
Monika Wisniewska, 123RF.com
Volltextsuchmaschinen wie Solr, Xapian und Sphinx machen nicht nur das tägliche Datenchaos auf einer Festplatte durchsuchbar, sondern kommen auch mit relationalen Datenbanken klar.
Eine Liste mit zehn Webseiten zu erstellen, die das neue Ubuntu besprechen, ist simpel: Man verwendet einfach eine der populären Web-Suchmaschinen. Doch wer selbst eine Webseite mit vielen Informationen präsentiert und für diese eine eigene Suchfunktion anbieten will, steht mitunter vor einer ganz anderen Aufgabe – und die heißt Volltextsuche.
Die fahndet in den frei vagabundierenden oder systematisch angeordneten Daten nach einem oder mehreren Suchbegriffen. Ihre Ergebnisse soll die Suche aber nicht nur nach Relevanz sortiert ausspucken, sondern die Treffer möglichst in Sekundenbruchteilen abliefern.
Ordnung muss (nicht) sein
Zum Glück müssen Admins und Entwickler dafür das Rad nicht neu erfinden: Solr, Xapian und Sphinx sind Open-Source-Projekte, die Daten indexieren und auswerten. Doch sind Daten nicht gleich Daten: Grob lassen sich zwei Zustände unterscheiden, in denen die Suchmaschinen ihre Informationen vorfinden: strukturiert und unstrukturiert.
Strukturierte Daten lassen sich einfach erkennen, kategorisieren und mit Hilfe von Anwendungen prozessieren, weil sie eine feste, vordefinierte Struktur aufweisen. Die häufigste Form ist die einer relationalen Datenbank, die Daten in Spalten und Reihen organisiert, die wiederum in Form von Tabellen verbunden sind. Unstrukturierten Daten fehlt hingegen ein Datenmodell. Solche Datensätze sind oft so mehrdeutig, dass ein Programm sie nicht einfach verarbeiten kann, weil sich etwa Daten, Zahlen und Fakten wild vermischen. Hier spielen Suchmaschinen ihre Trümpfe aus, da sie die Daten im Chaos zumindest semantisch ordnen.
Indexieren
Grundsätzlich verfolgen Suchmaschinen dabei zwei Ziele: Beim Indexieren bereiten sie Daten so auf, dass sie einfacher zugänglich werden. Der Suchvorgang stellt hingegen die Informationen, die in den Indizes stecken, sinnvoll zusammen. Das Wort Indexieren steht im Duden und bedeutet, eine Liste von Dingen erstellen. Das ist der erste Schritt im Prozess.
Solr, Sphinx und Xapian durchforsten mit Hilfe der so genannten Indexer den kompletten Bestand an Daten, um ihn mit Hilfe verschiedener Algorithmen (siehe Kasten “Stoppwörter und Wortstammbildung”) in eine durchsuchbare Form zu bringen. Grob vereinfacht isoliert die Suchmaschine Schlüsselbegriffe aus dem Datenwust und legt sie in Form von Trees, Hashtabellen oder Binary Trees in Indexdateien ab, die auch die relative Position der Begriffe in den Originaldokumenten verzeichnen.
Stoppwörter und Wortstammbildung
Es gibt Wörter in allen Sprachen, die dem eigentlichen Textkörper, zu dem sie gehören, keine weitere Bedeutung hinzufügen und die der Indexer gewöhnlich aussortiert. Im Deutschen gehören zu diesen Stoppwörtern die bestimmten Artikel (der, die, das), unbestimmte Artikel (ein, eine, einer) oder Konjunktionen (und, oder).
Als Wortstammbildung bezeichnet man ein Verfahren, das deklinierte oder konjugierte Wörter auf ihren Wortstamm zurückführt. Der zugehörige Algorithmus ordnet zum Beispiel die Wörter “ging” und “gegangen” beide dem Wortstamm “gehen” zu.
Suchen
Das Indexieren allein nützt nichts, wenn es keine Suchfunktion gibt, die erzeugte Indizes sinnvoll interpretiert. Gibt man der Suche einen oder mehrere Begriffe vor, durchforstet sie die zuvor erstellten Indizes und liefert mehr oder weniger relevante Treffer zurück [1]. Da das Indexieren redundante und bedeutungslose Wörter entfernt, läuft die Suche viel zügiger ab, als wenn ein Rechner die Originaldokumente durchsuchen würde.
