
© Dmitri Lechtchinski, commons.wikimedia.org
Wirft man C und Haskell in einen Mixer, kommt so etwas wie Kaya heraus. Die noch recht junge Skriptsprache besitzt zwar eine gewöhnungsbedürftige Syntax, bringt dafür aber praktische Konzepte mit, zum Beispiel für die Webprogrammierung.
Die japanische Nusseibe, Torreya Nucifera oder auch Kaya genannt, wächst im Süden Japans langsam vor sich hin. Ihr extrem hartes Holz dient unter anderem zur Herstellung von Go-Spielbrettern, an denen Edwin Brady und seine Kollegen von der Durham University Computing Society gerne ihre Freizeit verbringen, überdies tauchen Bäume häufig als abstrakter Datentyp auf. Beides zusammen brachte der von ihnen entwickelten Skriptsprache Kaya schließlich ihren Namen ein. Außerdem, so die Meinung der Programmierer, waren alle anderen guten Namen bereits vergeben.
Das Ergebnis hat nicht mehr viel mit dem schlichten Prinzip des Go-Spiels gemein, sondern überrascht mit ungewöhnlichen Konzepten und pfiffigen Details. Beispielsweise der für Skriptsprachen untypische Übersetzungsvorgang. Er fängt Syntaxfehler bereits vor der Ausführung ab, was wiederum Tests erleichtert. Die Syntax ist auch gleich der nächste auffällige Punkt: In Zeiten der Objektorientierung geht Kaya einen Schritt zurück und bedient sich lieber bei der funktionalen Programmierung.
Zugleich wirft Kaya mit umfangreichen Bibliotheken nur so um sich. Neben dem Zugriff auf Datenbanken erlauben sie die Manipulation von Bildern oder eine unkomplizierte Verschlüsselung von wichtigen Daten. Ganz besonders glänzen jedoch die eingebauten Netzwerkfunktionen. Sie gestatten die schnelle Entwicklung von kleinen oder mittelgroßen Webanwendungen. Kaya übernimmt dabei den üblichen Kleinkram wie Session-Management (von Kaya als Zustandsmanagement bezeichnet), den Aufbau von Webseiten oder die Verarbeitung von HTML-Formularen.
Durch entsprechende Sicherheitsmechanismen minimiert die Skriptsprache die Risiken von Cross-Site-Scripting und eingeschmuggeltem Code (Remote Code Execution). Ganz nebenbei bietet Kaya den üblichen Komfort gewohnter Skriptsprachen, etwa Garbage Collection, eine umfangreiche Ausnahmebehandlung (Exception Handling) und die Möglichkeit, externe C-Bibliotheken einzubinden. Wer kompilierte Skripte gar nicht mag, darf Kaya dank des mitgelieferten Interpreters auch wie jede andere Skriptsprache nutzen.
Auf den Projektseiten [1] stellen die Entwickler eine kostenlos nutzbare Referenzimplementierung unter der GPL-Lizenz zur Verfügung. Fertige Pakete gibt es für Linux, Mac OS X und Windows. Damit beweist Kaya seine Plattformunabhängigkeit – die nur voraussetzt, dass auf dem Zielsystem alle von Kaya genutzten Werkzeuge und Bibliotheken bereitstehen. Welche das sind, klärt der Kasten “Kaya-Installation”.
|
Kaya-Installation |
|---|
|
Der Kaya-Compiler benötigt einige Hilfskrücken. Im Einzelnen sind dies:
Da der Glasgow Haskell Compiler selbst in Haskell geschrieben ist, übersetzt er sich witzigerweise selbst. Um nicht in ein Abhängigkeitsdilemma zu geraten, sollte man lieber zu den fertigen Paketen von [2] greifen. Die später in den Skripten benutzten Bibliotheken benötigen unter Umständen noch weitere Pakete. Welche das im Einzelnen sind, verrät ihre API-Referenz unter [4]. Der bekannte Dreisatz »./configure; make; make install« erstellt die Kaya-Entwicklungsumgebung. Debian- und Ubuntu-Nutzer installieren hingegen einfach das Paket »kaya«. |
Hallo, Kaya
Am Anfang steht das Hallo-Welt-Programm in Listing 1. Der Code dürfte C-Programmieren vertraut vorkommen: Es gibt eine Funktion »main()«, die grundsätzlich immer als Erste nach dem Programmstart ausgeführt wird. Anweisungsblöcke stehen in geschweiften Klammern, während Kommentare mit »//« beginnen oder in »/* … */« eingefasst sind. »putStrLn()« gehört zur Standardbibliothek und schickt den übergebenen String zur Standardausgabe.
