
Wackamole arbeitet im Untergrund des Netzes und sorgt dafür, dass dessen Dienste verfügbar bleiben. Zwei Binaries genügen für einen dynamischen Cluster mit beliebigen Linux-Distributionen. Dieser Artikel erklärt Konfiguration und Technologie und vergleicht sie mit der Rainfinity Rainwall.
Es wird sich nie verhindern lassen, dass einzelne Server ausfallen. Findige Admins halten Ersatz bereit, um im Ernstfall schnell reagieren zu können. Noch schneller sind automatische Lösungen: Hochverfügbarkeitstechniken sorgen dafür, dass ein Cluster aus mehreren Servern nach außen hin störungsfrei erscheint, auch wenn einzelne Komponenten ausfallen. Wackamole[1] zeigt, dass diese Techniken gar nicht so schwierig zu implementieren sind.
Loadbalancer vs. Cluster
Allerdings hat der Begriff Cluster verschiedene Bedeutungen. Cluster Computing kann neben Hochverfügbarkeit auch der Lastverteilung oder der parallelen Datenverarbeitung dienen. Der Kasten “Cluster-Techniken” erläutert einige gängige Cluster und ordnet sie nach den technologischen Prinzipien.
Diese Techniken und Prinzipien lassen sich unter verschiedenen Gesichtspunkten betrachten. Tabelle 1 zeigt eine Einteilung anhand der stattfindenden Kommunikation. Cluster, die sich intern auf Gruppenkommunikation (Group Communication) verlassen, bestehen aus einer Clustersoftware (Middleware) auf jedem Clusternode. Mit der Middleware informieren sich die Nodes gegenseitig über ihren jeweiligen Status und ihre Mitgliedschaften. Solche Cluster benötigen keine Hardware wie Loadbalancer oder Content Switches.
Hardware-Loadbalancer arbeiten dagegen vor einer Gruppe von Servern, die untereinander meist nicht geclustert sind, und verteilen Requests auf diese Rechner. Bei vielen Produkten prüft die externe Hardware regelmäßig die Server (Health-Checks), ermittelt deren Erreichbarkeit sowie näherungsweise deren Auslastung. Dagegen kommuniziert bei Mod_backhand ein Apache-Modul Speicherbelegung und Systemlast aktiv an den Loadbalancern.
Wenn die zusätzliche Hardware nicht selbst redundant ausgelegt ist, sind Loadbalancer ein neuer Single Point of Failure im Netz. Ein Cluster besteht dagegen aus mehreren Rechnern (einer Gruppe), die in manchen Fällen nach außen hin als ein einziges hochverfügbares System erscheinen. Mit Wackamole und anderen Clustern, die auf Gruppenkommunikation basieren, müssen sich alle beteiligten Server über die Gruppe im Klaren sein. Ihre gemeinsame Aufgabe ist es, einen bestimmten Service hochverfügbar anzubieten.
Der Benutzer merkt in der Regel nicht, dass er gerade mit einem Cluster verbunden ist. Das ist durch zwei verschiedene, weitgehend unabhängige Mechanismen verwirklicht: Die Server müssen Status- und Mitgliedschaftsinformationen intern kommunizieren (etwa per Spread[2]) und nach außen hin als ein einziges System erscheinen (das leistet Wackamole).
Jeder mit jedem: Gruppenkommunikation
In modernen Clustern mit mehreren aktiven Komponenten kommen meist Algorithmen zum Einsatz, die sich am Extended Virtual Synchrony Model EVS[3] orientieren. Das gilt sowohl für den hier vorgestellten Spread-Daemon als auch für kommerzielle Produkte wie zum Beispiel die Rainfinity Rainwall[5]. Dieses Modell spiegelt die Notwendigkeit wider, dass alle Clusternodes zu jeder beliebigen Zeit den gleichen Wissensstand bezogen auf Cluster-Mitgliedschaft und Status benötigen.
