© Gina Sanders, Fotolia
Gerade im Notfall will der Admin schnell informiert sein, wenn ein System in der privaten Wolke streikt. Weder Monitoring- noch Hochverfügbarkeits-Konfiguration müssen dabei kompliziert sein, auch ein einfaches Setup mit KVM, Pacemaker, DRBD und Opsview hilft in den meisten Fällen.
Seit der Release 2.6.20 des Linux-Kernels im Februar 2007 ist die Kernel-based Virtual Machine KVM ([1], [2]) auf dem besten Weg, andere Virtualisierungslösungen in vielen Bereichen vom Markt zu verdrängen. Nicht selten dient KVM auch als Grundlage für einen Virtualisierungscluster, der mehrere Gäste in einer hochverfügbaren Umgebung betreibt – dank Open-Source-Tools wie Heartbeat [3] und Pacemaker [4].
Nur wenig Monitoring
Dennoch sehen immer noch viele Systemverwalter bei Clustern keine Notwendigkeit, die Hosts und virtuellen Gäste zu monitoren. Heartbeat und Pacemaker bieten eingebaute Alerting-Funktionen. Vielen Admins reicht es, per E-Mail über den neuen Status des Clusters informiert zu werden. Doch mit einem einheitlichen, zentralen Monitoring, das auch die virtuellen Gastsysteme einer privaten Wolke einbindet, erhält der Admin eine nicht zu unterschätzende Notfallzentrale, in der er alle Systeme auf einen Blick überwachen und im Ernstfall sofort eingreifen kann.
Doch noch vor dem Monitoring stehen grundsätzliche Überlegungen zum Cluster-Setup: Eine simple Kombination aus Heartbeat und Pacemaker mit der Virtualisierung KVM sowie Logical Volumes und DRBD [5] kann vielleicht nicht mit dem Funktionsumfang von VMware mithalten, dafür muss der Admin aber auch nicht so tief in die Tasche greifen (Abbildung 1). Mit wenig Aufwand erhält er ein System, in dem immer eine virtuelle Instanz verfügbar ist.
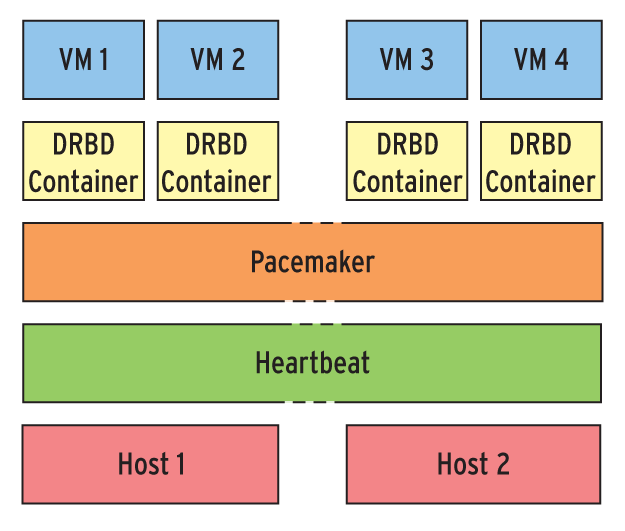
Abbildung 1: Zwei leistungsstarke Server als Gastgeber sowie Heartbeat, Pacemaker und DRBD bilden das Gerüst der Corebiz Virtual Server Base. Die Überwachung des Ganzen übernimmt Opsview.
Permanente Datensynchronisation mit DRBD sorgt dafür, dass zumindest die auf der virtuellen Festplatte gespeicherten Daten sofort wieder verfügbar sind, nur ungesicherte Session-Daten der Anwender gehen verloren, ähnlich wie bei einem lokalen Systemabsturz. Raucht einer der beiden Virtualisierungshosts ab, booten die VMs ganz automatisch neu. Dann aber laufen alle Instanzen auf einem Knoten. Die Mitarbeiter können nach kurzer Zeit weiterarbeiten, genügend Ressourcen auf dem verbleibenden Node vorausgesetzt.
DRBD und Logical Volumes
Abbildung 1 zeigt das Beispiel eines Linux-Clusters mit zwei Knoten auf Basis des Linux-Systems Corebiz VSB (Virtual Server Base, [6]) der Münchner LIS AG. Für die virtuelle Festplatte einer VM besteht der Stack aus dem physikalischen Speicher (in der Regel ein Raidsystem), einer LVM-Partition und für die Datenreplikation zwischen den beiden Knoten einem DRBD-Container. Der wird entweder der virtuellen Maschine direkt zugewiesen oder alternativ auf dem Cluster eingebunden und als Partition für eine Imagedatei (Qcow2, Vmdk, …) genutzt.
