
2014 ist ein besonderes Jahr für C++. Drei Jahre nach C++11 erfährt der Sprachstandard mit C++14 den letzten Feinschliff. Neben generischen Lambda-Funktionen und der vereinfachten Ermittlung des Rückgabetyps kann C++14 vor allem mit einem Feature punkten: Reader-Writer-Locks.
Zugegeben, C++ ist nicht mehr das, was es einmal war. Mit C++11, C++14 und C++17 muss sich die Programmiersprache immer wieder mit Veränderungen auseinandersetzen. Der Zeitstrahl zu den Standards in Abbildung 1 soll das Zahlenspiel entwirren: Während C++98, C++11 und C++17 (oben) vollwertige Standards für die Sprache sind, stellen C++03 und C++14 (unten) Überarbeitungen der zu diesem Zeitpunkt gültigen Norm dar. Sie beseitigen im Wesentlichen Bugs und bringen kleine Verbesserungen.

Abbildung 1: Die C++-Standards: Oben die maßgeblichen Neuauflagen, unten die Nachbesserungen der Sprachversionen.
Auch wenn C++17 suggeriert, dass genau im Jahr 2017 der nächste große Wurf ansteht, so ist das keine zuverlässige Datumsangabe, sondern eine Arbeitshypothese. Einen Einblick in den laufenden Standardisierungsprozess gibt [1].
Redundanz beseitigt
Gerade mal zwei Monate ist es her, da stellte ein Artikel [2] dieser Serie die automatische Ermittlung des Rückgabetyps eines Funktionstemplates vor. Bereits mit C++14 (Listing 1) wird das einfacher. Das Funktionstemplate »add« in Zeile 4 ermittelt den Rückgabetyp automatisch aus dem Ergebnis des Ausdrucks »decltype(fir + sec)« in Zeile 5. Dabei leitet das Schlüsselwort »auto« den verzögerten Rückgabetyp ein. Ein scharfer Blick auf das Funktionstemplate offenbart die Redundanz: Der Ausdruck »fir + sec« muss in C++11 sowohl bei der Definition des Rückgabetyps (Zeile 5) als auch bei der Berechnung des Rückgabewerts (Zeile 6) stehen.
Listing 1
Vereinfachte automatische Rückgabetypen
01 #include <iostream>
02 #include <typeinfo>
03
04 template <typename T1, typename T2>
05 auto add(T1 fir, T2 sec) -> decltype(fir + sec){
06 return fir + sec;
07 }
08
09 template <typename T1, typename T2>
10 auto add14(T1 fir, T2 sec){
11 return fir + sec;
12 }
13
14 int main(){
15
16 std::cout << std::endl;
17
18 auto a= add(2000,11);
19 auto b= add(2000L,11);
20 auto c= add(3,0.1415);
21
22 std::cout << "a: " << a << " of type " << typeid(a).name() << std::endl;
23 std::cout << "b: " << b << " of type " << typeid(b).name() << std::endl;
24 std::cout << "c: " << c << " of type " << typeid(c).name() << std::endl;
25
26 std::cout << std::endl;
27
28 auto a1= add14(2000,14);
29 auto b1= add14(2000L,14);
30 auto c1= add14(3,0.1415);
31
32 std::cout << "a1: " << a1 << " of type " << typeid(a1).name() << std::endl;
33 std::cout << "b1: " << b1 << " of type " << typeid(b1).name() << std::endl;
34 std::cout << "c1: " << c1 << " of type " << typeid(c1).name() << std::endl;
35
36 std::cout << std::endl;
37
38 }
Das ist in C++14 beim Funktionstemplate »add14« (Zeile 9) nicht mehr erforderlich. Die Sprache ermittelt nun automatisch den Rückgabetyp aus dem Rückgabewert. Wie das Ausführen des Programms in Abbildung 2 zeigt, sind die mit unterschiedlicher Notation automatisch ermittelten Rückgabetypen identisch. So ergibt »int + int« den Typ »int« (Zeilen 22 und 28), »long + int« den Typ »long« (Zeilen 19 und 29) und »double + int« den Typ »double« (Zeilen 20 und 30).
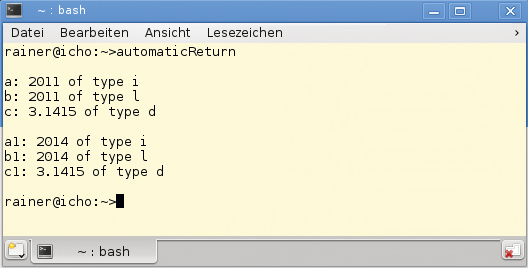
Abbildung 2: Automatisches Bestimmen des Rückgabetyps mit C++11 und C++14.
