
Was dem Perl-Programmierer altvertraut ist, fehlte C++ bisher. Der neue Sprachstandard C++11 bringt reguläre Ausdrücke ins Spiel, mit denen sich Textmuster beschreiben und finden lassen.
Reguläre Ausdrücke stellen eine Beschreibungssprache für Textmuster dar. C++11 verhilft C++-Entwicklern endlich zu dem lang vermissten Feature. Dieser Artikel führt mit einem kleinen Anwendungsbeispiel in das Programmieren mit Regular Expressions (Regex) ein: Ein E-Mail-Header enthält viele Adressen, die es herauszuklauben lohnt. Wer das nicht von Hand tun möchte, schreibt ein Programm, das diese Arbeit komfortabel und vor allem automatisch mit regulären Ausdrücken erledigt.
Sachter Anfang
Selbst die kompliziertesten Suchanforderungen lassen sich mittels regulärer Ausdrücke definieren. Zum Einstieg in des Thema verwendet dieser Artikel aber einen möglichst einfach gehaltenen Ausdruck, der eine E-Mail-Adresse beschreibt (Abbildung 1). Streng genommen müsste ein regulärer Ausdruck für eine Mailadresse dem RFC 2822 [1] folgen. Ein vollständig standardkonformer Ausdruck [2] ist allerdings sehr schwer verdaulich (siehe Abbildung 2).
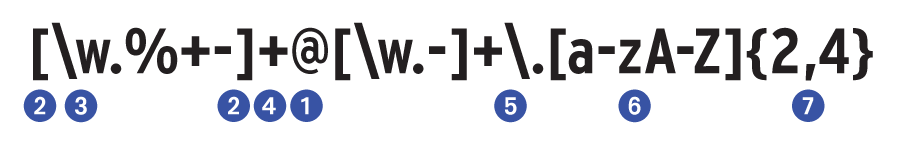
Abbildung 1: Vereinfachter regulärer Ausdruck, der auf eine gültige E-Mail-Adresse passt. Er enthält Zeichen, Zeichenklassen und Klammern.

Abbildung 2: Der reguläre Ausdruck für E-Mail-Adressen ist in seiner standardkonformen Version kaum zu verstehen.
Wie ist der reguläre Ausdruck zu lesen? Am einfachsten gelingt dies mit dem »@« -Zeichen 1 als Ausgangspunkt. Es trennt den lokalen Teil vom Domänenteil einer E-Mail-Adresse. Der lokale Anteil darf verschiedene, durch eckige Klammern 2 zusammengehaltene Zeichen enthalten. Zum einen sind dies Wortzeichen. Sie umfassen Zeichen wie Buchstaben, Zahlen und Unterstriche, die in Wörtern auftreten können. Da diese Zeichen sehr häufig zur Anwendung kommen, sehen die regulären Ausdrücke eine eigene Zeichenklassen dafür vor: »\w« 3.
Weitere gültige Zeichen im lokalen Anteil einer E-Mail-Adresse sind der Punkt ».« , das Prozent- »%« , das Plus- »+« und das Minuszeichen »-« . Von all diesen Zeichen, also »\w.%+-« , muss der lokale Teil mindestens eines enthalten, was das den Klammern folgende Pluszeichen 4 besagt.
Nach dem »@« folgt der Domänenanteil. Dieser beginnt mit mindestens einem Zeichen aus der Menge »\w.-« gefolgt von einem Punkt ».« . Der Punkt ist ein besonderes Zeichen in regulären Ausdrücken, daher muss ihn der Programmierer in diesem Kontext durch einen Backslash 5 maskieren, um einen gewöhnlichen Punkt anzugeben.
Jetzt fehlt nur noch die Top-Level-Domain, und schon ist die E-Mail-Adresse beschrieben. Sie besteht aus einem Wort aus kleinen und großen Buchstaben 6, das nur zwei bis vier Zeichen lang sein darf 7. Zugegeben, dieser reguläre Ausdruck für eine E-Mail-Adresse besitzt noch ein paar Ungenauigkeiten, beispielsweise könnte der Domänenanteil einen Unterstrich enthalten, aber das würde der Einfachheit des Beispiels entgegenstehen.
Exakte Treffer
Die simpelste Frage, die sich mit einem regulären Ausdruck beantworten lässt, ist, ob eine Zeichenkette eine gültige E-Mail-Adresse darstellt. Diese Aufgabe erledigt Listing 1.
