
Per Definition gibt es Supercomputer schon seit der Erfindung des Computers. Die ersten elektronischen Rechner waren nämlich allesamt Supercomputer, weil sie die zu ihrer Zeit höchstmögliche Rechenleistung bereitstellten.
Mit der Einführung von Homecomputern oder PCs, also der Vermarktung kleiner, privat nutzbarer Computer, kamen später Alternativen auf – daher brauchte man einen extra Begriff für die großen Kisten. Deshalb heißen seit Ende der 70er Jahre, der Zeit der Cray 1, Systeme mit der aktuell höchsten verfügbaren Rechenleistung Supercomputer.
Von Anfang an waren diese Supercomputer Parallelrechner. Die ersten basierten auf Hardware, die speziell für Hochleistungsrechner entwickelt worden war. Dazu gehören seit den 70er Jahren auch die Mainframes, die Banken und Versicherungen heute noch gerne einsetzen. Diese Computer sind vor allem auf Ausfallsicherheit und Durchsatz optimiert.
Der nächste Schritt in der Evolution war die Erfindung des Cluster-Konzepts. Frühe Parallelrechner waren zumeist als SMP (Symmetric Multiprocessor) mit einem gemeinsamen Speicher ausgelegt.
Verteilter Speicher
Bei einer höheren Zahl von Prozessoren führte dieser Aufbau jedoch sehr schnell zu technischen Schwierigkeiten, die als Konsequenz eine verteilte Anordnung der Hardware erzwangen. Einen (zumindest virtuellen) zentralen Speicher für sehr viele Prozessoren in einem verteilten System zu realisieren ist schwierig und erhöht die Komplexität der Hardware. Das Konzept ist zudem sehr fehleranfällig und limitiert die maximale Größe eines solchen Systems. Ein Cluster hingegen hat keinen zentralen Speicher, sondern lässt ausschließlich eine Nachrichtenkommunikation zwischen seinen Einzelrechnern, den Knoten, zu. Zum Cluster wird eine Gruppe von Computern dank spezieller Tools, die unter Linux alle frei zur Verfügung stehen.
Fast alle heute gebauten und betriebenen Supercomputer sind Cluster. Bestehen sie aus Standardkomponenten, nennt man sie Commodity-Cluster – die anderen Supercomputer enthalten speziell entwickelte Komponenten. So verfügen beispielsweise die weitverbreiteten Blue-Gene-Supercomputer über ein eigens für diesen Typ Computer entwickeltes Verbindungsnetzwerk.
Cluster-Aufbau
Das Cluster-Konzept führte ursprünglich die Firma Datapoint ein. Kommerzielle Erfolge damit feierte Anfang der 80er Jahre zuerst DEC mit dem VAX-Cluster. Linux als Betriebssystem hat mit Erfindung der Beowulf-Cluster (Abbildung 1) entscheidend zur Kostensenkung bei Supercomputern beigetragen: Heute kann sich jede Uni einen Cluster leisten.
Die Grundidee von Beowulf ist es, für den Bau eines Großrechners weder spezielle Hardware noch teure proprietäre Software einzusetzen. Vielmehr sollen Standardkomponenten zum Einsatz kommen, wie sie auch in normalen PCs verbaut sind. Die Basis eines solchen Clusters ist ein zentraler Server, der Dienste wie DHCP oder das Netzwerk-Dateisystem zur Verfügung stellt, aber auch als Login-Frontend dient. Hier müssen sich alle Nutzer zentral einloggen, alle anderen Rechner des Systems sind nur von hier aus zu erreichen.
Die wichtigste Komponente eines Clusters sind die so genannten Rechenknoten, sie verrichten die eigentliche Arbeit. Sie sollten möglichst zahlreich vorhanden und zugleich nur mit dem Nötigsten ausgestattet sein. Rechenknoten brauchen zwar keine identische Hardware, aber die installierte Software muss überall gleich sein. Bei größeren Clustern ist es zudem förderlich, wenn auch die Hardware der Rechenknoten identisch ist.