Generische Lambda-Funktionen
Lambda-Funktionen sind eines der wichtigsten Features von C++11. Mit ihnen drückt der Programmierer Funktionalität kurz und genau an der Stelle aus, an der er sie benötigt. Bessere Lesbarkeit und höhere Flexibilität des Codes sind zwei der vielen Punkte, die für Lambda-Funktionen sprechen. Die Details zu diesem funktionalen Baustein in C++11 lassen sich in den zwei ersten Artikeln dieser Serie nachlesen ([3], [4]).
Was fehlt den Lambda-Funktionen in C++11, das C++14 bietet? In C++11 muss der Entwickler den Typ der Argumente explizit angeben – das verhindert ihren generischen Einsatz. Den feinen Unterschied zwischen Lambda-Funktionen und generischen Lambda-Funktionen machen die zwei Funktionen »add()« und »add14()« in den Zeilen 7 und 8 von Listing 2 anschaulich. Während die erste nur Argumente vom Typ »int« akzeptiert, nimmt die zweite Argumente beliebigen Typs an. Kleiner Unterschied, große Auswirkungen: In Zeile 14 lassen sich mit »add()« lediglich zwei »int« -Werte zusammenzählen. Im Gegensatz dazu addiert »add14()« in den Zeilen 16 bis 22 Werte der Typen »int« , »long« , »double« und »std::string« .
Compiler für C++14
Die Version 3.4 des Clang-Compilers [5] unterstützt als erste vollständig den C++14-Standard. Aber auch der aktuelle GCC 4.9 [6] bietet die meisten Features von C++14. Mit »std=c++1y« als Flag übersetzt er alle Beispiele dieses Artikels. Genaueres zur Compiler-Unterstützung von C++14 ist im neuen C++-FAQ-Wiki [7] nachzulesen.
Listing 2
Generische Lambda-Funktionen
01 #include <algorithm>
02 #include <iostream>
03 #include <string>
04
05 using namespace std::literals;
06
07 auto add=[](int i,int i2){ return i + i2; };
08 auto add14=[](auto i,auto i2){ return i + i2; };
09
10 int main(){
11
12 std::cout << std::endl;
13
14 std::cout << "add(2000,11): " << add(2000,11) << std::endl;
15
16 std::cout << "add14(2000,14): " << add14(2000,14) << std::endl;
17 std::cout << "add14(2000L,14): " << add14(2000L,14) << std::endl;
18 std::cout << "add14(3,0.1415): " << add14(3,0.1415) << std::endl;
19
20 std::cout << "add14(std::string(\"Hello\"),std::string(\" World\")): "
21 << add14(std::string("Hello "),std::string("World")) << std::endl;
22 std::cout << "add14(\"Hello \"s,\"World\"s): " << add14("Hello "s,"World"s) << std::endl;
23
24 std::cout << std::endl;
25
26 std::vector<int> myVec{1,2,3,4,5,6,7,8,9};
27 auto res= std::accumulate(myVec.begin(),myVec.end(),0,[](int i,int j){ return i+j;});
28 std::cout << "res: " << res << std::endl;
29
30 auto res14= std::accumulate(myVec.begin(),myVec.end(),0, add14);
31 std::cout << "res14: " << res14 << std::endl;
32
33 std::vector<std::string> myStr{"Hello"s," World"s};
34 auto str14= std::accumulate(myStr.begin(),myStr.end(),""s, add14);
35 std::cout << "str14: " << str14 << std::endl;
36
37 std::cout << std::endl;
38
39 }
Besonders praktisch sind generische Lambda-Funktionen beim Einsatz in der Standard Template Library. Sie machen es möglich, Algorithmen ohne die Angabe eines Typs zu formulieren. Der subtile Unterschied zwischen »std::accumulate« in Zeile 27 und »std::accumulate« in den Zeilen 30 und 34 ist, dass die generische Lambda-Funktion »add14()« sowohl für Vektoren vom Typ »int« als auch solche vom Typ »std::string« geeignet ist. Diese Flexibilität fehlt der Lambda-Funktion »[](int i, int j){ return i+j; }« in Zeile 27. Sie lässt sich nur auf »int« -Typen anwenden. In Abbildung 3 ist das Programm in Aktion zu sehen.