Dem Cluster-Management dient die Kombination aus Heartbeat 3 und Pacemaker ([7], [8]). Ersteres sorgt dafür, dass die Knoten miteinander kommunizieren können, und prüft, ob das “Herzklopfen” eines Knotens noch zu hören, also ob der Node noch verfügbar ist. Pacemaker als Cluster Resource Manager (CRM) weiß, welche Dienste im Cluster voneinander abhängen, und kennt zu jedem Zeitpunkt deren Zustand.
Fürs Monitoring ist besonders Pacemaker von Interesse. Um den Zustand der Cluster-Ressourcen festzustellen, nutzt er so genannte OCF-Agenten (Open Cluster Framework, [9]). Die sind eine Art Weiterentwicklung der Ressourcen-Agenten der Linux Standard Base (LSB), die Admins als Init-Skripte unter »/etc/init.d« auf einem Linux-System finden. Ein solcher Agent stellt typischerweise folgende Funktionen bereit:
- »start« : Startet die Ressource
- »stop« : Stoppt die Ressource
- »monitor« : Gibt Auskunft über den Status der Ressource
- »meta-data« : Gibt Informationen über die Ressource
Einen OCF-Agenten kann der Admin zwar in einer beliebigen Programmier- oder Skriptsprache erstellen, die meisten Agenten sind jedoch simple Shellskripte. Weitere Parameter, die viele Agenten benötigen, um die oben genannten Aktionen durchführen zu können, sind in der Konfiguration der Pacemaker-Ressourcen festgelegt. Darüber hinaus muss der Admin noch Timeouts und Monitor-Intervalle definieren.
Jeder Ressource im Cluster weist der Admin einen passenden Agenten zu und gibt ihm die nötige Konfiguration mit. Der KVM-Cluster braucht einen Agenten für DRBD und das Management der virtuellen Maschinen. Für Letzeres bietet sich meist der Agent »ocf:heartbeat:VirtualDomain« an, bei Corebiz kommt eine Eigenentwicklung zum Zug.
Neben dem Starten und Stoppen prüft Pacemaker diese Ressourcen auch automatisch und regelmäßig mit dem Monitor-Kommando der OCF-Agenten. Auf diese Weise weiß der Cluster ständig über den Zustand seiner Ressourcen Bescheid.
Per Default prüfen der Corebiz-OCF- und auch der Virtual-Domain-Agent lediglich, ob eine KVM-Instanz aktiv, aber nicht, ob ein einzelner Dienst erreichbar ist. Doch »ocf:heartbeat:VirtualDomain« erlaubt weitere Checks, um die Verfügbarkeit beliebiger Dienste zu prüfen und diese automatisch auch auf anderen Hosts neu zu startet. Die Ursache des Ausfalls ist damit aber nicht behoben.
Agenten, Agenten!
Ist der Stand-alone-KVM-Host oder gleich ein ganzer Cluster auf Basis der oben beschriebenen Komponenten in Betrieb genommen, kann die Überwachung der einzelnen Ressourcen beginnen. Jetzt muss sich der Admin zunächst Gedanken über die richtigen Werkzeuge und die zu überwachenden Ressourcen machen. Weil im Falle von Software- oder Hardware-Versagen der oder die Hosts nicht wissen können, welche Anwendungen innerhalb der abgeschotteten virtuellen Umgebungen laufen, muss der Planer sein Hauptaugenmerk auf die Dienste, Prozesse und Anwendungen innerhalb der Gäste legen.
Zusätzlich muss er sicherstellen, dass die entsprechende KVM-Instanz auch aktiv ist. Im Cluster stößt er darüber hinaus auf das Problem, dass die Monitoring-Anwendung nicht wissen kann, auf welchem Knoten die virtuelle Maschine aktiv ist – sie prüft meist nur die Dienste in Form einer IP-Adresse in Verbindung mit einzelnen Ports.
Da ist es sinnvoll, das Überwachen von KVM-Instanzen Pacemaker zu überlassen, da dieser über alle im Cluster vorhandenen Ressourcen Bescheid weiß. Das Monitoringtool der Wahl sollte sich daher – zumindest im Cluster – auf das Monitoring des Schrittmachers konzentrieren. Das vorliegende Beispiel realisiert diese Anforderung mit dem Nagios-Plugin »check_crm« , wobei »crm« für den Cluster Resource Manager steht.