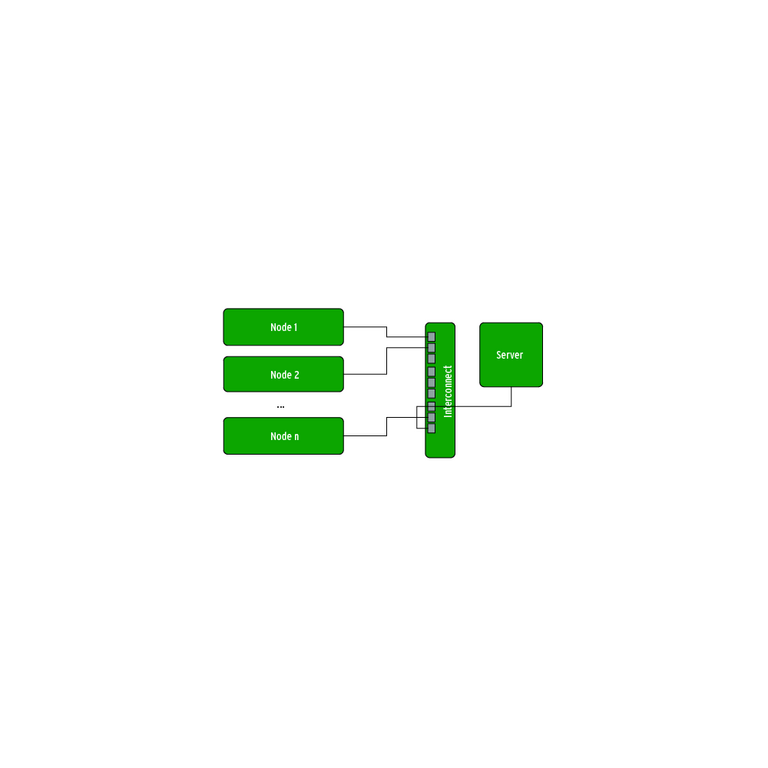
Abbildung 1: Der Aufbau eines reinen Beowulf-Clusters ist simpel. Es gibt einen Server und mehrere Rechenknoten, die durch ein Netzwerk verbunden sind.
Interconnect verbindet
Zuletzt muss der Cluster-Betreiber alle verteilten Komponenten verbinden, was über ein System geschieht, das im Fachjargon als Interconnect bezeichnet wird. Im einfachsten Fall nimmt man dafür das herkömmliche Ethernet, was die ersten Beowulf-Cluster auch so realisierten. Während Ethernet eine Datenrate bis zu 10 GBit/s erreichen kann, sieht es mit den Latenzen, also mit der Zeit, die ein Datenpaket benötigt, um gesendet zu werden, bei solchen Netzwerken erheblich schlechter aus.
Dies liegt vor allem daran, dass das Datenpaket zunächst die vielen Ebenen des TCP/IP-Stack durchwandern muss, bis die Kommunikation gelingt. Deswegen existieren heutzutage spezielle Interconnects wie zum Beispiel Infiniband oder Myrinet, die für Latenz-kritische Anwendungen konzipiert und als Standardkomponenten zu erwerben sind.
Moderne Cluster-Systeme erweitern das ursprüngliche Konzept von Beowulf (siehe Abbildung 2) oft. Neben den reinen Rechenknoten gibt es dann noch Login-Knoten, die auch zum Übersetzen der Programme dienen können, die der Cluster ausführt. Aus diesem Grund haben größere Systeme mit vielen Nutzern auch mehrere Login-Knoten. Die Serverdienste verteilen sich mit steigender Anzahl der Rechenknoten auf mehrere physische Maschinen.
Dann ist auch ein eigenständiger Server für die Überwachung des Clusters nötig. Der speichert zentral alle anfallenden Logs, überwacht mit einem Heartbeat-Dienst regelmäßig, ob alle Knoten noch auf Anfragen über das Netzwerk antworten, und bietet eine spezielle Monitor-Software, die dem Administrator Auskünfte über die momentane Auslastung des Systems liefert. Das Monitoring der Knoten ist deshalb so wichtig, weil ein einziger ausgefallener Knoten ein auf dem Cluster ausgeführtes Programm mit in den Tod reißen kann.