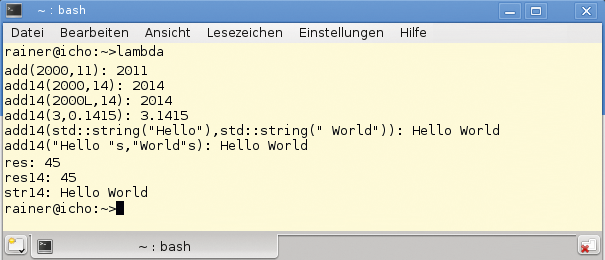
Abbildung 3: Lambda-Funktionen versus generische Lambda-Funktionen.
Viele neue Literale
Literale in C++ repräsentieren einen expliziten Wert. Beispielsweise steht »1« für den Integer-Wert 1, »1L« für den Long-Wert 1. C++14 bringt eine Vielzahl neuer Literale. Mit Ausnahme des binären Literals »0b10« , das durch das Präfix »0b« definiert ist, besitzen alle anderen neuen Literale in C++11 ein Suffix, das hinten angehängt wird. So wird »”Hello”s« durch »s« zum String-Literal. Neben binären Literalen führt C++14 Literale für Strings, Zeitangaben und komplexe Zahlen ein. Tabelle 1 stellt die Neuzugänge mit ihrem Typ und einem Beispiel vor.
Tabelle 1
Literal-Suffixe
|
Präfix/Suffix |
Typ |
Beispiel |
|---|---|---|
|
0b |
bool |
0b10 |
|
s |
std::string |
“Hello”s |
|
i |
complex<double> |
5i |
|
il |
complex<long double> |
5il |
|
if |
omplex<float> |
5if |
|
h |
std::chrono::hours |
5h |
|
min |
std::chrono::minutes |
5min |
|
s |
std::chrono::seconds |
5s |
|
ms |
std::chrono::milliseconds |
5ms |
|
us |
std::chrono::microseconds |
5us |
|
ns |
std::chrono::nanoseconds |
5ns |
Neben der Lesbarkeit bieten die neuen Literale besonders einen großen Vorteil: Da ihre Einheit direkt im Literal ausgedrückt ist, gewährleistet der Compiler die Typsicherheit. Das Rechnen mit Zeitangaben gerät damit zum Kinderspiel. Listing 3 als Beispiel berechnet, wie viel zeitlichen Aufwand ein gewöhnlicher Schultag benötigt. Die Antwort gibt das Programm in unterschiedlichen Zeiteinheiten.
Listing 3
Rechnen mit Zeitliteralen
01 #include <iostream>
02 #include <chrono>
03
04 using namespace std::literals::chrono_literals;
05
06 int main(){
07
08 std::cout << std::endl;
09
10 typedef std::chrono::duration<long long, std::ratio<2700>> hour;
11 auto schoolHour= hour(1);
12 // auto schoolHour= 45min;
13
14 auto shortBreak= 300s;
15 auto longBreak= 0.25h;
16
17 auto schoolWay= 15min;
18 auto homework= 2h;
19
20 auto schoolDayInSeconds = 2 * schoolWay + 6 * schoolHour + 4 * shortBreak + longBreak + homework;
21
22 std::cout << "School day in seconds: " << schoolDayInSeconds.count() << std::endl;
23
24 std::chrono::duration<double,std::ratio<3600>> schoolDayInHours = schoolDayInSeconds;
25 std::chrono::duration<double,std::ratio<60>> schoolDayInMinutes = schoolDayInSeconds;
26 std::chrono::duration<double,std::ratio<1,1000>> schoolDayInMilliseconds = schoolDayInSeconds;
27
28 std::cout << "School day in hours: " << schoolDayInHours.count() << std::endl;
29 std::cout << "School day in minutes: " << schoolDayInMinutes.count() << std::endl;
30 std::cout << "School day in milliseconds: " << schoolDayInMilliseconds.count() << std::endl;
31
32 std::cout << std::endl;
33
34 }
Sekundenbruchteile
Damit er die Zeitliterale verwenden kann, macht der Programmierer sie in Zeile 4 durch »using« bekannt. Per Definition besteht der Zeitaufwand für einen Schultag aus der Dauer von Hin- und Rückweg, sechs Schulstunden, vier kurzen Pausen, einer langen Pause und der Zeit für die Hausaufgaben (Zeile 20).
