
© Volodymyr Vasylkiv, Fotolia.com
Leider, leider enthält jedes Programm oberhalb von Hello World Fehler. Quellcode-Reviews von Experten sind ein probates Mittel, sie zu finden. Spezielle Scansoftware wie die von der Firma Coverity scheint eine geeignete Ergänzung zu sein. Ein Selbstversuch aus dem Umfeld des Kernels wird Klarheit bringen.
Niemand mag Fehler in Programmen – außer vielleicht Cracker. Gerade in abstrakten Bereichen eines Quelltexts übersehen Entwickler Sonderfälle, einzig die Hauptaufgabe ihres Code vor Augen ([1], [2]). Generationen von Compilerbauern und Projektmanagern haben sich Gedanken darüber gemacht, das Problem zu mildern oder zu lösen.
Einige befürworten strukturierte Programmiersprachen, die seltener Fehler machen sollen, andere schlagen regelmäßige Codereviews durch Partner oder QA-Abteilungen vor. Letztlich hat sich die Erkenntnis durchgesetzt, dass ein Mittel allein nicht wirksam ist. Die Kombination von mehreren Reviews aus unterschiedlichen Blickwinkeln scheint die besten Ergebnisse zu liefern.
Hinzu kam die Hoffnung, die Qualitätssicherung einer Automatik zu übertragen. Schon früh, als die ersten C-Compiler entwickelt wurden, lieferten deren Programmierer ein Werkzeug mit, das den Code auf eine Reihe von potenziellen Fehlern untersuchen und den Programmierer vor ihnen warnen sollte: Der Erfolg von Lint war eher mäßig [3]. Das Programm ging in die Annalen der Software-Entwicklung primär als mäkelndes Ärgernis ein, das hauptsächlich unwichtige Kleinigkeiten monierte (siehe Kasten “Das Prinzip”). Für lange Zeit galt daher das automatische Finden von Fehlern als nicht oder nur schwer machbar.
|
Das Prinzip |
|---|
|
Codechecker sollen Fehler in Programmen finden, bevor sie Nutzern Ärger bereiten. Ihr Funktionsprinzip basiert darauf, dass viele Fehler in nur leichter Variation immer wieder auftreten und sich automatisch erkennen lassen. Während die Analyseprogramme den Quelltext untersuchen, machen sie manchmal aber auch selbst Fehler. So meldet praktisch jeder Codechecker Defekte, die bei näherer Betrachtung keine sind (False Positives), oder vergisst solche, die vorhanden sind (False Negatives). Nicht gemeldete Fehler sind bedauerlich, zu viele Falschmeldungen ärgern schnell den Entwickler. Sie lassen das Werkzeug nutzlos erscheinen. Verwendet der Programmierer es nur ungern, ist es wenig hilfreich. Es gibt mehrere Möglichkeiten, mit False Positives umzugehen. Die meisten Codechecker definieren Klassen, die ähnliche Fehlermuster zusammenfassen (siehe Tabelle 1). Um False Positives zu reduzieren, könnte der Anwender naiverweise Fehlerklassen mit geringer Trefferquote schlicht abschalten. Dies spart zumindest etwas Frust. Dennoch sollten Entwickler diese Klassen zumindest einmal durchsehen und die wenigen echten Fehler beheben. Erfahrungen von Entwicklern mit den Kernelquellen zeigen, dass sich nach einigen Jahren eine erneute Untersuchung ebenfalls lohnt – in der Zwischenzeit hat durch die vielen Patches wieder eine Reihe gleichartiger Fehler Eingang in den Kernel gefunden. Einige Kernelhacker empfehlen, die Stellen, an denen ein Tool False Positives meldet, näher zu betrachten und umzuschreiben. Oft versteht ein menschlicher Leser den Code nämlich ebenfalls nicht. So besteht die Gefahr, dass durch künftige Patches wirkliche Fehler entstehen. Ein zweiter Blick ist noch aus einem weiteren Grund sinnvoll: Fehler haben die Neigung, sich in Gruppen zusammenzurotten. Auch Programmierer haben manchmal einfach einen schlechten Tag, manche machen mehr Fehler als andere. Einige Projekte arbeiten unter mehr Zeitdruck, andere sind erst neu in die Kernelentwicklung eingestiegen und haben damit weniger Erfahrung als alte Hasen. In jedem dieser Fälle entstehen Ballungen. Findet ein Codechecker einen ersten Fehler, lohnt es sich, nach weiteren Ausschau zu halten. Auch bei False Positives steht die Chance gut, weitere echte Fehler in der Nähe zu finden. Ein freies Tool verbessert zusätzlich die eingebauten Heuristiken, wenn Anwender die Ergebnisse an die Entwickler zurückgeben. Auf diese Weise haben es alle nachfolgenden Anwender dieser Werkzeuge ebenfalls einfacher. |
Statische Software-Analyse
Erst ab dem Jahr 2000 beschäftigten sich einige Forscher um den Professor Dawson Engler des Computer Systems Laboratory an der Stanford University in Palo Alto wieder mit dem Thema und entwickelten den Stanford Checker [4]. Seine Grundidee liegt darin, den Abstract Syntax Tree (AST) eines Quelltexts aufzubauen [5]. Das ist die weitgehend sprachunabhängige Darstellung einer imperativen Programmiersprache. Diesen AST untersuchte das Werkzeug nach möglichen Ausführungspfaden, die von Variablenbelegungen und anderen Zustandsinformationen abhängen.
