
Der Prüfstein für reguläre Ausdrücke heißt Word Count. Das Zählen von Wörtern in einem Dokument zeigt, ob sich eine Programmiersprache für das Prozessieren von Text eignet. Der Autor des Artikels zeigt, dass sich der Klassiker in C++11 fast mit der Kompaktheit von Python implementieren lässt.
Lang, lang ist es her, doch noch immer präsent: In meinem Einstellungsgespräch wurde ich mit der Frage konfrontiert, wie ich in einem Text zuverlässig bestimmen kann, welches Wort am häufigsten vorkommt. Das war beileibe keine triviale Aufgabenstellung, war ich doch mit den denkbar ungeeigneten Waffen C und Fortran angetreten, um die Schlacht zu schlagen. Was damals meine Körpertemperatur um einige Zehntelgrad steigerte, wäre heute keinen Schweißtropfen mehr wert, denn mit assoziativen Containern und regulären Ausdrücken bewaffnet reduziert sich die Lösung des Problems auf ein kurzes Gefecht.
Das ist in der Tat so kurz, dass ich noch gern ein paar weitere Statistiken zu einem Text ermitteln will (Listing 1) – das komplette Listing »wordcount.cpp« hält die Webseite des Linux-Magazins [1] vor. Das Programm zeigt schön, wie sich klassische C++-Funktionen mit denen des modernen C++11 kombinieren lassen.
Listing 1
wordcount.cpp
1 // replace #include <boost/tr1/regex.hpp>
2 // with #include <regex>
3 #include <boost/tr1/regex.hpp>[...]
30 // replace std::tr1 with std::
31 using std::tr1::regex;[...]
34 using str2Int= unordered_map<string,size_t>;
35 using intAndWords= pair<size_t,vector<string>>;
36 using int2Words= map<size_t,vector<string>>;[...]
39 str2Int wordCount(const string& text){
40 regex wordReg(R"(\w+)");
41 sregex_iterator wordItBegin(text.begin(),text.end(),wordReg);
42 const sregex_iterator wordItEnd;
43 str2Int allWords;
44 for (; wordItBegin != wordItEnd;++wordItBegin){
45 ++allWords[wordItBegin->str()];
46 }
47 return allWords;
48 }[...]
51 int2Words frequencyOfWords(str2Int& wordCount){
52 int2Words freq2Words;
53 for ( auto wordIt: wordCount ){
54 auto freqWord= wordIt.second;
55 if ( freq2Words.find(freqWord) == freq2Words.end() ){
56 freq2Words.insert( intAndWords(freqWord,{wordIt.first} ));
57 }
58 else {
59 freq2Words[freqWord].push_back(wordIt.first);
60 }
61 }
62 return freq2Words;
63 }[...]
65 int main(int argc, char* argv[]){[...]
80 ifstream file(myFile, std::ios::in);
81 if ( !file ){
82 cerr << "Can't open file "+ myFile + "!" << endl;
83 exit(EXIT_FAILURE);
84 }
85
86 // read the file
87 stringstream buffer;
88 buffer << file.rdbuf();
89 string text(buffer.str());
90
91 // get the frequency of each word
92 auto allWords= wordCount(text);
93
94 cout << "The first 20 (key, value)-pairs: " << endl;
95 auto end= allWords.begin();
96 advance(end,20);
97 for (auto pair= allWords.begin(); pair != end; ++pair){
98 cout << "(" << pair->first << ": " << pair->second << ")";
99 }
100 cout << "\n\n";
101
102 cout << "allWords[Web]: " << allWords["Web"] << endl;
103 cout << "allWords[The]: " << allWords["The"] << "\n\n";
104
105 cout << "Number of unique words: ";
106 cout << allWords.size() << "\n\n";
107
108 size_t sumWords=0;
109 for ( auto wordIt: allWords) sumWords+= wordIt.second;
110 cout << "Total number of words: " << sumWords <<"\n\n";[...]
117 for ( auto freqIt: allFreq) cout << freqIt.first << " ";
118 cout << "\n\n";
119
120 cout << "The most frequently occurring word(s): " << endl;
121 auto atTheEnd= allFreq.rbegin();
122 cout << atTheEnd->first << " :";
123 for ( auto word: atTheEnd->second) cout << word << " ";[...]