Im Stand-alone-Betrieb ist es ratsam, den Host direkt mit den Standardchecks zu überprüfen. In Frage kommen dafür die Erreichbarkeit übers lokale Netzwerk, die Systemauslastung und der SSH-Zugang – schließlich möchte der Admin stets wissen, ob der Fernzugriff auf den Host möglich ist. Für den KVM-Host muss er daher mindestens folgende Ressourcen im Blick behalten:
- Connectivity (LAN)
- Unix-Load
- RAM/Swap-Auslastung
- Storage Utilisation
- SSH-Verfügbarkeit (meist auf Port 22)
- Optionale Erweiterungen: Bei Verwendung von Libvirt lässt sich beispielsweise prüfen, ob der Daemon Libvirtd läuft (Abbildung 2).

Abbildung 2: Die richtigen Checks sind die halbe Miete: Hier prüft ein Monitoringsystem, ob der Libvirtd läuft.
Diese Checks genügen in den meisten Fällen, um zuverlässig Auskunft über den Zustand des Hosts geben zu können. Wer das KVM-System dann, wie oben beschrieben, zum Cluster ausbaut, sollte mindestens noch die Dienste CRM und DRBD ins Monitoring integrieren.
Keine Ahnung vom Gast
Weil der Cluster selbst keine Kenntnis über die Vorgänge in der virtuellen Maschine besitzt, muss das Monitoring-System auch diese überwachen. Für jeden Linux-Gast ergeben sich daher fast identische Anforderungen wie für das Host-System (siehe oben).
Zu den Basischecks kommen aber pro Gast noch (meist mehrere) individuelle Erweiterungen, weil je nach Anwendungsszenario auch die Dienste zu überwachen sind, die die virtuellen Gäste anbieten. Für einen Webserver wären dies etwa die Erreichbarkeit des Apache via HTTP, FTP und einer Datenbank, falls vorhanden.
Windows-Gäste lassen sich anhand der Verfügbarkeit folgender Systemressourcen überwachen:
- Connectivity (LAN)
- CPU-Auslastung
- Arbeitsspeicher
- Auslagerungsdatei
- Freie Kapazitäten auf den Laufwerken
- Verfügbarkeit des RDP-Zugangs für die Fernverwaltung
- Überwachung der Windows-Event-Logs »Application« , »Security« und »System«
Zusätzlich kommt auch hier niemand um das Monitoring der Applikationen herum, zu deren Zweck der Windows-Gast aufgesetzt wurde. Bei dem Einsatz von Branchensoftware ist es möglich, kontinuierlich nach bestimmten laufenden Diensten und Prozessen zu suchen. Segnet der zuständige Dienst zu einer Anwendung das Zeitliche, kann so der Admin zumindest informiert werden.
Bei der Frage nach dem richtigen Monitoringtool liegt der Griff zu Altbewährtem nahe, Nagios [10] scheint die erste Wahl. Dank der Anzahl der frei verfügbaren Check-Plugins und Erweiterungen ist es in vielen Fällen das Tool der Wahl, um einen Stand-alone-Server oder auch den Cluster im Auge zu behalten. Dagegen spricht, dass die Datei-basierte Konfiguration von Nagios so manchem Neuling Probleme bereitet. Für Quereinsteiger oder Freunde von simplen Konfigurationen in komplexen Umgebungen bietet sich ein modifizierten Nagios an, zum Beispiel Opsview [11]. Das Tool setzt auf Nagios auf, erweitert es um zahlreiche Features und bietet ein komfortables und modernes Webinterface. Anders als in manch anderen Weboberflächen kann der Admin hier zusätzlich die gesamte Nagios-Konfiguration vornehmen, neue Hosts anlegen oder einzelne Service-Checks feintunen (Abbildung 3).
