
Sobald eine Anwendung parallele Prozesse oder Threads einsetzt, ist deren Synchronisation unerlässlich. Der Kernel 2.6 stellt neben den etablierten Spinlocks und Sys-V-Semaphoren mit den Fast Userspace Mutexes einen neuen, oftmals besonders effizienten Ansatz bereit.
Moderne Anwendungen wie Apache, Oracle und SAP R/3 erzeugen mehrere Prozesse oder Threads, um Anfragen performanter abzuarbeiten. Die Prozesse konkurrieren dann allerdings um die dieselben Ressourcen, primär um gemeinsame Speicherbereiche [1]. Ohne eine Synchronisation führen solche Konkurrenzsituationen über kurz oder lang zu fehlerhaften Ergebnissen bis hin zum Absturz der Anwendung. Dieser Artikel beschreibt neben zwei gängigen Synchronisationsverfahren – Spinlocks und Sys-V-Semaphoren – auch eine Form, die mit dem Kernel 2.6 Einzug gehalten hat: die Fast Userspace Mutexes, kurz Futexe [2].
Das sehr einfache Beispiel einer gemeinsamen genutzten Variablen soll demonstrieren, welche Probleme ein unkontrollierter, nicht synchronisierter Zugriff mit sich bringt. Listing 1 zeigt einen, aus didaktischen Gründen vereinfachten Ausschnitt aus einer Multithreaded-Anwendung. Es nimmt an, dass zwei Threads A und B die Funktion »func()« ausführen. Der Wert der Variablen »glob« sei initial 0.
Beide Threads dürfen »glob« beschreiben. Ein typischer Zugriff verläuft so: Thread A hat gerade den Wert 0 der Variablen »glob« in ein Register gelesen, um ihn um 1 zu erhöhen. Wenn just zu diesem Zeitpunkt der Kernel Thread A unterbricht und Thread B zum Zuge kommen lässt, wird B ebenfalls den Wert 0 in ein Register schreiben. Anschließend schreibt er den um 1 erhöhten Wert, also eine 1, zurück in den Speicher an den Ort der Variablen »glob«. Wenn Thread A seine Arbeit wieder aufnimmt, findet er noch immer den Wert 0 im Register und schreibt demgemäß eine 1 zurück. Der Wert der Variablen »glob« ist also 1.
Ein Wettlauf ums Ergebnis ist nicht akzeptabel
Das entspricht nicht dem intuitiven Eindruck des Code aus Listing 1, der eine 2 als Ergebnis erwarten lässt. Viel schlimmer aber ist, dass das Endergebnis vom zeitlichen Verlauf abhängt: Wäre die Unterbrechung des Thread A durch den Thread B zu einem anderen Zeitpunkt erfolgt, hätte »glob« andere Werte, hier beispielsweise 2, angenommen. Situationen wie diese, bei denen das Ergebnis von zeitlichen Abläufen abhängt, werden allgemein als Race Condition bezeichnet, siehe [1] und [3].
Kritische Bereiche als Sperre errichten
Szenarien wie das hier konstruierte sind aus zwei Gründen problematisch: Zum einen decken sich die erzielten Ergebnisse nicht mit den erwarteten. Dabei entstehen oft Sondersituationen, die der Code nicht abfängt und die zu Fehlern führen. Zum anderen treten solche Fehler nicht reproduzierbar auf, sondern hängen nach menschlichen Maßstäben vom puren Zufall ab und sind damit sehr schwer einzugrenzen.
Das gezeigte Beispiel sollte nicht zu der Annahme verleiten, dass nur Threads für diese Effekte anfällig sind. Auch bei Anwendungen aus mehreren Prozessen treten solche Fehler auf, da auch sie Variablen gemeinsam nutzen – und zwar keine globale Variablen, sondern als Shared Memory [4]. Um diesem Problem zu begegnen, versucht man meist den Zugriff eines Thread oder Prozesses auf einen gemeinsam genutzten Speicherbereich ununterbrochen zu gestalten. Anders ausgedrückt: Es gibt Stellen im Code, die nur ein Prozess oder Thread zugleich durchlaufen darf, so genannte kritische Bereiche oder Pfade [1].
Entwickler realisieren solche kritischen Bereiche gern durch Sperren. Haben sie eine Sperre gesetzt, kann kein weiterer Prozess oder Thread in den kritischen Bereich eintreten. Es entsteht ein wechselseitiger Ausschluss: Mutual Exclusion (Mutex). Den Versuch, eine Sperre respektive einen Mutex zu implementieren, zeigt das ebenso einfache wie falsche Beispiel in Listing 2.
