
© Stock.Xchng
Two-Phase-Commits öffnen die Tür für verteilte Datenbanken: Nur nach einstimmiger Abstimmung geben sie Transaktionen ihr Okay. Der Bitmap-Scan beschleunigt Anfragen nach Werten aus mehreren Spalten. Das sind nur zwei Beispiele für viele Verbesserungen in der neuen PostgreSQL-Version 8.1.
Das Schrittmaß normalisiert sich wieder: Nach dem Sprung von Versionsnummer 7.4 auf 8.0 [1] zu Beginn des Jahres, folgt nun die Release 8.1. [2]. Wer darin allerdings nur Bugfixes erwartet, der täuscht sich: Auch diesmal haben die PostgreSQL-Entwickler wieder etliche neue und interessante Features implementiert.
Ein Server, eine Stimme
Eine der Neuerungen ist der so genannte Two-Phase-Commit, der für Anwendungen interessant ist, die auf mehrere, voneinander getrennte Datenbanken zugreifen. Ohne besondere Vorkehrungen ist es in dieser Situation so gut wie unmöglich, dafür zu garantieren, dass alle beteiligten Datenbanken zu einem bestimmten Zeitpunkt eine bestimmte Transaktion erfolgreich abgeschlossen haben. Das Two-Phase-Commit-Protokoll löst dieses Problem, indem es in einer ersten Phase alle Datenbanken befragt, ob sie erfolgreich committen könnten. Nur bei positiver Rückmeldung aller Teilnehmer führt es den Commit in der zweiten Phase tatsächlich aus.
Die Anweisung »BEGIN TRANSACTION« leitet dabei zunächst wie üblich die Transaktion ein. Nachdem die Datenbank die zugehörigen Befehle abgearbeitet hat, bereitet der Befehl »PREPARE TRANSACTION« die Transaktion für den Two-Phase-Commit vor. Danach kann der Datenbankbenutzer nichts mehr ändern. Die Anwendung präpariert jetzt nacheinander die Transaktionen auf allen beteiligten Datenbanken. Signalisieren alle eine erfolgreiche Vorbereitung, kann die Applikation die Transaktion endgültig abschließen. Der Befehl dafür lautet »COMMIT PREPARED«.
Meldet eine der Datenbanken hingegen einen Fehler und kann die Transaktion deshalb nicht erfolgreich vorbereiten, wird sie auf allen Datenbanken zurückgenommen und die bereits vorbereitete Transaktion abgebrochen (via »ROLLBACK PREPARED«).
Interessant ist ein Implementierungsdetail: PostgreSQL speichert die Daten einer vorbereiteten Transaktion im Verzeichnis »pg_twophase«. Dadurch löst sich eine einmal vorbereitete Transaktion von der aktuellen Sitzung. So kann auch eine andere Sitzung die Kommandos »COMMIT PREPARED« oder »ROLLBACK PREPARED« einleiten, selbst ein zwischenzeitlicher Neustart des Datenbankservers stört nicht.
Um vorbereitete Transaktionen eindeutig identifizieren zu können, erhalten sie einen Namen. Das Listing 1 demonstriert das Vorbereiten und Zurücknehmen einer Transaktion in einer verteilten Datenbankanwendung.
|
Listing 1: Vorbereitete |
|---|
01 db=# BEGIN TRANSACTION; 02 BEGIN 03 db# INSERT INTO test (a,b) VALUES (1,2); 04 INSERT 0 1 05 db# PREPARE TRANSACTION 'mytrans'; 06 PREPARE TRANSACTION 07 db# SELECT * FROM pg_prepared_xacts; 08 transaction | gid | prepared | owner | database 09 -------------+---------+-------------------------------+-------+----------- 10 577 | mytrans | 2005-09-20 21:28:08.805017+02 | joe | db 11 (1 Zeile) 12 13 # vorbereitete Transaktion zurückrollen 14 db=# ROLLBACK PREPARED 'mytrans'; 15 ROLLBACK PREPARED 16 17 # vorbereitete Transaktion committen 18 db=# COMMIT PREPARED 'mytrans'; 19 COMMIT PREPARED |
Sperren vermeiden
Der Anwendungsprogrammierer sollte allerdings Transaktionen nicht länger als nötig im Prepared-Zustand halten. Das Datenbanksystem muss für die vorbereiteten Transaktionen Sperren einrichten, um die Konsistenz der Daten zu gewährleisten. Beispielsweise könnte in einer vorbereiteten Transaktion eine Insert-Anweisung enthalten sein, die Daten in eine Spalte einfügt, auf der ein Unique-Constraint definiert ist.
