
© James Anak Anthony Collin, 123RF
Die Börsenkurse in maschinenlesbarer Form mal eben aus dem Internet holen? Kein Problem: Nach ein paar Mausklicks auf eine Börsen-Webseite webt Portia einen geeigneten Kommandozeilenbefehl und wickelt die gewünschten Daten in das passende Json-Format ein.
Im Internet verstecken sich nützliche Informationen und Texte oft auf bunten HTML-Seiten, die Interessierte nicht ohne Weiteres extrahieren und maschinell weiterverarbeiten können. Wer etwa automatisiert die aktuellen Börsenkurse aufbereiten oder neue Nachrichten aggregieren möchte, muss erst umständlich den HTML-Code von News-Portalen wie N-TV oder Slashdot zerlegen.
Abhilfe verspricht das in Python geschriebene Portia [1], dessen Name zugleich auf eine Spinnengattung verweist, was im World Wide Web ja Sinn ergibt. Das Tool besteht aus einer Webanwendung, dank der ein Anwender einfach per Mausklick die Börsenkurse, Nachrichten und alle anderen gewünschten Inhalte markiert. Anschließend extrahiert Portia diese Daten und spuckt sie im Json-Format wieder aus.
Unterstützt von einem mitgelieferten Webcrawler durchwühlt Portia zudem komplette Internetauftritte. Benötigt ein Entwickler die Überschriften aller Wikipedia-Artikel, zeigt er Portia lediglich einmal, wo auf einer Wikipedia-Seite die Überschrift klebt. Anschließend durchläuft der Crawler den kompletten Internetauftritt und liefert alle passenden Überschriften im Json-Format zurück.
Spinnennetz
Portia verlangt Python in der Version 2.7, einen C-Compiler, Git, das Paket mit Virtualenv sowie die Entwicklerpakete zu »libffi« , »libxml2« , »libxslt« , »libssl« und Python. Unter Ubuntu spielt der folgende Bandwurm alles Notwendige ein:
sudo apt-get install python-virtualenv python-dev libffi-dev libxml2-dev libxslt1-dev libssl-dev git
Jetzt können Anwender den Quellcode von Github holen:
git clone https://github.com/scrapinghub/portia.git
Portia besteht aus mehreren Einzelteilen: Zunächst stellt Slyd die eigentliche Webanwendung bereit. Sein Kollege Slybot ist ein Webcrawler, der die ausgesuchten Webseiten durchläuft und die gewünschten Informationen ausschneidet. Dazu greift Slybot auf die Dienste von Scrapy [2] zurück. Slyd wiederum liefert seine Seiten über Twisted [3] aus.
Die Befehle aus Listing 1 installieren alle Bestandteile. Die erste Zeile erstellt dabei eine virtuelle Python-Umgebung, die zweite aktiviert sie. Auf diese Weise vermischen sich nicht die in der letzten Zeile nachinstallierten Python-Komponenten mit denen aus der Distribution.
Listing 1
Notwendige Python-Komponenten installieren
01 virtualenv portiaenv 02 source ./portiaenv/bin/activate 03 cd portia/slyd 04 pip install -r requirements.txt
Gelingt die Installation ohne Fehler, startet der Anwender Slyd:
twistd -n slyd
Der Befehl ist korrekt geschrieben – »twistd« ist der Twisted-Daemon.
Schraubstock
Steuert der Portianer nun im Browser die URL »http://localhost:9001/static/main.html« an, erscheint die Seite aus Abbildung 1. Portia unterstützt derzeit nur Chrome und Firefox, wobei die Entwickler Chrome empfehlen.

Abbildung 1: Die Webanwendung gibt sich nach ihrem ersten Aufruf noch recht aufgeräumt.
Zunächst tippt der Anwender in das Eingabefeld am oberen Rand die URL der Seite ein, die er anzapfen möchte. Nach einem Klick auf »Start« lädt Portia die Seite und zeigt sie im großen Bereich darunter an. Das kann ein paar Sekunden dauern und funktioniert nicht mit allen Websites: So weigerte sich Portia im Test, die Seiten des Linux-Magazins zu laden. Sofern die gewünschte Seite erscheint, limitiert Portia die Navigationsmöglichkeiten. Auf der Wikipedia legt die Webanwendung etwa die Suchfunktion lahm, die Links funktionierten jedoch weiterhin.