Die entsprechenden Zeitliterale definieren die Zeilen 14 bis 18. Das Zeitliteral für eine Schulstunde, »45min« , ist in Zeile 12 auskommentiert. Statt dessen kommt das Objekt »schoolHour« in Zeile 11 zum Einsatz. »schoolHour« ist vom Typ »shour« . Dabei entspricht »shour« einer Zeitdauer von 2700 Sekunden, im Typ »long long« gespeichert (Zeile 10).
Da C++ als Auflösung für Zeitangaben Sekunden verwendet, entspricht dies genau 45 Minuten (2700= 45 * 60). Der umständlichen Definition einer Schulstunde in C++11 in den Zeilen 10 und 11 steht die einfache durch das Zeitliteral »45min« (Zeile 12) in C++14 gegenüber. Abbildung 4 zeigt das Resultat des Programms und gibt aus, der Schultag sei 27300 Sekunden lang (Zeile 22). Dies entspricht 7,58333 Stunden (Zeile 28), 455 Minuten (Zeile 29) oder 2.73*107 Millisekunden (Zeile 30).
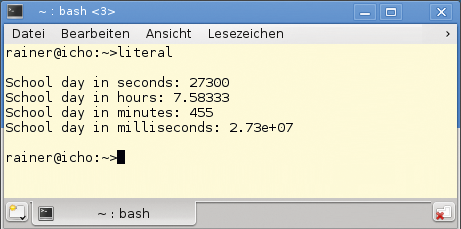
Abbildung 4: Der Zeitaufwand für einen Schultag, in verschiedenen Auflösungen dargestellt.
Die Brüche »std::ratio« in den Zeilen 24 bis 26 geben die Relation zu Sekunden wieder. So steht »std::ratio<3600>« für das 3600-Fache einer Sekunde, »std::ratio<1,1000>« für das 1/1000-Fache einer Sekunde. Um die Brüche exakt darzustellen, speichert der Code sie jeweils in »double« -Typen.
Kritische Wettläufe und Verklemmungen
Um die Problematik von Locks in C++11 und deren Lösung in C++14 einander gegenüberzustellen, ist ein wenig Theorie erforderlich: Ein kritischer Wettlauf um einen Datenbereich entsteht, wenn mehrere Threads gleichzeitig lesend und schreibend auf dessen Variablen zugreifen wollen. Entscheidend ist, dass mindestens einer der Threads die Variable verändern möchte.
Der Einfachheit halber geht dieser Artikel im weiteren Verlauf davon aus, dass der kritische Bereich aus einer einzigen Variablen besteht. Durch das gleichzeitige Lesen und Schreiben ist deren Wert undefiniert. Zu ihrem Schutz benutzen C++11-Programmierer typischerweise einen Mutex (Mutual Exclusion). Dieser stellt sicher, dass ein Thread nur exklusiv, also als Einziger, auf die Variable zugreifen darf. In C++11 verpackt man Mutexe in Locks, um zu gewährleisten, dass der Mutex die Variable wieder freigibt.
Geschieht dies nicht, kann ein vergessener Mutex zu einer so genannten Verklemmung führen. Im Englischen ist der Begriff Deadlock dafür gebräuchlich. In diesem Zustand wartet ein Thread auf Zugang zu dem kritischen Bereich, erhält aber nie den Zugriff. Das Programm ist blockiert und als einzige Rettung bleibt, das Programm mit [Strg]+[C] abzubrechen. Details zum Zusammenspiel von Mutexen und deren Abstraktion in Locks lassen sich in dem Artikel “Gemeinsam ins Ziel” [8] genau nachlesen.
Grobe Locks
Das Problem bei C++11-Locks besteht darin, dass sie zu grob vorgehen: Auch wenn alle Threads nur lesend auf die gemeinsame Variable zugreifen wollen, müssen sie unnötigerweise Schlange stehen und warten, bis sie zum Zuge kommen. Dabei wäre es nur erforderlich, dass der Thread, der die Variable verändern will, ein exklusives Lock auf die Variable erhält. C++14 löst das Problem mit einer besonderen Art von Locking.
Lesen erlaubt
Reader-Writer-Locks [9] erlauben es einerseits, mit Threads zu programmieren, die eine Variable nur gleichzeitig lesen, andererseits mit Threads zu arbeiten, die eine Variable exklusiv modifizieren. Listing 4 gibt ein Beispiel dafür. Die gemeinsame Variable, die es dort zu schützen gilt, ist ein Telefonbuch. Da der lesende Zugriff auf das Telefonbuch viel häufiger stattfindet als der schreibende, bietet es sich an, die neuen Reader-Writer-Locks einzusetzen.
