
© Yuanyuan Xie, 123RF.com
Was steckt im Linux-Kernel 3.0? Ein Rundgang durch Taskverwaltung, Memory-Management und weitere wichtige Architekturmerkmale eines modernen Betriebssystemkerns.
“Der Punkt ist, dass 3.0 nichts weiter als eine Neunummerierung bedeutet”, schreibt Linus Torvalds trocken in seiner Freigabemail zur Vorabversion des neuen Kernels [1]. Im Vergleich zum letzten Kernel der 2.6er Serie – Kernel 2.6.39 – hat Torvalds recht: “Keine Änderungen am Systemcall-Interface, keine Änderungen an der Programmierschnittstelle oder sonstige neue, magische Features, nur der übliche Fortschritt, im Wesentlichen Treiberupdates.”
Stille Revolution
Doch es kommt auf die Perspektive an. Der Vergleich mit Kernel 2.6.0 offenbart durchaus eine Revolution: Aus dem Kernel für ein Standardbetriebssystem ist in acht Jahren ein Kernel mit ausgefuchsten Echtzeiteigenschaften geworden. Seine Grundwerte hat er trotzdem behalten: Skalierbarkeit, Portierbarkeit, Cutting Edge und Open Source. Linux erschließt sich neue Einsatzfelder, ohne alte aufzugeben.
Linux ist, wie auch schon die ersten Unix-Systeme, monolithisch aufgebaut. Alle zentralen Dienste sind in einem großen Ganzen, dem Kernel, untergebracht. Das erhöht zwar – wie die Befürworter einer Mikrokernel-Architektur behaupten – das Risiko für Instabilitäten, in der Praxis aber überwiegen die Performance-Vorteile bei Weitem, die sich durch den Wegfall von Kontext-Wechselzeiten ergeben. Der Linux-Kern gilt trotzdem von jeher als ausgesprochen stabil.
Abbildung 1 zeigt grob den Aufbau des Systems. Das Systemcall-Interface legt Art und Anzahl der Dienste fest, die eine Applikation vom Betriebssystem anfordern kann: Jobs starten oder beenden, Daten speichern, lesen oder per TCP/IP an andere Rechner übertragen oder einfach nur die Uhrzeit auslesen. Kernel 2.6.0 offerierte bei einem 32-Bit-Linux 274 Dienste, bei 3.0 sind es schon 347. Die Dienste erbringen die darunter liegenden Blöcke I/O-, Task- und Memory-Management, die auf die Hardware über die Gerätetreiber zugreifen.

Abbildung 1: Systemarchitektur: Kernel 3.0 gehört zwar zu den monolithischen Betriebssystemkernen, ist aber modular aufgebaut.
Bei feinerer Unterteilung werden die Subsysteme des Kernels sichtbar, etwa für den Zugriff auf USB- oder PCI-Geräte, für Multimedia und Netzwerk. Die Schnittstellen zu den Subsystemen sind im Linux-Kernel meist so flexibel, dass sich verschiedenste Implementierungen für einzelne Funktionen – etwa den I/O-Scheduler – andocken lassen.
Innerhalb des Kernels ist die Taskverwaltung von zentraler Bedeutung, sie ist für das Multitasking – die gleichzeitige Abarbeitung mehrerer Programme – zuständig. Dabei mehrere CPU-Kerne zu nutzen ist für Linux seit vielen Jahren selbstverständlich.
Grundsätzlich ist das Scheduling – also das Festlegen, wann welche Task wie lange auf welchem CPU-Kern arbeitet – zweistufig aufgebaut: Der Multicore-Scheduler fasst einzelne Prozessoren beziehungsweise Prozessorkerne einer Mehrkernmaschine zu Gruppen zusammen. Innerhalb der Gruppe verteilt Linux die Tasks auf die CPUs. In der zweiten Stufe, dem Singlecore-Scheduling, wählt jeder einzelne Prozessorkern aus den zugeteilten Tasks jene aus, die laufen darf.
Verteilungskämpfe
Bevor der Multicore-Scheduler aktiv wird, hat der Kernel bereits beim Booten ein Abbild der vorhandenen Hardware angefertigt und diese aufgrund der Multicore-Architektur (Hyperthreading, Symmetric Multiprocessing, Non Uniform Memory Architecture) hierarchisch in so genannte Scheduling-Domains eingeteilt. Sie bestehen aus Scheduling-Gruppen, diese wiederum aus CPU-Kernen oder anderen Scheduling-Domains. Jeder Gruppe beziehungsweise jedem CPU-Kernel ist eine Liste der zugehörigen Jobs zugeordnet.
Lastverteilung
Der Scheduler sorgt durch Prozessmigration, also das Verschieben eines Jobs auf einen anderen Kern oder in eine andere Gruppe, innerhalb seiner Domain für eine ausbalancierte Lastverteilung. Multicore-Scheduling ist immer dann aktiv, wenn sich ein Job beendet, ein neuer Job gestartet wird, sich schlafen legt oder wenn ein starkes Ungleichgewicht bei der Auslastung der einzelnen Rechnerkerne festgestellt wird. Ob in letzterem Fall eine Prozessmigration Vorteile bringt, rechnet Linux in jedem Einzelfall aus, zudem kann der Sysadmin dies per Kommandozeilen-Option beeinflussen.
Fürs Singlecore-Scheduling hat Linux mit Kernel 2.6.23 ein erweiterbares Framework zur einfachen Implementierung von Scheduling-Algorithmen verpasst bekommen. Dieses Framework führt so genannte Scheduling-Klassen ein, die per implementiertem Algorithmus aus den zugeordneten Jobs den nächsten zu bearbeitenden auswählen. Liefert eine Klasse auf Nachfrage keinen Job, fragt der Scheduler bei der nächsten nach.