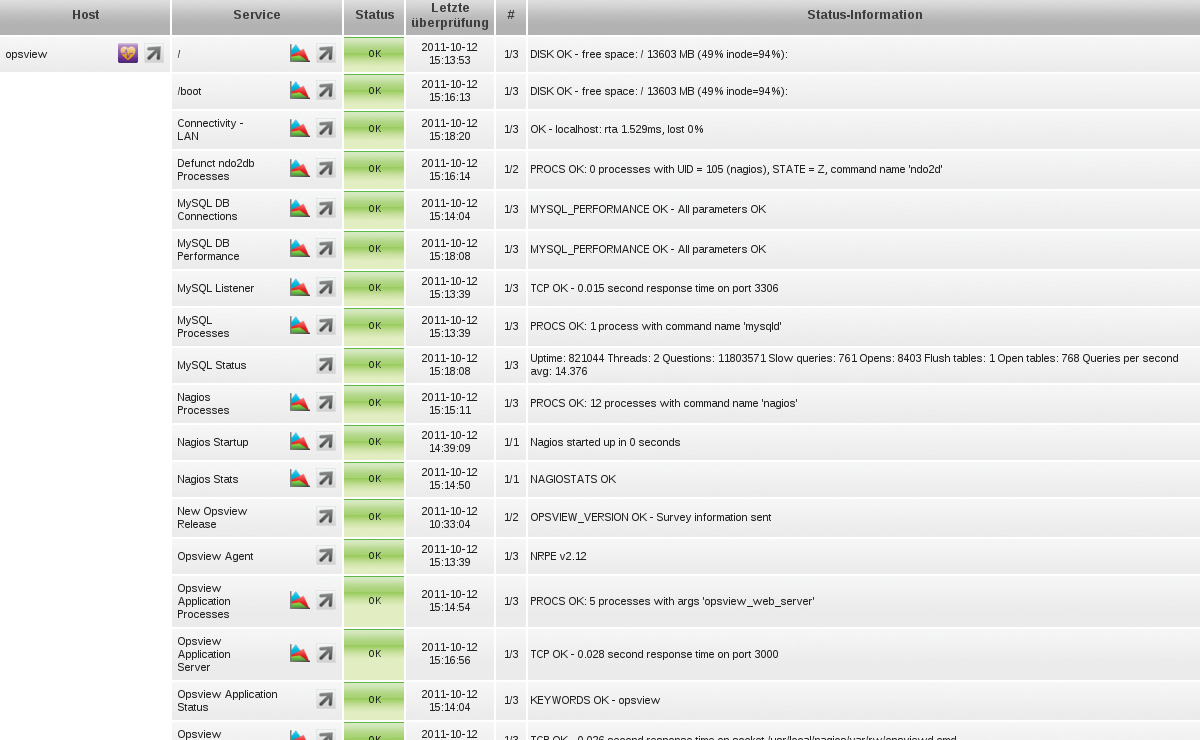
Abbildung 3: Nagios für Einsteiger: Opsview wartet mit einem schlanken und übersichtlichen Webinterface auf, erlaubt es aber auch, neue Hosts und Services via GUI hinzuzufügen.
Opsview speichert alle Einstellungen in MySQL-Datenbanken und generiert daraus die Konfigurationsdateien für Nagios. Auch zusätzliche Service-Checks, zum Beispiel für das Überwachen der Unix-Load, sind möglich. Für alle Hosts, die denselben Check zur Überwachung zugeteilt bekommen, greifen dann die allgemeinen Parameter des Service-Checks. Da die überwachten Systeme jedoch meist auch verschiedenen Zwecken dienen, lassen sich die Service-Checks auch über Attribute detaillierter spezifizieren und für jeden einzelnen Host individuell festlegen.
Ein weiteres Schmankerl von Opsview stellen die Benachrichtigungsprofile dar, die sogar für kleinere KVM-Installationen schon sinnvoll sind. Sie ermöglichen es beispielsweise, jeweils nur den Inhaber der virtuellen Instanz über Ausfälle zu benachrichtigen, was dritte Personen vor für sie uninteressanten Benachrichtigungen bewahrt.
Argumentationsgrundlagen für SLA-Agreements
Für Fans von Statistiken und größeren Auswertungen gibt es zudem die Möglichkeit, die einzelnen zugewiesenen Checks mit Schlüsselwörtern zu versehen und somit Ressourcen zu gruppieren. Das Feature »Report erstellen« von Opsview wertet diese Keywords aus und erzeugt PDF-Dateien, die nützliche Statistiken über die Verfügbarkeit der einzelnen Ressourcen beinhalten. Unternehmen, die mit SLAs arbeiten, können mit Hilfe dieser Reports ihren Kunden gegenüber verdeutlichen, dass sie alle Vereinbarungen eingehalten haben (Abbildung 4).