Zum Beispiel könnte ein Cluster aus drei Computern A, B und C bestehen. Zwischen A und C tritt ein Netzproblem auf, nicht aber zwischen B und C. In diesem Fall darf es unter keinen Umständen passieren, dass A denkt, C hätte den Cluster verlassen und A und B seien die verbleibenden aktiven Nodes. B und C würden jedoch glauben, dass der Cluster weiterhin aus A, B und C besteht.
|
Tabelle |
|
|---|---|
|
Technik |
Produkte |
|
Cluster mit Gruppenkommunikation, eine aktive Komponente |
|
|
VRRPd (RFC 2338) |
Linux VRRPd[9] |
|
Heartbeat |
Linux-High-Availability-Projekt[8] |
|
Cluster mit Gruppenkommunikation, mehrere aktive |
|
|
VIPs |
Spread/Wackamole, Rainfinity Rainwall[5] |
|
Multicast-Cluster |
Stonesoft Stonegate[15] |
|
Cluster ohne Gruppenkommunikation, etwa |
|
|
URI-Redirection |
Mod_backhand[7] |
|
Diverse Scheduling-Algorithmen |
Linux Virtual Server (LVS)[11], Radware Webserver Director[16], |
Geordnete Nachrichten
Die Theorie dazu ist stellenweise recht kompliziert. Vereinfacht betrachtet wird die Synchronisation der Nodes erreicht, indem sich die Clusternodes ständig eine Sequenz geordneter Nachrichten (Nachricht 1 kommt zwingend vor Nachricht 2) zusenden. Die auf jedem Node installierte Clustersoftware muss überall die gleiche Sequenz von Nachrichten empfangen. Alle Situationen, unter denen dies nicht möglich ist (zum Beispiel bei Störungen der Hardware oder des Netzwerks), gelten als Übergangszustand – ein oder mehrere Server treten dem Cluster gerade bei oder verlassen ihn in diesem Moment.
In dem hier vorgestellten dynamischem Cluster ist der Spread-Daemon für diese Gruppenkommunikation zuständig, er ist auf allen Servern installiert und gestartet. Für weitere Hintergrundinformationen zum EVS siehe Kasten “Partitionierbare Umgebung”.
Starkes Team statt Einzelkämpfer
Eine Gruppe von Servern ist noch lange kein Cluster, selbst wenn alle Computer über die Gruppe und ihre Mitgliedschaft Bescheid wissen. Es fehlt immer noch jener Teil eines Clusters, der dem Client vorgaukelt, dass er mit einem einzigen System verbunden ist. In den meisten Fällen ist dies durch eine IP-Adresse verwirklicht, die so lange vorhanden ist, bis auch der letzte Server der Gruppe in Rauch aufgeht.
Dies erfordert nicht notwendigerweise, dass mehrere Rechner gleichzeitig aktiv sind, es kann genauso durch VRRPd[9] oder Heartbeat (siehe den entsprechenden Artikel) verwirklicht sein. VRRP wählt einen Master im LAN und wird hauptsächlich verwendet, um Router hochverfügbar zu betreiben. Wenn der Master ausfällt, übernimmt ein Standby-Gerät seine Aufgabe.
Wie Spread und Wackamole läuft der Linux-VRRPd gegenwärtig im Userspace. Bei VRRPd und Heartbeat enthält der Cluster eine aktive Komponente und ein Standby-System, das im Fehlerfall die IP-Adresse und die Funktionalität übernimmt. Damit wird der Dienst hochverfügbar. Die Netzwerkkommunikation der Systeme untereinander ist bei Heartbeat und dem VRRPd rudimentär und nicht geeignet, um gut skalierbare Cluster mit mehreren aktiven Servern zu implementieren.