Im Standardkernel sind drei Klassen implementiert. Die Klasse »rt_sched_class« ist für Echtzeitprozesse zuständig. Der in dieser Klasse implementierte Algorithmus realisiert ein prioritätengesteuertes Scheduling. Besitzen mehrere Jobs die gleiche Priorität, wird entweder per FCFS (First Come First Served) oder per Zeitscheibenverfahren (Round Robin) ausgewählt. Insgesamt bietet Linux in dieser Klasse 99 Prioritätsebenen.
Normal gestartete Jobs sind der Klasse »fair_sched_class« zugeordnet, die den Completly Fair Scheduler (CFS) realisiert. Dieser Algorithmus sortiert lauffähige Rechenprozesse nicht mehr – wie in den ersten 2.6-Versionen – in Listen, sondern in Red-Black-Trees. Das ermöglicht ihm, mit wenig Rechenaufwand eine faire Verteilung der Rechenzeit vorzunehmen, die nicht mehr auf Heuristiken, sondern allein auf Mathematik beruht.
Im Userland sind dabei weiterhin Nice-Level (Kommando »nice« ) sichtbar, die schon die allerersten Unix-Systeme kannten und eine Priorisierung von Jobs im Bereich von -20 bis +19 ermöglichen. Das Kommando »ps -ce« stellt diese als Linux-Prioritäten von 0 bis 39 dar.
Die Echtzeitprioritäten (1 bis 99) werden bei dieser Ausgabe übrigens als Linux-Prioritäten 41 bis 139 ausgegeben, sodass zur Umrechnung von Linux-Priorität in eine Posix-Realzeitpriorität immer 40 zu subtrahieren ist (Abbildung 2). Die dritte Klasse heißt »idle_sched_class« und tritt nur in Aktion, wenn es keinen anderen lauffähigen Job gibt.
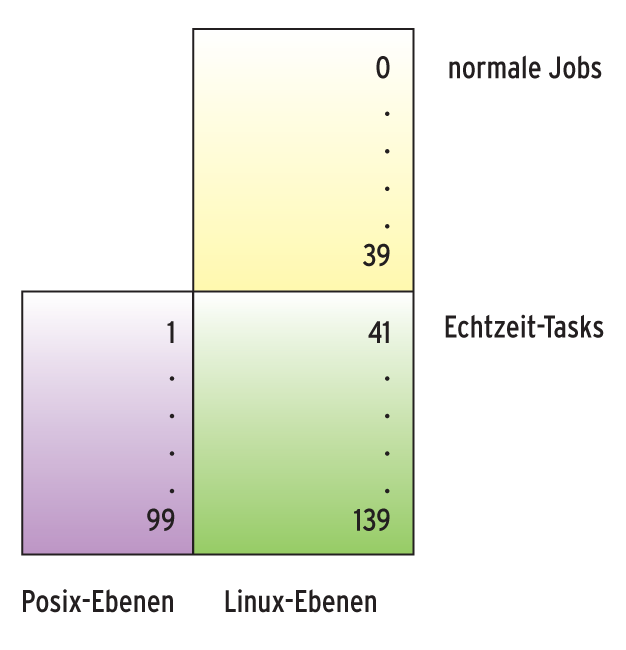
Abbildung 2: Aus logischer Sicht unterstützt Linux 140 Prioritätsebenen, die in einen Bereich für normale Jobs und in einen für Echtzeit-Tasks unterteilt sind. Die Posix-Spezifikation zählt dabei anders.
Bitte nicht stören!
Die Unterbrechbarkeit (Preemption) durch den Scheduler bezieht sich im Linux-Kernel auch auf Funktionen, die im Kernel- oder im Prozesskontext abgearbeitet werden (siehe Kasten “Unterbrechungsmodell”), also Systemcalls oder Kernelthreads. Klassischerweise bringt Linux einmal im Kernel begonnene Funktionen erst bis zum nächsten planmäßig unterbrechbaren Punkt aus, bevor es andere Funktionen auf Kernel- oder Prozessebene in Angriff nimmt. Das gilt auch für den Fall, dass – etwa per Hardware-Interrupt signalisiert – eine sehr wichtige Funktion abzuarbeiten ist.
In einem modernen Linux-Kernel ist das anders: Höher priorisierte Kernelfunktionen unterbrechen niedriger priorisierte. Dadurch reduzieren sich die Latenzzeiten deutlich. Einziger Nachteil: Auf Singlecore-Maschinen gibt es mehr kritische Abschnitte, die das Betriebssystem schützen muss.
Eine sinnvolle Ergänzung zur Kernel-Preemption sind Threaded Interrupts (Abbildung 3). Startet ein Kernel 3.0 mit der Option »threadirqs« , arbeitet das Betriebssystem die zentralen Teile der Interrupt-Serviceroutinen (ISRs) im Kernelkontext ab, also als Kernelthreads. Damit beeinflusst der Admin oder der Systemarchitekt die Priorisierung nicht nur der Interrupts untereinander, sondern sogar in Beziehung zu sonstigen Aufgaben.