Listing 1
Exakte Treffer mit regex_match()
01 // replace #include <boost/tr1/regex.hpp>
02 // with #include <regex>
03 #include <boost/tr1/regex.hpp>
04
05 #include <iostream>
06 #include <string>
07
08 // replace std::tr1:: with std:: in the source code
09 int main(){
10
11 std::cout << std::endl;
12
13 std::string email="rainer@grimm-jaud.de";
14
15 // regular expression for the email address
16 std::string regExprStr(R"(([\w.%+-]+)@([\w.-]+\.[a-zA-Z]{2,4}))");
17
18 // regular expression holder
19 std::tr1::regex rgx(regExprStr);
20
21 // search result holder
22 std::tr1::smatch smatch;
23
24 // looking for an exact match
25 if (std::tr1::regex_match(email,smatch,rgx)){
26
27 std::cout << "Text: " << email << std::endl;
28 std::cout << std::endl;
29 std::cout << "Email address: " << smatch[0] << std::endl;
30 std::cout << "Local part: " << smatch[1] << std::endl;
31 std::cout << "Domain name: " << smatch[2] << std::endl;
32
33 }
34
35 std::cout << std::endl;
36
37 }
Um den Sourcecode konform mit dem neuen C++-Standard zu formulieren, muss der Programmierer den standardkonformen Header (Zeile 3) und den Namensraum (Zeile 8) verwenden. Der vorige Artikel [3] in dieser Reihe erläutert ausführlich die Hintergründe. »rainer@grimm-jaud.de« ist die E-Mail-Adresse, die dem Muster »([\w.%+-]+)@([\w.-]+\.[a-zA-Z]{2,4})« entsprechen soll.
Ein scharfer Blick auf den String »regExprStr« im Programmcode erzeugt anfänglich ein wenig Verwirrung, beginnt er doch mit »R”(« . Das bedeutet, dass ein Raw-String folgt. Der wiederum bewirkt, dass C++11 eine Escape-Sequenz wie den Backslash »\« im String nicht interpretiert. Dadurch ist es nicht mehr notwendig, das Zeichen durch einen weitere Backslash zu schützen. Ein Raw-String besitzt in C++11 die Form »R”(Zeichenkette)”« . Für reguläre Ausdrücke sollte ihn der C++-Programmierer wann immer möglich verwenden.
Der reguläre Ausdruck »regExprStr« unterscheidet sich in zwei weiteren Punkten von dem regulären Ausdruck in Abbildung 1. In »regExprStr« ist sowohl der lokale Anteil als auch der Domänenteil durch zusätzliche runde Klammern gekapselt. Dank dieser weiteren Klammern stehen deren Inhalte als Erfassungsgruppen zu Verfügung. Dadurch kann der Code auf den lokalen Adressenteil mit »smatch[1]« und den Domänenteil mit »smatch[2]« explizit zugreifen. Dies ist schön in Abbildung 3 zu sehen.
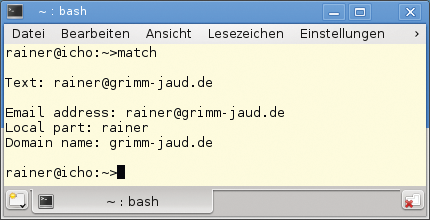
Abbildung 3: Mit »regex_match()« findet der Programmierer den exakten Treffer, auf Wunsch in lokalen und Domänenteil getrennt.
Der Rest von Listing 1 ist schnell erklärt: Zeile 19 instanziert den regulären Ausdruck mit Hilfe von »regExprStr« . Zeile 25 fragt ab, ob der String »email« dem regulären Ausdruck »rgx« entspricht. Das Ergebnis dieser Abfrage speichert der Code in der Variablen »smatch« (Zeile 22). Fällt diese Antwort positiv aus, gibt Zeile 29 den gesamten Treffer mit »smatch[0]« aus. Das Match-Objekt »smatch« kann aber noch deutlich mehr als nur den Gesamttreffer und seine Erfassungsgruppen (Zeilen 30 und 31) anbieten.
Eine mächtigere Antwort verlangt aber eine anspruchsvollere Frage. Die Frage lautet daher nicht mehr, ob der eingegebene Text einer E-Mail-Adresse entspricht, sondern ob sich eine E-Mail-Adresse in einem Text finden lässt.
Im Text suchen
Einfach, aber wirkungsvoll ist die Funktion »regex_search(emailText,smatch,rgx)« in Listing 2. Sie tut genau das, was sie verspricht: Sie sucht in »emailText« nach dem Text, der dem regulären Ausdruck »rgx« entspricht, und gibt anschließend das Ergebnis in dem Match-Objekt »smatch« zurück.