Die Neuorganisation der Daten erlaubt es dem Anwender, einen Artikel aufzuspüren, der den Titel »Viele Wege, eine Katze zu finden« trägt, indem er etwa nach »Ich suche meine Mieze« sucht.
Tabellenkalkulation
Suchmaschinen kommen in freier Wildbahn in Form von Bibliotheken vor, die sich in bestehenden Code integrieren lassen, oder als alleinstehende Dienste. Letztere bieten für Entwickler ein API an, über das sich ihre Programme in die Suchmaschine einklinken. Der Artikel legt den Fokus dabei auf den Umgang der drei vorgestellten Suchmaschinen mit relationalen Datenbanken, wobei SQL-Varianten im Vordergrund stehen.
Geht es um das Indexieren von Informationen, die in einer Datenbank stecken, enthält die von den Suchmaschinen erzeugte Indexdatei in der Regel mindestens zwei Dinge: Die Felder, die der Anwender durchsuchen kann, sowie die ID des Eintrags in der Datenbank, die es erlaubt, bei Bedarf den von der Suchmaschine übernommenen Datensatz zu rekonstruieren.
Sind in einer Datenbank mehrere Tabellen miteinander verknüpft, müssen die Suchmaschinenbetreiber zunächst verstehen, wie die einzelnen Tabellen aufgebaut sind, wie sie zusammenhängen und welche Informationen aus der Datenbank die Volltextsuche beim Indexieren erfassen soll. Geht es schließlich um die eigentliche Datensuche, schaut die Suchmaschine in der Indexdatei nach den Suchbegriffen und kommt mit den IDs der Treffer und dem dazu angelegten Datensatz zurück.
Einige Volltext-Suchmaschinen, seien es Server oder Bibliotheken, bringen von Hause aus Unterstützung für die Interaktion mit verschiedenen gängigen Datenbankdiensten mit. Diese erlaubt es, die Indexierung weitgehend zu automatisieren, was den Idealfall darstellt.
Fehlender Support
Deutlich komplizierter wird es, wenn eine Datenbankanbindung fehlt. Dann muss der User selbst dafür sorgen, dass die Suchmaschine jeden Datenbankeintrag als individuelles Dokument behandelt und ihn indexiert, als handele es sich um unstrukturierte Daten. Auch für spätere Einträge in die Datenbank muss der Admin jeweils ein neues Dokument anlegen lassen.
Zudem muss er die Interaktion mit der Datenbank auch für die Suche manuell programmieren. Es ist zwar möglich, um die Restriktionen herumzuarbeiten, allerdings ist einiges zu bedenken, etwa die Größe der Datenbank und ob sie in einer verteilten Umgebung steht.
Apache Solr
Solr [2] ist ein quelloffener Volltext-Suchserver der Apache Software Foundation (aktuell ist Version 4.3.0), der auf der Suchbibliothek Lucene [3] aufbaut, die ebenfalls zur Apache Software Foundation gehört. Solr erhält also automatisch neue Fähigkeiten, wenn das Lucene-Projekt seine Software aktualisiert. Zu den Firmen und Institutionen, die Solr einsetzen, gehören Netflix und Sourceforge, aber auch die Nasa und das Weiße Haus. Bereits im Mai 2011 beschlossen Solr und Lucene zu fusionieren.
Auch wenn Lucene die Suchergebnisse heranschafft, bringt Solr eine Reihe interessanter Zusatzfunktionen mit. Dazu gehören das Treffer-Highligthing, das Fundstellen im Suchergebnis optisch hervorhebt, aber auch eine Fast-Echtzeit-Indexierung (Near Real-Time Indexing), die dafür sorgt, dass eben indexierte Daten fast sofort für die Suche bereitstehen. Es indexiert und parst zudem Rich Documents über Apache Tika [4], etwa Doc-, HTML- und PDF-Dateien, integriert eine Geodaten-Funktion und verfügt über eine erweiterbare Plugin-Architektur.
Sein API erlaubt es, in nahezu allen Programmiersprachen mit dem Server zu kommunizieren, weil dieser REST-ähnliche Standards verwendet (siehe Kasten “REST”) und Informationen in XML-, Json- und CSV-Dateien aufzeichnet.