|
Listing 1: Hallo |
|---|
01 program hallowelt;
02
03 Void main() {
04 // Dies ist ein Kommentar
05 putStrLn("Hallo Welt!");
06 }
|
Die erste Zeile »program hallowelt« weist den Kaya-Compiler dazu an, aus dem Skript ein normales Programm mit dem Namen »hallowelt« zu erstellen. Die Übersetzung stößt auf der Kommandozeile »kayac hallowelt.k« an.
Im Gegensatz zu vielen anderen Skriptsprachen muss in Kaya der Typ einer Variablen bereits bei der Übersetzung bekannt sein (statische Typisierung). Als Hilfestellung gibt es die so genannte Typableitung (Type Inference). Dabei versucht der Compiler den Typ einer Variablen zu erschließen. Der Programmierer muss Typen somit nur dann angeben, wenn es wirklich notwendig ist. Ein Beispiel dafür zeigt Listing 2.
|
Listing 2: |
|---|
01 hallo = "Hallo"; 02 welt = "Welt!"; 03 hallowelt = hallo + welt; 04 putStrLn(hallowelt); |
Kaya kennt die üblichen Basistypen wie Ganzzahlen (»Int«), Wahrheitswerte (»Bool«) oder Gleitkommazahlen (»Float«). Gemäß den Kaya-Konventionen beginnen sie immer mit einem Großbuchstaben. Typumwandlungen geschehen recht untypisch in runden Klammern, etwa »textdreissig = String(30);«. Die Dimensionen von Arrays können wegfallen, man verwendet sie einfach je nach Bedarf:
a[0] = 5; a[1] = a[0] + 10; // a[1] = 15
Dazu gesellen sich ein paar häufig verwendete Kurzschreibweisen. Beispielsweise führen
a = [1,2,3,4,5]; b = [1..5];
jeweils zu einem Array mit fünf Einträgen, das aufsteigend die Zahlen von 1 bis 5 enthält.
Loopings
Besonders nützlich sind diese Abkürzungen in »for«-Schleifen:
for i in [1..x] {
putStrLn(String(i));
}
Kryptisch wird es jedoch, sobald ein Array als Argument dienen soll:
Void printArray([Int] zahlen) {
for i in zahlen putStrLn(String(i));
}
Die eckigen Klammern um das »Int« weisen »zahlen« als eindimensionales Array aus. Bei mehrdimensionalen Arrays sind entsprechend mehr Klammern erforderlich, beispielsweise »[[[Int]]]« für ein dreidimensionales Array. Alternativ dürfen C-Programmierer ihre For-Schleifen unter Kaya weiterhin nutzen. Gleiches gilt für »if« und »while«.
Als Beispiel berechnet Listing 3 den größten gemeinsamen Teiler und zeigt nebenbei, dass die Funkionsdeklaration wie in C aussieht. Wenn eine Funktion keine Argumente erhält, darf man bei der Definition die leeren runden Klammern einfach weglassen:
Float pi { return 3.14; }
Das Gleiche gilt für den Aufruf von »putStrLn (String(pi))«.
|
Listing 3: Berechnung des |
|---|
01 Int ggT(Int a, Int b){
02 if (b == 0) return a;
03 else if (a > b) return ggT(a-b, b);
04 else return ggT(a, b-a);
05 }
|
Erste Klasse
Kaya behandelt Funktionen wie Variablen – und erhebt sie damit zu so genannten First Class Objects. Man darf daher einer Funktion auch einfach eine andere übergeben, wobei als Typ die Signatur der Funktion anzugeben ist. Die wäre im Fall des ggT aus Listing 2 »Int(Int, Int)«. Ein recht simples Anwendungsbeispiel zeigt Listing 4.
