
© lightwise, 123RF.com
Wer eine Website betreibt, muss mit Auseinandersetzungen über abfällige Forenbeiträge, Formulierungen über Produkteigenschaften, frühere Shop-Preise oder -Impressen rechnen. Ein gelegentlicher Site-Abzug bringt den Betreiber in eine bessere Position.
“Das stand letzte Woche aber nicht da!” Derartige Aussagen hören nicht nur Inhaber von Onlineshops nach der übereilten Bestellung eines Kunden, auch Moderatoren in Foren müssen sich mit dem Nachklang fremder Beiträge herumschlagen. Um später falsche Behauptungen der Benutzer, Käufer oder sogar windiger Abmahnanwälte zu widerlegen, sollten Administratoren von ihrer Website regelmäßig einen Schnappschuss erstellen und archivieren. Das gilt insbesondere für dynamische Internetauftritte, bei denen die Nutzer die Inhalte selbst gestalten oder einpflegen – wie etwa in einem Forum. Nur so lassen sich auch später noch Seitenänderungen schnell nachvollziehen. Schließlich gibt es für eine Konservierung auch noch nostalgische Gründe: Administratoren und Website-Betreiber können so auf die Anfänge ihres Onlineshops, alte Produkte oder kuriose Diskussionen zurückblicken.
Kriechtiere
Beim Sichern des Ist-Zustands helfen die Tools Heritrix, Httrack und natürlich der Klassiker Wget. Sie rufen wie ein normaler Besucher die Startseite eines Internetauftritts ab und folgen dann allen Links. Eine Software, die sich nach diesem Prinzip von einer Seite zur nächsten hangelt, nennt man Crawler oder Spider. Mit dem gleichen Verfahren klappern Suchmaschinen das Web ab. Anders als Google & Co. speichern Heritrix, Httrack und Wget jedoch alle auf ihrem Weg besuchten Seiten auf dem lokalen Rechner ihres Benutzers.
Die Arbeitsweise der drei Tools hat den Vorteil, dass der Administrator beliebige Websites archivieren kann, selbst wenn er keinen Zugriff auf den Webserver und die Datenbank besitzt oder ihm die Admin-Rechte auf Dauer nichts nützen, da das CMS die Datenbankstruktur ändert. Heritrix, Httrack und Wget biegen zudem in den heruntergeladenen Seiten automatisch alle Links auf die entsprechenden gespeicherten Kopien um, beispielsweise wird aus einem ankommenden
<a href="www.example.de/irgendw.html"> <img src="www.example.de/news/artikel.png" /> </a>
auf der eigenen Festplatte dann ein:
<a href="./irgendw.html"> <img src="./news/artikel.png" /> </a>
Daher lässt sich die archivierte Website genauso wie das Original mit einem Browser aufrufen und durchstreifen. Die Tools ersetzen jedoch kein Backup, ein defekter Onlineshop oder CMS lässt sich aus den gespeicherten Seiten in akzeptabler Zeit nicht wiederherstellen.
Die Tester untersuchten alle drei Werkzeuge auf einem System mit Ubuntu 13.10, die Anbindung ans Internet erfolgte über eine VDSL-Leitung. Als Testobjekte dienten eine statische Website mit etwa 220 Dateien einerseits, der Onlineshop der Medialinx AG [1] andererseits.
Surfgewitter
Heritrix, Httrack und Wget rufen schnell hintereinander alle Seiten eines Internetauftritts ab. Sie erzeugen folglich eine zusätzliche und je nach Einstellungen auch relativ hohe Last, die Webserver-Heuristiken schnell als Angriff interpretieren. Benutzer sind daher gut beraten, die Werkzeuge nur auf eigene Auftritte anzuwenden und sicherzustellen, dass die Tools keine Links zu anderen Websites verfolgen. Wer trotzdem einen fremden Auftritt archivieren möchte oder muss, sollte dessen Betreiber besser und vorab um Erlaubnis bitten.
Heritrix
Das Internet-Archive-Projekt https://archive.org verfolgt das hehre Ziel, die Zeitgeschichte des WWW zu archivieren. Im Backend der Wayback-Machine arbeitet ein selbst entwickelter Crawler namens Heritrix [2]. Das in Java geschriebene Tool steht unter der Apache License 2.0 und lädt auch weniger altruistisch ambitionierte Anwender zum Speichern einzelner Websites ein.
Auf der Heritrix-Homepage finden sich die ältere Version 1.14, die nur Bugfixes erfährt – wobei die letzte Aktualisierung aus dem Jahr 2010 stammt –, und neue Ausgaben, die auf dem Spring-Framework für Java [3] aufsetzen. Bei Redaktionsschluss aktuell war die Version 3.1.1, die sich auch im Test beweisen musste.
Heritrix erwartet ein Java Runtime Environment (JRE). Die Entwickler empfehlen die Fassung von Oracle in der veralteten Version 6. Unter Ubuntu 13.10 arbeitete der Crawler im Test aber reibungslos mit dem vom Software-Center angebotenen Open JDK 7 zusammen. Neben dem Quellcode bieten die Entwickler ein Binärpaket an [3].