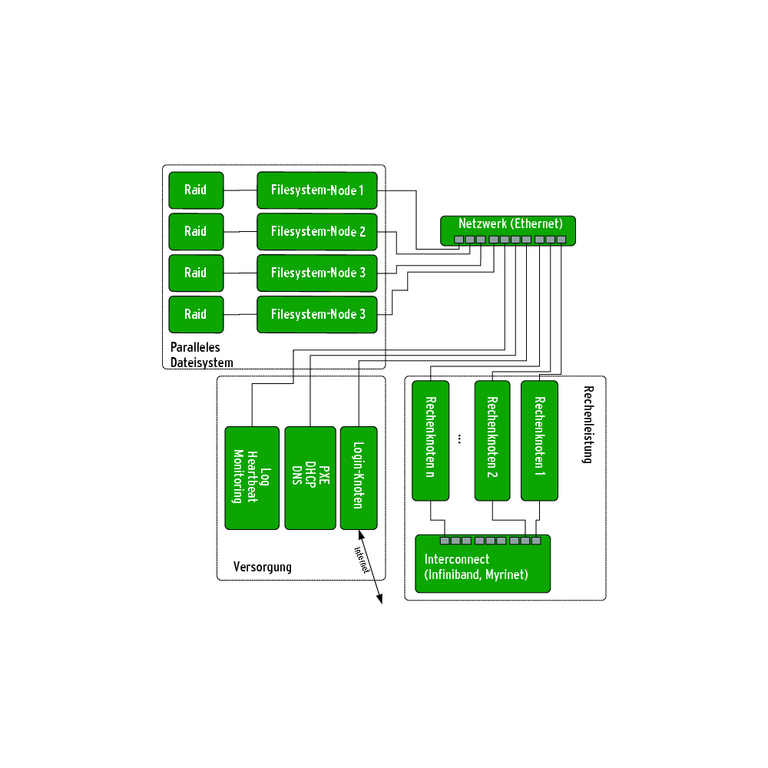
Abbildung 2: Heutige Cluster sind komplexer aufgebaut als ein reiner Beowulf-Verbund. Die Rechenknoten sind mit einem schnellen Interconnect verbunden, spezielle Filesystem-Nodes stellen das verteilte Dateisystem bereit. Die Serverdienste erstrecken sich auf mehrere Maschinen.
Booten via Netz
Ein PXE-Server-Netzboot, der gleichzeitig DHCP und DNS zu Verfügung stellt, befreit die Rechenknoten von ihren Festplatten, was die Ausfallsicherheit erhöht. Eine Festplatte in jedem Rechenknoten ist sowieso nicht nötig, weil meist die Nutzdaten ohnehin auf einem parallelen Dateisystem liegen.
Dieses System stellt einer weiteren Gruppe von Servern die Dateisystem-Knoten zur Verfügung. Sie bilden quasi einen weiteren Cluster im Cluster, um den hohen Anforderungen zu entsprechen, die durch den parallelen Dateizugriff entstehen. Das bedeutet zugleich, dass die Systemsoftware für solche Cluster-Dateisysteme selbst aus parallelen Programmen besteht. Um eine hohe Datenrate bei einer gewissen Ausfallsicherheit zu erzielen, müssen die Daten im Hintergrund auf Raid-Systemen gespeichert sein.
Linux als Hochleistungs-Betriebssystem
Profis oder auch interessierte Anwender erfahren zweimal jährlich durch die Top-500-Liste, welches die aktuell schnellsten Rechner der Welt sind. Dabei fällt sofort auf, dass die meisten dieser Systeme unter Linux laufen. Hierbei spielen vor allem Suse Linux Enterprise (SLES) und Red Hat Enterprise Linux (RHEL) eine große Rolle. Ersteres, weil es standardmäßig auf der Blue-Gene-Serie von IBM zum Einsatz kommt, das zweite, weil es im amerikanischen Raum sehr beliebt ist und weil zudem mit Cent OS eine preisgünstige und außerdem binärkompatible Variante existiert.