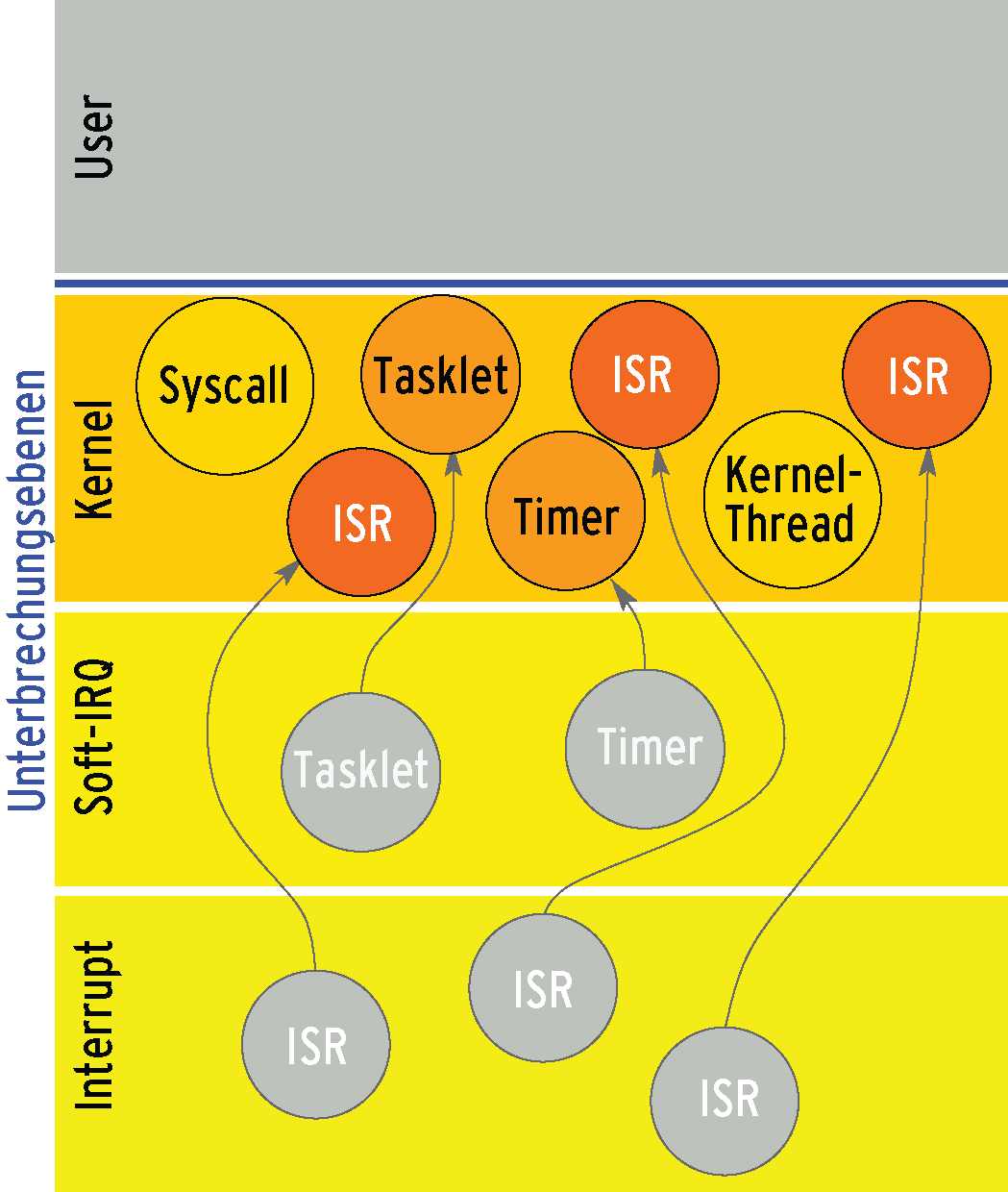
Abbildung 3: Interrupt-Serviceroutinen und Soft-IRQs mutieren zu Threads, was sie unterbrechbar macht: Ein Echtzeitprozess, der auf der Userebene läuft, kann sie verdrängen.
Jiffies
Damit der Scheduler überhaupt aktiv werden kann, sind Interrupts notwendig. Daher erzeugt klassischerweise ein Timer-Baustein periodisch (zum Beispiel alle 10 Millisekunden) einen Interrupt. Die Anzahl der Interrupts zählt Linux in der Variablen »jiffies« mit, sie sind so etwas wie der Herzschlag des Kernels. In Kernel 2.6 hatte Linus Torvalds den zeitlichen Abstand auf 4 Millisekunden reduziert und so das Interaktivitätsverhalten spürbar verbessert. Das geht allerdings zu Lasten der Effizienz, schließlich wird auf diese Art der Kernel häufiger aktiv.
Herz ohne Schlag
Kernel 3.0 ist tickless: Er erzeugt Interrupts nicht mehr periodisch, sondern zu den Zeitpunkten, zu denen sie auch tatsächlich benötigt werden. Die Liste der Vorteile ist beeindruckend: Systemlast reduziert, Effizienz gesteigert, gerade auf mobilen Endgeräten wird durch längere Zeiten der Inaktivität Energie eingespart und die Genauigkeit zeitgesteuerter Aktionen erhöht, da Zeitaufträge nicht mehr zum Zeitpunkt des nächsten periodisch auftretenden Interrupts abgearbeitet werden, sondern punktgenau.
Natürlich gibt es auch Kosten: Mit jedem Interrupt muss der Kernel den nächsten Zeitpunkt berechnen, den Timer-Baustein neu programmieren und die interne Zeitbasis aktualisieren. Jiffies gibt es zwar weiterhin, aber unabhängig davon haben die Linux-Entwickler das Timekeeping mit dem Tickless-System auf Nanosekunden-Genauigkeit umgebaut.
Die zweite wesentliche Komponente des Kernels ist die Speicherverwaltung (Memory-Management). Eine ihrer Aufgaben ist die Adressenumsetzung. Der Kernel sorgt dafür, dass jede Applikation auf einen Hauptspeicher zugreifen kann, der an Adresse 0 startet und dann – je nach Konfiguration – 3 oder 4 oder noch mehr GByte umfasst.