Dieses müssen Anwender nur noch auf der Festplatte entpacken, den Pfad zum Heretrix-Ordner in der Umgebungsvariablen »HERITRIX_HOME« hinterlegen (wie etwa »export HERITRIX_HOME= /home/tim/heritrix-3.1.1« ) und schließlich das Tool aufrufen:
$HERITRIX_HOME/bin/heritrix -a Name:Passwort
Die Bedienung erfolgt über eine Weboberfläche im Browser. Dazu startet Heritrix automatisch einen eigenen Webserver, der an Port 8443 lauscht.
Die Verbindung erfolgt HTTPS-verschlüsselt, weshalb Nutzer bei der ersten Kontaktaufnahme ein von Heritrix unterschriebenes Zertifikat bestätigen müssen. Für den Zugriff sind zudem ein Benutzername und ein Passwort notwendig, die der Administrator entweder beim Start von Heritrix über den Parameter »-a« vorgibt oder in einer Textdatei hinterlegt.
Die karge Weboberfläche lässt sich nur umständlich bedienen (Abbildung 1). Um beispielsweise zu erfahren, ob eine Aktion noch läuft oder bereits abgeschlossen ist, müssen Anwender manuell die aktuelle Seite neu laden.
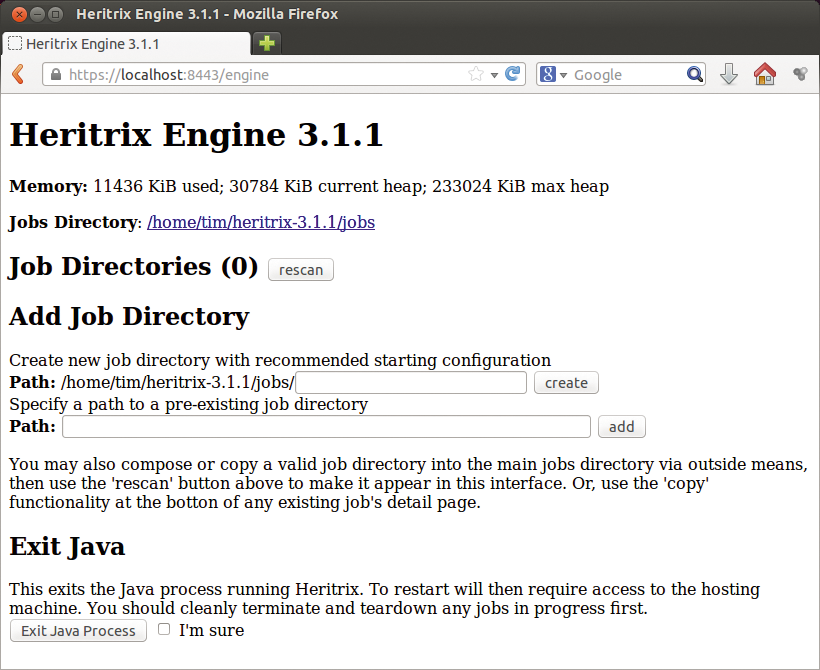
Abbildung 1: Die Weboberfläche von Heritrix besteht nur aus einzelnen HTML-Formularen. Zwischen ihnen wechseln Anwender über die Vor- und Zurück-Buttons ihres Browsers.
Arbeitsagentur
Für jede zu sichernde Website muss der Benutzer einen so genannten Job anlegen. Technisch besteht der aus einem Verzeichnis, in dem später die eigentlichen Webseiten nebst Logs landen, sowie einer kryptischen Konfigurationsdatei im XML-Format. Um sie ganz zu verstehen, ist ein ausführliches Studium des lückenhaften Wiki notwendig, hilfreich sind Kenntnisse über das Framework Spring.
Die Bearbeitung der Konfigurationsdatei erfolgt vorwiegend in einem rudimentären Editor im Browser (Abbildung 2). Immerhin lassen sich Vorlagen für Job-Konfigurationen anlegen, so genannte Profiles.
In der Konfigurationsdatei hinterlegt der Benutzer mindestens die URLs der zu speichernden Websites. Die bezeichnet Heritrix verwirrenderweise als Seeds. Das Tool kennt neben dem HTTP- auch das FTP-Protokoll und sichert somit auch komplette FTP-Server.
Der Crawler gibt sich später als »Mozilla/5.0« aus, fügt im Useragent in Klammern aber seinen Namen, seine Versionsnummer und eine von dem Benutzer vorgegebene Internetadresse hinzu. In der Konfigurationsdatei lässt sich ein beliebiger anderer Useragent eintragen. Dort muss ein Anwender auch die Zugangsdaten hinterlegen, wenn Heritrix eine Website mit Zugriffsschutz archivieren soll. Das Tool kann dabei mit RFC 2617 (Basic und Digest) und HTML-Formularen umgehen.
