
Eine Logdatei anonymisieren, Fließkommazahlen oder Datumsangaben lokalisieren: Das alles lässt sich mit der C++11-Funktion std::regex_replace() in einem Rutsch umsetzen.
Der Sprachstandard C++11 hat endlich reguläre Ausdrücke eingeführt. Wie moderner C++-Code damit Texte gegen Muster prüft oder Passagen findet, zeigte die vorige Folge dieser Artikelreihe [1]. Daneben kann der Programmierer die leistungsstarken Ausdrücke aber auch nutzen, um Strings zu verändern.
Logdatei anonymisieren
Als einfaches Beispiel soll ein Webserver-Log dienen, in dem die aufrufenden IP-Adressen anonymisiert werden sollen. Dabei kommt die Funktion »std::regex_replace()« zum Einsatz, die die verräterischen Zahlen durch »XXX.XXX.XXX.XXX« ersetzt. Sie benötigt in ihrer einfachsten Form drei Dinge, um ihre Arbeit zu erledigen: Der Aufruf
regex_replace(log,rgxIPs,"XXX.XXX.XXX.XXX")
enthält den String »log« , den regulären Ausdruck »rgxIPS« , der die zu ersetzende Zeichenmuster im Text identifiziert, sowie die Zeichenkette »XXX.XXX.XXX.XXX« , die die Stelle der identifizierten Zeichenmuster einnehmen soll. Dabei tauscht die Funktion »std::regex_replace()« alle Vorkommen des Zeichenmusters im Text aus und gibt den neuen String als Ergebnis zurück (Listing 1).
Listing 1
Anonymisieren einer Logdatei
01 // replace #include <boost/tr1/regex.hpp> with
02 // #include <regex>
03 // and
04 // std::tr1:: with std:: in the source code
05
06 #include <boost/tr1/regex.hpp>
07
08 #include <iostream>
09 #include <string>
10
11 int main(){
12
13 std::cout << std::endl;
14
15 std::string log="66.249.64.13 - - [18/Sep/2012:11:07:48 +1000] GET /robots.txt HTTP/1.0 200 468 - Googlebot/2.1\n"
16 "66.249.64.13 - - [18/Sep/2012:11:07:48 +1000] GET / HTTP/1.0 200 6433 - Googlebot/2.1";
17
18 std::cout << log << "\n\n";
19
20 // anonymize IPs
21 std::tr1::regex rgxIPs(R"([0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3})");
22
23 std::string anonymizeLog{std::tr1::regex_replace(log,rgxIPs,"XXX.XXX.XXX.XXX")};
24 std::cout << anonymizeLog << std::endl;
25
26 std::cout << std::endl;
27
28 }
Das Programm beginnt in bekannter Manier mit den Anpassungen an die Boost-Bibliothek [2], da weder Clang- noch GCC-Compiler die Bibliothek für reguläre Ausdrücke derzeit vollständig unterstützen. Der »log« -String in den Zeilen 15 und 16 enthält die zu anonymisierenden Daten. Anonymisieren bedeutet in diesem konkreten Fall, die IP-Adressen zu verschleiern. Dazu kommt der reguläre Ausdruck in Zeile 21 zum Einsatz: »rgxIPs« beschreibt vier Zahlen, die jeweils durch einen Punkt getrennt sind. Dabei kann jede der Zahlen eine bis drei Stellen aus den Ziffern von 0 bis 9 enthalten: »[0-9]{1,3}« .
Der Gesamtstring erhält die Form eines Raw-String (mit »R”« markiert), damit der Programmierer den Schrägstrich nicht zu schützen braucht. Zeile 23 vollzieht die Ersetzung und damit das Anonymisieren der Daten. Das Ergebnis landet im String »anonymizeLog« .
Zugegeben, das war ein besonders einfacher Anwendungsfall für »std::regex_replace()« . Bestand doch seine Aufgabe lediglich darin, die erkannten Textmuster zu überschreiben. Oft sind aber zwei Schritte beim Modifizieren eines Textes notwendig: Der erste identifiziert das Textmuster, der zweite modifiziert einen Teil des gefundenen Textes. Dank der so genannten Erfassungsgruppen stellt das keine große Herausforderung für »std::regex_replace()« dar.
Fließkommazahlen lokalisieren
Ein typisches Einsatzgebiet für Erfassungsgruppen ist das (Um-)Formatieren von Daten. Im Beispiel liegen die Fließkommazahlen des String »germanDoubles{“+0,85 -13,2 1,0 ,45 -13,7 1,03425 10134,25”}« in deutscher Lokalisierung vor. Um die Kommata in jeder Zahl des String durch die im Englischen üblichen Punkte zu ersetzen, kommt der reguläre Ausdruck in Abbildung 1 zum Einsatz. Dieser zerlegt jede Zahl in ihre zwei Komponenten vor und nach dem Komma. Das tut er mittels zweier Erfassungsgruppen, die Teile des Ausdrucks in runde Klammern einschließen.