|
Cluster-Techniken |
|---|
|
Hinter dem Oberbegriff Cluster verbergen sich einige recht unterschiedliche technische Prinzipien und Produkte. Abbildung 1 ordnet die Techniken in zwei Hauptzweige: Eine Variante dient als hochverfügbare Systemumgebung mittels redundanter Knoten (Hot-Standby), die andere teilt die Last unter den redundanten Systemen auf (Active-Active). Kein Cluster ist für alle Anwendungsfälle geeignet, die Aufgabenstellungen sind einfach zu unterschiedlich. Webserver haben ihren Schwerpunkt beim Netzwerk, Datenbanken beim Filesystem-I/O. Beide Technologien (Hot-Standby und Active-Active) lassen sich je nach der Applikation weiter unterscheiden. Hot-Standby-Cluster sind in Cluster für Anwendungen mit hohen und solche mit geringen Ansprüchen an das Filesystem zu unterteilen. Die erste Gruppe kommt meist für hochverfügbare Datenbanken zum Einsatz, entsprechende Produkte sind zum Beispiel der Veritas Cluster Server (VCS) [13] und Steeleye Lifekeeper [14]. Bei der zweiten Gruppe reicht eine einfache Synchronisation oder Replikation der Applikationen auf den einzelnen Clusternodes für einen transparenten Failover. Komplexere Aspekte, zum Beispiel im Filesystem, bleiben unberücksichtigt. Hier sind Produkte wie Heartbeat (siehe Artikel), VRRPd [9] und Wackamole gut geeignet. Der Active-Active-Teilbaum ist noch in Parallel Processing und in Netzwerk-Loadbalancing unterteilt. Das Loadbalancing lässt sich noch weiter nach Endpunkten des Netzwerkverkehrs (etwa Webserver) und Durchgangsstationen (Router, Firewalls) unterteilen. Nur beim echten Parallel Processing ist es möglich, dass mehrere CPUs gleichzeitig an einer Aufgabe rechnen. Dabei kann es sich um einen einzigen Rechner mit mehreren CPUs und SMP-Kernel (symmetrisches Multiprocessing) handeln oder um Rechner, die sich die Arbeit teilen (Beowulf-Cluster [12]). Die Aufgabe wird dazu in mehrere Unteraufgaben zerlegt, die die Knoten mittels Gruppenkommunikation (zum Beispiel Message Passing Interface, MPI) einander zuteilen.  Abbildung 1: Die verbreiteten Cluster-Techniken (weiße Felder) und -Produkte lassen sich in mehrere Linien unterteilen. Hauptgruppen sind Hot-Standby auf der einen und Lastverteilung auf der anderen Seite, Letztere teilt sich in Parallel Processing und Netzwerk-Loadbalancer. |
Wackamole kann mehr
Mit Wackamole lassen sich Aktiv- oder Standby-Implementierungen verwirklichen, die Software kann aber mehr: Das Zusammenspiel mit der Spread-Gruppenkommunikation macht Cluster mit mehreren aktiven Servern und einem Pool von virtuellen IP-Adressen (VIPs) möglich, die zu jeder Zeit erreichbar sind. Kein Server erhält eine VIP durch seine Boot-Konfiguration. Wackamole verteilt alle VIPs aus dem Pool auf die Server im Cluster. Jede VIP befindet sich nur auf einem einzigen Server, jeder Server kann aber beliebig viele VIPs haben. Dieses Konzept (VIP-Mobility) verfolgt auch die Rainwall[5].
Die Abbildungen 2 und 3 zeigen eine Spread-Gruppe aus drei Servern und sechs VIPs, die gleichmäßig auf die Server verteilt sind. In Abbildung 3 fällt Server 2 zum Beispiel wegen eines schweren Hardwareproblems aus. Die Spread-Gruppe merkt durch das EVS, dass eine Änderung im Systemstatus vorliegt, kommuniziert dies und Wackamole verteilt die VIPs neu unter den verbliebenen Knoten.