REST
Der Begriff Representational State Transfer (REST) stammt aus der Dissertation von Roy Fielding. Nach dem Konzept sollen unter anderem alle Komponenten dynamisch generierter Webseiten über URIs erreichbar sein.
Gut strukturiert
Weil es in Java geschrieben wurde und bereits ein paar Jahre auf dem Buckel hat, kommt Solr gut mit strukturierten Daten zurecht [5]. Der Server versetzt den User in die Lage, fast jede Datenbank zu indexieren, wenn er zwei Dinge erledigt: den korrekten JDBC-Treiber installieren und einige XML-Dateien konfigurieren. Der erste Schritt wird kompliziert, wenn keine Standard-Datenbank-Engine zum Einsatz kommt. Setzt der Anwender hingegen auf die weitverbreitete MySQL-Datenbank [6], installiert er unter Ubuntu 13.04 einfach das Paket »libmysql-java« und nimmt ein paar manuelle Anpassungen vor.
Solr selbst lässt sich über »solr-common« einspielen, hinzu kommt mit »solr-tomcat« noch ein passender Server. Ein Data Import Handler kümmert sich dann um das Anzapfen der Datenbank. Um den zu nutzen, muss der Admin ihn unter Ubuntu zunächst über die Datei »/etc/solr/conf/solrconfig.xml« anmelden (siehe Listing 1, Zeile 1). Zugleich erwartet diese Datei einen Link zur Konfigurationsdatei »data-config.xml« (Zeile 3), die er zum Beispiel unter »/home/Benutzername« ablegt.
Listing 1
solrconfig.xml (Solr)
01 <requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> 02 <lst name="defaults"> 03 <str name="config">/home/Benutzername/data-config.xml</str> 04 </lst> 05 </requestHandler>
In dieser Konfigurationsdatei (Listing 2) soll dann stehen, wie Solr an die Daten der Datenbank kommt (Zeile 5), welche XML-Felder und Ergebnisspalten es lesen und ob es Felder ändern, löschen oder hinzufügen soll (Zeilen 9 bis 12). Bei Bedarf lassen sich verschiedene Datenbanken anzapfen, indem der Admin das Namensfeld nutzt [7]. Im Beispiel gehören in Solrs Schemadatei (»/etc/solr/conf/schema.xml« ) zusätzlich die Felder »id« , »name« und »desc« , die der Datenbanknutzer dank der Lektüre des Wiki [8] einrichtet, um dann die Datei »data-config.xml« anzupassen.
Listing 2
data-config.xml (Solr)
01 <dataConfig> 02 <dataSource type="JdbcDataSource" 03 name="Datenbank1" 04 driver="com.mysql.jdbc.Driver" 05 url=""replaceable">localhost/Datenbankname" 06 user="Benutzername" 07 password="Passwort"/> 08 <document> 09 <entity name="id" 10 dataSource="Datenbank1" 11 query="select id,name,desc from Beispieltabelle"> 12 </entity> 13 </document> 14 </dataConfig>
Der nächste Schritt soll sicherstellen, dass der passende JDBC-Treiber in Form einer Jar-Datei im Verzeichnis »/usr/share/solr/web/WEB-INF/lib« landet. Im Falle von MySQL findet man die aktuelle Position schnell über
sudo dpkg -L mysqldata-java
heraus und verlinkt dann den Treiber. Im letzten Schritt importiert ein Befehl die Datenbank in Solr, wobei ein einfacher HTTP-Aufruf mit der passenden Port-Angabe genügt:
http://localhost:8080/solr/ dataimport?command=full-import
Als »command« lässt sich wahlweise auch ein »=delta-import« anhängen, wenn es sich um das reine Update einer bestehenden Datenbank handelt.
Xapian
Anders als Solr ist Xapian [9] kein unabhängiger Server, der getrennt von den Anwendungen läuft, die seine Dienste nutzen. Vielmehr handelt es sich um eine C++-Bibliothek, die sich als Suchfunktion in Anwendungen integrieren lässt. Das Projekt bringt Bindings für andere Programmiersprachen mit, darunter Perl, Python, PHP, Java, Tcl, C#, Ruby, Lua und Erlang.