127 auto biggerIt= find_if(allFreq.begin(),allFreq.end(),
128 [](intAndWords iAndW){return iAndW.first > 1000;});
129 if ( biggerIt == allFreq.end()){
130 cerr << "No word appears more then 1000 times !" << endl;
131 exit(EXIT_FAILURE);
132 }
133 else{
134 for ( auto allFreqIt= biggerIt; allFreqIt != allFreq.end(); ++allFreqIt){
135 cout << allFreqIt->first << " :";
136 for ( auto word: allFreqIt->second) cout << word << " ";
137 cout << endl;
138 }
139 }
140 [...]
In den Zeilen 34 bis 36 beginnt der Quellcode – nach einer längeren Serie von Include- und Using-Anweisungen – spannend zu werden. So definiert der Ausdruck »str2Int« ein Alias für ein assoziatives Array, das Strings auf ganze Zahlen abbildet. Da man die Strings mit dem Ziel einsetzt, ganze Zahlen als Ergebnis zu erhalten, werden Erstere als Schlüssel und Letztere als Werte bezeichnet.
Assoziative Arrays, die man auch unter der Bezeichnung Dictionary oder Hash kennt, haben zwei besondere Eigenschaften: Der Zugriff auf ihre Elemente erfolgt konstant, also unabhängig von der Anzahl der enthaltenen Elemente. Zugleich sind ihre Schlüssel, hier also die Strings, nicht sortiert. Diese Charakterzüge unterscheiden die neue Datenstruktur »unordered_map« in C++11 von den »map« -Funktionen im klassischen C++, denn bei diesen verhält sich die Zugriffszeit auf die Werte logarithmisch und die Schlüssel sind sortiert.
In Zeile 36 kommt eine klassische Map zum Einsatz. Diese bildet ganze Zahlen auf einem Vektor aus Strings ab. Bleibt noch das Alias »intAndWords« in Zeile 35 übrig. Es postuliert ein Paar, das aus einer ganzen Zahl und einem Vektor aus Strings besteht.
Einschränkungen für GCC und Clang
Das Beispielprogramm (Listing 1) braucht die Boost-Bibliothek [2], denn die aktuellen GCC- und Clang-Compiler unterstützen die neuen regulären Ausdrücke noch nicht. Im Gegensatz dazu bietet der Visual-C++-Compiler von Microsoft bereits reguläre Ausdrücke an. Für diesen reicht dann ein einfaches Ersetzen der Boost-Header in Zeile 3, wie es die Zeilen 1 und 2 beschreiben, sowie des Namespace »std::tr1::« durch »std::« in der Zeile 30, und schon ist das Programm standardkonform.
Mächtige Helfer
Die Funktion »wordCount()« (Zeilen 39 bis 48) tut wenig überraschend genau das, was ihr Name verspricht. Sie gibt in einem Dictionary zurück, wie oft ein Wort in dem Text vorkommt. Das Wort dient in diesem Szenario als Schlüssel, der Wert enthält hingegen die Häufigkeit, mit der ein Wort im Text auftritt.
Ein Blick auf den zugehörigen Funktionskörper zeigt: Hier kommen reguläre Ausdrücke zum Einsatz. Der reguläre Ausdruck »wordReg(R”(\w+)”)« beschreibt zunächst ein Wort, wobei der eingesetzte Raw-String »R”(regulärer Ausdruck)”« in C++11 dafür sorgt, dass der Entwickler den Backslash im Ausdruck »\w« nicht mehr durch Zuhilfenahme eines weiteren Backslash escapen muss.
Ist der reguläre Ausdruck erklärt, benutzt ihn Zeile 41, um einen Iterator über alle Wörter zu definieren, der als »wordItBegin« in Zeile 44 startet. Der kompakte Ausdruck
++allWords[wordItBegin->str()]
in Zeile 45 nimmt jedes Wort aus dem Text »wordItBegin->str()« und erhöht über »++allWords« den Zähler um 1. Falls das Wort noch nicht im Dictionary steht, legt der Code es erstmalig an, was den Zähler auf »1« setzt.
Die zweite Funktion – »frequencyOfWords()« (Abbildung 1) in den Zeilen 51 bis 63 – erwartet als Argument ebenfalls ein Dictionary aus Schlüssel-Wert-Paaren, die jeweils aus einem String und einer ganzen Zahl bestehen. Hier dreht sich die Relation um: Der Wert wird zum Schlüssel, der Schlüssel zum Wert. Da das Abbilden nicht eindeutig sein kann, wie Abbildung 1 zeigt, landen die neuen Werte in einem Vektor aus Strings.