Auf den ersten Blick erscheint es vielleicht konservativ, auf eine solche kostenpflichtige Enterprise-Variante zurückzugreifen. Aber die Anschaffung eines größeren Clusters verschlingt normalerweise Millionen und ein Ausfall verursacht erhebliche Kosten. Die Hersteller gehen davon aus, dass die Enterprise-Versionen besonders getestet wurden und damit sicherer sind.
Für kleinere bis mittelgroße Cluster-Projekte existieren noch weitere Distributionen. Um unverbindliche Ausflüge in die Welt des Hochleistungsrechnens zu unternehmen, eignen sich besonders spezielle Live-Distributionen, die Allzweckcomputer zu einem Cluster zusammenschließen. Frühe Pionierarbeit haben auf diesem Gebiet Distributionen wie Cluster- und Parallel-Knoppix geleistet. Beide Projekte werden aber zurzeit nicht weiterentwickelt, mit Pelican HPC existiert jedoch ein aktiv gepflegter Nachfolger von Parallel-Knoppix.
Cluster-Distributionen
Es gibt darüber hinaus auch spezielle Cluster-Distributionen, die traditionell auf den Festplatten der Knoten laufen. Eine freie Variante ist hierbei Rocks, das auf Cent OS (einem RHEL-Klon) basiert und die nötige Software für Parallelrechner mitbringt. Außerdem lässt sich diese Distribution dank eines speziellen Installers auf viele Knoten gleichzeitig aufspielen (siehe Tabelle 1).
Neben den kommerziellen und spezialisierten Distributionen eignet sich aber auch fast jede Distribution, um einen Cluster zu betreiben. Oft reicht es, wenn der Admin unter geläufigen Distributionen, zum Beispiel Open Suse, Debian oder vielleicht sogar Gentoo, zusätzliche Repositories einbindet, die spezielle Software enthalten.
| Tabelle 1: Alle Cluster-Distributionen |
||
|---|---|---|
| Name | Typ | URL |
| SLES | Installiert | [http://www.novell.com/de-de/linux] |
| RHEL | Installiert | [http://www.de.redhat.com/rhel] |
| Rocks | Installiert | [http://www.rocksclusters.org] |
| Pelican HPC | Live | [http://idea.uab.es/mcreel/ParallelKnoppix] |
| BCCD | Live | [http://bccd.net] |
| ABC Linux | Live/Netboot | [http://www.ehu.es/AC/ABC.htm] |
Installation
Der Punkt Installation ist beim Betrieb eines Clusters eine nicht zu unterschätzende Aufgabe, denn während das Aufspielen der Systemsoftware auf einen einzigen Rechner noch gut manuell erledigt werden kann, würde dieser Vorgang bei mehreren Hundert Knoten Monate dauern. Außerdem ist sehr wichtig, dass die Software auf allen Rechenknoten exakt denselben Stand hat.
Eine wirklich einfache Variante, um dieses Problem zu lösen, ist der Einsatz von Netboot-Servern, bei denen die gesamte Systemsoftware direkt aus dem Netz bootet. Dies kann ein PXE-Server leisten, Alternativen sind zum Beispiel Open Bootrom oder EFI. Für sehr große Installationen ist diese Betriebsart besonders vorteilhaft, weil die Knoten auf Festplatten verzichten können. Damit ist eine potenzielle Fehlerquelle beseitigt und Strom spart es außerdem. Aber auch bei kleineren Installationen lassen sich mit einem solchen Setup die Wartungskosten minimieren und Rechner, die tagsüber als normale Arbeitsrechner dienen, nachts in einen Cluster verwandeln.
Sollte die Systemsoftware der Knoten nicht auf eine Ramdisk passen oder sprechen andere technische Gründe gegen ein Setup ohne Festplatten, muss der Admin Linux verteilt installieren. Ein technischer Grund kann beispielsweise sein, dass eine Anwendung, die auf dem Cluster später laufen soll, einen großen lokalen Festplattenspeicher voraussetzt. Eine solche lokale Installation bewältigen netzwerkfähige Installer wie FAI (Fully Automic Installation, [1]) sehr gut. FAI wurde entwickelt, um automatische Debian-Installationen vornehmen zu können, ist aber auch in der Lage, andere (auf Debian basierende) Distributionen verteilt zu installieren.