Auf den ersten Blick scheint der Ablauf klar zu sein: Findet ein Thread die globale Sperrvariable »sperre« gesetzt vor, geht er in eine Endlosschleife, bis die Sperrung wieder aufgehoben ist, das heißt bis »sperre« den Wert »UNLOCKED« erhält. Er setzt dann seinerseits die Sperre und tritt in den kritischen Bereich ein. Nach Beendigung der Arbeit gibt er die Sperre mit »sperre = UNLOCKED« wieder frei.
Dummerweise krankt dieser Ansatz prinzipbedingt an dem gleichen Problem wie der Zugriff auf »glob« in Listing 1. Eine Unterbrechung nach dem Prüfen des Wertes von »sperre« in der »while«-Bedingung und vor dem erneuten Setzen »sperre = LOCKED« kann dazu führen, dass mehrere Prozesse in den kritischen Bereich hineingelangen.
Halbe Miete: Die richtigen Fragen stellen
Trotz seines fehlerhaften Verhaltens hilft der eben beschriebene Ansatz die funktionstüchtigen Synchronisationsformen zu verstehen, indem er zwei Aspekte ins Blickfeld rückt:
- Welche Schritte muss der Prozess oder Thread durchlaufen, der
die Sperre erhält? Die Frage ist insbesondere, ob er das
Betriebssystem kontaktieren muss, um in den Besitz der Sperre zu
kommen, oder ob er mit Mitteln des Userspace auskommt. - Welche Schritte durchläuft der Prozess oder Thread, der
die Sperre nicht erhält und gesperrt ist? Hier ist bedeutsam,
in welchem Zustand er sich während des Wartens befindet
– verbraucht er Prozessorzeit oder schläft er?
Die folgende Abschnitte beschreiben anhand dieser Kriterien die drei unter Linux wichtigsten Formen der Synchronisation auf Anwendungsebene.
Synchronisation mit Spinlocks
Spinlocks sind in mancher Hinsicht die einfachste Synchronisationsform. Sie setzt direkt bei Listing 2 an und dem dort beschriebenen Problem der möglichen Unterbrechung zwischen Prüfen und Setzen der Sperrvariablen. Wenn es gelingt, diese beiden Aktionen ununterbrechbar – oder atomar – zu machen, sollte auch das Beispiel aus Listing 2 eine korrekte Synchronisation gewährleisten.
In der Regel stellt die Hardware die Hilfsmittel, um das Testen und Setzen atomar abzuwickeln [1]. Fast alle Linux-fähigen Plattformen besitzen dafür geeignete Maschinenbefehle. Listing 3 zeigt eine etwas vereinfachte Spinlockform und benutzt der Einfachheit halber den Maschinenbefehl »tas« (für test and set) als Pseudocode. In der Praxis erfordert die Implementierung eines solchen Spinlock etwas mehr Aufwand, das heißt Assemblercode, als hier geschildert. Ein sehr schönes Beispiel für eine Implementierung für Intel x86 findet sich im Linux-Kernel selbst unter »include/asm-i386/spinlock.h«.
Für das Verständnis wichtiger als die Hardware-Seite ist die Bewertung der Spinlocks nach den oben genannten Kriterien. Deren Einsatz zum Errichten einer Sperre ist für den Sperrer kaum mit Aufwand verbunden. Die Funktion, die das atomare Verhalten der Anwendung zur Verfügung stellt, ist ohne Hilfe des Betriebssystems implementierbar. Die Sperre wird also nach wenigen Instruktionen sehr schnell zugeteilt.
Ähnlich schnell ist die Reaktion auf einen Wechsel: Springt die Sperre von »LOCKED« auf »UNLOCKED«, erfährt es der gesperrte Prozess oder Thread umgehend, da er kontinuierlich den Zustand der Sperre abfragt. Dieser Punkt führt zum zweiten Aspekt, der Frage nach dem Zustand des gesperrten selbst. Der Code aus Listing 3 verdeutlicht, dass er eine Schleife abarbeitet und damit Prozessorzeit verschwendet.