Die Methode, die dabei vor allem zum Einsatz kommt, ist das so genannte Paging. Es teilt den Hauptspeicher in Seiten gleicher Größe (Pages) ein. Typischerweise hat eine Page eine Größe von 4 KByte. Einen 4 GByte großen Hauptspeicher teilt das Betriebssystem somit in eine Millionen Speicherseiten ein. Um eine Millionen Pages zu adressieren, benötigt man 20 Bit; um innerhalb der Page eine Speicherzelle auszusuchen 12 Bit. Auf einem 32-Bit-System (PC-Plattform) ist das normalerweise über eine zweistufige Speicherverwaltung (Two-Level-Paging) realisiert, auf einem 64-Bit-Rechner über eine dreistufige.
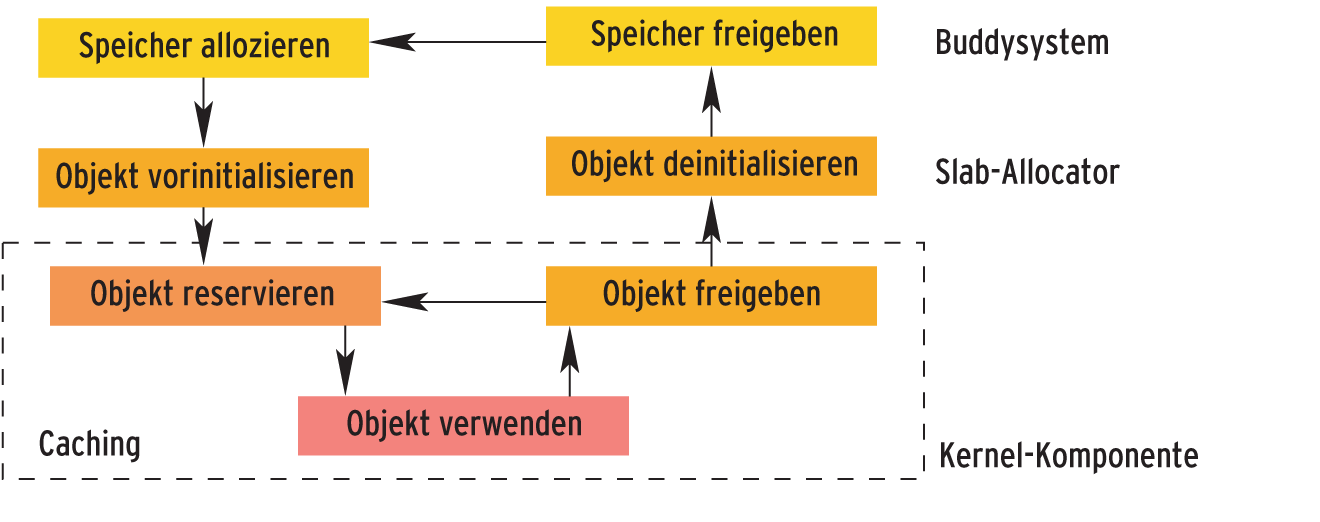
Abbildung 4: Der Lebenszyklus typisierter Kernelobjekte: Indem der Linux-Kernel massiv Objekte wiederverwendet, spart er sich das andauernde Reservieren und Initialisieren von Speicher und steigert so seine Performance.
Aus Sicherheitsgründen variiert Linux die Adressenlagen der einzelnen Segmente einer Applikation (Heap, Stack, Shared Libraries) um jeweils einen zufälligen Wert. Dass Linux bei dieser Adress Space Layout Randomisation (ASLR) genannten Technik stärker variiert als andere Betriebssysteme, ist ein wichtiges Sicherheitsmerkmal.
Speicherschutz
In dieselbe Kerbe schlägt der Speicherschutz, eine weitere Aufgabe des Memory-Managements. Applikationen dürfen nicht auf die Speicherbereiche einer anderen Applikation oder auf die des Kernels zugreifen und mal eben die im Hauptspeicher abgelegten Passwörter auslesen. Zur Realisierung von Speicherschutz benutzt Linux die in Hardware festgelegten Mechanismen.
Das gilt auch für den Schutz vor Ausführung von Code auf dem Stack (Data Execution Prevention, DEP) – ebenfalls eine wesentliche Eigenschaft zum Schutz vor Hackerangriffen. Unglücklicherweise aktivieren die Linux-Distributoren in ihren 32-Bit-Versionen dieses Feature des Kernels meist nicht.