Umzugstechnik
Gegenwärtig haben Admins keine Möglichkeit, VIPs ohne eine Statusänderung gezielt umzuverteilen, etwa um die Last besser zu verteilen oder die Bandbreite geschickter zu nutzen. Bei solchen Features ist die Rainwall gegenwärtig voraus. Immerhin kann Wackamole ein einfaches Loadbalancing erreichen, wenn es das Round-Robin-Verfahren des DNS nutzt (bei Webservern) oder die umliegenden Router mit mehreren statischen Routen für eine Destination-Adresse arbeiten (bei Routern und Firewalls):
route add -net 192.168.100.0 netmask 255.255.255.0 gw VIP1 route add -net 192.168.100.0 netmask 255.255.255.0 gw VIP2 route add -net 192.168.100.0 netmask 255.255.255.0 gw VIP3
Wenn es sich bei den Servern um Webserver (also Endpunkte des Netzwerkverkehrs) oder um Linux-Router und Firewalls (Durchgangsstationen) handelt, ist das uneingeschränkt möglich. Bei Firewalls muss der Admin jedoch für die Synchronisation der Firewall-Applikation sorgen oder symmetrisches Routing gewährleisten.
Ein Kommando, das VIPs ohne vorherige Statusänderung vom einen Server zum anderen bringt, steht gegenwärtig auf der To-do-Liste der Wackamole-Entwickler. Es könnte wie folgt lauten:
./wackatrl mv VIP IP
Immer wenn eine VIP von einem Host zum anderen umzieht, müssen das die ARP-Caches der umliegenden Systeme auch erfahren. Beim Umzug ändert sich auch die zugehörige MAC-Adresse – das müssen die anderen Komponenten im LAN berücksichtigen.
Wackamole erledigt dies durch so genanntes ARP-Spoofing. Der Cluster-Knoten, der die VIP neu erhält, sendet unaufgefordert ARP-Replies an alle relevanten Systeme. Welche das sind, steht in »wackamole.conf« im Konfigurationsabschnitt »Notify«. Die unangeforderten ARP-Replies bringen die Zielsysteme (typischerweise Router) dazu, Ethernet-Frames, die für den ausgefallenen Node bestimmt waren, nun an das Ersatzsystem zu senden.
Hier gibt es einen interessanten Unterschied zur Rainwall: Sie nutzt die VIPs auch fürs Loadbalancing und erhöht den Firewall-Durchsatz über die Bandbreite einer einzigen Netzwerkkarte hinaus. Die Rainwall betreibt kein ARP-Spoofing, sondern verwendet Gratuitous ARP (gARP). Der Server, der die VIP nach dem Umzug erhält, sendet einen ARP-Request nach eben dieser VIP und beantwortet die Frage selbst. Das zwingt alle mithörenden Systeme, ihren ARP-Cache zu aktualisieren. Da es sich nur um einen Broadcast und einen Reply handelt, ist das Verfahren mit weniger Overhead behaftet als ARP-Spoofing.
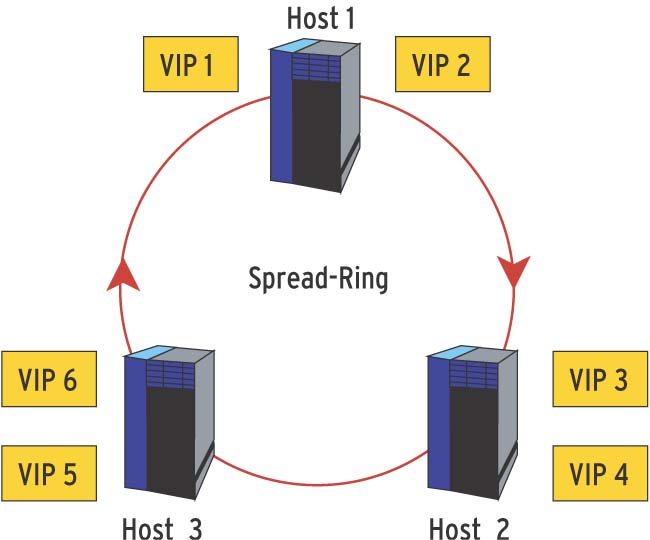
Abbildung 2: Eine Gruppe von drei Servern informiert sich per Spread-Kommunikation gegenseitig über ihren Status. Wackamole verteilt sechs VIPs (virtuelle IP-Adressen) auf die Hosts, sodass alle Rechner für Anfragen bereitstehen.