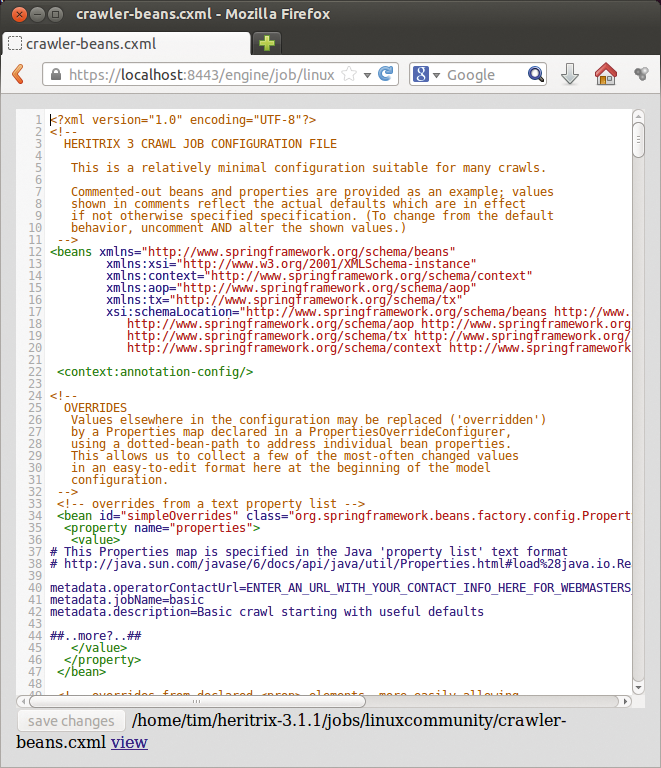
Abbildung 2: Diese Einstellungen in der recht unübersichtlichen Konfigurationsdatei bestimmen das Verhalten von Heritrix.
Im Schneckentempo
Nachdem der Administrator die Konfigurationsdatei angepasst hat, muss er den Job explizit bauen lassen (»build« ). Erst jetzt darf er den Job scharf schalten (»launch« ) und ihn auf das Internet loslassen (»unpause« ). Standardmäßig nimmt Heritrix alle Cookies an und beachtet die Regeln in einer eventuell vorhandenen »robot.txt« .
Der Crawler geht sehr gemütlich zu Werke – im Test sickerten durchschnittlich nur 4 KBit pro Sekunde durch die Leitung. Das Speichern der einfachen statischen Homepage dauerte so 12 Minuten, der Abruf des kompletten Onlineshops quälende Tage (Abbildung 3). Über die Konfigurationsdatei kann der Anwender den Download-Prozess nur indirekt beschleunigen, etwa indem er die Link-Tiefe beschränkt und über Filterregeln bestimmte URLs ausnimmt.
Wer Heritrix nicht so lange unbeaufsichtigt lassen möchte, kann den Job pausieren beziehungsweise unterbrechen. Auch lassen sich Checkpoints anlegen, die den aktuellen Arbeitsstand in einem eigenen Unterverzeichnis konservieren. Später kann der Benutzer den Checkpoint wiederherstellen, Heritrix arbeitet dann an der alten Stelle weiter.
Darüber hinaus führt das Tool ein Journal, mit dessen Hilfe es nach einem Absturz die zuletzt gelesenen Daten rekonstruiert. Den aktuellen Arbeitsfortschritt protokolliert Heritrix in mehreren Logdateien im Job-Verzeichnis sowie auf der Weboberfläche. Die Logs halten detailliert fest, wann Heritrix welche Seiten angefordert hat. Zudem schreibt das Tool mehrere Reports, die Auskunft über die Prozessorauslastung, die Zeitdauern, den Datendurchsatz und so weiter geben [4].
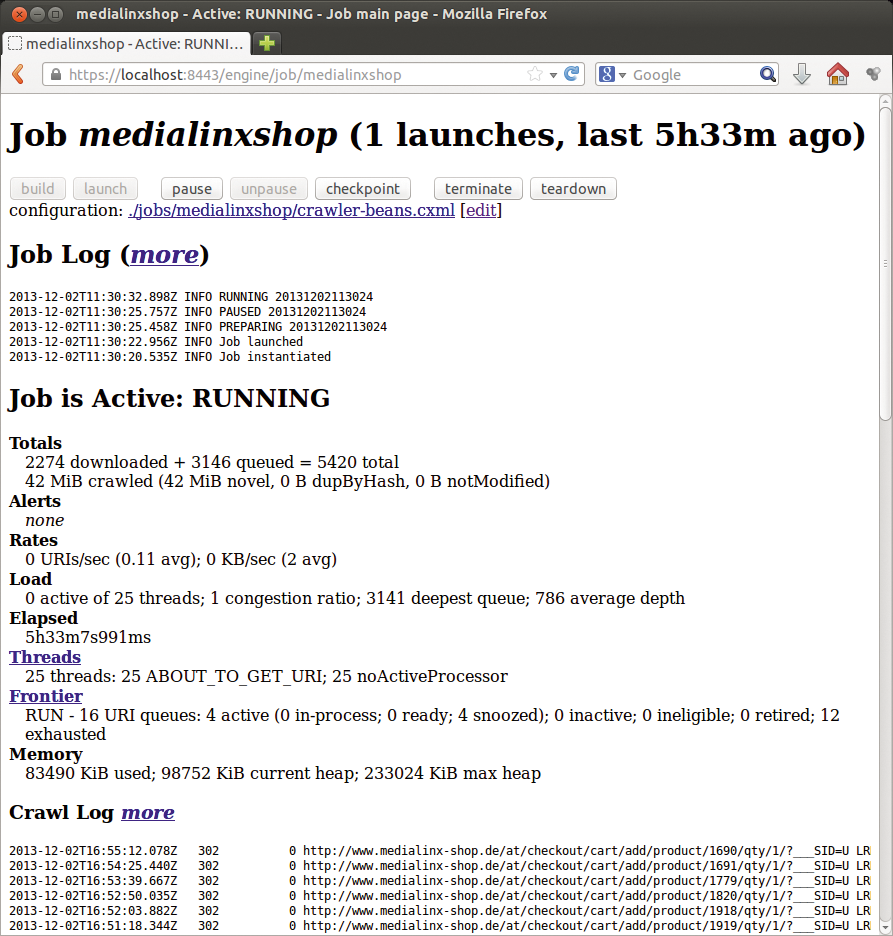
Abbildung 3: Selbst nach über fünf Stunden hatte Heritrix erst 42 MiByte heruntergeladen. Konkurrent Wget war hingegen nach einer Stunde schon fertig und hatte dabei über 700 MByte gesammelt.