Listing 4
Reader-Writer-Locks
01 #include <chrono>
02 #include <iostream>
03 #include <map>
04 #include <mutex>
05 #include <shared_mutex>
06 #include <string>
07 #include <thread>
08
09 std::map<std::string,int> teleBook{{"Dijkstra",1972},{"Scott",1976},{"Ritchie",1983}};
10
11 std::shared_mutex teleBookMutex;
12
13 void addToTeleBook(const std::string& na, int tele){
14 std::lock_guard<std::shared_mutex> writerLock(teleBookMutex);
15 std::cout << "\nSTARTING UPDATE " << na;
16 std::this_thread::sleep_for(std::chrono::milliseconds(500));
17 teleBook[na]= tele;
18 std::cout << " ... ENDING UPDATE " << na << std::endl;
19 }
20
21 void printNumber(const std::string& na){
22 std::shared_lock<std::shared_mutex> readerLock(teleBookMutex);
23 std::cout << na << ": " << teleBook[na];
24 }
25
26 int main(){
27
28 std::cout << std::endl;
29
30 std::thread reader1([]{ printNumber("Scott"); });
31 std::thread reader2([]{ printNumber("Ritchie"); });
32 std::thread w1([]{ addToTeleBook("Scott",1968); });
33 std::thread reader3([]{ printNumber("Dijkstra"); });
34 std::thread reader4([]{ printNumber("Scott"); });
35 std::thread w2([]{ addToTeleBook("Bjarne",1965); });
36 std::thread reader5([]{ printNumber("Scott"); });
37 std::thread reader6([]{ printNumber("Ritchie"); });
38 std::thread reader7([]{ printNumber("Scott"); });
39 std::thread reader8([]{ printNumber("Bjarne"); });
40
41 reader1.join();
42 reader2.join();
43 reader3.join();
44 reader4.join();
45 reader5.join();
46 reader6.join();
47 reader7.join();
48 reader8.join();
49 w1.join();
50 w2.join();
51
52 std::cout << std::endl;
53
54 std::cout << "\nThe new telephone book" << std::endl;
55 for (auto teleIt: teleBook){
56 std::cout << teleIt.first << ": " << teleIt.second << std::endl;
57 }
58
59 std::cout << std::endl;
60
61 }
Als Telefonbuch kommt in Zeile 9 eine Map zum Einsatz. Diese bildet Strings auf natürliche Zahlen ab, beziehungsweise Namen auf Telefonnummern. Die Zeilen 30 bis 39 sind dabei der Dreh- und Angelpunkt. Zehn verschiedene Threads möchten gleichzeitig das Telefonbuch verwenden. Aber nur zwei davon, »w1« und »w2« (Zeilen 32 und 35), wollen das Telefonbuch modifizieren, die restlichen Threads geben nur die Telefonnummer auf der Konsole aus. Alle Threads erhalten ihre Arbeitspakete als Lambda-Funktionen, die die globalen Funktionen »printNumber« (Zeile 21) oder »addToTeleBook()« (Zeile 13) aufrufen.
Das Entscheidende an der Funktion »printNumber()« zum Ausgeben der Telefonnummer ist der Ausdruck »std::shared_lock<std::shared_mutex> readerLock(teleBookMutex)« in Zeile 22. Er stellt durch das Shared Lock auf den Shared Mutex »teleBookMutex« sicher, dass die lesenden Threads beim Zugreifen auf die Map »teleBook[na]« in der folgenden Zeile gemeinsam den Mutex verwenden. Beim Verlassen der Funktion wird das Shared Lock und damit auch der Shared Mutex automatisch freigegeben.
Im Gegensatz dazu steht der Ausdruck »std::lock_guard<std::shared_mutex> writerLock(teleBookMutex)« (Zeile 14) in der Funktion »addToTeleBook()« . Er benutzt für den synchronisierten Zugriff exklusiv den gleichen Mutex »teleBookMutex« . Durch »std::lock_guard« in Kombination mit »std::shared_mutex« ist der Zugriff auf die Variable »teleBook[na]« exklusiv, während »std::shared_lock« in Kombination mit »std::shared_mutex« den gemeinsamen Zugriff erlaubt.