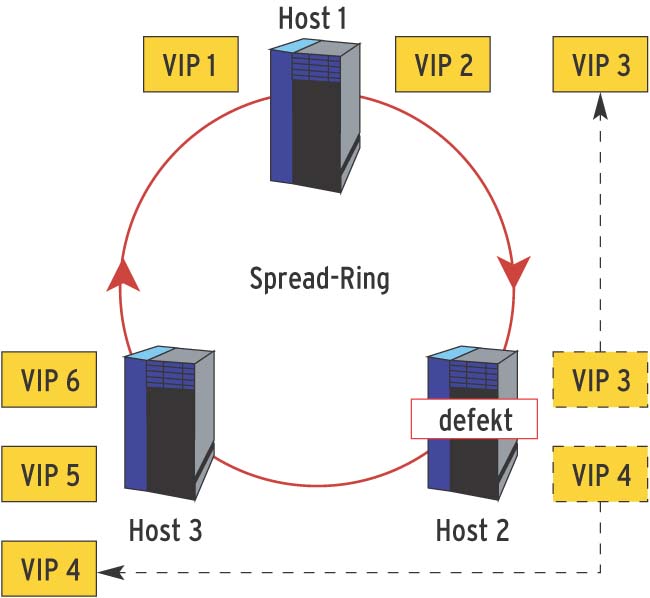
Abbildung 3: Fällt ein Server aus, erfahren die anderen dies dank des Spread-Rings. Wackamole verteilt die VIPs neu, sodass die Clients nichts von dem Ausfall bemerken und weiterhin alle Adressen ansprechen können.
Fairer Mitspieler
Die bisherigen Betrachtungen betrafen nur die OSI-Schichten 2 und 3 (Ethernet und IP), aber nicht die Dienste und Applikationen. Diese wissen in der Regel nichts von der Gruppenkommunikation oder der Hochverfügbarkeit. Das wäre auch unnötig bei statischen (zustandslosen) Anwendungen und bei solchen, deren dynamische Konfiguration schnell regenerierbar ist. Zu Letzteren gehören zum Beispiel Router, die ihre Routingtabellen automatisch durch Updates neu aufbauen, wenn sie als bisheriges Standby-Gerät aktiv werden.
Bei Anwendung wie LDAP oder MySQL, die häufigen Änderungen ausgesetzt sind, muss dagegen nicht nur die Clustersoftware, sondern auch die Anwendung durch zusätzliche Protokolle synchronisiert werden. Bei Datenbanken ist das als Replikation zu verstehen.
Die folgenden Abschnitten zeigen, wie man eine hochverfügbare Implementierung zweier Linux-Apache-Server passend zu Abbildung 4 konfiguriert.