Zu den Xapian-Nutzern gehören beispielsweise die Wochenzeitung “Die Zeit” sowie das Debian-Projekt, das die Suchfunktion für die Mailingliste einsetzt. Für Ubuntu 13.04 stehen die Pakete »xapian-omega« , »xapian-tools« sowie »libxapian22« bereit.
Xapian legt die beim Indexieren gesammelten Daten in einer Standarddatenbank ab, die beim Suchschritt zum Einsatz kommt. Zu den Features von Xapian gehört eine gewichtete Wahrscheinlichkeitssuche: Wichtige Wörter erhalten mehr Gewicht als unwichtige, sodass relevantere Dokumente an die Spitze der Resultate wandern.
Die Anwender dürfen nach exakten Begriffen fahnden (Abbildung 1) oder nach einer spezifischen Anzahl von Wörtern, die im Suchtext wahlweise sortiert oder zufällig auftauchen können. Xapian korrigiert zudem die Suchbegriffe des Anwenders auf Basis des eigenen Suchindex und erlaubt das Indexieren von Daten während einer Suche, indem es neue Dokumente sofort in die Suchergebnisse integriert.
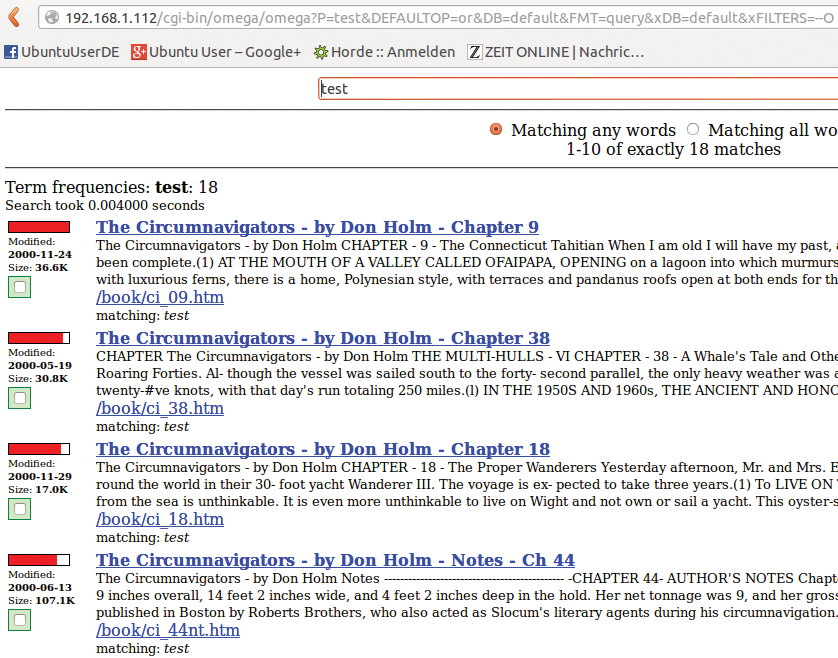
Abbildung 1: Die Xapian-Suchseite läuft unter Ubuntu auf einem Apache-Server und durchforstet hier einige der zuvor indexierten Testdokumente. Die Bilder wurden im Test allerdings nicht indexiert.
Xapian liefert eine interessante Antwort auf das hier gestellte Problem der Datenbanksuche. Standardmäßig bringt es keinen Support für Datenbank-Indexierungen mit. Allerdings gehört zum Xapian-Projekt auch ein Server-Projekt, das Omega [10] heißt und Xapian als Basis nutzt. Unter Ubuntu steckt Omega im Paket »xapian-omega« und installiert einen Apache-Server. Eine Anleitung [11] erklärt, wie man ein paar Testdaten durchsucht (Abbildung 2).
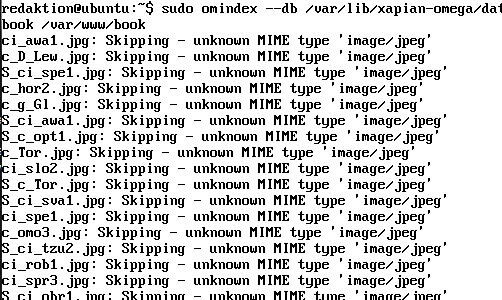
Abbildung 2: Was Xapian nicht kennt, frisst sie nicht – im Bild verweigert die Suchsoftware zum Beispiel das Indexieren von Bildern.