|
Listing 4: Übergabe einer |
|---|
01 Int erhoeheumeins(Int a) {return a+1;}
02
03 Void aufalleanwenden([Int] elemente, Int(Int) einefunktion) {
04 for i in elemente {
05 ergebnis = einefunktion(i);
06 putStrLn(String(ergebnis));
07 }
08 }
09
10 Void main(){
11 a = [1..5];
12 aufalleanwenden(a erhoeheumeins);
13 }
|
Mehrere Variablen kann Kaya zu einer Gruppe zusammenfassen. Das Ergebnis ist dann ein neuer (abstrakter) Datentyp. Name und Alter beispielsweise kennzeichnen eine Person. C-Programmierer kennen dies als »struct« in Verbindung mit einem »typedef«, die Kaya-Welt spricht hier von einem »record«. Die Definition eines neuen Datentyps geschieht bei Kaya allerdings in einer etwas merkwürdigen Form, die stark an einen Funktionsaufruf erinnert:
data Person = newPerson(String name, Int alter);
Die obige Zeile definiert einen neuen Datentyp (»data«) namens »Person«. Diese Person setzt sich aus »name« und »alter« zusammen. Die Funktion »newPerson()« bezeichnet Kaya als Constructor. Sie erstellt später eine neue Instanz der Person. Hier werden zum ersten Mal die Wurzeln der funktionalen Programmierung sichtbar. Zum Vergleich: In C würde die Definition etwa folgendermaßen aussehen:
typedef struct {
char* name;
int alter;
} Person;
Der neue Personentyp lässt sich wie in Listing 5 weiter nutzen. Da in Kaya die Namensräume von Funktionen und Datentypen unterschiedlich sind, ist auch
data Person = Person(String name, Int alter);
als Schreibweise erlaubt, was sich noch einmal verkürzen lässt zu:
data Person(String name, Int alter);
Zuweisung und Konstruktor erfolgen also in einem.
|
Listing 5: Nutzung des neuen |
|---|
01 Void main() {
02 herrbert = newPerson("Herr Bert", 36);
03 herrbert.name = "Sieglinde";
04 hatgeburtstag(p);
05 }
06 Void hatgeburtstag(Person p) {
07 p.alter += 1;
08 }
|
Chamäleon
Polymorphie realisiert Kaya mit Typvariablen, die für beliebige Typen stehen:
data Paar<a,b>(a erster, b zweiter);
Der auf diese Weise definierte Datentyp »Paar« umfasst die zwei Variablen »erster« und »zweiter«, die wiederum von einem beliebigen Typ sein dürfen:
zahlen = Paar(3,2.2);
gemischtes = Paar("Herr Lohse", false);
Ein Datentyp darf in Kaya mehr als einen Konstruktor umfassen. In diesem Fall entstehen so genannte algebraische Datentypen (Algebraic Data Type, ADT). Sie beschreiben gewöhnlich Objekte, die es in mehreren Ausprägungen gibt. Damit deklariert man eine verkettete Liste in nur zwei Zeilen:
data List<a> = nil
| cons(a head, List<a> tail);
Womit nun endgültig der Bereich der funktionalen Programmierung erreicht ist. Im Beispiel kann eine Variable vom Typ »List« entweder »nil« oder ein Record sein, der eine Variable mit dem Namen »head« sowie eine weitere Variable »tail« vom Typ »List« enthält. Wer sich schon einmal mit algebraischen Spezifikationen herumgeschlagen hat, dem dürfte die obige Notation recht bekannt vorkommen.
In Kaya lässt sich folglich eine solche Spezifikation recht einfach umsetzen. Um eine Liste mit fünf Integer-Elementen anzulegen, genügt eine weitere Zeile:
list = cons(1,cons(3,cons(10,nil)));
Kürzer geht es kaum. Die definierte Liste steckt auch genau so in der Standardbibliothek, wo sich außerdem noch weitere, häufig gebräuchliche Typen tummeln, beispielsweise der am Anfang erwähnte binäre Baum.