|
Partitionierbare |
|---|
|
Im EVS (Extended Virtual Synchrony Model) synchronisieren die beteiligten Knoten ihr Wissen über den Zustand der Gruppe. Sie benutzen dazu Sequenzen geordneter Nachrichten, die sie sich gegenseitig zusenden. Die Algorithmen, mit denen das EVS umgesetzt wird, dürfen nicht von der Verfügbarkeit eines einzelnen Servers abhängig sein. Andernfalls käme der gesamte Cluster zum Stillstand. Wenn nicht mehr jeder Server die gleiche Sequenz geordneter Nachrichten erhält, darf der Cluster nicht einfach so lange warten, bis alle Nachrichten wieder durchkommen. Vielmehr gehen die übrig gebliebenen Knoten in einen Übergangszustand, kommunizieren Mitgliedschaftsänderungen (zum Beispiel ein defektes System verlässt den Cluster) und bilden eine neue, stabile Gruppenzusammensetzung ohne die fehlerhaften Systeme. Diese Fähigkeit zur schnellen Neuordnung bietet den übergeordneten Anwendungen eine konsistente Basis, mit der sie sinnvolle Entscheidungen treffen können. Als Beispiel soll eine Gruppe aus vier Knoten {A, B, C, D} dienen (zur besseren Übersicht in geschweiften Klammern notiert). Bei einem Netzwerkfehler könnte sie in zwei unabhängige und gleichzeitig operierende Partitionen {A, C} und {B, D} (oder jede andere Kombination) auseinanderbrechen. Für die Anwendungsschicht wäre das in den meisten Fällen fatal. EVS sorgt dafür, dass die Partitionen nach dem Beheben des Fehlers wieder eine gemeinsame Gruppe bilden können. Zwei Partitionen wissen nichts voneinanderDas eben genannte Beispiel ist in {A, C} auf der einen sowie {B, D} auf der anderen Seite partitioniert. A und C sehen sich gegenseitig, sie glauben aber, dass B und D nicht verfügbar sind. Auch B und D gehen davon aus, dass A und C ausgefallen sind. In dieser Situation nimmt Wackamole an, dass entweder die Partition {A, C} von außen sichtbar ist oder {B, D}, aber nicht beide. Beide Partitionen bieten VIPs (Virtuelle IP-Adressen) an, unter denen die Clients sie erreichen können. Solange wirklich nur eine der Partitionen von außen sichtbar ist, stört es auch nicht, wenn sich die andere Partition ebenfalls für die einzige noch aktive hält und die VIPs anbietet. In dem meisten lokalen Netzen gilt diese Annahme, die Partitionierung verursacht dann keine Störungen. |
Installation und Konfiguration
Derzeit sind Spread und Wackamole in keiner der üblichen Linux-Distributionen enthalten. Die Quellen liegen auf mehreren Webseiten zum Download bereit[1],[2]. Wackamole steht unter der CNDS Open Source License (Center for Networking and Distributed Systems, Johns Hopkins University), Spread unter der Spread Open Source License.
Spread ist im Sourcecode oder als Binary für diverse Plattformen verfügbar. Wer es sich leicht macht und die Binaries installiert, muss die Spread-Header, die Shared Libraries, Manpages und das Spread-Programm in die im Users Guide[6] genannten Verzeichnisse kopieren. Wackamole ist leider nicht als vorkompiliertes Binary erhältlich. Es lässt sich aber problemlos ohne exotische Abhängigkeiten, wie man sie vielleicht von Clustersoftware erwarten würde, durchkompilieren – wenn Spread bereits korrekt installiert ist.
Der gesamte Cluster wird von zwei Konfig-Dateien gesteuert: »spread.conf« (siehe Listing 1) und »wackamole.conf« (Listing 2), die Files liegen per Default im »/etc«-Verzeichnis. Wer die Grundlagen der Hochverfügbarkeit mit Wackamole kennt, wird sich in diesen Dateien schnell zurechtfinden.
In »spread.conf« sind die Mitglieder des Clusters anhand ihrer wirklichen IP-Adresse (real IP, RIP) definiert. »wackamole.conf« beschäftigt sich mit den VIPs und ihren Präferenzen (eine VIP bleibt an einem bestimmtem Server, solange er verfügbar ist). Der Spread-Abschnitt in »wackamole.conf« teilt Wackamole mit, über welchen Port es mit dem lokal gestarteten Spread-Daemon kommunizieren soll. Die Defaulteinstellung in »spread.conf« und »wackamole.conf« ist Port 4803.
Im vorliegenden Beispiel sind beide Webserver zur selben Zeit aktiv (Round Robin per DNS) und über ihre VIPs erreichbar. Wenn ein Webserver ausfällt (etwa RIP 10.200.1.10) übernimmt sein Partner dessen VIP (10.200.1.20). Für den Anwender passiert das völlig transparent und unterbrechungsfrei.