Paketpacker
Heritrix steckt sämtliche Seiten in ein WARC-Archiv. Neben den eigentlichen Webseiten enthält dieses “Web ARChive” auch Metadaten, etwa die Zeitpunkte der einzelnen Requests und die dabei verwendeten HTTP-Header. Zwar ist das WARC-Format in einem Standard festgeschrieben [5], jedoch nur wenige Programme benutzen es. Wenigstens legt Heritrix im Verzeichnis »bin« das Tool »arcreader« bei, das ein WARC-Archiv wohl zu öffnen vermag, unter Ubuntu 13.10 jedoch den Dienst verweigerte.
Mit WARC-Dateien füttern lässt sich auch die Wayback-Machine [6]. Diese Webanwendung aufzusetzen erfordert jedoch Kenntnisse des Application-Servers Tomcat. Glücklicherweise handelt es sich bei einem WARC-Archiv schlicht um eine große mit Gzip gepackte Textdatei, die Admins mit einem selbst geschriebenen Skript auseinandernehmen beziehungsweise analysieren können.
Heritrix bietet eine rudimentäre Versionsverwaltung: Sobald der User einen Job anwirft, erstellt Heritrix im zugehörigen Job-Verzeichnis einen neuen Ordner. Dieser trägt das aktuelle Datum und die Uhrzeit als Namen. Darin finden sich dann wiederum alle Logdateien, die Reports, eine Kopie der Konfigurationsdatei und die WARC-Datei. Ins Job-Verzeichnis legt Heritrix zudem einen symbolischen Link namens »Latest« , der auf die letzte Version zeigt. Die Konfigurationsdatei offeriert keine Möglichkeit, diese Namensschemata zu ändern.
Httrack und seine Frontends
Das Kommandozeilentool Httrack [7] steht unter der GPLv3 und liegt praktisch allen großen Distributionen bei. Zum Test trat die in Ubuntu 13.10 serienmäßige Version 3.47.21 an. Wem die Bedienung im Terminal zu fummelig ist, der muss eine Wahl treffen zwischen zwei grafischen Frontends: dem auf Qt fußenden Httraqt [8] und der Webanwendung Webhttrack. Letztere liegt gewöhnlich Httrack bei, einige Distributoren verfrachten sie jedoch in ein eigenes Paket – so auch Canonical in Ubuntu 13.10. Nach seinem Start aktiviert Webhttrack im Hintergrund seinen eingebauten Webserver, der an Port 8080 lauscht, und öffnet anschließend automatisch die Weboberfläche im voreingestellten Browser (Abbildung 4).
Vom Konkurrenten Httraqt gibt es fertige Pakete für Ubuntu, Open Suse, Fedora und Debian auf Sourceforge im Unterordner »Packages« [9]. Die Tester ließen die Version 1.1.9 aus dem Ubuntu-Paket antreten. In der Bedienung ähneln sich Webhttrack und Httraqt sehr: Beide Frontends fragen nach und nach die Einstellungen ab und starten anschließend den Download automatisch (Abbildung 5). Übrigens stellt auch die Kommandozeilen-Version Httrack ihrem Benutzer Fragen, lässt sich aber alternativ auch über Parameter steuern.
In jedem Fall muss der Anwender als Erstes ein neues Projekt anlegen. In ihm merkt sich Httrack die URL der zu speichernden Website sowie alle zugehörigen Einstellungen. Später lässt sich dann der Download mit wenigen Mausklicks erneut anstoßen. Wie bei Heritrix darf der Benutzer mehrere URLs vorgeben, von denen aus sich der Crawler seinen Weg durch das Internet bahnt. Httrack zapft neben HTTP- auch FTP-Server an. Bei zugriffsgeschützten Seiten müssen Anwender ihren Benutzernamen und das Passwort hinterlegen.