Die Abbildung 1 zeigt dieses Verhalten schematisch. Den kritischen Bereich, in der Mitte des Bildes dargestellt, schützt ein Spinlock. Prozess Nummer 1 erlangt durch eine Abfrage ohne Kernelunterstützung die Sperre. Prozess 2 hingegen muss auf die Freigabe des Spinlock warten und hängt so lange in einer Schleife. Auch für dieses Warten ist keine Aktion des Betriebssystemkerns nötig.
|
Listing 1: Unsynchronisierter |
|---|
01 int glob;
02
03 void func () {
04 glob = glob + 1;
05 }
|
|
Listing 2: Fehlerhafte |
|---|
01 sperre_t sperre;
02 int glob;
03 ...
04
05 void func() {
06 while (sperre == LOCKED) ;
07 sperre = LOCKED;
08 /* kritischer Bereich ? */
09 glob = glob + 1;
10 /* Ende kritischer Bereich */
11 sperre = UNLOCKED;
12 }
|
|
Listing 3: Spinlocks über |
|---|
01 sperre_t sperre;
02
03 void func() {
04 while (tas(&sperre)) ;
05 /* kritischer Bereich */
06 ...
07 /*Ende kritischer Bereich */
08 sperre = UNLOCKED;
|
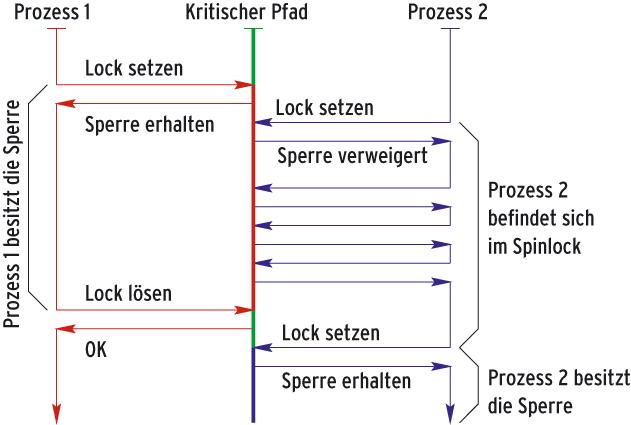
Abbildung 1: Mit einem Spinlock erlangt Prozess P 1 durch eine Abfrage die Sperre. Prozess P 2 hingegen muss auf die Freigabe des Spinlock warten und hängt so lange in einer Schleife.
Synchronisation mit Sys-V-Semaphoren
Komplexer wirkt die zweite gebräuchliche Form der Synchronisation unter Linux. Die so genannten System-V-Semaphore (Sys-V-Semaphore) bauen zwar auch auf der atomaren Ausführung einiger Operationen auf, gehen aber weiter als Spinlocks:
- Semaphore haben einen Zähler, der mehr als nur die Werte
»LOCKED« und »UNLOCKED« enthalten darf.
Damit können Semaphore auch komplexere Situationen abbilden,
in denen zwei oder mehr Akteure zeitgleich auf mehrere Ressourcen
zugreifen. - Semaphore verwalten die gesperrten Prozesse oder Threads in
einer Warteschlange. Gesperrte Prozesse oder Threads benötigen
folglich auch keine Prozessorzeit und lassen sich außerdem
gemeinsam wecken.
|
Listing 4: Sys-V-Semaphore |
|---|
01 int semid, key;
02 union semun {
03 int val;
04 struct semid_ds *buf;
05 unsigned short *array;
06 struct seminfo *__buf;
07 } semval;
08 ...
09
10 semval.val = 1;
11
12 if ((semid = semget(key, 1, 0666|IPC_CREAT)) == -1)
13 return errno;
14
15 if ( -1 == semctl(semid, 0, SETVAL, semval))
16 return errno;
|
Der Programmierer verwendet Sys-V-Semaphore über die Systemcalls »semget()« für den Zugriff auf einen Semaphor, »semctl()« zum Verwalten der Semaphore und »semop()« für die Ausführung der eigentlichen Sperroperationen [4]. Die Semaphor-Terminologie bezeichnet das Sperren als »WAIT« oder »DOWN«, weil es den Zähler erniedrigt und die Operation blockiert, sobald der Zähler einen Wert kleiner als null erreicht. Das Aufheben der Sperre ist als »SIGNAL« oder »UP« bekannt.
Typische Codeschnipsel beginnen mit dem Aufruf von »semget()«, was der Anwendung einen Semaphor zugänglich macht. Der Programmierer kann der Funktion den Initialen Wert des Semaphoren-Zählers mitgeben. Listing 4 erzeugt einen Semaphor und initialisiert ihn dann auf den Wert 1. Details der einzelnen Aufrufe vermittelt [5].