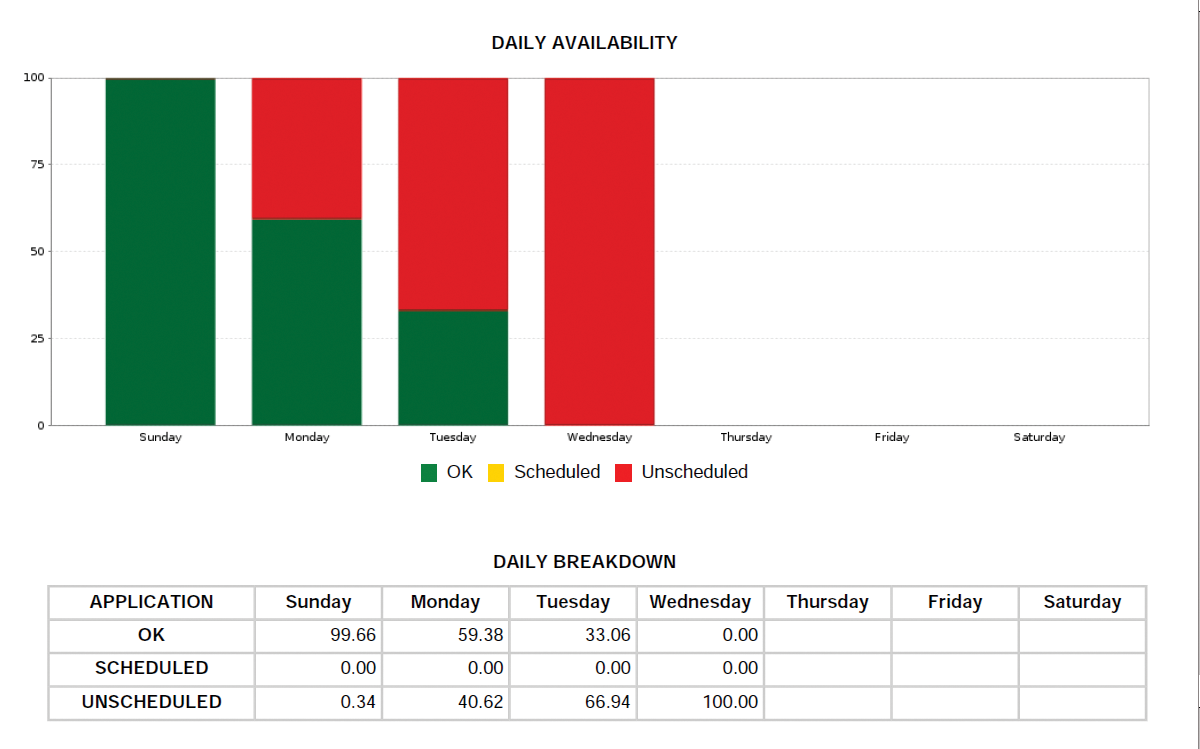
Abbildung 4: Der Beispiel-Report von Opsview zeigt die RAM-Auslastung einer virtuellen Maschine über einen Zeitraum von vier Tagen.
Doch Vorsicht: Der Admin sollte immer darauf achten, nur einen Report zur gleichen Zeit zu erstellen. Denn selbst Opsview-Installationen mit einer geringen Anzahl an Service-Checks können andernfalls eine hohe Systemlast verursachen. Auch ein Blick auf die Webseite des Herstellers lohnt sich: Dort gibt es nützliche Tipps zur Optimierung von MySQL, was bei entsprechender Anwendung auch im Alltagsbetrieb der Monitoring-Software Vorteile bei der Performance mit sich bringt.
Eine App für den Admin-Androiden
Eingefleischte Open-Source-Anwender können sich zusätzlich über eine Android-App sowie ein Browser-Plugin für Google Chrome freuen, womit sie alle Server stets im Auge behalten. Besonders fleißigen Systemadministratoren, die ihr KVM-System auch unterwegs observieren möchten, bietet sich die kostenlose Android-App Opsview Mobile an ([12], Abbildung 5). Nach dem Eingeben der API-URL zu Opsview sowie der Login-Credentials zeigt die App den Status der überwachten Systeme zumindest dann, wenn der Monitoring-Server übers Internet erreichbar ist.
