
Der C++-Spezialist Rainer Grimm nimmt ein diffiziles Thema in Angriff: Das neue Memory-Modell von C++11 führt unter Umständen zu überraschendem Verhalten von Programmen. Für mehr Disziplin sorgen atomare Variablen und die so genannte Memory-Ordnung.
Das neue Memory-Modell von C++ beschreibt eine abstrakte Maschine. Es sichert dem Entwickler einerseits definiertes Programmverhalten zu, lässt dem System aber andererseits die Freiheit, eine angepasste ausführbare Datei zu erzeugen. Dieser Vertrag zwischen Programmierer und System ist die Grundlage für hochoptimierten ausführbaren Code, der für die gewünschte Plattform maßgeschneidert ist. Denn was zählt, ist – wie immer – die Performance.
Das System besteht aus dem Compiler, den Prozessoren und den verschiedenen Speichern. Jede der drei Komponenten versucht den resultierenden Code zu optimieren. So kann der Compiler Schleifendurchläufe vereinfachen, unbenutzte Variablen entfernen, Maschinenbefehle eliminieren oder Ausdrücke vorab berechnen. Die Prozessoren dürfen Anweisungen ignorieren oder umordnen, die verschiedenen Speicherlevels (Caches) können Werte zwischenspeichern oder verzögert den anderen Speichern zur Verfügung stellen. Diese Optimierungen gehen von der Annahme aus, dass ein einziger Kontrollfluss existiert. Kein Wunder, dass dieses Modell in Multithreading-Umgebungen eindeutige Regeln in Form eines formalen Vertrags benötigt.
Memory-Modell
Mit C++11 erhielt C++ in Anlehnung an das Memory-Modell von Java ein eigenes, das im Standardfall dem von Java entspricht. Ein Memory-Modell muss atomare Operationen, die partielle Ordnung von Operationen und die Speichersichtbarkeit berücksichtigen (siehe Kasten “Das Memory-Modell”). C++ geht mit dem Relaxed-Memory-Modell aber noch einen Schritt weiter. Damit erlaubt es die Sprache dem Programmierer, auf maximale Optimierung zu setzen.
Das Memory-Modell
Ein Memory-Modell für eine Programmiersprache muss sich mit folgenden Punkten auseinandersetzen:
1. Atomare Operationen: Operationen, die ohne Unterbrechung ausgeführt werden.
2. Partielle Ordnung von Operationen: Eine Reihenfolge von Operationen, die das System nicht umsortieren darf.
3. Sichtbarkeit des Speichers: Zusicherungen, ab wann gemeinsam genutzte Variablen für einen anderen Thread den gleichen Wert besitzen.
Dieser Artikel bietet nur eine Einführung in das komplexe Thema. Alle Feinheiten kennen nur wenige Experten, die etwa den C++-Compiler oder die Bibliotheken für eine Plattform implementieren.
Undefiniertes Verhalten
Dass bereits ein sehr einfaches Programm mit mehreren Threads der alltäglichen Intuition widerspricht, zeigt das Beispiel in Listing 1. Dieser Artikel wird das Programm im weiteren Verlauf sukzessive verfeinern. Das Programm besitzt zwei Threads namens »thread1« und »thread2« , welche die Funktionen »writing()« in Zeile 6 und »reading()« in Zeile 11 ausführen. Die Funktion »reading()« liest die Werte von »x« und »y« in umgekehrter Reihenfolge.
Listing 1
Unsynchronisiertes Schreiben
01 #include <iostream>
02 #include <thread>
03
04 int x,y;
05
06 void writing(){
07 x= 2000;
08 y= 11;
09 }
10
11 void reading(){
12 std::cout << "y: " << y << " ";
13 std::cout << "x: " << x << std::endl;
14 }
15
16 int main(){
17
18 std::cout << std::endl;
19
20 std::thread thread1(writing);
21 std::thread thread2(reading);
22
23 thread1.join();
24 thread2.join();
25
26 std::cout << std::endl;
27
28 };
Da »writing()« den Wert »x« vor dem Wert »y« schreibt, ist die naive Annahme natürlich, dass mögliche Ausgaben des Programms »(11,2000)« , »(0,2000)« und »(0,0)« sind. Dem ist aber nicht so. Es ist durchaus möglich, dass der Programmlauf den Wert »(11,0)« ergibt. Abbildung 1 stellt die möglichen Ergebnisse des hypothetischen Programmlaufs dar.