Möchte eine andere Transaktion den gleichen Wert einfügen, wird PostgreSQL diese Transaktion so lange blockieren, bis die vorbereitete konkurrierende Transaktion entweder endgültig committet oder aber zurückgerollt ist. Zu lange gehaltene Sperren behindern außerdem den Vacuum-Befehl und die Ausführung anderer Wartungsarbeiten.
Außerdem empfiehlt es sich bei Verwendung dieser Art von Transaktionen, den Parameter »max_prepared_transactions« anzupassen. Um Ressourcen einzusparen, erlaubt PostgreSQL in der Standard-einstellung nämlich nur wenige vorbereitete Transaktionen.
Eine Rolle für Benutzer oder Gruppe
Die Version 8.1 führt ein neues Rollensystem ein. Es verallgemeinert das bisherige System von Benutzern und Gruppen und bietet sowohl neue Möglichkeiten zum Verwalten der Zugriffsprivilegien wie auch größere Konformität mit dem SQL-Standard. Eine Rolle kann in diesem Konzept sowohl einen Benutzer als auch eine Gruppe repräsentieren. Die Eigenschaften der Rolle bestimmen die Zugriffsrechte. Dabei dürfen Rollen in anderen Rollen enthalten sein, wodurch Hierarchien entstehen.
Der Datenbankbenutzer erstellt eine Rolle durch das SQL-Kommando »CREATE ROLE« gefolgt vom Namen der Rolle und den gewünschten Berechtigungen, zum Beispiel »CREATE ROLE john WITH CREATEDB CREATEROLE LOGIN ENCRYPTED PASSWORD ‘geheim’;«. Der Befehl erzeugt die Rolle »john«, die neue Datenbanken anlegen und selbst neue Rollen erstellen darf. Das Recht, sich am Datenbanksystem anzumelden, macht die Rolle zu einem Benutzer in herkömmlicher Betrachtungsweise. Der Befehl »CREATE USER«, der aus Kompatibilitätsgründen nach wie vor zu finden ist, entspricht einem »CREATE ROLE«-Befehl mit einem automatisch vergebenen Login-Privileg.
In Tabelle 1 findet sich eine Übersicht der Eigenschaften, die auf »CREATE ROLE« folgen können. Eine Eigenschaft, die der Benutzer in der »CREATE ROLE«-Anweisung nicht explizit aufführt, vergibt PostgreSQL in der Regel auch nicht.
|
Tabelle 1: |
|
|---|---|
|
Option |
Bedeutung |
|
SUPERUSER/NOSUPERUSER |
Legt fest, ob die neue Rolle Superuser ist |
|
CREATEDB/NOCREATEDB |
Legt fest, ob die neue Rolle Datenbanken anlegen darf oder |
|
CREATEROLE/NOCREATEROLE |
Legt fest, ob die neue Rolle selbst weitere Rollen anlegen |
|
INHERIT/NOINHERIT |
Legt fest, ob vererbte Zugriffsrechte automatisch aktiviert |
|
LOGIN/NOLOGIN |
Legt fest, ob sich die Rolle einloggen darf |
|
[ENCRYPTED/UNENCRYPED] |
Passwort (nur sinnvoll bei ebenfalls erteilter |
|
VALID UNTIL ‘…’ |
Verfallsdatum des Zugriffs |
|
IN ROLE Rollenname |
Die neue Rolle wird zu einer Unterrolle der angegebenen |
|
ROLE Rollenname |
Die Umkehrung der vorherigen Option, die neue Rolle wird |
|
ADMIN Rollenname |
Die angegebene Rolle darf Mitglieder in die neue Rolle |
Angenommen der zuvor angelegte Benutzer »john« möchte eine weitere Datenbank »technik« anlegen und zwei Mitglieder in eine neue Gruppe aufnehmen. Dann müsste er dazu folgende Befehle ausführen:
CREATE ROLE technik WITH ADMIN john; CREATE ROLE jane WITH IN ROLE technik LOGIN ENCRYPTED PASSWORD 'geheim1 '; CREATE ROLE tarzan WITH IN ROLE technik LOGIN ENCRYPTED PASSWORD 'geheim2 ' VALID UNTIL '2006-06-30';
Anschließend kann »john« die erforderlichen Datenbankobjekte anlegen und der Rolle »technik« Zugriff darauf gewähren. Dadurch erhalten die Rollen »jane« und »tarzan« ebenfalls Zugriff.