Listing 2
Text suchen mit regex_search()
01 // replace #include <boost/tr1/regex.hpp>
02 // with #include <regex>
03 #include <boost/tr1/regex.hpp>
04
05 #include <iostream>
06 #include <string>
07
08 // replace std::tr1:: with std:: in the source code
09 int main(){
10
11 std::cout << std::endl;
12
13 std::string emailText="A text with an email address: rainer@grimm-jaud.de.";
14
15 // regular expression for the email address
16 std::string regExprStr(R"(([\w.%+-]+)@([\w.-]+\.[a-zA-Z]{2,4}))");
17
18 // regular expression holder
19 std::tr1::regex rgx(regExprStr);
20
21 // search result holder
22 std::tr1::smatch smatch;
23
24 // searching for a match
25 if (std::tr1::regex_search(emailText,smatch,rgx)){
26
27 std::cout << "Text: " << emailText << std::endl;
28 std::cout << std::endl;
29 std::cout << "Before the email address: " << smatch.prefix() << std::endl;
30 std::cout << "After the email address: " << smatch.suffix() << std::endl;
31 std::cout << std::endl;
32 std::cout << "Length of email address: " << smatch.length() << std::endl;
33 std::cout << std::endl;
34 std::cout << "Email address: " << smatch[0] << std::endl;
35 std::cout << "Local part: " << smatch[1] << std::endl;
36 std::cout << "Domain name: " << smatch[2] << std::endl;
37
38 }
39
40 std::cout << std::endl;
41
42 }
Interessanter ist schon die »if« -Schleife in den Zeilen 25 bis 38. Das Match-Objekt gibt den Text vor (Zeile 29) und mit Zeile 30 dem Treffer zurück. Auch die Länge des Treffers lässt sich in Zeile 32 ermitteln. Mit den Ausdrücken »smatch[0]« , »smatch[1]« und »smatch[2]« stehen wieder der Gesamttreffer und die Erfassungsgruppen zur Verfügung. Was das Match-Objekt sonst noch zu bieten hat, ist in [4] übersichtlich dargestellt. Dabei ist »smatch« ein Synonym für »match_re- sults<std::string::const _iterator>« .
Etwas fehlt noch: Mit der Funktion »regex_search()« lässt sich nur eine einzelne E-Mail-Adresse aus dem Text extrahieren. Damit erfüllt »regex_search()« aber nicht die Aufgabenstellung, automatisch alle E-Mail-Adressen aus einem Mailheader zu extrahieren. Dies ist eine Arbeit für die Funktion »regex_token_iterator()« . Mit ihr kann der Programmierer über die Treffer iterieren.
Im Prinzip wäre dies zwar auch händisch durch wiederholtes Anwenden von »regex_search()« möglich. Hier lauern aber einige Gefahren im Detail, die Pete Becker in seinem Buch “The Standard Library Extension” [5] sehr anschaulich darstellt. Listing 3 beginnt vertraut, lediglich der Text »email« in Zeile 19 ist deutlich länger. Richtig spannend wird es in Zeile 35. Der Ausdruck »sregex_token_iterator it(email.begin(),email.end(),rgr)« definiert einen Token-Iterator. Dabei sind die Tokens die E-Mails.
Listing 3
Iterieren über alle Treffer
01 // replace #include <boost/tr1/regex.hpp> with
02 // #include <regex>
03 #include <boost/tr1/regex.hpp>
04
05 #include <iostream>
06 #include <string>
07
08 // replace std::tr1:: with std:: in the source code
09 int main(){
10
11 std::cout << std::endl;
12
13 // regular expression for the email address
14 std::string regExprStr(R"(([\w.%+-]+)@([\w.-]+\.[a-zA-Z]{2,4}))");
15
16 // regular expression holder
17 std::tr1::regex rgx(regExprStr);
18
19 std::string email="From: Mathias Huber <mhuber@linux-magazin.de>\n"
20 "User-Agent: Thunderbird 2.0.0.24 (X11/20101027)\n"
21 "MIME-Version: 1.0\n"
22 "To: Rainer Grimm <rainer@grimm-jaud.de>\n"
23 "CC: Rainer Grimm <R.Grimm@science-computing.de>\n"
24 "Subject: Re: Neuer Artikel\n"
25 "References: <50ABFDEB.2060202@grimm-jaud.de>\n"
26 "In-Reply-To: <50ABFDEB.2060202@grimm-jaud.de>\n"
27 "X-Enigmail-Version: 0.95.0\n"
28 "Content-Type: text/plain; charset=ISO-8859-15\n"
29 "Content-Transfer-Encoding: 8bit\n"
30 "Message-Id: <20121121102930.B9326580@mail.linux-new-media.de>;\n";
31
32 std::cout << email << std::endl << std::endl;
33
34 // define an iterator over all emails
35 std::tr1::sregex_token_iterator it(email.begin(),email.end(),rgx);
36 std::tr1::sregex_token_iterator end;
37
38 // iterate over the emails
39 while (it != end) std::cout << *it++ << std::endl;
40
41 std::cout << std::endl;
42
43 // define an iterator over all capture groups
44 std::tr1::sregex_token_iterator itCaptureBegin(email.begin(),email.end(),rgx,{{1,2}});
45 std::tr1::sregex_token_iterator itCaptureEnd;
46
47 // iterate over the capture groups
48 while(itCaptureBegin != itCaptureEnd){
49 std::cout << *itCaptureBegin++ << " ";
50 std::cout << *itCaptureBegin++ << std::endl;
51 }
52
53 std::cout << std::endl;
54
55 }
Zeile 39 wendet den Iterator an. Das Programm gibt so lange Tokens aus, bis der Iterator »it« den gleichen Wert wie der End-Iterator »end« besitzt. Dies ist dann der Fall, wenn keine E-Mail-Adresse mehr zur Verfügung steht. Der sehr kompakte Ausdruck »*it++« dereferenziert zuerst den Wert des Iterators, gibt ihn aus und geht dann einen Schritt weiter.