Im Gegensatz dazu handelt es sich bei der Rainwall um ein einziges Binary, das zugleich die Cluster-Gruppenkommunikation und die Bewegung der VIPs regelt. Der Admin steuert beide Mechanismen über eine zentrale Konfigurationsdatei. Listing 3 zeigt einen Auszug aus »rain.xml«, die eine Rainwall analog zu den in Listing 1 und 2 vorgenommenen Einstellungen konfiguriert.
Der Spread-Daemon und Wackamole laufen im Userspace, wo das Scheduling und Paging wie unter Unix gewohnt ablaufen. Unter sehr hoher Systemlast kann es daher vorkommen, dass die Gruppenkommunikation und damit der gesamte Cluster nicht mehr stabil funktionieren. Kernelmodule wie die Rainwall sind hier im Vorteil: Sie können deutlich schneller reagieren, auch weil zum Beispiel der Overhead durch Software-Interrupts entfällt und Syscalls direkt innerhalb des Kernel-Adressraums ablaufen.
|
Listing 1: |
|---|
01 Spread_Segment 127.0.0.255:4803 {
02 localhost 127.0.0.1
03 }
04
05 Spread_Segment 10.200.1.255:4803 {
06 10.200.1.10
07 10.200.1.30
08 }
|
|
Listing 2: |
|---|
01 Spread = 4803
02 SpreadRetryInterval = 5s
03 Group = wack1
04 Control = /var/run/wack.it
05
06 prefer none
07
08 # List all the virtual interfaces (ALL of them)
09 VirtualInterfaces {
10 eth0:10.200.1.15/24
11 eth0:10.200.1.20/24
12 }
13
14 Arp-Cache = 90s
15
16 Notify {
17 eth0:10.200.1.254/32
18 arp-cache
19 }
|
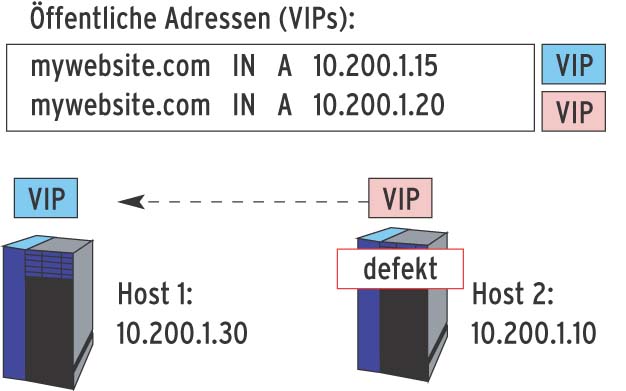
Abbildung 4: Nur die VIPs 10.200.1.15 und 10.200.1.20 sind für externe Clients per DNS sichtbar. Wackamole verteilt diese Adressen auf die verfügbaren Hosts.
Fazit
Dieser Artikel sollte die technischen Prinzipien der HA-Cluster erklären und zeigen, wie einfach mit Open-Source-Software ein hochverfügbarer Cluster entsteht. Auf diesen technischen Prinzipien beruhen verschiedene Produkte, auch kommerzielle Lösungen. Die Zielsetzungen und Schwerpunkte von Wackamole und Rainwall sind zum Teil recht unterschiedlich. Beide Produkte sind daher nicht als Alternativen füreinander zu sehen, sondern als zwei Cluster, die auf einer gemeinsamen Technologie beruhen. (fjl)
|
Listing 3: |
|---|
01 <NodeInfo> 02 <NodeID>25</NodeID> 03 <NodeName>Node_25</NodeName> 04 <Enabled>yes</Enabled> 05 <Interface> 06 <IP>10.200.1.10</IP> 07 <Mask>255.255.255.0</Mask> 08 <TokenAllowed>no</TokenAllowed> 09 </Interface> 10 </NodeInfo> 11 12 <NodeInfo> 13 <NodeID>26</NodeID> 14 <NodeName>Node_26</NodeName> 15 <Enabled>yes</Enabled> 16 <Interface> 17 <IP>10.200.1.30</IP> 18 <Mask>255.255.255.0</Mask> 19 <TokenAllowed>yes</TokenAllowed> 20 </Interface> 21 </NodeInfo> 22 23 <VIPManager ID="VIPMgr" version="1"> 24 <AddRemoveVIPScript></AddRemoveVIPScript> 