Die Variable »semid« dient in den weiteren Aufrufen zur Identifikation des Semaphors. So zeigt Listing 5 das Sperren des auf 1 initialisierten Semaphors und Listing 6 das Entsperren. Beide verwenden den Systemaufruf »semop()«, um den Wert des Semaphoren-Zählers zu verändern. Das wichtigste Argument dieses Aufrufs in beiden Listings ist die Angabe in Zeile 4, ob der Wert des Zählers erniedrigt oder erhöht wird.
Diese Codeschnipsel entsprechen also dem Setzen des Spinlock auf »LOCKED« beziehungsweise »UNLOCKED«. Sie zeigen, dass Sys-V-Semaphore zum einen etwas umständlicher in der Bedienung sind, zum anderen auch mehr Komfort mitbringen, da das Betriebssystem die Dienste bereitstellt. Zur Bewertung sind aber die beiden oben hervorgehobenen Aspekte interessant:
- Jeder Prozess oder Thread, der mit Sys-V-Semaphoren eine Sperre
setzen will, muss dies über Systemaufrufe tun. Auch der
Sperrer kommt nicht umhin in den Kernel abzutauchen. - Die gesperrten Prozesse oder Threads zeichnen sich nur dadurch
aus, dass sie – anders als der Sperrer – vorläufig
nicht aus dem Kernel auftauchen. Der Systemaufruf blockiert, die
Prozesse oder Threads liegen passiv in der Warteschlange. In diesem
Sinne sind Sys-V-Semaphore das genaue Gegenteil zu Spinlocks.
Dieser Eindruck erklärt sich bei der folgenden Behandlung der
Futexe.
Abbildung 2 zeigt analog zu Abbildung 1 dieses typische Verhalten der Semaphore. Sowohl der sperrende P 1 als auch der gesperrte P 2 müssen in den Kernelspace abtauchen, um mit Sys-V-Semaphoren zu arbeiten. Der Kernel selbst verwaltet die Warteschlange, die dem Semaphor zugeordnet ist.
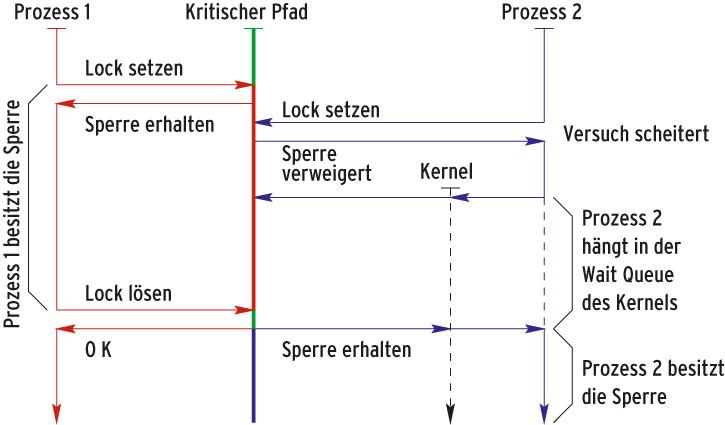
Abbildung 2: Um mit Sys-V-Semaphoren zu arbeiten, müssen sowohl der Sperrer P 1 als auch der gesperrte P 2 in den Kernelspace abtauchen. Dort befindet sich die dem Semaphor zugeordnete Warteschlange.
Fast Userspace Mutexe ab Kernel 2.6
Ab Kernel 2.6 kennt Linux einen dritten Ansatz, der sowohl direkt verwendbar ist als auch andere Mechanismen der Synchronisation realisieren kann. Die Implementation basiert auf den Fast Userspace Mutexes, die zuerst auf dem 2002er Ottawa Linux Symposium breitere Beachtung fanden [2]. Die Entwicklung lag bei Hubertus Franke, IBM, Rusty Russel, IBM und Matthew Kirkwood.
Die Grundidee dieses Ansatzes geht von einer der eben skizzierten Eigenschaften der Sys-V-Semaphore aus. Der eigentlich schnell abzuhandelnde Fall, in dem die Sperre nicht gesetzt ist, erfordert im Sys-V-Szenario einen Systemaufruf, was den Vorgang verlangsamt. Auf der anderen Seite bringt ein Spinlock-artiges Vorgehen, bei dem das Erhalten der Sperre zwar sehr schnell geht, die gesperrten Prozesse aber permanent Prozessorzeit anfordern, auch nicht die gewünschte Performance.