Das Ergebnis der Bemühungen ist eine komplexe kombinatorische Aufgabe. Bei ihr bewertet ein Programm, ob der Code zu Widersprüchen führt, etwa zum Überschreiten von Array-Grenzen oder der Dereferenzierung von nicht-initialisierten oder illegalen Zeigern. Das Verfahren nennt die Fachwelt meist statische Software-Analyse, da es den Code noch vor der Übersetzungszeit untersucht. Andere Verfahren versuchen die Probleme zur Laufzeit zu erkennen.
Richtig eingesetzt findet die statische Software-Analyse also Fehler. Beheben die Programmierer sie, dürfen sich die Anwender über größere Stabilität und weniger Abstürze freuen. Besondere Bedeutung hat das Verfahren aus Sicht der Sicherheit: Nicht jeder Defekt muss zwangsläufig einen Absturz nach sich ziehen, können Anwender jedoch interne Strukturen verändern, lassen sich oft Sicherheitsmaßnahmen umgehen oder gar eigener Code einschleusen.
Universitäre Ausgründung
Im Jahr 2003 gründete Stanford das Projekt in das Unternehmen Coverity aus, das seither am freien Markt operiert [6]. Es bietet unter anderem das kommerzielle Prevent for C [7] an. Als weitere Sprachen unterstützt das Werkzeug auch C++ und Java. Als Testbett für das ursprüngliche Werkzeug benutzten die Forscher in Stanford und später bei Coverity unter anderem den Linux-Kernel. Sie schickten die gefundenen potenziellen Fehler an entsprechende Mailinglisten und erarbeiteten sich so bei einigen den Ruf, auch schwere und schwerwiegende Fehler zu entdecken.
Im Anschluss startete Coverity 2006 im Rahmen eines Vertrages [8] mit der amerikanischen Heimatschutzbehörde [9] das Scan-Projekt. Sein Ziel ist es, Open-Source-Software sicherer zu machen [10]. Laut Aussage von Scan haben die teilnehmenden Projekte allein in den ersten zwölf Monaten über 6000 echte Defekte behoben, die der Checker entdeckt hatte.
Zugang zu Scan bekommt, wer eine Anfrage per Mail an [scan-admin@coverity.com] schickt. Dazu ist Geduld notwendig, da nur der von Coverity eingestellte Community-Manager David Maxwell alle Anfragen bearbeitet. Allerdings reist er nebenbei noch zu Konferenzen, hält Vorträge, administriert Serverhardware und hat dementsprechend viel zu tun.
Anmeldung
Wer einmal Zugang erhalten hat, macht David Maxwell den eigenen Quellcode zugänglich, etwa dadurch, ihm einen öffentlichen Git-Baum bekannt zu geben. Andere Formate akzeptiert das Scan-Projekt ebenfalls. Der Community-Manager lässt daraufhin den Checker über den Code laufen und antwortet mit einer URL, die die Ergebnisse der Analyse zusammenfasst und es erlaubt, im Code zu browsen. Alle Projekte greifen auf denselben Server zu, der pro Projekt eine andere Portnummer nutzt. Den Zugang zu dieser Website schützt ein Passwort.