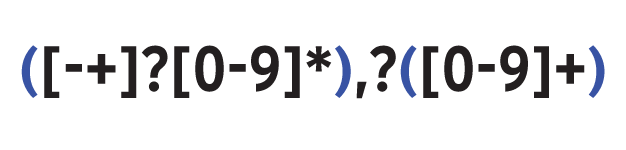
Abbildung 1: Der Ausdruck für deutsche Fließkommazahlen verwendet zwei Erfassungsgruppen.
Die Erfassungsgruppen beeinflussen nicht, wie ein regulärer Ausdruck seine Treffer findet, sondern erlauben es, einzelne Teile eines Treffers explizit zu adressieren. So lassen sich die Vor- und Nachkommastellen einer Fließkommazahl, durch einen Punkt verbunden, wieder zusammensetzen – ein Format, das der englischen Lokalisierung der Zahlen entspricht. Listing 2 setzt die skizzierten Ideen in konkreten C++-Code um.
Listing 2
Fließkommazahlen formatieren
01 // replace #include <boost/tr1/regex.hpp> with
02 // #include <regex>
03 // and
04 // std::tr1:: with std:: in the source code
05
06 #include <boost/tr1/regex.hpp>
07
08 #include <iostream>
09 #include <string>
10
11 int main(){
12
13 std::cout << std::endl;
14
15 std::string germanDoubles{"+0,85 -13,2 1,0 ,45 -13,7 1,03425 10134,25"};
16 std::cout << germanDoubles << std::endl;
17
18 // replace "," with "."
19 std::tr1::regex rgxDouble(R"(([-+]?[0-9]*),?([0-9]+))");
20
21 std::string englishDoubles{std::tr1::regex_replace(germanDoubles,rgxDouble,"$1.$2")};
22 std::cout << englishDoubles << std::endl;
23
24 std::cout << std::endl;
25
26 }
Zwei Stellen in Listing 2 verdienen größere Aufmerksamkeit. Das ist zum einen in Zeile 19 der reguläre Ausdruck »([-+]?[0-9]*),?([0-9]+)« , zum anderen die Anwendung der Erfassungsgruppen in »regex_replace(germanDoubles,rgxDouble,”$1.$2″)« (Zeile 21). Zuerst zum regulären Ausdruck. Er besteht aus einem Teil vor und einem nach dem Komma. Dabei ist das Komma optional »,?« . Vor dem Komma kann ein Minus- oder Plus-Zeichen stehen, auf das beliebig viele Ziffern von 0 bis 9 folgen »[0-9]*« .
Während die Komponenten des regulären Ausdrucks vor dem Komma optional sind, sind die nach dem Komma obligatorisch. Der Nachkomma-Bestandteil der Fließkommazahl besteht ebenfalls aus den Ziffern von 0 bis 9 und muss mindestens eine Stelle aufweisen.
Den Vorkomma- und Nachkomma-Anteil der Fließkommazahl adressiert je eine der beiden Erfassungsgruppen, die sich anschließend in der Replace-Funktion verwenden lassen. Die Funktion »regex_replace()« ersetzt jedes Textmuster in dem Text »germanDoubles« durch den String »$1.$2« . Dabei stehen »$1« und »$2« für die erste und die zweite Erfassungsgruppe des identifizierten Textmusters. Abbildung 2 zeigt die Ausgabe des kleinen Programms.
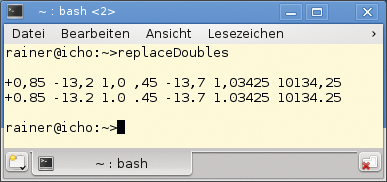
Abbildung 2: Mit regulären Ausdrücken kann C++ das Format von Fließkommazahlen lokalisieren.
Erfassungsgruppen in regulären Ausdrücken sind ein leicht verständliches Konzept, das dennoch interessante Anwendungsfälle abdeckt. So lässt sich mit ihnen beispielsweise die Reihenfolge von Gruppen in einem zu ersetzenden String vertauschen.
Datumsangaben international
Welches Datum verbirgt sich hinter dem Ausdruck »01/02/03« ? Die meisten Leser dürften das als den 1. Februar 2003 interpretieren. So einfach ist es aber nicht, denn die richtige Antwort hängt von der Lokalisierung der Datumsangabe ab, die nach Land und Region verschieden ist. Fast jede Komponente von »01/02/03« lässt sich als Tag, Monat oder Jahr interpretieren. Wer’s nicht glaubt, kann auf der Wikipedia-Seite zum Datumsformat [3] nachsehen. Listing 3 stellt ein paar Beispiele gegenüber, wie der 1. Februar 2003 in verschiedenen Regionen richtig zu formatieren ist.