Da »jane« eine Spezialisierung der Rolle »technik« ist, kann sie mittels »SET ROLE technik« bei Bedarf auch in die übergeordnete Rolle schlüpfen. Sie kann jedoch nicht »SET ROLE tarzan« ausführen. Darüber hinaus kann der Anwender die Rollen »jane« und »tarzan« auch als Gruppen verwenden und ihnen weitere Mitglieder hinzufügen.
Das Rollensystem erlaubt also eine sehr flexible Gestaltung der Zugriffsrechte. Man muss sich jedoch im Klaren darüber sein, wer welche Berechtigungen erhalten soll, und sich Gedanken über die Hierarchie und Vererbung von Zugriffsrechten machen. Eine schematische Darstellung der Abhängigkeiten auf einem Blatt Papier hilft dabei.
Geschwindigkeit
Version 8.1 enthält auch eine ganze Reihe Performance-Verbesserungen. PostgreSQL verwendet im Gegensatz zu einigen anderen Datenbankmanagementsystemen nicht das Thread-, sondern das Prozessmodell. Bei gleichzeitigen Datenbankzugriffen, insbesondere auf Multiprozessorsystemen, startet es mehrere Backend-Prozesse, die dann über Shared Memory kommunizieren.
Einen großen Teil macht hierbei der so genannte Buffer Cache aus, der oft benutzte Datenbankbereiche für den schnelleren Zugriff im RAM hält. In der Version 8.1 haben die PostgreSQL-Entwickler nun die Koordination des Zugriffs mehrerer Backend-Prozesse auf diesen Shared-Memory-Bereich weiter optimiert. Hiervon sollten vor allem Datenbankserver auf Multiprozessormaschinen profitieren.
Eine sehr interessante Entwicklung hinter den Kulissen der Datenbank ist die Fähigkeit der Version 8.1, mehrere Indizes im Speicher zu kombinieren und so flexibler mit ihnen umzugehen. Zuvor hatte PostgreSQL das Problem, bei einer Anfrage des Typs »WHERE spalte1 = 12 AND spalte2 = 4« nur einen Index verwenden zu können. Im Idealfall war dieser mehrspaltig auf »(spalte1, spalte2)« definiert.
Gab es hingegen zwei getrennte Indizes für Spalte 1 und Spalte 2, konnte PostgreSQL nur einen von beiden benutzen. Jetzt berücksichtigt es beide Indizes und kombiniert die Ergebnisse im Speicher. Das ist insbesondere dann vorteilhaft, wenn eine Anwendung Anfragen automatisch erstellt und es unmöglich ist, alle denkbaren Kombinationen mehrspaltiger Indizes vorher zu erstellen.
Bitmaps zur Beschleunigung
Dieses Verfahren heißt Bitmap-Scan, der Begriff illustriert zugleich die interne Implementierung. Für einen Indexscan erzeugt PostgreSQL im Speicher eine Bitmap. Die neue Version markiert darin für eine einzelne Where-Klausel (zum Beispiel »spalte1 = 4«) jede Tabellenzeile entweder mit einer »1« oder einer »0«, je nachdem, ob die Tabellenzeile die Where-Klausel erfüllt oder nicht. Anschließend führt PostgreSQL auf den erstellten Bitmaps die logischen Operationen durch, die die Anfrage vorgibt, also ein logisches »AND« oder »OR«. Daraus ergibt sich dann eine »1« oder »0« für die entsprechende Kombination der Where-Klauseln pro Tabellenzeile.
Das Verfahren kann bereits bei einem einzelnen Index von Vorteil sein. Lautet die Anfrage beispielsweise »… WHERE a = 4 AND (a = 2 OR a = 7)« und es existiert ein Index auf der Spalte A, wird PostgreSQL hier ebenfalls drei Bitmaps erzeugen, daraufhin dreimal den Index über A konsultieren und die Ergebnisse im Speicher kombinieren. Frühere Versionen verwendeten den Index über der Spalte A hier nur einmal.