Stufe für Stufe
Das hinter dem Projekt stehende Unternehmen Coverity teilt registrierte Projekte in drei Kategorien ein, so genannte Rungs (Leitersprosse). Wer sich erstmals anmeldet, startet in Rung 0. Hat ein Projekt auf einer Leitersprosse alle seine Defekte behoben, steigt es eine Stufe auf. Gegenwärtig befinden sich 173 Projekte in Rung 0, in Rung 1 sind es 86 und elf haben es bis auf Rung 2 geschafft.
Dort aktiviert Coverity einige zusätzliche Untersuchungen des Checkers. Zumindest in Rung 0 sind nämlich nicht alle Überprüfungen aktiv, die in dem kommerziell nutzbaren Tool vorhanden sind (siehe Tabelle 1). Außerdem kommt eine ältere Version zum Einsatz.
|
Tabelle 1: |
|
|---|---|
|
Checker |
Durchgeführte Tests |
|
Deadcode |
Code, der nicht ausgeführt werden kann |
|
Forward null |
Ein Zeiger wird dereferenziert, der »NULL« sein |
|
Negative returns |
Ein negativer Rückgabewert, der etwa als Array-Index |
|
Null return |
Ein Zeiger wird dereferenziert, obwohl er »NULL« |
|
Overrun static |
Statische Überläufe von Feldern |
|
Resource leak |
Eine Ressource, etwa dynamischer Speicher, wird nicht wieder |
|
Reverse inull |
Ein Zeiger wird auf »NULL« geprüft, aber |
|
Reverse negative |
Ein Integer wird auf Vorzeichen geprüft, aber vorher schon |
|
Uninit |
Eine Variable wird uninitialisiert benutzt |
|
Use after free |
Eine Ressource wird nach der Freigabe noch benutzt |
Das Webfrontend präsentiert nach dem Einloggen eine Maske, in der Programmierer gefundene Defekte auswählen dürfen. Die Weboberfläche verwaltet mehrere Scannerdurchläufe. Der Anwender schränkt über die Maske ein, welche Defekte er sich anzeigen lassen möchte. Dabei stehen als Filterkriterien unter anderem der Scandurchlauf, die Fehlerklasse, der Status des Defekts oder dessen Besitzer zur Auswahl.
Im ersten Anlauf darf der Entwickler das alles erst einmal getrost ignorieren und benutzt den Knopf »Find Errors«. In der Standardeinstellung zeigt Scan damit alle gefundenen Fehler in einer Liste an. Die Fundstellen lassen sich auf verschiedene Arten sortieren, zum Beispiel nach Fehlertyp, Datei oder Besitzer. Jeder einzelne Bug verlinkt auf eine Detailseite mit vier Frames. An dieser Stelle mag sich so mancher Benutzer einen größeren Bildschirm wünschen. Der Hauptframe enthält den Sourcecode mit Hyperlinks, in ähnlicher Form wie bei der Web-basierten Linux Cross Reference LXR [11].
Entscheidend für Programmierer sind jedoch so genannte Events, also Ereignisse, die für die gelisteten Fehler relevant sind. Das Deklarieren einer Variablen und das Benutzen ohne vorherige Initialisierung sind zum Beispiel solche Ereignisse.
Kommentarfunktion
Das Scan-Projekt bietet seinen Benutzern eine gute Hilfe, die die Fehlerklassen ausführlich erläutert, Beispiele angibt und auch erklärt, wie sich die Fehler beheben lassen. Die Hilfe, wie auch die komplette Benutzerführung der Weboberfläche liegt aber nur auf Englisch vor.
Der Programmierer prüft die gemeldeten Defekte und darf sie kommentieren. Auf diese Weise kennzeichnet er auch False Positives. Hat ein teilnehmendes Projekt mehrere Entwickler, vermerkt jeder Programmierer außerdem, welche Defekte er schon inspiziert hat, und darf sich damit als dessen Besitzer verewigen.
Die Codebasis von Logfs [12], eines Dateisystems des Kernels für Flashspeicher, diente dem Linux-Magazin als erster Test für die Leistungsfähigkeit von Scan, die Quellen erhielt Scan als Git-Baum. Die Ergebnisse waren überschaubar, denn die Analyse meldete nur einen einzigen Defekt (siehe Abbildung 1) in Zeile 1018 der Datei »readwrite.c«: Die Funktion »page_mapping()« liefere möglicherweise einen »NULL«-Pointer zurück. Der Rückgabewert zeigt auf eine Datei, die zu der übergebenen Speicherseite »page« gehört. In diesem Kontext, einem Dateisystem, gibt es in jedem Fall eine solche Datei und der Rückgabewert ist daher nie »NULL«. Dieser Umstand trifft jedoch nicht auf jede Stelle im Kernel zu, sodass er den Checker vermutlich in die Irre geführt hat.