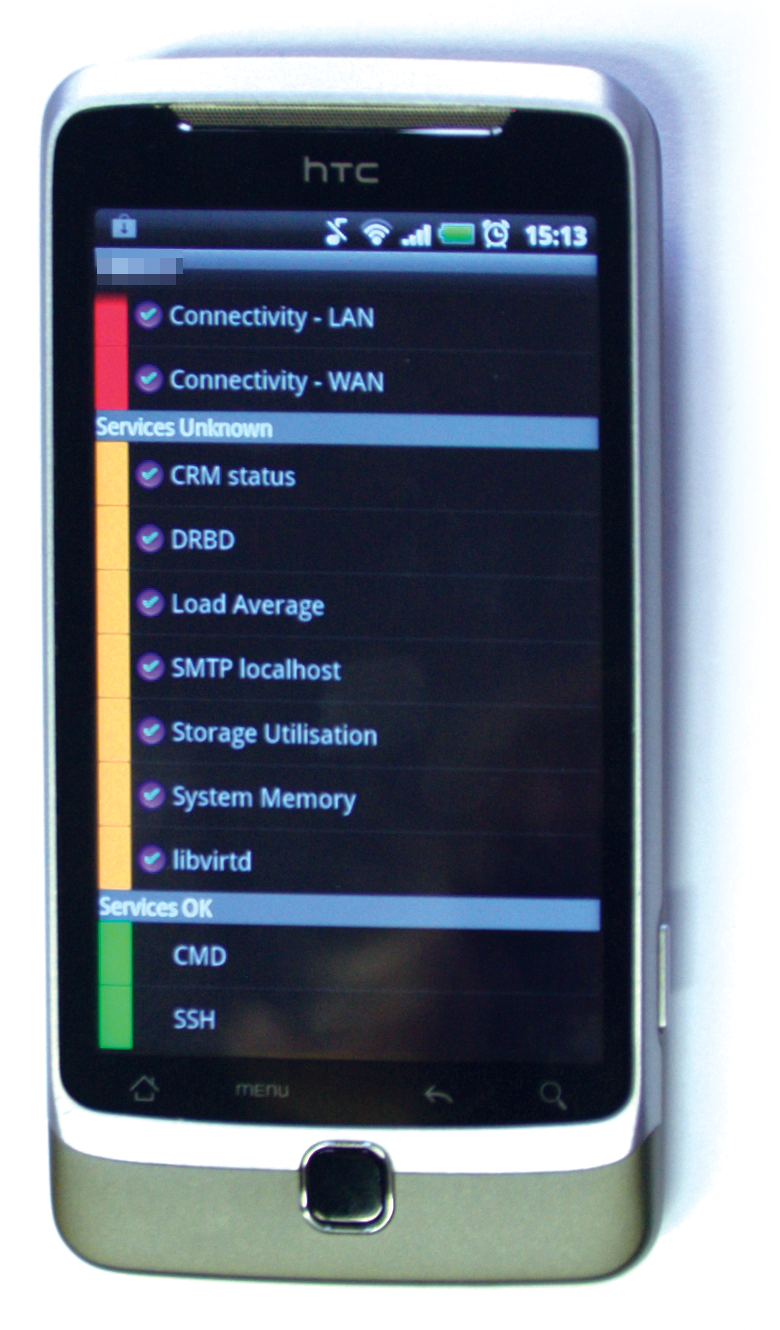
Abbildung 5: Die kostenlose Opsview-App gibt’s auch im Android Market.
Für die Überwachung von Windows-Systemen steht der Opsview Agent for Windows in einer 32- und 64-Bit-Variante zur Verfügung. Der Agent läuft auch auf älteren Windows-2000-Server-Installationen und legt die Grundlage für das Einbinden von Microsoft-Gästen ins Monitoring. Das auf Nsclient++ [13] basierende Tool installiert sich wie jede andere gewöhnliche Software.
SNMP-Traps und LDAP
Für Unternehmen hingegen bietet Opsview die Möglichkeit, SNMP-Traps auszuwerten, eine LDAP-Anbindung vorzunehmen oder die im vorgestellten Setup nützliche Option, das Monitoringtool auf mehrere Server zu verteilen. Weitere Unterschiede zwischen Nagios und der frei erhältlichen Erweiterung Opsview zeigt [14]. Von Opsview gibt es auch eine Enterprise-Variante, die je nach Ausstattung zwischen knapp 10 000 und 50 000 Dollar kostet. Für die meisten Setups reicht jedoch die Community-Edition vollkommen aus.
Sowohl für DRBD als auch den Cluster Resource Manager Pacemaker liefert Opsview je ein Plugin, das deren aktuellen Zustand zuverlässig abfragt. Die Plugins sind auf den KVM-Hosts meist unter »/usr/lib/nagios/plugins« zu finden. Das für die Überwachung von DRBD zuständige Perl-Skript heißt »check_drbd« und lässt sich auch in der Shell ausführen. Es wertet die Ausgabe von »/proc/drbd« aus und gibt bei Unregelmäßigkeiten die Zustände »OK« , »WARNING« , »CRITICAL« und »UNKNOWN« zurück.