Die Verbindung von Omega und Xapian funktioniert ähnlich wie die von Solr und Lucene. Sie erlaubt es, Datenbanken zu indexieren, wozu alle SQL-Datenbanken gehören sowie andere Datenbanksysteme, die das DBI-Modul von Perl unterstützt. Konkret durchforstet das Team Xapian/Omega also MySQL, PostgreSQL, SQLite, Oracle, DB2, MS SQL, LDAP sowie ODBC.
Angenommen der Admin hat eine Tabelle »kunden« mit den Feldern »id (primary key)« , »kundenName (varchar 255)« und »adresse (text)« , die Teil der MySQL-Datenbank »myDB« ist, und möchte diese indexieren. Dann konvertiert er zunächst die Datenbank in ein Textformat für Xapian. Dazu exportiert er erst über die Kommandozeile den Datenbank-Benutzernamen und das dazugehörige Passwort:
export DBUSER=DB-Benutzername; export DBPASSWORD='DB-Passwort';
Im nächsten Schritt führt er ein Skript namens »dbi2omega« aus, das Ubuntu 13.04 im Verzeichnis »/usr/share/doc/xapian-omega/examples/dbi2omega« ablegt. Es überführt die Inhalte der Tabelle in eine Textdatei:
dbi2omega myDB kunden >> kunden.txt
Im nächsten Schritt muss der Xapian-Benutzer ein Skript erstellen (Listing 3), das Xapian erklärt, welche Felder aufzunehmen sind – im Beispiel heißt es »felder.script« . Auf diese Weise versteht die Suchsoftware, dass es sich bei dem »id« -Feld um ein einmaliges Feld handelt, dass sie das Feld »kundenName« indexieren soll, das eine fünfmal größere Relevanz besitzt als das Feld »adresse« , das ebenfalls im Index landet [12].
Listing 3
felder.script (Xapian)
01 id: field=id unique=Q boolean=Q 02 kundenName: field=kundenName lower index weight=5 03 adresse: field=adresse lower index
Unter Ubuntu startet der Administrator dann »scriptindex« , das im Pfad »/usr/bin/« liegt, und erzeugt damit die »BeispielDB« :
scriptindex --stemmer=german BeispielDB felder.script kunden.txt
Die Option »–stemmer« hilft bei der Wortstammbildung, da Xapians Algorithmus standardmäßig nur Englisch spricht. Hier gibt der Admin wahlweise »german« oder »german2« an, wobei Letzteres die Umlaute normalisiert.
Sphinx
Ähnlich wie Solr ist Sphinx [13] ein Volltext-Suchserver, der aktuell in Version 2.0.8 vorliegt. Aber anders als Solr bringt Sphinx kein sprachagnostisches REST-API mit. Dem Entwickler stehen jedoch drei Wege offen, um mit dieser Open-Source-Suchlösung zu arbeiten: Zunächst kann er einfach über das Sphinx-API kommunizieren. Die Suchmaschinen-Entwickler bieten bereits eine Reihe von Clients für Sphinx an, die in den Sprachen PHP, Java und Python vorliegen, daneben gibt es inoffizielle Sphinx-Clients in Perl, Ruby und C++.
Zweitens existiert mit Sphinx SE eine andockbare Storage Engine für MySQL, die es dem MySQL-Server erlaubt, große Mengen an Daten an den Such-Daemon »searchd« zu schicken. Und Drittens gibt es mit Sphinx QL eine SQL-ähnliche Skriptsprache, mit der sich Informationen auf demselben Weg zutage fördern lassen, wie das auch in einer MySQL-Datenbank geschieht. Sphinx QL erspart sich den Umweg über das Sphinx-API und redet direkt mit MySQL, weshalb die Datenbeschaffung schneller über die Bühne geht.
Zu den Features von Sphinx gehört die Fähigkeit, Sammlungen von Volltexten in Echtzeit zu indexieren. Es integriert SQL-Datenbanken nativ, kann Suchergebnisse nicht nur gruppieren und sortieren, sondern beim Suchen auch arithmetische Funktionen wie »MIN« , »MAX« , »SUM« und »AVG« einsetzen. Zudem läuft die Suche sehr performant, da Sphinx mit nur einem CPU-Kern 10 bis 15 MByte an Daten pro Sekunde indexiert.
