
© Arvydas Kniuk¨ta, 123RF.com© Oliver Widder
Dass Cloud Computing im Anmarsch ist, steht für Freunde und Feinde ausgelagerter Dienste außer Frage. Eine verbindliche Definition dessen, was da eigentlich kommt, gibt es jedoch nicht. Die gute Nachricht: Das meiste ist längst da.
Aktuelle Weitverkehrsnetze erreichen mit 1 bis 10 GBit/s ähnliche Bandbreiten wie gängiges Ethernet. Ein Client erreicht somit einen Server im Internet ähnlich gut wie den im Serverraum nebenan. Ist die topologisch weiter entfernte Rechenressource nun potenter als die leichter zugängliche, kann es darum durchaus Sinn ergeben, mindestens einzelne Aufgaben in die Internetwolke auszulagern. Alle paar Jahre wird diese eigentlich einleuchtende Idee zum Kern einer neuen Entwicklung:
- Server-based Computing (SBC) und Thin Clients
- Application Service Provision oder Application Solution
Providing(ASP), später Software-as-a-Service (SaaS) - Grid Computing
- Utility Computing
- Service-oriented Architectures (SOA) und Webservices
- Meta-Computing
- Enterprise Application Integration
- Infrastructure-as-a-Service (IaaS)
- Platform-as-a-Service (PaaS)
- Storage-as-a-Service
- HPC-as-a-Service …
- Cloud-Computing
Selbst Human-as-a-Service soll es geben. Man ahnt es: Nicht alles ist neu.
Gemeinsam ist den meisten der Wunsch, organisations- oder weltweit verteilte Ressourcen den verteilt agierenden Nutzern transparent zugänglich zu machen: Im Idealfall kann der User nicht unterscheiden, ob gerade sein eigener Computer für ihn arbeitet oder ein entfernter.
An einer Schwierigkeit laborieren alle Entwicklungen auch. So reicht zwar meist sogar eine DSL-Verbindung, um entfernte Dienste interaktiv zu nutzen. Wegen Netzwerk-Latenzen dauert es andererseits schon mal eine drittel Sekunde, bis eine Antwort aus Australien in Mitteleuropa ankommt – die Verarbeitungszeit für die Anfrage nicht mitgerechnet.
Für ein Flugbuchungssystem, das ein Mensch tippend bedient, spielt das keine Rolle. Für verteilte umfangreiche Berechnungen, die viel Kommunikation zwischen den Rechenknoten erfordern, ist eine drittel Sekunde aber eine halbe Ewigkeit. Hier steuern Cloud-Anbieter gegen, etwa mit regionalen Frontends zur flotteren Ausliefen der Daten [2].
Vorläufer SOA
Der Begriff Service-orientierte Architektur bezeichnet das Abbilden von Geschäftsprozessen auf Webservices niedrigerer Ebene. Als Service gilt eine Applikation, die standardisiert über eine XML-Schnittstelle ansprechbar ist. Zur Kommunikation kommt meist SOAP (Simple Object Access Protocol) zum Einsatz, in älteren Anwendungen auch XML-RPC (XML Remote Procedure Call). WSDL (Web Services Description Language) beschreibt die vom Webservice unterstützten Methoden einschließlich ihrer Datentypen.
Durch das Zusammensetzen von Diensten aus elementaren Angeboten lassen sich wieder verwendbare und in mehreren Umgebungen nutzbare, an Services orientierte Architekturen aufbauen – so die Theorie. Die einzelnen Webservices dürfen natürlich weltweit verteilt laufen. Um SOA entstand zu seiner Zeit ein Hype, aus dessen Abebben sich aber nicht schließen lässt, dass die dahinter stehende Idee obsolet ist (Abbildung 1).