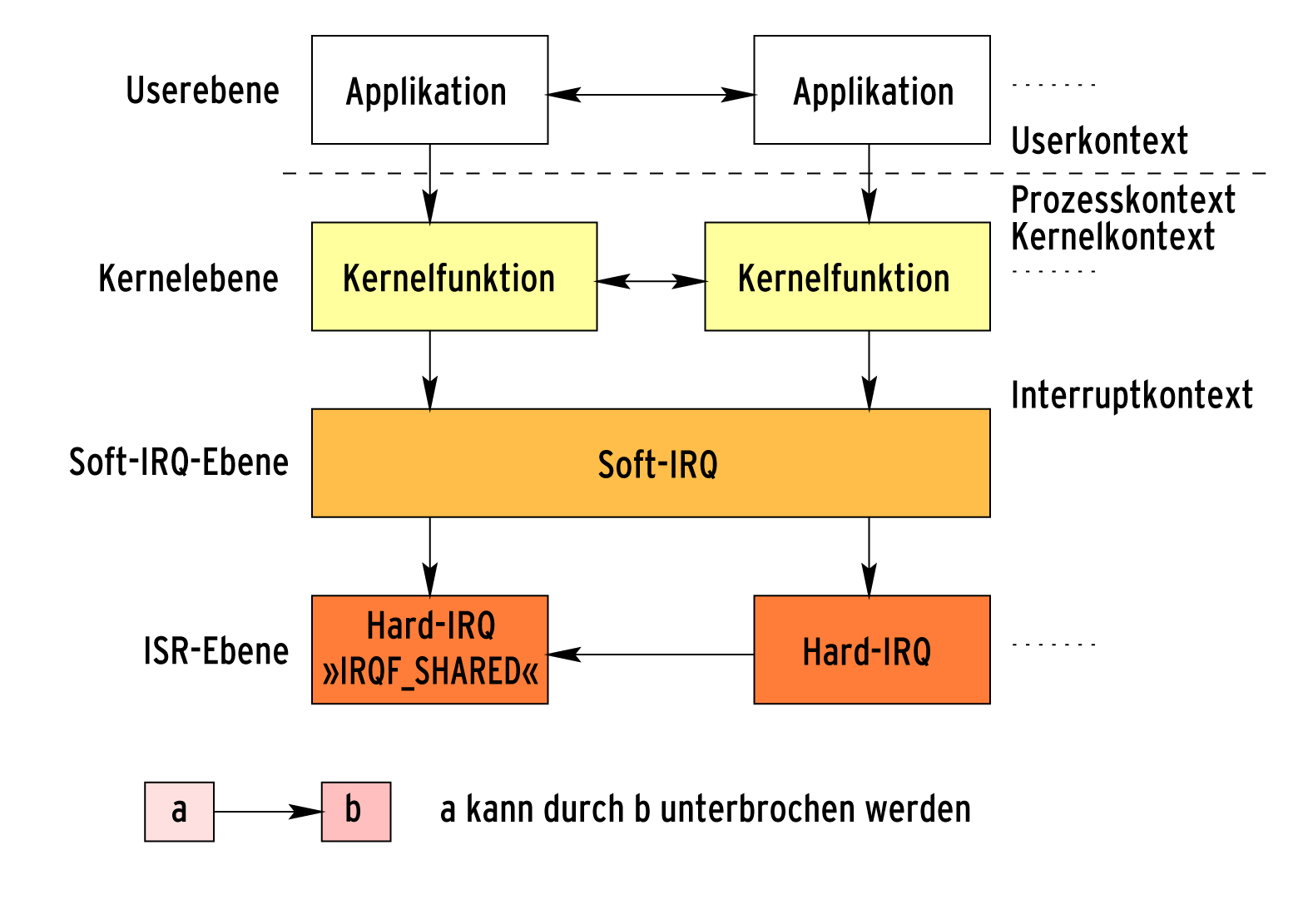
Abbildung 5: Kernel-Programmierer müssen das Unterbrechungsmodell kennen, um kritische Abschnitte erkennen und richtig schützen zu können.
Die Speicherverwaltung hat noch mehr Aufgaben: Dank Swapping macht sich ein Applikationsprogrammierer keine Gedanken über die Menge des physisch zur Verfügung stehenden Hauptspeichers. Und sollten auf einem 32-Bit-System mehr als die adressierbaren 4 GByte zur Verfügung stehen, ist dank Memory Management auch dieser erweiterte Speicher nutzbar.
Unterbrechungsmodell
Linux unterscheidet vier Ebenen, auf denen es Code abarbeitet (Abbildung 5): Die Userebene ist dem so genannten Userland und damit Applikationen vorbehalten. Die hier laufenden Tasks können unterbrochen (preempted) werden und sich schlafen legen. Auf Multicore-Maschinen allerdings können die Funktionen real mehrfach parallel arbeiten.
Auf der Kernelebene sind Systemcalls und Kernelthreads angesiedelt, die ähnliche Eigenschaften haben: Sie sind unterbrechbar, laufen dadurch auf Singlecore-Maschinen scheinbar parallel, auf Multicore-Maschinen real parallel und sie können schlafen.
Wenn Schlafen verboten ist
Auf der Soft-IRQ-Ebene ist Schlafen dagegen ein absolutes Tabu. Hier arbeiten Timer und Tasklets, also kurze Codesequenzen, die eine Unterbrechung durch Interrupts zulassen und früher auch “Bottom Half” genannt wurden. Auf der untersten Ebene schließlich laufen Interrupt-Serviceroutinen (ISRs). Sie können alle darüber liegenden Codesequenzen unterbrechen. Selbst sind sie typischerweise nicht unterbrechbar (Interrupts gesperrt), es sei denn, sie erlauben dies explizit.
Das Unterbrechungsmodell zeigt nicht nur, dass die jeweils niedrigeren Ebenen darüber liegende Ebenen unterbrechen können, sondern auch, in welchem Kontext eine Ebene abgearbeitet wird. ISRs und Soft-IRQs laufen demnach im Interruptkontext.
Auf Kernelebene wird der Prozesskontext vom Kernelkontext unterschieden. Im Prozesskontext laufen all jene Jobs, die zu einer Userland-Applikation gehören. Das sind die Systemcalls, die die Applikationen aufgerufen haben wie etwa »open()« , »close()« , »read()« oder »write()« . Diese Codesequenzen können Daten zwischen dem Kernel und der zugehörigen Applikation austauschen.
Für den Kernelkontext bleiben nur die Kernelthreads übrig. Für jeden Kontext gibt es in den Kernel-Headerdateien ein Define (»GFP_ATOMIC« für den Interruptkontext, »GFP_KERNEL« für den Kernelkontext und »GFP_USER« für den Prozesskontext). Allgemeine Funktionen, beispielsweise »kmalloc()« (»malloc()« im Kernel), lassen sich aus unterschiedlichen Kontexten aufrufen. Ihnen muss der Kernelprogrammierer über das Define den aktuellen Kontext mitgeben, etwa damit die Funktion weiß, ob sie schlafen darf oder nicht.