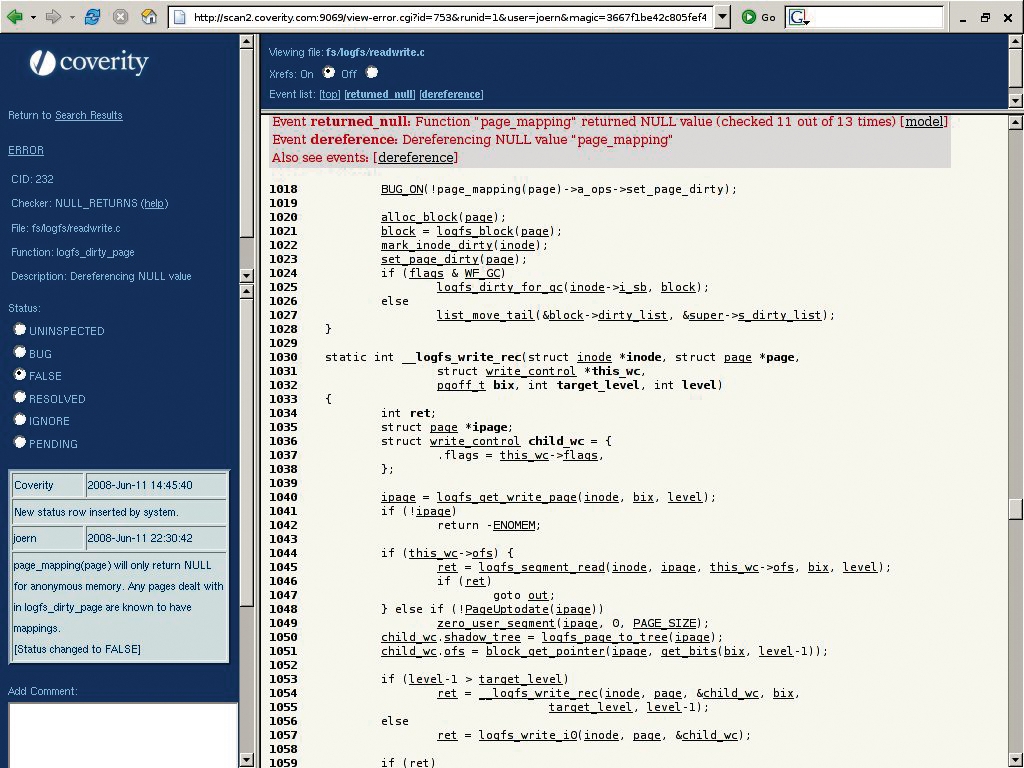
Abbildung 1: Das Scan-Projekt präsentiert sich dem Entwickler als Webapplikation. Im zum Test herangezogenen Quelltext fand das Werkzeug einen Defekt, der sich jedoch als False Positive herausstellte.
Ein typischer Code des Linux-Kernels enthält nach den statistischen Angaben von Coverity knapp 0,2 gemeldete Defekte pro 1000 Zeilen Quellcode. Logfs enthielt zur Zeit des Tests etwa 8000 Zeilen Code, daher liegt das Ergebnis im Rahmen der Erwartungen.
Linux, bitte antreten
Als zweiter Kandidat musste daher der Linux-Kernel selbst herhalten. Nach Rücksprache mit dem Ansprechpartner Dave Jones erhielt das Linux-Magazin Einblick in die Statistiken des Kernels. Seit dem ersten Lauf im Februar 2006 hat Scan die Quellen 380-mal durchsucht. In den rund 3,1 Millionen Zeilen Code beim ersten Lauf fand der Checker 1055 Defekte, von denen die Entwickler mindestens 213 als Fehler bestätigten. Zwei Jahre später, im Mai 2008, führten sie nur noch 42 bekannte Fehler auf. In beiden Fällen markierten sie rund 80 Defekte als False Positives, sie sind 2006 aber auch nur 64 Prozent und 2008 nur 47 Prozent aller Meldungen nachgegangen.