In Opsview selbst lässt sich zum Auswerten dieser Übergabe ein gewöhnlicher »check_by_SSH« -Check anlegen:
check_by_ssh -H Adresse_des_Hosts -l Benutzername-C "/usr/lib/nagios/plugins/check_drdb -d All"
Der Parameter »-d ALL« weist den Agenten an, den Check auf allen DRBD-Devices auszuführen (Abbildung 6). Auch den Status der CRM-Ressourcen ermittelt er auf ähnliche Weise. Auf jedem KVM-Host findet sich das Perl-Skript »check_crm« , das »/usr/sbin/crm_mon« aufruft und die Ausgabe auf Fehler prüft. Wie bei der Überprüfung von DRBD wird der Service-Check selbst ebenfalls mit »check_by_SSH« angelegt:
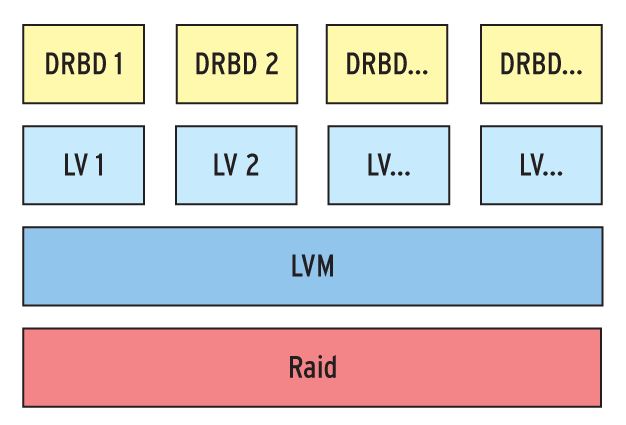
Abbildung 6: Wer DRBD einsetzt, sollte seine Nagios-Checks anweisen jedes DRBD-Device in jedem Volume zu prüfen.
check_by_ssh -H Adresse_des_Hosts -l Benutzername -C "/usr/lib/nagios/plugins/check_crm"
Nagios verbindet sich daraufhin in regelmäßigen Abständen via SSH mit dem zu überwachenden Server und führt das angegebene Kommando aus.
Automatische Aktionen
Neben der gewöhnlichen Überwachung von Ressourcen und dem Alerting im Notfall kann das Monitoring auch als Grundlage für weiterführende Aktionen dienen. Denkbar wäre, dass bestimmte Service-Checks bei der Rückgabe des »WARNING« -Status automatisiert Aktionen auslösen, um einem Ausfall vorzubeugen. Deutet sich beispielsweise die Überlastung eines Cluster-Node an, so könnte der Hypervisor zuvor definierte virtuelle Gäste automatisch auf den zweiten Knoten migrieren. Der unter Volllast stehende Knoten hätte auf diese Weise die Gelegenheit, sich regelrecht zu erholen, und läuft gar nicht erst Gefahr, den Cluster durch einen kompletten Ausfall zu belasten.
Tatsächlich sind solche automatisierten Umschaltungen zwischen aktiven Hosts nur dann möglich, wenn der Ausfall der betroffenen virtuellen Maschinen für zumindest wenige Minuten verkraftbar ist. Geht das nicht, könnte eine Live-Migration der Gäste helfen. Die aber gestaltet mit Konzepten wie Multi-Primary und Fencing das Cluster-Setup sowie die Administration deutlich komplexer.
Für die Administration eines Pacemaker-Clusters gibt es mehrere GUI-Tools, die das Management von Ressourcen vereinfachen. Die wahrscheinlich umfangreichste Implementation ist die so genannte DRBD Management Console [15] des in Wien ansässigen Unternehmens Linbit. Der Name ist dabei etwas irreführend, da es weit über das Management von DRBD hinausgeht und sämtliche Komponenten eines Linux-Clusters verwaltet, auch Pacemaker, Corosync, Heartbeat, DRBD, KVM, Xen und LVM.
DRBD MC wird LCMC
Einen neuen Namen brachte der jüngste Fork der DRBD MC. Der vermeintliche Nachfolger firmiert als Linux Cluster Management Console (LCMC, [16], Abbildung 7). Die genauen Gründe dafür lassen sich in der Ankündigung unter [17] nachlesen. Es bleibt spannend, wie sich die LCMC in Zukunft weiterentwickeln wird, da der bisherige Entwickler das Projekt [18] künftig in seiner Freizeit fortführen wird.