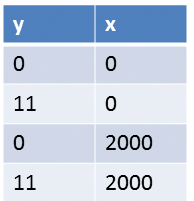
Abbildung 1: Mögliche Resultate bei unsynchronisiert ausgeführten Threads.
Es wird sogar noch schlimmer: Da die Variablen »x« und »y« nicht atomar sind, geschieht ihr Lesen und Schreiben ungeschützt, sodass sie beliebige Werte enthalten können. Die Rettung vor solch undefiniertem Verhalten naht mit Locks.
Schutz mit Locks
Locks sorgen für Ordnung. Das bedeutet für den konkreten Fall (Listing 2), dass entweder »thread1« oder »thread2« als Erster zum Zuge kommt. Folglich sind die Ausgaben »(0,0)« oder »(11,2000)« in Abbildung 2 möglich.
Listing 2
Synchronisation mit Locks
01 #include <iostream>
02 #include <mutex>
03 #include <thread>
04
05 std::mutex mutex;
06
07 int x,y;
08
09 void writing(){
10 mutex.lock();
11 x= 2000;
12 y= 11;
13 mutex.unlock();
14 }
15
16 void reading(){
17 mutex.lock();
18 std::cout << "y: " << y << " ";
19 std::cout << "x: " << x << std::endl;
20 mutex.unlock();
21 }
22
23 int main(){
24
25 std::cout << std::endl;
26
27 std::thread thread1(writing);
28 std::thread thread2(reading);
29
30 thread1.join();
31 thread2.join();
32
33 std::cout << std::endl;
34
35 };
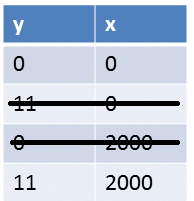
Abbildung 2: Bei der Synchronisation mit Threads sind nur noch zwei Ergebnisse möglich.
Das Aufrufen der Paare »mutex.lock()« und »mutex.unlock()« in den Zeilen 10 und 13 sowie in den Zeilen 17 und 20 stellt zwar sicher, dass nur ein einziger Thread in der kritischen Region der Funktion »writing()« oder »reading()« aktiv ist.
Das Lock leistet aber noch mehr. Zum einen sorgt »mutex.lock()« in Zeile 17 dafür, dass der lesende Thread alle aktuellen Werte der Variablen »x« und »y« erhält. Zum anderen erreicht der Aufruf »mutex.unlock()« in Zeile 13, dass der schreibende Thread seine geänderten Daten veröffentlichen darf. In diesem Zusammenhang spricht der C++-Standard von der Acquire-Semantik (in Besitz nehmen) des »mutex.lock()« -Aufrufs und von der Release-Semantik (freigeben) des »mutex.unlock()« -Aufrufs.
Ein weiterer Aspekt der Aufrufe »mutex.lock« und »mutex.unlock« ist bemerkenswert: Sie erklären einen untrennbaren, atomaren Programmbereich. Das hat den schönen Seiteneffekt, dass die Aufrufe in diesem ebenfalls atomar sind. So ist das Schreiben und Lesen der Variablen »x« und »y« wohldefiniert, insbesondere kann das Programm keine beliebigen Werte schreiben oder lesen. Damit leisten Locks deutlich mehr, als es der erste Anschein vermuten lässt.
Dieser Aufwand hat aber seinen Preis. Das größte Performanceproblem besteht darin, dass immer nur ein Thread aktiv sein kann. Polemisch ausgedrückt: Die Synchronisation mit Locks macht aus einem Multithreading- ein Singlethreading-Programm. Der Programmablauf ist zu Lasten der Performance wohldefiniert. Abhilfe schaffen atomare Variablen, die Teil des C++-Memory-Modells sind.
Atomare Variablen
Statt der Funktionen »reading()« und »writing()« schützt Listing 3 nur die Variablen »x« und »y« . Der Code erklärt sie zu atomaren Variablen. C++ bringt einen Satz einfacher atomarer Datentypen mit [1], daneben lassen sich auch eigene definieren. Atomare Datentypen haben einen offensichtlichen und einen nicht so offensichtlichen Mehrwert: Zum einen sind Operationen auf ihnen atomar, zum anderen legen sie im Standardfall eine Ordnung fest.