Auf RPM aufsetzende Distributionen bringen meist ihren eigenen netzwerkfähigen Installer mit. So lassen sich auf Red Hat basierende Distribution mit Kickstart und Suse-Distributionen mit Yast installieren. Bei all diesen Varianten kann übrigens der Installationsserver schnell zum Engpass werden, wenn die Knotenzahl hoch ist.
Eine weitere und sehr elegante Variante der lokalen Installation eines Clusters ist die Installation mit Hilfe einer Image-Software. Sie installiert nicht per Installer auf jeden Knoten einzeln, sondern repliziert eine bestehende Installation von einem auf alle anderen Knoten. Dieses Vorgehen hat eine ganze Reihe von Vorteilen:
- Die Software muss nicht unbedingt mit der Paketverwaltung der
jeweiligen Distribution installiert sein, was dem Administrator das
Packen entsprechender Pakete erspart. - Es lässt sich neben dem Hauptcluster ein kleiner
Testcluster betreiben, dessen Installation man nach ausgiebigen
Tests einfach repliziert. - Die Systeme sind wirklich hundertprozentig gleich.
Eine einfache Image-Software ist zum Beispiel Partimage [2]. Es beherrscht das Sichern und Wiederherstellen von Partitionen unterschiedlichen Typs. Eine erheblich ausgereiftere Variante ist der Systemimager [3], der neben dem reinen Installieren auch die erzeugte Installation zu konfigurieren vermag. Zudem kann Systemimager seine Daten aus einem lokalen Bit-Torrent-Netzwerk beziehen, was den Engpass einer Server-gestützten Installation beseitigt.
Administration
Ist der Cluster installiert, stellt sich die Frage nach der Verwaltung. SSH ist hier das am meisten verwendete Werkzeug, um Teile des Clusters remote zu verwalten. Terminalprogramme wie VNC spielen keine Rolle, weil sie schlecht zu skripten sind. Ein einziger Server ist damit zwar sehr gut und komfortabel grafisch zu verwalten, um bei 100 Knoten simultan die gleiche Änderung vorzunehmen, bedarf es aber der Automatisierung. Nicht selten greifen Admins hier auf Projekte wie Parallel SSH zurück [4].
Ein weiterer wichtiger Punkt bei der Administration ist die komplette Hardware-Überwachung, um einen bevorstehenden Ausfall zu erkennen. Lüfter und Temperatur lassen sich per LM-Sensors [5] auslesen. Mit ein wenig Skripting ist es sogar möglich, eine Heatmap des Clusters zu erstellen und so Wärmenester ausfindig zu machen.
Die Smartmontools [6] erledigen ähnliche Aufgaben für Festplatten, wobei darauf zu achten ist, dass die Festplatten innerhalb der spezifizierten Temperaturgrenzen arbeiten. Auch eine zu geringe Betriebstemperatur kann zum vorzeitigen Ableben führen.
Um einen Überblick über die auf dem Cluster laufenden Programme zu erhalten, taugt ein herkömmliches Top nicht. Hier hilft verteile Monitoringsoftware weiter. Ganglia [7] ist so ein verteiltes Monitoringsystem für Hochleistungsrechner (Abbildung 3).