Darüber hinaus setzt Linux auf typisierte Objekte und nutzt mit dem Slab-Allocator die Vorteile der Wiederverwertung [3]. Hierbei stellt der Kernel eine Reihe bereits vorinitialisierter Objekte zur Verfügung. Das hat vor allem Performance-Vorteile: Das gleichzeitige Initialisieren mehrerer gleichartiger Objekte nutzt den Hauptspeicher und die Wirkung des Prozessor-Cache besser aus.
Zudem fällt Code weg, weil sich die Operationen “Speicher allozieren”, “Objekt vorinitialisieren”, “Objekt deinitialisieren” und “Speicher freigeben” einsparen lassen (Abbildung 4). Der Sysadmin bekommt Informationen zu den Objekten, indem er das Kommando »cat /proc/slabinfo« aufruft.
Virtual Filesystem Switch
Das I/O-Management ist für den Zugriff auf Dateien und auf Peripherie zuständig. Zentrale Verteilstation ist hierfür der Virtual Filesystem Switch (VFS). Dieser verteilt die Zugriffe auf zeichen- oder blockorientierte Geräte, setzt Dateinamen auf Sektornummern um, speichert die Daten zwischen und gibt Aufträge für die Festplatten an den I/O-Scheduler weiter. Der I/O-Scheduler ist für eine geschickte Sortierung zuständig, sodass der Lesekopf einer Festplatte möglichst wenige Rückwärtsbewegungen macht. Da Solid State Disks (Flashspeicher) keine Köpfe zu bewegen haben, reicht Linux in diesem Szenario bei entsprechender Konfiguration die Daten direkt an die Platte weiter.
Der VFS implementiert auch das hierarchische Modell, gemäß dem Linux Daten auf Festplatten abspeichert oder wieder einliest. Jede Datei ist in diesem Modell über einen Inode repräsentiert [4]. Der Inode, der über eine eindeutige Inodenummer bestimmt ist, speichert die wesentlichen Meta-Informationen: Dateigröße, Zeitstempel bezüglich des Anlegens, des letzten Zugriffs oder der letzten Modifikation, Zugriffsrechte, Besitzverhältnisse und so weiter. Ein einzelner Name gehört allerdings nicht zu diesen Meta-Informationen. Inodenummern lassen sich im Übrigen durch Eingabe von »ls -i« in einer Konsole listen.
Ein Dentry genanntes Objekt verknüpft schließlich einen Dateinamen mit dem Inode. Um per Namen auf eine Datei zugreifen zu können, sind zunächst die Dentries zu durchsuchen. Diesen zeitlich teuren Vorgang beschleunigt Linux durch einen Zwischenspeicher, den Dcache.
Mit dem Inode-Objekt ist eine Reihe von Methoden verknüpft, die – verkürzt ausgedrückt – die Abbildung auf die Festplatte und die dort vorhandenen Datenstrukturen, das eigentlichen Dateisystem, vornehmen.
Dateisysteme
Aktuell verwenden die meisten Distributionen ein Ext-4-Dateisystem, das nicht nur performant arbeitet, sondern auch besonders große Dateien ermöglicht. Mittelfristig wird aber wohl Btrfs die Rolle des Standardfilesystems übernehmen. Dann sollen auch Filesystemchecks bei einem gemounteten und in Verwendung befindlichen Dateisystem möglich sein. Die universelle Dateisystemschnittstelle ermöglicht es Linux, auf unterschiedlichste Dateisysteme zuzugreifen, wie etwa FAT, NTFS oder ISO9660.
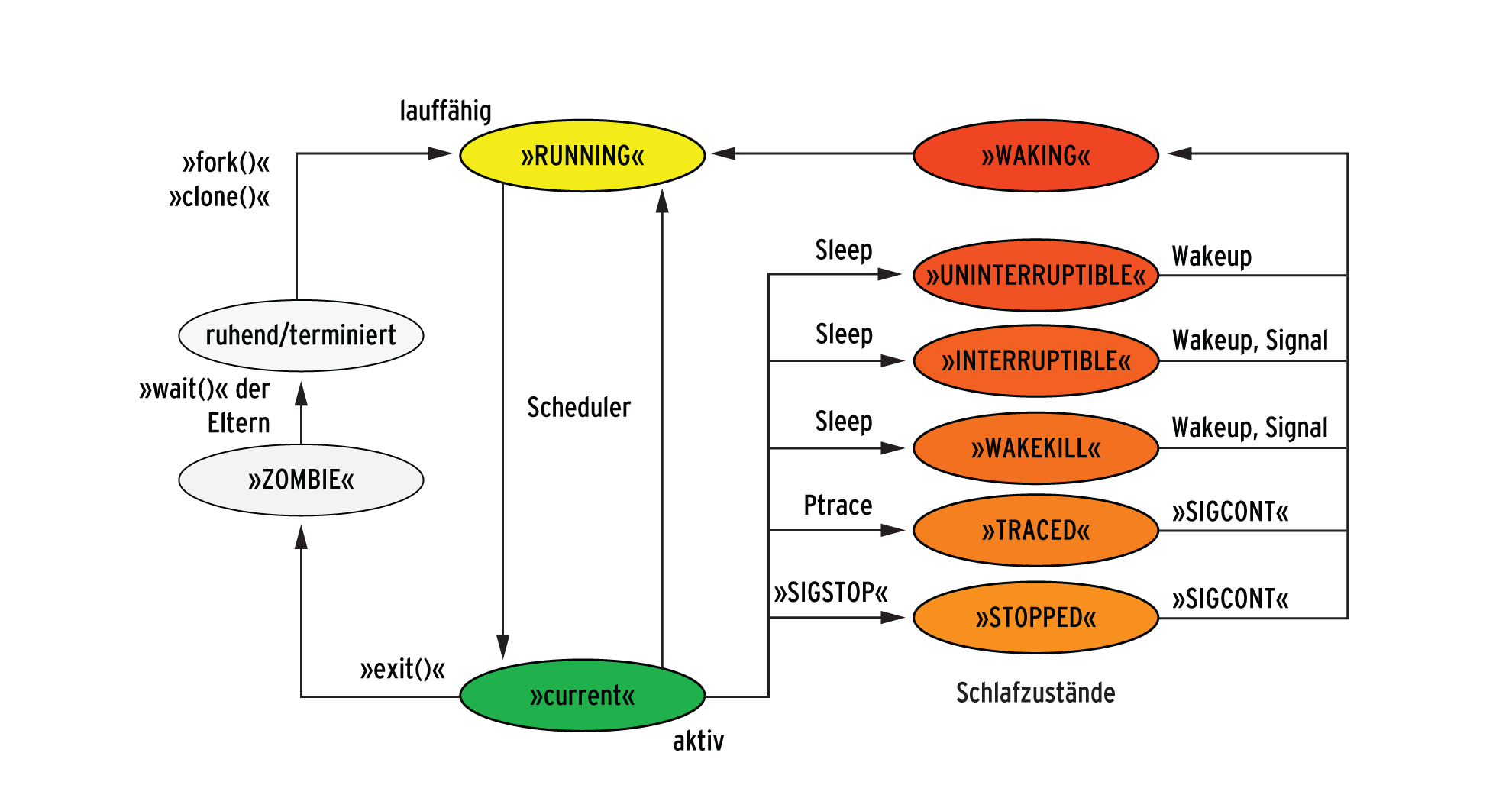
Abbildung 6: Applikationen und Kernelthreads durchlaufen verschiedene Zustände.
Taskzustände
