=2.2&start=0&rows=50&indent=on&wt=json&callback=?&json.wrf=on_data';
40 $.getJSON(url);
41 function on_ready() {
42 $('#search').click(on_search);
43 /* Hook enter to search */
44 $('body').keypress(function(e) {
45 if (e.keyCode == '13') {
46 on_search();
47 }
48 });
49 }
50 $(document).ready(on_ready);
51 </script>
52 </html>
Diese einfachen Formen der Nutzerinteraktion lassen ahnen: Hier schlummert viel Potenzial für Jquery- und Webprogrammierer. Zum professionell anmutenden Suchmaschinen-Frontend fehlen noch Formulare und zusammenklickbare Abfragen, aber auch Eingabeprüfungen und das Hervorheben der gesuchten Begriffe in den Resultaten – so wie das der Open Search Server macht [5]. (jk)
Infos
- Google Search: https://www.google.com/work/search/
- Nutch: https://nutch.apache.org
- Solr: https://www.linux-magazin.de/Ausgaben/2013/07/SQL-Suchmaschinen/,https://lucene.apache.org/solr/
- Lucene: https://lucene.apache.org
- Markus Feilner, Thomas Pfeiffer, Markus Heller, “Gut sortiert”: Linux-Magazin 06/11, S.60.
Der Autor


Markus Feilner ist ein Linux-Spezialist aus Regensburg, der seit 1994 mit dem freien Betriebssystem als Autor, Trainer, Consultant und Journalist arbeitet. Der Conch-Diplomat, Minister der Universal Life Church und Jedi-Ritter leitet heute das Dokumentationsteam bei Suse in Nürnberg.
Sebastian Mogilowski ist Dipl.-Informatiker (FH) und Freizeitangler aus Regensburg. Seit 2005 arbeitet er, teils als Angestellter in einem großem Rechenzentrum, teils als Selbstständiger, mit Linux als Administrator, Consultant und Autor. Er beschäftigt sich mit Open Source, Systemmanagement, Virtualisierung und Heimautomatisierung.