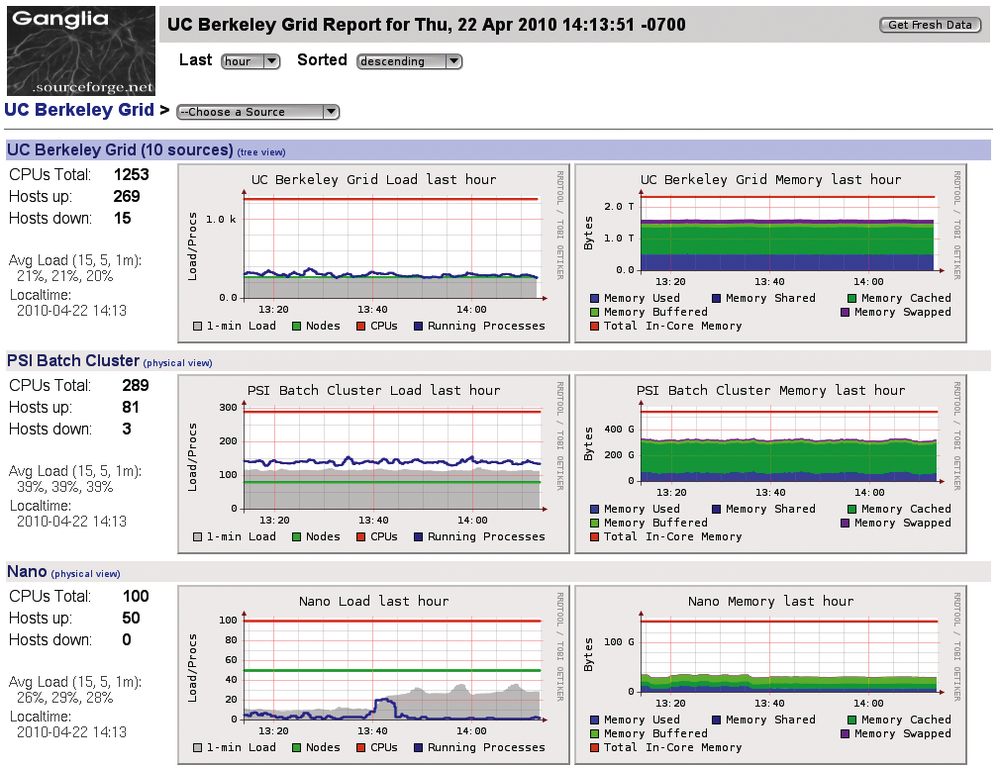
Abbildung 3: Ganglia liefert schnell einen Überblick über das Geschehen auf dem Cluster.
Parallele Dateisysteme
Für die verteilte und ausfallsichere Speicherung der Daten ist ein Netzwerk-Dateisystem nötig. Es ist leicht auf einem Raid zu installieren, was vor den Folgen von Plattenausfällen schützt. Ein solches paralleles Filesystem muss besonderen Ansprüchen genügen, denn in einem Cluster greifen im Ernstfall alle Knoten zugleich auf das Dateisystem zu.
Glücklicherweise ist Linux bereits mit Bordmitteln sehr gut für solche Anwendungszenarien gerüstet. Das in den Kernel integrierte Software-Raid-Subsystem [8] beherrscht die meisten Raid-Modi und steht auch bei der Leistung den meisten Hardwarelösungen wenig nach. Zudem lässt sich der im Pool verfügbare Speicher mit LVM2 [9] sogar dynamisch verwalten. Mit diesen beiden Werkzeugen lassen sich auf sehr preiswerte Art und Weise die Dateisystem-Knoten implementieren, die eine Grundlage für den Storage-Cluster liefern.
Die Auswahl an parallelen Dateisystemen unter Linux ist groß, denn es sind viele bereits in den Kernel integriert. Das bekannteste sollte wohl CIFS sein, das seit geraumer Zeit Cluster-fähig ist. Das von Red Hat freigegebene GFS2 (Global File System 2, [10]) ist ebenfalls direkt im Kernel enthalten und zudem bereits von Anfang an für den Einsatz in einem Cluster konzipiert.
Neben GFS2 gibt es noch OCFS2 (Oracle File System 2, [10]), das auch schon in aktuellen Linux-Kerneln integriert ist. Die beiden zuletzt genannten Dateisysteme waren vor ihrer Freigabe übrigens proprietär und teuer. Ein wirklich heißer Kandidat für ein besonders performantes und freies Cluster-Dateisystem ist das ab Kernelversion 2.6.34 enthaltene CEPH [11], das eine Forschungsgruppe programmiert hat.