Tasks können sich in unterschiedlichen Zuständen befinden. Grundsätzlich erzeugt der Systemcall »clone()« eine neue Task als exakte Kopie ihres Elternprozesses. Der neue Job befindet sich im lauffähigen Zustand (»TASK_RUNNING« ). Der Scheduler wählt aus allen lauffähigen Jobs jenen aus, den die CPU als nächsten abarbeitet. Der so genannte Context-Switch aktiviert die Task, die sich damit im aktiven Zustand befindet. Es gibt diverse Gründe, warum sich eine Task selbst in den schlafenden Zustand versetzt: Sie wartet auf Daten, sie wartet auf ein Betriebsmittel oder will einfach nur Zeit verstreichen lassen.
Linux unterscheidet verschiedene Arten des Schlafens. In der einfachsten Variante schläft der Job exakt so lange, bis das Ende der Schlafensbedingung erreicht ist und niemand im Kernel die »wake_up« -Funktion aufruft. In diesem Zustand weckt den Job nichts anderes. Nicht gar so tief schläft der Job im Killable-Zustand. Hier kann ihn immerhin das Signal 9 (»SIGKILL« ) aufwecken. Den leichten Schlaf repräsentiert der Interruptible-Zustand. Hier wird der Job durch jedes Signal geweckt.
Selbstmord im Kernel
In Abbildung 6 ist gut zu erkennen, dass Jobs sich grundsätzlich selbst beenden. Die Aufforderung zum “Selbstmord” kann jedoch per Signal von anderen Jobs aus (per Systemcall »kill« ) erfolgen. Bevor aber sämtliche Spuren des Jobs erloschen sind, nimmt er noch den Zombie-Status an.
In diesem Zustand hat der Kernel zwar bereits die zum Prozess gehörenden Speicherbereiche (Code-, Daten- und Stacksegmente) freigegeben, der Task-Kontrollblock aber, die Datenstruktur, die den Job im Kernel repräsentiert, existiert noch. Bevor diese gelöscht wird, muss die Elterntask den Exitcode (Returnwert der Funktion »main« ) abholen. Ist die Elterntask bereits selbst beendet, übernimmt der Job mit der PID 1 (der Init-Prozess) dieses Abholen.
Außerdem lassen sich Daten auch in virtuellen Dateisystemen ablegen: Aus Sicht der Applikation gibt es Dateien, die real nur im Hauptspeicher und nicht auf der Festplatte zu finden sind. Mehr noch, die Daten entstehen erst beim Zugriff.
Drei virtuelle Dateisysteme kennen die meisten Admins: Das Proc-Filesystem enthält Informationen über sämtliche Rechenprozesse, das Sys-Filesystem über die Hardwarestruktur inklusive der zugehörigen Treiber. Das Temp-Filesystem schließlich ermöglicht die Ablage von Daten im Hauptspeicher, ohne dass überhaupt ein klassisches Dateisystem zum Zuge kommt. Das nutzt Linux, um per Initram-FS quasi ohne Treiber zu booten [5]. Außerdem ermöglicht ein VFS auch das Schichten von Dateisystemen, um damit beispielsweise einfach eine Verschlüsselung zu realisieren.
In enger Verbindung zum VFS stehen die Gerätetreiber, die den weitaus größten Teil des Linux-Quellcode stellen. Historisch wird ein Treiber über eine Major-Nummer identifiziert, die 8 Bit breit ist. Die sich daraus ergebende Anzahl von gerade einmal 256 Treibern ist für ein modernes Betriebssystem jedoch viel zu wenig. Linux arbeitet daher mit Gerätenummern, die insgesamt 32 Bit breit sind. Mit einer Kodierung von rund 4000 Treibern mit insgesamt 4 Milliarden anzusprechenden Geräten ist das ausreichend dimensioniert.