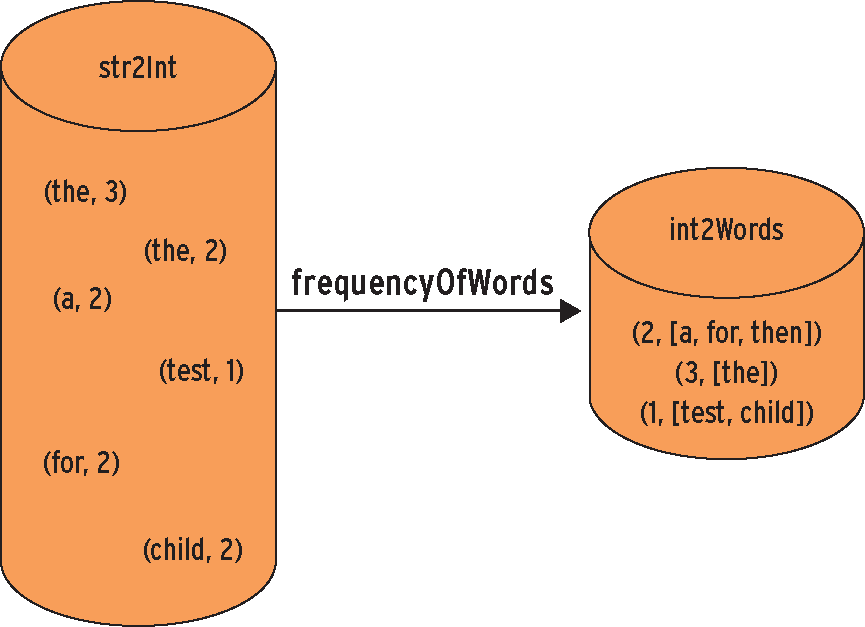
Abbildung 1: Die Funktion »frequencyOfWords« verwandelt Schlüssel-Wert-Paare in Wert-Schlüssel-Assoziationen.
Der Grund: Das Dictionary der Funktion »frequencyOfWords()« enthält zunächst Schlüssel-Wert-Paare, wobei die Schlüssel stellvertretend für die Wörter des Textes stehen und die Werte für die Häufigkeit ihres Auftretens im Text. Die Ausgabe der Funktion besteht hingegen aus Paaren, die jeweils aus einem Wert sowie einem Vektor aus Wörtern bestehen. Dabei stecken alle Wörter, die mit gleicher Häufigkeit auftreten, im selben Vektor.
Diese Invertierung der Schlüssel-Wert-Gemeinschaft findet in der »if« -Schleife in den Zeilen 55 bis 60 statt. Während der »if« -Zweig den initialen Eintrag zum Schlüssel anlegt, schiebt der »else« -Zweig der Schleife das Wort nur hinten auf den Vektor. Dem aufmerksamen Betrachter fällt auf, dass der assoziative Eingabecontainer »str2Int« ungeordnet, der assoziative Ausgabecontainer »int2Words« hingegen geordnet ist. Letzterer sortiert die Schlüssel nach ihrer Häufigkeit und bringt sie so in eine optimale Struktur, um sie in einem späteren Schritt weiterzuverarbeiten.
Name verpflichtet
2013 ist nicht nur offiziell ein Grimm-Jahr, auch als Namensvetter der Gebrüder Grimm ist es natürlich meine Pflicht, die Ausgabe von “Grimms Märchen” im Projekt Gutenberg [3] genauer unter die Lupe zu nehmen. Abbildung 2 zeigt die zugehörige Statistik. Los geht es mit dem Hauptprogramm ab Zeile 65. Als Argument erwartet es einen Pfad, um schließlich die Datei in Zeile 80 zu öffnen und ihren Inhalt in Zeile 89 als String »text« zur Verfügung zu stellen.