Zu den bekannteren Kunden von Sphinx gehören Craigslist mit 300 Millionen Suchanfragen pro Tag, Tumblr sowie Phpbb.com. Wer Sphinx als Suchserver in Kombination mit Ubuntu nutzen will, installiert das Paket »sphinxsearch« .
MySQL anzapfen
Wenn es um das Indexieren von Daten geht, betrachtet Sphinx alles als ein Dokument, was jeweils die gleichen Attribute und Felder mitbringt. Mit SQL-Daten geht es ähnlich um, wobei es die Reihen als Dokumente betrachtet, die Spalten als Felder oder Attribute. Ein so genannter Data Source Driver überführt die Quelldaten aus verschiedenen Typen von Datenbanken in Dokumente. Standardmäßig bringt Sphinx Treiber für MySQL, PostgreSQL, MS SQL und ODBC mit. Auch einen generischen Treiber namens »xmlpipe2« für XML-Dateien kennt die Software.
Um eine MySQL-Tabelle mit den Feldern »id« ,»title« und »description« zu indexieren [14], muss der Sphinx-Nutzer im Vorfeld noch einiges konfigurieren. So sollte er unter anderem klären, woher die Informationen kommen, wo der Datenbankserver läuft und wie er Sphinx mit ihm bekannt macht.
Dann stellt sich die Frage, wo der erstellte Index landen soll, zudem muss der Indexer so eingerichtet werden, dass er die Datenbank durchforstet und die Informationen weiterleitet. Der Suchdaemon Searchd kümmert sich schließlich um die Konfiguration von Sphinx.
Die Listings 4 und 5 zeigen Abschnitte aus der Konfigurationsdatei von Sphinx (»sphinx.conf« ). Gut, dass es unter Ubuntu bereits eine Vorlage gibt, die sich nutzen lässt:
sudo cp /etc/sphinxsearch/sphinx.conf. sample /etc/sphinxsearch/sphinx.conf
Sie enthält zwar Hunderte von Einträgen, ist aber, das sei positiv erwähnt, ausführlich kommentiert und lässt sich so an die eigenen Bedürfnisse anpassen (Abbildung 3).
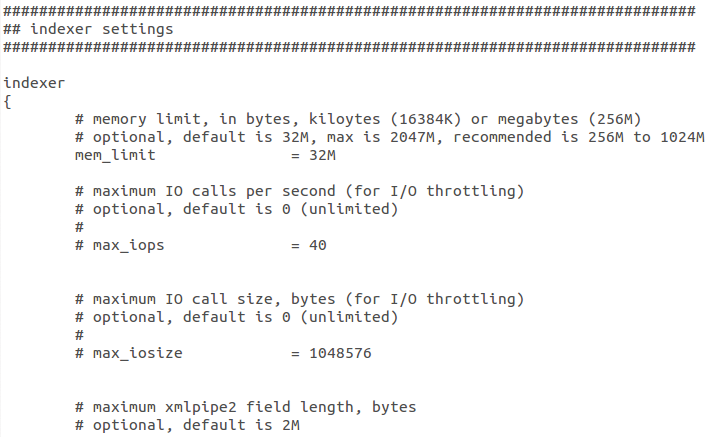
Abbildung 3: Über die sehr ausführliche Konfigurationsdatei lässt sich Sphinx mit Datenbanken verknüpfen.
Das »id« -Feld neben dem Eintrag »sql_query« muss auf eine positive Ganzzahl verweisen, die in der Datenbank genau ein Mal auftaucht. Dafür eignet sich beispielsweise ein auto-inkrementeller Integerschlüssel.
Listing 4
sphinx.conf
01 # Sorgt für die Datenbankanbindung
02 source meine_quelle
03 {
04 type = mysql
05 sql_host = localhost
06 sql_user = Benutzername
07 sql_pass = Passwort
08 sql_db = Datenbankname
09 sql_port = 3306
10 sql_query = SELECT id, title, description FROM Beispieltabelle
11 }
Listing 5
sphinx.conf
01 # Speicherort für den Datenbank-Index
02 index mein_sphinx_index
03 {
04 source = meine_quelle
05 path = /var/lib/sphinxsearch/mein_sphinx_index
06 docinfo = extern
07 charset_type = utf-8
08 }
[...]