Jetzt muss der Schnittmeister die benötigten Informationen markieren. Dazu klickt er am oberen Rand auf »Annotate this page« . Portia wechselt jetzt in einen Auswahlmodus: Fährt er mit dem Mauszeiger über ein Element der Seite, das sich ausschneiden lässt, hebt Portia es blau hervor. Der HTML-Code taucht im schwarzen Kasten links oben auf.
Nach einem Klick auf den blauen Bereich erscheint das Fenster aus Abbildung 2. In ihm stellt der Anwender in der linken Dropdown-Liste das HTML-Attribut ein, dessen Inhalt er später übernehmen möchte. »Content« würde den Inhalt des HTML-Elements liefern, bei einer Überschrift also die Überschrift selbst.
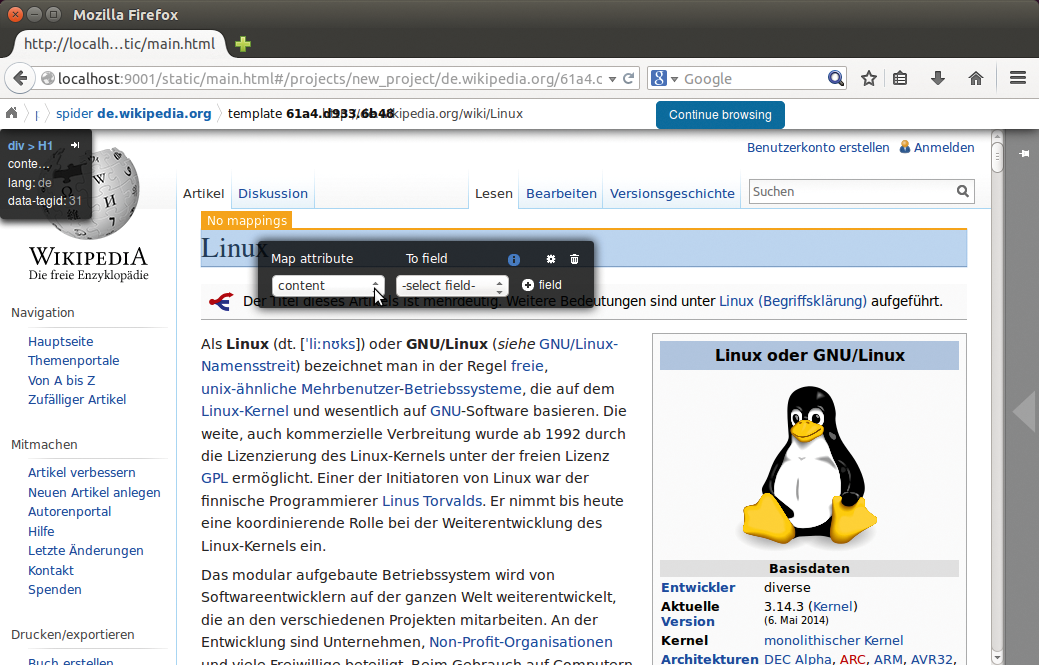
Abbildung 2: Wer einem Feld Inhalte zuweisen will, braucht ruhige Finger: Sobald die Maus den schwarzen Kasten verlässt, blendet Portia ihn umgehend aus.
Skalpell
Anschließend wählt der Zuschneider unter »To Field« den Punkt »Create New« . Es öffnet sich ein weiteres Fenster, in dem er festlegt, wie das Feld später in den Json-Daten heißen soll und um welchen Datentyp es sich handelt. Zur Auswahl stehen die üblichen Verdächtigen, etwa Zahlen und Text. Mit einem Klick auf den Haken geht es wieder zurück. Analog markiert der Anwender alle weiteren benötigten Daten. Dann schaltet er mit »Continue Browsing« wieder in den normalen Modus zurück. Über »Show Items« blendet Portia noch einmal alle bislang extrahierten Daten ein.
Ausgehend von der gerade geladenen Seite folgt Slybot nun allen Links, schneidet dort jeweils die markierten Informationen aus und liefert sie zurück. Dieses Verhalten kann der Spinnenmeister über Einstellungen beeinflussen, die sich nach einem Klick auf das graue Dreieck am rechten Seitenrand offenbaren.