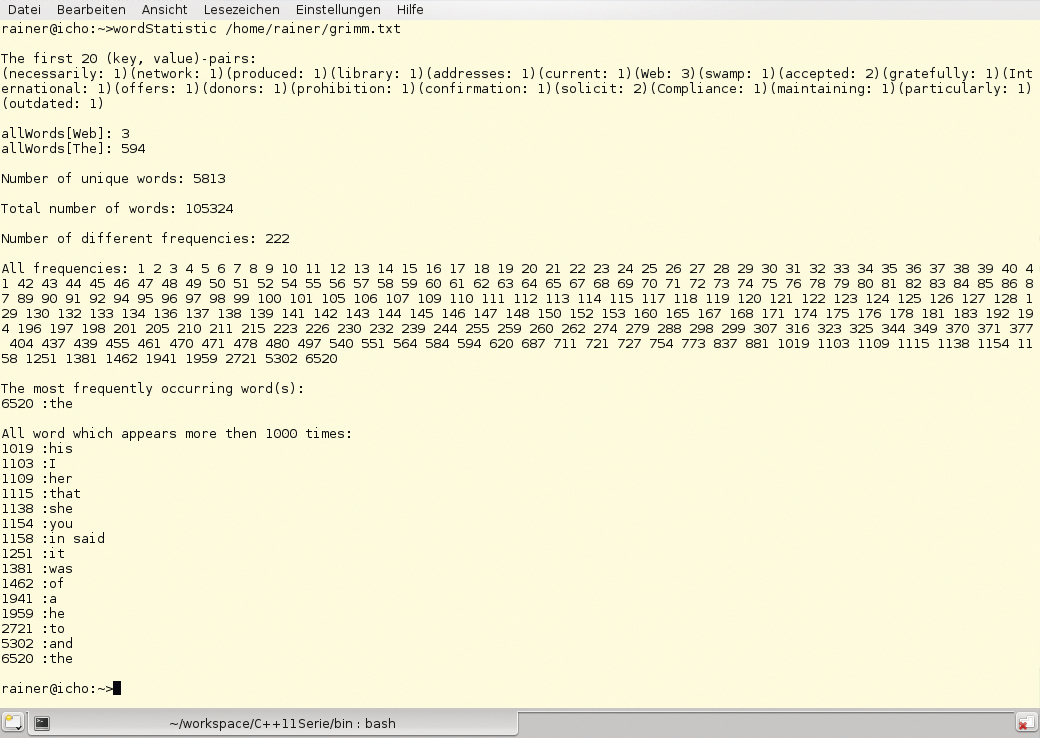
Abbildung 2: Statistische Auswertung der englischen Version von “Grimms Märchen” im Projekt Gutenberg.
Das geht am einfachsten und schnellsten mit Hilfe der Funktion »rdbuf()« des Eingabestreams (Zeile 88). Mit »text« lässt sich die Hilfsfunktion »wordCount()« (Zeile 92) füttern. Sie gibt ein Dictionary zurück, das zu jedem Wort in »text« dessen Häufigkeit enthält. Damit lassen sich einfach die ersten 20 Wörter »advance (end,20)« (Zeile 96) ausgeben.
Hier erst beginnt die statistische Auswertung des Textes, denn »allWords« ist ein Dictionary. Was liegt da näher, als es auch so zu nutzen und explizit etwa nach der Häufigkeit von “Web” (»allWords[“Web”]« ) oder “The” (»allWords[“The”]« ) zu fragen, wie es in den Listingzeilen 102 bis 103 geschieht.
Wie viele verschiedene Wörter enthält der Text? Diese Frage beantwortet dann der Ausdruck »allWord.size()« im Beispieltext mit »5813« , denn er bestimmt die Anzahl der Schlüssel. Wird die Summe über die Häufigkeit aller Wörter (Zeilen 108 bis 110) berechnet, lässt sich die Frage beantworten, wie viele Wörter der Text enthält. Die Antwort lautet »105324« . Die eigentliche Aufgabenstellung bestand allerdings darin, zu bestimmen, welches Wort am häufigsten vorkommt.
An diesem Punkt kommt nun die zweite Funktion »frequencyOfWords« ins Spiel, denn sie stellt die Relation auf den Kopf. Die Schlüssel für die Anfrage sind in diesem Fall nicht mehr allein die Wörter im Text, sondern die jeweilige Häufigkeit ihres Auftretens. Diese Information ist in der Map »allFreq« gespeichert, die verrät, dass Wörter in 222 Häufigkeiten auftreten. In Zeile 117 findet die neue Range-basierte »for« -Schleife sämtliche Häufigkeiten heraus.
Das meistbenutzte Wort kommt 6520-mal im Text vor und lautet – man hat es geahnt – “the”. Da C++11 die Werte der Map »allFreq« standardmäßig aufsteigend sortiert, genügt es, das letzte Schlüssel-Wert-Paar auszugeben. Genau dies findet in den Zeilen 121 bis 123 statt, wobei der Wert ein Vektor aus Strings ist. Die Werte des Vektors – das sind die Wörter mit gleicher Häufigkeit – lassen sich mit einer weiteren Range-basierten »for« -Schleife (Zeile 123) auslesen.