25 <GratArpUpdateEnabled>yes</GratArpUpdateEnabled> 26 <GratArpUpdateMs>2000</GratArpUpdateMs> 27 <VIPAllocation></VIPAllocation> 28 <VIP> 29 <IP>10.200.1.15</IP> 30 <Mask>255.255.255.0</Mask> 31 <VIPRange>1</VIPRange> 32 <Sticky>no</Sticky> 33 <Preferences> 34 <NodeID>25</NodeID> 35 <NodeID>26</NodeID> 36 </Preferences> 37 </VIP> 38 <VIP> 39 <IP>10.200.1.20</IP> 40 <Mask>255.255.255.0</Mask> 41 <VIPRange>1</VIPRange> 42 <Sticky>no</Sticky> 43 <Preferences> 44 <NodeID>25</NodeID> 45 <NodeID>26</NodeID> 46 </Preferences> 47 </VIP> 48 </VIPManager> 49 50 <VIPGroupManager ID="VIPGrpMgr" version="1"> 51 <AddRemoveVIPGroupScript></AddRemoveVIPGroupScript> 52 <GratArpUpdateEnabled>yes</GratArpUpdateEnabled> 53 <GratArpUpdateMs>2000</GratArpUpdateMs> 54 </VIPGroupManager> |
|
Infos |
|---|
|
[1] Wackamole: [http://www.wackamole.org] [2] Spread-Toolkit: [http://www.spread.org] [3] Louise E. Moser, Yair Amir, P. Michael Melliar-Smith, Deborah A. Agarwal, “Extended Virtual Synchrony”: [http://www.cs.jhu.edu/~yairamir/dcs-94.ps.gz] [4] Jörg Fritsch und Frank Lindemann, “Balance-Akt – Load Balancing Cluster mit Turbolinux”: Linux-Magazin 03/02, S. 66 [5] Jörg Fritsch und Frank Lindemann, “Der Regenmacher – Siemens-Appliance mit Checkpoint Firewall-1 und Rainwall”: Linux-Magazin 08/02, S. 48 [6] Users Guide to Spread: [http://www.spread.org/docs/guide/] [7] Mod_backhand: [http://www.backhand.org/mod_backhand/] [8] Linux-HA: [http://www.linux-ha.org] [9] VRRPd: [http://off.net/~jme/vrrpd/] [10] LAM/MPI: [http://www.lam-mpi.org] [11] LVS: [http://www.linuxvirtualserver.org] [12] Beowulf: [http://www.beowulf.org] [13] Veritas: [http://www.veritas.com] [14] Steeleye Lifekeeper: [http://www.steeleye.com/products/linux/] [15] Stonesoft: [http://www.stonesoft.com] [16] Radware: [http://www.radware.com] [17] Nortel: [http://www.nortelnetworks.com] [18] F5 Networks: [http://www.f5.com] |
|
Die |
|---|
|
Theo Schlossnagle ist Consultant bei Omni TI Computer Consulting, Inc., die er 1997 gegründet hat. Nach seinem Studium an der Johns Hopkins University forschte er vier Jahre am Center for Networking and Distributed Systems. Nun wendet Theo akademische Modelle an, um hochskalierbare und hochperformante verteilte Systeme zu entwerfen und zu implementieren. [http://www.omniti.com/~jesus/] Jörg Fritsch hat Chemie studiert und arbeitet seit mehreren Jahren als Systemspezialist für Internetdienste und Security. Er veröffentlicht gern zu interessanten Themen im Bereich Linux, TCP/IP und Security. Er ist einer der Autoren des kürzlich bei Addison-Wesley erschienenen Buchs “Firewalls illustriert”. [http://www.joerg.cc] |