Eine Kombination beider Verfahren liegt nahe. Sie müsste die folgenden Eigenschaften besitzen:
- Wenn die Sperre nicht gesetzt ist, kann der anfragende Prozess
ohne einen Systemaufruf direkt in den kritischen Bereich
gelangen. - Liegt eine Sperre vor, gehen die gesperrten Prozesse schlafen
und erhalten erst nach dem Wecken wieder Prozessorzeit.
Abbildung 3 skizziert dieses Grundmuster. Der Prozess P 1 kann ohne Abtauchen in den Kernel die Sperre erhalten. Der Prozess P 2 stellt seine Abfrage zunächst auch ohne Mithilfe des Kernels. Wenn die Sperre frei ist, benötigt dies kaum Ausführungszeit. Hier hat aber P 1 schon die Sperre allokiert, sodass P 2 einen Kernelaufruf absetzt und der Kernel ihn in eine Warteschlange steckt.
Listing 7 zeigt den vereinfachten Pseudocode für dieses Erniedrigen einer Sperre, was möglicherweise zum Blockieren führt. Das Testen und Setzen der Sperrvariablen »ftx« muss natürlich atomar geschehen. Den zugehörigen vollständigen Code könnte eine Bibliothek wie die Glibc bereithalten.
Aus dem Listing ist ersichtlich, dass der aufrufende Prozess oder Thread nur bei gesetzter Sperre einen Systemaufruf, also »sys_ftx_wait()«, ausführen muss. In allen anderen Fällen geschieht der Aufruf der Funktion »futex_down()« viel schneller. Wenn der Systemaufruf »sys_ftx_wait()« außerdem auch noch geeignet implementiert ist, realisiert der Pseudocode auch den langsameren Pfad bei gesetzter Sperre auf die gewünschte Weise. Futexe so zu benutzen setzt also voraus,
- dass im Linux-Kernel die zugehörigen Systemaufrufe
implementiert sind und - dass die Glibc geeignete Bibliotheksfunktionen vorrätig
hält.
Posix Thread Library
Seit der Version 2.6 ist die erste Bedingung im Linux-Kernel gegeben. Parallel dazu haben die Glibc-Entwickler die Futexe eingebaut. Dies geschah vor allem im Zusammenhang mit der Umstellung der Linux-Threads-Bibliothek auf die Native Posix Thread Library (NPTL, [6], [7]). Die einfachsten Futex-Funktionen aus der Glibc-Bibliothek sind die Posix-Semaphore. Diese Form dient zwar ebenso wie die besprochenen Sys-V-Semaphore der Synchronisation von Prozessen oder Threads, ist im Detail von diesen aber deutlich unterschieden.
Die Posix-Spezifikation unterscheidet zwischen benannten und unbenannten Semaphoren [8]. Der Aufruf
int sem_init(sem_t *Sem, int Pshared,U unsigned int Value)
erzeugt einen unbenannten Posix-Semaphor. Das erste Argument gibt den Verweis auf die Posix-Semaphore und das dritte den initialen Wert der Semaphore vor. Das zweite Argument spezifiziert, ob der Semaphor nur einem Prozess gehören soll oder prozessübergreifend verwendbar ist. In einigen aktuellen Distributionen greift die letzte Möglichkeit aber selbst in der NPTL-Implementierung nicht. Die folgenden Beispiele benutzen deshalb die benannte Form der Posix-Semaphore, die häufig nicht ausreichend dokumentiert, in der Glibc aber verfügbar ist [9].
Die benannte Variante setzt bei dem Aufruf »sem_open()« an und folgt damit dem unter Posix üblichen Muster für den Umgang mit Objekten der Interprozesskommunikation ([4], [10]). Sie verfügt über die weiteren Aufrufe:
- »sem_post()« beziehungsweise
»sem_wait()«, um den Wert des Semaphors atomar zu
erhöhen oder zu erniedrigen. Wenn er bei der Erniedrigung
durch »sem_wait()« einen Wert kleiner oder gleich 0
erreicht, blockiert der aufrufende Prozess oder Thread. Diese
Aufrufe basieren auf den eben beschriebenen Futex-Verfahren. - »sem_getvalue()«, um den Wert des Semaphors
abzufragen. - »sem_close()«, um den Semaphor freizugeben.