Jobkontrolle
Wenn alle Knoten installiert, gebootet und überwacht sind, stellt sich die Frage, wer welche Programme auf dem Cluster ausführt und wie die Anfragen verschiedener Nutzer zu koordinieren sind. Die Software, die ein paralleles Programm auf einem Cluster startet, wird als Batchsystem oder Jobkontrolle bezeichnet. Solche Systeme [1] werden in zwei Kategorien eingeteilt: die Queue- und die Plan-basierten Systeme.
Der Fachjargon bezeichnet den Ausführungslauf eines Programms auf einem Cluster als Job. Der User muss dem Batchsystem mitteilen, wie viele Knoten er benötigt und ob es sich um einen Batch- oder einen interaktiven Job handelt. Liegt ein Batch-Job vor, braucht das System normalerweise noch ein Skript, das das Programm startet.
Queue-basierte Systeme sind die am weitesten verbreitete Art der Jobkontrolle auf Clustern. Anfragen für die Bereitstellung der gewünschten Ressourcen reihen sich hier in eine Warteschlange ein. Queue-Systeme arbeiten sie dann der Reihe nach anhand von Kriterien wie Größe, Priorität und Eingangszeit ab. Eines der ältesten Systeme ist das Portable Batch System, das die Nasa Mitte der 90er entwickelt hat. Als Open PBS [12] ist es quelloffen erhältlich. Viel gebräuchlicher ist aber heutzutage die ebenfalls freie Variante Torque [13].
Plan-basierte Systeme ermöglichen es dem Nutzer, sich im Vorhinein Teile des Clusters zu reservieren. Einem solchen System muss der Anwender beim Übermitteln eines Jobs noch mitteilen, wann der Job laufen soll. Dieses Feature ist besonders für interaktive Jobs geeignet, für die ein Nutzer Knoten reservieren möchte. Ein System dieser Gattung ist das ebenfalls freie Open CCS [14].
Standardsoftware
Nicht jeder, der eine Aufgabe zu bewältigen hat, die ein HPC-System voraussetzt, möchte sofort in die parallele Programmierung einsteigen. Es lohnt sich, zunächst zu prüfen, ob nicht bereits eine gute Software für das Problem existiert. Wenn eine Software das Message Passing Interface (MPI) voraussetzt oder zumindest fähig ist MPI zu nutzen, ist das ein guter Hinweis dafür, dass sie im Cluster lauffähig ist. Von dieser Art gibt es bereits jede Menge Software und manche Projekte erschließen dem Clustercomputing sogar ganz neue Bereiche.
Dist CC [15] ist beispielsweise ein Projekt, das einen verteilten Compiler bereitstellt. Er spart Kosten, weil der Entwickler nicht mehr auf das Übersetzen warten muss. Um große Statistiken auf einem Cluster auszuwerten, eignet sich der freie S-Plus-Klon R [16].
Der Bereich der physikalischen Mechanik-Simulation kann durch FEM-Programme (Finite Elemente Methode) abgedeckt werden. Elmer [17] ist eine freie Software, die Strömungs- und Strukturmechanik mit der FE-Methode simulieren kann und Cluster-fähig ist. Einen anderen Bereich der Simulation deckt das Weather Research and Forcasting Model [18].
Auch für rein naturwissenschaftliche Zwecke sind viele freie Simulationscodes verfügbar. Clustal [19] und Emboss [20] sind ganze Suiten für molekulargenetische Simulationen. APBS [21] ist dagegen eine Software, die elektrochemische Eigenschaften und Prozesse von Biomolekülen berechnen kann (siehe Abbildung 4). Aus dem Bereich der Physik kommt die Cernlib [22], die die gleichnamige Forschungseinrichtung frei für die Belange physikalischer Labors anbietet.
Um einen Cluster in eine Renderfarm zu verwandeln, existieren ebenfalls freie Projekte. Povray [23] lässt sich schon seit vielen Jahren verteilt ausführen, und der freie 3D-Modeller Blender kann entweder in das Povray-Format exportieren oder mittels Dr. Queue [24] selbst parallel rendern.