![Abbildung 1: Das stetige Neuerfinden von Begriffen für verteiltes Rechnen spiegelt sich sogar in Cartoons wieder. Im Webcomics „From hype to hype“ betrachten zwei Personen ein totes SOA-Pferd [1]. Einer sagt: „Lass es uns in der Cloud verstecken.“](https://www.linux-magazin.de/wp-content/uploads/2011/08/abb1.png-9.png)
Abbildung 1: Das stetige Neuerfinden von Begriffen für verteiltes Rechnen spiegelt sich sogar in Cartoons wieder. Im Webcomics „From hype to hype“ betrachten zwei Personen ein totes SOA-Pferd [1]. Einer sagt: „Lass es uns in der Cloud verstecken.“
Vorläufer Grid
Einen ähnlichen Weg hat das Grid Computing, die “Rechenzeit aus der Steckdose”, seit 1998 hinter sich. In der Tat leitet sich der Begriff vom englischen “Electical Power Grid” (Stromnetz) ab [3]. Heute, zwölf Jahre später, betreibt das Projekt Enabling Grids for E-Science (EGEE, [4]) die vermutlich größte real existierende Grid-Infrastruktur.
Mit Rechenzeit aus der Steckdose hat das aus einem EU-Projekt hervorgegangene Grid allerdings nur wenig zu tun. Hinter einer einheitlichen Schnittstelle sind 150 000 CPU-Kerne in 260 Rechenzentren so zusammengeschaltet, dass sie wie eine einzige Rechenressource aussehen. Ähnlich wie in einem Hotel leitet ein Broker täglich 330 000 Programme – meist wissenschaftlicher Provenienz – zu solchen Zentren, die sowohl freie Kapazitäten haben, als auch über die für die Applikation notwendigen Datensätze verfügen. Dort schleust sie ein lokales Batch-Submission-System an die lokalen Rechenknoten. Eines der 13 Herzen des EGEE-Grid steht übrigens in Deutschland, das Gridka-Rechenzentrum im Karlsruhe Institute of Technology [5].
Open Source spielt bei Grids eine tragende Rolle. Praktisch überall auf dem EGEE-Grid läuft Scientific Linux, ein Fedora-Abkömmling. Als Middleware kommt oft die Open-Source-Software G-Lite zum Einsatz, auch Unicore oder Globus sind vertreten. Der anfängliche Grid-Hype ist wie bei SOA der Ernüchterung gewichen. So überschrieb Sun 2001 seinen Stand auf Supercomputing-Messen mit “Sun powers the Grid”. Heute werben große Hersteller nur noch für das neue Neue: Cloud Computing.
Wolken überall
Eine einheitliche Definition von Cloud Computing gibt es nicht. In der Folge kleben neue wie etablierte Firmen, die gegen eine Gebühr eine Leistung im Internet anbieten, heute das Etikett “Cloud” auf die Verpackung – in gewisser Weise zu Recht, denn sie betreiben Public Clouds. Dazu gesellen sich alle Virtualisierungs- und Terminalserver-Spezialisten, denn die schreiben die Software, um Cloud Computing im eigenen Rechenzentrum zu veranstalten oder eine Private Cloud zu betreiben. Mindestens die Hälfte der am Anfang dieses Artikels aufgezählten Kategorien lassen sich heute unter Cloud Computing subsummieren.
Ein paar Beispiele sollen helfen die Spannweite der Public-Cloud-Angebote auszumessen: Mit der “Elastic Compute Cloud” (EC2, [6]) stellt der Onlinehändler Amazon 2007 einen De-facto-Standard für Cloud Computing ins Netz. Ähnlich wie bei einem herkömmlichen Hoster kann jeder für einen geringen Betrag virtuelle Systeme mieten – dies aber “on Demand” auch für sehr kurze Zeit, bezahlt wird pro genutzter CPU-Stunde.