Das Beispiel in Tabelle 2 illustriert eine Abfrage mit der Klausel »WHERE (x=5 OR x=3) AND (y=4)«, die mit dem Bitmap-Scan-Verfahren bearbeitet wird. Hier kommen schließlich nur die Zeilen 3 und 5 für das Ergebnis in Frage.
|
Tabelle 2: Beispiel |
||||
|---|---|---|---|---|
|
Zeile |
x = 5 |
x = 3 |
y = 4 |
Ergebnis |
|
1 |
0 [ ( 0 OR 0 ) AND 0 ] |
|||
|
2 |
1 |
0 [ ( 1 OR 0 ) AND 0 ] |
||
|
3 |
1 |
1 |
1 [ ( 0 OR 1 ) AND 1 ] |
|
|
4 |
1 |
0 [ ( 1 OR 0 ) AND 0 ] |
||
|
5 |
1 |
1 |
1 [ ( 1 OR 0 ) AND 1 ] |
|
Vom Kleinsten und Größten
Für die Aggregatfunktionen »MIN()« und »MAX()« lässt sich ab sofort ein Index verwenden, was die Performance deutlich steigert. Dieses Feature wurde immer wieder auf der Mailingliste gefordert. Bislang musste PostgreSQL hierfür stets einen sequenziellen Scan über die komplette Tabelle durchführen. Obwohl es theoretisch ein Leichtes ist, den kleinsten oder größten Wert aus einem B-Tree-Index herauszulesen, konnte PostgreSQL dies aus internen Gründen bisher nicht leisten.
Alle Aggregatfunktionen sind, wie in PostgreSQL üblich, vom Benutzer definierbare Objekte, wobei jene für die eingebauten Datentypen natürlich vorgegeben sind. Ihre Definition enthält lediglich eine einfache Funktion, die für jede Zeile die Werte zusammenzählt oder vergleicht. Auf diese Weise lassen sich alle Aggregatfunktionen wie »MIN«, »MAX«, »SUM« und »COUNT« definieren. Die Indexunterstützung ist in diesem System aber nicht vorgesehen und von der Implementierung von hartkodierten Ausnahmefällen für »MIN« und »MAX« sah man bewusst ab.
Der einfache Workaround für ein »SELECT MAX(id) FROM …« bestand darin, die Anfrage zu »SELECT id FROM … ORDER BY id DESC LIMIT 1« umzuschreiben. Intern nimmt PostgreSQL genau diese Transformation künftig automatisch vor, sodass »MIN()« und »MAX()« ab jetzt immer einen Index verwenden können, sofern einer existiert. Das lässt sich auch mit Hilfe des Befehls »EXPLAIN« beobachten. Bisher sah ein Anfrageplan in etwa so aus wie Listing 2. Ab PostgreSQL 8.1 können aber auch Anfragepläne vorkommen, wie sie Listing 3 zeigt. Wie immer wird auch hier der Planer alle möglichen Fälle durchtesten und den günstigsten verwenden.
|
Listing 2: »Max()« |
|---|
01 =# EXPLAIN SELECT max(id) FROM test; 02 QUERY PLAN 03 ----------------------------------------- 04 Aggregate (cost=1691.00..1691.01 rows=1 width=4) 05 -> Seq Scan on test (cost=0.00..1441.00 rows=100000 width=4) |
|
Listing 3: »Max()« |
|---|
01 =# EXPLAIN SELECT max(id) FROM test; 02 QUERY PLAN 03 ----------------------------------------- 04 Result (cost=0.02..0.03 rows=1 width=0) 05 InitPlan 06 -> Limit (cost=0.00..0.02 rows=1 width=4) 07 -> Index Scan Backward using test_ix on test (cost=0.00..1762.00 rows=100000 width=4) 08 Filter: (id IS NOT NULL) |
Aufgeräumt
PostgreSQL-Anwender mussten bisher regelmäßig staubsaugen, sprich den »VACUUM«-Prozess starten, der den durch »UPDATE«- und »DELETE«-Operationen angefallenen Datenmüll entfernte. Wer dies vergaß, hatte bald keinen Platz mehr auf der Festplatte. Stapelte sich der Müll gar so hoch, dass die Transaktionsnummern die 32-Bit-Grenze überschritten, waren die Daten futsch.
Bereits in Version 7.4 gab es im Contrib-Bereich ein Programm namens »pg_autovacuum«, das versucht, die »VACUUM«-Läufe automatisch anzusetzen, indem es den Füllgrad der Tabellen und die laufenden Transaktionsnummern überwacht. Diese Funktion ist jetzt direkt in den Server eingebaut, der sich dadurch erheblich einfacher warten lässt. Um vorhandene Konfigurationen nicht zu stören, ist der Autovacuum-Prozess in der Voreinstellung ausgeschaltet, lässt sich aber mit einer einfachen Einstellung in der Konfigurationsdatei »postgresql.conf« aktivieren.