Über den Slider »Initialize« fügt der Anwender dem Projekt noch weitere Internetseiten hinzu. Dazu tippt er einfach die URL in das leere Feld und klickt anschließend auf das Plussymbol, ein Klick auf die URL öffnet die entsprechende Seite wieder im Hauptbereich. Dort kann er dann weitere auszuschneidende Bereiche markieren. Verwendet eine der Seiten einen Passwortschutz, setzt der Anwender einen Haken vor »Performe Login« und tippt dann die Login-Daten ein.
Routenplanung
Auf dem Slider »Crawling« steuert der Nutzer das Verhalten von Slybot. Er legt fest, ob Slybot sich an die vom Webmaster in der »robots.txt« vorgegebenen Zugriffsregeln hält (»Respect Nofollow« ). Soll der Spider bestimmte Seiten ignorieren, setzt der Anwender die Dropdown-Liste auf »Configure Follow And Exclude Patterns« . Slybot folgt jetzt nur noch jenen Links, die mit dem regulären Ausdruck im oberen Feld übereinstimmen. Analog folgt Slybot keinem Link, auf den der reguläre Ausdruck im unteren Feld passt. Wer »Overlay Blocked Links« anhakt, sieht links in der Vorschau, welchen Links der Spider derzeit folgen würde und welchen nicht (Abbildung 3).
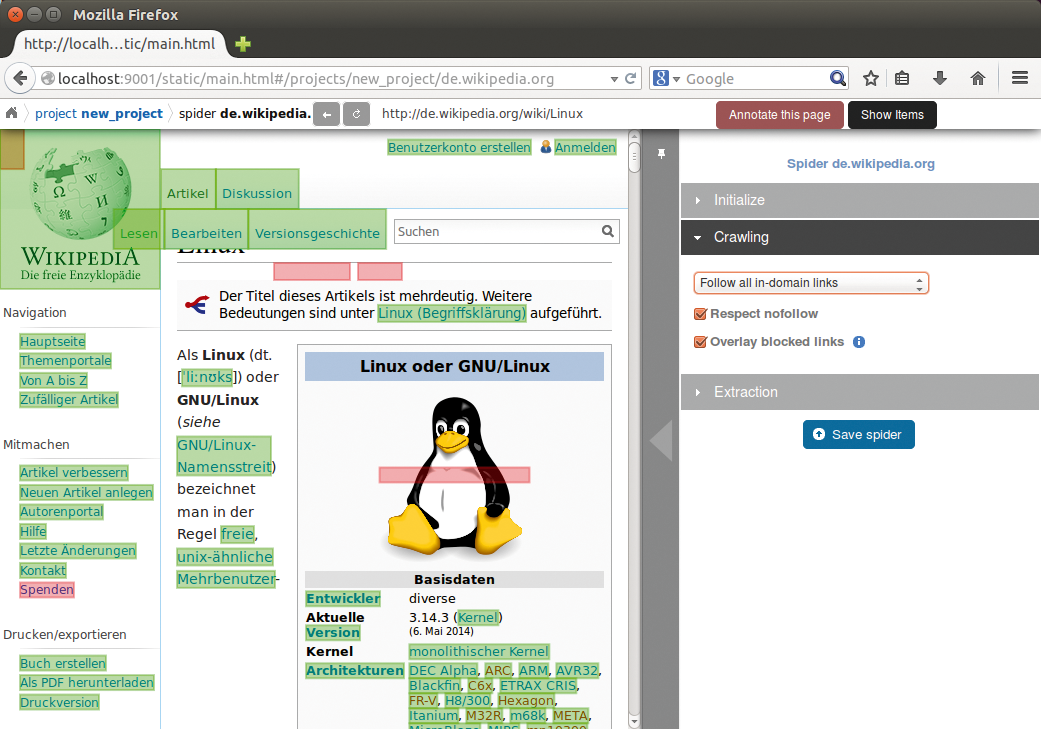
Abbildung 3: Allen grün markierten Links würde Slybot folgen, den rot hervorgehobenen hingegen nicht.
Die zuvor auf einer Seite hellblau markierten Stellen merkt sich Portia in einem so genannten Template. Der Slider »Extraction« listet alle derzeit vorhandenen Templates auf. Ein Klick auf einen der Bezeichner öffnet das entsprechende Template im Markierungsmodus. Hier bringt der Anwender jetzt noch auf gewohnte Weise weitere Markierungen an. Die einzelnen ausgewählten Elemente kann er auf dem Slider »Annotations« noch einmal nachbearbeiten.