Daraus lassen sich zwei Schlüsse ziehen: Das Nachverfolgen der Defekte nimmt substanziell Zeit in Anspruch und rund 20 Prozent der Meldungen sind echte Fehler, die die Linuxer anderweitig nicht fanden – ordentlich für ein automatisiertes Werkzeug, finden viele Entwickler. Einer der gefundenen und bestätigten Defekte betrifft einen UMTS-Treiber in der Datei »ipwireless/hardware.c«. Der Entwickler hatte vergessen, in einer besonderen Situation einen Datenblock wieder freizugeben (siehe Abbildung 2).
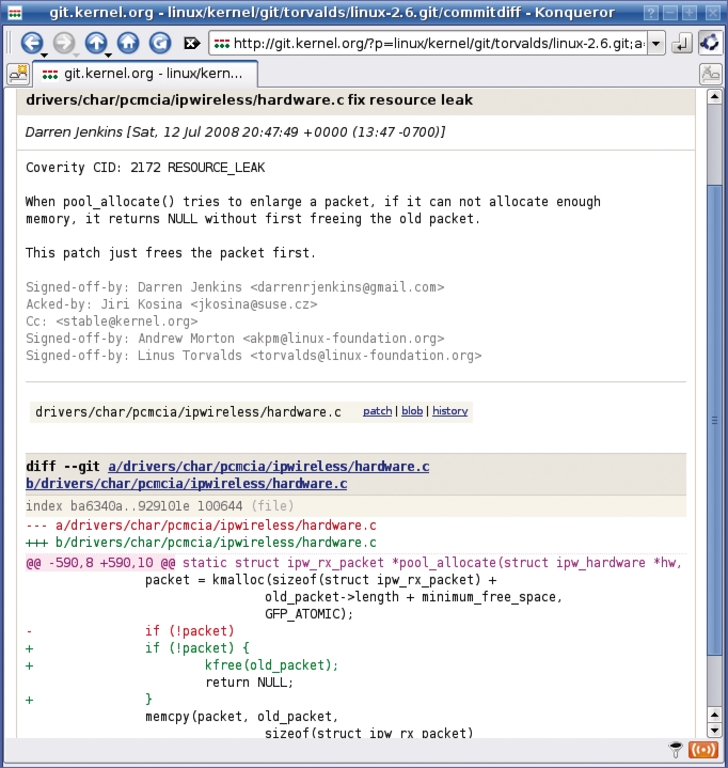
Abbildung 2: In einem UMTS-Gerätetreiber hatte es ein Entwickler vergessen, einen dynamischen Speicherbereich für ein Netzpaket wieder freizugeben. Das Scan-Projekt hat den Defekt unter der ID 2172 vermerkt.
Qualitätssicherung
Die Werkzeuge der Scan-Weboberfläche sind durchaus nützlich, Entwickler müssen sie aber nicht nutzen. Wichtig ist, dass sie Fehler finden und beheben (Abbildung 3). Kann sich ein Projekt darauf verständigen, das Projekt als Maßnahme zur Qualitätssicherung regelmäßig zu verwenden, verbessert das die Codequalität. Entscheidend ist, ob sich alle Entwickler dauerhaft auf ein neues und zudem Web-basiertes Werkzeug einlassen. Ein einmaliger Check fördert zwar auch Erkenntnisse zu Tage, seine Stärke spielt Scan aber erst aus, wenn Entwickler es regelmäßig einsetzen.

Abbildung 3: Das Webfrontend zeigt die kritischen Stellen von Defekt 2172 detailliert an und erklärt nach Zeile 589 in roter Schrift dessen Grund.
Der zugrunde liegende Checker basiert auf einer speziellen Parametrierung des kommerziellen Produkts von Coverity und liegt nicht im Quelltext vor. Kritiker mahnen an, freie Software solle sich nicht von proprietären Werkzeugen abhängig machen, Befürworter weisen auf die nützlichen Effekte für die Codequalität hin. Vom pragmatischen Standpunkt aus ist es lästig, das Programm nur über das Webinterface zu nutzen. Es entspricht eher den Arbeitsabläufen eines Kernelentwicklers, lokale Werkzeuge in seine Toolchain zu integrieren.
Dazu kommt, dass eine einzige Person alle wichtigen Einstellungen von Scan-Läufen erledigt, die schnell überarbeitet sind. So warten die Nutzer lange, und die Meinung über das Geschäftsmodell von Scan bleibt geteilt: Ist es für die einen eine Bereicherung, die kritische Fehler findet, empfinden es andere eher als Marketingmaßnahme, um ein kommerzielles Produkt zu bewerben.