- »sem_unlink()«, um den Semaphor zu
löschen.
|
Listing 5: Sperren mit einem |
|---|
01 struct sembuf ops[1]; 02 03 ops[0].sem_num = 0; 04 ops[0].sem_op = -1; 05 ops[0].sem_flg = 0; 06 07 semop(semid, ops, 1); |
|
Listing 6: Entsperren eines |
|---|
01 struct sembuf ops[1]; 02 03 ops[0].sem_num = 0; 04 ops[0].sem_op = 1; 05 ops[0].sem_flg = 0; 06 07 semop(semid, ops, 1); |
|
Listing 7: Futex-Pseudocode |
|---|
02 ...
03
04 int futex_down(futex_t *ftx)
05 {
06 if (*ftx == UNLOCKED) {
07 *ftx--;
08 return 0;
09 }
10 return sys_ftx_wait(ftx);
11 }
|
Listing 8 zeigt das Anlegen und Initialisieren eines Posix-Semaphors. Der Aufruf »sem_open()« bekommt zunächst den Namen des Posix-Semaphors übergeben. Er bildet einen Teil des Namens, unter dem der Semaphor im Tmp-FS sichtbar ist. Listing 9 zeigt das Tmp-FS nach dem Aufruf aus Listing 8.
Ein angelegter Semaphor ist entweder durch den Namen »EinName« oder den Zeiger »posix_sem« ansprechbar. Alle Funktionen, die auf dem Semaphor operieren, benötigen den Zeiger, sodass ein erneutes »sem_open()« den Namen erst auf den Zeiger abbilden muss. Listing 10 geht davon aus, dass die Variable »posix_sem« den Zeiger vorhält.
|
Listing 8: Einen Posix-Semaphor |
|---|
01 #include <semaphore.h>
02
03 #define POSIX_LOCKED 0
04 #define POSIX_UNLOCKED 1
05
06 sem_t *posix_sem;
07
08 posix_sem = sem_open("/EinName", O_CREAT, 0644, POSIX_UNLOCKED);
09 ...
|
|
Listing 9: Posix-Semaphor im |
|---|
01 linux:> ls -la /dev/shm 02 drwxrwxrwt 3 root root 80 2005-06-21 12:20 . 03 drwxr-xr-x 37 root root 181952 2005-06-21 11:23 .. 04 -rw-r--r-- 1 wn users 16 2005-06-21 12:20 sem.EinName |
|
Listing 10: Sperren und |
|---|
01 /* Sperre setzen */ 02 sem_wait(posix_sem); 03 04 /* kritischer Bereich */ 05 ... 06 07 /* Sperre freigeben */ 08 sem_post(posix_sem); |
Da die Posix-Semaphore – anders als die Sys-V-Form – nicht in Menge auftreten, sind sie vergleichsweise einfach verwendbar. Die Funktion »sem_wait()« versucht den Wert des Semaphors zu erniedrigen, wenn der Wert größer als 0 ist. Wenn der Wert gleich 0 ist, blockiert der aufrufende Prozess oder Thread, bis wieder ein Wert größer als 0 erreicht ist. Dann erfolgt das Erniedrigen. Diese Operation geschieht wieder atomar. Analog erhöht die Funktion »sem_post()« den Wert des Semaphors atomar. Eine Erhöhung führt nie zu einer Blockade.
Posix-Semaphore und Futexe als Mischform
Die Unterschiede zwischen den Futex-basierten Posix-Semaphoren und den Spinlocks beziehungsweise Sys-V-Semaphoren lassen sich am besten bei der Betrachtung der beiden Basiskriterien erkennen:
- Konstruktionsbedingt erlangt ein Futex-User eine freie Sperre
sehr schnell. Der Sperrer benötigt keine Unterstützung
durch das Betriebssystem. Diesbezüglich verhalten sich Futexe
– und in ihrem Gefolge auch die Posix-Semaphore – wie
Spinlocks. - Anders sieht es für die gesperrten Prozesse oder Threads
aus. Ist die Sperre gesetzt, übernimmt das Betriebssystem die
gesperrten und verwaltet sie in einer Warteschlange. Ähnlich
wie bei den Sys-V-Semaphoren belegt dies keine
Prozessor-Ressourcen.
Die Posix-Semaphore und mit ihnen die Futexe stehen also in der Mitte zwischen Spinlocks und Sys-V-Semaphoren. Posix-Semaphore sind zudem als einfachste Form der Futexe aufzufassen.