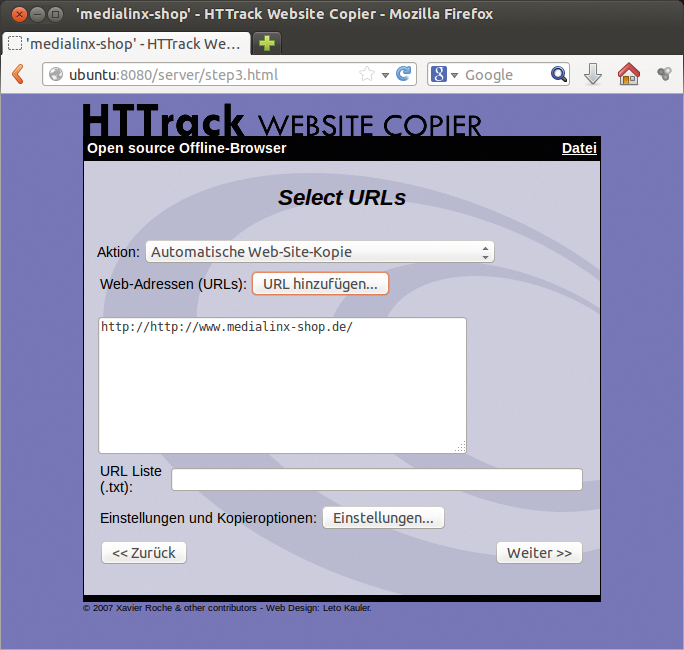
Abbildung 4: Die grafischen Httrack-Frontends Webhttrack und …
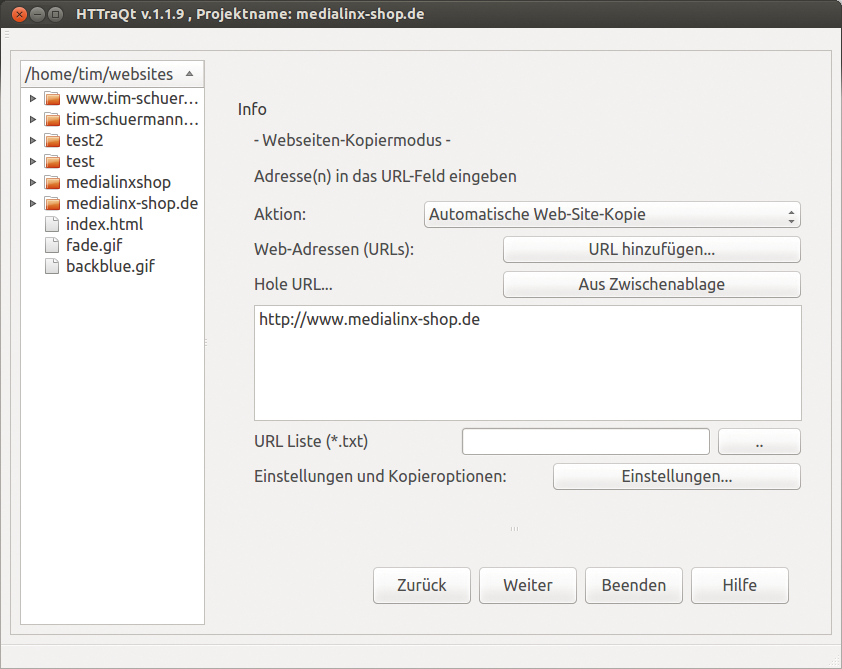
Abbildung 5: … Httraqt ähneln sich in Funktionsumfang und Bedienung sehr. Nach dem Abfragen der Parameter beginnen beide mit dem Download.
Feine Auslese
Im zweiten Schritt entscheidet sich der Anwender für eine Download-Art. Httrack kann in allen Situationen selbstständig entscheiden oder aber bei Links mit herunterladbaren Inhalten jedes Mal nachfragen. Wenn nicht anders instruiert, holt Httrack nur die Seiten der vorgegebenen Domains, andernfalls auch alle anderen von dort aus verlinkten Webpages. Auf Wunsch lädt Heritrix nur ganz bestimmte Dateien herunter, etwa Zip-Archive oder PNG-Bilder, oder prüft lediglich alle Links auf ihre Erreichbarkeit.
Wer über einen Proxy ins Internet geht, muss diesen in den Einstellungen hinterlegen, wo er Httrack im Ganzen detailliert beeinflussen kann. So beschränkt er hier den Download auf HTML-Dateien, klammert Fehlerseiten vom Speichern aus und schließt über Filterregeln bestimmte URLs, Seiten und Dateien explizit ein oder aus. Vorgegeben ist eine Regel, mit der Httrack Links auf das Werbenetzwerk »ad.doubleclick.net« ignoriert.
Ladehemmung
Httrack gibt sich gegenüber dem Webserver als »Mozilla/4.5« aus, tackert aber in die Fußzeile einer jeden heruntergeladenen Seite einen Kommentar mit seinem Namen an. Anwender dürfen sowohl den Useragent als auch den Kommentar beliebig abändern. Httrack achtet vorhandene »robot.txt« -Dateien oder ignoriert auf Wunsch entweder nur deren Filterregeln oder die Datei als Ganzes. Der Crawler nimmt Cookies an, analysiert Java-Dateien und lässt sich am Ende eine Wortliste entlocken.
Httrack geht kaum flotter als Heritrix zur Sache. Im Schnitt wanderten 20 KBit pro Sekunde durch die Leitungen. Die einfache statische Seite mit 221 Dateien war innerhalb von fünf Minuten auf dem lokalen Rechner, der Onlineshop erst nach mehreren Stunden. Wer das zu langsam findet, der schraubt in den Projekteinstellungen so lange an der Übertragungsrate, der zu verfolgende Link-Tiefe sowie der Anzahl der Verbindungen, bis er eine angemessene Dauer erreicht.