Listing 3
Synchronisation mit atomaren Variablen
01 #include <iostream>
02 #include <atomic>
03 #include <thread>
04
05 std::atomic<int> x, y;
06
07 void writing(){
08 x.store(2000);
09 y.store(11);
10 }
11
12 void reading(){
13 std::cout << y.load() << " ";
14 std::cout << x.load() << std::endl;
15 }
16
17 int main(){
18
19 std::cout << std::endl;
20
21 std::thread thread1(writing);
22 std::thread thread2(reading);
23
24 thread1.join();
25 thread2.join();
26
27 std::cout << std::endl;
28
29 };
Atomar bedeutet in diesem konkreten Fall, dass das Schreiben der Werte »x« und »y« (Zeilen 8 und 9) und das Lesen (Zeilen 13 und 14) atomar sind. Durch die atomaren Variablen »x« und »y« ist aber auch die Reihenfolge der Variablenzugriffe in den Funktionen »writing()« und »reading()« sequenziell konsistent. Das heißt insbesondere, dass »thread1« die Anweisungen in seiner Funktion »writing()« genau in der Reihenfolge ausführen muss, in der sie im Quelltext stehen. Gleiches gilt natürlich für »thread2« und seine Funktion »reading()« .
Der Begriff sequenzielle Konsistenz stammt aus den 70er Jahren und geht auf den Mathematiker und Informatiker Leslie Lamport zurück, der unter anderem die Textsatz-Sprache Latex geschaffen hat und kürzlich den Turing-Preis erhielt [2]. Im Unterschied zu Listing 2 kann Listing 3 auch die Ausgabe »(0,2000)« besitzen, siehe Abbildung 3. Dieser Fall tritt genau dann ein, wenn auf das Ausführen der Anweisung »y.load()« in Zeile 13 die Anweisungen der Funktion »writing()« komplett ausgeführt werden.
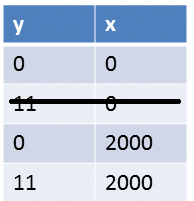
Abbildung 3: Synchronisation mit atomaren Variablen.
Sequenzielle Konsistenz beschreibt das Standardverhalten für atomare Variablen. Sie entspricht der natürlichen Intuition des Programmierers: Die Anweisungen laufen in der Reihenfolge ab, in der sie im Programmcode stehen. Mit dem Relaxed-Memory-Modell verlässt C++ den vertrauten Bereich der Intuition und betritt ein Gebiet, in das sich Programmierer nur im äußersten Fall wagen sollten. Bis zu diesem Punkt unterscheidet sich das Memory-Modell von C++ nicht vom Java-Pendant, dann aber geht es eigene Wege.
Für atomare Variablen lässt sich exakt spezifizieren, welche Zusicherungen Operationen auf ihnen einzuhalten haben. Der Einfachheit halber ist das Listing 4 nur so weit modifiziert, dass es die gleiche Semantik und Ausgabe wie Listing 3 besitzt. Im Vergleich mit Listing 3 erzeugt es potenziell aber eine ausführbare Datei mit besserer Performance.
Listing 4
Acquire-Release-Semantik
01 #include <iostream>
02 #include <atomic>
03 #include <thread>
04
05 std::atomic<int> x, y;
06
07 void writing(){
08 x.store(2000,std::memory_order_release);
09 y.store(11,std::memory_order_release);
10 }
11
12 void reading(){
13 std::cout << y.load(std::memory_order_acquire) << " ";
14 std::cout << x.load(std::memory_order_acquire) << std::endl;
15 }
16
17 int main(){
18
19 std::cout << std::endl;
20
21 std::thread thread1(writing);
22 std::thread thread2(reading);
23
24 thread1.join();
25 thread2.join();
26
27 std::cout << std::endl;
28
29 };
Der Unterschied zwischen den beiden Listings ist minimal. Die »store()« -Operationen in den Zeilen 8 und 9 sind mit »std::memory_order_release« , die »load()« -Operationen in den Zeilen 13 und 14 sind mit »std::memory_order_acquire« ausgezeichnet. Die entscheidende Beobachtung ist, dass Listing 4 die »store()« -Operation der Variablen »y« in Zeile 9 mit der »load()« -Operation der gleichen Variablen in Zeile 13 synchronisiert, sodass die »load« ()-Operation nach der »store()« -Operation ausgeführt wird.