Der Kunde bestimmt ein Diskimage einer Betriebssysteminstallation, das Amazon dann in beliebig vielen Instanzen virtuell ausführt. Den Inhalt des Image bestimmt der Kunde selbst und genießt darauf vollen Root-Zugriff, was den Einsatzszenarien kaum Grenzen setzt. Amazons Angebot lässt sich als Platform-as-a-Service oder – weitergedacht – als Infrastructure-as-a-Service kategorisieren. Hier kommt auch der Aspekt des so genannten Cloud Bursting zum Tragen, bei dem der Kunde nur für Lastspitzen-Zeiten “elastisch” die externen Ressourcen beansprucht. Das könnte bei einem Onlineshop-System die Zeit nach dem Versenden eines Newsletter sein, wenn innerhalb von vielleicht einer Stunde die Hälfte der Gesamtbestellungen des Monats anfällt.
Neben EC2 hostet Amazon andere Cloud-Dienste [7], so das verteilte Speichern großer Datenmengen (S3, Simple Storage Service) oder für das Map-Reduce-Verfahren basierend auf Hadoop (Elastic Map Reduce). Das Amazon-API ist mit Eucalyptus [8] und (zumindest in Teilen) mit Open Nebula [9] und Nimbus [10] auch als Open-Source-Software implementiert.
HPC-as-a-Service und SaaS
Anders als Amazon wirbt die US-Firma Penguin Computing mit HPC-as-a-Service (High Performance Computing, [11]), das on Demand Zugriff auf dynamische, skalierbare High-Performance-Cluster für parallele Rechenlasten realisiert.
Google stellt zu seinen öffentlichen Angeboten Google Mail, Youtube, Picasa und so weiter eine so genannte App Engine für Java- oder Python-Webapplikationen bereit [12]. Der Benutzer schreibt damit dedizierte Webservices und stellt sie anderen zur Verfügung. Früher wären diese Angebote als Software-as-a-Service oder ASP durchgegangen – heute schlägt man das dem Cloud Computing zu.
Hewlett-Packard betreibt zusammen mit Intel und Yahoo das Open Cirrus Cloud Testbed [13]. Anders als bei den meisten kommerziellen Angeboten sind hier auch einige akademische Einrichtungen beteiligt, darunter die University of Illinois at Urbana Champaign, die Infocomm Development Authority aus Singapur sowie das Karlsruhe Institute of Technology.
Unterwegs-Schreibtisch
Bei In-House-Clouds kommt ab mittlerer Unternehmensgröße auch die Virtualisierung von Desktops in Betracht. Das Desktop-Betriebssystem liegt dann als virtuelle Maschine auf einem Server, die Mitarbeiter greifen mit Thin Clients, Laptops oder PCs per RDP, VNC oder Nomachines NX darauf zu. Geht ein Angestellter auf Reisen, verlagert er vor der Abreise seine virtuelle Maschine mit Tools auf Cloud-Ressourcen in seiner baldigen geografischen Nähe. So folgt der Desktop seinem Nutzer, was Latenzen reduziert und den Zugriff beschleunigt.
Auch in einer Firma mit nur einem Standort bringt die Desktopvirtualisierung Vorteile. Zum einen sind die administrativen Folgen eines Arbeitsplatz-Hardwaredefekts sehr gering. Zum anderen teilen sich an- wie abwesende Mitarbeiter statistisch die Rechnenkapazität des Terminalservers, was unterm Strich CPU- und RAM-Kapazität, also Hostingressourcen, einspart. (Das Sharing von dedizierten Mitarbeiter-PCs wäre zwar möglich, ist aber ungleich komplizierter.)
Noch nicht produktionsreif, aber zu erwarten sind die Nachfolger der Spielkonsole (siehe Kasten “Cloud-Gaming”) oder Augmented Reality. Bei Letzterem nimmt das Smartphone über eine kleine Kamera in der Brille des Reisenden dessen Umgebung auf und schickt sie per Mobilfunk zur Analyse in die Cloud. Die Brille spiegelt dann das Ergebnis passend zum Ambiente auf die Netzhaut des Nutzers. Alle Techniken dafür sind vorhanden, nur muss jemand es umsetzen.
| Cloud-Gaming |
|---|
| Es gibt die These, der Betrieb eines Spieleservers sei der Killer-Usecase (im Wort- wie im übertragenden Sinne) des Cloud Computing. Denn eine gehostete (virtuelle) Konsole bedarf einer viel geringeren Investition. Nutzer greifen immer auf aktuelle Spiele zu, die sie wahrscheinlich nicht mehr kaufen, sondern für die Dauer der Nutzung mieten oder für die verwendete Rechenzeit bezahlen.