Um beim Durchlaufen der Liste ihr Ende zu erkennen, hilft das »case«-Konstrukt aus Listing 6. Kaya vergleicht dabei keine Variablen, sondern die Codemuster und führt das erste Muster aus, das mit der Form von »list« übereinstimmt. »list« enthält entweder die Funktion »cons()« oder »nil()«. »case« prüft, welche der beiden vorliegt, und führt den Code hinter dem Pfeil aus.
|
Listing 6: Beispiel für |
|---|
01 Void printList(List<Int> list) {
02 case list of {
03 cons(head,tail) -> putStrLn(String(head));
04 printList(tail);
05 | nil -> return;
06 }
07 }
|
Kaya kennt auch Referenzen auf Funktionen. Wie Listing 7 beweist, sind sie jedoch nur entfernt mit den Zeigern aus C verwandt. Diese Referenzen gestatten dem Kaya-Programmierer aber, einen kleinen Trick anzuwenden: Bevor er eine Funktion aufruft, übergibt er schon einen Teil der benötigten Parameter. Bei ihrem eigentlichen Aufruf ergänzt er dann die restlichen. Dazu ein Beispiel:
Int addition(Int a, Int b) {
return a+b;
}
So weit nichts Neues. Doch jetzt erstellt er eine Referenz auf eine anonyme Funktion mit nur einem Parameter vom Typ »Int(Int)«. Hierbei rutscht das »@« nach hinten:
f = addition@(5);
Damit wurde »addition()« bereits teilweise angewandt. »f« ist jetzt eine Referenz auf eine Funktion, die nur noch einen Parameter benötigt:
ergebnis = f(7);
Die Zeile übergibt den zweiten, noch fehlenden Parameter, führt »addition()« also komplett aus. Die Variable »ergebnis« ist jetzt vom Typ »Int« und enthält den Wert »12«. Mit diesem effektiven Trick lassen sich große Codesegmente recht einfach in kleinere aufspalten.
|
Listing 7: Beispiel für |
|---|
01 Float pi() {
02 return 3.14;
03 }
04 a=@pi(); // a ist eine Referenz auf die Funktion pi()
05 b=a; // b ist jetzt 3.14
|
Wie die meisten anderen Programmiersprachen kann auch Kaya Codesstückchen in Bibliotheken, die so genannten Module, auslagern. Um ein solches einzubinden, steht am Anfang des Skripts die »import«-Anweisung (Listing 8, Zeilen 1 und 2). Ohne jedes Zutun lädt Kaya ein paar Standardmodule aus der mitgelieferten Standardbibliothek.
|
Listing 8: Einsatz von |
|---|
01 import MatheModul;
02 import nocheinMatheModul;
03
04 Void main() {
05 a = 27;
06 b = MatheModul::wurzel(a);
07 }
|
Auf diese Weise bindet es auch die Funktion »putStrLn()« ein. Welche Funktionen in welchem Modul stecken, verrät die ausführliche API-Referenz auf der Kaya-Homepage [4]. Wer zwei Module einbindet, in denen jeweils eine gleichnamige Funktion steckt, wählt die richtige per »::«-Operator aus (Listing 8).
Tricks fürs Web
Die Standardbibliothek umfasst ein paar Module, mit denen sich schnell eine kleine Webanwendung zaubern lässt. Ein Beispiel zeigt Listing 9, das übersetzt ein Programm namens »webhallowelt.cgi« ergibt. Dies lässt sich nun entweder wie gewohnt ausführen oder auf einem Webserver speichern, der CGI-Anwendungen unterstützt. Die neue erste Zeile »webapp webhallowelt« teilt dem Kaya-Compiler mit, dass das Ziel eine Webanwendung für die CGI-Schnittstelle ist, die CGI-konforme Ein- und Ausgaberoutinen verwendet.
|
Listing 9: Beispiel für |
|---|
01 webapp webhallowelt;
02
03 import Webapp;
04 import HTMLDocument;
05
06 HTMLDocument webmain() {
07 doc = HTMLDocument::new(HTML4Strict,"Meine Internetseite");
08 h1 = addHeading(doc.body,1,"Dies ist eine Überschrift erster Ordnung");
09 p = addParagraph(doc.body,"Und dies ein");
10 emphasise = appendInlineElement(p,StrongEmphasis,"fettgedruckter");
11 addString(p,"Absatz!");
12 return doc;
13 }
|
Bei einer Browseranfrage ruft der Webserver zunächst das kleine Kaya-Programm auf. Es startet die Funktion »webmain()«, welche das gewohnte »main()« ersetzt. Sie erstellt ein neues HTML-Dokument (»doc = HTMLDocument…«) mit dem Titel »Meine Internetseite«, dessen Rumpf eine Überschrift (»addHeadding()«) enthält, der wiederum ein Absatz folgt (»addParagraph()«). Das so zusammengesetzte HTML-Dokument gibt das Kaya-Programm an den Webserver zurück (»return doc«).