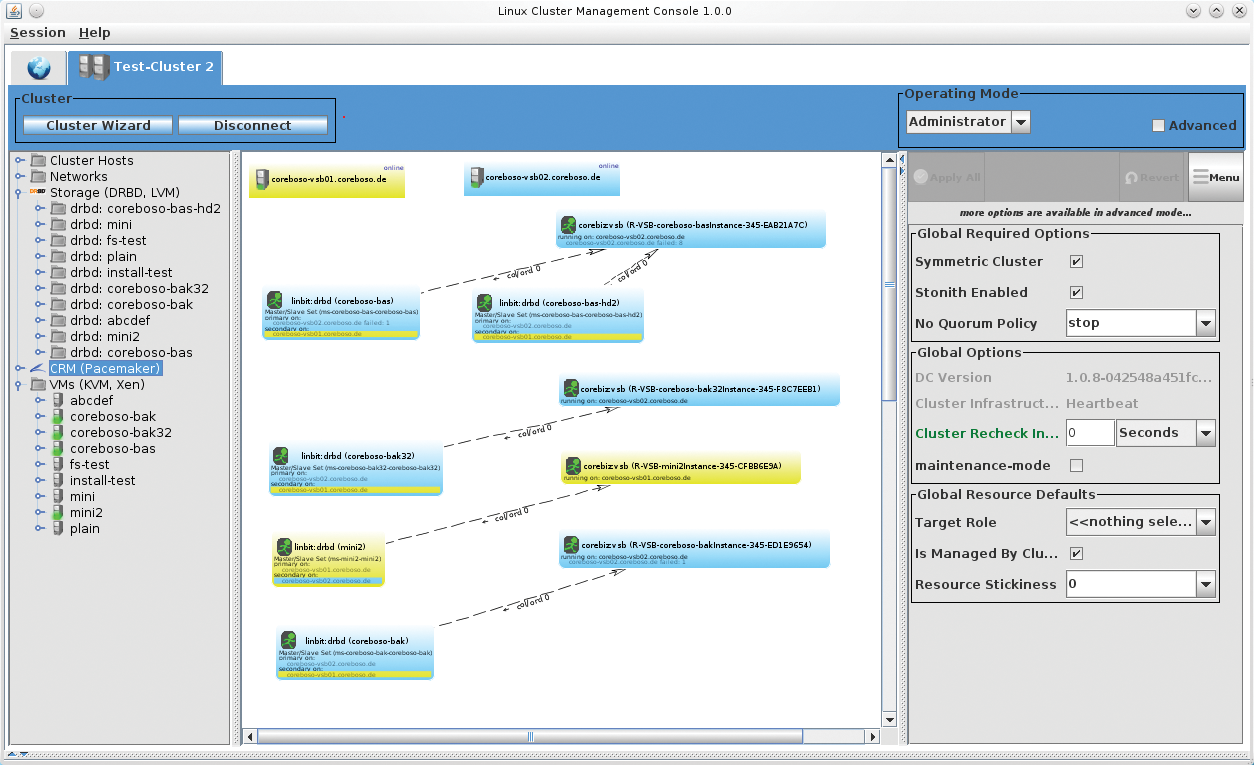
Abbildung 7: Bau von Clustern mit der Linux Cluster Management Console.
Infos
- KVM: http://www.linux-kvm.org
- Thorsten Scherf, “Senkrechtstarter”: Linux-Magazin 03/09, S. 30
- Heartbeat: http://linux-ha.org
- Pacemaker: http://www.clusterlabs.org
- DRBD: http://www.drbd.org
- Corebiz Virtual Server Base: http://www.linux-ag.com/produkte/CB-Virtualisierung/
- Andreas Sebald, “Reservespieler”: Linux-Magazin 07/04, S. 60
- Michael Kromer, “Schrittmacherdienste”: Linux-Magazin 11/10, S. 86
- OCF-Agenten: http://linux-ha.org/wiki/OCF_Resource_Agents
- Nagios: http://www.nagios.org
- Opsview: http://www.opsview.com
- Opsview Mobile: https://market.android.com/details?id=com.opsview.android
- Nsclient++: http://www.nsclient.org
- Unterschiede zwischen Nagios und Opsview: http://www.opsview.com/community/compare-opsview
- DRBD MC: http://oss.linbit.com/drbd-mc
- Linux Cluster Management Console: http://lcmc.sf.net
- Announcing LCMC: http://oss.clusterlabs.org/pipermail/pacemaker/2011-October/011574.html
- LCMC-Sourcecode: https://github.com/rasto/lcmc