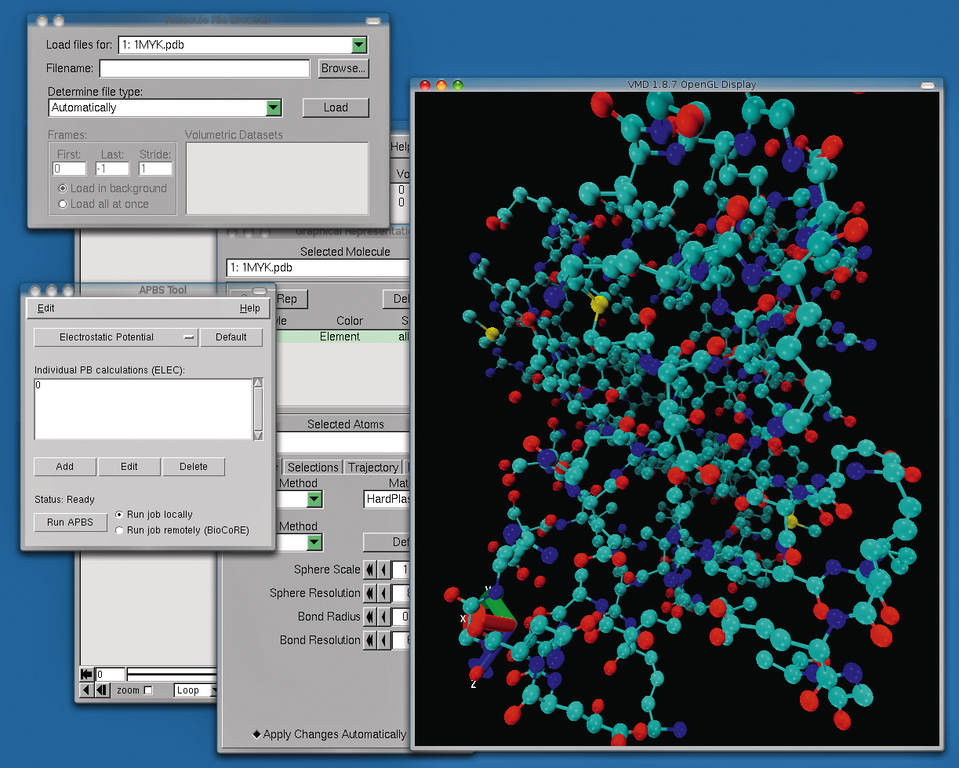
Abbildung 4: Ein in VMD dargestelltes Molekül von einem Protein. VMD kann direkt mit der Simulations-Software APBS zusammenarbeiten.
Paralleles Programmieren
Ist ein sehr spezifisches Problem zu lösen, bietet es sich oft an, die Software selbst zu schreiben oder ein bestehendes Programm selbst zu parallelisieren. Für verteilte Computersysteme gibt es dafür zwei Paradigmen. Das ist zum einen das Message Passing Interface (MPI), ein komplettes Programmiermodell, das die Kommunikation zwischen parallelen Prozessen gestattet. MPI bildet oft sogar die Treiberschnittstelle für Hochgeschwindigkeits-Netzwerke, die in großen Parallelrechnern zum Einsatz kommen. Freie MPI-Implementierungen sind Open MPI [25] oder MPICH2 [26].
Das andere stark vertretene Paradigma ist Open MP. Sein Programmiermodell ist in erster Linie auf die parallele Programmierung von Multicore-Systemen ausgelegt. Über spezielle Pragma-Direktiven, die der Programmierer direkt in den Code des Programms schreibt, teilt er dem Compiler mit, was der automatisch parallelisieren kann. Viele Compiler, auch der GCC, verstehen heutzutage bereits von Haus aus Open-MP-Direktiven. (jcb)
| Der Autor |
|---|
| Dominic Eschweiler ist wissenschaftlicher Mitarbeiter am Supercomputing Centre des Forschungszentrums in Jülich. Er befasst sich mit der automatischen Leistungsanalyse hoch skalierender paralleler Codes.
|