Neben den schon beschriebenen Funktionen in der Glibc ist der Futex-Systemaufruf selbst interessant, da er Einblicke in die einem Futex innewohnende Funktionsweise bietet. Im Gegensatz zu den Systemaufrufen »sys_semget()«, »sys_semctl()« und »sys_semop()«, die die Sys-V-Form benötigen, kommen Futexe mit dem Aufruf »sys_futex()« aus. Dessen wichtigste Argumente sind:
- Die Adresse der Variablen, die letztlich die Sperre
implementiert. Der Kernel setzt die virtuelle Adresse, die die
Anwendung angeben muss, in eine absolute um und stellt damit
sicher, dass auch andere Prozesse denselben Futex verwenden. Die
Anwendungsseite arbeitet dann mit einem Pointer, zum Beispiel
»posix_sem« auf »sem_t«. - Ein Code, der angibt, welche Operation auf dem Futex
gewünscht ist. Wichtige Codes sind »FUTEX_WAIT«
und »FUTEX_WAKE«, die den Aufrufer in den Wartezustand
versetzten und ihn aufwecken.
In den aktuellen 2.6er Kerneln ist der Futex-Support auch für produktive Umgebungen hinreichend stabil. Auch die Unterstützung durch die Glibc ist in einem guten Zustand. Zudem existieren interessante Futex-Erweiterungen wie die FUSYNs [11]. Lediglich die Verwaltung der Warteschlange, in der die gesperrten Prozesse oder Threads liegen, und der Aufweck-Mechanismus sind vom Anfang der Implementierungen bis heute steter Gegenstand von Diskussionen.
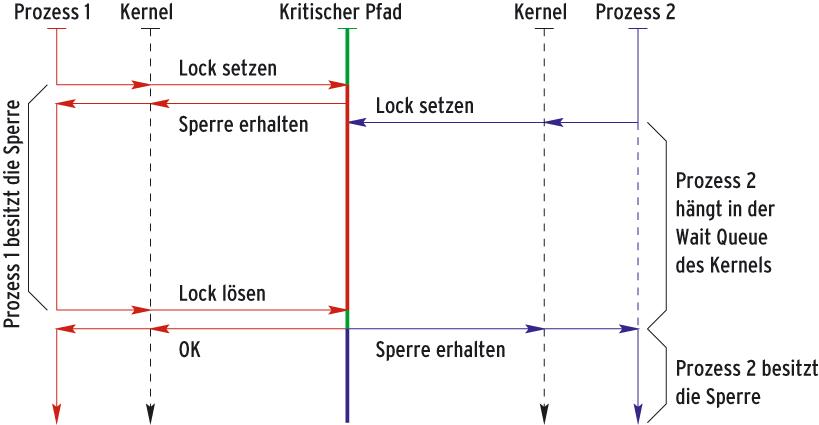
Abbildung 3: Mit einem Futex erhält der Prozess P 1 die Sperre ohne Hilfe des Kernels. Der Prozess P 2 will es ihm gleichtun, muss aber wegen P 1 einen Kernelaufruf absetzen und erhält einen Platz in einer Warteschlange.
Welche Synchronisation ist die richtige?
Dass Linux jetzt drei Verfahren zur Synchronisation von Prozessen oder Threads bereitstellt, wirft für jede konkrete Anwendung die Frage auf, welches Verfahren das geeignete ist. Der Programmierer muss sich dabei mit zwei Kriterien auseinander setzen, die sachlich eng mit den beiden eingangs definierten Basisfragen zusammenhängen. Das erste Kriterium betont die Wettbewerbssituation. Sie entsteht immer dann, wenn mehr als ein Prozess oder Thread eine Sperre erhalten möchten.
Ein Wettbewerb tritt bei der Notwendigkeit von Synchronisation prinzipbedingt immer auf, offen aber ist dessen Ausmaß. Sobald ein Prozess oder Thread lange im kritischen Bereich bleibt oder wenn sich viele Prozesse oder Threads um die Sperre bewerben, entsteht ein besonders scharfer Wettbewerb (Contention). Jeder Entwickler wird versuchen, die Contention möglichst klein zu halten, da sie immer die Performance beeinträchtigt.
Das zweite Kriterium bewertet das erlaubte Verhalten der gesperrten Prozesse oder Threads. Vielerorts ist ein Spinning, das heißt ein aktives Warten, nicht sinnvoll, da es teure Prozessorzeit beansprucht. Auf Einprozessor-Maschinen ist Spinning ganz besonders nachteilig, da alle aktiv wartenden Prozesse oder Threads genau jenem Prozess oder Thread die Prozessorzeit beschneiden, der gerade seinen kritischen Bereich durchläuft.