Die »store()« -Operation in Zeile 9 bewirkt, dass die »store()« -Operation der Variablen »x« in Zeile 8 zuvor ausgeführt wird. Außerdem sorgt sie dafür, dass die »load()« -Operation von »x« in Zeile 14 erst nach der »load()« -Operation von »y« in Zeile 13 ausgeführt wird.
Nach dem Verknüpfen der Abhängigkeiten ist das Programm mit minimalem Synchronisationsaufwand wohldefiniert: Einerseits geschieht das Speichern von »x« vor dem Speichern von »y« , das Laden von »x« nach dem Laden von »y« im jeweiligen Thread. Andererseits erfolgt das Laden von »y« nach dem Speichern von »y« . Das Ergebnis dieser Reihenfolge ist, dass »y« und auch »x« die gesetzten Werte aufweisen.
Acquire-Release-Semantik
Der Unterschied zwischen den beiden Varianten von atomaren Operationen ist folgender: Listing 3 gibt keine explizite Memory-Ordnung an. Daher gilt der Standardfall – und der heißt sequenzielle Konsistenz. Somit befinden sich die atomaren Operationen auf dem Thread in einer totalen Ordnung. Im Gegensatz dazu baut die Acquire-Release-Semantik eine teilweise Ordnung der atomaren Operationen auf gleichen Variablen auf.
Relax!
Operationen auf atomaren Variablen verfügen über zwei wichtige Eigenschaften: Sie sind erstens atomar und zweitens definieren sie eine Ordnung (auf atomaren Operationen). Mit der Memory-Ordnung »std::memory_order_relaxed« wird die zweite Zusicherung vollkommen gebrochen. Das macht die Aussagen zu Listing 5 sehr einfach. Den ausführbaren Code darf der Compiler bei diesem Listing beliebig optimieren, lediglich die Atomizität der Variablen »x« und »y« ist sichergestellt. Damit entspricht seine Ausgabe der von Listing 1, in der alle Kombination von »x« – und »y« -Werten möglich sind.
Listing 5
Relaxed-Semantik
01 #include <iostream>
02 #include <atomic>
03 #include <thread>
04
05 std::atomic<int> x, y;
06
07 void writing(){
08 x.store(2000,std::memory_order_relaxed);
09 y.store(11,std::memory_order_relaxed);
10 }
11
12 void reading(){
13 std::cout << y.load(std::memory_order_relaxed) << " ";
14 std::cout << x.load(std::memory_order_relaxed) << std::endl;
15 }
16
17 int main(){
18
19 std::cout << std::endl;
20
21 std::thread thread1(writing);
22 std::thread thread2(reading);
23
24 thread1.join();
25 thread2.join();
26
27 std::cout << std::endl;
28
29 };
Ein feiner, aber entscheidender Unterschied zu dem undefinierten Verhalten von Listing 1 besteht allerdings: Die Werte von »x« und »y« sind nicht undefiniert, sodass sie keine beliebigen Bitmuster enthalten können. Zwischen den beiden Extremen der sequenziellen Konsistenz und dem Relaxed-Memory-Modell kennt C++ noch mehrere Abstufungen: Die Webseite zur Memory-Ordnung [3] liefert die weiteren Details.
Wie geht’s weiter?
Auf diese – zugegeben – schwere Kost soll leichter Verdauliches folgen. So wird der nächste Artikel dieser Serie sich mit der Initialisierung von Objekten beschäftigen. Mit den Initialisierer-Listen für Konstruktoren, der Delegation und der Vererbung von Konstruktoren sowie der direkten Initialisierung der Klassenelemente eines Objekts hat modernes C++ einiges zu bieten, das die Arbeit eines Programmierers deutlich einfacher, aber auch mächtiger macht.
Infos
- »std::atomic« : http://en.cppreference.com/w/cpp/atomic/atomic
- Leslie Lamport: http://en.wikipedia.org/wiki/Leslie_Lamport
- Memory-Ordnung: http://en.cppreference.com/w/cpp/atomic/memory_order
- Listings zum Artikel: https://www.linux-magazin.de/static/listings/magazin/2014/06/cpp/
Der Autor

Rainer Grimm arbeitet als Software-Architekt und Gruppenleiter bei der Metrax GmbH in Rottweil. Insbesondere die Software der hauseigenen Defibrillatoren ist ihm eine Herzensangelegenheit. Seine Bücher “C++11 für Programmierer” und “C++ kurz & gut” sind beim Verlag O’Reilly erschienen.