Abgebrochene Downloads kann Httrack übrigens später wieder fortsetzen. Webhttrack und Httraqt zeigen während des Downloads die gerade angefragten URLs an (Abbildung 6). Mit einem Klick auf »Auslassen« kann der Anwender die URL überspringen. Da kleine Dateien gerade bei mehreren offenen Verbindungen recht zügig vorbeihuschen, gelingt das Auslassen jedoch nur bei größeren.
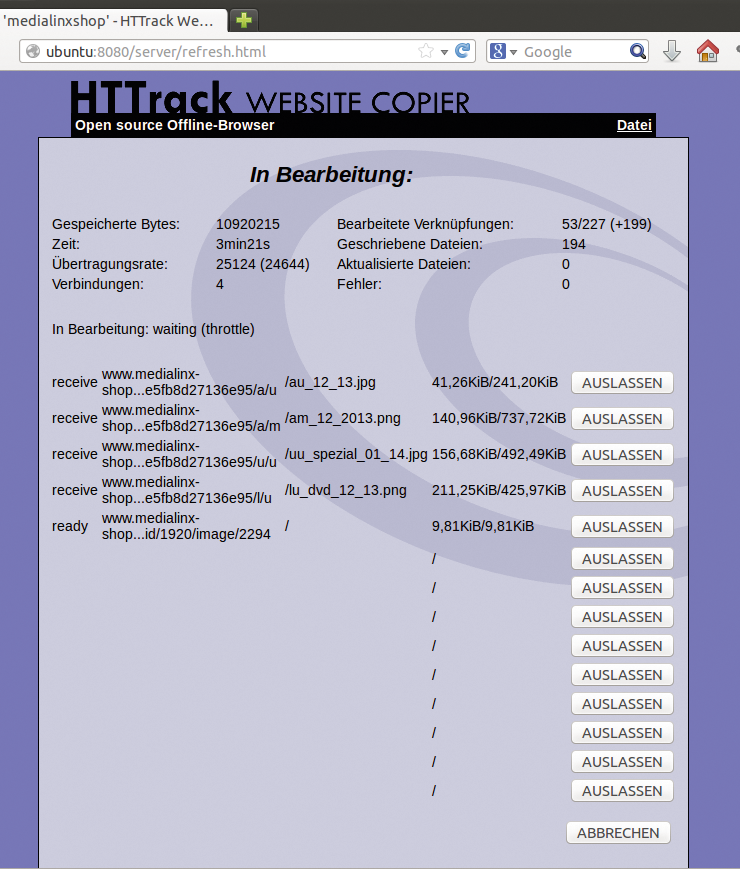
Abbildung 6: Webhttrack-Nutzer dürfen einzelne Downloads abbrechen. Sinnvoll ist das beispielsweise bei sehr großen Dateien oder Archiven.
Ein eigenes Namensschema
Eine eigene Versionsverwaltung bietet Httrack nicht, ein Projekt lässt sich nur aktualisieren. Für jedes Projekt erstellt das Tool aber ein eigenes Verzeichnis. Darin legt es jede Seite in Unterverzeichnissen ab, die sich wiederum an der URL der Seite orientieren. So landet zum Beispiel »http://www.medialinx-shop.de/agb« im Unterordner »www.medialinx-shop.de/agb/« .
Wer es anders will, wählt entweder einen von mehreren Vorschlägen oder bastelt sich über Platzhalter ein eigenes Namensschema. Auf diese Weise kann er beispielsweise alle HTML-Seiten im Verzeichnis »web« sammeln und die Bilder unter »images« . In jedem Fall speichert Heritrix sämtliche Bestandteile der Seite, lädt also auch Javascript- und CSS-Dateien herunter, die Menüs bleiben als Links erhalten.
Wget
Der Weg in die Klassiker-Abteilung der Download-Tools führt schnurstracks zu Wget. Sofern die eigene Distribution das kleine Kommandozeilen-Programm nicht schon von Haus aus installiert, lässt es sich schnell über den Paketmanager nachholen. Im Gegensatz zu Heritrix und Httrack existiert kein offizielles Wget-GUI. Die im Internet feilgebotenen inoffiziellen Frontends sind durchweg veraltet.
Um Wget auf eine Website anzusetzen, übergibt ihm der Anwender die entsprechenden URLs und ein paar Parameter:
wget -r -p -k -Ehttp://www.medialinx-shop.de
Mit »-r« läuft das Tool rekursiv durch die Seiten, »-p« sorgt dafür, dass Wget alle zur Darstellung notwendigen Bestandteile einer Website herunterlädt. Letzteres umfasst insbesondere die CSS- und Javascript-Dateien, Menüs bleiben als Links erhalten. »-k« biegt die Links auf die Kopien um, während »-E« allen HTML-Dateien die Endung ».html« verpasst. Letzteres ist beispielsweise bei Contentmanagement-Systemen sinnvoll, die in ihren URLs die Endung ».php« verwenden.
Wget zapft neben HTTP- und HTTPS- auch FTP-Server an. Weitere Parameter geben die Zugangsdaten für zugriffsgeschützte Seiten sowie maximale Linktiefe und die Anzahl der Wiederholungen vor. Anfragen lassen sich sogar auf IPv4- oder IPv6-Adressen beschränken.