Mutex plus Lock
Aus den Sprachfeatures Shared Mutex und Shared Lock entstehen so die Reader-Writer-Locks. Je nachdem, wie der Programmierer den Mutex anwendet, gewährt er einem einzigen Thread exklusiven Zugriff (»lock_guard<shared_mutex>« ) oder mehreren Threads gemeinsam lesenden (»shared_lock<shared_mutex>« ).
Der Rest des Programms ist schnell erklärt: Die Funktion »addToTeleBook« schreibt die zwei Statusmeldungen (Zeilen 15 und 18) auf die Konsole und schläft für eine halbe Sekunde, während sie exklusiv das Lock hält. Zum Abschluss geben die Zeilen 55 bis 57 den Inhalt des Telefonbuchs aus.
Wer sich die Ausgabe des Programms in Abbildung 5 genau ansieht, wird sich vermutlich wundern. Nur der Aufruf der Funktion »addToTeleBook()« mit den Statusmeldungen »STARTING UPDATE […] ENDING UPDATE« für Scott und Bjarne wird geschützt ausgeführt, sodass der Inhalt des Telefonbuchs die definierten Werte besitzt. Die lesenden Threads dagegen schreiben unkoordiniert auf die Konsole. Das ist aber nicht verwunderlich, denn die Konsole ist eine gemeinsame Variable, die lesenden Threads greifen gleichzeitig schreibend auf sie zu. Das Ergebnis ist der abgebildete Textsalat. Wer wissen möchte, was C++14 noch zu bieten hat, dem sei der gelungene Wikipedia-Artikel [10] empfohlen.
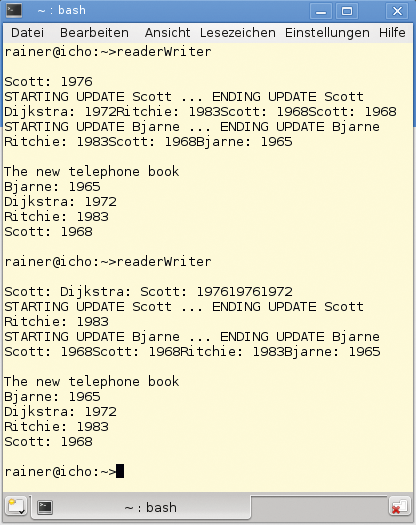
Abbildung 5: Gemeinsames Lesen und Schreiben eines Telefonbuchs mit Reader-Writer-Locks.
Wie geht’s weiter?
Der nächste Artikel dieser Reihe wird in die Tiefen des C++11-Memory-Modells eintauchen und die Antwort auf den Leserbrief von Jörg Böhme [11] geben. Das C++11-Memory-Modell basiert auf den Erfahrungen des Java-Memory-Modells und definiert unter anderem Zusicherungen, wann eine Aktion eines Thread für andere Threads sichtbar ist. Überraschungen – und nicht nur für den C++-Guru – gibt es in der nächsten Folge inklusive. (mhu)
Infos
- Status der C++-Standardisierung: http://isocpp.org/std/status
- Rainer Grimm, “Neue Ausdruckskraft”: Linux-Magazin 02/14, S. 104
- Rainer Grimm, “Die Elf spielt auf”: Linux-Magazin 12/11, S. 94
- Rainer Grimm, “Kurz und knackig”: Linux-Magazin 02/12, S. 92
- Clang 3.4: http://llvm.org/releases/3.4/tools/clang/docs/ReleaseNotes.html
- GCC 4.9: http://gcc.gnu.org/gcc-4.9/changes.html
- “When will compilers implement C++14?”: http://isocpp.org/wiki/faq/cpp14#cpp14-compilers
- Rainer Grimm, “Gemeinsam ins Ziel”: Linux Magazin 06/12, S. 90
- Howard Hinnant, Detlef Vollmann, Hans Boehm, “Shared locking in C++”: http://isocpp.org/blog/2013/04/n3659-shared-locking
- C++14: http://en.wikipedia.org/wiki/C%2B%2B14
- Jörg Böhme, Leserbrief zum Memory Management: Linux Magazin 01/14, S. 82
- Listings zum Artikel: https://www.linux-magazin.de/static/listings/magazin/2014/04/cpp/
Der Autor

Rainer Grimm arbeitet als Software-Architekt und Gruppenleiter bei der Metrax GmbH in Rottweil. Insbesondere die Software der hauseigenen Defibrillatoren ist ihm eine Herzensangelegenheit. Seine Bücher “C++11 für Programmierer” und “C++ kurz & gut” sind beim Verlag O’Reilly erschienen.