Wie das Beispiel zeigt, verwenden Webanwendungen hauptsächlich zwei Datentypen. Einmal ist dies »HTMLDocument«, das eine komplette HTML-Seite einschließlich der passenden HTTP-Header-Informationen repräsentiert. Der zweite Datentyp »ElementTree« kapselt die einzelnen HTML-Tags mit ihren jeweiligen Inhalten, also beispielsweise »<p>Absatz</p>«. Ein komplettes HTML-Dokument besteht nun aus einem oder mehreren verschachtelten »ElementTree«, analog zur DOM-Repräsentation des Dokuments.
Baukasten
Über entsprechende Funktionen lässt sich diese Baumstruktur aufbauen und manipulieren. Listing 9 hängt beispielsweise via »appendInlineElement()« das Element »<b>fettgedruckter</b>« in den zuvor definierten Absatz ein. Die restlichen mit »add« beginnenden Funktionen arbeiten analog. Dank dieser Arbeitsweise braucht sich niemand mehr mit den Tags auseinanderzusetzen, sie minimiert gleichzeitig Tippfehler. Sobald das Dokument steht, iteriert Kaya über den fertigen Baum und gibt ihn an den Webserver zurück.
Alle Funktionen aus Listing 9 übernehmen einen String, den sie dann in ein passendes »ElementTree« packen. Wenn dieser String HTML-Befehle enthält, wandelt ihn Kaya automatisch in reinen Text um. Ein »<p>Absatz</p>« würde folglich später genau so im Klartext auf der Seite erscheinen. Auf diese Weise vermindert Kaya das Risiko von Cross-Site-Scripting-Angriffen.
Wer mehr Kontrolle über seine Webanwendung möchte, kann das so genannte CGI-Modell heranziehen. Im Gegensatz zu der hier beschriebenen Webapp-Variante ist es aber auf Low-Level-CGI-Programmierung ausgelegt. Der Kaya-Programmierer muss sich folglich um alles selbst kümmern, einschließlich des korrekten Aufbaus der HTML-Dokumente. Ein Beispiel hierfür zeigt das Listing 10 in Anlehnung an [5].
|
Listing 10: |
|---|
01 cgi helloweb;
02
03 import CGI;
04
05 Void PreContent() {
06 content("<html><head><title>Meine Internetseite</title></head><body>");
07 }
08
09 Void Default() {
10 content("Hier folgt der Inhalt der Seite");
11 }
12
13 Void PostContent() {
14 content("</body></html>");
15 }
|
Interaktion
Die Interaktion mit den Benutzern der Seite geschieht über so genannte Handler. C-Programmierer kennen dieses Konzept als Callback-Funktionen. Listing 11 zeigt dies an einem kleinen Beispiel, das zwei Zahlen addiert (Abbildung 1). »BaueFormular« konstruiert zunächst wieder ein HTML-Dokument. Es besteht aus einem Formular, in das der Benutzer zwei Zahlen eingibt. Die Eingabefelder erhalten die internen Namen »erstezahl« und »zweitezahl«. Sie ebnen den Weg zum Inhalt des jeweiligen Feldes.