Die statische Beispielseite hatte Wget in weniger als 10 Sekunden heruntergeladen, den Onlineshop binnen einer Stunde (Abbildung 7). Im Gegenzug beanspruchte Wget damit aber auch die Webserver besonders stark. Über Parameter kann der Protokollant die Download-Geschwindigkeit jedoch drosseln und zudem zwischen den Anfragen Wartezeiten einfügen.
Als User-Agent verwendet Wget seinen Namen mit der Versionsnummer, der Anwender darf ihn gegen einen beliebigen anderen austauschen. Über Filterregeln ausgewählt kann er Seiten und Dateien vom Download ausnehmen. Anders als Heritrix und Httrack lädt Wget erst auf explizite Weisung Dateien und HTML-Seiten von anderen Domains herunter. Das Beachten der »robots.txt« darf der Anwender abschalten. Das ist auch oft notwendig, da viele Seiten Wget in der »robots.txt« den Zugriff verbieten.
Bei HTTPS-Verbindungen kann Wget das Zertifikat des Servers auf seine Gültigkeit prüfen. Cookies nimmt das Tool standardmäßig an, verwendet aber auch in Dateiform schon vorhandene auf Zuruf oder weist die Datenkekse komplett ab. Das Tool protokolliert im Terminal jeden seiner Schritte (Abbildung 7), die Textflut lässt sich in eine Logdatei umleiten.
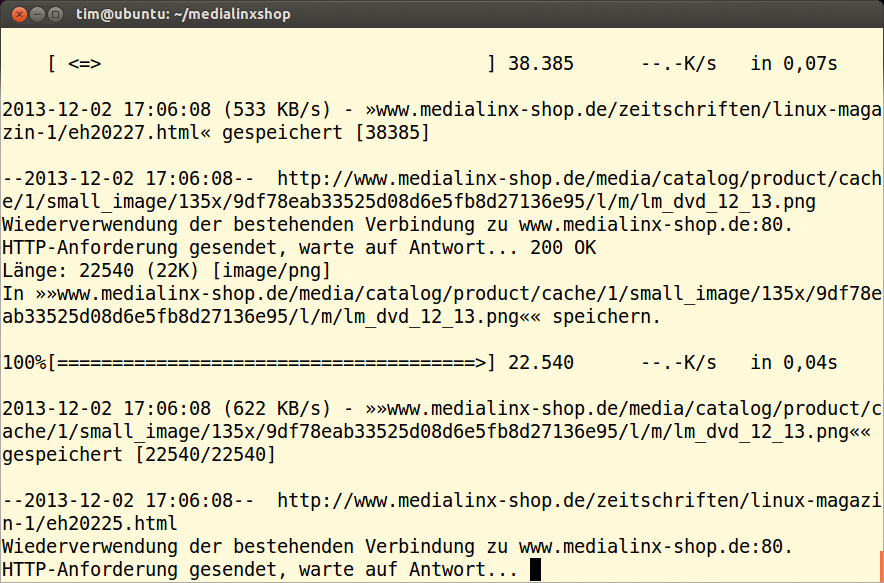
Abbildung 7: Wget rennt extrem schnell durch die Website und protokolliert außerdem den Download-Fortschritt einer jeden Seite im Terminal.
Das Wget-Archiv
Eine Versionsverwaltung kennt Wget nicht, bei einem erneuten Download erstellt das Tool jedoch ein Backup bereits vorhandener Dateien. Gewohnheitsmäßig sammelt Wget heruntergeladene Webseiten in einem Unterverzeichnis mit dem Domainnamen. Das Tool orientiert sich dabei wie Httrack an der URL: Die Seite unter »http://www.medialinx-shop.de/agb« landet im Unterverzeichnis »www.medialinx-shop.de/agb« (Abbildung 8).
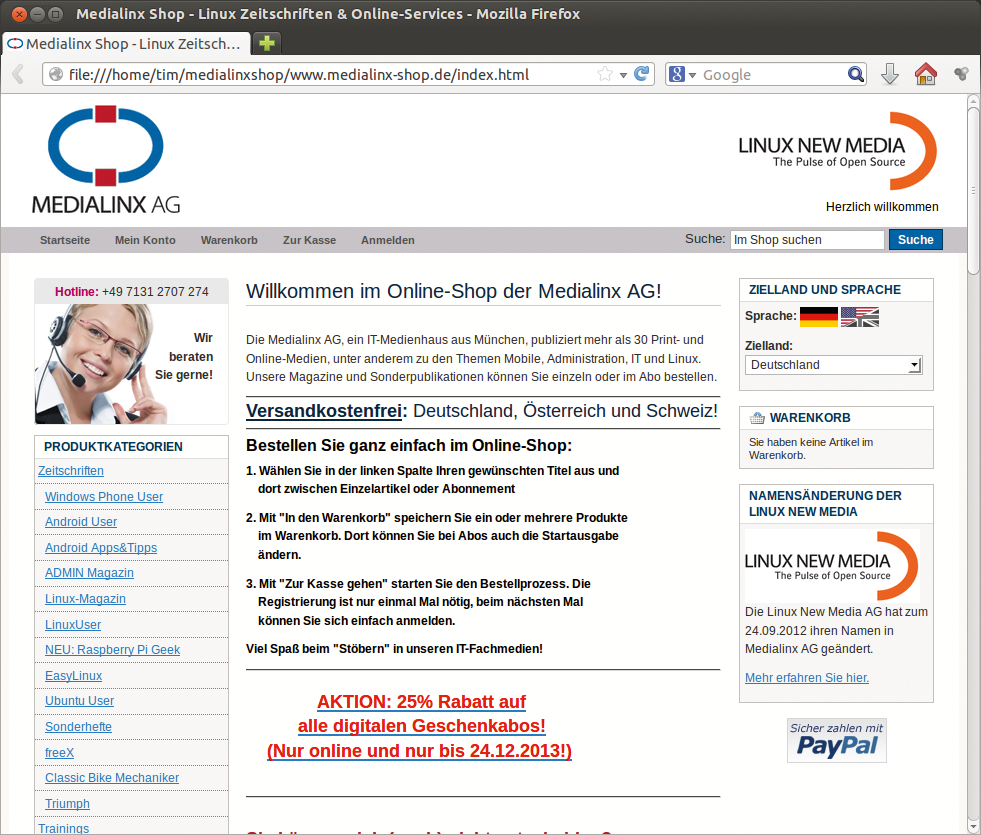
Abbildung 8: Die von den Werkzeugen heruntergeladenen Webseiten lassen sich genau so bedienen wie das Original – hier das von Wget angelegte Archiv.