Listing 3
Datumsformate international
01 // replace #include <boost/tr1/regex.hpp> with
02 // #include <regex>
03 // and
04 // std::tr1:: with std:: in the source code
05
06 #include <boost/tr1/regex.hpp>
07
08 #include <iomanip>
09 #include <iostream>
10 #include <string>
11
12 int main(){
13
14 std::cout << std::endl;
15
16 int len= 17;
17
18 // 01.02.2003
19 std::string german{"01/02/03"};
20 std::cout << std::setw(len) << std::left << "Germany: " << german << std::endl;
21
22 // extract the date parts
23 std::tr1::regex rgxDate(R"(([0-9]{1,2})/([0-9]{1,2})/([0-9]{1,2}))");
24
25 std::cout << std::setw(len) << std::left << "North America: " << std::tr1::regex_replace(german,rgxDate,"$2/$1/$3") << std::endl;
26 std::cout << std::setw(len) << std::left << "South America: " << std::tr1::regex_replace(german,rgxDate,"$1/$2/$3") << std::endl;
27 std::cout << std::setw(len) << std::left << "China: " << std::tr1::regex_replace(german,rgxDate,"$3/$2/$1") << std::endl;
28 std::cout << std::setw(len) << std::left << "Russia: " << std::tr1::regex_replace(german,rgxDate,"$1/$2/$3") << std::endl;
29
30 std::cout << std::endl;
31
32 }
Der reguläre Ausdruck »rgxDate« in Zeile 23 beschreibt das Datumsformat. Er definiert für jede Datumskomponente eine eigene Erfassungsgruppe. In Abbildung 3 sind die Gruppen farbig markiert. Jede der drei Erfassungsgruppen »[0-9]{1,2}« besteht aus den Ziffern 0 bis 9, die genau ein- oder zweimal verwendet sein müssen. Darüber hinaus müssen sie durch den Schrägstrich getrennt sein. In den Zeilen 25 bis 28 kommt der reguläre Ausdruck zum Einsatz.
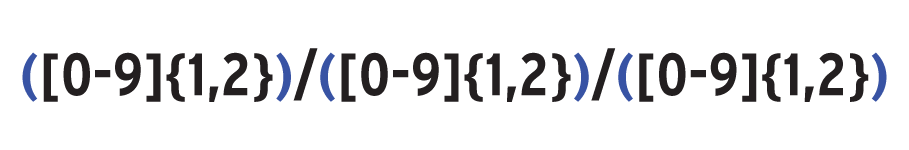
Abbildung 3: Die drei Erfassungsgruppen für Jahr, Monat und Tag kennzeichnen den Ausdruck für Datumsangaben.
Exemplarisch sei der erste Ausdruck erklärt, der die Lokalisierung für Nordamerika umsetzt: Der Funktionsaufruf »regex_replace(german, rgxDate,”$2/$1/$3″)« wendet die Musterbeschreibung »rgxDate« auf den String »german« an, um ihn durch »$2/$1/$3« zu ersetzen. Darin ist aber die Reihenfolge der Datumskomponenten abhängig von der Region umsortiert. Genau dies zeigt Abbildung 4.
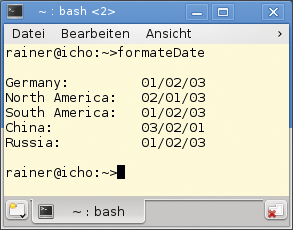
Abbildung 4: Ein kleines C++11-Programm formatiert Datumsangaben für unterschiedliche Regionen.
Erfassungsgruppen können noch mehr
Mit dem Ansprechen der i-ten Erfassungsgruppe durch den Ausdruck »$i« endet die Funktionalität der Erfassungsgruppen jedoch noch nicht. So kann der C++11-Programmierer mit »$« den ganzen Treffer, mit »$`« (Dollar und Backquote) die Zeichenkette vor dem Treffer und mit »$’« (Dollar und Vorwärtsquote) den Text nach dem Treffer ansprechen. Das heißt für einen Text »before66.249.64.13after« konkret, dass der reguläre Ausdruck aus Abbildung 6 die gesamt IP-Adresse »66.249.64.13« mit »$« zur Verfügung stellt. Hingegen ergibt »$`« den String »before« und »$’« den String »after« .
Abbildung 6: Der reguläre Ausdruck zum Anonymisieren des Hostanteils einer IP-Adresse.
