Ausgabe Februar 2016

Titelthema: Versteh' Systemd
Die Mehrheit der wichtigen Distributionen ist auf Systemd eingeschwenkt. Höchste Zeit für den Admin, sich näher mit der Mechanik des neuen Initsystems zu befassen: Wie verwaltet er Dienste? Wie migriert er Sys-V-Initskripte, analysiert er den Zeitbedarf beim Systemstart, überwacht er Prozesse, limitiert er Ressourcen und wertet er Logfiles aus?
Zu den Listings
Artikel

Jetzt ist er fertig, der Entwurf der neuen Datenschutz-Grundverordnung (DS-GVO). EU-Rat und-Parlament haben ihre konkurrierenden Papiere zusammengeworfen. Voraussichtlich 2017 wird die DS-GVO in Kraft treten. Die rund 100 Seiten entwickeln die EU-Datenschutzrichtlinie aus dem Jahr 1995 weiter....

Ihr Zehnjähriges konnte in diesem Jahr die Open Source Monitoring Conference feiern. Der Jubilar bewies mit einer Fülle interessanter Vorträge, dass er wieder einen Besuch in Nürnberg wert war.

Mit rund 100 Teilnehmern startete im November in Berlin die erste Konferenz rund um das Initsystem Systemd. Sie richtete sich vor allem an professionelle Init-Nutzer, also Admins und Entwickler.

Fast alles, was ein Computer tut – rechnen, speichern, ein- und ausgeben von Daten –, das tut er mit Hilfe von Prozessen. Entsprechend wichtig ist die Kontrolle über diese Prozesse, bei der Systemd ein gewichtiges Wörtchen mitzureden hat.

Seit der Fedora-Version 20 gibt es kein "/var/log/messages" mehr, und auch der klassische Syslog-Daemon läuft dort nicht. Trotzdem kann der Admin nach Herzenslust in Systemmeldungen stöbern – und das sogar viel bequemer als früher.

Ursprünglich als Tool für Systemd-Tester gedacht, mausert sich Systemd-nspawn zu einer eigenständigen Containerlösung. Bei Rkt von Core OS ist es bereits als Low-Level-Tool im Einsatz. Rkt-Entwickler Jonathan Boulle stellt Systemd-nspawn vor.

Systemd betrifft nicht nur Admins von Systemen, sondern auch die Betreuer von Paketen. Ganz gleich, ob es sich um offizielle Distributionspakete oder das eigene Repository handelt – beim Umstieg auf Systemd gibt es einiges zu beachten.

Auch diesen Monat bekommen die DELUG-Käufer die doppelte Datenmenge zum einfachen Preis: Seite A der DVD enthält Videos von den Kieler Open Source und Linux Tagen sowie von der ersten Systemd.conf. Auf Seite B warten Linux Mint 17.3, Raspbian 2015-11-21, eine VM mit UCS 4.1 und vieles...

Dass Linux und sein umfangreiches Open-Source-Ökosystem kostenlos sind, müsste für die finanziell klammen Schulen ein starkes Argument für deren Einsatz sein. Warum das jedoch nicht immer zieht und in welcher Form Linux bereits die Schulbank drückt, beleuchtet die Bitparade.

Dgit verbindet als Zwei-Wege-Gateway das Debian-Archiv mit einem Git-Repository. Das beschert Paketbetreuern ganz neue Möglichkeiten der Softwareverwaltung, verbessert aber auch den allgemeinen Umgang mit Debian-Quellpaketen und dem Archiv.

Im Kurztest: Dxirc 1.20.0, XS-HTTPD 3.7, Nmap 7.0, Megafont Next, Isync 1.2.1, Zeal 0.2.1
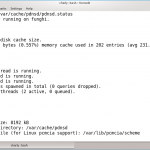
Cache it, if you can! – sagt sich Sysadmin Charly Kühnast, wenn die Latenzen seiner Internetverbindung gefühlt länger als die Regentschaft Napoleons dauern. In der heutigen Kolumne stellt er seine Cache-Lösung für die Namensauflösung vor.

Eine leistungsfähige Suchmaschine, ein Tool zum Verarbeiten und Normalisieren von Protokollen und eins zum Visualisieren der Auswertungen – Elasticsearch, Logstash und Kibana bilden den ELK-Stack, der auf Systemen mit großem Log-Aufkommen den Karren aus dem Dreck zieht.

CMS, Wiki, Word-Files, … – selbst bei größter Disziplin aller Mitarbeiter kann kein Unternehmen seine Daten so strukturiert speichern, dass jedes Detail zügig auffindbar bleibt. Was tun? Aus den Apache-Projekten Solr, Nutch und Lucene eine eigene sauschnelle...

Mit Hyperstore will der Hersteller Cloudian den etablierten Cloudspeicher-Techniken wie Ceph oder Open Stack Swift die Nutzer abspenstig machen. Ein Pluspunkt ist schon mal ein benutzerfreundliches GUI, dagegen fehlt eine Anbindung an Open Stack Cinder.
| LINUX-MAGAZIN KAUFEN | ||
|---|---|---|
| DIESES HEFT KAUFEN | Heft im Shop bestellen | Digitale Ausgabe im Shop bestellen |
| EINZELNE AUSGABE | Print-Ausgaben | Digitale Ausgaben |
| ABONNEMENTS | Print-Abos | Digitales Abo |
| TABLET & SMARTPHONE APPS |  Bald erhältlich |  Deutschland |