09 # Mehr Speicher bereitstellen
10 indexer
11 {
12 mem_limit = 256M
13 write_buffer = 8M
14 }
[...]
15 # Such-Daemon vorbereiten
16 searchd
17 {
18 listen = 9312
19 listen = 9306:mysql41
20 pid_file = /var/run/sphinxsearch/searchd.pid
21 max_matches = 1000
22 }
Jetzt muss der Admin noch dafür sorgen, dass Sphinx als Dienst läuft. Dazu ändert er in der Datei »/etc/default/sphinxsearch« den Parameter »START=no« auf »START=yes« und wirft den Dienst an:
sudo service sphinxsearch start
Nach diesen Anpassungen genügt unter Ubuntu ein Befehl, um mit dem Indexieren zu beginnen. Dabei kommt der Indexer zum Einsatz, den Ubuntu beim Installieren des Sphinx-Pakets automatisch unter »/usr/bin/« ablegt.
indexer mein_sphinx_index -c /etc/ sphinxsearch/sphinx.conf
Der fertige Index landet unter dem Namen »mein_sphinx_index« im Verzeichnis »/var/lib/sphinxsearch« . Weitere Details zur Datenbankanbindung und den möglichen Optionen liefert die Sphinx-Dokumentation [15].
Fazit
Von den drei Open-Source-Projekten, die der Artikel vorgestellt hat, fiel Sphinx beim Indexieren von Datenbanken positiv auf. Es wurde offenbar gerade mit dieser Aufgabe im Hinterkopf entwickelt, zumindest was die Benutzbarkeit und Konfiguration angeht.
Dennoch müssen Anwender bei allen drei Kandidaten im Vorfeld genau wissen, welche Felder der Datenbank sie indexieren möchten, und dies explizit festlegen. Es genügt nicht, den Suchmaschinen einen Datenbank-Dump vorzusetzen und zu hoffen, dass hinten das richtige Ergebnis rausfällt. Richtig kompliziert wird es, wenn Suchmaschinen keinen SQL-Support mitbringen – dann ist für den Admin Handarbeit angesagt. Per Skript muss er die Daten mühsam aus den Tabellen pulen.
Solr ist ansonsten eine Empfehlung, wenn es um NoSQL-Indexierungen geht, einem hier nicht besprochenen Datenbanktyp. Dank seines REST-ähnlichen API bringt Solr sprachunabhängige Kompatibilität mit. Da es keine Bibliothek ist, braucht das Indexieren keinen in die Anwendung integrierten Code.
Infos
- Mehr zu Genauigkeit und Trefferquote im Suchkontext: https://de.wikipedia.org/wiki/Beurteilung_eines_Klassifikators#Genauigkeit-Trefferquote-Diagramm
- Suchmaschine Solr: http://lucene.apache.org/solr/
- Solr-Unterbau Lucene: http://lucene.apache.org
- Inhaltsanalyse-Tool Tika von Apache: http://tika.apache.org
- Solr mit Datenbankanbindung: http://wiki.apache.org/solr/DIHQuickStart
- MySQL-Projekt: http://www.mysql.de
- MySQL-Import in Solr: http://wiki.apache.org/solr/DataImportHandler#Configuration_in_data-config.xml
- Konfiguration von Solrs »schema.xml« : http://wiki.apache.org/solr/SchemaXml
- Suchbibliothek Xapian: http://xapian.org
- Omega-Projekt: http://xapian.org/docs/omega/
- Omega im Einsatz: http://trac.xapian.org/wiki/OmegaExample
- Scriptindex Xapian: http://xapian.org/docs/omega/scriptindex.html
- Suchmaschine Sphinx: http://sphinxsearch.com
- Konfiguration von MySQL für Sphinx: http://astellar.com/2011/12/replacing-mysql-full-text-search-with-sphinx/
- Ausführliche Sphinx-Dokumentation: http://sphinxsearch.com/wiki/doku.php?id=sphinx_docs#sphinxconf_options_reference