Ersetzen auf Iteratoren
In »std::regex_replace()« steckt eine Familie von sechs Funktionstemplates. Die Details lassen sich auf einer Community-Dokumentationsseite zu C++ [4] nachlesen. Besonders praktisch: Zwei interessante Varianten dieser Funktionstemplates arbeiten nicht auf Strings, sondern – nach der bekannten Vorgehensweise der Standard Template Library – auf Iteratoren. Ruft der Programmierer die Funktionen mit dem Flag »std::regex_constants::format_no_copy« auf, so enthält die Ausgabe nur die modifizierten Treffer. So kann er in einem Durchlauf alle Treffer extrahieren, modifizieren und ausgeben.
Listing 4 wendet diese Ideen an: Das Programm extrahiert die IP-Adressen aus dem String, anonymisiert den Hostanteil und gibt das Ergebnis (Abbildung 5) aus. Der Einfachheit halber nimmt der Code an, dass der Hostanteil der IP-Adresse aus den letzten 8 Bits besteht. Abbildung 6 zeigt den regulären Ausdruck, der eine Erfassungsgruppe für den Netzanteil der IP-Adresse verwendet. Zeile 22 definiert den regulären Ausdruck
Listing 4
Hostanteil einer IP-Adresse anonymisieren
01 // replace #include <boost/tr1/regex.hpp> with
02 // #include <regex>
03 // and
04 // std::tr1:: with std:: in the source code
05
06 #include <boost/tr1/regex.hpp>
07
08 #include <iostream>
09 #include <iterator>
10 #include <string>
11
12 int main(){
13
14 std::cout << std::endl;
15
16 std::string log="66.249.64.13 - - [18/Sep/2012:11:07:48 +1000] GET /robots.txt HTTP/1.0 200 468 - Googlebot/2.1\n"
17 "66.249.64.13 - - [18/Sep/2012:11:07:48 +1000] GET / HTTP/1.0 200 6433 - Googlebot/2.1";
18
19 std::cout << log << "\n\n";
20
21 // anonymize IPs
22 std::tr1::regex rgxIPs(R"(([0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3})\.[0-9]{1,3})");
23
24
25 std::string allIPs;
26 std::tr1::regex_replace(std::back_inserter(allIPs), log.begin(), log.end(),rgxIPs,"$1.XXX\n",std::tr1::regex_constants::format_no_copy);
27
28 std::cout << allIPs << std::endl;
29
30 }
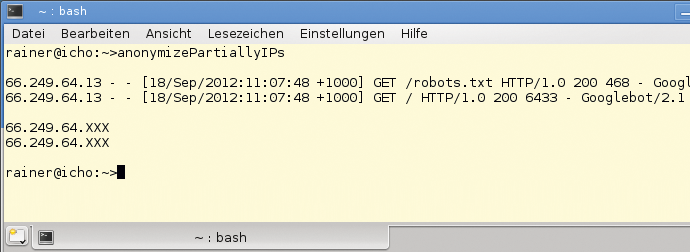
Abbildung 5: Diskret: Mit regulären Ausdrücken und Erfassungsgruppen anonymisiert C++11 gezielt den Hostanteil von Adressen im Webserverprotokoll.
([0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3})\.[0-9]{1,3}«
der in Zeile 26 zum Einsatz kommt. »std::regex_replace()« schiebt durch »std::back_inserter(allIPs)« die modifizierten Strings »$1.XXX\n« auf »allIps« .
Wie geht’s weiter?
Die hier behandelten regulären Ausdrücke besitzen eine Gemeinsamkeit mit dem Datentyp Hashtabelle: Beide vermissten die Entwickler lange in der Sprache C++. Hashtabellen, in anderen Communities auch bekannt unter dem Namen Dictionary oder assoziatives Array, fühlen sich sehr ähnlich an wie die klassischen, assoziativen Container »std::map« . Unter der Oberfläche existieren aber gravierende Unterschiede. Welche das sind, wodurch sich eine Hashtabelle auszeichnet und warum modernes C++ acht verschiedene assoziative Container zur Auswahl bietet, wird der nächste Artikel dieser Reihe erklären. (mhu)
Infos
- Rainer Grimm, “Starke Ausdrücke”: Linux-Magazin 08/13, S. 100
- Boost-Bibliothek: http://www.boost.org
- Datumsformat: http://de.wikipedia.org/wiki/Datumsformat
- »std::regex_replace« : http://en.cppreference.com/w/cpp/regex/regex_replace
- Listings zum Artikel: https://www.linux-magazin.de/static/listings/magazin/2013/10/cpp
Der Autor

Rainer Grimm arbeitet seit 1999 als Software-Entwickler bei der Science + Computing AG in Tübingen. Insbesondere hält er Schulungen für das hauseigene Produkt SC Venus. Im Dezember 2011 ist sein Buch “C++11: Der Leitfaden für Programmierer zum neuen Standard” im Verlag Addison-Wesley erschienen.