Doch es kommt noch besser. Im nächsten Schritt der Auswertung interessieren den Entwickler alle Wörter, die mindestens 1000-mal im Text vorkommen. Dazu definiere ich einen Iterator »biggerIt« in Zeile 127, der genau die richtige Position in der Map »allFreq« enthält. Das ist möglich, weil diese Map aufsteigend sortiert ist. Der Ausdruck
find_if(allFreq.begin(),allFreq.end(),[](intAndWords iAndW){return iAndW.first>1000;})
ab Zeile 127 gibt genau diesen Iterator zurück, denn die Lambda-Funktion
[](intAndWords iAndW){return iAndW.first >1000;}
definiert das Suchkriterium: Der Schlüssel soll größer als 1000 sein. Der Rest ist eine reine Fingerübung. Die »for« -Schleife (Zeilen 134 bis 138) gibt alle Wörter des Textes aus, die mindestens 1000-mal vorkommen. Die Wörter “in” und “said” gibt es übrigens exakt 1158-mal im Text. Das hier entwickelte Programm lässt sich natürlich auch problemlos auf andere Textdateien anwenden, Abbildung 3 zeigt als einen möglichen Anwendungsfall die Auswertung der Datei »/etc/services« .
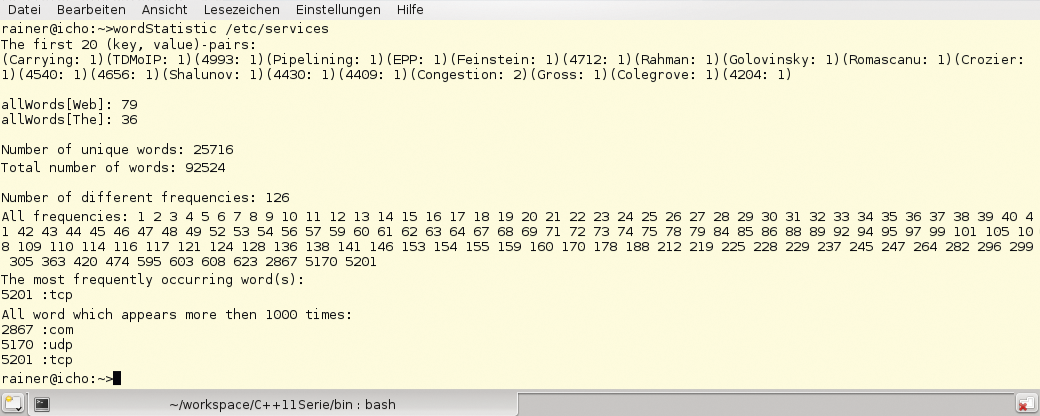
Abbildung 3: Mit Hilfe des Programms »wordcount.cpp« lassen sich auch beliebige andere Textdateien statistisch auswerten, hier die Datei »/etc/services«.
Wie geht’s weiter?
In Zeile 45 gibt der Ausdruck »wordItBegin->str()« das aktuelle Wort zurück. Genauer gesagt ist »wordItBegin« ein so genanntes Match-Objekt, das noch deutlich mehr auf dem Kasten hat, als mit seiner Methode »str()« den Treffer zu extrahieren. Wesentlich mehr Funktionalität besitzt auch die C++11-Bibliothek für reguläre Ausdrücke: Sie identifiziert und verändert Muster in einem Text, filtert bestimmte Elemente heraus oder zerlegt einen Text einfach in seine Bestandteile. Das alles ist Grund genug, die regulären Ausdrücke in der nächsten Folge der C++11-Reihe etwas genauer unter die Lupe zu nehmen.
Infos
- Komplettes Listing zum Text: https://www.linux-magazin.de/static/listings/magazin/2013/06/cpp
- Boosts reguläre Ausdrücke Bibliothek: http://www.boost.org/doc/libs/1_53_0/libs/regex/doc/html/index.html
- Grimms Märchen (auf Englisch) im Projekt Gutenberg: http://www.gutenberg.org/ebooks/11027
Der Autor

Rainer Grimm arbeitet seit 1999 als Software-Entwickler bei der Science + Computing AG in Tübingen. Insbesondere hält er Schulungen für das hauseigene Produkt SC Venus. Im Dezember 2011 ist sein Buch “C++11: Der Leitfaden für Programmierer zum neuen Standard” im Verlag Addison-Wesley erschienen.