|
Listing 11: Interaktion mit der |
|---|
01 webapp additionsbeispiel;
02
03 import Webapp;
04 import HTMLDocument;
05
06 ElementTree BaueFormular() {
07 formular = addLocalForm(anonymousBlock);
08 felder = addFieldset(formular,"Addition von zwei Zahlen");
09 eingabefeld1 = addLabelledInput(felder, "Erste Zahl:", InputText, "erstezahl", "", 3);
10 eingabefeld2 = addLabelledInput(felder, "Zweite Zahl:", InputText, "zweitezahl", "", 3);
11 submit = addLocalControlInput(felder,"Addiere!",OnAddiere,"Addition");
12 return formular;
13 }
14
15 HTMLDocument webmain() {
16 doc = new(HTML4Strict, "Additionsbeispiel");
17
18 result = runHandler(@BaueFormular);
19 appendExisting(doc.body,result);
20
21 return doc;
22 }
23
24 ElementTree OnAddiere(String message) {
25 if (incomingExists("erstezahl",DataPost) &&
26 incomingExists("zweitezahl",DataPost)) {
27 ergebnis= Int(incomingValue("erstezahl",DataPost)) + Int(incomingValue("zweitezahl",DataPost));
28 return addParagraph(anonymousBlock,"Ergebnis:"+String(ergebnis));
29 } else {
30 return addParagraph(anonymousBlock, "Ein Fehler ist aufgetreten");
31 }
32 }
|
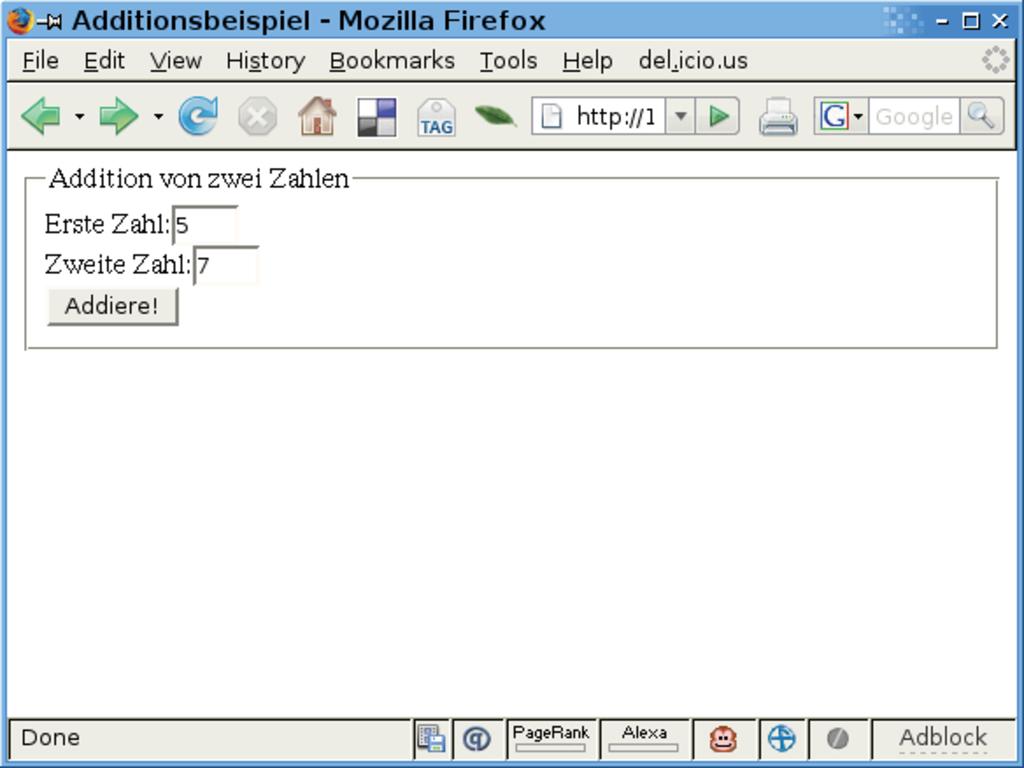
Abbildung 1: Das Kaya-Skript aus Listing 11 ist verantwortlich für die Darstellung des hier abgebildeten Formulars, führt aber auch selbst die Berechnung durch.
Die Funktion »addLocalControlInput()« in Zeile 11 packt noch eine Schaltfläche mit der Beschriftung »Addiere!« dazu. Sobald der Benutzer sie anklickt, werden die Daten aus dem Formular verpackt und an das Kaya-Skript zurückgeschickt. Dort – wie in »addLocalControlInput()« vorgegeben – wird die Routine »OnHello()« aufgerufen. Innerhalb von »webmain()« übernimmt die Funktion »runHandler()« das Eventmanagement und sorgt dafür, dass »OnHello()« in der richtigen Situation aktiv ist.
Praktischerweise landen alle übersandten Werte aus dem Formular automatisch in der globalen Variablen »DataPost«, aus der sie der Webentwickler nur noch herauslösen muss (genau genommen enthält »DataPost« alle per HTTP-POST-Request übermittelten Daten).
Die Funktion »OnAddiere()« prüft in den Zeilen 25 und 26 zunächst via »incomingExists()«, ob in diesen Antwortdaten auch die Eingaben aus den Feldern »erstezahl« und »zweitezahl« vorhanden sind. Wenn dies der Fall ist, extrahiert sie die zugehörigen Inhalte per »incomingValue()«, addiert sie und liefert das Ergebnis an den Browser zurück, der es wiederum anzeigt.