Empfehlungen – abhängig vom Spinning
Beide Gesichtspunkte helfen Empfehlungen auszusprechen, für welche Art Anwendung sich eines der drei Synchronisationsverfahren besonders eignet:
- Wer Spinning vermeiden will oder muss, kann nur zwischen Posix-
und Sys-V-Semaphoren wählen. - Besteht in diesen Fällen nur ein niedriges Maß an
Wettbewerb, besitzen Posix-Semaphore gegenüber den
Sys-V-Formen einen deutlichen Geschwindigkeitsvorteil. Ein
wechselseitiger Ausschluss – wie oben beim Zugriff auf
gemeinsame Speicherbereiche beschrieben – ist deshalb mit
Posix-Semaphoren (also Futexen) am besten zu lösen. - Ist Spinning tolerierbar und ist wenig Wettbewerb gegeben
– typisch für Multiprozessor-Systeme -, zeigen die
Spinlocks für den wechselseitigen Ausschluss eindeutig die
beste Performance. Sobald aber auch hier der Wettbewerb steigt,
werden Posix-Semaphore interessanter. - Komplexere Aufgaben, zum Beispiel die Synchronisation mehrfach
vorhandener Ressourcen, lassen sich zumeist mit Sys-V-Semaphoren am
einfachsten realisieren.
Tabelle 1 gibt eine Übersicht über geeignete Einsatzbereiche der Verfahren.
|
Tabelle 1: Eignung |
||
|---|---|---|
|
|
Spinning akzeptabel |
Spinning nicht akzeptabel |
|
Starker Wettbewerb |
Posix-, eventuell Sys-V-Semaphore |
Posix-, eventuell Sys-V-Semaphore |
|
Geringer Wettbewerb |
Spinlocks |
Posix-Semaphore |
|
Komplexer Wettbewerb |
Sys-V-Semaphore |
Sys-V-Semaphore |
Fazit
Seit der 2.6er Reihe besitzt der Linux-Kernel eine elegante Variante zur Synchronisation von Prozessen und Threads. Die Futexe erlauben Bibliotheken die Bereitstellung effizienter Verfahren, etwa zur Realisierung von kritischen Bereichen. Die Glibc hat dies in der NPTL und mit den Posix-Semaphoren getan. Aber auch Anwendungsentwickler profitieren in der einen oder anderen Situation vom Futex-Mechanismus. Sicher ist, dass die Futexe und ihre Ableger eine Lücke füllen und den Linux-Kernel ein weiteres Stück geeigneter machen für große Anwendungen. (jk)
|
Infos |
|---|
|
[1] A. Siberschatz, G. Gagne, P. B. Galvin, “Operating System Concepts”: Wiley, 2005 [2] H. Franke, R. Russell, M. Kirkwood, “Fuss, Futexes and Furwocks, Fast Userlevel Locking in Linux”: [http://www.linux.org.uk/~ajh/ols2002_proceedings.pdf.gz] [3] Wikipedia zu “Race Condition”: [http://de.wikipedia.org/wiki/Race_Condition] [4] W.R. Stevens, “Advanced Programming in the Unix Environment”: Addison-Wesley, 1992 [5] Manpage zu »semget«, »semctl« und »semop« [6] U. Drepper, I. Molnar, “The new Native POSIX Thread Library for Linux”: [http://people.redhat.com/drepper/nptl-design.pdf] [7] U. Drepper, “Futexes are tricky”: [http://people.redhat.com/drepper/futex.pdf] [8] Manpage zu »sem_init«, »sem_post«, »sem_wait« [9] Manpage zu »sem_open()«: [http://docs.sun.com/app/docs/doc/816-5171/6mbb6dcpm?a=view] [10] Willi Nüßer, “Spiegelbilder – Speicherbelegung im Proc-Filesystem analysieren”: Linux-Magazin 08/04, S. 96 [11] OSDL, FUSYN: [http://developer.osdl.org/dev/robustmutexes/] |
|
Der Autor |
|---|
|
Dr. Willi Nüßer ist Heinz-Nixdorf-Stiftungsprofessor für Informatik an der Fachhochschule der Wirtschaft (FHDW) in Paderborn. Davor arbeitete er sechs Jahre bei der SAP AG. Dort war er zuletzt als Entwickler im SAP Linux Lab unter anderem für die Portierung der SAP-Speicherverwaltung auf Linux und die Unterstützung verschiedener Hardwareplattformen zuständig. |