Der feine Unterschied zwischen dem Iterator »it« in Zeile 35 und »itCaptureBegin« in Zeile 44 besteht in dem Ausdruck »{{1,2}}« . Dieses optionale Argument für den Iterator bewirkt, dass er über die zweite und die dritte Erfassungsgruppe der Adresse iteriert. Die erste Komponente ist wider der lokale Teil, die zweite der Domänenteil (Abbildung 4).
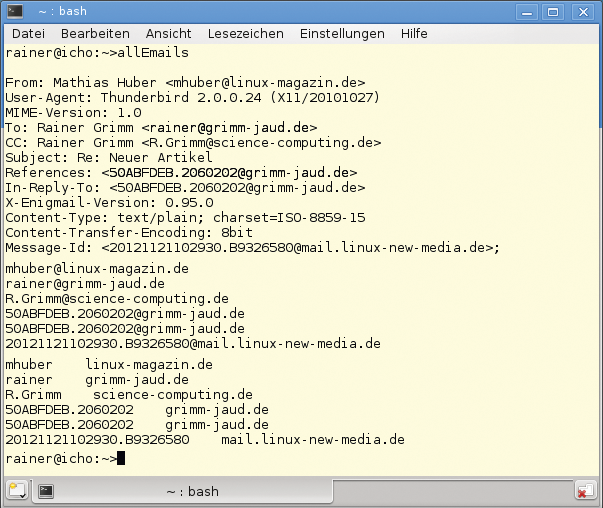
Abbildung 4: Das Programm iteriert über alle Mailadressen in der Eingabe.
In den Zwischenräumen
Die Funktion »regex_token_iterator()« kann aber noch viel mehr [6]. Sie erlaubt es, den Text zwischen den Treffern als Erfassungsgruppe mit dem Index -1 zu adressieren. Damit lässt sich beispielsweise leicht ein Algorithmus formulieren, der aus einer kommaseparierten Liste die Werte extrahiert, indem er das Komma als regulären Ausdruck verwendet.
Bestimmen, ob ein Text einem regulären Ausdruck entspricht oder ob ein regulärer Ausdruck in einem Text ein- oder mehrmals vorkommt – all das hat dieser Artikel gezeigt. Damit ist der Funktionsumfang der regulären Ausdrücke aber nicht erschöpft. Sie können den gefundenen Text nämlich auch ersetzen. Dies ist das Einsatzgebiet von »regex_replace()« , dem sich die nächste Folge dieser Reihe widmen wird. (mhu)
Infos
- RFC 2822: http://tools.ietf.org/html/rfc2822#section-3.1
- Beispiele zu Regular Expressions für E-Mail-Adressen: http://www.regular-expressions.info/email.html
- Rainer Grimm, “Zähl mich!”: Linux-Magazin 06/13, S. 84
- Match-Objekt: http://en.cppreference.com/w/cpp/regex/match_results
- Pete Becker, “The Standard Library Extensions: http://www.petebecker.com/tr1book/tr1book.html
- »regex_token_iterator« : http://www.cplusplus.com/reference/regex/regex_token_iterator/regex_token_iterator/
- Listings zu diesem Artikel: https://www.linux-magazin.de/static/listings/magazin/2013/08/
Der Autor

Rainer Grimm arbeitet seit 1999 als Software-Entwickler bei der Science + Computing AG in Tübingen. Insbesondere hält er Schulungen für das hauseigene Produkt SC Venus. Im Dezember 2011 ist sein Buch “C++11: Der Leitfaden für Programmierer zum neuen Standard” im Verlag Addison-Wesley erschienen.