Schema F
Nur in engen Grenzen kann der User dieses Schema beeinflussen. So darf er alle Dateien in einem einzigen Verzeichnis parken und ein beliebig langes Präfix der URL streichen. Im letzten Fall landet dann etwa die Seite »http://www.medialinx-shop.de/zeitschriften/linux-magazin-1/abm2002.html« im Verzeichnis »linux-magazin-1/abm2002.html« . Auf Wunsch verfrachtet Wget aber auch alle Daten in eine große Text- oder eine WARC-Datei.
Alternativ kann Wget auch nur kurz prüfen, ob alle Linkziele erreichbar sind. Das Umsetzen der Links in den Archiven klappte im Test allerdings nicht ganz fehlerfrei. So führte der Menüpunkt »Raspberri Pi« nicht zur entsprechenden Seite, sondern öffnete nur das Verzeichnis, in der die Unterseite lag.
Verschiedene Archivare
Auch wenn sich der Funktionsumfang der drei Tools stark ähnelt, richten sie sich dennoch an ganz unterschiedliche Zielgruppen. Heritrix ist deutlich auf die Archivierung von Webseiten und das Internet-Archive-Projekt zugeschnitten. Die Konfiguration erweist sich als umständlich und ist im Wiki nur lückenhaft dokumentiert. Java-Programmierer mit Kenntnissen in Spring dürften sich jedoch zügig heimisch fühlen und können zudem den Crawler erweitern beziehungsweise umbauen.
Das Frontend Webhttrack und sein Arbeitskollege Httraqt starten hingegen nach wenigen Mausklicks den Download. Sie eigenen sich damit für alle Site-Administratoren, die unkompliziert einen Schnappschuss erstellen wollen. Das Kommandozeilen-Werkzeug »httrack« lässt sich zudem in eigene Skripte einbinden – vorausgesetzt der Anwender freundet sich mit den zahlreichen kryptischen Parametern an [10].
Sowohl Httrack als auch Heritrix gehen äußerst gemächlich zu Werke. Das schont zwar den zu archivierenden Server, eine Site zu erfassen dauert jedoch mehrere Stunden. Httrack saugt dabei in den Standardeinstellungen etwas schneller als Heritrix. Angenehm flott holt nur Wget die Seiten aus dem Netz. Der Klassiker liegt jeder Distribution bei, lässt sich einfach in Bash-Skripte einbinden und akzeptiert zahlreiche Feineinstellungen über Parameter. Die müssen Einsteiger allerdings erst einmal lernen, um das Studium der ausführlichen Manpage kommen sie folglich nicht herum.
Nicht gerichtsfest
Wichtig zu wissen: Keines der Werkzeuge fertigt eine rechtssichere Kopie an, denn die heruntergeladenen Seiten lassen sich allesamt nachträglich manipulieren. Wer Abmahnung durch Konkurrenten befürchtet, könnte aber die Archive digital signieren und auf ein externes Medium brennen, am besten write-only, behelfsweise auch eine DVD. Bei Aussage gegen Aussage bekommt der eigene Rechtsanwalt zumindest so etwas wie einen Anscheinsbeweis in die Hand.
Infos
- Medialinx Online-Shop: http://www.medialinx-shop.de
- Heritrix: https://webarchive.jira.com/wiki/display/Heritrix/Heritrix
- Spring-Framework: http://spring.io
- Alle von Heritrix erzeugten Logs und Reports: https://webarchive.jira.com/wiki/display/Heritrix/Heritrix+Output
- WARC-Format: http://www.digitalpreservation.gov/formats/fdd/fdd000236.shtml
- Wayback-Machine: http://archive-access.sourceforge.net/projects/wayback/
- Httrack: http://www.httrack.com
- Httraqt: http://httraqt.sourceforge.net/index_de.html
- Download-Seite von Httraqt: http://sourceforge.net/projects/httraqt/files/?source=navbar
- Dokumentation zum Kommandozeilentool Httrack: http://www.httrack.com/html/fcguide.html