Frei, aber eingeschlafen
Es gibt mehrere Ansätze für Codechecker als freie Software. Das Tool Smatch patcht den GCC in der Version 3.1.1 und ermöglicht es, neue Checker mit eigenen Tests zu schreiben [13]. Es basiert ebenfalls auf den Ideen aus Stanford und erlaubt auf komplexe Datenstrukturen zuzugreifen, die der Compiler beim Übersetzen sammelt. Allerdings entwickelt niemand das Programm weiter, sodass sich Software, die einen aktuellen Compiler erfordert, inzwischen mit dieser Version nicht mehr übersetzen lässt. Aktuell ist Version 4.3.1 des C-Compilers.
Das von Linus Torvalds 2003 ins Leben gerufene Tool Sparse ist eine weitere Alternative, um Quelltext semantisch zu parsen. Josh Tripplett entwickelt es aktiv weiter [14]. Es prüft eine ganze Reihe von Kernel-spezifischen Eigenheiten, etwa Attribute von Variablen, die darauf hindeuten, ob ein Pointer auf Speicher aus dem Userspace oder aus I/O-Bereichen zeigt. Insbesondere ist Sparse nicht vom GCC abhängig, sondern ein eigenständiges Compiler-Frontend. Die gefundenen Fehler überdecken sich jedoch kaum mit den Erkenntnissen aus dem Scan-Projekt, sodass Entwickler idealerweise beide Werkzeuge nutzen.
Nützliche Ergänzung
Die Technik hat seit Lint große Fortschritte gemacht. Das Scan-Projekt ist durchaus technisch in der Lage, einige Fehler zu finden, die ohne automatische Analyse vermutlich lange unentdeckt blieben. Doch gibt es Einschränkungen: Eine Untersuchung bietet sich schon aus statistischen Gründen erst ab mittleren Projekten an und ist auch nicht nebenher erledigt. Entwickler sollten ein gerüttelt Maß Zeit mitbringen, um die Tests richtig einzurichten, die Funktionsweise zu verstehen und zu lernen, wie sie das Webfrontend bedienen.
Dieser Aufwand macht sich vor allem dann bezahlt, wenn Projekte den Dienst nicht nur einmal in Anspruch nehmen, sondern dauerhaft in ihre QA-Prozesse integrieren. Bis dahin ist noch ein gewisses Wegstück zurückzulegen. (mg)
|
Infos |
|---|
|
[1] Achim Leitner, “Programmiererfallen: Sicherheitslücken in Programmen vermeiden”: Linux-Magazin 06/01, S. 30 [2] Achim Leitner, “Programmiererfallen: Sicherheitslücken durch den Format-String”: Linux-Magazin 08/01, S. 96 [3] Stephen Johnson, “Lint, a C program checker”: Computer Science Technical Report 65, Bell Laboratories, Dezember 1977 [4] Dawson Engler, “Checking System Rules Using System-Specific Programmer-Written Compiler Extensions”: Stanford, [http://www.stanford.edu/~engler/mc-osdi.pdf] [5] Wikipedia, “Abstract Syntax Tree”: [http://wikipedia.org/wiki/Abstract_Syntax_Tree] [6] Coverity: [http://www.coverity.com] [7] Prevent für C, C++, C# und Java:[http://www.coverity.com/html/prevent-for-c-c++.html] [8] Ryan Naraine, “DHS Funds Open-Source Security Project”: Eweek, 2006,[http://www.eweek.com/c/a/Security/DHS-Funds-OpenSource-Security-Project/] [9] US-amerikanische Heimatschutzbehörde: [http://www.dhs.gov] [10] Scan-Projekt: [http://scan.coverity.com] [11] Linux Cross Reference: [http://lxr.linux.no] [12] Logfs: [http://logfs.org] [13] Smatch: [http://smatch.sourceforge.net] [14] Sparse: [http://www.kernel.org/pub/software/devel/sparse/] |
|
Der Autor |
|---|
|
Jörn Engel ist Software-Entwickler und beteiligt sich am Linux-Kernel, vorrangig durch die Entwicklung von Logfs, eines neuen Dateisystems für Flashspeicher. Er lebt in Hamburg. |