Die Cloud-Ressource ist so auszulegen, dass sie viel mehr Polygone in Echtzeit berechnen kann als eine konventionelle Spielekonsole. Die Spieler benötigen nur noch eine Anwendung, die die übertragenen Polygondaten rendert. Bald könnte sogar das Rendering ebenfalls in der Cloud stattfinden, was bedeutet, dass ein schneller 3D-Fernseher oder gar das eigene Mobiltelefon als “Client” ausreicht, was Cloud Computing im großen Enduser-Markt etablieren würde. |
Versuch einer Definition
Im Unterschied zu Grid Computing stellt die Cloud Ressourcen on Demand bereit, während existierende Grids statischer Ressourcen eher orchestrieren. Zudem zeichnet sich das Cloud Computing durch seine kommerzielle Abstammung aus. Das hat Konsequenzen auf die Art der Software-Entwicklung und auf das Setzen globaler Standards.
Firmen, deren Marktmacht groß genug erscheint, werden versuchen für ihre Angebote Alleinstellungsmerkmale zu etablieren. Per definitionem stellen andere Anbieter nicht die gleichen Unique Selling Points bereit, was die einzelnen Angebote im Umkehrschluss inkompatibel macht. Anwender muss das nicht unbedingt stören, sofern die Angebote des Anbieters umfassend (und erschwinglich) sind. Wie beim gängigen Outsourcing ganzer IT-Departments muss der Kunde nur beachten, dass sein Cloud-Dienstleister für Fehler finanziell geradesteht.
Zweifler an Public Clouds dürfen sich noch vor Augen führen, dass die Migration zu Cloud-Ressourcen hin nicht in einem Schritt erfolgen muss. Denn viele Techniken des Cloud Computing lassen sich auch erst mal mit eigenen, internen Rechenkapazitäten und -zentren nachbilden – Open Source sei Dank (Eucalyptus [8], Open Nebula [9] und insbesondere das App-Engine-kompatible Appscale (Abbildung 2, [14]), das sogar in EC2, Eucalytus und XEN/KVM läuft).
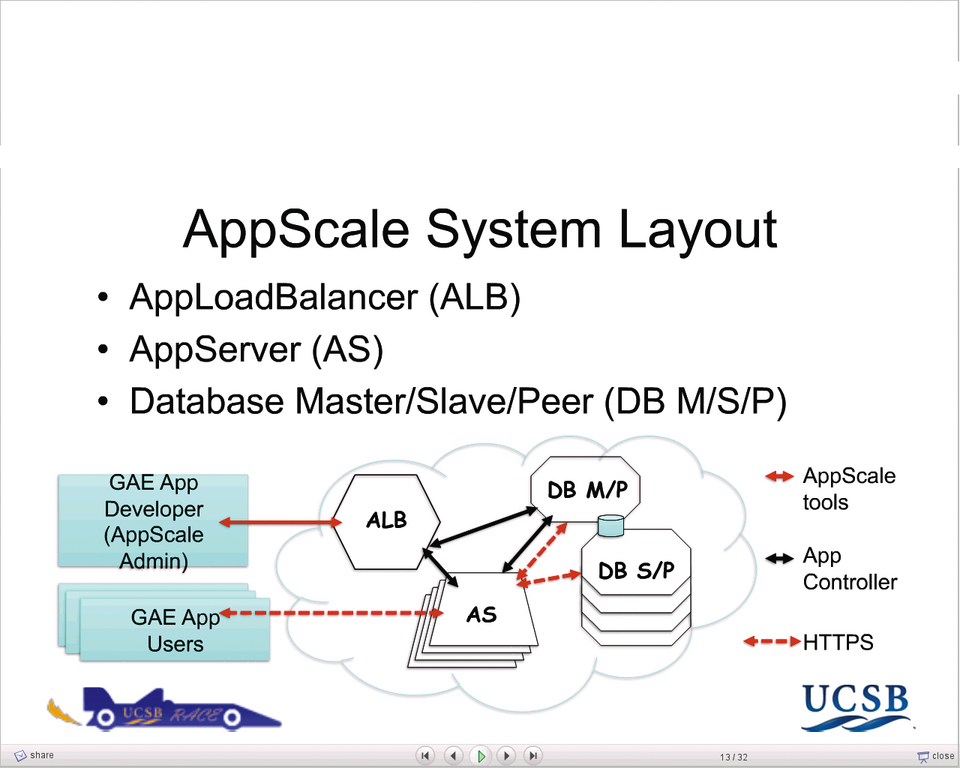
Abbildung 2: Das Appscale-System besteht aus Controller und Load Balancer für Cloud-Applikationen sowie einem Datenbankmanagement.