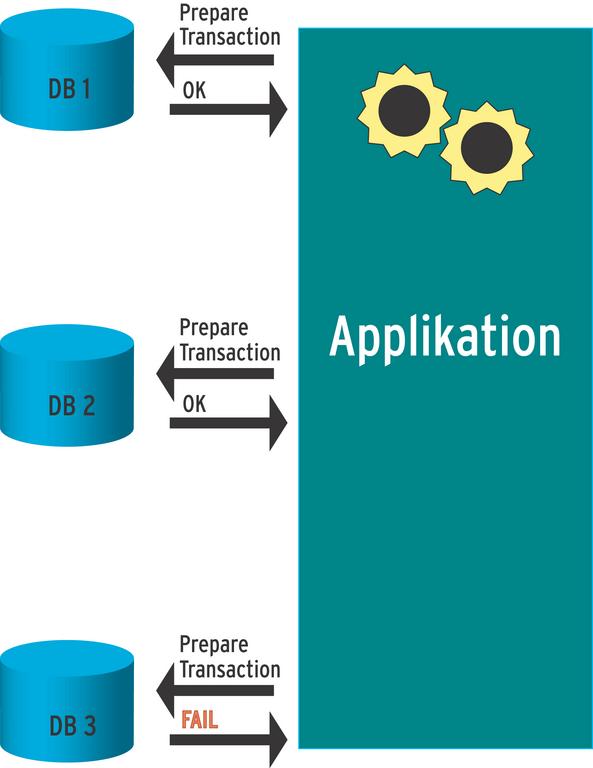
Abbildung 1: Eine Applikation muss eine Transaktion auf allen Datenbanken zurückrollen, falls eine der Datenbanken beim Vorbereiten einen Fehler liefert.
Rein und raus
Neuerungen finden sich auch in der prozeduralen Sprache PL/PgSQL. Augenfällig ist hier vor allem die geänderte Syntax für die Variablenübergabe. Mit so genannten »OUT«-Parametern ist es nun sehr einfach möglich, mehrere Variablen zurückzugeben, ohne hierfür eine Variable des Typs Record verwenden zu müssen. Dies wird besonders Umsteiger von der durch Oracle bekannten Sprache PL/SQL freuen. Ein einfaches Beispiel:
CREATE FUNCTION multiples(v int, OUT m2 int, OUT m3 int, OUT m4 int) AS $$ BEGIN m2 = v * 2; m3 = v * 3; m4 = v * 4; END; $$ LANGUAGE plpgsql;
liefert:
db=# SELECT * FROM multiples(5); m2 | m3 | m4 ----+----+---- 10 | 15 | 20 (1 Zeile)
Wer die Funktion »multiples()« aufruft und ihr nur einen Wert übergibt, erhält eine Tabelle mit drei Spalten zurück. In der Funktionsdeklaration ist zu sehen, dass es nur eine Variable gibt, die nicht mit dem Schlüsselwort »OUT« deklariert wurde – dies ist der übergebene Wert. Die mit »OUT« deklarierten Variablen sind die Rückgabevariablen. Jede repräsentiert eine Spalte der Ergebnistabelle.
Auch an der Integration der Sprache PL/Perl haben die Entwickler gearbeitet. Das fällt manchem Anwender schon beim Definieren einer PL/Perl-Funktion auf, denn die neue Version führt jetzt dabei einen Syntaxcheck durch. Ein weiteres Ziel der Arbeit an PL/Perl ist es, Objekte und Methoden der Sprache Perl auf die entsprechenden Äquivalente der Datenbank abzubilden. Die Version 8.1 unterstützt etwa die Abbildung von Perl-Warnmeldungen auf PostgreSQL-Warnungen. Ebenso ist es für eine PL/Perl-Funktion nun möglich, ein Array zurückzuliefern, das sich in ein Resultset verwandelt. (jcb)
|
Infos |
|---|
|
[1] PostgreSQL 8.0: [https://www.linux-magazin.de/Artikel/ausgabe/2005/03/postgres8/postgresql8.html] [2] PostgreSQL-Homepage: [http://www.postgresql.org/] |
Copyright © 2002 Linux New Media AG