Während des gesamten Ablaufs stellt die symmetrische Verschlüsselung nach dem AES-256-Algorithmus sicher, dass ein Angreifer keine modifizierten Eingaben senden und somit auch keine andere Handler-Funktion aufrufen kann.
Noch nen Keks?
Die bisher vorgestellten Kaya-Skripte konnten sich nicht merken, von wem sie welche Daten erhalten haben. Für diesen Zweck müssen Cookies herhalten. Die Technik erlaubt es, unter einem bestimmten Schlüssel einen Wert dauerhaft im Browser abzulegen. Ein neues Cookie erstellt der Kaya-Webprogrammierer per:
cookie = setCookie(schluessel, wert); addHTTPHeader(doc,cookie);
Mit der nächsten Anfrage des Browsers sendet dieser seine Cookies wieder zurück. Im Kaya-Skript stehen sie dann in der globalen Variablen »DataCookie« bereit, die sie mit »incomingValue(schluessel, DataCookie)« ausliest.
Schattenseiten
Wer jetzt begeistert in Richtung Kaya-Homepage surft, sollte bedenken, dass sich die Skriptsprache noch in der Entwicklung befindet. Drastische Änderungen an Syntax und Semantik waren in der Vergangenheit keine Seltenheit. Vor dem Umstieg auf eine neue Kaya-Version sollten Interessenten das Changelog gründlich lesen. Die Kaya-Entwickler spendieren diesem Vorhaben sogar eine eigene Seite mit wertvollen Upgrade-Hinweisen unter [6].
Ein weiteres Problem betrifft ausgerechnet die Sicherheit. Jedes Kaya-Programm enthält einen internen, geheimen Anwendungsschlüssel. Den erzeugt es automatisch während des Kompilierens und zieht ihn dann bei allen Verschlüsselungsvorgängen heran. Leider kann ein Angreifer ihn mit geringem Aufwand aus dem binären Programm herausziehen und damit jede beliebige Funktion aufrufen.
Warum der Schlüssel nicht durch entsprechende weitere Maßnahmen geschützt ist, wissen wohl nur die Kaya-Entwickler. Für den Programmierer bleibt immerhin das mitgelieferte Werkzeug »rekey«. Sobald er den Verdacht auf eine Manipulation hegt oder ein fremdes Kaya-Programm verwenden möchte, sollte er mit »rekey« für das kompilierte Skript am besten einen neuen geheimen Schlüssel erzeugen.
Esoterisch, aber funktional
Kaya bietet eine interessante Mischung aus funktionaler und imperativer Skriptsprache. Selbst komplexe Datentypen sind in nur wenigen Codezeilen deklariert. Diese Kürze erkauft sich Kaya jedoch mit teilweise schwer lesbarem Code. Gerade Umsteiger von objektorientierten Sprachen werden daran eine Weile zu knabbern haben. Dafür lockt Kaya schon jetzt mit einem Funktionsumfang, den woanders nur zusätzliche Bibliotheken eröffnen.
Seine Praxistauglichkeit muss die Sprache allerdings erst noch unter Beweis stellen. Derzeit gibt es nur wenige Anwendungen, in denen Kaya zum Einsatz kommt. Neben zwei Projekten für die Datenauswertung ist dies laut Projektseite der Skriptsprache gerade einmal ein in Kaya geschriebener Generator für Web-Fotoalben. (ofr)
|
Infos |
|---|
|
[1] Kaya: [http://kayalang.org] [2] Glasgow Haskell Compiler: [http://www.haskell.org/ghc] [3] Happy Parser Generator: [http://www.haskell.org/happy] [4] API-Referenz der Bibliotheken: [http://kayalang.org/library] [5] Einführung in Kaya: [http://kayalang.org/tutorial] [6] Upgrade-Hinweise: [http://kayalang.org/download/upgrading] |
|
Der Autor |
|---|
|
Tim Schürmann ist selbstständiger Diplom-Informatiker und derzeit als freier Autor unterwegs. Zu seinen Büchern gesellen sich zahlreiche Artikel, die in Zeitschriften und auf Internetseiten in mehreren Ländern veröffentlicht werden. |