Solche Private oder In-House-Clouds bieten Arbeitsumgebungen als virtuelle Maschinen, ohne die Sicherheit mehr zu gefährden, als dies mit unternehmensweit verteilten Clustern ohnehin der Fall wäre. Die Migration zu externen Ressourcen erfolgt dann Zug um Zug. Diese Mischform aus Private und Public Clouds heißt hybrides Cloud Computing.
Es geht rund
Server-based, Grid, SOA, … bis hin zu den neuen und alten Spielarten des Cloud Computing: Das Auf und Ab dieser einander gar nicht unähnlichen Ressourcen-Verteiltechniken erscheint dem Betrachter wie bei Schaukelpferden eines Kirmeskarussels. Bei jeder Runde entdeckt man ein neues Detail – auch wenn es nicht wirklich neu ist, kann es nun doch nützen. Dem Trend Cloud Computing kommt die sich stetig verbessernde Internetstruktur zugute. Dass in den meisten Anwendung die wirtschaftlichen Vorteile der gemeinsamen Nutzung verteilter Ressourcen die einhergehenden technischen und juristischen Nachteile überwiegen, darf man getrost als belastbare Arbeitshypothese ansehen. Drum ist das im Anzug. (jk)
| Infos |
|---|
| [1] “Geek and Poke”-Strip vom 13.12.2009:[http://geekandpoke.typepad.com/geekandpoke/2009/12/from-hype-to-hype.html]
[2] Cloudfront als Content Delivery Network: [http://aws.amazon.com/cloudfront] [3] Schwerpunkt “Grid Computing”, Linux-Magazin 06/04 [4] EGEE: [http://www.eu-egee.org] [5] Grid Computing Centre Karlsruhe: [http://grid.fzk.de] [6] Amazon Elastic Compute Cloud: [http://aws.amazon.com/ec2/] [7] Amazone Webservices: [http://aws.amazon.com] [8] Eucalyptus: [http://www.eucalyptus.com] [9] Open Nebula: [http://opennebula.org] [10] Nimus: [http://www.nimbusproject.org] [11] HPC-as-a-Service: [http://www.penguincomputing.com/POD/HPC_as_a_service] [12] Google App Engine: [http://code.google.com/intl/de-DE/appengine/] [13] Open Cirrus: [https://opencirrus.org] [14] Appscale: [http://code.google.com/p/appscale/] |
| Der Autor |
|---|
 Dr. Rüdiger Berlich forscht am Karlsruhe Institute of Technology über Cloud Computing. Er beschäftigt sich seit 2001 mit verteiltem Rechnen und ist Autor der Open-Source-Software Geneva, einer Umgebung zur parallelen Problemoptimierung in Cloud und Grid. |