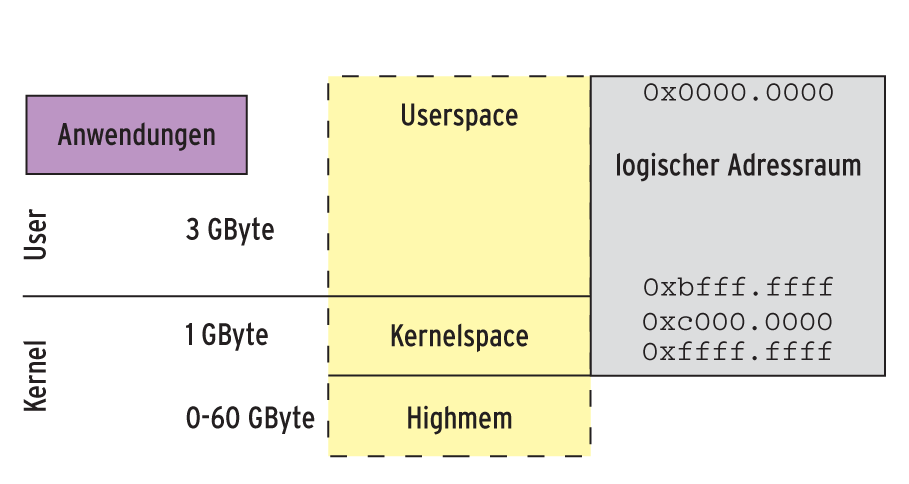
Abbildung 7: Da alle Page-Directories in den höchsten Adressen die gleichen Einträge aufweisen, ist beim Übergang in den Kernel kein Umschalten der Speicherbereiche notwendig.
Den größten Sprung von 2.6.0 zu 3.0 hat der Linux-Kernel im Bereich Echtzeitverhalten gemacht. Nicht zuletzt dank des deutschen Kernelentwicklers Thomas Gleixner, der seine Realtime-Patches in “schmackhafte, Trojanische Pferde” verpackt hat [6], stehen dem Architekten eines Echtzeitsystems mit Linux viele Möglichkeiten offen: Hochauflösende Timer (Hrtimer) erlauben sehr genaue Zeitsteuerungen, Realtime-Mutexe bieten Prioritätsvererbung und die bisher nicht erwähnten CPU-Sets fixieren Rechenprozesse exklusiv auf spezifischen Rechnerkernen eines Multicoresystems.
4G/4G-Patch
Auf einem 32-Bit-System sind Adressenregister 32 Bit breit und geben damit Zugriff auf 4 GByte virtuellen Hauptspeicher. Der Versuch einer Applikation, diesen Adressraum komplett zu nutzen und auf eine Adresse oberhalb von 3 GByte zuzugreifen, scheitert jedoch kläglich mit einem Segmentation Fault. Im Adressraum der Applikation haben die Kernelentwickler das oberste Gigabyte für den Kernel reserviert. Konkret: In dem Page-Directory einer jeden Task stehen in den höchsten Adressen exakt die gleichen Einträge, während die übrigen Einträge Task-spezifisch sind (Abbildung 7).
Dadurch kann der Kernel mit dem Page-Directory jeder gerade aktiven Task auf seine dort referenzierten Speicherbereiche – den Kernelspace – zugreifen. Ohne diesen Trick müsste Linux bei jedem Systemcall und bei jedem Interrupt das Page-Directory, also den Einsprung in die Speicherverwaltung, austauschen. Dazu gehörte dann auch das Leeren des Translation Lookaside Buffer (TLB), des Cache für die Speicherverwaltung. Das ist zeitlich betrachtet ein teurer Vorgang.
Sollte eine speicherhungrige Task doch den Bedarf nach 4 GByte virtuellem Speicher haben, kann der Admin das 4G/4G-Patch aktivieren, das dem Kernel ein eigenes Page-Directory zuweist. In einem solchen Fall sollte er allerdings vorzugsweise den Umstieg auf ein 64-Bit-System erwägen.
Hinzu kommen die erwähnten Techniken Threaded Interrupts, Kernel-Preemption und Tickless Kernel. Das unter Entwicklern berüchtigte Big Kernel Lock (BKL), das in den alten Versionen mal eben Interrupts auf sämtlichen Prozessoren gesperrt hat, ist ebenfalls rechtzeitig vor der Veröffentlichung von 3.0 aus dem Kernel verschwunden.
Code zum Anfassen
Der Linux-Kernel 3.0 präsentiert sich aus vielen Gründen als spannendes Stück produktiver Software. Nicht nur, weil er objektorientiert aufgebaut ist, ohne eine objektorientierte Programmiersprache zu verwenden, und weil er eine ungewöhnliche Skalierbarkeit und Portierbarkeit aufweist oder weil er die Ideen und die Programmierfähigkeiten unterschiedlichster, weltweit verstreuter Entwickler vereint, sondern auch, weil er dank seiner Open-Source-Lizenz ein Stück Hightech zum Anfassen ist.
Infos
- Linus Torvalds, “Linux 3.0-rc1”: http://thread.gmane.org/gmane.linux.kernel/1147415
- Quade, Kunst, “Kern-Technik”, Folge 33 (Multicore): Linux-Magazin 05/07, S. 52
- Quade, Kunst, “Linux-Treiber entwickeln”, 3. Auflage: Dpunkt-Verlag, 2011, S 232 ff.
- Quade, Kunst, “Kern-Technik”, Folge 23 (VFS): Linux-Magazin 10/05, S. 90
- Quade, Kunst, “Kern-Technik”, Folge 39 (Tempfs): Linux-Magazin 05/08, S. 98
- Thomas Gleixner, “Forced threaded interrupt handlers”: https://lkml.org/lkml/2011/2/23/510