Mitunter wählt ein Anwender den gewünschten Text nur grob mit der Maus aus und verfeinert die Auswahl auf dem Slider »Extractors« mit einem regulären Ausdruck. Er klickt auf »New Extractor« , zieht den Ausdruck auf das entsprechende Feld darüber, und Slybot wendet ihn auf den ausgeschnittenen Text an und liefert nur das Ergebnis zurück.
Familienzuwachs
Die jetzt komplette Konfiguration bezeichnet Portia als Spider, mit den darin gespeicherten Einstellungen beschneidet Slybot später Seiten, die den gleichen Aufbau aufweisen wie die gerade angezeigte. Ein Spider gilt meist für eine bestimmte Domain, über die Webanwendung legt der Anwender weitere Spinnen an. Diese gruppiert Portia zu so genannten Projekten. So lässt sich etwa ein Projekt »Nachrichten« anlegen, das einen Spider mit allen Einstellungen für »theregister.co.uk« und einen für »slashdot.org« enthält (Abbildung 4).

Abbildung 4: Hier befinden sich im Projekt »Nachrichten« zwei Spider. Mit einem Klick auf den Namen benennt der Anwender das Projekt in dieser Ansicht um.
Standardmäßig erstellt Portia selbst ein Projekt namens »New_Project« . Welche Spider in einem Projekt stecken, erfährt der Anwender, wenn er links oben in der Ecke auf den Projektnamen klickt. Die Seitenleiste listet dann die Spider auf, ein Klick auf diese zeigt die darin abgelegten Einstellungen. Einen neuen Spider ergänzt der Anwender, indem er auf den Projektnamen klickt und dann eine neue URL aufruft. Jeder Spider erhält standardmäßig den Namen der Domain. Alle Projekte listet die Seitenleiste nach einem Klick auf das Haussymbol.
Dauerlauf
Portia platziert alle Projekte in Unterverzeichnissen unterhalb von »slyd/data/projects« , die zugleich als Name des Projekts dient. Welche Spider das Projekt »new_project« anbietet, verrät auf der Kommandozeile:
portiacrawl slyd/data/projects/new_project
Um nun endlich die Informationen aus den Seiten zu schneiden, ruft der Schnittmeister über »portiacrawl« einfach den entsprechenden Spider auf:
portiacrawl slyd/data/projects/new_project de.wikipedia.com
Die Ausgaben landen im Json-Format auf der Standardausgabe, der Parameter »-o« lenkt die Daten in eine Datei um:
portiacrawl slyd/data/projects/new_project de.wikipedia.com -o ausgabe.txt
»portiacrawl« ist eigentlich nur ein Wrapper-Skript für Slybot. Dessen Dokumentation findet sich unter [4].
Fazit
Mit Portia schneiden Anwender schnell und komfortabel Datenhäppchen aus fremden Websites. Dank des Json-Formats lassen sich die zurückgelieferten Daten in eigenen Anwendungen aggregieren und weiternutzen. Mit Hilfe von Cronjobs lasen sich auch fehlende RSS-Feeds ersetzen. Es braucht jedoch einige Klicks, bis der Suchende die Informationen in einer Tabelle markiert hat. Portia verführt allerdings dazu, “einfach mal eben” Informationen von fremden Webseiten zu klauen. Verantwortungsvolle User erhalten mit Portia aber ein praktisches Tool, das ihnen die stundenlange Analyse fremden Codes erspart.
Warnung
Die Daten auf fremden Webseiten sind in den meisten Fällen urheberrechtlich geschützt. Entwickler dürfen folglich nur mit einer Erlaubnis die Informationen und Texte in ihre eigenen Projekte übernehmen.
Die Abfrage der Daten erzeugt zudem eine kontinuierliche Last: Je mehr Unterseiten eine Website besitzt, desto länger saugt Portia am fremden Webserver. Dessen Besitzer dürfte darüber alles andere als erfreut sein und im schlimmsten Fall entsprechende Gegenmaßnahmen treffen.
Infos
- Portia auf Github: https://github.com/scrapinghub/portia
- Scrapy: http://scrapy.org
- Twisted: https://twistedmatrix.com/trac/
- Anleitung zu Slybot: http://slybot.readthedocs.org/en/latest/





